
Abstract
In HDLC serial communication protocol, CRC calculation can first process the most or least significant bit of data. Nowadays most CRC calculation is based on the most significant bit (MSB) first processing. An algorithm of the least significant bit (LSB) first processing parallel CRC is proposed in this paper. Based on the general expression of the least significant bit first processing serial CRC, using state equation method of linear system, we derive a recursive formula by the mathematical deduction. The recursive formula is applicable to any number of bits processed in parallel and any series of generator polynomial. According to the formula, we present the parallel circuit of CRC calculation and implement it with VHDL on FPGA. The results verify the accuracy and effectiveness of this method.
1. Introduction
Cyclic redundancy checksum (CRC) is the core computation step of HDLC protocol [1]. CRC is widely used in high-speed data communications systems, such as Asynchronous Transport Modes (ATM), Ethernet wired networks (ieee802.3), WiFi (ieee802.11), and WiMAX (ieee802.16). Now the data processing capacity is growing, which has reached Gb/s. The traditional easy hardware solution for CRC calculation is the Linear Feedback Shift Register (LFSR), which processes bits serially. Although LFSR can work on high frequency, it is relatively slow to calculate CRC. With the development of modern communications, the high rate of data transmission requires speeding up CRC calculation, the speed of this serial implementation is absolutely inadequate in high-speed data communications. In these cases, a parallel computation of the CRC is used widely [2–10].
CRC calculation can be divided into most or least significant bit first processing. Nowadays most CRC calculation is based on the most significant bit (MSB) first processing [4]. This paper presents the algorithm and implementation of least significant bit first processing parallel CRC. The traditional serial implementation for CRC calculation is the Linear Feedback Shift Register (LFSR); we first analyze the principle of LFSR in this paper. Then, based on the requirement of least significant bit first processing and the incomplete relative theory, we deduce the formula of least significant bit first processing parallel CRC and implement it with FPGA which is widely applicable [11–14].
2. The Algorithm of Least Significant Bit First Processing Parallel CRC
2.1. The Algorithm of Serial CRC
In typical serial CRC algorithm [1, 10], the computing processes are assuming that the input information is calculated from the MSB. However, in practical application, input data CRC operation may be processed from the lowest bit first. When the least significant bit of the data flow is processed firstly, the corresponding generator polynomial is necessary to reverse order. For example, the antisequence CCITT-16 standard polynomial expressed in binary is 0'8408. Because the structure of serial CRC is only relevant to the generator polynomial and the order of the data processing, in order to get more generic hardware architecture, assuming least bit processing first, the generator polynomial g(x) = xm – 1*gm – 1 + xm – 2*gm – 2 + … + x*g1 + g0, which used the reverse order, the input sequence m(x) = xk – 1*bk – 1 + xk – 2*bk – 2 + … + x*b1 + b0. You can get universal serial hardware structure as shown in Figure 1.

Universal serial processing hardware architecture of LSB first CRC.
2.2. The Algorithms of Parallel CRC
It is not easy to summarize LSB first with the simple mathematical calculation, but it is an idea to describe in the classic serial feedback shift register implementation (the state diagram shown in Figure 1). The assumptions of generator polynomial and input sequence are the same as above. [xm – 1 … x1x0] denote the current computing state of CRC, and [xm – 1′ … x1′x0′] represent the next calculation state of CRC. [gm – 1 … g1g0] is polynomial coefficients from high to low. m indicate LSB first input data.
The universal serial hardware architecture described in Figure 1 can be seen as discrete linear time-invariant systems, which is a method of parallel computing. The equation of state can be described as follows:

In (1), X(i) is the current state of the system, that is, the current CRC operation result. X(i + 1) is the next state of the system, and U represent the system's input, that is, the LSB first processing serial input data. Y is the output of the system, which is the result of CRC operation. As first process LSB, we can see from Figure 1 that the first feedback data is the least significant bit which is calculated firstly. According to the state transition relation as shown in Figure 1, in (1) the state equation as follows:
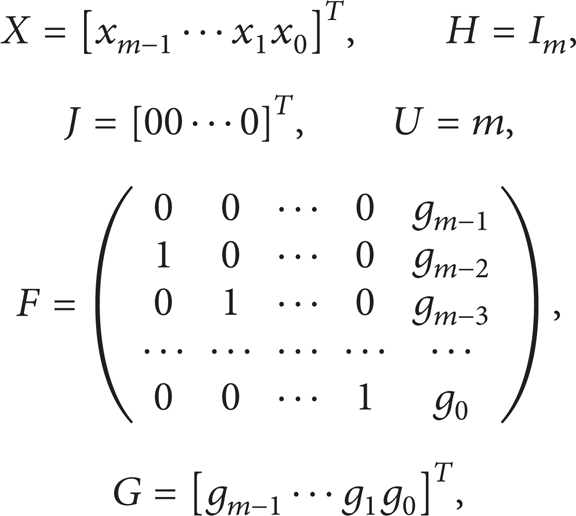
I m is the identity matrix. Use induction and recursive algorithm to solve this state equation. The operations can be described as follows:

In (3),

We can get the solution of state equation (1) as
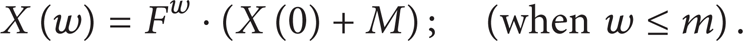
w is the width of parallel processing data, m is the degree of the generator polynomial. Through this recursive formula, the CRC can be achieved by one time parallel data processing when w ≤ m. In order to obtain parallel processing of continuous operation CRC recurrence relations, assumptions w = m, because the process of conducting CRC calculation, all calculations are based on modulo 2 arithmetic. The modulo 2 addition is equal to XOR which symbol is ⊕. In Matrix multiplication processing, there are both AND gates to achieve the modulo 2 multiplication and XOR gates to achieve modulo 2 sum, and ⊗ is used to descript this process. Thus, (5) can be expressed as recurrence relations as follows:

According to (6), we derive the recursive formula of parallel CRC when w = m. This is just a special case, for the more general case w < m, just need a little change in the recurrence relations according to (5), that is

According to (6) and (7), we can get the recursive formula of LSB first processing parallel CRC when w ≤ m.
In the above derivation process, the parallel CRC calculation condition for the establishment of recurrence relations is the width of the data w not greater than the degree of generator polynomial m. But that does not mean that the width of the parallel processing of data not greater than degree of generator polynomial. When the width of parallel processing data is greater than the degree of generating polynomial, the data can be divided into several sections so that the width of each section is no greater than the degree of generating polynomial, in resulting CRC computing recurrence relations when w > m. For example, when w = 2m, according to (5), we can derive one time parallel data processing of CRC:

Using gate function to represent Mode 2 operation, according to (8) and induction method, we can derive recursive formula of parallel CRC when w = 2m:

And then extend formula to the general situation, let us suppose w = lm + n; 1 ≤ l; 0 ≤ n ≤ m – 1; according to (5), one time parallel process for the CRC operation is as follows:

According to (10) and induction operations, and use gate function to represent Mode 2 operation in (10), the recursive formula of parallel CRC can be described as follows:

From (11), we can get the recursive formula of LSB first processing parallel CRC when w > m, which can be implemented in hardware. In summary, the recursive formula is applicable to any number w of bits processed in parallel and any degree m of the generator polynomial. We can achieve the hardware architecture according to the recurrence relations of (7) and (11).
3. Hardware Architecture of the Parallel CRC Algorithms
Here given the special examples of w ≤ m and w > m, to illuminate hardware implementation structure of LSB first processing parallel CRC.
3.1. w ≤ m Example
Assume generator polynomial use that the reverse order form of CCITT-16 polynomial standard g(x) = x16 + x12 + x5 + 1, expressed as a binary sequence 0'8408. The width of parallel processing data w = 16, that is w = m. The initial value of the CRC registers 0xffff; that is

According to (6), the recurrence relation of parallel computing CRC becomes

The result of F16 is

According to the recurrence relation of (13), we obtain the hardware structure shown in Figure 2.
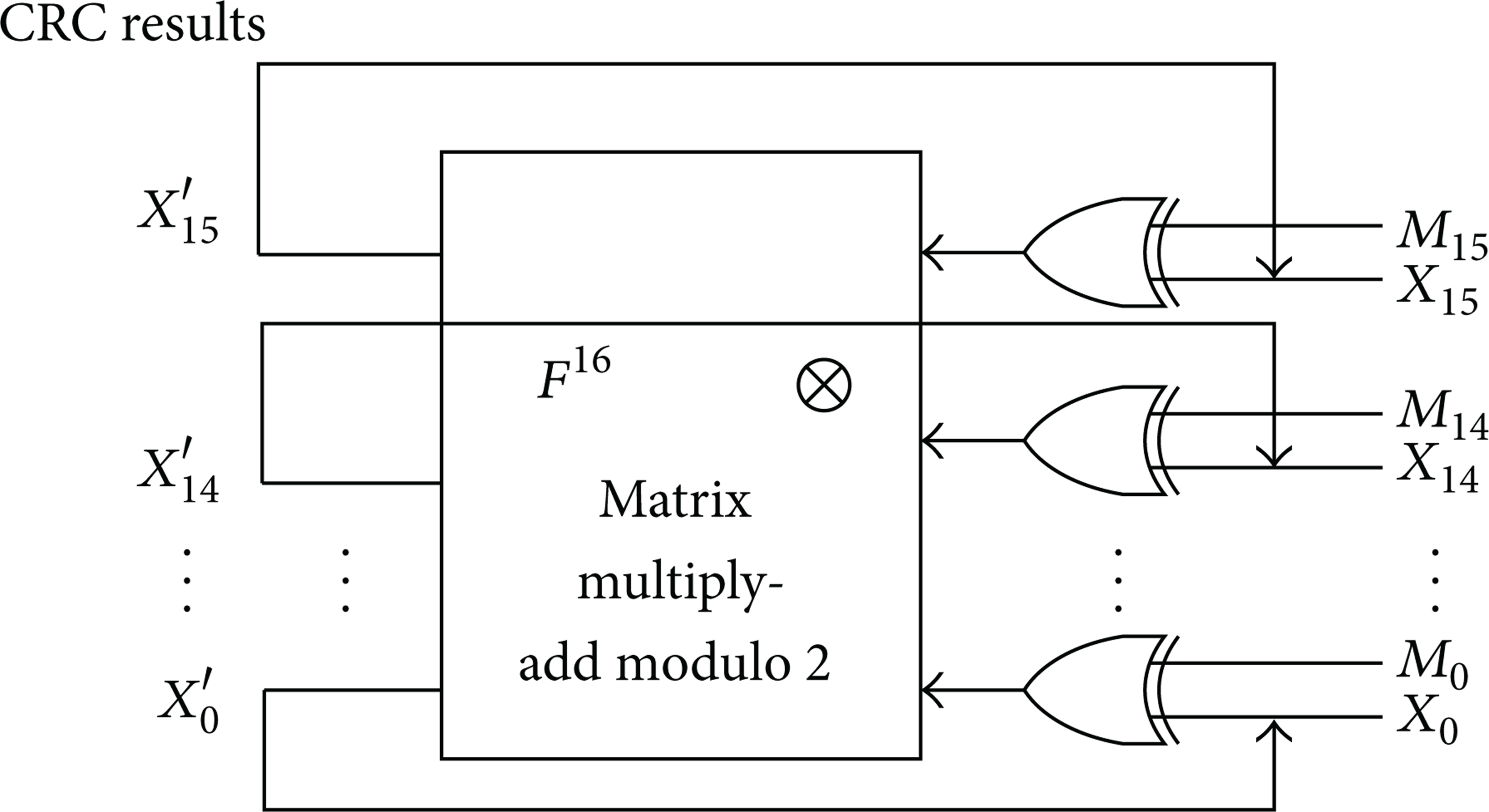
w = m = 16 hardware implementation structure of the parallel CRC.
3.2. w > m Example
Still using the assumptions above, generator polynomial uses the reverse order form of CCITT-16 polynomial standard g(x) = x16 + x12 + x5 + 1, expressed as a binary sequence 0'8408. The initial value of the CRC registers 0xffff; that is
According to (9), when w = 2m = 32, the recurrence relations of parallel CRC become

Because of the same generating polynomial, matrices F and F16 are the same as above, but matrix F32 needs to be calculated.

From (15), we can obtain the recursive formula of parallel CRC when w = 2m = 32, and the hardware structure is shown in Figure 3.
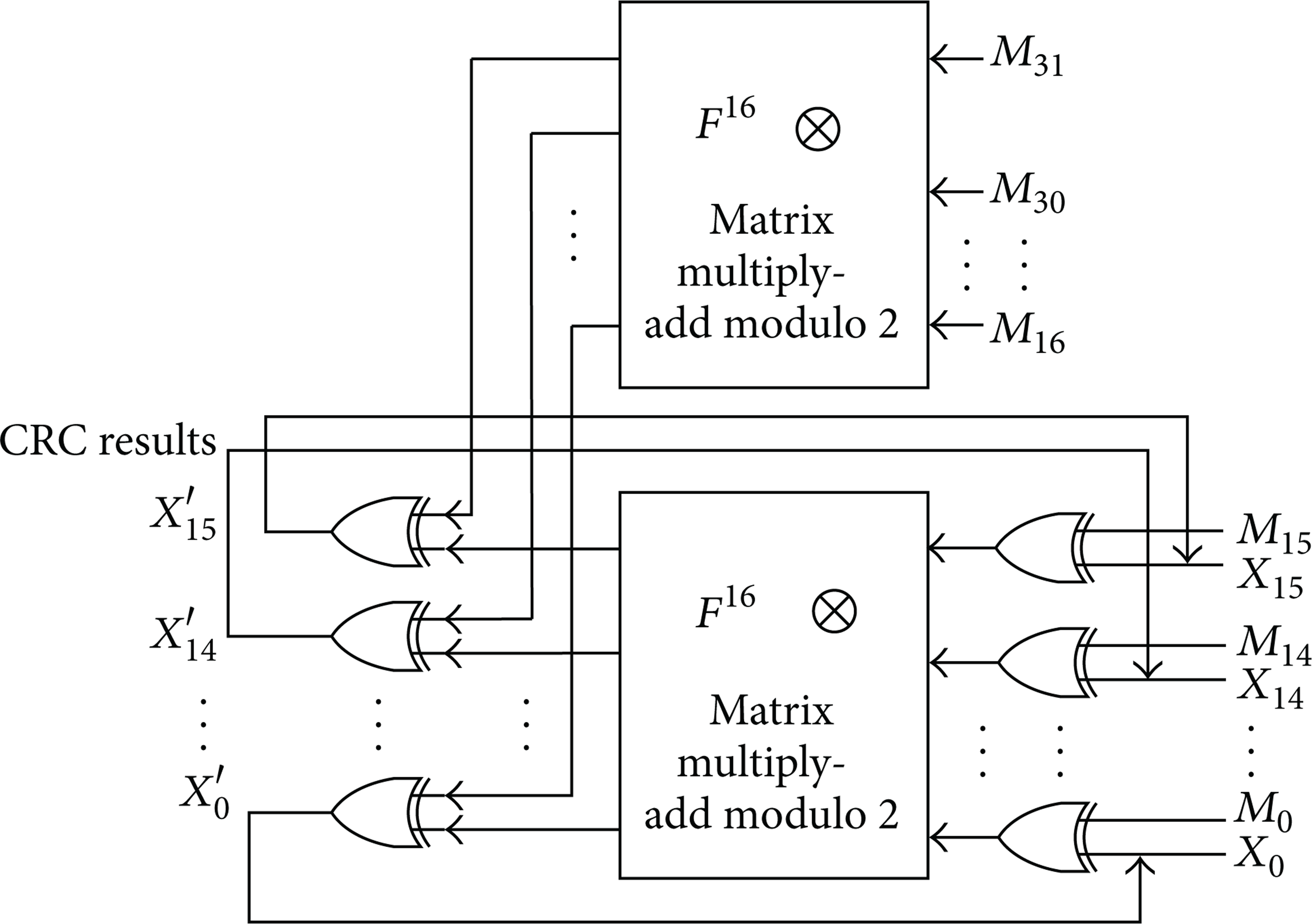
w = 2m = 32 Hardware implementation structure of the parallel CRC.
4. Implementation Results
According to (13) and (15) and the design shown in Figures 2 and 3, implement both w ≤ m and w > m instance, respectively, using the Xilinx V4 series FPGA. Compare experimental results with the literature [4] proposed method and the results are shown in Table 1.
Parallel CRC FPGA resources consumption compare.

By comparing the data of Table 1 roughly, Table 1 proves that the efficiency of LSB first processing parallel CRC algorithm is more desired. The point of this paper is that the algorithm analyzes both w ≤ m and w > m LSB first processing parallel CRC from the principle.
5. Conclusions
In HDLC serial communication protocol, CRC calculation is the key and usually is implemented by LFSR. With data quantity unceasing increasing and usage of other high-speed communication systems, parallel processing has become as inevitable. In this paper, we firstly analyze the serial implementation of CRC, which uses the serial feedback shift register method. Then, by means of the generic hardware architecture of LSB first processing serial CRC, based on the state equation approach, this paper achieves a LSB first processing parallel CRC algorithm, which is applicable to any number w of bits processed in parallel and any series m of the polynomial generator. Finally, the algorithm is implemented using VHDL programming language on FPGA, which prove its correctness. Comparing FPGA resources consumption with other MSB first processing parallel CRC algorithm proves the effectiveness of the implementation. Error detection performance fully meets actual communication length of 91 Bytes error detection requirements.