
Abstract
We present a lightweight and scalable method for classifying network and program traces to detect system intrusion attempts. By employing interelement dependency models to overcome the independence violation problem inherent in the Naive Bayes learners, our method yields intrusion detectors with better accuracy. For efficient and lightweight counting of n-gram features without losing accuracy, we use a k-truncated generalized suffix tree (k-TGST) for storing n-gram features. The k-TGST storage mechanism enables us to scale up the classifiers, which cannot be easily achieved by Support-Vector-Machine- (SVM-) based methods that require implausible computing power and resources for accuracy. Experimental results on a set of practical benchmark datasets show that our method is scalable up to 20-gram with consistent accuracy comparable to SVMs.
1. Introduction
Data mining algorithms have been widely used for classifying program traces (i.e., sequences of system calls or sequences of network packets) in intrusion detection tasks. For example, in a host-based intrusion detection task, a program trace is defined as a sequence of system calls that the program invokes during its execution, whereas in a network-based intrusion detection task, a program trace can be defined as a sequence of network packets that the program transmits during its execution. As a preprocessing step for data mining algorithms on intrusion detection tasks, the n-gram (n consecutive system calls in a trace) approach [1] has been widely used for featurization of system call sequences [2–5].
However, those n-gram approaches suffer from three critical problems when applied to intrusion detection tasks.
Dimensionality Issues. Since the number of distinct system calls is usually as many as about 200, the number of distinct n-gram features increases drastically as n increases. For example, the number of distinct SunOS system calls is 183, and if a 20-gram approach is used, then the number of 20-gram features will be Overlap of Features. When n-gram features are generated from an original trace using a fixed-length sliding window, one system call in the trace can be considered as many as n times in the worse case, in the resulting n-gram features [8, 9]. Violation of Independence Assumption. If the resulting intrusion detectors rely on the statistical independence assumption among features (e.g., Naive Bayes), the above-mentioned way of generating overlapped features systematically breaks the assumption.
Against these backgrounds, we applied interelement dependency models [8, 10] of n-gram features to intrusion detection tasks and compared their performance with those of widely used data mining algorithms such as Naive Bayes with n-gram features and those of SVM with n-gram features. To overcome the curse of dimensionality problem, we adapted the k-truncated generalized suffix tree storage mechanism [11, 12] to index system call traces and to generate counts for each n-gram in an efficient way. Since the features with more order information (i.e., longer n-gram features) from an appropriate amount of input data sets usually contribute more to classification, it is important for an intrusion detection algorithm to be scalable with the length of n-grams.
Experimental results on host-based and network-based intrusion detection benchmark data sets show that the proposed method outperforms the Naive Bayes learner with n-gram features as input, which breaks the independence assumption, on intrusion detection tasks and shows comparable accuracies and false positive rates to those of SVMs with n-gram features. With the suffix tree storage mechanism, we tested the performance of the classifiers up to 20-gram in the experiments, which indicates the advantage of scalability of the proposed combination of the interdependency model of n-gram features and suffix tree storage mechanism over the other methods. We were able to perform the experiments with n-grams much longer than 20-grams, but because of lack of data sets and overfitting, the results were not so significant.
The rest of the paper is organized as follows: Section 2 describes our method, Section 3 presents the experimental results, and Section 4 summarizes and concludes this paper.
2. Method
First of all, we introduce Naive Bayes with n-gram features (NB n-gram), interdependency models of n-Grams (IM(n)), and SVM with n-gram features (SVM n-gram). After that, we explain suffix tree mechanism which is used to store n-gram features.
Before we describe each method, we formally define the intrusion detection problem as follows: Let
If a probabilistic model is applied for the intrusion detector h (e.g., Naive Bayes), then the probabilistic model For each class For a new sequence Z, assign the class c such that
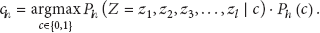
2.1. Naive Bayes Classifier
One of the important assumptions in the Naive Bayes classifier as a host-based intrusion detector is that each system call of the sequence is independent of the other system calls given the class label. Therefore, as for Naive Bayes, the classification (shown in (1)) of a new sequence will be formulated as follows:

When the Naive Bayes classifier is applied to text or protein sequence classification, it treats each document or protein sequence as a bag or set of words or letters that denotes amino acid [9, 13]. There are a few researches [15–17] that explore intrusion detection tasks with a bag or set of system calls, but most intrusion detection researches focus on the n-gram approach [4, 14, 18, 19].
2.2. Naive Bayes with n-Gram Features (NB n-Gram)
Since it is difficult to deal with variable length sequences directly, each sequence
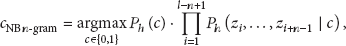
There is one serious problem in the NB n-gram approach. When n-gram features are generated from an original trace using a sliding window, one system call in the trace can be considered and included as many as n times in the resulting n-gram features. This systematically violates the independence assumption of the Naive Bayes learning algorithm.
2.3. Interdependency Models of n-Grams (IM(n))
To overcome the previously mentioned problem, we applied interdependency models of n-grams [8, 10] for scalable n-gram-based intrusion detection. The applied method tried to explicitly model the dependencies among the elements inside an n-gram feature generated from a sequence.
Figure 1 shows the model that describes dependencies among six consecutive elements in a sequence.

Graphical models that incorporate the dependencies among the six consecutive elements in a sequence.
Following the Junction Tree Theorem [20], the probabilistic model for IM(n) is as follows:

From Figure 1 and (4), it can be seen that the probabilistic graphical model of IM(n) is a Markov Network where the probabilistic distribution is obtained by dividing the product of the marginals of the maximal cliques (maximally connected subgraphs) in the graph by the product of the marginals of the separators (overlaps among cliques).
Algorithm 1 shows the pseudocode of the intrusion detection algorithm using the interdependency model.
(1) probabilistic model (2) based on D that comprises the intrusion detector h (3) follows:
2.4. Support Vector Machines with n-Gram Features (SVM n-Gram)
For the comparison of IM(n)'s performance with the other data mining algorithm, we consider Support Vector Machines with n-grams as input.
It is of interest to compare IM(n) and NB n-gram with SVM n-gram, because, in contrast to Naive Bayes with n-gram features (NB n-gram), SVMs do not rely on the independence assumption between features.
However, the SVM algorithm suffers from the explosion of the number of features as n increases, because it takes at least
2.5. k-Truncated Suffix Tree
A suffix tree is a data structure to index a string [11]. Figure 2 shows an example suffix tree for a string “banana$”, where “$” denotes the end of the string. The number in each node represents the number of pattern occurrences. For example, in the string “banana$”, “a” occurs three times and “na” occurs twice.

A suffix tree of a string “banana$”. The number in each node represents the number of pattern occurrences.
When the length of a string is l, then it takes
In practice, to store multiple strings, a generalized suffix tree is used. A generalized suffix tree is a storage that contains all suffixes of a set of strings [11]. An example of a generalized suffix tree for the strings “bagle
Even with the suffix tree storage, it still takes a lot of memory to save the entire traces of system calls. However, in our application, it is not necessary to store a whole trace into a suffix tree. Instead, we store n-gram features into the generalized suffix tree, as shown in Figure 3, which are of interest for generating intrusion detectors.

A 4-truncated suffix tree of “ktruncatedsuffixtree$”.
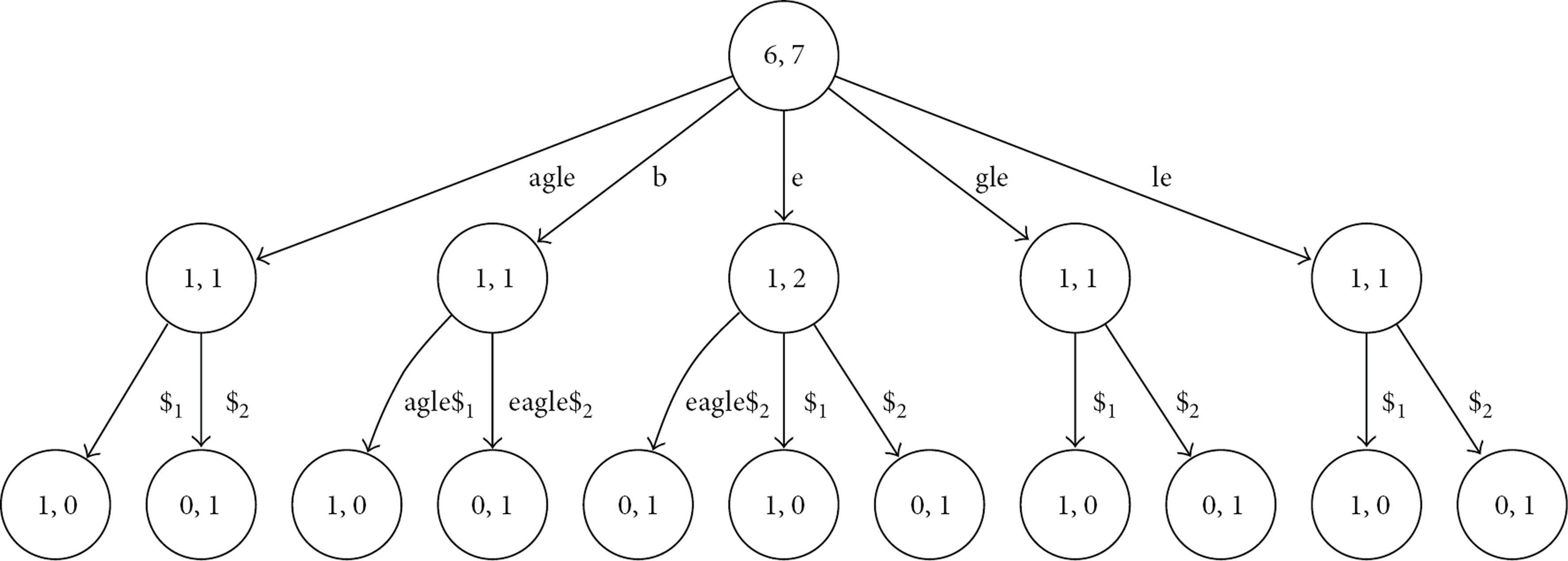
A generalized suffix tree of “bagle
3. Experimental Setup and Results
To evaluate the performance of interdependency models of n-grams (IM(n)), we compared its performance with Naive Bayes (NB), Naive Bayes with n-gram features (NB n-gram), and Support Vector Machines with n-gram features (SVM n-gram). For the experiment, we chose publicly available data sets from the University of New Mexico (UNM) [14] and MIT Lincoln Lab 1998 DARPA Intrusion Detection Evaluation Data Sets (MIT LL 1998) [22].
3.1. Data Sets
3.1.1. UNM Data Sets
The University of New Mexico (UNM) provides a number of system call data sets. Each data set corresponds to a specific attack or exploit. The data sets we tested are “live lpr”, “live lpr MIT”, and “denial of service” (DoS).
In UNM system call traces, each trace is an output of one program. Sometimes, one trace has multiple processes. In such cases, we have made as many sequences as the number of processes in the original trace. Thus, multiple sequences of system calls are made from one trace if the input trace has multiple processes in it. However, most traces have only one process and usually one sequence is created for each trace. Table 1 shows the number of original traces and the number of sequences for each data set.
The number of instances for each type of attack.

There are two different mapping files in the UNM call traces we used for the experiment. One is Sun (live lpr and live lpr.MIT), and the other is Linux (denial of service). There are old and new Sun mapping files but only one system call is added to the new mapping file, so both can be easily converted. The Sun mapping file has a few duplicate system calls (e.g., “fstat”, “stat”, etc.), but we changed them such that each system call is unique.
3.1.2. MIT LL 1998 Data Sets
In the MIT Lincoln Lab 1998 data sets [14], we used both seven weeks of training data and two weeks of testing data. The data comprises a detailed set of data files representing the state of a particular system over eight-hour daytime periods over the course of the nine weeks (seven for training and two for testing). Of interest to the experiments are the omnibus data files containing all system calls made during the collection period and the network traffic analysis files (distilled from raw network data) that identify inbound network connection attempts.
We explained the issues with cross-indexing the data files. The MIT Lincoln Lab data sets include omnibus files containing all system call traces. For each omnibus file, there is a separate, network traffic analysis data file that indicates inbound network connections to the system. Attack attempts are logged with the network data, which implies that labeling the training data requires cross-indexing this file with the system call trace file. The system call trace file identifies the source of each call using the process ID. Therefore, cross-indexing requires tracking the argument to the “exec” system call identifying the binary to be executed. Additionally, the timestamps from the network traffic analyzer do not exactly correspond to the execution timestamps from the operating system kernel. A tolerance of one second is arbitrarily chosen and permits the matching of a large majority of connection attempts with their corresponding server processes on the target system.
All processes detected that do not correspond to some network connection attempt identified in the trace are removed from consideration (since they cannot be classified), as are all calls attributed to a process ID for which an “exec” system call is not found.
As for the experimental setting, we both followed training and testing experiments as explained in the data set description and performed 10-fold cross-validation over the whole nine-week data sets.
3.2. Results
We applied the following performance measures:
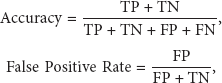
Table 2 shows accuracies and false positive rates of the three algorithms (IM(n), NB n-gram, and SVM n-gram) on the “UNM live lpr” data. IM(n) shows the best performance when n is from 6 to 8. Its performance is comparable to that of Support Vector Machines (SVMs). Overall, IM(n) shows better performance than NB n-gram.
Comparison of accuracy (A) and false positive rate (FP) of intrusion detectors generated by IM(n), NB n-gram, and SVM n-gram on the UNM live lpr data. The accuracies and false positive rates were estimated using 10-fold cross-validation. We calculated a 99% confidence interval on the accuracies and false positive rates. Note that when

As for the “UNM live lpr” data, IM(n) and NB n-gram show the best performance when n is from 6 to 8. The best accuracy and false positive rate of IM(n) are 100.00 and 0.00, and the best accuracy and false positive rate of NB n-gram are 99.87 and 0.24. These results correspond to the widely known claim that “six is the magic number” [23]. However, for the other data sets (“UNM live lpr MIT” and “UNM denial of service”) we have tested, the claim does not always hold.
Table 3 shows the results of the three algorithms for UNM live lpr MIT data. When n is from 17 to 20, IM(n) shows the best performance (accuracy is 99.97 and false positive rate is 0.00) over SVM (accuracy is 99.95 and false positive rate is 0.00) and NB n-gram (accuracy is 93.49 and false positive rate is 8.92).
Comparison of accuracy (A) and false positive rate (FP) of intrusion detectors generated by IM(n), NB n-gram, and SVM n-gram on UNM live lpr MIT data. The accuracies and false positive rates were estimated using 10-fold cross-validation. We calculated a 99% confidence interval on the accuracies and false positive rates. Note that when

In Table 4, which is for the UNM denial of service data, we can see that SVM with 2-grams shows the best performance (accuracy is 99.99 and false positive rate is 0.00), but the difference from the results of IM(n) is very marginal (accuracy is 99.93 and false positive rate is 0.00). Moreover, during the training stage, SVM learns its discriminative model by the Sequential Minimal Optimization algorithm [24], which takes more than several hours. In contrast, IM(n) takes only about one or two minutes and its performance is comparable to that of SVM.
Comparison of accuracy (A) and false positive rate (FP) of intrusion detectors generated by IM(n), NB n-gram, and SVM n-gram on the UNM denial of service data. The accuracies and false positive rates were estimated using 10-fold cross-validation. We calculated a 99% confidence interval on the accuracies and false positive rates. Note that when

In Table 5, we show the results of training and testing experiments on the MIT LL 1998 data sets. In these training and testing experiments, we use predefined training data sets of the MIT LL 1998 data sets for learning intrusion detectors and use predefined testing data sets for evaluating the intrusion detectors. Notice that we do not calculate confidence intervals because it is infeasible to obtain distributions from the train/test setting.
Comparison of accuracy (A) and false positive rate (FP) of intrusion detectors generated by IM(n), NB n-gram, and SVM n-gram on MIT LL 1998 data. We followed the train/test setting specified in the data set description. Note that when
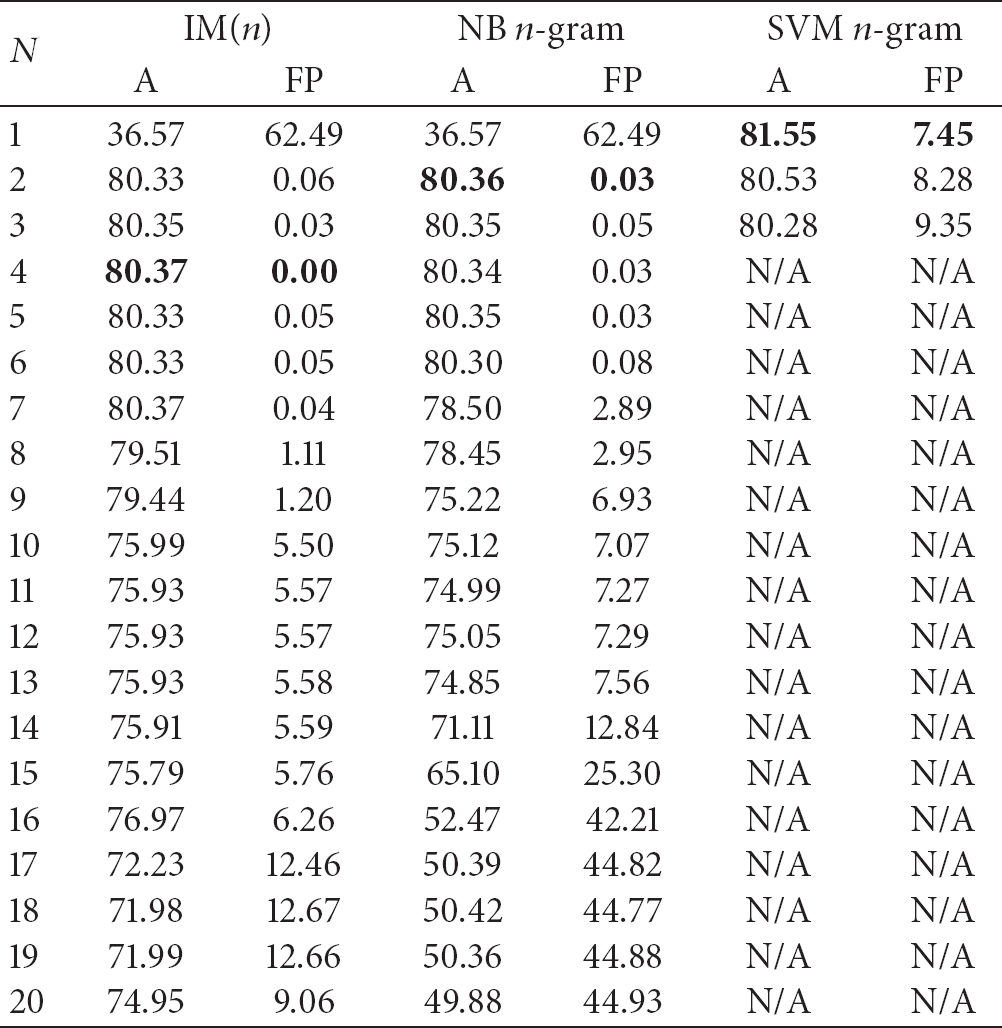
It can be seen that SVM with 1-gram shows the best performance on the accuracy with 81.55, but the false positive rate is 7.45. The difference from the results of IM(4) is marginal (accuracy is 80.37 and false positive rate is 0.00). Moreover, the false positive rate of IM(4) is far better than that of SVM with 1-gram. As discussed, the total learning and testing time of SVM is more than several hours, while, in contrast, it takes about one or two minutes for all the IM(n) models and their performances in general are comparable to those of SVMs.
In Figure 5, we show the Receiver Operating Characteristic (ROC) curves of train/test experiments on the MIT LL 1998 data sets. Area under the curve (AUC) of IM(4) is 0.7290, AUC of NB 2-gram is 0.6654, and AUC of SVM 1-gram is 0.7043. Thus, in terms of ROC, IM(4) outperforms SVM 1-gram.

Receiver Operating Characteristic (ROC) curves of interelement dependency model of 4-gram (IM(4),
In Table 6, we show the results of 10-fold cross-validation on the MIT LL 1998 data sets.
Comparison of accuracy (A) and false positive rate (FP) of intrusion detectors generated by IM(n), NB n-gram, and SVM n-gram on MIT LL 1998 data. The accuracies and false positive rates were estimated using 10-fold cross-validation. We calculated a 99% confidence interval on the accuracies and false positive rates. Note that when
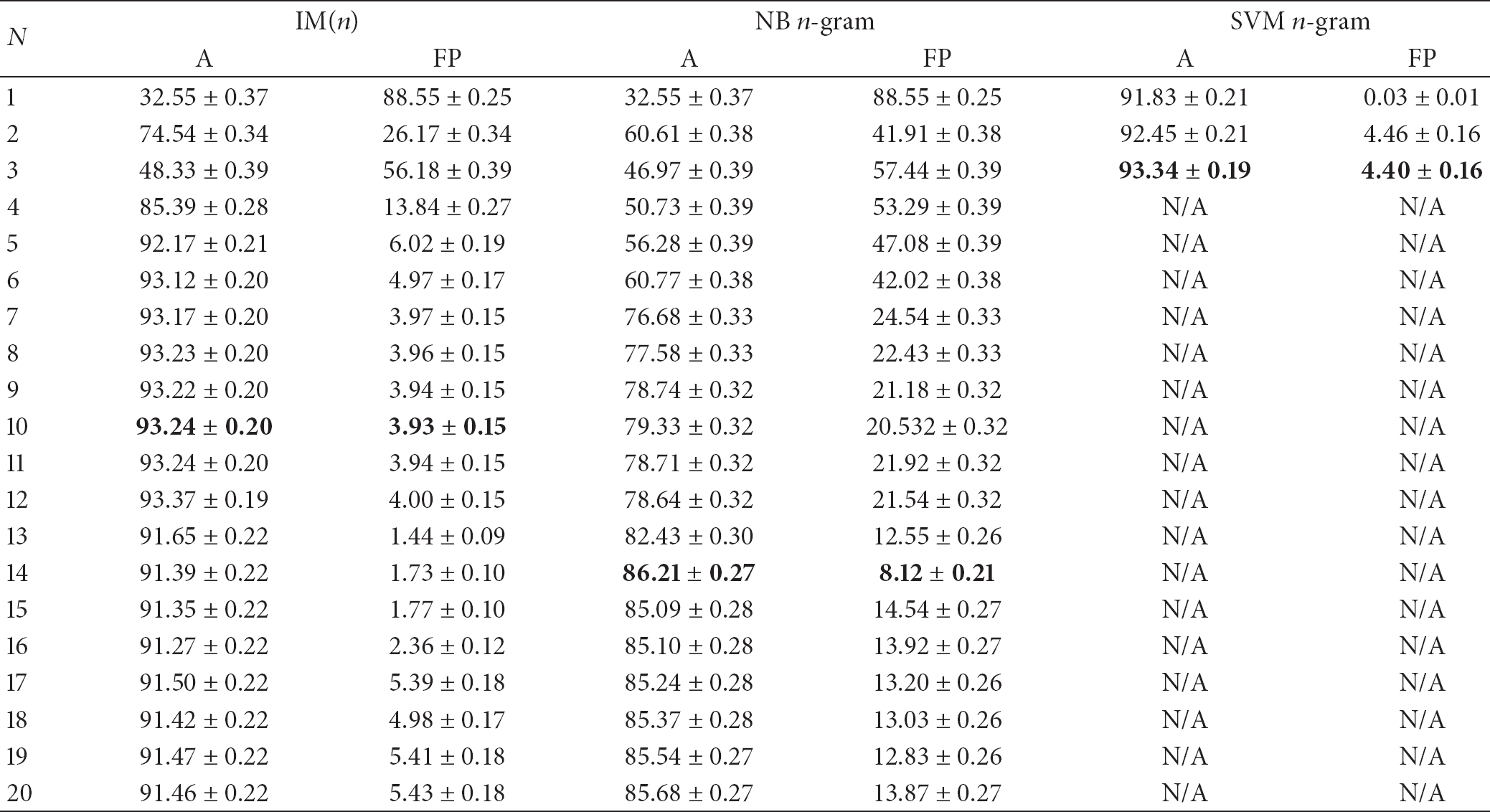
It can be seen that SVM with 3-grams shows the best performance with the accuracy 93.34 and the false positive rate 4.40. Again, the difference from the results of IM(n) is marginal (accuracy is 93.24 and false positive rate is 3.93). Moreover, the running time of SVM 3-grams is more than a week for learning and testing, whereas the running time of IM(n) is less than two minutes and the performance of IM(n) is comparable to that of SVM.
In Figure 6, we show the Receiver Operating Characteristic (ROC) curves of train/test experiments on the MIT LL 1998 data sets. Area Under the Curve (AUC) of IM(10) is 0.7742, AUC of NB 2-gram is 0.5271, and AUC of SVM 1-gram is 0.8729. Thus, in terms of ROC, SVM 1-gram shows the best performance among the three.
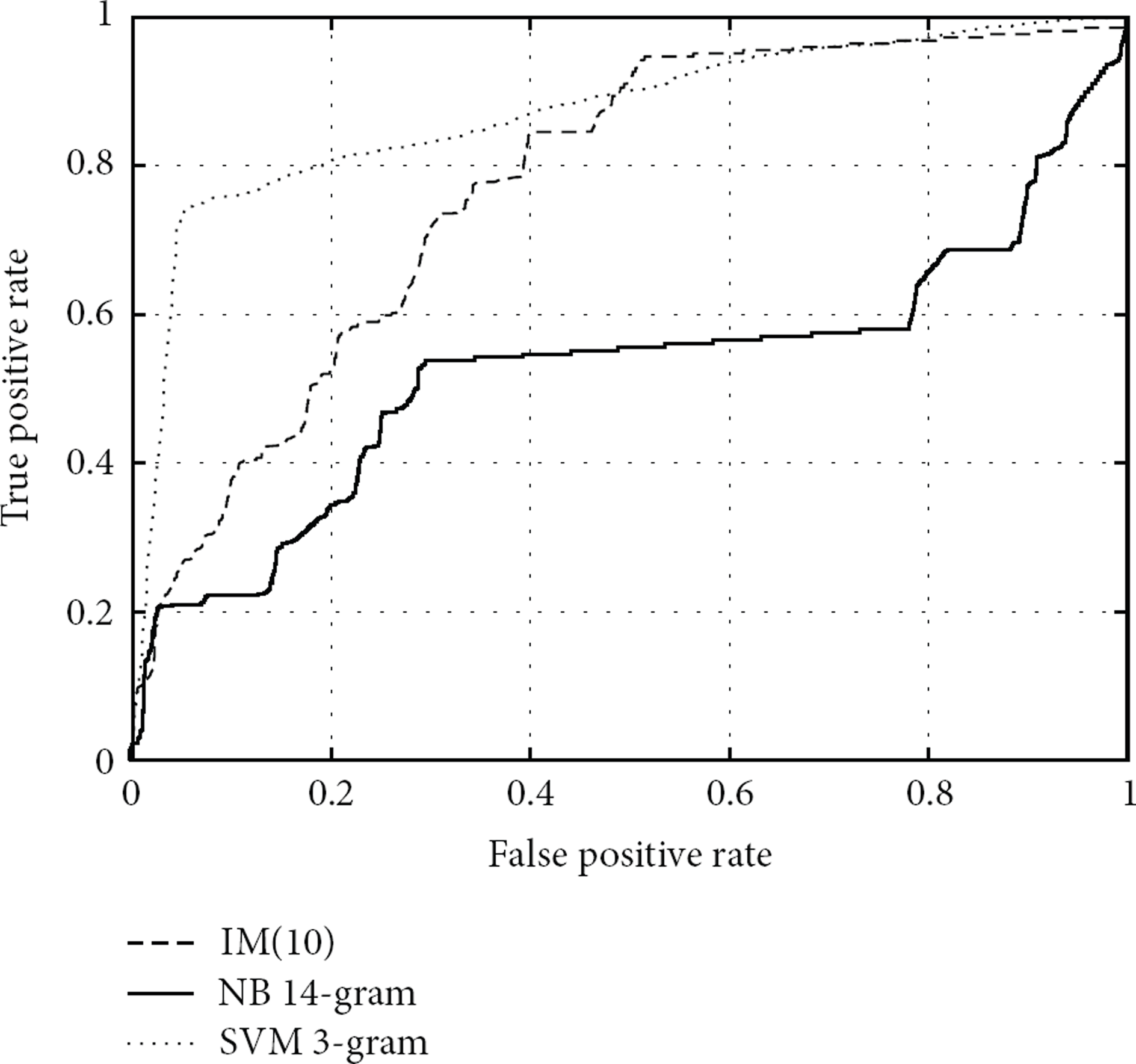
Receiver Operating Characteristic (ROC) curves of interelement dependency model of 10-gram (IM(10),
To show the big picture of comparing IM(n) and NB n-gram, in Figure 7, we show ROC curves of the train/test experiments on the MIT LL 1998 data sets, when

ROC curves of the train/test experiments on the MIT LL 1998 data sets, when
4. Conclusion
4.1. Related Work
Peng and Schuurmans [8] introduced n-gram augmented Naive Bayes and applied their algorithms to text classification. Silvescu et al. [10] proposed interelement dependency models which are similar to n-gram-augmented Naive Bayes. However, to the best of our knowledge, there has been no research on application of interelement dependency models for intrusion detection tasks.
Rieck and Laskov [4] used language models to detect unknown network attacks. They used a trie data structure [25, 26] to compute the similarity between two traces. The generalized suffix tree we used is more advantageous for storing n-gram features in that it does not take constant time to find a substring in a trie data structure. We performed our experiments with n ranging from 1 to 20, whereas Rieck and Laskov did the experiments when n is only 1, 3, and 5.
Most intrusion detection research focuses on the n-gram approach [4, 14, 18, 19]. However, there have been a few research efforts [15–17] that explore intrusion detection tasks with a bag or set of system calls. Liao and Vemuri [15] applied the K-Nearest Neighbor text classification method to intrusion detection tasks. Kang et al. [16] proposed a bag of system calls representation for intrusion detection. They performed various experiments for misuse detection and anomaly detection and showed that a bag of system calls representation is effective for misuse detection. Liu et al. [17] compared different system call feature representations and concluded that system call alone is not sufficient for detecting insider threats. Our work extends the representation to n-gram and shows that the resulting intrusion detectors are more accurate than n-gram features in terms of accuracy and false positive rate.
Forrest et al. [18] devised a Sequence Time-Delay Embedding (STIDE) intrusion detector which takes the n-gram approach with a few thresholds. Tan and Maxion [23] tried to define the operational limit of STIDE and concluded that 6-gram is enough for anomaly detection. Our work shows that the interelement dependency model (IM(n)) is more accurate than the n-gram approach and, for some attack types (UNM live lpr MIT and UNM denial of service), six is not always the magic number.
4.2. Summary and Future Work
We discussed an application of interelement dependency models to n-grams stored in a k-truncated generalized suffix tree (k-TGST) directly to classify intrusive sequences. We evaluated the performance of our method with those of Naive Bayes and Support Vector Machines (SVMs) with n-gram features by the experiments on intrusion detection benchmark data sets.
Experimental results on the University of New Mexico (UNM) benchmark data sets and MIT Lincoln Lab 1998 DARPA intrusion detection evaluation data sets show that our method, which solves the problem of independence violation that happens when n-gram-features are directly applied to Naive Bayes (i.e., Naive Bayes with n-gram features), yields intrusion detectors with higher accuracy than those from Naive Bayes with n-gram features and shows comparable accuracy to those from SVM with n-gram features.
For scalable and lightweight counting of n-gram features, we use the k-truncated generalized suffix tree mechanism for storing n-gram features. With this mechanism, we tested the performance of the classifiers up to 20-gram in our experiment, which illustrates the scalability and accuracy of n-gram augmented Naive Bayes with the k-truncated generalized suffix tree storage mechanism.
As for future work, we plan to apply n-gram representation to system call arguments [27], because system call arguments are important for accurate intrusion detection. Since there has been a lot of research on n-gram approaches, it is of interest to devise an n-gram representation where each element is the audit record data structure (i.e., system call and its arguments). However, there have been no researches we are aware of for the application of n-gram representation for the audit record data structure.