
Abstract
We propose a location-based mobile social networking system (SNS) that integrates biometric facial authentication using a modified local directional pattern (MLDP), collaborative content recommendations, and communication among users. The proposed system is an effective fusion of a traditional social networking system, a location-based system, and a provider of intelligent recommendations. The prototype and service scenario in this study show possibilities for technical advancement and the future extension of mobile social networking services. To verify the proposed system, we performed experiments to determine the recognition rate for a user's facial image on a real-world smartphone and the preference prediction accuracy of a collaborative filtering-based recommendation system. Through our implementation and preference prediction experiments, we confirmed that the proposed system is highly effective and applicable to convergence using a location-based service and a content recommender.
1. Introduction
A social networking service (SNS) focuses on building and reflecting social networks and social relations among people who share interests or activities. It provides personal connections to individual users via Internet applications by offering communities, instant messenger programs, blogs, and user-created content services. In recent years, SNSs have become popular through the ubiquitous computing concept. SNS is now evolving from a PC-based service to a mobile-based service via an IT convergence platform, and a location-based system (LBS) is optimal for the new mobile environment. A mobile SNS is the SNS and LBS convergence product [1–4].
Studies of LBS trends show that the system is becoming a more general purpose for users with global positioning system (GPS) enabled mobile devices, such as smartphones, tablet PCs, and portable multimedia players [5, 6]. Existing studies, products, and services related to GPS-enabled mobile devices show that the devices provide a way to share various location-tagged content generated by the user, such as photographs, movie clips, text, and sound. A mobile device user with such a system can access location-tagged content and then share the content via that device [7–9]. SNSs that were formerly PC based have now converted to a mobile platform. This technological and industrial trend has developed throughout the years [10]. Recently, a problem regarding the information security of SNSs and LBSs has resurfaced, for they contain the user's personal data, including their location data [11]. Furthermore, the flood of information shared by users from their mobile device at any time and from anywhere is becoming an issue. This low-quality content introduced to the system eventually extends the time required to search for more useful information. Therefore, a program within the framework of a personal LBS on a mobile device is required to resolve this problem.
In this paper, we present a personal location-based mobile SNS that integrates facial recognition-based user authentication, collaborative recommendations, and communication among users of an SNS. The proposed system is a convergence of the SNS, the LBS, and a recommendation system (RS) and consists of a single security module, the user authentication module (UAM), two key filtering modules, a distance filtering module (DFM), and a preference filtering module (PFM). First, the DFM searches for location-tagged content within a specific user-centered radius and improves the recommendation efficiency by determining the user's current location. The PFM, as the RS, then selects and recommends content of interest by considering the user's preferences based on collaborative filtering (CF) [12, 13]. The PFM determines and personalizes the real-time recommendations using a memory-based CF framework. The UAM improves security for hand-held PC SNSs by using the user's facial image. We applied facial recognition software to a smartphone in unconstrained illuminated conditions using modified local directional pattern (MLDP) and image covariance-based face feature extraction algorithms, such as two-dimensional principal component analysis (2DPCA) [14] and the alternative two-dimensional principal component analysis (A2DPCA) [15], which are accurate high-speed pattern recognition algorithms suitable for the mobile environment [16–18]. Then, the MLDP image is directly inserted into the image covariance-based face feature extraction algorithm. In comparison with a previous work using binary pattern descriptors such as local directional pattern (LDP) to extract histogram features, the proposed method has enriched a different approach.
Generally, the binary patterns used in a previous work have produced long histograms, leading to high computational complexity for a large face database. Therefore, this work directly utilizes a face image transformed by the MLDP descriptor as the input data for the image covariance-based feature extraction algorithms. The proposed approach has the advantage of retaining illumination effects which can be degraded by the MLDP descriptor. Because the image covariance-based feature extraction algorithms, such as 2DPCA and A2DPCA, are line-based local features, they are also more robust to illumination variation than global features, such as principal component analysis (PCA) [19]. The convergence of DFM and PFM is a novel approach toward solving the scalability problem of the CF.
In our proposed SNS, we intend to expand the application of CF to the LBS. We suggest a prototype of an LBS-based personalized mobile SNS that uses RS and mobile-based real-time facial authentication, which is a state-of-the-art authentication method. The facial image used for authentication can also be used to represent the user on the mobile SNS. We proved that the CF-based RS is effective for an LBS-based SNS with an in-depth CF experiment. The experimental results showed that the CF was excellent at recommending location-tagged content, as well as making traditional recommendations such as movies, books, and other e-commerce content. We also showed the successful convergence of LBS, RS, and SNS in the service scenario, which comprises an authentication process for a user's facial image and a syndication method for location-tagged content among people who share interests or activities.
This paper is organized as follows. In Section 2, we describe the SNS, LBS, RS, and mobile biometric facial authentication systems and explain existing studies and their products in detail. In Section 3, we propose a mobile social networking system using facial recognition-based user authentication and collaborative recommendation for location-based content as a convergence of SNS, LBS, and RS. In Section 4, we show the experimental results for each module, including the facial recognition rate and the user preference prediction accuracy of the RS. We explain our prototype in Section 5 and conclude our study in Section 6.
2. Related Works
2.1. Location-Based System and Service
An LBS is an information and entertainment service that utilizes the geographical position of a mobile device and is accessible via mobile devices through the mobile network. In the United Kingdom, networks do not use triangulation. The LBS services use a single base station with a radius of inaccuracy to determine a phone's location. A mobile carrier company in Singapore implemented an LBS system in 2007 that involved many local marketers and was reported to be a huge success in terms of subscriber acceptance. Mobile systems do not restrict users to a fixed desktop location but allow ubiquitous mobile activities. Tourist guides are the most common application scenario for location-based services. A mobile city guide for the city of Lancaster was one of the first systems to integrate “personalized” information for the user. More recent projects have integrated multimedia into mobile city guides. However, these systems do not address the dynamic generation of personalized content. This is the objective of the current study [5].
In Web development, a mashup is a Web application that combines data from more than one source into a single integrated tool. The term mashup implies easy, fast integration that is frequently performed by accessing open APIs and data sources to produce results that were not the original goal of the data owners. A study by Floyd et al. showed how mashup techniques can be used for rapid prototyping in the user-centered software development processes [6]. A study at the Human-Computer Interaction Institute of Carnegie Mellon University showed that mashups can even be utilized in user programming [7]. Another study emphasized the great benefits of “enterprise” mashups, which are information-heavy applications that integrate distributed business information within an enterprise in a quick and dynamic way [8]. Most existing mashups have been programmed manually. However, there are a number of mash-up platforms that facilitate development. For example, “Mash-o-matic” [9] can be used to generate geomashups, which integrate information based on a certain location. With well-known online tools, mashups can be constructed out of predefined components and combined using interactive drag-and-drop methods. These were an early form of modern SNSs like Facebook, YouTube, and Myspace. The SNS acts to provide relationships among the users in an online environment. Looking into recent studies concerning SNSs using LBS, state-of-the-art intelligent methodologies for the mobile environment have been applied to SNSs. Yamamoto et al. proposed a social network service based on the locations of students [20]. To acquire the locations of students, data from both the login records of educational computers and the attendance records of classes in the university are required. The analysis of login records and attendance records is used to create a friendship relation map between SNS users. This study is a kind of intelligent location-based SNS in a conditional mobile environment using user behavior. Kim et al. focused on personalization, which is the process of tailoring information to individual users' characteristics or preferences [21]. He has also studied personalized SNSs using machine intelligence [22]. The study provides a social media platform composed of GPS-equipped smart phones, a social media server system, and integrated service ontology to achieve a personalized social user-created-content service. It enables a more intelligent and active information sharing system. The ontology server in the study includes predefined categories of family, friends, coworkers, romantic partners, and location-based relations, and service modules create a personalized recommendation list of user-created content in the SNS database.
SNS technology has been changing and evolving quickly to answer the needs of individuals. A recent issue at the application layer has been the convergence between mobile SNS and intelligent ability represented by personalization. This paper proposes a more sophisticated mobile SNS based on state-of-the-art content recommendation methods and an intuitive user authentication module.
2.2. Mobile-Based Biometric Facial Authentication
Biometrics technologies refer to the identification of individuals based on their distinguishing biological or behavioral traits. These traits include facial features, speech, fingerprints, gait, hand veins, retinas, irises, palm prints, ears, and written signatures. Biometric security systems provide convenience and a high degree of stability since they do not require passwords or physical tokens. The convenience of biometric security systems and their reliability have led to the integration of biometric systems into devices such as desktop computers, laptop computers, PDAs, smartphones, and mobile phones [14]. Few studies have investigated biometric security systems in mobile devices. For example, studies regarding facial recognition have been conducted by Venkataramani et al., Tao and Veldhuis, Hadid et al., Zuo and de With, and Rahman et al. [17, 18, 23–25]. Facial recognition algorithms are generally divided into six categories, as shown in Table 1.
Algorithmic categories of facial recognition.

2.3. Personalized Recommendation
Content-based filtering (CBF) chooses a new item based on items that have been explicitly rated by the user in the past. Though CBF is based on the user's explicit preferences, the method varies according to the information type. In the case of movie retrieval, for example, CBF searches for movies similar to those that have been highly rated by the user. Various attributes can be used, such as actor, genre, release date, or producer. If we can extract common features from the movies that have been rated highly by the user, then this approach should be effective. For image and music retrieval, CBF extracts an object from the image or a rhythm from the music and then searches for other images containing the object or for other music with the same rhythm.
Collaborative filtering (CF) is a state-of-the-art algorithm used to create personalized recommendations. It analyzes the preferences of each user and searches for users similar to the target user. It then predicts a rating for a new item based on the previous rating scores of similar users. Existing studies have proposed methods to improve the data scarcity problem, which decreases prediction accuracy. Recent study trends can be classified into the three approaches described below [12, 13].
The first method reduces the empty space of nonrated items by reducing the dimensionality of the user-item rating matrix using a model-based CF. The second method expands the memory-based CF framework and the use of additional information with an existing similarity method. The third method strengthens existing approaches by developing a new similarity method. Data scarcity problems result from incorrect calculations of the similarity between items or users, which is the main cause of less accurate predictions. For this reason, improving the similarity method is the most radical approach; however, it has the advantage of being applicable to the two other methods.
3. Proposed System
Figure 1 shows the architecture of the authors' proposed system. Every user in the system can register and request location-tagged multimedia content via an Internet-enabled mobile device. A user performing the registration uses the camera or microphone of his own mobile device to record content. At this point, the user's location, consisting of latitude and longitude, is tagged along with the content. The content, including the user's text comments, is sent to the content-sharing server as location-tagged content. These steps are denoted by ① to ④ in Figure 1. A user receives personalized content through a request, and then the user rates his preference after experiencing the content. This process is denoted by steps ⑤ to ⑨. The key modules of the proposed system, the DFM and PFM, are described in the next subsections.
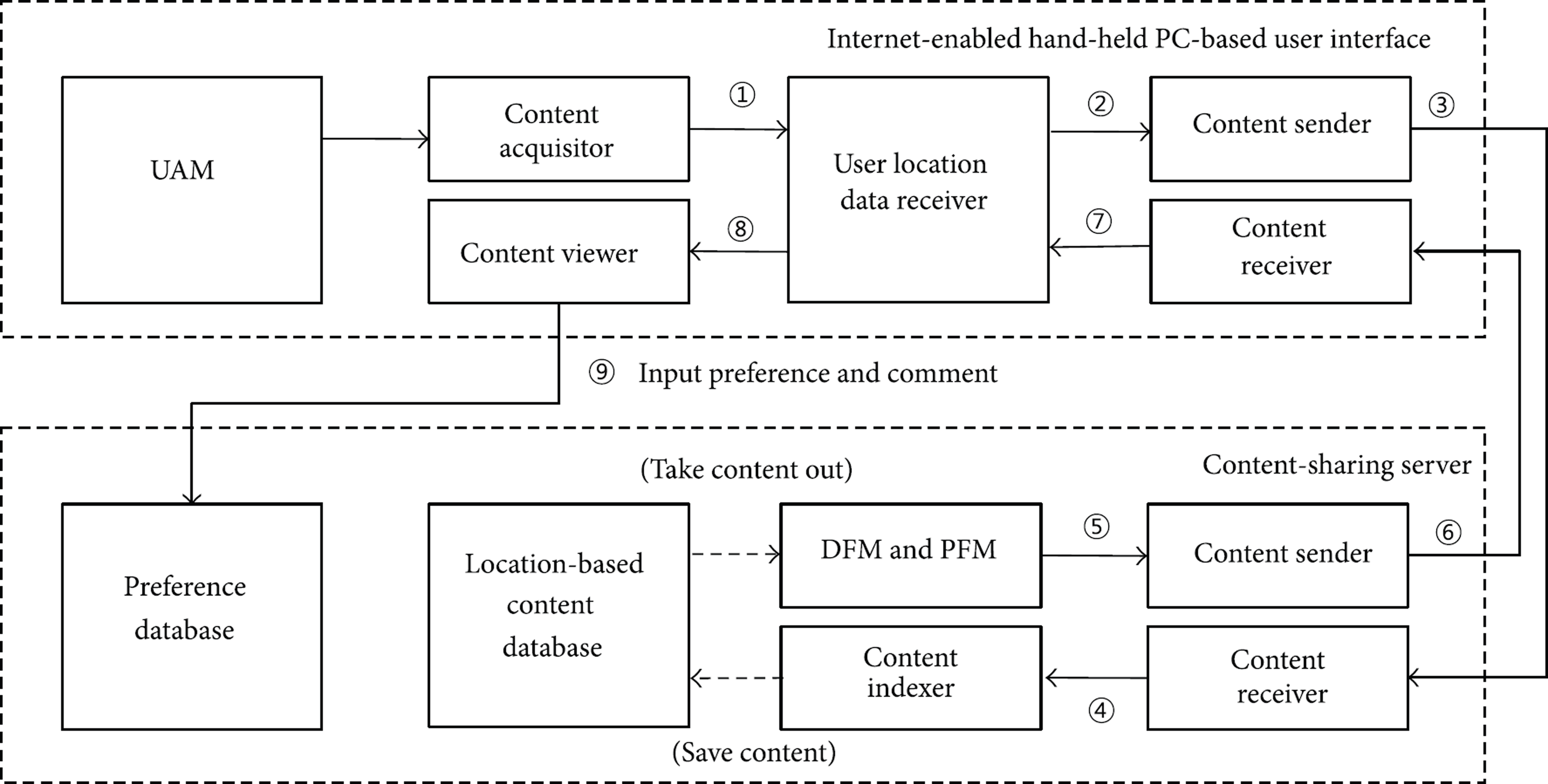
The system architecture.
3.1. The UAM: User Authentication Module
In this subsection, we describe the facial recognition system, which is composed of image acquisition and facial region detection, feature extraction of the facial image, and a recognition phase. For this study, we employed the AdaBoost algorithm based on Haar-like features for facial region detection. The nearest neighbor classifier using 2D-PCA as a feature vector was also used in the process of facial recognition. Specifically, 2D-PCA computes the corresponding eigenvectors more efficiently than PCA because the size of the image covariance matrix is equal to the width of the images, which is quite small compared to the size of a covariance matrix in PCA. Thus, we employed 2D-PCA in the facial recognition system of a mobile device.
The first phase of facial recognition is facial region detection in an image acquired by a digital camera on a mobile device. For this study, we employed the AdaBoost algorithm based on the Haar-like features introduced by Viola and Jones for object detection [17]. The Haar-like features are used to search the face region, and the prototypes are trained until the face region is accurately represented through the AdaBoost learning algorithm. The AdaBoost algorithm is a method used to construct a strong classifier by combining weak multiple classifiers. A weak classifier 
Each weak classifier is associated with a feature
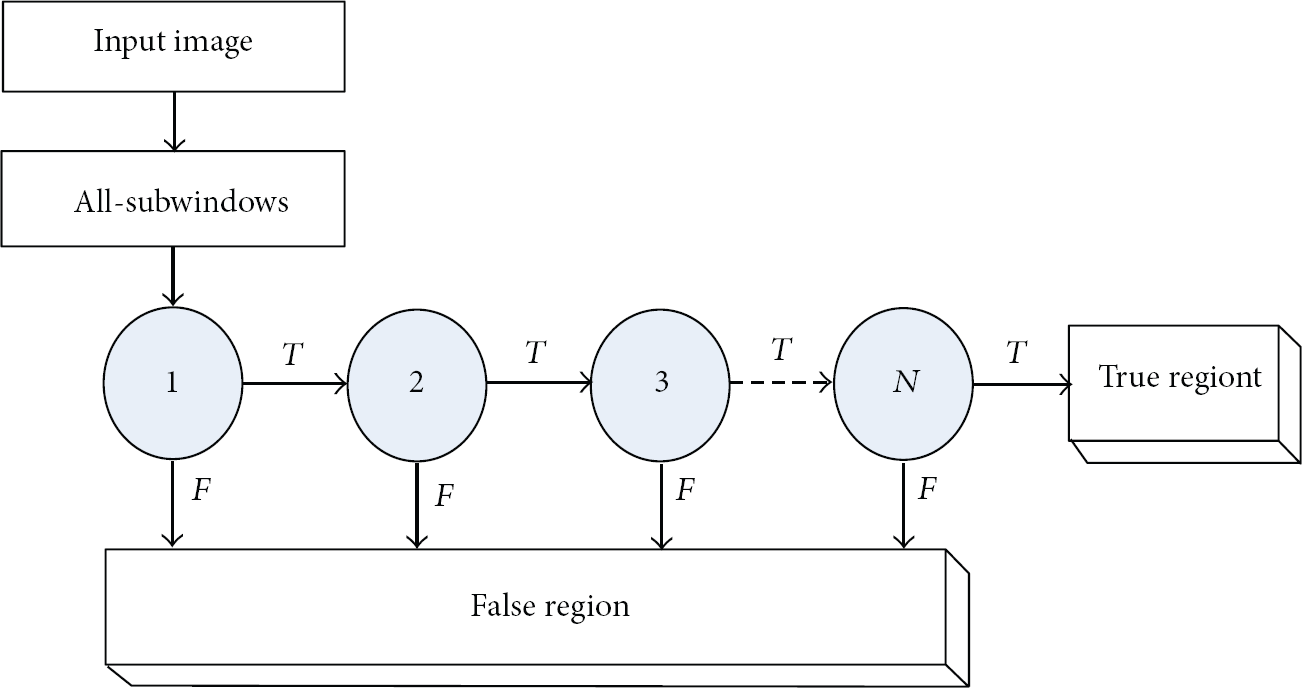
Cascade structure for facial region detection.
To improve recognition performance in uncontrolled illumination environments, such as those encountered on smartphones, we perform a preprocessing procedure in which the MLDP operator is applied to the detected face image. Moreover, we devised a new methodology that directly combines the MLDP image with image covariance-based face feature extraction algorithms such as 2DPCA and A2DPCA. Note that this is a different approach than that used in a previous work, which employed binary pattern descriptors to acquire histogram features. Recently, local binary pattern (LBP) has received increasing interest for use in face representation to overcome the problem of performance degradation caused by illumination variation [26, 27]. The LBP operator labels the pixels of an image by thresholding a

An example of LDP code.
To provide a more stable pattern from the impulse noise and to make an independent pattern against the k value of the LDP, we modify the LDP operator by considering all directions of the 3*3 neighborhood pixels. Because the LDP only selects k components with high response values, unselected components that had relatively high response values compared to those of the selected components are ignored during pattern creation. Thus, we devise the MLDP operator by considering the response values of all neighborhood pixels. This operator is derived as

In Figure 4, we depict a sample image transformed using the MLDP and the LDP operators for face images. With fewer noise components than the LDP images, the proposed MLDP image has stronger facial texture components than the LDP image. In addition, the proposed MLDP has merit in that it is more robust than previous LBP and LDP operators against impulse noise. In Figure 5, we show examples of several binary patterns for a small image patch, before and after adding impulse noise. After adding the noise, we can observe that the 2nd bit of the LDP has changed from 1 to 0. However, the MLDP shows the same pattern, that is, 01111100; thus, it provides a more stable pattern than those of the LBP or LDP. Note that the MLDP is computed using the edge response values without performing the absolute operation as shown in Figure 5, while the LDP carries out the absolute operation. For example, bit values having edge response values of −399 and −503 were set to 1, as shown in Figure 5(a), since the edge response values are converted to absolute values.

Comparison of LDP and MLDP images: (a) raw image, (b) LDP image, and (c) MLDP image.

Stability of MLDP: (a) binary patterns for image patch and (b) binary patterns for image patch with impulse noise.
Principal component analysis (PCA) is a well-known feature extraction and data representation technique that is widely used in the areas of pattern recognition, computer vision, and signal processing [23, 24]. The central underlying concept is to reduce the dimensionality of a dataset while retaining variations as much as possible [25]. In PCA-based facial representation and recognition methods, the 2D facial image matrices must have been previously transformed into 1D image vectors column by column or row by row. However, concatenating 2D matrices into 1D vectors often results in a high-dimensional vector space, where it is difficult to accurately evaluate the covariance matrix due to its large size and the relatively small number of training samples [14]. Furthermore, computing the eigenvectors of a large covariance matrix is very time-consuming.
To overcome these problems, a new technique called two-dimensional principal component analysis (2D-PCA) was proposed to directly compute the eigenvectors of the so-called image covariance matrix without a matrix-to-vector conversion [14]. Because the size of the image covariance matrix is equal to the width of the images, which is quite small compared to the size of a covariance matrix in PCA, 2D-PCA evaluates the image covariance matrix more accurately and computes the corresponding eigenvectors more efficiently than PCA. It was reported in [15] that the recognition accuracy of several face databases is higher using 2D-PCA than when using PCA, and the extraction of image features is computationally more efficient using 2D-PCA than when using PCA [15]:


Unlike PCA, which treats 2D images as 1D image vectors, 2D-PCA views an image as a matrix. Consider an m by n image matrix A. Let
It has been shown that the optimal value for the projection matrix 
Similar to 2DPCA, A2DPCA is also employed for face recognition in this work. While 2DPCA essentially works in the row direction of images, A2DPCA works in the column direction [15]. When compared to 2DPCA, A2DPCA is different in that the covariance matrix is computed by

After feature extraction through 2DPCA or A2DPCA, the nearest neighbor classifier is used to measure the similarities between the training feature and the test feature. The nearest neighbor classifier is a simple classifier that requires no specific training phase. Here the distance between the two arbitrary feature vectors, Y and 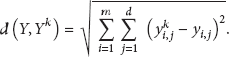
In this formula, k is 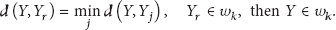
3.2. The DFM: Distance Filtering Module
The DFM searches for the location-tagged content of a place in a specific user-centered radius. The radius is established by user selection. The error value varies according to the approach and the real distance. The simplest method considers the two-dimensional coordinates according to the latitude and longitude, as shown in (9), which is given as a directional distance on the map:
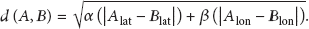
In this formula, α is the number of kilometers per 1 degree of latitude in the target area, and β is the number of kilometers per 1 degree of longitude in the target area. If it is possible to measure the distance on the road, another artificial intelligence method should be considered, such as the
3.3. The PFM: Preference Filtering Module
A key module in the system considers content-sharing personalization. This module refers to a preference database and then generates a content recommendation list based on the memory-based CF [12]. However, the memory-based CF has a scalability problem that increases the calculation cost as the content and number of users increase. The PFM, which is based on the results from the DFM, helps to ameliorate this problem. This module recommends personalized content for a user by predicting a preference rating score for new content using results from the DFM. CF is mainly applied to electronic commerce; in this study, we attempted to apply CF to LBS and confirm its effectiveness. Our scheme and generalized steps for the PFM are shown below.
Step 1.
Collect ratings for the experimental location-based content from a large number of users and then construct the preference database. The target user must have evaluated location-based content in the preference dataset because this is a necessary condition to use CF.
Step 2.
Search the top- k similar users who rated the target item. Considering linear similarity algorithms such as PCC, COS, and RMS is important when searching for similar users. The vector space model-based method includes cosine similarity (COS), which is frequently used in information retrieval. The COS model assumes that the rating of each user is a point in vector space and then evaluates the cosine angle between the two points by considering the common rating vectors 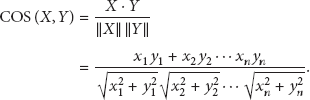
One correlation-based method utilizes the Pearson dot-product correlation coefficient (PCC), which is normally used to evaluate the association intensity between two variables. PCC is given by

Our research team proposed row moment-based similarity (RMS) in August 2011. This method is more effective than traditional methods under data sparsity conditions. The RMS is given by

Step 3.
Predict ratings based on a preference database to determine the expected rating of a target user for the target content. Accordingly, the PFM predicts the rating of the target user for the target content with weight similarities. Equation (13) shows the prediction method, where u indicates the target user, i indicates the target item, j indicates other users, and w is the similarity between u and j [12]:
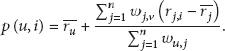
3.4. Characteristics of the System
The proposed system contains various academic and practical advantages. First, concerning the UAM, the system is largely protected against security problems and is more tractable than existing security methods. We will show the processing results of the UAM on a smartphone. Second, concerning the DFM and PFM, the system employs a novel approach for solving the scalability problem of the CF. The convergence of DFM and PFM in the proposed system shows that the use of characteristics in the application area can improve the scalability problem. Third, concerning the PFM, application of the CF is extended to the LBS. The CF is commonly applied to increase sales in e-commerce, but here it is used to create recommendations for users. Last, the generalized form of a novel SNS system is shown by a convergence of RS, LBS, and the existing SNS.
4. Experiment and Result
4.1. Experimental Results for Facial Recognition
To verify the UAM, we used a smartphone with a 1 GHz processor, 512 MB of memory, a 5 MP front-facing camera, and the Android-based Gingerbread version 2.3 operating system. For the purposes of this performance evaluation, we constructed a database consisting of frontal facial images with lighting maintained at about 200 lux in an indoor environment. The experimental database contains a total of 1,000 images of 50 subjects, that is, 20 images per individual. This study used 250 images for training, and the remaining images were used to evaluate performance.
To evaluate the recognition performance of the proposed face recognition system, we employed images from the Yale B database [24] and the CMU-PIE database [25]. The Yale B database consists of 640 face images of 10 subjects in a frontal pose and in 64 illumination conditions. The CMU-PIE database contains more than 40,000 facial images of 68 individuals, 21 illumination conditions, 13 poses, and four different expressions. From these, we selected illumination images of 68 individuals in frontal poses. So, the CMU-PIE set consists of 21 images of 68 individuals (21 × 68 images in total). First, we investigated the detection rates and detection times for each database. The detection rates were 91.71% and 94.57% for the Yale B database and the CMU-PIE database, respectively. Also, the average detection times for one image were 182 ms and 187 ms for the Yale B database and the CMU-PIE database, respectively. Undetected images, including false-detected images, were added to the experimental datasets by manually cropping the associated regions. Based on the datasets described, the performance evaluation of the proposed approach was carried out using various recognition approaches, such as PCA, 2DPCA, A2DPCA, Gabor-wavelets based on LBP [26], and support vector machine (SVM) based on LDP [27].
Next, we investigated the recognition performance of the proposed system with two databases. During the performance evaluation, we partitioned each database into training and testing sets. For the Yale B database, we used 45 face images for each subject, and the database was further subdivided into four subsets depending on the direction of light [28]. For the Yale B database, we employed the first subset for training, and the remaining subsets were used for testing. For the CMU-PIE databases, five images from each person were used for training and the remaining images were used for testing. Here, we selected illumination-invariant images for training, and the remaining images were employed for testing.
For the Yale B database, the recognition results for different recognition algorithms such as PCA, 2DPCA, and A2DPCA are shown in Figures 6, 7, and 8, respectively. To further show the relationship between the recognition rate and the dimensions of the feature vectors, we provide the recognition results along with the different dimensions. Furthermore, we summarized the maximum recognition rates in Table 2. The maximum recognition rates were found to be 93.98%, 98.98%, and 98.98% for PCA, 2DPCA, and A2DPCA, when using the MLDP image. Here, we can observe that the maximum rates were achieved with the proposed approach, which uses image covariance-based feature extraction algorithms, that is, 2D-PCA and A2D-PCA, and the MLDP image. For the CMU-PIE database, the recognition results for PCA, 2DPCA, and A2DPCA are shown in Figures 9, 10, and 11, respectively. Also, we summarized the maximum recognition rates in Table 2. The maximum recognition accuracies had values of 94.55%, 96.25%, and 96.17% for PCA, 2DPCA, and A2DPCA, respectively, when using the MLDP image. As with the recognition results from the Yale B database, we can observe that the maximum rates were achieved with the proposed approach. Consequently, the proposed approach using 2DPCA and A2DPCA based on the MLDP images achieved the best recognition rates for all databases. Also, the proposed approach showed better performance compared to previous methods, such as Gabor-wavelets based on the LBP approach [26] and SVM based on the LDP approach [27].
Summary of recognition accuracies.

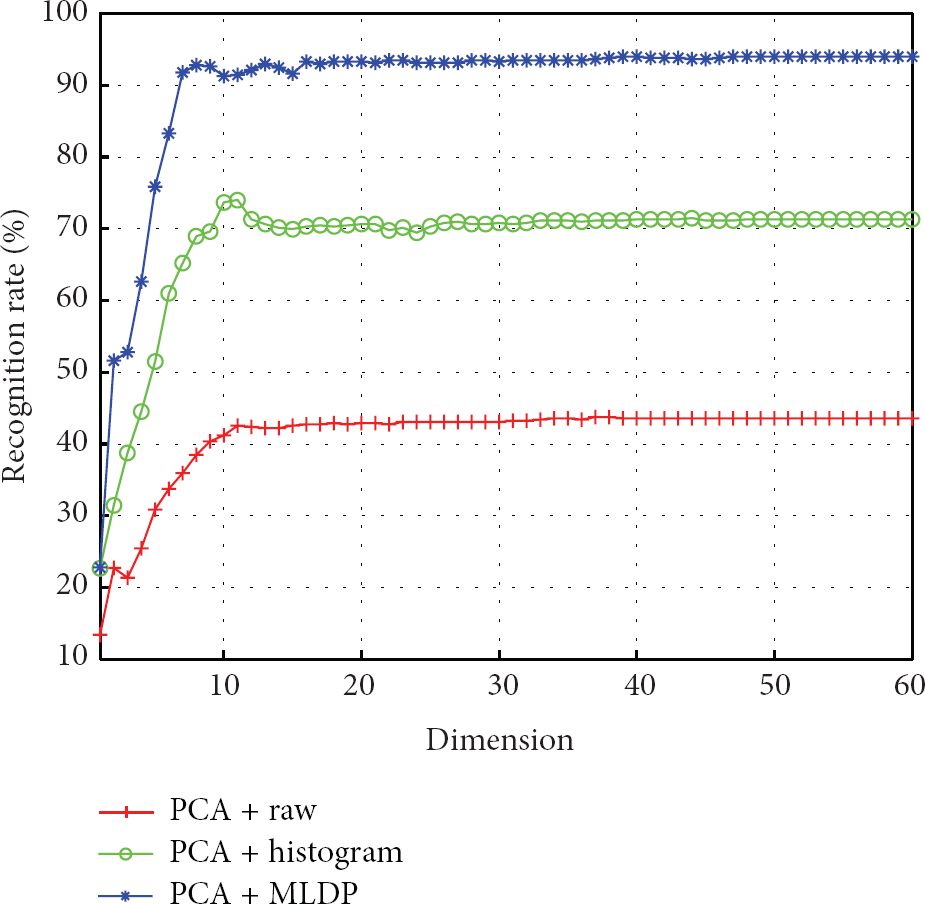
Recognition results using PCA for the Yale B database.
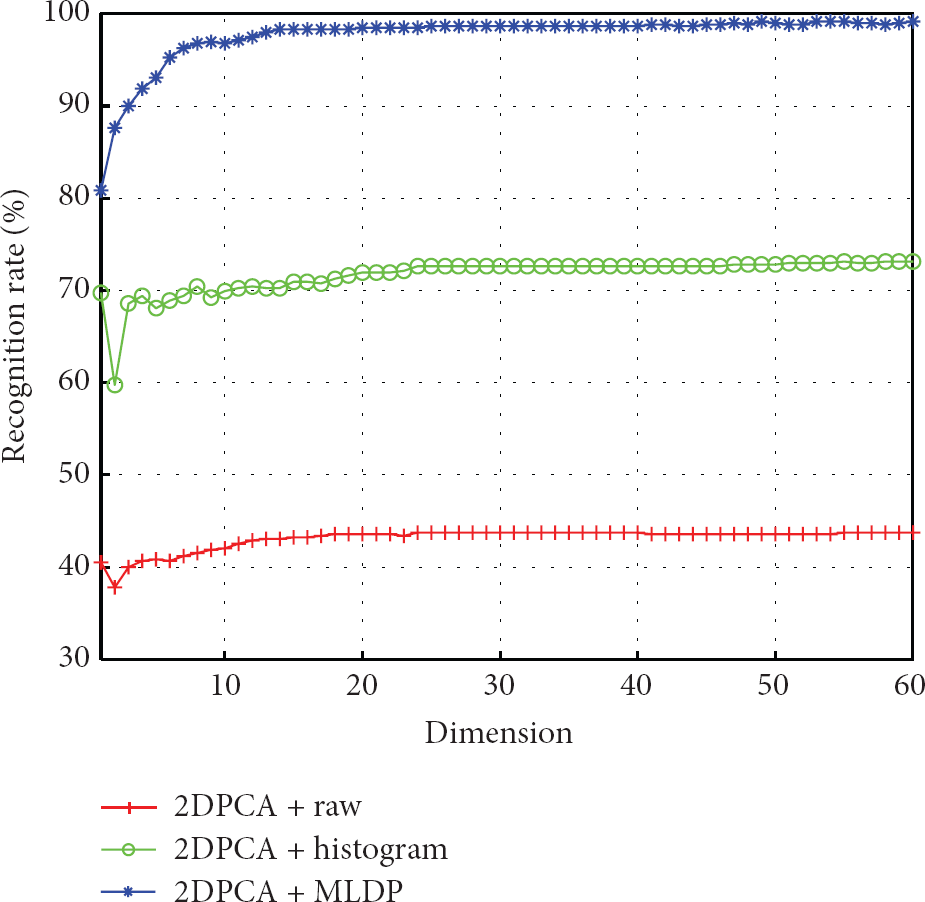
Recognition results using 2DPCA for the Yale B database.

Recognition results using A2DPCA for the Yale B database.

Recognition results using PCA for the CMU-PIE database.

Recognition results using 2DPCA for the CMU-PIE database.

Recognition results using A2DPCA for the CMU-PIE database.
4.2. The PFM: Preference Prediction Accuracy and Recommendation Quality
To verify the PFM, we collected content and user preference scores over a period of one year. We obtained 687 images consisting of location-tagged content from 52 users. The users rated shared content on a scale from 1 to 5. The total number of rating data points was 9,473. The data format was {user id, content id, rating score}. We randomly divided the rating dataset using an 8 : 2 ratio, then predicted a rating of 20%, and measured the absolute average error (MAE).
Figure 12 shows the general prediction accuracy of the proposed system using our dataset. COS is the cosine coefficient, PCC is the Pearson correlation coefficient, and RMS is the raw-moment similarity method [13]. The existing CF area shows that the MAE values ranged from 0.73 to 0.75 in the MovieLens 100 k dataset, which has the same rating scale as our dataset. Our experimental results showed 0.5406 to be the best MAE, confirming that applying the CF to the LBS was more effective than the more common application area of e-commerce.

Full-rating experimental result.
Figure 13 shows the results of the artificial data scarcity experiment. This experiment creates an artificial data scarcity condition by restricting the number of coitem ratings between two variables. The coitem ratings used to measure similarity were randomly selected. This experiment showed that our method was robust with regard to the data scarcity problem. We applied an optimal neighborhood size around each similarity method, similar to those seen in Figures 12 and 13, to show that the user's preference was reflected more strongly in the personal LBS. In other words, we confirmed strong performance of the proposed method in spite of a comparatively small amount of ratings data, which showed a good convergence of the CF and LBS. However, an intensive study using many more rating data points is required.
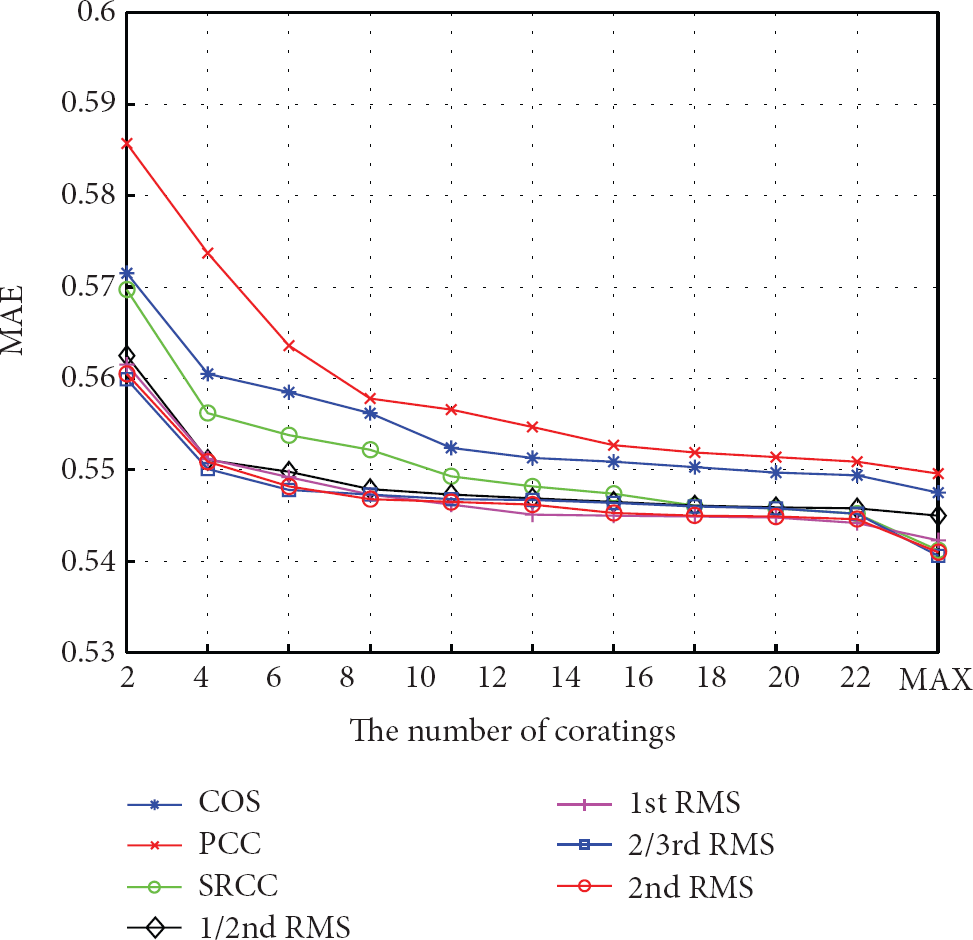
Artificial data scarcity experimental results.
The second experiment for the PFM addressed the recommendation quality of the full-rating experimental results. The measures were precision, recall, and F-score. The precision and recall are defined by (14), where 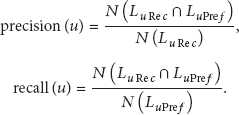
Experimental results for recommendation quality.

5. Application
5.1. Prototype Implementation Environment
We implemented a prototype of the proposed system. Since mobile applications based on Java are slower than applications written in native C/C++ languages, we used the Native Development Kit (NDK) for mobile operating systems and Java Native Interfaces (JNI) [29, 30] to improve the performance of the mobile application. Further, the system frequently requires memory access, which involves complex calculations due to the real-time image processing. Consequently, the code related to facial detection and recognition algorithms used in this study was written in native C, and other codes related to the Graphical User Interface (GUI) were written in Java with the Software Development Kit (SDK) for mobile operating systems.
5.2. Service Scenario
Figure 14 shows the results from the implementation of the proposed system. In the UAM, the system detects a user's face and then saves the facial image file. The UAM recognizes a user's face based on the facial image file, which could be used to recognize the user during the next authentication or to represent the current user to other users on the map. Existing SNS services use a text input method for authentication, while the proposed system in this study uses a state-of-the-art, biometric authentication method. Our method also includes a remarkable level of security for protecting personal information in the mobile SNS, which could contain the personal information of many users.
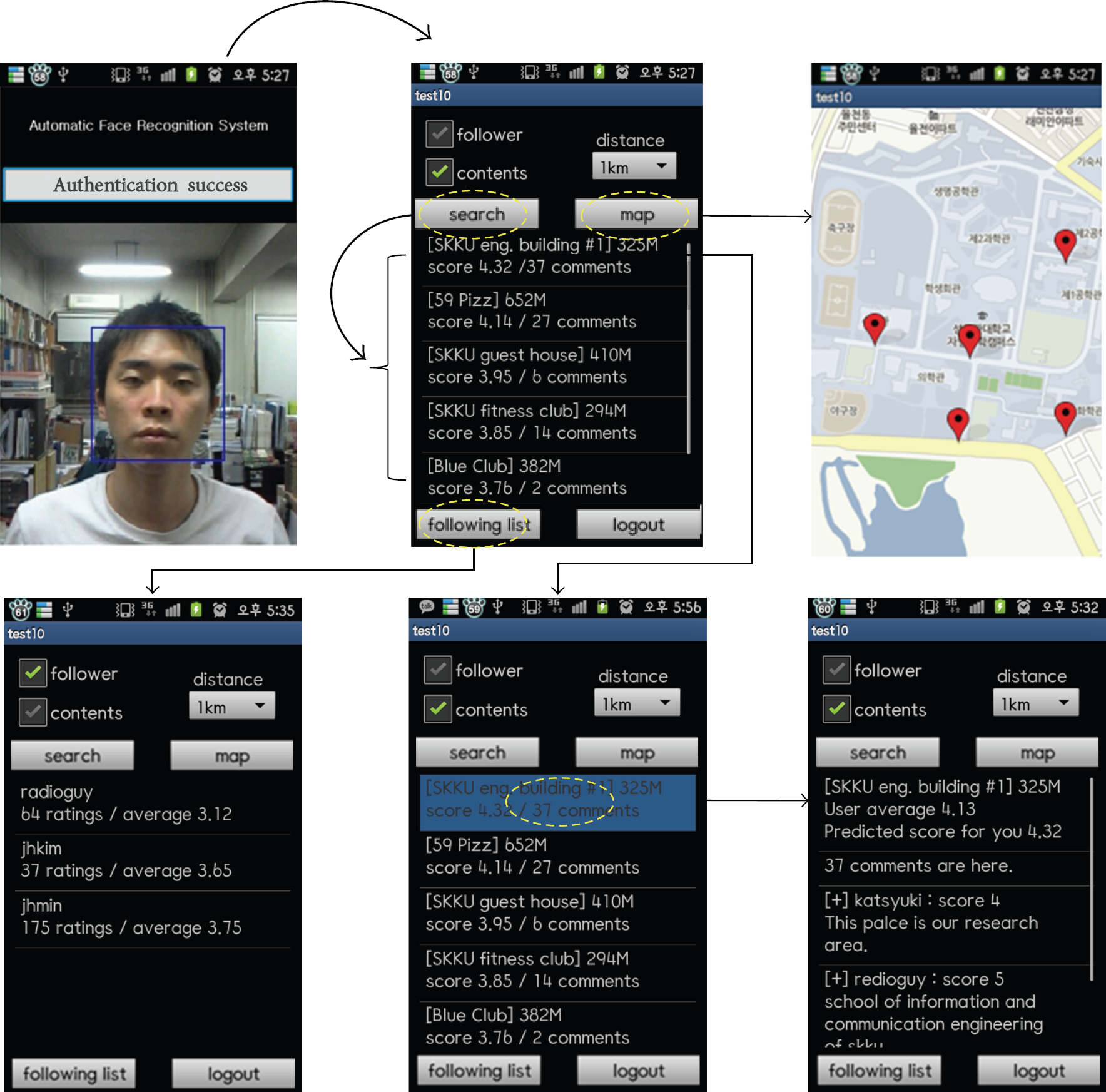
Actual images and a scenario based on a free Internet map.
After authentication by the UAM, the system shows the recommended content list, which is the processing result of preference filtering by PFM and distance filtering by DFM, as a user-oriented personalized content list recommended according to a default radius that can be changed by the user. The system shows the location of the user and the recommended content based on the mobile maps. The map is implemented using mobile mash-up technology. The PFM and DFM in the proposed system select personalized content from a large collection of location-tagged content based on the ratings of users who showed similar tastes.
When the user wants to view detailed information about the location-tagged content, he or she will click on the content from a printed list. Clicked content will be highlighted for a moment and then will show detailed information such as comments and ratings from other users. The [+] symbol next to a username in the comments means that the target user can be added to the “following” list. In the proposed system, the “following” list is a group of users with similar ratings values. Users clicking the follow button [+] will cause the system to count the selected users' ratings and their rating averages similar to the user-closest results based on PFM. For instance, the message and trace function between followers can be considered. Namely, a user can communicate with other users and followers based on these facilities; this ability is intrinsic to the SNS. We are able to improve this ability with intuitive user authentication by user facial recognition, personalization by sharing content by CF, and user position recognition by LBS.
In summary, the proposed system improves mobile SNSs using state-of-the-art technologies, including the ability to post from a blog. Images from the user may also be used as markers on a map to show followers the size, location, or conditions of the area. This prototype can be used in two-way TVs, PCs, tablet PCs, and car navigation systems by changing their application platforms to IT convergence solutions.
6. Conclusion
This study proposed a new mobile SNS system that combines LBS, RS, and user facial authentication technology. The user authentication method in the proposed system is a secure way to protect personal information on a mobile SNS. A PFM and DFM in the proposed system select personalized content from a collection of location-tagged content based on the ratings of users with similar preferences. The CF has constraints that apply when an individual's preference has not been clearly defined. A user can communicate with other users based on his comments and preference ratings for shared content. We improved mobile social networks by adding user facial recognition, personalization for sharing content, and user position information. We created a prototype and a scenario based on a smartphone for testing. In this study, we applied a state-of-the-art personalization method, CF to LBS, and validated it. We expanded its formerly restricted e-commerce application to include quantitative performance to verify its effectiveness. The proposed system can be extended by integration into other platforms, that is, two-way TVs, Web-map services, and car navigation systems.
The proposed system was created for location-based services and personalized recommendations. Accordingly, it was compared to existing SNSs that have been developed based on personal blogs. The proposed system's convergence with existing SNSs will be a novel study topic for next-generation mobile SNSs. We are pursuing further study with an in-depth analysis of the system and its suitability for various applications and completing additional verification.
Footnotes
Acknowledgments
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (2013059769) and the Basic Science Research Program through NRF of Korea, funded by MOE (NRF-2010-0020210).