
Abstract
The deployment of anchor nodes (or beacon nodes) is a key element in the design of range-free localization schemes for wireless sensor networks (WSNs). The majority of range-free localization schemes deploy numerous anchor nodes within the monitored region. However, in certain cases (e.g., hazardous areas), it may not be possible to manually install anchor nodes within the monitored region of a WSN. In this study, very few anchor nodes are installed at the boundary of a WSN monitored region to estimate the locations of unknown sensors. The locations of the unknown sensors are estimated based on the minimum hop counts to the anchor nodes. The average hop distance is estimated by applying parameters derived from prior experiments. The simulation results show that the range error of the proposed localization scheme can be as low as 0.15. The localization accuracy, computation cost, and communication cost of the proposed scheme are compared with those of the well-known DV-Hop method.
1. Introduction
Wireless sensor networks (WSNs) have recently received unprecedented attention due to their potential wide-ranging applications such as military surveillance, healthcare, home automation, tracking, and habitat monitoring. A WSN consists of a large number of small and inexpensive smart sensors working collaboratively to achieve a common objective and one or more sinks (or base stations) collecting data from all sensor devices. Sensors are being deployed to monitor or disseminate information of various environmental or physical conditions, such as sound, temperature, motion, pressure, pollutants, and vibration.
The energy consumed for transmitting a wireless radio signal is in proportion to the square of the distance, or even a higher order if the environment contains hindrances. Thus, in a WSN, multihop routing is usually considered as an alternative to direct communication for transmitting data to the sink. The majority of WSN routing algorithms count on knowledge of the precise location of each sensor. However, for specific hazardous environments, it is hard to measure the positions of sensors manually. Fortunately, various localization techniques can be used to estimate the locations of sensors. Perhaps the most popular localization approach is to install the GPS on the sensors in a WSN. Despite the declining cost of GPS receivers, they remain too cost- and energy-inefficient for installing in a WSN. Therefore, other techniques need to be developed for localization problems in WSNs.
There are two general classes of WSN localization technology: (1) range-based approaches and (2) range-free approaches [1]. Range-based approaches require sensor nodes to be positioned using additional devices, such as directional antennas, ultrasonic detectors, antenna arrays, and signal-strength receivers. By contrast, range-free approaches do not rely on any extra hardware for additional information. Rather, they depend solely on the basic properties of sensor nodes, the network connectivity, and the information of their direct neighbors.
An established range-free localization method called the DV-Hop method was proposed by Niculescu and Nath in [2]. The DV-Hop method is based on classical distance vector exchange from general packet-switched network protocols. In DV-Hop, anchor nodes flood their positions to all nodes in the network. Each node computes the minimum distance in hops to every anchor node. Anchor nodes compute an average distance per hop (i.e., hop size) to other anchors. The hop size of each anchor is then flooded to the whole network to facilitate unknown sensors to compute their positions. Each unknown sensor estimates the distances to their respective neighboring anchors based on the number of hop counts and the hop size of the anchor with the smallest hop count. The unknown sensors subsequently multilaterate their positions based on the estimated distances to their nearest neighboring anchors.
Different from the DV-Hop, the MDS-MAP [3] method uses the hop count to construct a proximity matrix as a relative map by the multidimensional scaling technology, and it then obtains absolute locations by some linear transformation. There are three major steps in the MDS-MAP. The first step is to form the distance matrix with distances between all pairs of nodes in the network. In the absence of anchors, the distance is obtained by multiplying the hop count with the radio range. In the second step, singular vector decomposition (SVD) is performed to get an initial relative map of the nodes in the monitored region. The last step performs some linear transformations according to the distances between anchors whenever applicable. Otherwise, the relative map would be the result of SVD. The time complexities of the first two steps are
APIT [4] employs an area-based approach to perform location estimation by dividing the monitored area into triangular regions between anchor nodes. Each unknown node runs the point-in-triangle (PIT) tests to find the triangle regions it resides in. However, it is hard for the unknown nodes to perform the exact PIT test. The authors presented an approximate PIT test, in which the node is only required to be able to determine whether any one of its neighbors is farther or closer to all of the three anchors that form its residing triangle. For better localization accuracy, the suggested degree of connectivity should be greater than six, and, in order to improve accuracy, APIT assumes that the anchors have radio ranges that are 10 times larger than those of ordinary nodes.
Localization refers to the ability of determining the position (absolute or relative) of an unknown sensor node, with an acceptable accuracy. The estimation accuracy of unknown sensors is usually affected by the location of anchor nodes. Numerous studies have examined the influence of anchor positions on the estimation accuracy of unknown sensor nodes [5–8]. In [7], the authors sought to identify anchor locations that would obtain the highest accuracy for all target sensor node positions. They selected anchors that offered the minimum of the mean Cramér-Rao bound (CRB). They studied the optimal anchor positions for three to eight anchors in the following two noise models: (1) the additive noise model (aNm) and (2) the multiplicative noise model (mNm). The authors concluded that the CRB achieved the lowest mean when the anchors were located equidistantly at the boundary of a square region for four and eight anchor nodes.
In [8], the authors installed four anchors in an 8 × 8 square region to estimate the location of unknown sensors by using a multihop setup, where neighboring nodes with unknown positions assisted other nodes to estimate their locations by acting as anchor points. They concluded that the anchor nodes should be installed at the perimeter of the network so that their proposed localization algorithms can have minimal variance of the mean error bounds.
This study proposes a low-cost and an effective localization scheme for WSNs. The scheme requires fewer than 16 anchor nodes placed at the boundary of a monitored region. The location of each unknown sensor is estimated using bilateration (employing two anchors) or multilateration (employing more than two anchors). For multilateration, we equidistantly installed the anchors at the boundary of the monitored square region. The distances between unknown sensors and anchor nodes are estimated based on their minimum hop counts, instead of applying noise models.
This study shows that additional anchor nodes increase the accuracy of location estimation. However, the accuracy ratio converges when the number of anchor nodes reaches a certain threshold. This study also provides a performance comparison, including communication cost and computation cost, between the proposed scheme and the DV-Hop method to demonstrate the superiority of the proposed scheme.
The remainder of this paper is organized as follows. Section 2 introduces a mechanism for estimating the distance of each unknown node to the anchor nodes, and Section 3 details the proposed localization scheme. Section 4 proposes two anchor placement strategies and compares their performance. Section 5 provides simulations of the proposed localization scheme and a comparison of its performance with the DV-Hop method and some renowned schemes. Lastly, Section 6 offers a conclusion.
2. Distance Estimation of Unknown Sensors
In the proposed localization scheme, few (i.e., 2–16) anchor nodes are installed at the boundary of a monitored square region to estimate the positions of unknown sensors. Two major stages are conducted to locate the unknown sensors.
Preliminary Stage
Obtain the minimum hop counts from the unknown sensors to each anchor node. Estimate the distances between the unknown sensors and the anchor nodes based on their corresponding minimum hop counts.
Localization Stage. Apply bilateration (i.e., for two anchors) or multilateration (i.e., for 4–16 anchors) to estimate the position of the unknown sensors.
This study assumes that (1) the network is connective (the theoretical expected number of local neighbor nodes to ensure connectedness is between 2.195 and 10.526, and simulation experiments suggest at least 5 [9]), (2) sensors are uniformly distributed in the monitored region, and (3) all sensors are homogeneous.
We extend the distance estimation method proposed in [10] from two anchor nodes to k (
2.1. Obtain the Minimum Hop Counts from the Unknown Sensors to Each Anchor Node
Suppose that there are k anchor nodes, where k ranges from 2 to 16 (the influence of the number of anchor nodes is discussed in Section 4), and each anchor node is initially allowed to broadcast a Hello packet to its neighbor nodes. The Hello packet consists of the following two fields: (1) Min_hc (minimum hop count to the source node), which is initialized at zero, and (2) the source anchor node ID.
Each sensor stores a k-tuple vector (
After completing this procedure, each unknown sensor obtains the minimum hop-count value to each anchor node. The values in each unknown sensor are denoted as a k-tuple (
2.2. Estimate the Hop Distances between Unknown Sensors and Anchor Nodes
Let n be the total number of sensors, let CR be the communication range of each sensor, and let w be the length of the monitored square region. The probability that sensor v is within the communication range of sensor u is
According to [12], the probability of a message flooding along the straight-line path between nodes is ≥0.85 if the number of expected neighboring nodes is ≥15. Therefore, in the same example, if
The average hop distance between sensors is determined by the node density and the communication range of the sensors in the monitored region [10–12]. When the node density is high, each sensor may have a larger number of neighbor nodes. Therefore, it is very likely that some sensor nodes are located at the edge of each one-hop broadcast boundary of an anchor node. As shown in Figure 1, in this extreme case, there always exist sensor nodes at the edge of the one-hop broadcast boundary of the sink. Therefore, under this circumstance, the maximum distance of an unknown sensor to the sink with minimum hop count m is

An extreme case of sensors (red nodes) routing with minimum hop count to the sink along straight-line paths (the dotted lines).
Observation 1.
Let CR be the communication range. If messages are forwarded along straight-line paths, the maximum distance of an unknown sensor with minimum hop count m from the sink is
The other extreme case happens when the node density is low and each node has a small number of neighbors, yet the network remains connective. As shown in Figure 2, sensors are pairs located proximally to the edge of the one-hop broadcast boundary of the sink. The first node in each pair is within the scope of the second node of the preceding pair, but it is immediately outside the scope of the first node of the preceding pair. At the same time, the second node in each pair is immediately outside the scope of the second node of the preceding pair.
For example, in Figure 2,
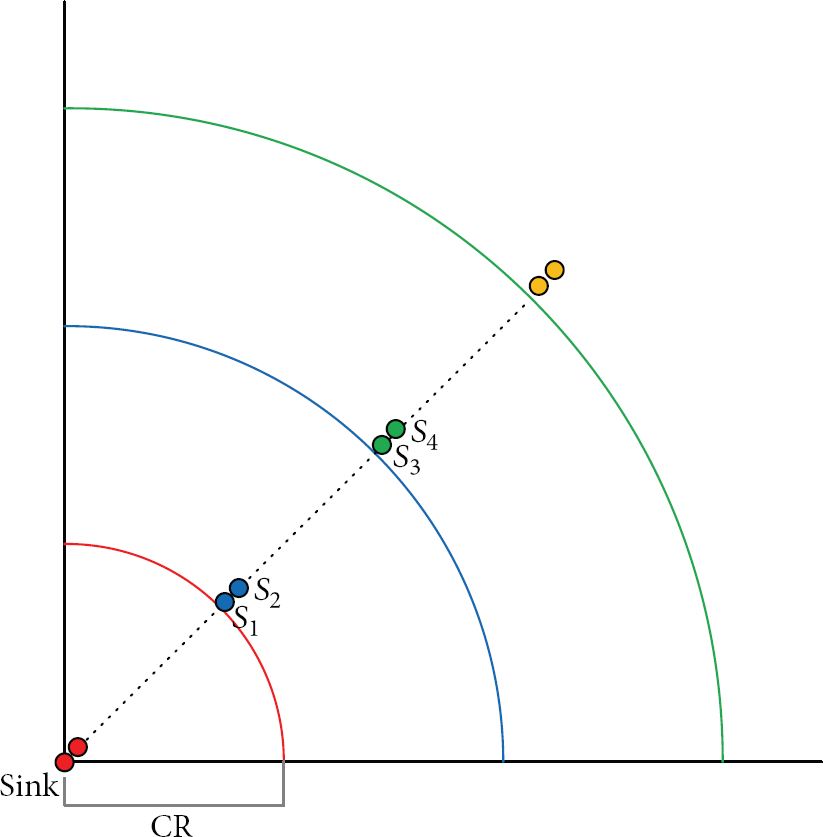
The case of minimum distance to the sink when the forwarding of messages is along a straight line, in which sensors are pairs located proximally to the edges of the one-hop broadcast boundaries of the sink.
Observation 2.
Let CR be the communication range. If messages are forwarded along straight-line paths, the minimum distance of a sensor with hop count m from the sink is
From Observations 1 and 2, we conclude that if packets are forwarded along a straight-line path, the distance from any sensor with minimum hop count m to the sink is between

3. The Localization Scheme
In this study, 2–16 anchor nodes were used to estimate the positions of unknown sensors. For the WSNs that require coarse-grained localization, the bilateration localization method (BLM) is applied. The BLM, which was introduced by Chen et al. in [10], uses only two anchor nodes and employs a basic geometry property—the intersection of two circles—to estimate the position of an unknown sensor. For the WSNs that require fine-grained localization, the least-squares multilateration localization method (LSMLM) with 4 to 16 anchor nodes is applied based on the Newton-Raphson method.
3.1. Bilateration Localization Method
In the BLM, only two anchor nodes are used to estimate the location of unknown sensors. The two anchor nodes are installed at the lower-left (Sink X) and lower-right (Sink Y) corners of a monitored square region (Figure 3).
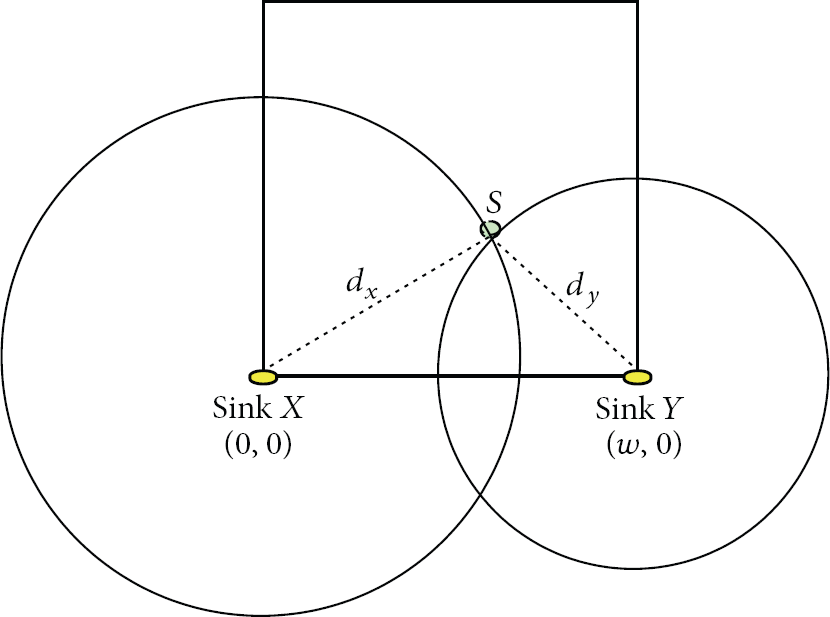
Two sinks are located at the lower-left corner and the lower-right corner, respectively, of the monitored region.
Suppose that Sink X is installed at (0,0) and Sink Y is installed at

Thus,
Because the unknown sensor S is located in the first quadrant of the Cartesian coordinate system, only the positive solution of y can be taken. Therefore, the coordinate of sensor S is

Note that, in order to obtain a real solution using (2), the following inequality should be stratified:

This constraint will be considered when estimating
3.2. Least-Squares Multilateration Localization Method
Although the BLM is appealing because the number of required anchor nodes is very small, the range error (defined in Section 4) of localization is slightly high. To reduce the error rate of localization, in this study, additional anchor nodes (from 4 to 16) were added to the localization scheme. The LSMLM is used to estimate the locations of the unknown nodes. In the following subsections, the mathematical background of the LSMLM is detailed, and a common least-squares solver is offered.
3.2.1. Multilateration of Newton-Raphson/Least Squares
Given k nodes with known Cartesian positions


Expression (5) can be solved using Newton-Raphson/least squares, described in [13], as follows. First, approximate the error function

Next, substitute this approximation into (5):
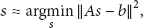
Stacking the terms yields
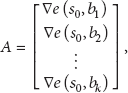


The right side of (8) is suitable for being solved using an off-the-shelf least-squares solver. If
The multilateration method is summarized as follows.
Step 1.
Estimate the distance
Step 2.
Select

Step 3.
Step 4.
Compute
Step 5.
If
3.2.2. Least-Squares Solver
To solve the minimization problem of Step 4 in the previous multilateration method, an expression for the square of the Euclidean norm on

Regarding (12) as a function of x, to minimize this expression, we need to set its gradient to zero:

Equation (13) is called the normal equation for the linear least-squares problem. This equation has a unique solution provided that all of the columns of matrix A are linearly independent. Various methods can be used to solve (13), for example, Cholesky decomposition or QR factorization (by directly substituting
4. Anchor Node Placement Strategies and the Determination of α Values
In this section, the anchor node placements associated with the values of α in (1) for distance estimation are evaluated through experiments, and the best selection of the α value is recommended for each condition. Two anchor node placement strategies are compared according to their range errors of various localizations. The range error is defined as follows:

The term α is a parameter used to estimate the distances of each unknown sensor to the anchor nodes in (1). The value of α can be regarded as the ratio of the estimated hop distance to CR, and it depends on the node density, the CR values, and the locations of anchor nodes.
For the BLM, the two anchor nodes are installed at the bottom-left and bottom-right corners. However, for the LSMLM, the number of anchor nodes is from 4 to 16. What are the best installation positions for these anchor nodes in order to obtain the most accurate estimation of the locations of unknown sensors?
According to [8], the authors suggested that the anchor nodes can be installed at the perimeter of the sensor network in order to reduce the variance of the mean error bound. In this study, we compare the performance of two strategies for the installation of anchor nodes. The first strategy is randomly installing the anchor nodes in the monitored region.
The second strategy is installing the anchor nodes equidistantly at the perimeter of the monitored square region. Figure 4 shows the deployments of the anchor nodes, where LSMLM-k denotes the LSMLM with k anchor nodes. To the best of our knowledge, no formula exists that can be used to calculate the exact value of α. Therefore, the values of α were determined through experimentation in this study. The values of α were tested from 0.1 to 1.0 in 0.1 increments to compute the location error of the BLM (node number = 2) or the LSMLM (node number = 4, 8, 12, 16) for each deployment. Table 1 presents the α values that produce the lowest location error for each combination of the node density and the communication range for 500 deployments. The node density in Table 1 is defined as (number of sensors/area of monitored region).
The best selection of α values for different numbers of anchors under various node densities and communication ranges.


The deployment of anchor nodes (the yellow ovals) of BLM and LSMLM-k, where k = 4, 8, 12, and 16, in a 200 m × 200 m region.
As shown in Table 1, the majority of α values are between 0.6 and 0.8, except for the cases that both the node density and the communication range are very low (i.e., number of nodes ≤ 400 and
Figure 5 shows the simulation results of the two anchor placement strategies. In the figure, LSMLM-k-RND is the LSMLM with k anchor nodes which are randomly deployed in the monitored region, and LSMLM-k is the LSMLM with k anchor nodes which are installed equidistantly at the perimeter of the monitored region. The experiments are conducted under the communication range

Comparison of the range errors of the two anchor placement strategies under
It is easy to see that the range errors of the perimeter installation strategy are smaller than those of the random installation strategy under the same number of anchor nodes. Therefore, in the following, we only consider the cases that install the anchor nodes at the perimeter of the monitor region.
5. Performance Analysis of the Localization Methods
In this section, the computation cost and the communication cost of the BLM, LSMLM, and DV-Hop are measured. These methods are simulated separately, and their range errors are compared.
5.1. Performance Analysis
This section presents a performance analysis of the proposed methods. Subsequently, these methods are simulated separately, and their range errors are compared to those of the DV-Hop method.
According to the procedure in Section 3.1, the BLM requires two separate flooding operations initiating from Sink X and Sink Y. Computation of the intersection points of two circles takes constant time and applies only fundamental mathematical operations such as multiplication, addition, and square root.
Similarly, LSMLM-k requires k flooding operations initiating from the anchor nodes for the unknown nodes to attain the minimum hop counts to the anchor nodes. Each unknown node estimates its distance to the k anchor nodes by selecting an appropriate α value from Table 1. The position of each unknown node can be calculated using the least-squares multilateration method in a finite number of steps.
In the DV-Hop method (detailed in Section 1), each beacon node requires one flooding operation for all of the sensors (i.e., both unknown sensors and beacon nodes) to compute the minimum hop count to each beacon node and, meanwhile, for each beacon node to calculate its hop size. Subsequently, an extra flooding operation is required for each beacon node to broadcast its hop size to all unknown sensors. Therefore, the number of flooding operations required for this method is equal to twice the number of beacon nodes. Trilateration is used for each unknown sensor to estimate its position, which requires a variable number of iterations (i.e., from two to hundreds in the conducted experiments) for the process to be converged.
The BLM requires two anchor nodes, and the LSMLM requires <16 anchor nodes, whereas, according to the simulations reported in [2], the DV-Hop method demands at least 20% of the sensors to be anchor nodes to improve the simulation results. Table 2 presents the performance comparison of these methods. The table shows that both the BLM and the LSMLM outperform the DV-Hop method in terms of the required anchor nodes number and the communication cost. The BLM requires only a constant number of simple mathematical operations, whereas both the LSMLM and the DV-Hop method require a variable number of iterations for least-squares multilateration.
Performance comparison of the BLM, the LSMLM-16, and the DV-Hop method (n is the total number of nodes).

In addition to the DV-Hop method, we also compare the performance of several well-established schemes and two recent results (one is hop-count based [15] and the other is bilateration based [16]) for the WSN localization problems in Table 3.
Performance comparison of localization schemes.

n: number of unknown sensors.
m: number of anchors.
In [15], the authors proposed a new source to destination (s2d) distance estimator known as HCNP based on the observation that there exists some correlation between the number of destination's neighbors with hop count
In [16], Cota-Ruiz et al. presented a distributed and formula-based bilateration algorithm that can be used to provide an initial set of locations. In their scheme, each node uses distance estimates to beacons to solve a set of circle-circle intersection (CCI) problems, solved through a purely geometric formulation. The resulting CCIs are processed to pick those that cluster together, and the average is then used to estimate an initial node location.
5.2. Simulation Results
The simulation environment in this study was set up as follows. The monitored region measured is 200 m × 200 m. The communication range was from 20 m to 60 m, and the sensor number was from 300 to 1000 in 100 increments. Sensors were randomly distributed in the region. The corresponding α values were selected from Table 1. Each simulation involved 50 tests, and the mean was used as the final result. All of the methods (i.e., the BLM, the LSMLM, and the DV-Hop method) were simulated using MATLAB R2012a software.
The range error is defined as the average localization errors of all of the deployed unknown sensors divided by the communication range. Figure 6 shows the relation between the true locations of the deployed unknown sensors and their corresponding estimated locations using LSMLM-16 for the case of 300 sensors and

Illustration of true locations versus estimated locations of LSMLM-16 with 300 nodes and communication range 40 in a 200 × 200 area (red dots: true locations; red crosses: estimated locations; blue lines: connections between corresponding true and estimated locations).
Figure 7 shows the range errors of the BLM, the LSMLM-k (k = 4, 8, 12, 16), and the DV-Hop method for various communication ranges and numbers of sensors. As anticipated, under an identical CR, the range error decreases as the number of anchor nodes increases, until the number of anchor nodes reaches 16. The experimental results show that the difference of range errors between LSMLM-12 and LSMLM-16 is within 3% in all cases. This indicates that the error rate converges as the number of anchor nodes approaches 16.
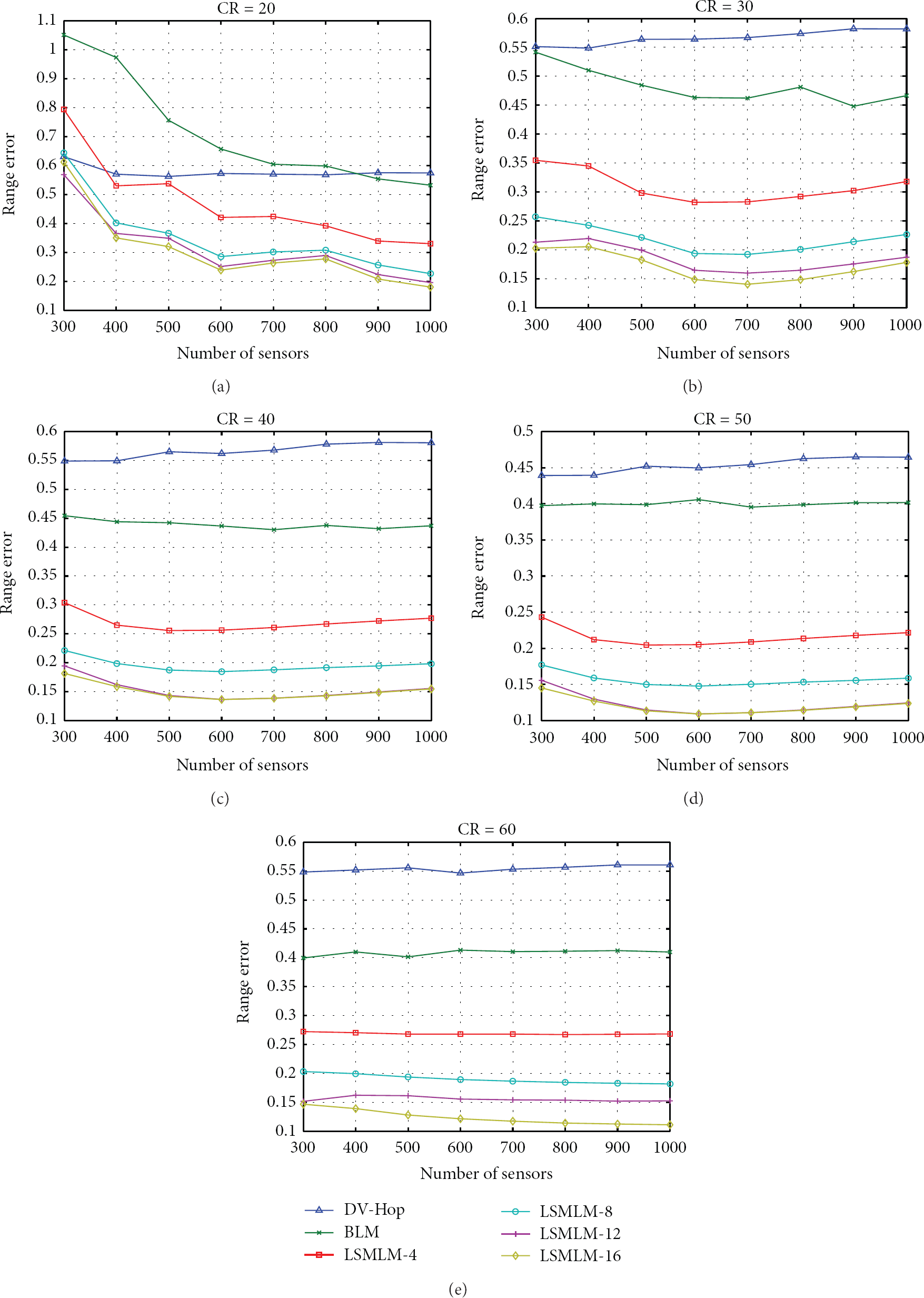
Range errors under different communication ranges (20–60 m) and node densities for BLM, LSMLM, and DV-Hop method.
Note that, in our experiments, we also used 3, 5, 6, and 7 anchors for each case of the different communication ranges. However, we found out that the error rate decreases proportionally as the number of anchors grows until the anchor number reaches 16. In order to show this observation clearly in the figures of experiment results, we only use 4, 8, 12, and 16 to demonstrate this phenomenon, instead of using the whole sequence of numbers.
For the simulation of the DV-Hop method, the percentage of anchor nodes was set to 20% since the performance falls significantly if using less than 20% of anchor nodes [2]. As shown in Figure 7, both the BLM and the LSMLM outperform the DV-Hop method, except when
Similar to the DV-Hop method, our proposed mechanism computes hop-count numbers between unknown sensors and anchor nodes to estimate the distance between them. However, our proposed mechanism is more adaptable to various situations of the distribution of unknown sensors and uses more sophisticated calculation to estimate the positions of them.
The DV-Hop method and our proposed mechanism differ in the following two aspects.
In the DV-Hop method, each unknown sensor uses the hop size from the anchor with the smallest hop count to estimate the distances to all of the chosen neighboring anchors. The estimated distances are imprecise and usually biased according to our simulation. However, in our proposed scheme, we use (α × hop-count number × communication range) to estimate the distances between unknown sensors and anchor nodes, where parameter α, as shown in Table 1, is derived from the prior experiments of hundreds of cases with different communication ranges. In DV-Hop method, each unknown sensor chooses anchors within a fixed hop count from it. These anchors may distribute unevenly, for example, gathering together or lying near the same lines of the same sides to the given unknown sensor. This will reduce the accuracy of multilateration due to the geometric dilution of precision (GDOP) [18]. However, in our proposed method, we use 16 anchors located equidistantly at the perimeter and apply the multilateration to estimate the position of the unknown sensors.
6. Conclusion
This study presents a low-cost yet effective anchor node placement strategy for the range-free localization problems of WSNs. Numerous researches have attempted to resolve the range-free localization problems in WSNs, although many of them require excessive number of anchor nodes. The proposed localization method uses as few as two anchor nodes to estimate the positions of the unknown sensors.
In this study, all anchors were installed equidistantly at the boundary of the monitored region. The distances between each unknown sensor and anchor nodes were estimated based on the minimum hop counts to the anchor nodes. The locations of the unknown sensors were derived by applying the BLM or the LSMLM depending on the number of anchor nodes. The simulation results showed that this strategy is effective. The average range error of an unknown sensor is as low as 0.15 when LSMLM-16 is employed and CR is greater than 50 meters.
The BLM uses only two anchor nodes to locate the unknown sensors. Although the BLM is appealing because of the low installation cost and communication overhead, its range error is slightly high (between 0.4 and 0.5 in general). Thus, it is suitable for coarse-grained localization. This study showed that adding more anchor nodes can reduce the error rate. The experiments also showed that the marginal effect of adding anchor nodes to reduce the error rate decreases as the number of anchor nodes increases. In the LSMLM, the error rate converges as the number of anchor nodes approaches 16.
The proposed localization scheme was compared with the established DV-Hop method. The simulation results showed that the proposed scheme surpasses the DV-Hop method in terms of localization accuracy and communication cost.
Although both the BLM and the LSMLM were applied to the monitored square region in this study, identical algorithms can be used for a rectangular region without requiring modification.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.