
Abstract
Wireless sensor networks (WSNs) are composed of numerous low-cost, low-power sensor nodes communicating at short distance through wireless links. Sensors are densely deployed to collect and transmit data of the physical world to one or few destinations called the sinks. Because of open deployment in hostile environment and the use of low-cost materials, powerful adversaries could capture them to extract sensitive information (encryption keys, identities, addresses, etc.). When nodes may be compromised, “beyond cryptography” algorithmic solutions must be envisaged to complement the cryptographic solutions. This paper addresses the problem of nodes replication; that is, an adversary captures one or several nodes and inserts duplicated nodes at any location in the network. If no specific detection mechanisms are established, the attacker could lead many insidious attacks. In this work, we first introduce a new hierarchical distributed algorithm for detecting node replication attacks using a Bloom filter mechanism and a cluster head selection (see also Znaidi et al. (2009)). We present a theoretical discussion on the bounds of our algorithm. We also perform extensive simulations of our algorithm for random topologies, and we compare those results with other proposals of the literature. Finally, we show the effectiveness of our algorithm and its energy efficiency.
1. Introduction
WSNs are composed of a large number of low-cost, low-power, and multifunctional sensor nodes communicating at short distances through wireless links. They are self-configuring, self-maintaining, and usually deployed in an open and uncontrolled environment that requires secure communication and routing and where attackers may be present. Moreover, most of the WSNs use low-cost commodity hardware components that are not tamper resistant. Due to cost considerations, using shielding to detect changes is impracticable. Thus, an adversary could access a sensor's internal state. An adversary can easily capture a single node, replicate it indefinitely, and insert duplicated nodes at any location in the network. Node replication attacks occur when a single identity is used by multiple nodes simultaneously in the network. If no specific detection mechanism is set up, the attacker could lead many insidious attacks such as subverting data aggregation protocols by injecting false data, revoking legitimate nodes, and disconnecting the network if the replicated nodes are judiciously placed at chosen locations.
In this work, we focus on this particularly dangerous attack: the node replication attack described in [1]. The replication attack consists in adding one or more nodes with nodes identities that are already deployed in the network. This can be done by first capturing nodes in the WSN and deploying duplicated after. However, we suppose here as done in [1] that the adversary cannot deploy malicious nodes with new identities; that is, the attacker cannot construct new identities. If this attack is not detected, many other attacks such as Wormhole [2] or Sybil [3] can be launched in the network. Whereas in a Sybil attack, a single Sybil node uses many identities at the same time; in a node replication attack, several nodes have the same ID in the network. In this paper, we detail the algorithm already proposed in [4] which is a hierarchical distributed algorithm for detecting node replication attacks using a Bloom filter mechanism [5]. Our algorithm could be used by a WSN as soon as the network is built upon a cluster head selection mechanism generating a three tiers hierarchy. Without loss of generality, in this paper, the local negotiated clustering algorithm (LNCA) protocol [6] is used as the cluster head election mechanism, but other cluster head election mechanisms could be used making the approach generic. Our algorithm works as follows: each cluster head exchanges the member nodes IDs through a Bloom filter with the other cluster heads to detect eventual node replications. Thus, our proposal is decentralized, based on a hierarchical localized approach, and no additional hardware artifact is required. We demonstrate the capabilities of our algorithm with several extensive simulations.
Section 2 describes the node replication attack and presents the related work that develops countermeasures against this attack. In Section 3, we give the definition of a Bloom filter, we introduce the network model, the underlying method for cluster head election, and the adversary model. We also present the different assumptions we make. In Section 4, we detail our replication detection algorithm and the network replies when a replication is detected. Section 5 discusses the parameters choices and gives theoretical bounds for our algorithm. Section 6 provides simulation and comparison results, whereas Section 7 concludes this paper.
2. Related Work
As illustrated in Figure 1, the replication attack consists of introducing new malicious nodes with existing identities in the network.

Nodes replication. An attacker compromises a legitimate node and inserts some copies of this node into the network.
Intuitively, the most straightforward approach to solve node replication attacks is the use of a centralized scheme in which each node joining the network should broadcast a signed message (referred to as location claim) to its neighbors. At least one of its neighbors forwards this location claim to the base station. If the base station receives more than one location claims with the same identity but different locations, then the base station detects node replication attacks. It broadcasts a message to the whole network to revoke the replicated node. The centralized scheme achieves 100% detection of node replication attacks. However, the centralized scheme has some disadvantages in terms of communication and memory costs.
Distributed protocols are much promising due to the distributive nature of sensors networks. In [7], the authors propose a very specific solution where the node replication attacks are detected using the probabilistic key sharing scheme described in [8]: instead of detecting replicated nodes, this method detects replicated keys. The seminal work on distributed methods for node replications detection has been proposed by Parno et al. in [1] where two protocols are described: randomized multicast and line-selected multicast. Both of them operate similarly: the location claims of each node are broadcasted to witnesses which record all the received claims. If a witness receives duplicated claims, he floods the network with an authenticated revocation request.
In the randomized multicast solution, each node α broadcasts its location claim to its d neighbors. Using a geographical routing protocol, each neighbor forwards the location claim of α with probability p to g nodes randomly selected (g and p are protocol parameters). So, collectively, all the nodes chosen by all the neighbors of α constitute the set of witnesses of node α. So, if we fix
To tackle the communication cost problem, the line-selected multicast algorithm was proposed in the same paper. In this algorithm, the set of witnesses is also composed of all the intermediate nodes that route the messages from the neighbors of α to the other witnesses. The algorithm thus considers the lines created between the witnesses (hence, the algorithm name). And so, with a little number of lines per node (e.g., five lines), replicated nodes can be detected with a probability of 95%. In summary, when a node α announces its location claim, each of the d-neighbors forwards claims of α with probability p to a chosen random node. Along the line between the neighbor node and the random node, each intermediate node stores the α's claim and verifies if it has a duplicated location claim. If yes, it initiates a revocation request in the network, else it forwards the α's claim to the next witness node. From a global point of view, node replication may be detected by the witness on the intersection of two lines originated from different network positions by replicated nodes. The total communication cost is
From this original proposal, some other schemes have been proposed [9–11]. The first one named SET is based on computing set operations (intersection and union) of exclusive subsets in a WSN, seen as a set of nonoverlapping subregions, to detect replicated nodes. As each node ID is unique, the intersection of subsets must be empty, if not, there are some replicated nodes in the network. In [10], Conti et al. proposed the RED protocol where the base station broadcasts a one-time seed (changed at each verification) to the whole network. The location of the witness nodes of a node is determined from the node ID and the seed. Then, the other operations are similar to the Parno schemes. In [11], Zhu et al. proposed two schemes named single deterministic cell (SDC) and parallel multiple probabilistic Cells (P-MPCs) based on geographical limited regions.
Some other solutions have been proposed. Among the most recent ones, we could cite [12] where the basic idea is to integrate a constant countervalue into a HELLO message broadcasted by each sensor node after its deployment. The counter is maintained by the node to keep track. When two received counter values are not equal, it means that two nodes with the same ID are present in the network. However, this method works only with synchronized clocks. In [13], the authors propose a solution for node replications detection when the nodes are mobile. Finally, in parallel to our own study, [14] also proposes a solution based on a Bloom filter.
In this paper, we propose a novel node replication detection mechanism based on a hierarchical network structure to limit the communication overhead and with a detection probability equal to 100% for a pair of replicated nodes.
3. Background and Network and Adversary Models
In this section, we first introduce what a Bloom filter is and describe our network and our adversary model. Then, we give some details on the LNCA protocol.
3.1. The Bloom Filter
A Bloom filter is a simple space-efficient probabilistic and random data structure usually used for membership tests [5]. The main advantage of the Bloom filter is its compression capability. Using a Bloom filter, a set

Bloom filter computations.
3.2. Network Model
We consider here a wireless network where nodes are fixed. According to the required applications, two main kinds of architecture could be considered: the flat architecture and the hierarchical one. In the first case, no specific mechanism is required for the network deployment which is very simple. In the second one, network organization and self-configuration mechanisms are needed to provide network management and to finally reduce the energy consumption (by reducing the number of transmitted packets).
In our proposal, we focus on large-scale wireless sensor networks based on a three tiers hierarchical architecture as described in Figure 3: low-power sensor nodes S, low-power cluster head nodes CH elected by the other nodes, and a single access point which we call the sink or the base station BS. In our approach, all the nodes (except the base station) are exactly the same: they are supposed to have a unique predistributed ID, and the cluster heads are elected using, for example, the LNCA protocol [6]. Usually, a three tiers hierarchical architecture works as follows. Sensor nodes send their data only to their respective cluster head CH. Then, each cluster head aggregates and forwards those data to the base station. Cluster heads communicate each other through dedicated paths and create a kind of tree with the base station as a root. We assume that the network is composed of n sensor nodes and t cluster heads. Each cluster has one cluster head and many sensor nodes.
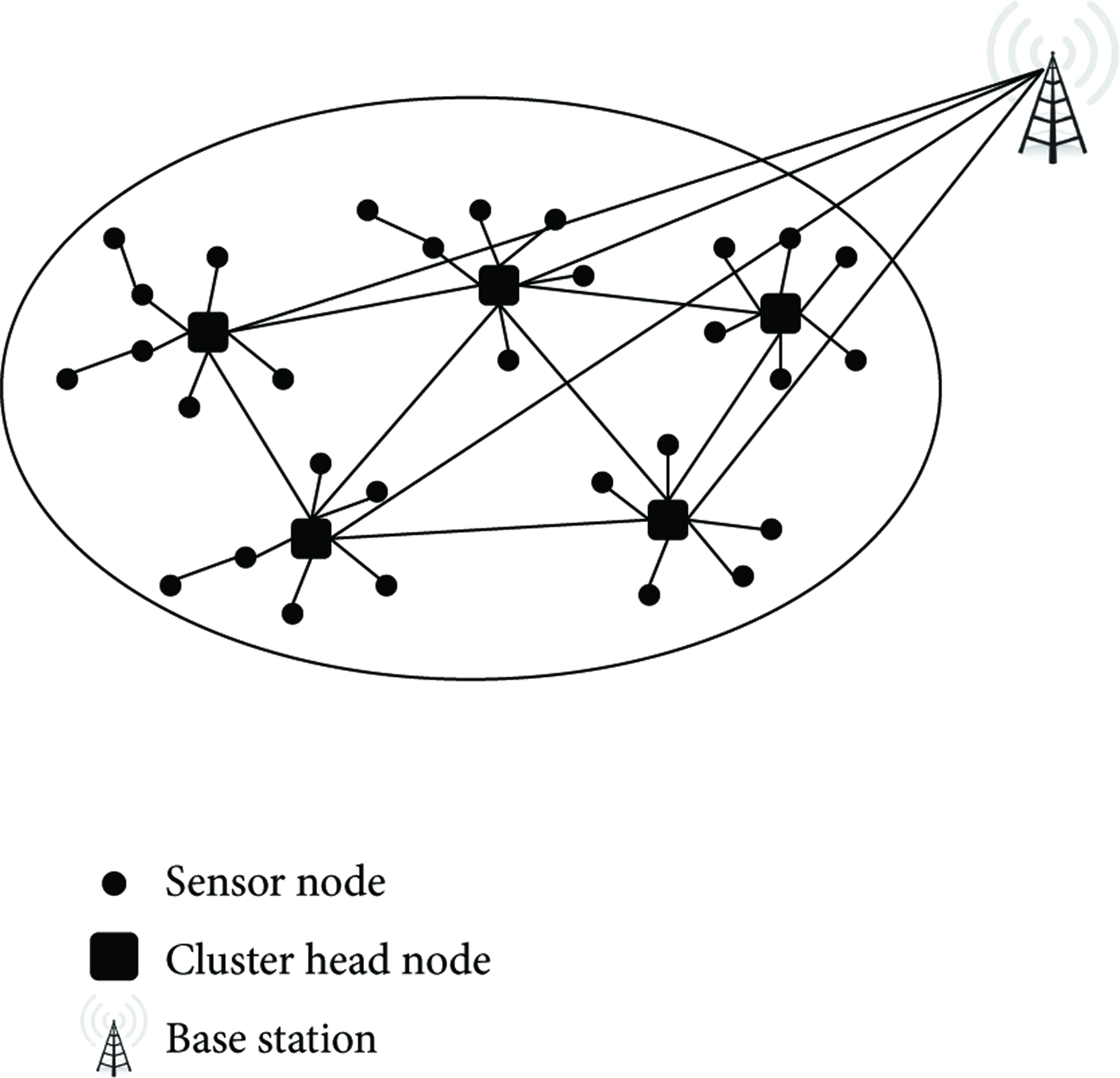
Hierarchical sensor network architecture.
3.3. Adversary Model
In this work, we assume that the adversary's goal is to replicate nodes (i.e., to create clones) into the network in order to deceive nodes and to apply any other types of known attacks. We assume that an attacker can capture sensor nodes and construct replicated devices with same credentials. The attacker can either compromise a sensor node or a cluster head node. We will present in Section 4.3 how we can detect the two cases. This attack is different from the Sybil attack which consists of that a single Sybil node broadcasts many identities during the network life. Our security goal is to detect replicated nodes that exist into the network. This detection is performed by the cluster head nodes using a Bloom filter mechanism and based on the hierarchical architecture of the WSN. We also focus on minimizing the overhead communication compared to the other solutions presented in Section 2.
3.4. LNCA
In this work, we have chosen the LNCA protocol [6] as a good candidate for the clustering mechanism without loss of generality. However, many other clustering protocols could be used as LEACH [15] or others. Our node replication detection approach is relatively independent from the underlying clustering mechanism. We will detail here, in Sections 4.5 and 5, the conditions for the underlying clustering protocol. The only hypothesis we require is a hierarchical topology. LNCA has been chosen because of its simplicity to manage the size and the number of clusters and its really simple implementation. The role of a clustering protocol consists in organizing the network around two tasks:
select a set of cluster heads CH among the nodes deployed in the network; class the rest of the nodes in the different clusters. Each node must choose a unique cluster head to relate to him.
Following those principles, LNCA is able to create hierarchical topologies using clusters of radius w-hop. Each node is at most distant from w-hop of the cluster head.
The LNCA mechanism works as follows.
Data exchange and degree computation: each node sends to its neighbors a physical value sensed in its environment. In the LNCA protocol, two nodes are declared direct neighbors by the protocol if they share the same physical value sensed and exchanged. Once done, a node computes its degree, that is, the total number of its direct neighbors. Degrees diffusion: each node sends its local degree to its w-hop neighbors. This is done using a TTL (time to live). At the beginning, each node sends its degree and the TTL value initialized to w. Each node, that receives the message, first certifies the TTL value. If the TTL is greater than 0, it stores the source node and its corresponding degree in its neighbors table. Then, the node decrements the TTL by 1 and retransmits the message to its neighbors. Else, if the TTL is negative, the message is ignored and dropped. Thus, messages could be easily sent to w-hop nodes. Cluster heads election: each node compares its local degree with the degrees received from its w-hop neighbors. If it possesses the greatest value, it self-elects as cluster head (in case of equality, the values of the residual energy in the nodes are used). Then, the elected node broadcasts a message announcing its election to its w-hop neighbors using the same technique as before. Thus, each node, that hears an announcement from a valid cluster head, returns a join message to be related to this cluster head. Clusters formation: each cluster head, that receives a join message, adds the identity of the corresponding node in its member list. If a cluster head does not receive any join message, it becomes a normal node and is related to the cluster head of its neighbors.
At the end of the LNCA protocol, we obtain a w-hop radius clustering network structure. In our simulations, we have varied the values of w to ensure all the possible topologies scenarios. The parameter w influences the number and the size of the clusters created in the network. We decide to periodically execute the election rule eventually replacing the highest degree by the second highest degree for energy efficiency point of view.
We also need to add a particular hypothesis in order to make our protocol work. To prevent a cluster head from lying on the members of its cluster, we need to add a last step to LNCA where the cluster head and all the members exchanged the members list of their own cluster (using the join messages, a neighbor intersection algorithm, and eventually a voting system). This step is executed locally inside each cluster and is directly included in most clustering mechanisms such as in LNCA.
3.5. Secure Communications
As done in [1] and in many other node replication detection proposals, we assume that there are security mechanisms in the network we consider. We therefore consider that there exist secure cryptographic schemes to cipher data, safely generate signatures, and that there exist methods to build keys (see [16], e.g.). Methods using symmetric cryptography or asymmetric cryptography can be used (as done in [10, 17, 18]) even if asymmetric cryptography remains more costly in terms of energy. Similarly, we do not describe here the underlying routing mechanism used for communication between the nodes; we just assume that such a mechanism exists. Note that those choices do not affect our results and that our proposition is independent of the security mechanism, of the used clustering protocol, and of the routing protocol.
4. Our Proposal
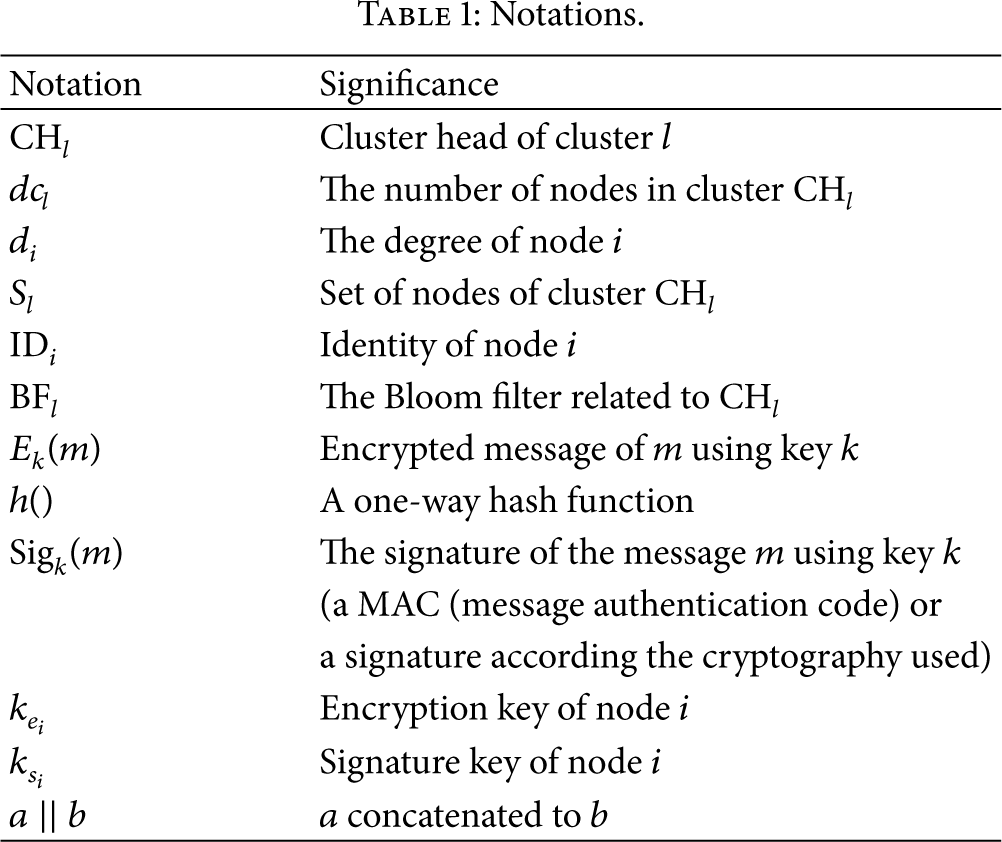
Based on a three-tier hierarchical network model, we propose a node replication attack detection algorithm for large-scale wireless sensor networks. Our approach is based on the use of a Bloom filter which is computed by cluster head nodes. The notations used in this paper are listed in Table 1.
Notations.
Our algorithm will be divided in three steps. The first one predistributes in each sensor node all the material required for the Bloom filter computations and for cryptographic operations that will be performed in the network. The second step consists in the cluster head election (we do not detail this step, the reader could refer to [6] for more details). The last step consists in the Bloom filter construction performed by each cluster head and the Bloom filter verification performed by the other cluster heads. The routing method used between the cluster heads is out of the scope of this paper.
4.1. Predistribution Phase
During the predistribution phase, the base station generates the required cryptographic materials, a hash function
4.2. Election Phase
The cluster heads election is performed here using the LNCA protocol (note that other protocols (especially more energy efficient) could easily replace LNCA). This election could be periodically restarted (each period time t). The detection phase could not be applied at each t period (due to its cost) but for example at each
4.3. Detection Phase
In our protocol, replicated nodes detection is performed by the cluster heads. The main idea is that each cluster head computes a dynamic Bloom filter that contains the node identities of its cluster set. Here, the term dynamic means that clusters have different densities, so cluster heads construct the Bloom filter with different sizes (the size m of the bloom filter depends on the size of the cluster in such a way that we minimize the probability of false positives).
In the following, even if all the cluster heads perform all the next steps, we focus on two particular cluster heads: The cluster head It computes the Bloom filter It sends to With its own IDs list When a node replication is detected and verified in the network,

Illustration of our algorithm.
4.4. Network Replies When Node Replications Are Detected
Two different responses are expected in the network during the steps (5) and (7). The first response (step (5)) concerns a Bloom filter problem: the cluster head
In the case where (step (7)) a replicated node
4.5. Security Analysis of Our Protocol
First of all, due to the use of encryption and signature provided by cryptographic algorithms, the Bloom filters exchanged between nodes could not be compromised by an attacker.
Now, let us analyze how our algorithm could efficiently detect one or many replicated nodes. If a single simple node is replicated, in order to act into the network, it needs to be included in a cluster. If the two nodes with the same identity belong to the same cluster, then the protocol will detect this replication at step 1 by an honest cluster head and at step 5 by a dishonest cluster head but an honest simple node. As this step 5 is repeated by the different cluster heads and different simple nodes, the nondetection probability is really really low. Thus, our protocol is able to detect two replicated nodes in a cluster head even if the cluster head itself is dishonest or replicated. Two nodes that belong to different clusters will also be detected with a really high probability even if the corresponding cluster heads are dishonest or replicated thanks to step 5. In the same way, with the same high probability, a cluster head and a single node that belong or not to the same cluster will be detected.
As previously mentioned, our protocol works correctly if each member of a cluster has the same vision of the cluster than the cluster head. This is why in Section 3.4, we add the hypothesis that each cluster member knows all the members of its cluster. Thus, under this hypothesis, two replicated nodes, whatever there are cluster heads or not, will be detected essentially because of step 5.
If a complete cluster is replicated, the protocol under its present form will not be able to detect it because there is no comparison at each cluster head level between all the received Bloom filters. This step could be easily added because it only requires local computation on each cluster head and a global voting decision of all the cluster heads as proposed in Section 4.4.
In summary, our protocol shares the detection of replicated nodes into two main steps: a local detection mechanism at step 1 and a global aggregated detection step at step 5 and step 7.
5. Theoretical Discussion and Parameters Evaluations
In this section, we describe the complexity bounds when comparing our proposal and the Parno algorithms described in [1]. We also compute all the parameters required for our approach given a concrete example.
5.1. Theoretical Discussion
We will now theoretically compare our solution with and without a Bloom filter to the line-selected multicast (LSM) algorithm proposed in [1] and described in Section 2. We choose the LSM algorithm because this is one of the best existing proposals. We sum up in Table 2 the different notations. So, for a network of size n and as previously explained, the total communication cost of the LSM algorithm is
Notations.

The general complexity of our algorithm mainly depends on the number of cluster heads t. Each cluster head sends
Thus, without considering the Bloom filter use (supposing that each cluster head sends the concatenation of its member IDs), our algorithm is more efficient than the LSM algorithm in terms of communications (i.e., number of bits exchanged) when
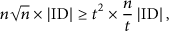
Considering the Bloom filter use that compresses information, the evaluation in terms of communications becomes
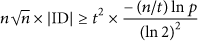

But in this last case, each cluster head
In summary, our algorithm is more efficient than the LSM algorithm when
Moreover, in this subsection, we have not taken into account the communication cost required for the cluster head election because we assume that our algorithm only works with networks that are already self-organized through clusters.
5.2. A Concrete Example
So, let us now give a complete example for the different parameters given a network of
Using those parameters, the communication cost of the LSM algorithm will be about 31600 identity messages, whereas our own algorithm using a Bloom filter requires the sent 200 Bloom filters which is about the sent 16000 single identities considering identities of 10 bits.
In step (5), the average number of hash computations performed by
Note also that in the example given above, the network is large but has not a high degree, for higher degrees (i.e.,
6. Simulation Results
We run a set of simulations using the WSNet simulator [21] to compare the performances of our proposal with the Parno et al. protocols described in Section 2. The tests are performed over random topologies and concerned the detection rates, the communication overheads, and the energy gains between our proposal and the Parno et al. protocols.
Note also that the tests are performed without the cryptographic layer for all schemes. Finally, note that in all the simulations presented here, the cost of the clustering mechanism is not taken into account. Our protocol could be seen as a particular feature that could be implemented at low cost when a clustering mechanism is used in the network.
For our proposition, we have simulated different scenarios: we have varied the number and the size of the clusters to study its influence on network performances; we have also varied the number of replicated nodes between 1 and 17.
6.1. Simulation Parameters
We implement our node replication detection algorithm with
For the Parno et al. protocols (RM and LSM), we set
The tests are performed using the IEEE 802.11 physical and MAC layers which are fully simulated in the WSNet environment. Each simulation is run with n nodes
To model interference, WSNet replaces the SNR by a signal to interference plus noise ratio, SINR, which can be derived according to


Neighborhood with different radio range modeling: (a) perfect unit disk and (b) Links with pathloss and shadowing.
We have computed the average detection probability of a single node replication as defined in [1]. It represents the number of times the protocol must run to detect the attack. We have also compared the communication cost of each of the three protocols and the energy gain consumption. Note also that in the three figures of Section 6.2 (Figures 6, 7, and 8), our algorithm is implemented with

Detection probability: average probability of a single node replication detection for the three considered algorithms.

Communication overhead: average number of packets sent and received per node for the three algorithms.

Energy gain: energy consumption gain of our protocol compared with the Parno et al. protocols.
6.2. Results for One Replicated Node
Figure 6 presents the detection probability of a single node replication (i.e., a single identity present at two places in the network). This probability reaches 100% in our case whereas it is equal to 75% for the Parno protocols (this probability is the one described in the Parno et al. paper [1]). The probability is equal to 1 in our case because our approach is mostly deterministic and not probabilistic: any replicated node who belongs to a filter will be detected by any other cluster head excluding false positives of the Bloom filter (step (6)). The only case where the detection will not reach 100% is when a node and its cluster head are replicated, they thus lie on the corresponding Bloom filter, and all the other cluster heads verify the same replicated node. This case is really improbable. Moreover, the really low false positives rate (of 2% when considering that step (6) is omitted, i.e., the detected identities are not verified) will be reduced to 0.4% in the symmetric step (7). Thus, our algorithm is really efficient when considering the node replication detection probability, better than the two algorithms proposed in [1].
Figure 7 presents the average number of packets sent and received per node for the three algorithms. Clearly, the RM algorithm generates many traffic and is less efficient than the LSM algorithm. Moreover, our algorithm generates less traffic than the two other protocols because our protocol requires only communication between cluster heads and with witness nodes randomly chosen for the Bloom filter verifications. Note also that the number of nodes of step (5) is equal to 3. So, decreasing this number implies even less communication traffic. Another way to decrease the communication overhead induced by our protocol is to introduce cluster heads cooperation where each cluster head only verifies a subset of all the clusters. So, simulations show that our proposal needs fewer packets to better detect a replication attack even if the size of the packets generated by our approach is bigger.
In order to take into account the different packet sizes, Figure 8 shows the energy consumption gain between our protocol and the Parno ones. To do so, we have computed the energy ratio using the following equation:
So, all the results confirm that our hierarchical replication detection mechanism is more efficient than the Parno et al. ones in terms of communication overhead and of energy consumption with a detection probability equal to 100% of detections most of the time.
6.3. Results for Several Replicated Nodes
Figures 9 and 10 compare the detection probability of replicated nodes when many replicated nodes are introduced in the network for our own protocol with

Real propagation model: replicated node detection probability: (a) for 2 replicated nodes; (b) for 7 replicated nodes.

Real propagation model: replicated node detection probability: (a) for 12 replicated nodes; (b) for 17 replicated nodes.
Figure 11 shows the influence of communication overhead of our approach for
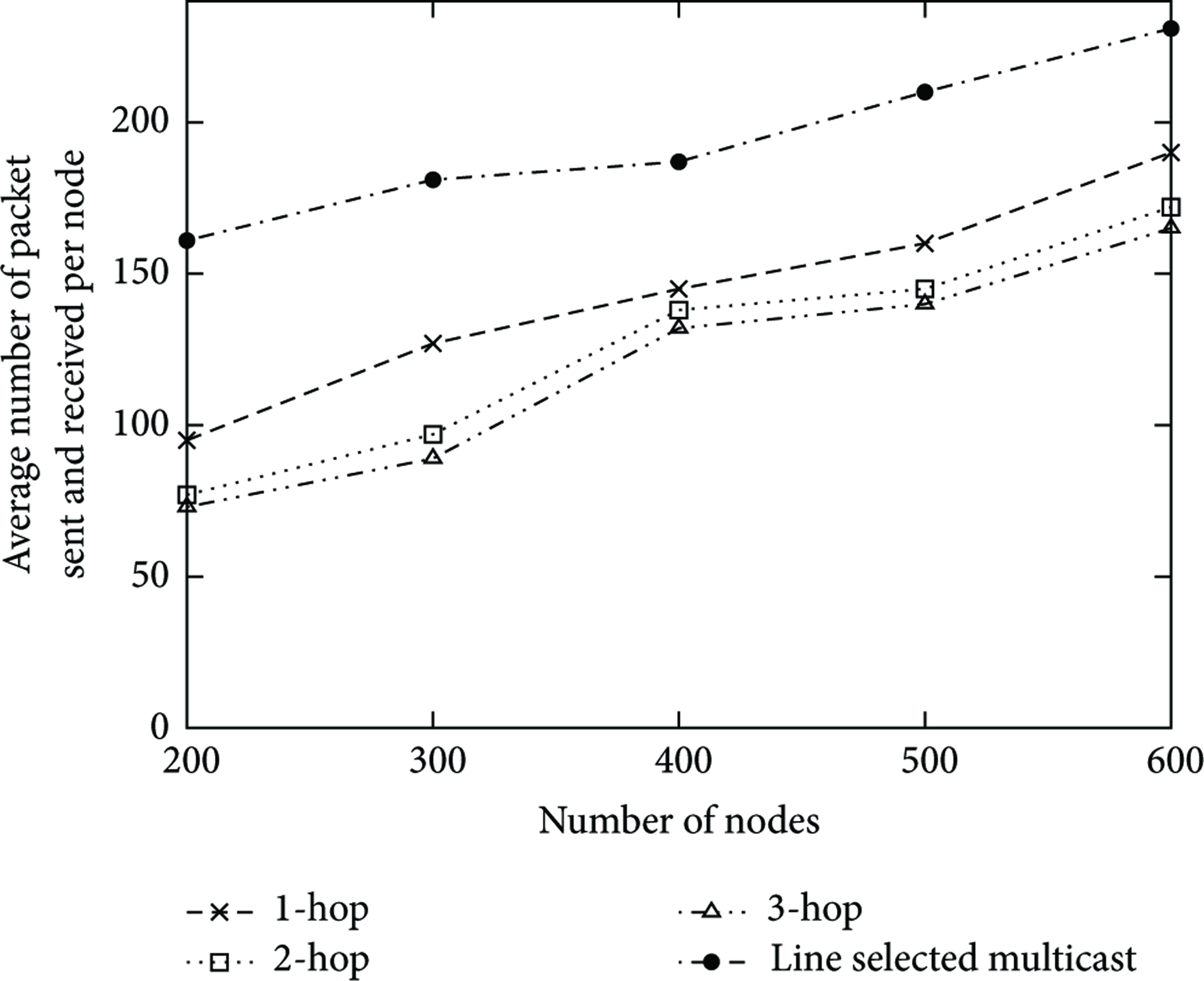
Communication overhead in a real propagation model: this figure presents the influence of clusters size on the average number of packets sent and received for each node.
In summary, our approach stays more efficient in terms of communication overhead than the LSM protocol proposed in [1] with better detection rates even if many replicated nodes are present in the network. However, Figure 11 does not take into account the packet sizes which are smaller for the LSM approach. As shown in Section 5.1 and in our simulations, our approach stays more energy efficient than the LSM protocol for well chosen parameters (
6.4. Other Simulation Results
We have also simulated the case where a complete cluster is duplicated and inserted in the network (as already mentioned in Section 4.5). In this case, this attack could not be detected by our approach as described here because each member of the cluster and the cluster head agree on the same Bloom filter value and the invalidity of the Bloom filter could not be detected. A solution to detect this particular kind of attack could be to add a test for each cluster head that test the consistency between the different Bloom filter it receives: it tests the correlation between each pair of the Bloom filters and when this correlation is near 1, it sends an alert message to the other cluster heads. As done in step (5), a voting process could thus be launched between the different cluster heads to decide whether a complete cluster is replicated or not.
We have also simulated the case where the cluster heads are duplicated nodes. In this case, the duplicated cluster head is detected with a probability of about 98% in all cases by step (5) of our algorithm. In this last study, we have not studied the case where more than two malicious cluster heads cooperate to dissuade the other legitimate cluster heads about the validity of their filters. A solution to detect this kind of attacks consists in the periodical use of a secure clustering mechanism. In this case, malicious cluster heads introduced at period T will be detected at the next period
A last case could emerge in the network if other clustering mechanism rather than LNCA is used in the network: a single cluster is presented in the network with a single cluster head. In this case, the cluster head is going to play the role of a central entity that will be responsible for the node replication detection. If the cluster head is itself an attacker, we could imagine that the base station itself verifies the Bloom filter built by the unique cluster head by asking some nodes to build again the Bloom filter.
6.5. Conclusion
In conclusion, our algorithm stays always more efficient than the ones of Parno et al. proposed in [1] in terms of detection probability, but the energy efficiency mainly depends on the number of cluster heads. So, our protocol could be easily implemented jointly with a clustering mechanism that verifies that the number of cluster heads t present in the network is such that
So, the use of our protocol could be easily considered with 1-hop clustering protocols when the network is dense (e.g., FISCO [23], CDS [24], MIS [25], or RNG [26]) and is recommended with k-hop (
7. Conclusion
In this paper, we have proposed a simple, practical, and hierarchical algorithm to detect node replications in WSNs based on the optional use of Bloom filters. The simulation results show that our proposal is really efficient with a really high detection probability of replicated nodes (100% of detection in most cases). This mechanism could be directly implemented when a k-hop hierarchical protocol is already deployed in a WSN for a really low complexity add. Our general aim is to provide particular security mechanisms linked with the implemented routing methods to limit the general size of code and the general network overhead required by security mechanisms.
In further works, we mainly focus on two main directions: on the one hand, studying the influence of the underlying clustering mechanism to optimize the energy consumption of our protocol; and on the other hand, establishing a secure mechanism for cluster heads election to be able to trust cluster heads. This last remark would thus reduce energy consumption by failing to verify the validity of Bloom filter through witnesses and thus achieving the same results in terms of detection.