
Abstract
With the development of wireless sensor network (WSN) technologies, WSNs have been applied in many areas. In all WSN technologies, localization is a crucial problem. Traditional localization approaches in WSNs mainly focus on calculating the current location of sensor nodes or mobile objects. In this paper, we study the problem of future location prediction in WSNs. We assume the location histories of mobile objects as a rating matrix and then use a random walk based social recommender algorithm to predict the future locations of mobile objects. Experiments show that the proposed algorithm has better prediction accuracy and can solve the rating matrix sparsity problem more effectively than related works.
1. Introduction
Recently, WSNs have been applied in many areas, such as environmental monitoring [1], target tracking [2], and intrusion detection [3]. However, in all of these areas, location is very important, for data without location in WSNs will be useless. Research of localization is a hot topic in WSN, and it includes two kinds, that is, localization of sensor nodes in the WSN itself and localization of mobile objects using a WSN. For localization of sensor nodes in the WSN itself, several anchor nodes with known location are selected, and locations of other sensor nodes can be calculated with predefined anchor nodes [4]. For localization of mobile objects using a WSN, all sensor nodes are assumed to be anchor nodes, and the location of mobile objects can be calculated with observed anchor nodes [5]. The most popular localization system of this kind is the global position system (GPS).
Given a WSN, where all sensor nodes are anchor nodes, the locations of mobile objects can be calculated with the WSN. Furthermore, if we save all location records of mobile objects, then we can predict future locations of mobile objects with the observed location histories and the WSN. In this paper, we study the problem of future location prediction in WSNs. Here, we assume a WSN as a connected network, where each sensor node has connections with all its neighbors. The reason is that if a mobile object visits location A, it will probably visit A's neighborhood. In a WSN, each node records the number of visits of all mobile objects to itself. Hence, we have a network of sensor nodes and a rating matrix of sensor nodes on all mobile objects. The purpose of this paper is to predict which mobile object will probably visit the desired locations or sensor nodes in the future.
2. Related Works
If we assume each sensor node as a user and each mobile object as an item or a commodity, then the number of visits from a mobile object to a sensor can be assumed to a
2.1. Traditional Recommender Systems
As mentioned by Huang et al. [6], collaborative filtering (CF) method is one of the most commonly used and successfully deployed methods in recommender systems. The CF recommender method can be classified into memory based and model based [3, 4].
The memory-based CF method is heuristic, and it aims to find a neighborhood of similar users [7, 8] or items [9–11] for recommendation. The user-based method predicts ratings based on ratings of neighborhood users, and the item-based method predicts ratings based on ratings of neighborhood items. Here, the similarity between users or items could be Pearson correlation coefficient [12], vector space similarity [13], cosine similarity [14], and so on.
In model-based CF method, one can build a model by the priori
Recently, due to its efficiency in dealing with large datasets, several matrix factorization methods [20–24] have been proposed. The matrix factorization methods factor the
2.2. Trust-Based Recommender Systems
Traditional recommender systems have been well studied and developed in both academia and industry, but they all assume that users are independent and identically distributed and ignore the relationships between users. However, in practice, recommendations from different users should have different weights. For example, a preference or advice from a close friend should be more trustable than that of a stranger. Based on this idea, many researchers have recently begun to analyze trust-based recommender systems [25–30]. Trust-based recommender systems use both the rating matrix and the network of users to predict unknown ratings.
TidalTrust [25] applies the social network to find neighbors and aggregates their ratings weighted by the trusts between the source user and his neighbor. The searching of neighbors is based on breadth first search, which finds the nearest raters in the social network, and the trust between the source user and a rater is aggregating the trust value between source user's direct neighbors and the rater, weighted by the trust values between the source user and its direct neighbors. MoleTrust [26] is similar to TidalTrust, except that the computation of trust between the source user and a rater is based on direct neighbors of the raters.
Golbeck and Hendler [27] studied how trust information can be mined and integrated into social-rating systems. They defined trust as “trust in a person is a commitment to an action based on a belief that the future actions of that person will lead to a good outcome,” presented two algorithms for inferring trust relationships between individuals that are not directly connected in the network, and proposed a prototype email client—TrustMail, which could filter spam for an email system.
TrustWalker [28] is a combination of item-based CF and trust-based recommendation, and it considers both ratings of similar items by trustable friends and ratings of the exact item by further neighbors in the social network. The random walk model of TrustWalker is as follows. Starting from the source user u, at step k and at node v, if v has rated i, then it returns to the rating
The works in [25–28] are all heuristic or memory based. However, model-based recommender methods, such as SocialTrustEnsemble [29] and SocialMF [30], can also be used in social recommender systems. Both SocialTrustEnsemble and SocialMF apply the matrix factorization method, and they factor both the
2.3. Other Types of Recommendation
Besides recommending items for users, the social recommender systems can also recommend users [31–33], communities [34, 35], and tags [36, 37], as well as all kinds of recommendations for a group of users [38–40]. For more details about social recommender systems, readers can refer to [5].
3. SocialSlopeOne Location Prediction Algorithm
3.1. Problem Definition
In this paper, we consider each sensor node as a user, each mobile object as an item, and the number of visits from a mobile object to a sensor as the rating of user (sensor node) on that item (mobile object), and then we have a
Assuming a WSN with n sensor nodes and m mobile objects, the WSN network
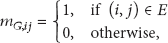

Moreover, the rating matrix R is


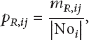
Given a WSN with a network G and a rating matrix R, the purpose of the paper is to predict unknown ratings
Notations.

3.2. Overall Recommender System
While predicting an unknown rating of user i on j, our overall recommender system works as follows.
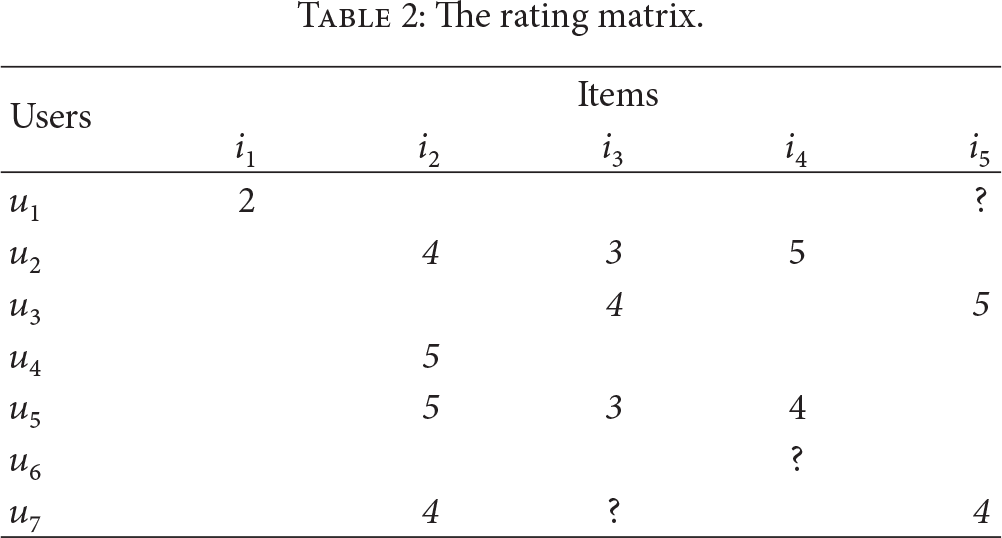
It constructs a social-rating graph with the WSN graph and the rating matrix. Here, we merge the common nodes of users in the two graphs. Figure 1 is an example of a social-rating graph, and Table 2 is its rating matrix, where While predicting the rating Once we get the similarities between i and other users, we can weigh the ratings of each user based on its similarity to i. With the rating matrix, we design a social slope one algorithm to predict the rating
The rating matrix.

An example of social-rating graph.
3.3. Random Walk Based Similarity
While predicting the rating starting from the source node i; at each step k and at user node u:
with probability ε, return to i; with probability
firstly, randomly walk to a direct neighbor user secondly, randomly walk to a direct neighbor item i of thirdly, randomly walk to a direct neighbor user
The fingerprint of a random walk is a chain of nodes, which is 

3.4. The Social Slope One Algorithm
As the slope one algorithm is an effective CF algorithm in recommender systems, we apply the idea of slope one for predicting unknown ratings. The slope one algorithm tries to find slope one suggestions in the rating matrix and uses slope one to predict unknown ratings. However, in a social recommender system, the rating matrix is sparse, and the slope one algorithm cannot predict ratings for users who do not have any slope one suggestion.
In order to solve the sparsity of the rating matrix, we propose a social slope one algorithm. While predicting a rating for user u on i, our proposed algorithm works as follows.
3.4.1. Predicting Ratings for New Users
In social recommender systems, a new user is a person that has not rated any item yet, that is, 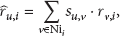
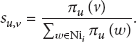
Taking Table 2, for example,
3.4.2. Predicting Ratings for Non-Cold-Start Users
While predicting the rating
If all items that u has rated have been rated only by u itself, that is,
Otherwise, if 
Equation (10) means that it is better to choose two ratings for items i and j from users similar to each other, and moreover, both of them are similar to the active user. If users p and q are the same user, then 
Input: Output: (1) For (2) Find (3) (4) Let (5) End for; (6) Return
Then, for all 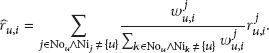
In Table 2, if we want to predict the rating
3.5. Complexity Analysis
In the problem of location prediction, our approach include two steps, that is, computing nodes' similarities with the random walk model and computing recommender results with the social slope one algorithm.
Theorem 1.
The computational complexity of the random walk based similarity, defined by formula (6), is
Proof.
The computation of formula (6) is the process of iterations, and the number of iterations decides the precision of the results. Here, we assume the number of iterations is k. At each iteration, there are three matrix-vector multiply operations, and their computational complexities are
Theorem 2.
The computational complexity of the social slope one algorithm is
Proof.
We assume that the rating matrix R contains r nonnull elements, and then each item is rated by about
From Theorems 1 and 2, we can have the following corollary.
Corollary 3.
The computational complexity of our random walk based social slope one algorithm is
4. Experiments
In this section, we perform experiments on two datasets, report the experimental results, and compare the results with existing CF algorithms. As the acquirement of sensor network data is very difficult, we use two social network data instead. However, both of them have similar characteristics with WSN data.
4.1. Datasets
The datasets in our experiments are Epinions [26] and Flixster [30], and both of them contain a social network and a rating matrix. The Flixster dataset is a social network service, where users can rate movies, the relationships between users are bilateral, and the rating values are 10 discrete numbers in the range [0.5, 5] with step size 0.5. The Epinions dataset is also a social network service containing a social network and a rating matrix. However, the relationships in the Epinions dataset are unilateral, and the rating values are integers from 1 to 5. Basic statistics of the two datasets are in Table 3.
Statistics of datasets.

4.2. Metrics
In the experiments, we treat the social network as known data and make 90% of the rating data as the training set and the remaining 10% as the test data. Our evaluation metrics are RMSE (root mean square error), precision, and coverage.
The RMSE of a model prediction with respect to the estimated variable 
Precision (also called positive predictive value) is the fraction of retrieved instances that are relevant:
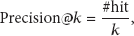
Coverage is the ratio of successful recommendations in the whole test set:
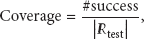
4.3. Baseline Algorithms
In our experiments, we compare the predicting results of different algorithms. Following is the description of labels that we use to denote each of these algorithms.
PearsonCF. It is user based CF algorithm with Pearson correlation coefficient as similarity measure [12].
SlopeOneCF. It is the slope one CF algorithm proposed in [16]. However, the algorithm does not take the social network into consideration and cannot deal with sparse matrix effectively.
TrustWalker [28]. This algorithm takes the social network into consideration and considers both ratings of similar items by trustable friends and ratings of the exact item by further distance users.
SocialMF [30]. It is model based matrix factorization algorithm considering both the social network and the rating matrix.
4.4. Results
In this subsection, we present the results of our experiments, first for all users and then for cold start nodes, and finally evaluate the impact of number of neighbors on the results of the proposed SocialSlopeOne algorithm.
4.4.1. Performance on All Users
We evaluate the performances (RMSE, precision, and coverage) of all algorithms on the whole test set, and the results are listed in Table 4. For better illustrating the results, we compare the results in Table 4 with Figures 2 and 3.
Experimental results for all users.


Comparison of RMSE for all nodes.

Comparison of precision and coverage for all nodes.
As shown in Figure 2, for the Flixster dataset, SocialSlopeOne has similar prediction error to SlopeOneCF, and both of them have lower prediction error than other algorithms; for the Epinions dataset, SocialSlopeOne has the lowest prediction error. In Figure 3, for precision, SocialMF is the best in the Flixster dataset, whereas SocialSlopeOne is the best in the Epinions dataset; for coverage, SocialSlopeOne is the best in both datasets. Moreover, SocialSlopeOne is the best for the sum of coverage and precision for all datasets. Hence, we can have that SocialSlopeOne has the best prediction accuracy and coverage in both datasets.
4.4.2. Performance on Cold Start Nodes
We also evaluate the performances (RMSE, precision, and coverage) of all algorithms on cold start nodes, and the result is listed in Table 5. In our experiments, we define cold start nodes as ratings for new items and new users. For better illustrating the results, we compare the results in Table 5 with Figures 4 and 5.
Experimental results for clod start nodes.


Comparison of RMSE for cold start nodes.

Comparison of precision and coverage for cold start nodes.
As shown in Figure 4, SocialSlopeOne has the lowest prediction error in both datasets for cold start nodes. In Figure 5, for precision, SocialSlopeOne and TrustWalker have similar precision, and they are better than others; for coverage, SocialSlopeOne is also the best in both datasets. Moreover, SocialSlopeOne is the best for the sum of coverage and precision for all datasets. Hence, we can conclude that SocialSlopeOne has the best prediction accuracy and coverage for cold start nodes in both datasets.
4.4.3. Impact of k on the Results
In the SocialSlopeOne algorithm, we need to construct
This top-k method cannot be applied in new items, so we observe the RMSE along with k for new users and all nodes. From Figure 6 we can see that, for both all nodes and new users, the RMSEs decrease with the rising of k. For small k, RMSEs decrease quickly, but as the increasing of k, RMSEs decrease slower and slower, which means that we can use small k to approximate the results for large

RMSE VS neighbors.
5. Conclusions
Traditional localization technologies focus on calculating the location of sensor nodes or mobile objects using WSNs. However, this paper studies the problem of future location prediction for mobile objects in WSNs. In addition to the WSN, we assume the location histories of all mobile objects as a rating matrix and transfer future location prediction problem to a social recommender problem. In social recommender systems, although current recommender algorithms could give recommender results, they have either low prediction accuracy or high computational complexity and cannot deal with sparse data efficiently. In this paper, we propose a random walk based similarity metric to find similar users and use slope one suggestions from similar users to construct recommender results. With our defined similarity metric, we can find more similar users, and this solves the matrix sparsity problem. In addition, we propose the social slope one recommender method, which has higher prediction accuracy and lower computational complexity. Experiments show that the proposed algorithm has better prediction accuracy and can solve the rating matrix sparsity problem more effectively than related works.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National High Technology Research and Development Program (“863” Program) of China (no. 2012AA011201).