
Abstract
Few studies have researched the temporal and spatial effects of insufficient exposure of sensors in mobile phone sensing. In this paper, the missing data problem in mobile phone sensing is addressed by using a hybrid approach to design an estimation model. This estimation model reflects the effects of participatory and opportunistic nodes based on the success probability model. The proposed model considers the spatial and temporal correlation of sensing data to accurately estimate the missing information. By applying the linear regression and linear interpolation models to sample data from neighboring nodes of the missing data, the spatial and temporal context can be described. The experiment results show that the proposed model can estimate the missing data accurately in terms of simulated and real-world datasets.
1. Introduction
The emergence of smart phones has changed the vision of mobile sensing research. Smart phones that are each equipped with a powerful computing unit and several sensors can monitor human beings and their environments from a personal level to the societal level [1]. The smart phone is not only a communication device, but also a rich set of embedded sensors that enables the use of new applications across a variety of domains like homecare, healthcare, social networks, surveillance systems, environmental monitoring, and transportation [2]. Various sensors like a digital compass, gyroscope, GPS, accelerometer, and microphone are increasingly included in the smart phone as sensor technology rapidly develops.
There are two types of sensing approaches in mobile phone sensing systems: participatory sensing and opportunistic sensing. In participatory sensing, people continuously coordinate the sensing system to meet the requests of applications and make critical decisions on sensing location, target, and data [3]. This system simplifies complex operations by leveraging the intelligence of the person and guarantees high data quality through actively engaging users in data collection. Participatory sensing, however, brings burden to the user and needs a reinforcement mechanism to encourage user activity. These features make it difficult to achieve large scale sensing [4]. In opportunistic sensing, data collection is automated without user involvement [5]. This approach relieves the burden from the user to support the system and increases the scale of applications and sensing field. The users do not need to be preoccupied with the sensing stage, but system designers should carefully build a system that is only activated if predefined conditions have been satisfied. Opportunistic approach has low data quality and high data-missing rate because it does not guarantee sufficient exposure time for sensors.
In the opportunistic approach, missing sensing data is inevitable in terms of the temporal and spatial context. The Wireless Sensor Networks (WSNs) nodes are homogenous and stationary, whereas users move dynamically and monitor different target area during each sensing period in mobile phone sensing. These features cause severe missing data problem as shown in Figure 1.

The missing data problem in opportunistic sensing.
To address the missing data problem, many studies that propose estimation algorithms for the missing data have been conducted in WSNs. These algorithms cannot be applied to mobile sensing systems, because they focus on energy efficiency decreasing data accuracy even though mobile phone sensing is different from typical WSNs in many aspects. For instance, sensing data is affected by its activity, and people carry several types of devices for different uses. Therefore, a new hybrid approach to improve data quality of mobile phone sensing based on the temporal and spatial context is suggested. In the proposed scheme, participatory and opportunistic approaches are combined to collect consistent sampling data that can be used to accurately estimate the missing data. Participatory nodes that continuously monitor certain target fields with high accuracy provide the spatial aspect for opportunistic nodes and the temporal aspect for the sink node. The main contributions are as follows.
Developing a new estimation model based on the spatial-temporal correlation to improve the accuracy of estimating the missing data for the mobile phone-sensing system. Applying the success probability model of the participatory and opportunistic sensing to the estimation model. Presenting comprehensive experimental evaluation of the approach by showing that the proposed model can improve the accuracy of estimated values in terms of the simulated and real-world datasets.
This paper is organized as follows. Section 2 presents related works, Section 3 describes the algorithm design of the hybrid approach, and Section 4 details the evaluation results. Finally, concluding remarks are given in Section 5.
2. Related Works
Missing data estimation algorithms have been studied in WSNs. Most of the research tried to reduce the energy consumption of sensor nodes that have limited processing power and resource constraints. In [6], the authors proposed a tree-based data aggregation algorithm to minimize the size of transmitted data and the number of messages. The missing data of a child node is estimated by its parent node which stores the previous data of child nodes. The algorithm in [7] schedules the active time of each node to achieve the energy efficiency and infers the missing data from awaking sleep nodes that are adjacent to the missing data area. It is inevitable to decrease the data quality because the accuracy of this algorithm based on Bayesian inference depends on the reliability of observations. Papers [8, 9] proposed the probability-based algorithms to estimate the missing data in an energy-efficient manner by using a pairwise Markov Random Field and an adaptive prediction model, respectively. The estimation process operates on a cluster head or a coordination node. These algorithms that are designed to avoid a cluster head to request additional information from its member nodes decrease the energy consumption. The authors only focused on improving the energy efficiency by reducing the data transmission in [10, 11]. They took advantage of the temporal and spatial correlation of sensing data to detect notifications of the same event due to the high density of sensor nodes. The missing data is just replaced with the value of a nearby node or ignored. Orchis that is a consistency-driven data quality management framework was proposed to integrate the data quality into an energy-efficient sensor system design [12]. The authors measured the data consistency with the error between the real value and the estimated value at the sink. Each sensor node calculates its data consistency and compares its result to the threshold that is defined by a user according to applications. The node sends its data to the sink node only if the error is bigger than the predefined threshold value.
There are other approaches to improve the accuracy of estimated value in difference view. We classified these approaches into four types such as physical, temporal correlation, spatial correlation, and spatial-temporal correlation model. The physical model uses physical laws for data estimation. For example, estimating values of land surface temperature uses the relationship between altitude and temperature or approximating noise uses the noise attenuation by the distance. In [13], the authors proposed the estimation model of light intensity by using the inverse square law that defined the light intensity (I) as
The temporal correlation models use historical information or data freshness to estimate the missing data. The authors in [15] proposed the slide-window-based estimation model. They designed a data cube to keep track of all existing datasets in each round. The cube implemented the sliding window concept by storing data for the last w rounds. The newest data is stored at the front of the cube, and the oldest data is stored at the back of the cube. The size of the sliding window (w) which is a dynamic parameter changes as per the requirements of applications. This approach applies the Apriori algorithm [16] to datasets in the cube to estimate the missing value. Freshness Association Rule Mining (FARM) was an estimation scheme based on a weighted average of the current reading of neighbor nodes near the missing area in [17]. To consider the freshness of data in estimation process, they used a simple weigh function as
Kriging [18] estimates the missing data by calculating the spatial correlation between two points. The localized spatial interpolation is derived from the variogram model. This model is devised to obtain weights for linear combination and these weights vary spatially. The authors in [19] proposed a sparsity-based recovering method that can capture the spatial variation without requiring the knowledge of the historical spatial correlation. They tried to find how to choose an appropriate Discrete Cosine Transform (DCT) dictionary to reduce estimation errors in the regular grid sensor networks. In [20], the authors proposed a K-nearest neighbor-based missing data estimation algorithm called the Applying K-Nearest Neighbor Estimation (AKE). AKE adopts the linear regression model to describe the spatial correlation of sensor data among different sensor nodes. It utilizes the information of neighbor nodes near the missing data area to estimate values jointly. These spatial models are practical solutions, but they are easily affected by the topology and density of sensor nodes.
The spatial-temporal correlation model has researched to address the problem of the temporal or spatial model. The algorithm in [21] uses the Markov model to learn a time series and the fuzzy model to detect the spatial correlation. In order to deal with the missing data, this algorithm finds neighbor nodes within the sensing range and the missing data is replaced with its neighbor's value. If there is no neighbor node, the missing data is replaced with the previous value. In [22], the authors suggested a matching function between three strategies and several estimation models to minimize the error of estimation values. Three strategies include finding the best couple, calculating weighted average (Single Input and Single Output), and inferring from multiple inputs (Multiple Inputs and Single Output). They also designed the dependency graph that considers the communication delay among sensor nodes to evaluate the temporal correlation. The authors in [23] proposed a multisensor vector tree based on the Prediction History Tree (PHT) Algorithm [24] for error correction in WSNs. This algorithm reinforces the PHT that emphasizes the temporal correlation of the sensing data to achieve the balance between the temporal and the spatial correlation. It assigned the predicted value calculated by the autoregressive model and the observed value to the entry of the PHT. If the observed value contains significant error or is missed, the prediction value is sent to the sink node. These spatial-temporal models presume that the sensing data is highly correlated in time and space. This condition is satisfied when the target field is small and the sensor nodes are deployed densely. In the proposed model, we consider not only the spatial-temporal correlation, but also the reliability of sensor nodes in terms of the participatory and opportunistic sensing to improve the accuracy of the estimated value.
3. Algorithm Design
3.1. A Hybrid Approach
In [25], the authors conducted a simple success probability experiment of participatory and opportunistic sensing to prove that opportunistic sensing is more superior to participatory sensing in a large scale. As shown in (1), we modified their idea so that

Parameter list.

Figure 2 shows the probability of success of two approaches as the context match probability of the opportunistic sensing decreases and the number of smart phones increases. In the case of the participatory model, the success probability converges to 80%. For the opportunistic model, the success probability is below 50% when the difference between the context match probabilities of the two approaches is more than twice the value. This means that we cannot collect accurate sensing data if we build the opportunistic system without support from the participatory system.
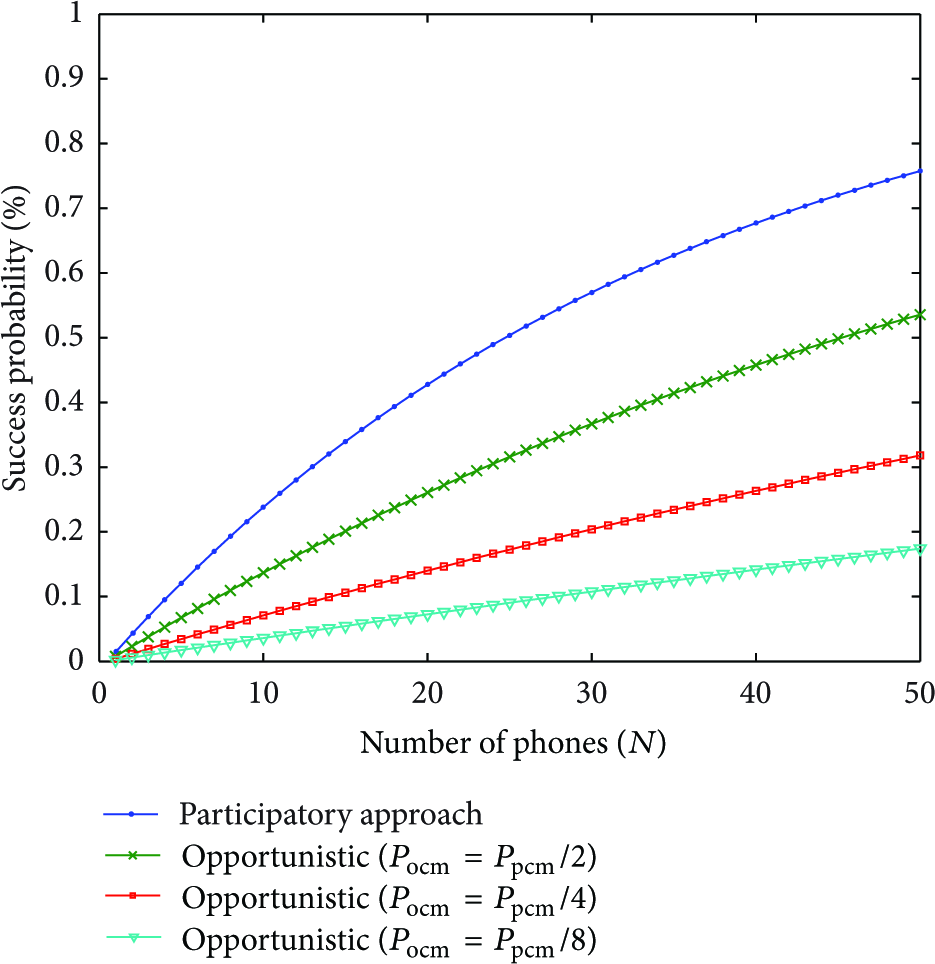
The success probability of two approaches.
An important issue for designing the hybrid approach is recruiting the proper participants. It is difficult to find individuals willing to collect data about a particular phenomenon. There are various factors involved in this recruitment service such as device capabilities, geographic and temporal coverage of participants, and their social networks. The problem becomes more complicated when we consider the overall costs associated with managing the participants. In order to address this problem, the author in [26] proposed a recruitment framework to enable a system designer to identify well-suited participants for data collection based on geographic and temporal availability as well as participation habits. Solving the recruitment of participants is out of the scope of this paper, even though it was utilized in the hybrid approach. Therefore, we assume that this mobile-sensing system can secure enough participatory users that are sufficiently qualified to monitor the target field.
The pseudocode of the algorithm that describes the proposed hybrid approach is shown in Algorithm 1. The opportunistic nodes send a data tuple that is composed of its identification, temporal and spatial information, and sensing values (
Notation: (1) (2) (3) (4) CALL Estimation method ( (5) (6) (7) Add (8) (9) send
(11) send (12)
3.2. Estimation Model
We devised the spatial-temporal estimation model to estimate the missing data in our hybrid approach. Table 2 shows the notations used for designing our estimation model.
List of notations.

The proposed model for estimating the missing data is designed by considering the temporal (
The temporal model based on historical information uses the linear interpolation model as shown in (3). Each neighbor node near the missing data calculates its variation between each round. If some opportunistic nodes do not have the previous sensing value, they send the current round's sensing data to a participatory node. The participatory node calibrates these opportunistic nodes' data by using the previous sensing data stored in storage or requesting this information from the sink:
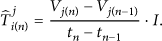
We also designed the spatial model based on AKE [20] as shown in (4). The AKE using the linear regression model focuses on the spatial correlation more than the temporal correlation and is designed for WSNs. We modified its paring method and weight function to adapt to the mobile phone-sensing environment and our hybrid approach. The accuracy of this model is critically affected by pared data. If inaccurate data is frequently included in pared data, the accuracy drops dramatically. During the paring phase, the proposed estimation model gives more priority to the sensing data from participatory nodes and the closest node in the area of the missing data:

Our weight function has a similar concept in terms of the temporal and spatial context. The proposed estimation scheme can assign the proper weights to the corresponding estimated values that were calculated in different neighbor nodes. The three criteria are whether the estimator is an opportunistic node or a participatory node, the distance between the estimator and the missing data area, and the error of the estimated value. As these three criteria increase, the weight decreases because the error probability of the estimated value is high:

4. Experimental Results
We compared the proposed model with the previous works based on the average model, temporal model, the spatial model, and the regression model, respectively, by using real-world dataset (Intel-Lab data, http://db.csail.mit.edu/labdata/labdata.html). The dataset provided by Intel Berkeley Research Laboratory contains data collected from 54 sensor nodes that monitored light, humidity, and temperature. We added the location information of each node to this dataset to assign the weight as the distance between the missing data area and its neighbor nodes.
Figure 3 shows the average error of each model as missing data rate increases. In the physical model, the average error fluctuates as the missing data rate or the number of rounds increases, because the estimation value of the missing data is calculated by the predefined method without cooperating with its neighbor nodes. If the environment condition severely changes and the target field space is enlarged, the error range fluctuates more. In the temporal model, the average error is stable but the error accumulates as the number of rounds increases, and the error range depends on the sensing interval. In the spatial model and AKE that use the neighbor nodes' data, the error range changes dramatically according to the accuracy of the estimation algorithm and node density. Our scheme that considers the temporal and spatial context shows stable results and high accuracy.

The average error of each model (sensing interval = 5 min, the number of rounds = 10).
We also simulated our hybrid approach on the SIDnet-SWANS simulator that supports various models of phenomena and discrete event operation as shown in Figure 4 [27], to verify its adaptability to mobile phone sensing. Additionally, Table 3 describes our simulation environments.
Simulation environments.

SIDnet-SWANS snapshot.
The error probability of estimation value between our hybrid approach and opportunistic approach is shown in Table 4. A uniform deployment that can fix the number of neighbor nodes evenly is more accurate than random deployment. The results of the proposed hybrid approach show that it is more stable and accurate than the opportunistic approach. If the number of participatory nodes in the estimation of the missing data area is larger, the accuracy is higher. In the opportunistic approach, the error probability of the estimation value is higher in some spots like the missing area surrounding opportunistic nodes and the hat spot where the sensing value is much higher than its neighbor areas.
The average error probability of estimation value between the opportunistic approach and the proposed hybrid approach.

Figure 5 shows the error rate of two approaches in the uniform and random deployment when rounds increase. The error rate is represented as

The error rate while increasing rounds ((a) uniform deployment/(b) random deployment).
The error rate increases if the missing data rate increases as shown in Figure 6. Increasing the missing data rate means that the size of the missing data area is enlarged, and it is difficult to collect accurate data from its neighbor nodes. The error rate of the opportunistic approach increases dramatically, but the error rate of our approach increases steadily as when the number of participatory nodes increases. The effect of participatory nodes is higher in the uniform deployment than the random deployment. Therefore, we deploy participatory nodes evenly in the target field to improve the accuracy of the estimation value of missing data.
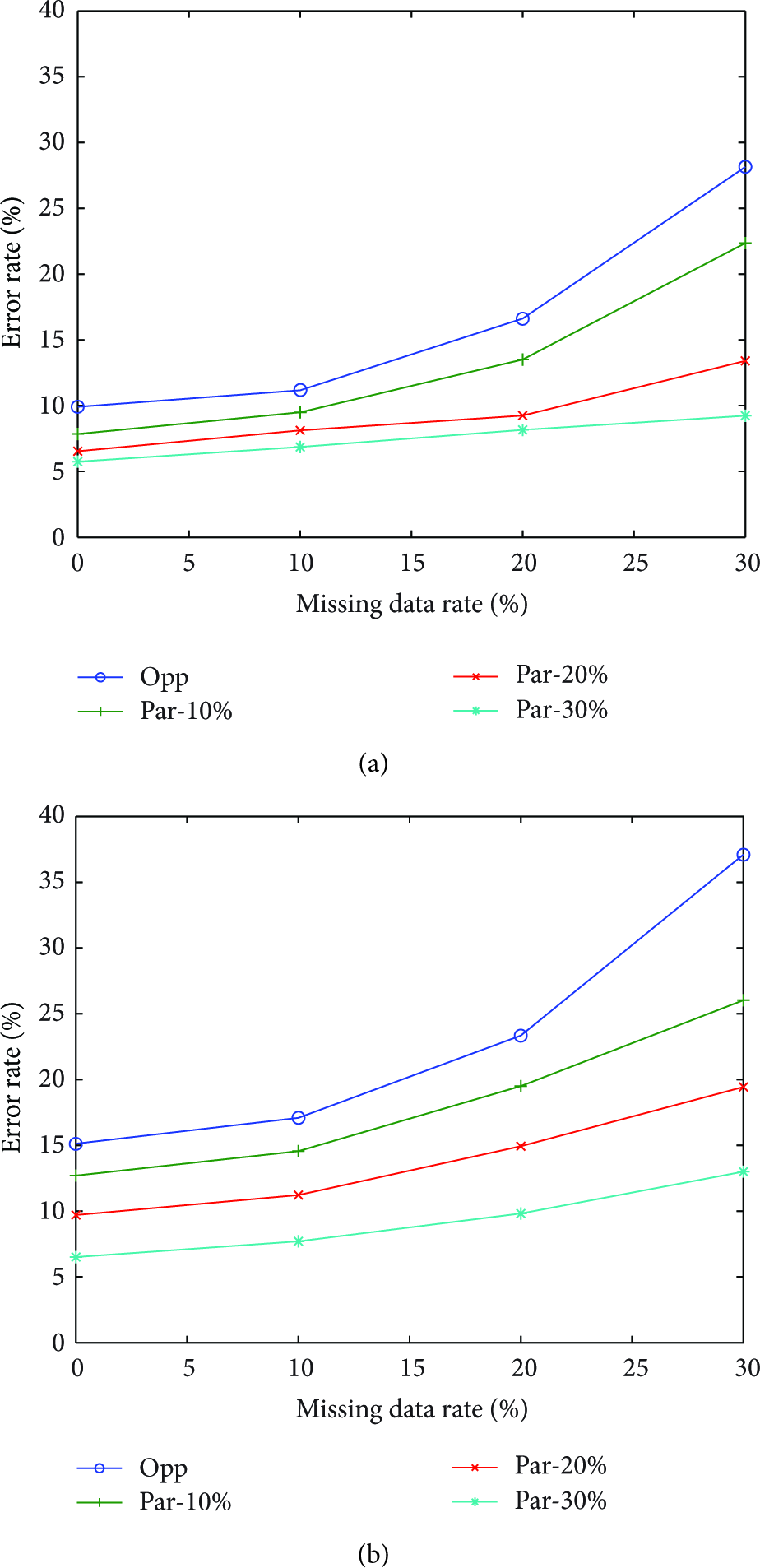
The error rate while increasing missing data rate ((a) uniform deployment/(b) random deployment).
Figure 7 shows the relationship between the error rate and the node density. The error rate decreases sharply as the number of mobile phones increases in both approaches. The node density has a crucial effect on the estimation model based on the spatial context. The opportunistic approach has the reasonable error rate if it supported by a large number of nodes. However, it is difficult to secure enough mobile users to gather accurate data. Therefore, we should uniformly deploy participatory nodes near missing data areas.

The error rate while increasing the number of mobile phones ((a) uniform deployment/(b) random deployment).
Figure 8 shows the relationship between the error rate and the weight parameter between the temporal and spatial context (α). If α is close to zero, the estimation model only reflects the spatial aspects, while if α is close to one, the estimation model only considers temporal aspects. In the case of uniform deployment, the accuracy is more stable than in random deployment because it shows the same trend when the number of participatory nodes increases.

The error rate as increasing the weight parameter (α), ((a) uniform deployment/(b) random deployment).
5. Conclusions
Smart phones that are equipped with various types of sensors have changed the mobile-sensing system. These changes can improve human life in diverse fields such as security, healthcare, social networks, e-commerce, and transportation. There are many studies that research the system architecture and its application, but few studies consider data accuracy. In this paper, we proposed a new estimation model based on the spatial-temporal correlation to improve the accuracy of the estimated missing data for the mobile phone-sensing system. We applied a hybrid approach that considers the success probability model of the participatory and opportunistic sensing to our estimation model. The experimental results showed that our estimation algorithm can improve the accuracy of estimated values. However, these experimental results highly depend on limited datasets like temperature and humidity. To solve this problem, we need to collect various real-world-sensing datasets. Since mobile phone sensing is a recent research issue, it is difficult to collect enough data for various sensing sources. In the future, we want to keep maintaining these precious datasets and protect the privacy of collected data.
Footnotes
Acknowledgments
This research was financially supported by Hansung University. This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (NRF-2011-0013774).