
Abstract
Biological sensors are a very promising technology that will take healthcare to the next level. However, there are obstacles that must be overcome before the full potential of this technology can be realized. One such obstacle is that the heat generated by biological sensors implanted into a human body might damage the tissues around them. Dynamic sensor scheduling is one way to manage and evenly distribute the generated heat. In this paper, the dynamic sensor scheduling problem is formulated as a Markov decision process (MDP). Unlike previous works, the temperature increase in the tissues caused by the generated heat is incorporated into the model. The solution of the model gives an optimal policy that when executed will result in the maximum possible network lifetime under a constraint on the maximum temperature level tolerable by the patient's body. In order to obtain the optimal policy in a lesser amount of time, two specific types of states are aggregated to produce a considerably smaller MDP model equivalent to the original one. Numerical and simulation results are presented to show the validity of the model and superiority of the optimal policy produced by it when compared with two policies one of which is specifically designed for biological wireless sensor networks.
1. Introduction
Biological wireless sensor networks (BWSNs) are networks made up of biological sensors (biosensors, for short) which are tiny wireless devices attached or implanted into the body of a human or animal to monitor and control biological processes. They have originated because of the need to improve and modernize healthcare. The sensing elements in biosensors are biological materials such as enzymes and antibodies. They are integrated into transducers for producing electrical signals in response to biological reactions and changes.
A famous application of BWSNs is the geodesic sensor network developed by EGI corporation [1]. In this application, a cap-based system of electrodes is worn by a patient for continuous brain monitoring. Figure 1 shows a girl wearing a geodesic sensor network. The sensor network collects electroencephalographical (EEG) measurements of the brain and delivers them to a controller which processes them and displays the results. Another example is glucose biosensors which monitor the blood glucose level in a diabetic patient. They can be used to optimally control the infusion of insulin into the patient or to initiate a prompt medical intervention. An example of glucose biosensors can be found in [2].

A girl wearing a geodesic sensor network [1].
In addition to being energy-constrained, biosensors are also temperature-constrained. This is due to the heat generated as a result of their operation in temperature-sensitive environments like the human body. Radiation which is mainly due to wireless communication is the major source of heat. (Another major source of heat is the radiation due to RF recharging in rechargeable BWSNs. This source of heat is not considered here since we are assuming nonrechargeable biosensors.) The tissues surrounding biosensors absorb the RF energy which gets transformed into heat. This effect is balanced by the human thermoregulatory system. However, if the generated heat is larger than what can be drained, the temperature of the tissues rises. If the blood flow is not sufficient, the affected tissues might be damaged.
Thermal effects caused by biosensors are a major obstacle in the road to realizing the full vision for BWSNs. These effects can be mitigated through the use of effective thermal management techniques. One such technique is the dynamic scheduling of the transmission of biosensor measurements. As will be shown, this technique is very effective in reducing the temperature rise in the tissues due to heating. In this paper, the thermal management problem in BWSNs is studied. It is shown how it can be modeled as a stochastic control problem. Randomness is present due to the random behavior of the wireless channel between biosensors and the base station where measurements are collected and processed.
Toward that end, the framework of MDPs is used to build a mathematical model of the BWSNs under study. The model is then solved to obtain a policy which dictates how the BWSN should be operated in order to avoid a hazardous temperature increase. The obtained policy can achieve the best balance between transmission energy consumption and temperature increase. It also results in the minimum temperature increase when compared to existing policies.
In order to reduce the size of the MDP model, state aggregation is used. Two classes of system states are identified. A considerable reduction in the size of the MDP model is achieved when the states in these two classes are aggregated. The equivalence of the reduced MDP model to the original one is established and the reduction in model size is shown. A reduction of as high as 79% can be achieved.
The remainder of the paper is organized as follows. First, the necessary background information is given. Second, the available literature is briefly reviewed. Third, the system under study is described. Then, its MDP model is presented. After that, the minimization of the size of the MDP model using state aggregation is discussed. Then, numerical and simulation results are presented within the context of an example to illustrate the viability of the MDP model. Finally, conclusions and directions for further research are given.
2. Background
This section presents the necessary information to understand how temperature increase is calculated. It also briefly explains MDPs and points out some approaches for handling their state explosion problem.
2.1. Calculating Temperature Increase
RF signals used for wireless communication and recharge of implanted biosensors produce electrical and magnetic fields. When a human gets exposed to electromagnetic fields, the absorbed radiation gets converted into heat which manifests itself as a temperature increase inside the tissues. This phenomenon is balanced by the human thermoregulatory system. If the generated heat is larger than what can be drained, the temperature of the tissues will rise. The tissues might be damaged if the generated heat cannot be regulated by the blood circulation system.
The level of radiation absorbed by the human body when exposed to RF radiation is measured by the specific absorption rate (SAR) which is expressed in units of watts per kilogram (W/Kg). SAR records the rate at which radiation energy is absorbed per unit mass of tissue [3]. SAR is a point quantity. That is, its value varies from one location to another. SAR in the near field (i.e., the space around the antenna of the biosensor) causes the heating of the tissue surrounding the biosensor. It is a function of the current provided to the antenna of the biosensor. As an example to appreciate the importance of this measure, it was reported in [4] that an exposure to an SAR of 8 W/Kg in any gram of tissue in the head for 15 minutes may result in tissue damage.
The Pennes's bioheat equation [5] is the standard for calculating the temperature increase in the body due to heating. This equation can be transformed into a discrete form by using the finite-difference time-domain (FDTD) method [6]. Basically, the area under consideration is divided into cells and the temperature is evaluated in a grid of points defined at the centers of the cells. It is assumed that the temperature of the surrounding cell points is the normal body temperature (i.e., 37°C).
2.2. Markov Decision Processes
An MDP is a model of a dynamic system whose behavior varies with time. The elements of an MDP model are the following [7]:
system states, possible actions at each system state, a reward or cost associated with each possible state-action pair, next state transition probabilities for each possible state-action pair.
The solution of an MDP model (referred to as a policy) gives a rule for choosing an action at each possible system state. If the policy chooses an action at time t depending only on the state of the system at time t, it is referred to as a stationary policy. An optimal stationary policy exists over the class of all policies if every stationary policy gives rise to an irreducible Markov chain. This means that one can limit the attention to the class of stationary policies.
An interesting class of MDPs is the class of MDPs with a terminating state. This state is reached with probability one in a finite number of steps. The number of steps represents the lifetime of the Markovian process induced by the MDP model (hence, the lifetime of the modeled system). The solution of the model is a policy which drives the system into the terminating state while optimizing an objective function which may include the lifetime of the system as a parameter.
In order to obtain a policy from an MDP model, it is necessary to form and solve the so-called optimality equation (or Bellman equation). The following is the standard form of this equation with the maximization operator [8]:

Equation (1) can be solved using the classical policy iteration, value iteration, and relative value iteration algorithms [8]. However, these algorithms become impractical when the number of system states is large. In such situations, one typically resorts to approximate techniques such as in [9–12]. Another solution for the problem of state explosion is state aggregation [13–17]. In this technique, using some notion of equivalence, equivalent states are combined into one class which is represented by a single state in the reduced MDP model. The new MDP model is equivalent to the original one but with significantly fewer states. In this paper, this technique is used to aggregate two kinds of system states.
3. Related Work
The research on the possible biological effects caused by biosensors and how to mitigate those effects is very recent. Most of the existing research deals with other technical issues such as energy efficiency and quality of service. In this section, we briefly review the limited available literature.
The effect of leadership rotation on a cluster-based biological WSN was studied in [18]. It was observed that rotating the role of which node collects measurements from other sensors and delivers them to the base station can significantly reduce the temperature increase in tissues due to wireless communication. The computation of an optimal rotation sequence involves using the Pennes's bioheat equation [5] and the finite-difference time-domain (FDTD) method [6] to calculate the temperature increase due to a sequence. Because of its time requirement, the authors proposed another scheme to calculate the temperature increase. It is referred to as the temperature increase potential (TIP). It efficiently estimates the temperature increase of a sequence. Using this scheme and a genetic algorithm, they were able to find the minimum temperature increase rotation sequence. They, however, did not consider the effect of the wireless channel and limited energy.
The issue of routing in biological WSNs was studied in [19]. The authors proposed a thermal-aware routing protocol that routes the data away from high temperature areas referred to as hot spots. The location of a biosensor becomes a hot spot if the temperature of the biosensor exceeds a predefined threshold. The proposed protocol achieves a better balance of temperature increase and shows the capability of load balance.
In [20], the sensor scheduling problem is formulated as an MDP. The objective is to find an operating policy that maximizes the network lifetime. The state of a sensor is characterized by its current energy level only. Three kinds of channel state information are considered: global, channel statistics, and local. Considering only the energy level at each sensor gives rise to an acyclic (i.e., loop-free) transition graph which enables the MDP model to converge in one iteration. On the other hand, if the temperature of each sensor is included in the model, the transition graph of the underlying MDP becomes cyclic. This is because when the sensor cools down (i.e., its temperature decreases), it transitions back to a less hot state. An MDP model whose transition graph is cyclic needs more time to converge.
Dynamic sensor activation in networks of rechargeable sensors is considered in [21]. The objective is to find an activation policy that maximizes the event detection probability under the constraint of slow rate of recharge of the sensor. The state of the system is characterized by the energy level of the sensor and whether or not an event would occur in the next time slot. The recharge event is random and recharges the sensor with a constant charge. The model does not include the state of the wireless channel which is very crucial when temperature is considered.
Body sensor networks [22] with energy harvesting capabilities are another kind of WSNs in which each sensor has an energy harvesting device that collects energy from ambient sources such as vibration, light, and heat. In this way, the more costly recharging method which uses radiation is avoided. The interaction between the battery recharge process and transmission with different energy levels is studied in [23]. The proposed policies utilize the sensor's knowledge of its current energy level and the state of the processes governing the generation of data and battery recharge to select the appropriate transmission mode for a given state of the network.
4. System Model
Figure 2 shows a BWSN consisting of three biosensors implanted into the body of a patient. The biosensors communicate with an access point (or base station) over a wireless channel. The wireless access point initiates the data collection process by determining which biosensor is going to transmit the next measurement. A biosensor is selected for transmission based on the current network state and some policies. The wireless access point is assumed to know the global channel state information (CSI) of the wireless channel and the state of each biosensor at each point in time. It is assumed that the instantaneous received signal-to-noise ratio (SNR) fully characterizes the state of the wireless channel.

A patient with three biosensors implanted into his body.
The setup in Figure 2 can mathematically be modeled as a discrete-state system which evolves in discrete time. Thus, the time axis is divided into slots of equal duration
The system in Figure 2 works as follows. At the beginning of each time slot, a biosensor is selected by the base station to transmit its measurement. As a result, the energy and temperature of the selected biosensor change according to its transmission energy requirement which is determined by the state of the wireless channel. Also, the temperature of the neighbors of the selected biosensor increases based on the amount of energy used in the transmission. On the other hand, the temperature of the nonneighboring biosensors decreases. The change in the temperature of the biosensors can be calculated using the Pennes's bioheat equation and the FDTD method (for more details, see Section 2.1.). However, due to the large simulation time required before the temperature change reaches a steady state, this approach is not followed here. Instead, the temperature decrease is assumed to be a constant reduction which occurs whenever the biosensor is not transmitting and not a neighbor of a transmitting biosensor. The temperature increase is also assumed to be directly proportional to the energy consumed by the transmitting biosensor.
Clearly, from the previous description, the location of a biosensor represents a critical point since it experiences the maximum temperature increase. This is because the tissues surrounding a biosensor might be heated continuously due to the local radiation generated by the biosensor itself and the radiation generated by its neighbors.
Let χ be the set of biosensors which have been surgically implanted in the body of a patient and at known locations. Also, let
At the end of each time slot, the energy level at each biosensor i is given by the following equation:
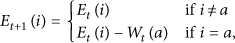

Finally, the communication between the biosensor and base station occurs over a Rayleigh fading channel with additive Gaussian noise. Hence, the instantaneous received SNR denoted by γ is exponentially distributed with the following probability density function [24]:

Such a wireless channel can be modeled as a finite-state Markov chain (FSMC) [25, 26]. The model can be built as follows. For a wireless channel with K states, the state boundaries (i.e, SNR thresholds) are denoted by
The steady-state probability of the ith state of the FSMC is given by

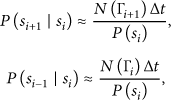

Therefore, the transmission energy requirement for a biosensor i follows a Markov chain with L states and transition probabilities
5. MDP Model
5.1. Formulation
The purpose of the MDP formulation of the system described in the previous section is to find a policy π that prescribes the best action to take in each state of the system so as to maximize the long-term expected lifetime of the system. The policy π is a stationary policy which means that it is independent of time and depends only on the state of the system. Next, we give the details of the MDP model.
5.1.1. State Set
The state of the system with

Let S be the set of possible system states. Then, the number of possible system states is
The system enters a terminating state when any one of the following two conditions is true:
temperature of any biosensor is harmful (i.e., a biosensor cannot transmit its measurement due to lack of enough energy (i.e.,
Once the system is in a terminating state, the system must be halted to protect the patient. The system can then be restored to an initial state by recharging the biosensors and letting them cool down.
5.1.2. Action Set
In each time slot, based on the current state of the system, the base station chooses an action (i.e., a biosensor to transmit its measurement). The set of possible actions consists of the indexes of all biosensors. In other words, the set of actions available in each state
5.1.3. Reward Function
Let

5.1.4. Transition Probability Function
The behavior of the system is described by

5.1.5. Value Function
The thermal management problem is formulated as an infinite-horizon MDP using the average reward criterion [7]. So, let

The optimal policy
The relative value iteration (RVI) algorithm [8] is used to numerically solve the following recursive equation for

In (12), the subscript n denotes the iteration index. As
5.2. Minimizing the Size of the MDP Model through State Aggregation
The large state space of the MDP model makes the computation of the optimal policy a highly intensive process and thus only feasible for small-scale networks. This is due to the storage and runtime requirements which are both functions of the number of possible system states. State aggregation can be used to mitigate this problem. With this technique, the state space is partitioned and the states belonging to the same partition are aggregated into one new state. Partitioning is performed by using some notion of equivalence between system states. The final result is a reduced MDP model with the same properties as the original one but significantly fewer states.
In this work, the definition of state equivalence in MDPs introduced in [14] is utilized. This definition can be stated as follows.
Definition 1 (state equivalence [14]).
Two states are equivalent if and only if for every action:
they achieve the same immediate reward, they transit to the same next states with the same transition probabilities.
For example, consider Figure 3 which shows an excerpt of the state space of an instance of the MDP model of the system in Figure 2. In this case, τ and

Excerpt of the system state space showing three classes of states.
The following theorem asserts that system states identified as final valid (terminating) are equivalent and thus can be represented by one final valid (terminating) state in the reduced MDP model.
Theorem 2.
The system states in the class of final valid states (terminating states) are equivalent.
Proof.
We provide the proof for any two system states belonging to the class of final valid states. The proof for any two states belonging to the class of terminating states is the same.
By definition, a valid system state is one at which each biosensor can make a transmission (i.e., all actions are possible). Also, by definition, a final valid system state is one at which the execution of an action generates a reward of one unit and causes the system to enter a terminating state. Since all terminating states are equivalent, the system transits to a terminating state with a probability of one.
The equivalence of the optimal policy produced by solving the reduced MDP model is established by the following theorem.
Theorem 3.
The reduced MDP model produced by combining the final valid states and terminating states induces an optimal policy for the original MDP model.
Proof.
Let
For the inductive case (i.e.,
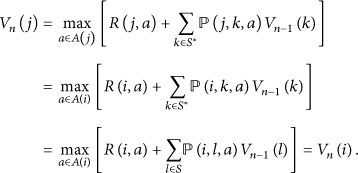
Table 1 shows the percentage reduction obtained for a network with three biosensors.
Reduction in the number of system states when terminating states and final valid states are aggregated. The number of biosensors is 3. τ and L are 7 and 2, respectively.

6. Numerical and Simulation Results
The numerical and simulation results are obtained by using the following example. Consider again the biosensor network shown in Figure 2. The biosensors are indexed from one to three. The neighbors of each biosensor are as follows:
Also, the ℱ function in (3) is defined for each biosensor i as


Figure 4 shows the expected network lifetime for different levels of initial energy (
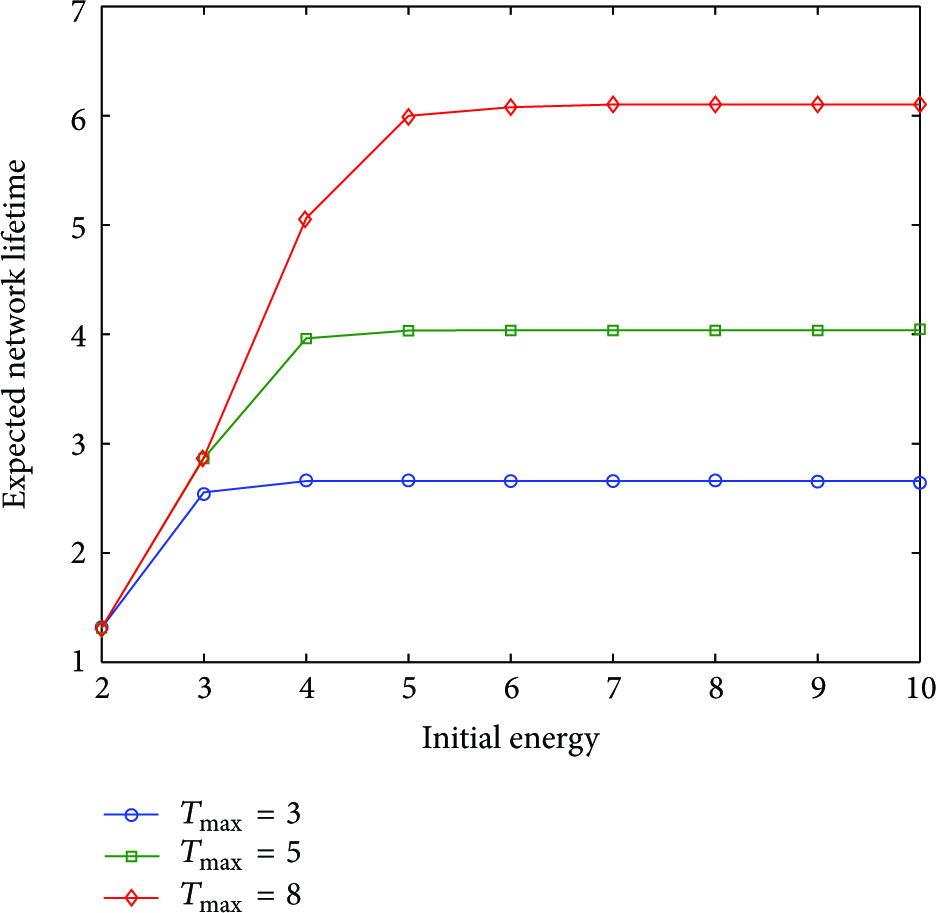
Expected network lifetime versus initial energy for different values of τ.
The initial energy of a biosensor might also become a limiting factor. For example, for
Another interesting issue is the amount of energy which remains in biosensors after the system is halted due to a high temperature increase. For example, from Figure 4, it can be seen that for
Figure 5 shows the actions the optimal policy makes when the remaining energy at each biosensor is fixed at three and the transmission energies of biosensors 1 and 2 are both two and that of biosensor 3 is one.
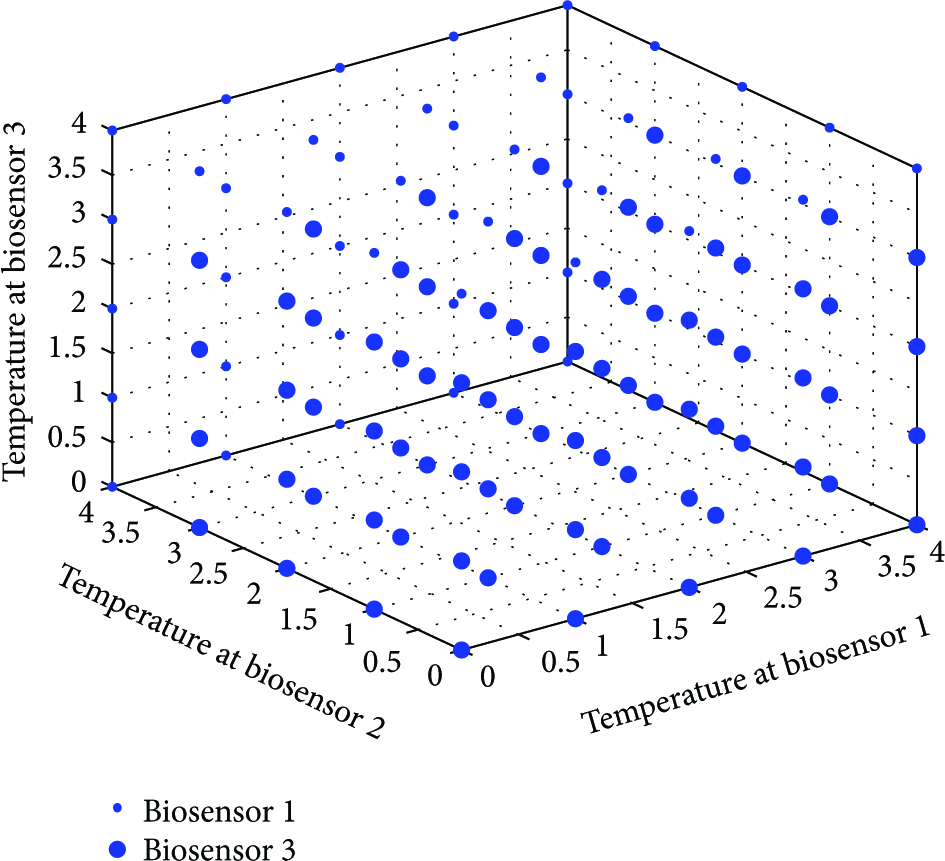
Optimal actions when
Next, the biosensor network is simulated to compare the performance of the optimal policy with that of the TIP-based and most residual energy policies. Also, the impact of varying the initial energy and maximum safe temperature level is evaluated. The simulator is written in Matlab [28] and each data point is the average of 1000 simulation runs. The TIP-based policy (or the optimal rotation sequence) is computed as described in [18]. The optimal sequence is
First, the impact of varying the initial energy on the network lifetime is studied using simulation. Figure 6 shows the simulated lifetime of the biosensor network when the initial energy is varied from 2 to 10. Essentially, the network lifetime increases as the initial energy increases. However, after a threshold (around 4), the lifetime curve starts to level off for all policies. This is because the limit on the maximum allowed temperature increase is reached. Therefore, unless τ is increased, the average network lifetime will not increase with the increase of the initial energy.
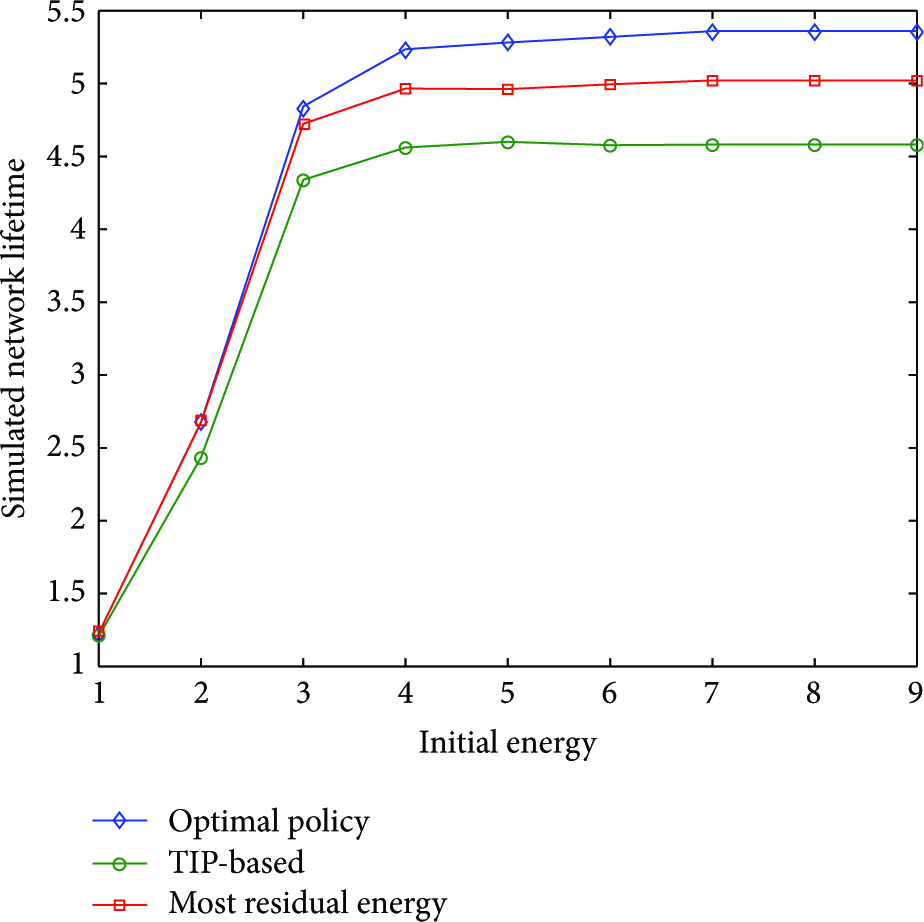
Simulated network lifetime versus initial energy for the different policies.
Figure 6 also shows that the optimal policy outperforms the other two policies. The TIP-based policy performs the worst. The main reason for its poor performance is that the TIP-based policy does not account for the effects of the wireless channel. On the other hand, the policy based on the most residual energy performs better than the TIP-based policy. This is because it always chooses the sensor which consumes the least amount of energy for transmission. Hence, the gap between its curve and that of the optimal policy is smaller. Nevertheless, its performance cannot reach the performance of the optimal policy since temperature is not considered explicitly.
Figure 7 shows the impact on the network lifetime when fixing the initial energy and varying the upper limit on the safe temperature level. As expected, the network lifetime increases as τ increases. However, this increase eventually levels off due to the lack of energy. Clearly, the optimal policy gives the best network lifetime. The policy based on the most residual energy gives the next best network lifetime. The worst network lifetime is achieved by the TIP-based policy.

Simulated network lifetime versus maximum safe temperature level for the different policies.
The performance of the three policies in terms of temperature increase is compared. The initial energy is fixed at
Figure 8 shows the temperature at biosensor 2 over four time slots. As expected, the TIP-based policy gives the maximum temperature increase. A closer examination of the simulation data reveals that biosensor 2 has indeed been continuously heated. This in turns leads to a larger temperature increase and thus shorter lifetime since the maximum allowed temperature is approached very fast.
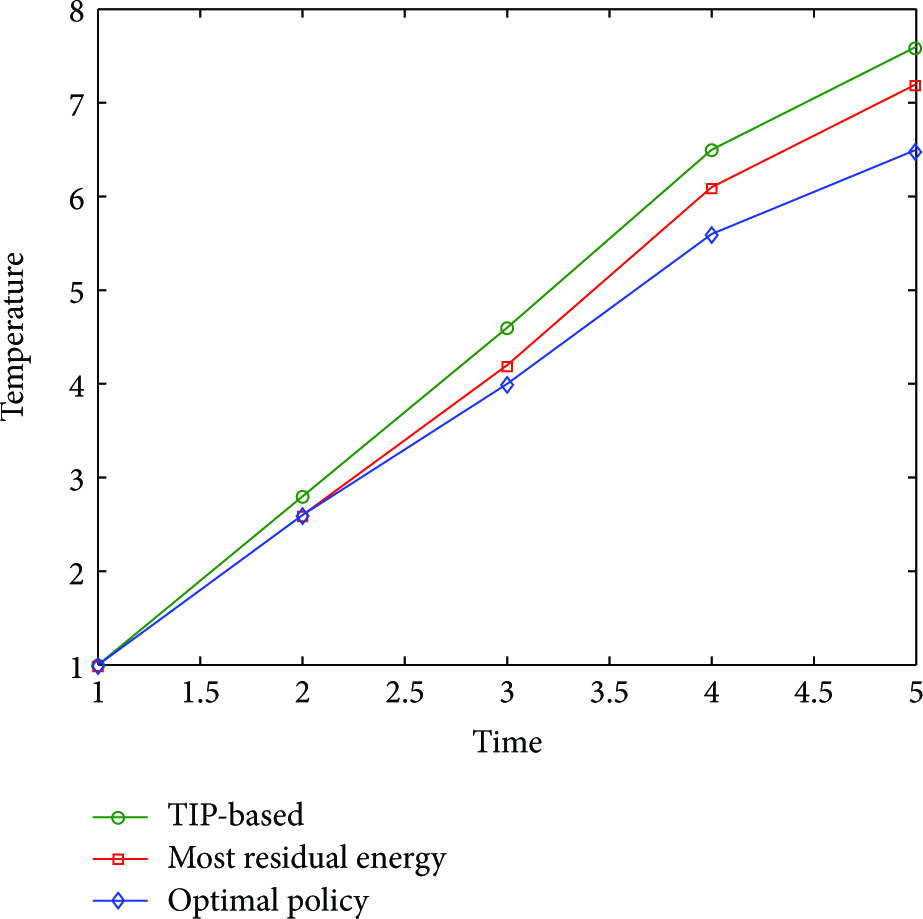
Temperature at biosensor 2 for the different policies.
Both the most residual energy and optimal policies give a significant improvement over the TIP-based policy. The performance of the two policies is slightly the same over the first two time slots. Then, the optimal policy shows a lower temperature increase over the remaining time slots.
The previous observation is very interesting since the goal of the TIP-based policy is to give a minimal temperature increase rotation sequence. However, since the wireless channel and its dynamics are not taken into account, the precomputed rotation sequence will most probably lead to a larger temperature increase when implemented in practice.
7. Conclusions and Directions for Further Research
The future of BWSNs is bright. However, much remains to be done to define the full potential of this technology. In this paper, we have taken one step further in understanding the thermal management problem in BWSNs. The problem is modeled as an MDP to obtain an optimal operating policy for the network. Further, the aggregation of final valid and terminating system states is proposed as a way for minimizing the number of states in the proposed MDP model. The equivalence of the reduced MDP model is established. Also, numerical results show a substantial reduction in model size which is obtained by aggregating just two types of system states. The optimal policy produced by the MDP model outperforms the policies based on the most residual energy and temperature increase potential. This is because the optimal policy gives the best balance between transmission energy consumption and the resulting temperature increase.
The following directions for further research are suggested. First, the notion of state equivalence used in this work is too strict and too sensitive. It is too strict because it requires that its conditions be met exactly. And, it is too sensitive because any perturbation of the transition probabilities can make two equivalent states no longer equivalent. More flexible metrics for state equivalence are needed. The works in [16, 17] can be used as a starting point. Second, in some applications like ours, the state transition probability matrix is built programmatically. This means a runtime which largely grows with the number of system states and thus state aggregation might not always be helpful. Hence, approximate techniques based on reinforcement learning are recommended (see [8–12]). Third, the possibility of obtaining effective policies based on simple heuristic techniques should be investigated. Heuristic techniques are typically characterized by their low runtime and storage requirements.
Footnotes
Acknowledgment
The first author would like to acknowledge the financial support of King Fahd University of Petroleum and Minerals (KFUPM) while conducting this research.