
Abstract
In large-scale networks, the structure of the underlying network changes frequently, and thus the power iteration method for Personalized PageRank computation cannot deal with this kind of dynamic network efficiently. In this paper, we design a Monte Carlo-based incremental method for Personalized PageRank computation. In a dynamic network, first, we do a random walk starting from each node and save the performed walks into a fingerprint database; second, we update the fingerprint database in a fixed time interval with our proposed update algorithm; finally, when a query is issued by a user, we estimate the Personalized PageRank vector by our proposed approximation algorithm. Experiments on real-world networks show that our method can handle multichanges of the underlying network at a time and is more efficient than related work, so it can be used in real incremental Personalized PageRank-based applications.
1. Introduction
Large-scale networks are ubiquitous in today's world, such as World Wide Web, online social networks, and huge search and query-click logs regularly collected and processed by search engines. PageRank [1], which is the stability distribution of a random walk in a Markov chain, has emerged as an effective measure for ranking on large-scale networks. In addition, Personalized PageRank [2, 3], which is the stability distribution of a random walk with restart in a Markov chain, has been proved to be an effective method of personalized ranking in many applications, such as link prediction [4–6], friend recommendation [7–9], and personalized searching [10, 11]. Given a network, there are two main methods for computing the PageRank or Personalized PageRank vector: one is power iteration applying the linear algebra proposed by Page et al. [1] and the other is the Monte Carlo approximation methods proposed by Litvak [12] and Fogaras and Rácz [13].
In practice, the structure of the underlying network is dynamic, such that Webpages join or leave frequently in World Wide Web and following relations appear or disappear frequently in an online social network. Recomputing PageRank or Personalized PageRank for every change, that appears or disappears in an edge, of the structure is impossible in large-scale networks, so incremental PageRank or Personalized PageRank algorithms are necessary for this situation.
1.1. Background
Given a graph
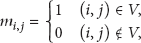
where
The transition possibility matrix P of the graph G is

where the weights on the outgoing edges of each node sum up to 1.
PageRank is the stability distribution of a random walk in a Markov chain. The main idea of random walk on a graph is that starting from a source node, at each step, jump to a random node with a probability ε (usually called the teleport probability), and follow a random outgoing edge from the current with the probability
Personalized PageRank is the same as PageRank, except that the random walk jumps to the source node with a probability ε at each step. Given a source (or called personalized) node u, the Personalized PageRank score of node v is

where
1.2. Problem Statement
In this paper, we study the incremental computation of Personalized PageRank based on the Monte Carlo method; that is, given a graph, we do a random walk of fixed length starting from each node update the performed walks incrementally in fixed time interval, and approximate Personalized PageRank with the performed walks whenever needed.
Here, the core of the problem is designing an incremental update algorithm and a Personalized PageRank approximation algorithm.
1.3. Our Contribution
First, we design an approximation method for Personalized PageRank based on Monte Carlo method. We do a random walk of fixed length starting from each node, and save the performed walks in a fingerprint database.
Second, we propose an incremental algorithm, which updates the performed walks in fixed time interval, while the structure of underlying graph changes.
Third, we propose an approximation algorithm for computing Personalized PageRank vector based on the performed walks.
Finally, we do some experiments on real world graphs, and the experiments show that our proposed method is more efficient than related researches in estimating Personalized PageRank on dynamic networks.
2. Related Work
Matrix Computation. Matrix computation, which applies power iteration of linear algebra to compute the PageRank vector [1], is the most popular method for PageRank computation. In order to accelerate the convergence of power iteration, Borgs et al. [14] propose a sublinear time algorithm for PageRank computations. Because the graphs in real applications are usually sparse, del Corso et al. [15] and Fujiwara et al. [16] all apply sparse matrices to speed up the PageRank computation. Though these algorithms can accelerate the Personalized PageRank computation, they cannot be used in dynamic networks.
Monte Carlo Method. The Monte Carlo approximation methods [12, 13] are efficient for estimating Personalized PageRank on large-scale graphs. The basic idea is that starting from the source node, do a number R of random walks (called fingerprints); at each step, stop the random walk with a probability ε, and follow a random outgoing edge from the current node with the probability
Personalized PageRank Application. Personalized PageRank and other random walk with restart-based measures are the most well-known graph computation problems, and they have proved to be very effective in a variety of applications, such as link prediction [5, 21] and friend recommendation [22, 23], Webpage retrieval [1–3, 24–27], and trust-based recommendation systems [28–31] in large-scale networks. A similar work is [32], which uses dynamic GPS data to recommend an individual with interesting locations or travel sequences matching her travel preferences. But, the difference is that although they use the dynamic dataset, they do not mention how they handle this dynamic dataset incrementally. However, in this paper, we focus on the incremental update of recommendations, and the results can be used in any Personalized PageRank-based applications.
3. Monte Carlo-Based Incremental Personalized PageRank Computation
In this section, we describe our proposed system for incremental Personalized PageRank computation and illustrate the system in detail.
3.1. System Overall Design
Our system answers users’ Personalized PageRank queries or recommend Personalized PageRank results to the specific users, and the architecture of the system is in Figure 1. First, we initialize the fingerprints and save them in a fingerprint database, and then, in a fixed time interval, we update the fingerprint database. These two phases are done automatically by the system. When a query is issued by a personalized user, the searching engine retrieves related fingerprints from the fingerprint database, estimates the Personalized PageRank vector, and then returns nodes with highest score to the user. Some of the main phases of the system work as follows.
Initializing Fingerprint Database. Given a graph
Updating Fingerprint Database. The structure of the graph changes frequently, and it is impossible to update the fingerprint database with every change, so we update the fingerprint database with a fixed time interval t.
Computing Personalized PageRank. When a query is issued from a user, the searching engine generates SQL queries according to the specified user, retrieves related results from the fingerprint database, computes the Personalized PageRank vector, and returns a top-k list to the user.
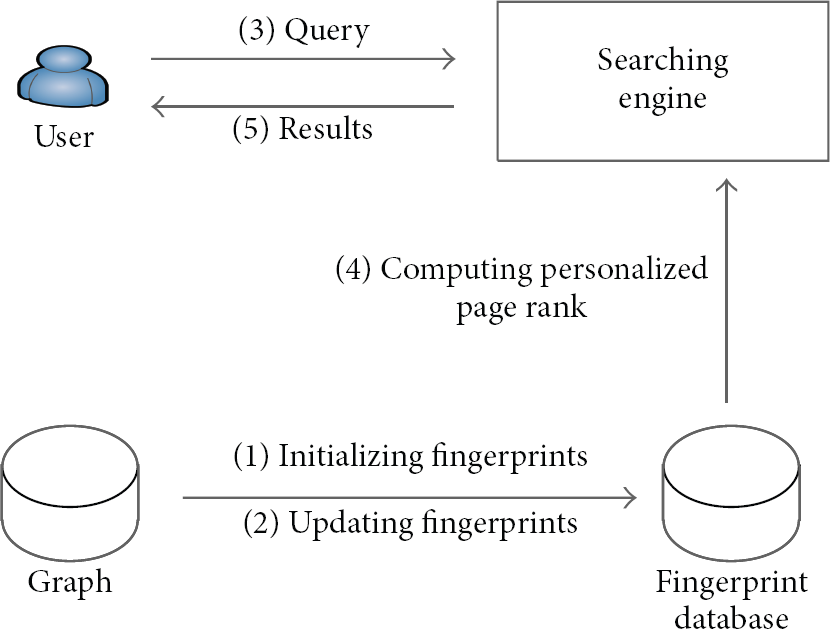
System architecture.
3.2. Initializing Fingerprint Database
Given a graph
node (1) (2) Let (3) (4) (5) (6) (7) (8) (9) Return W;
After doing the performed random walks, we save the performed walks in the fingerprint database.
3.3. Updating Fingerprint Database
In dynamic networks, Bahmani et al. [20] propose a model to update the fingerprint database whenever there is a joining edge or leaving edge. However, the structure of the underlying graph changes frequently, so it is impossible to update the fingerprint database for very change. In this paper, we propose an update algorithm that handles multichanges while updating the fingerprint database.
In a time interval t, there will be k changes in the structure of the underlying network. These k changes include joining edges and leaving edges in any order. We can apply the algorithm proposed in [20] k times, but this will consume lots of computation resources. In this paper, we propose an update algorithm, which could handle multichanges at a time, and the details of the algorithm are in Algorithm 2.
and W, the set of fingerprints. (1) Reorder (2) Let (3) (4) Let (5) (6) (7) (8) (9) (10) Let (11) (12) (13) (14) Let (15) Let (16) (17) Let (18) (19) (20) (21) (22) (23) Let (24) (25) (26) (27) (28) Let of w until the length reaches λ; (29) (30) Update W with
Given a series of changes
For the
For the
Finally, for both L and J, the lengths of fingerprints are smaller than λ, so we go on walking randomly on
3.4. Computing Personalized PageRank
In this subsection, we propose an approximation method for estimating Personalized PageRank vector based on the performed walks, and the details are in Algorithm 3.
Personalized PageRank, and ε, the teleport probability. (1) Let (2) (3) Scan w, find all sub-fingerprints of length from u, and add these sub-fingerprints to (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) Return
For each fingerprint
4. Experiments
In this section, we do some experiments to validate the efficiency of our proposed method. We use the method proposed by the Bahmani et al. [20] as baseline algorithm, and compare it with our method in execution time.
4.1. Dataset
To validate the performance of both algorithms, we use two real-world datasets of networks, Dianping [33] and Gowalla [34]. The details of the datasets are in Table 1.
Details of datasets.

4.2. Experimental Setup
Our experimental environment is a personal computer with a 4-core processor and 4 GB memory. All algorithms are implemented by Java on the Ubuntu operation system. Our toolkit for dealing with graph is Jung [35], and the database for storing fingerprints is MySQL.
4.3. Experimental Results
For each graph G, we choose 90% of the dataset as already known graph A, and the other 10% as B. When an edge joins A, we randomly choose an edge e from B, delete it from B, and add it to A. When an edge leaves A, we randomly choose an edge e from A, delete it from A, and add it to B. The probabilities of joining and leaving are equal. We build an extra thread that changes the structure of the underlying graph once per ten seconds.
First, we compare the update time between our method with the method proposed by Bahmani et al. We update the fingerprint database in a fixed time interval from 1 to 10 second, and the results for two datasets are in Figures 2 and 3. From these two figures we can see that our update algorithm executes only once, but the Bahmani's algorithm need to update the fingerprint database multitimes that is proportional to the time interval. Moreover, we find that the time used in updating the fingerprint database contains a nearly constant time retrieving the related fingerprints.

Comparison of update time (Dianping).

Comparison of update time (Gowalla).
Second, we compare the execution time of Personalized PageRank approximation between the proposed method and Bahmani's method. Both of the algorithms retrieve fingerprints from the fingerprint database first and then estimate the Personalized PageRank vector with the fingerprints. The Bahmani's algorithm retrieves related fingerprints starting from the personalized node, and there are millions of fingerprints, so the searching process takes a lot of time. Our algorithm returns all fingerprints, and it needs only one pass of scanning the whole fingerprints to compute the Personalized PageRank vector. We randomly choose 10 personalized nodes and compare the average approximation time of Personalized PageRank, and the details are in Figure 4.
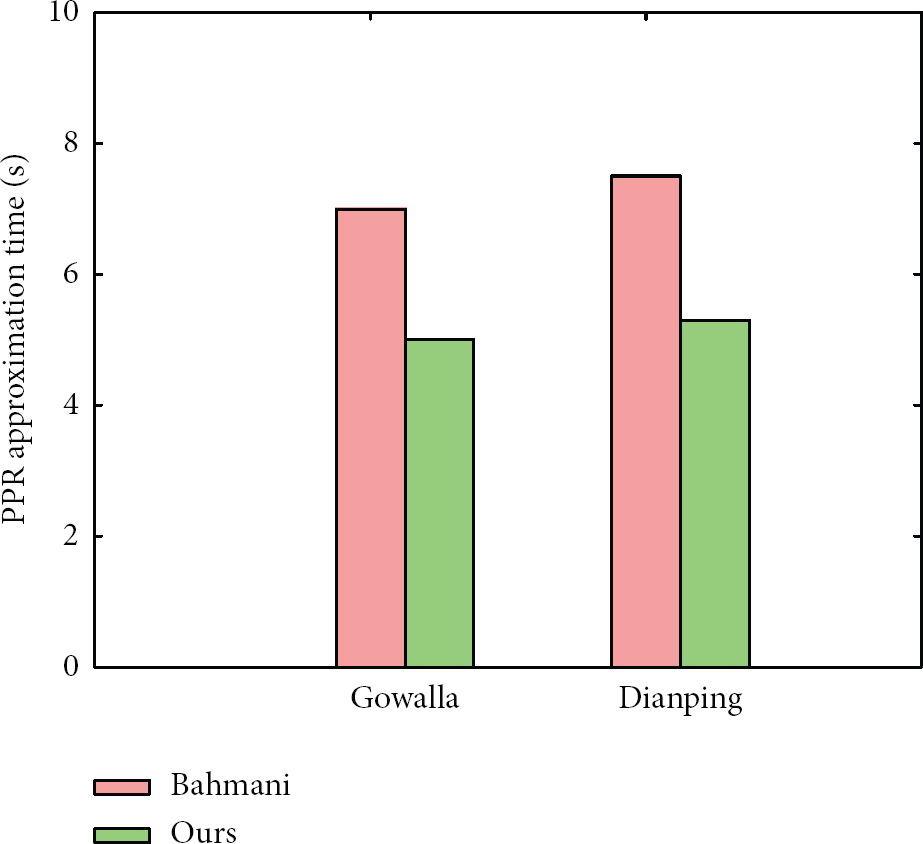
Average approximation time comparison of Personalized PageRank (PPR) approximation.
Third, we compare the overall performance between the two methods. The update time and Personalized PageRank approximation time of our method are all shorter than the Bahmani's method, and thus it is obvious that the overall time used by our method should be shorter. Here, using the multithreading technology of Java, we compare the throughput of the two methods, and the results are in Figure 5. In this experiment, one thread is used to generate changes of the structure of underlying graph, one thread is used to update fingerprints, and other threads are generated dynamically to compute the Personalized PageRank vector. We use the number of finished Personalized PageRank vectors per minute as the throughput. From the figure we can see that our proposed method is more efficient than the Bahmani's method in throughput.

Comparison of throughput.
Finally, we compare the accuracy of the two algorithms. To measure the quality of the results, for a node u and a value k, we define

where
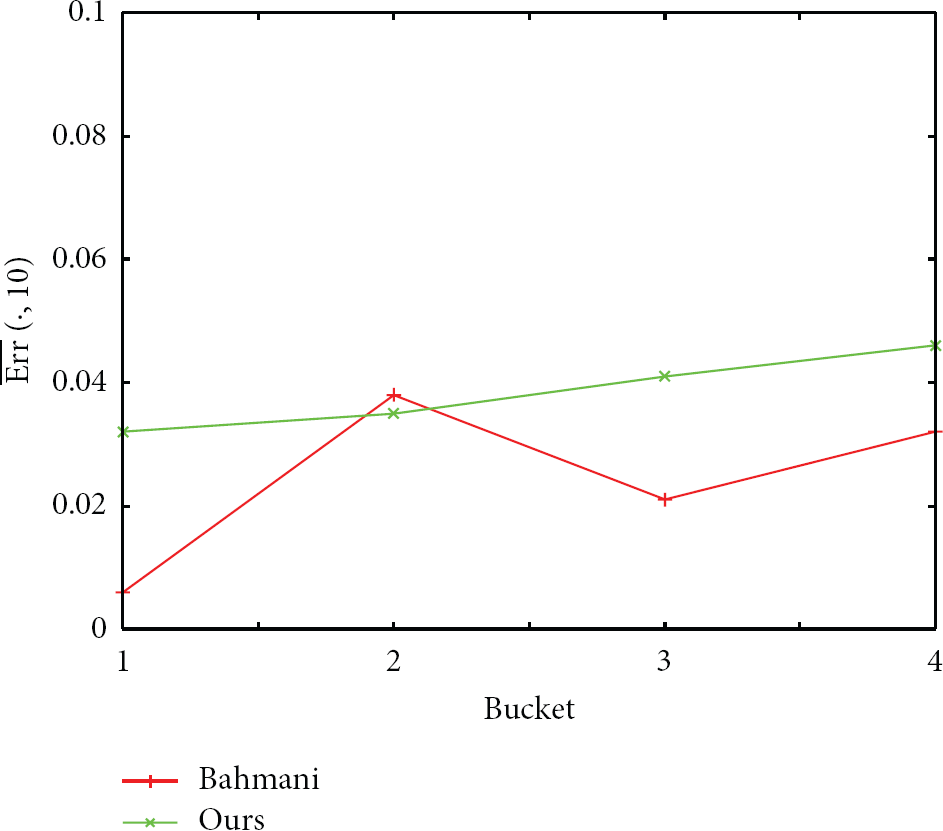
Bucket versus

Bucket versus

Bucket versus
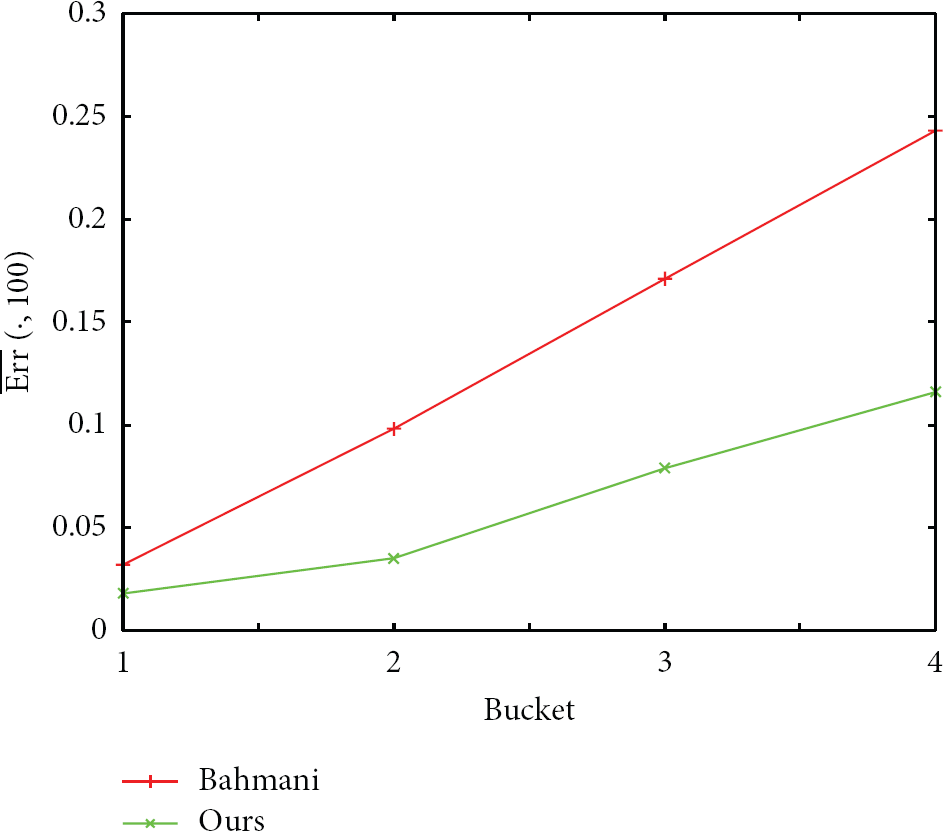
Bucket versus
5. Conclusion
Personalized PageRank is very important for complex networks, and it has been proved to be effective in many real applications, such as link prediction, entity recommendation, and social searching. However, in these applications, the underlying networks are usually dynamic, and traditional power iteration method cannot deal with them efficiently.
In this paper, we design a Monte Carlo-based incremental method for Personalized PageRank approximation in dynamic networks. We propose an efficient update algorithm to handle changes of the structure of the underlying network, and an efficient Personalized PageRank approximation algorithm with the performed walks. Experiments on real-world networks show that our method can handle multichanges of the underlying network structure at one time and is more efficient than related work, so can be used in real incremental Personalized PageRank-based applications.
Footnotes
Acknowledgments
This work was supported in part by the National Significant Science and Technology Special Project of China and the National Natural Science Foundation of China.