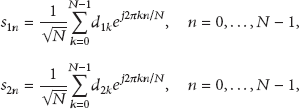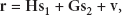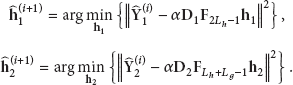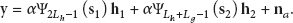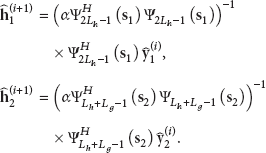The growing popularity of machine-to-machine (M2M) communications in wireless networks is driving the need to update the corresponding receiver technology based on the characteristics of M2M. In this paper, an expectation-maximization-based maximum likelihood cascaded channel estimation method is developed for relay-based M2M two-way communications. As the closed-form solution of maximum likelihood channel estimation does not exist, and the superimposed signal structure at the receiver is conducive to the expectation-maximization application, the expectation-maximization algorithm is utilized to provide the maximum likelihood solution in the presence of unobserved data through stable iterations. Even in the absence of the training sequence, the cascaded channel estimates are obtained through the expectation-maximization iterations. The Bayesian Cramér-Rao lower bounds are derived under random parameters for the channel estimation, and the simulation demonstrates the validity of the proposed studies.
1. Introduction
Machine-to-machine (M2M) communication is expected to be one of the major derivers of cellular networks [1, 2] and has become one of the focuses in 3GPP [3]. M2M technology allows machine devices to communicate directly with each other without human intervention, which has been attracting more and more interests for their wide applications in many popular wireless communication systems, such as mobile ad hoc networks [1–3]. Wireless M2M networks supporting M2M-enabled machine devices are pivotal to the success of M2M. Sensor nodes in wireless M2M networks could be connected by a wide range of wireless network technologies, for example, cellular networks.
Cooperation is crucial in wireless networks as it can greatly attribute to ensuring connectivity, reliability, and performance. Relaying is promising in a wide variety of network types for the cooperation purpose. According to the recent IEEE 802.16p proposals, a wireless M2M device may act as an aggregation point and communicate data packets on behalf of the other M2M devices, which may have a poor communication link to the network. Relay-based schemes have been proposed to improve the link reliability for devices with weak links [4–7].
As a basic model of the relay-based M2M two-way communications, the three-node cooperation model, which is also referred to as the two-way relay channel, where two source nodes exchange information via a relay node using amplify-and-forward (AF) or decode-and-forward (DF) strategy, has attracted a great deal of research interest because of its improved spectral efficiency [8–12]. AF relaying is more popular in practice because the relays only amplify and process the signal linearly before they retransmit it again and thus AF leads to low-complexity relay transceivers. A lot of research therein assumes perfect channel knowledge at the nodes, which is unpractical in wireless communications, so it is important to develop efficient channel estimation algorithms. Channel estimation for this communication scene has been studied in [13–18]. Specifically, in [13] the maximum-likelihood-based estimator, flat-fading channels were reported, and in [14, 15], the cascaded source-relay-source channels were estimated using block-based training under the assumption of time-invariant frequency-selective fading channels although the individual channels were also estimated using pilot-tone-based training in [14]. Different from [14, 15], where the relay only amplifies and forwards the received signal, the work in [16] allowed the relay to estimate the channel parameters and allocated the powers for these parameters. The channel estimation problem was extended to the multiple antennas scene at all the three nodes in [17], and an optimal method was proposed to design the training signals based on the mean-square-error (MSE) criterion. A blind channel estimation algorithm by applying a nonredundant linear precoding at both source nodes was proposed for the frequency-selective channels in [18].
The expectation-maximization (EM) algorithm is a general method for solving maximum likelihood estimation problems given incomplete data, and it consists of two iterative steps: the expectation step and the maximization step. These two steps are iterated until the estimated values converge [19, 20]. The EM-based maximum likelihood estimation for one-way relay channel has been investigated in [21–24], where different variables are treated as the missing data and iterative process is provided for the channel estimation. To the best of our knowledge, the EM estimation algorithm in two-way relay channels has not been investigated yet.
Since the received signal at the source node in the relay-based M2M two-way communications is a superimposed signal, which can be decomposed into two signal components with two unknown channel parameters, one is the self-interference signal, and the other is the desired signal from the other source node. Take the channel estimation at source node 1, for example, the two unknown parameters are source1-relay-source1 cascaded channel and source2-relay-source1 cascaded channel. The source1-relay-source1 channel is the unobserved data when estimating source2-relay-source1 channel, while the source2-relay-source1 channel is also the unobserved data when estimating source1-relay-source1 channel. Since the superimposed signal structure at the receiver is conducive to the application of the EM algorithm and the closed-form solution of maximum likelihood channel estimation does not exist for this relay-based M2M two-way communication, the EM algorithm is utilized to provide the maximum likelihood solution in the presence of unobserved data through stable iterations.
In this paper, we propose an EM-based channel estimation algorithm for relay-based M2M two-way communication to jointly estimate the two cascaded channels. The idea is to decompose the observed data into its signal components and then estimate the parameters of each signal component separately. In the EM algorithm, the received signal at the source node is treated as the incomplete data, and the set of the two signal components from the two source nodes is modeled as the complete data. Conditioned upon the incomplete observations, the channel estimation algorithm maximizes the expectation of log likelihood function defined over the complete data, by averaging over the unknown underlying parameters and using the current estimates of the cascaded channels without channel statistical information. The algorithm iterates back and forth, using the current channel parameter estimates to decompose the received signal better and thus increase the likelihood of the next channel parameter estimates. Even in the absence of training sequence, the cascaded channel estimates can still be obtained through the iterations between the E-step and M-step. The Bayesian Cramér-Rao lower bounds are derived under random parameters for cascaded channel estimation, and the validity of the proposed studies is verified by Monte Carlo simulations.
The rest of the paper is organized as follows. Section 2 describes the three-node model in relay-based M2M networks. Section 3 presents the EM-based cascaded channel estimation algorithms. Section 4 provides the Bayesian Cramér-Rao lower bounds of the cascaded channel estimation. Simulation results and conclusion are given in Sections 5 and 6, respectively.
2. System Model
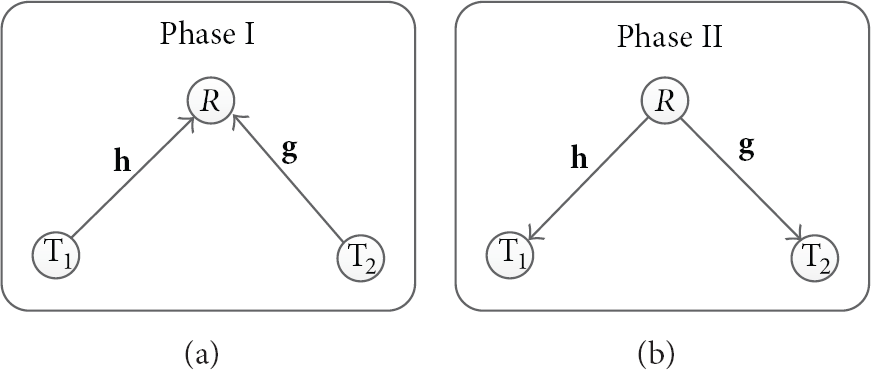
Consider a three-node cooperation model in wireless M2M networks where two source nodes, and , exchange information through one relay node R, as shown in Figure 1, which is also the model of two-way relay network. Each node has a single omnidirectional antenna and operates in half-duplex mode. The direct link between and is very weak or even nonexistent, and thus the source-destination communication is performed only via the relay. The transmission is divided into two phases. During Phase I, both and send a signal frame to R via an uplink manner, whereas during Phase II, R processes the received signals and broadcasts them to and .
Three-node cooperation model.
The baseband channel between and R is denoted by , and the one between and R is denoted by , where and are the numbers of the taps of the corresponding channel delay spread. and are independent from each other. The frequency-domain representations are and , respectively. Both h and g are assumed to remain unchanged at least for one round of data exchange. As for time-division duplexing (TDD), h and g can be considered as reciprocal. The average transmission powers of , and R are denoted as , and , respectively.
Suppose that each OFDM symbol contains N information symbols. The time-domain OFDM signals transmitted from and after inverse discrete Fourier transform (IDFT) are, respectively, given by
where and are zero-mean independent and identically distributed (i.i.d.) data with average power of . Denoting that frequency-domain , and time-domain signals , , the time-domain OFDM signals transmitted from and can be rewritten in vector-matrix form as
where F is the normalized DFT matrix whose entry is .
The time-domain symbols and go through regular OFDM transmission steps. Both and insert the cyclic prefix (CP) of length in front of the OFDM block to avoid intersymbol interference. The time-domain received signal at the relay after removal of CP and DFT is expressed as
where is the complex gain of the subcarrier of channel h, is the complex gain of the subcarrier of channel g, and is zero-mean circular complex Gaussian with the variance at the relay. The time-domain received signal at the relay can be rewritten in vector-matrix form as
where , , H is the circulant matrix whose first column is , and G is the circulant matrix whose first column is . Define as the column-wise circulant matrix with the first column x; then we have and .
After DFT, the received signal at the relay of the subcarrier is written as
where is the corresponding frequency response of the relay noise over the subcarrier with the variance .
The relay amplifies the received signal , adds a new CP, and forwards the signal to and . The relay amplification factor α is chosen as . For symmetry, only the process at is discussed. The time-domain received signal at , after CP removal, is
where is zero-mean circular complex Gaussian with variance at the receiver of . Defining the time-domain cascaded channels and , , , the time-domain received signal at can be rewritten in vector-matrix form as
where is the total noise of the receiver at .
After DFT, the received signal at of the subcarrier is written as
where is the corresponding frequency response of the relay noise over the subcarrier. The frequency-domain received signal at can be rewritten in vector-matrix form as
where Y is the corresponding frequency response of the time-domain received signal y, , , is the corresponding frequency response of the noise , and . and are the corresponding frequency responses of the time-domain cascaded channels and , , and . is the first column of the DFT matrix F, and is the first column of F. The task of cascaded channel estimation is to find and from Y.
3. The EM Algorithm Based Channel Estimation
The EM algorithm is a technique for finding maximum likelihood estimates of system parameters in a broad range of problems where observed data are incomplete [19]. The expectation step is performed with respect to unknown underlying parameters, using the current estimate of the parameters, conditioned upon the incomplete observations. The maximization step then provides a new estimate of the parameters that maximizes the expectation of log likelihood function defined over complete data, conditioned on the most recent observation and the last estimate. The EM algorithm consists of two iterative steps: the expectation step and the maximization step. These two steps are iterated until the estimated values converge [20]. When the underlying complete data come from an exponential family whose maximum-likelihood estimates are easily computed, then each maximization step of an EM algorithm is likewise easily computed.
The received signal at the source node in the relay-based M2M two-way communications is a superimposed signal, which can be decomposed into two signal components with two unknown channel parameters, one is the self-interference signal, and the other is the desired signal from the other source node. Take the channel estimation at source node 1, for example, the two unknown parameters are source1-relay-source1 cascaded channel and source2-relay-source1 cascaded channel. The source1-relay-source1 channel is the unobserved data when estimating source2-relay-source1 channel, while the source2-relay-source1 channel is also the unobserved data when estimating source1-relay-source1 channel. Since the superimposed signal structure at the receiver is conducive to the application of the EM algorithm and the closed-form solution of maximum likelihood channel estimation does not exist, the EM algorithm is utilized to provide the maximum likelihood solution in the presence of unobserved data through stable iterations.
In the EM channel estimation, the set of unknown parameters is , the received signal Y/y at is treated as the observed (incomplete) data, and the set of the two signal components from the two source nodes is modeled as the complete data. Conditioned upon the incomplete observations, the algorithm maximizes the expectation of log likelihood function defined over the complete data, by averaging over the unknown underlying parameters and using the current estimate of the parameters.
3.1. Cascaded Channel Estimation Based on Frequency Domain Processing
The frequency-domain received signal Y at , also the incomplete data, can be written as
A natural choice for the complete data is obtained by decomposing the observed data Y into its signal components:
where is the component of the received signal Y transmitted by the source node through the channel with impulse response , is the component of the received signal Y transmitted by the source node through the channel with impulse response . and are obtained by arbitrarily decomposing the total noise into two components:
It is found to be most convenient to let and be statistically independent, zero-mean, and Gaussian with the covariance matrix and , respectively. Denote the covariance matrix of as ; then .
The log-likelihood of the complete data is
where c contains all the terms that are independent of and the mean vector and the covariance matrix Λ are given, respectively, by
where and are both real numbers, , , and .
Suppose that denotes the current value of after i iterations of the EM algorithm. The iteration can be described in two steps as follows.
(1) E-step: given the observations Y and the last estimates , compute the expectation of the log-likelihood of the complete data , which is also the conditional expectation of (13),
where d contains all the terms that are independent of , and the estimate of the conditional expectation of the complete data is [25]
contains both the unknown variable and the known constant . The conditional expectations of and are given, respectively, by
(2) M-step: maximize the conditional expectation of the log-likelihood of the complete data ,
which is equivalent to solve
We obtain
The new estimates are utilized in the E-step of the next iteration to update and . Each iteration cycle increases the likelihood until convergence is accomplished.
The most striking feature of the algorithm is that it decouples the multiple-input channel estimation problem into two separate single-input channel estimation problems, a much more palatable problem. Therefore, the complexity of the channel estimation algorithm is essentially unaffected by the assumed number of signal components. Since F and are DFT matrices and and are diagonal matrices, the matrix inversion operation is relatively simple.
3.2. Cascaded Channel Estimation Based on Time Domain Processing
The time-domain received signal y at can be written as
A natural choice for the complete data is obtained by decomposing the observed data y into its signal components:
where is the component of the received signal y transmitted by the source node through the channel with impulse response , is the component of the received signal y transmitted by the source node through the channel with impulse response , and and are obtained by arbitrarily decomposing the total noise into two components:
Let and be statistically independent, zero-mean, and Gaussian with the covariance matrix and , respectively. Denote the covariance matrix of as ; then .
The log-likelihood of the complete data is
where c contains all the terms that are independent of and the mean vector and the covariance matrix Λ are given, respectively, by
where and are both real numbers, , , .
Suppose that denotes the current value of after i iterations of the EM algorithm. The iteration can be described in two steps as follows.
(1) E-step: given the observations y and the last estimates , compute the expectation of the log-likelihood of the complete data , which is also the conditional expectation of (24),
where d contains all the terms that are independent of and the estimate of the conditional expectation of the complete data is [23]
The conditional expectations of and are given, respectively, by
(2) M-step: maximize the conditional expectation ,
We obtain
The new estimates are utilized in the E-step of the next iteration to update and . Each iteration cycle increases the likelihood until convergence is accomplished.
3.3. Cascaded Channel Estimation without Training Sequence
In Sections 3.1 and 3.2, the channel estimate is continuously updated by transmitting pilot symbols using specified time-frequency lattices. When no training sequence is available and signals are still to be detected from the observations, the EM algorithm is applied to take an average over the unknown channel impulse response for reducing bit errors caused by uncertainty in the channel. Here no training sequence means that the source node only knows its own signals , while is completely unknown to .
The selection of the complete data is the same as Section 3.1, and the log-likelihood of the complete data is the same as (13).
Suppose that denotes the current value of after i iterations of the EM algorithm. The iteration can be described in two steps as follows.
(1) E-step: given the observations Y and the last estimates , compute the expectation of the log-likelihood of the complete data , which is the conditional expectation of (13)
where d contains all the terms that are independent of and the estimate of the conditional expectations of and are given, respectively, by [23]
where is the estimate of in the iteration,
where is the estimate of in the iteration and is the estimate of . and are different points in the constellation of , and is the probability of .
(2) M-step: maximize the conditional expectation ,
We obtain
The new estimates are utilized in the E-step of the next iteration to update and . Each iteration cycle increases the likelihood until convergence is accomplished.
4. The Bayesian Cramér-Rao Lower Bound
For many practical estimation problems, optimal estimators such as the maximum-likelihood estimator, maximum a posteriori estimator or minimum mean square error estimator are infeasible, so suboptimal estimators are needed, which are typically evaluated by determining MSE through simulations and comparing this error to theoretical performance bounds. In particular, the family of Cramér-Rao lower bounds (CRLBs) has been shown to give tight estimation lower bounds in a number of practical scenarios [26–29].
The CRLB for the estimation of deterministic parameters is given by the inverse of the Fisher information matrix (FIM), and Van Trees derived an analogous bound to the CRLB for random variables, referred to as “Bayesian CRLB” [30]. Unlike the standard and modified CRLBs, the statistical dependence is naturally considered within the Bayesian CRLB framework. With the assistance of Bayesian CRLB, the performance of the suboptimal estimators can be assessed, and the optimal training design could be obtained.
Denoting , the corresponding FIM is defined as
where the expectation is taken over the joint probability . The Bayesian CRLB is the lower bound of any error covariance matrix ,
Lemma 1.
The FIM can be calculated as
where and are the covariance matrices of and , respectively, , .
Proof.
See Appendix.
It indicates that the Bayesian CRLB is the inverse of the FIM 𝒥, and 𝒥 is a block matrix. If 𝒥 can be simplified to a diagonal matrix, then the inverse operation becomes simple. Therefore, when calculating the Bayesian CRLB, we may assume that and are orthogonal to each other, which means and , and 𝒥 is simplified to a diagonal matrix. The Bayesian CRLBs for and can be, respectively, expressed as
The channel error covariance matrices are lower bounded by
Furthermore, the channel estimation MSEs are lower bounded by
5. Simulations
In this section, we provide numerical results to verify our studies in the relay-based M2M two-way communications, and only the channel estimation at is considered because of symmetry. For simplicity, is assumed, the noise variance is set as 1, and SNR is defined as . In all simulations, the QPSK modulation is applied, and the OFDM symbol length is taken as . The channel delay spread taps are set as , and all channel taps have unit variances. All the simulation results are averaged over Monte-Carlo runs, and between Monte-Carlo runs, independent realizations of noise, input, and channels are used. The random initialization of and is utilized as the initial value of the EM algorithm. The normalized estimation mean square errors (NMSE) is adopted as the figure of merit to evaluate the channel estimation accuracy:
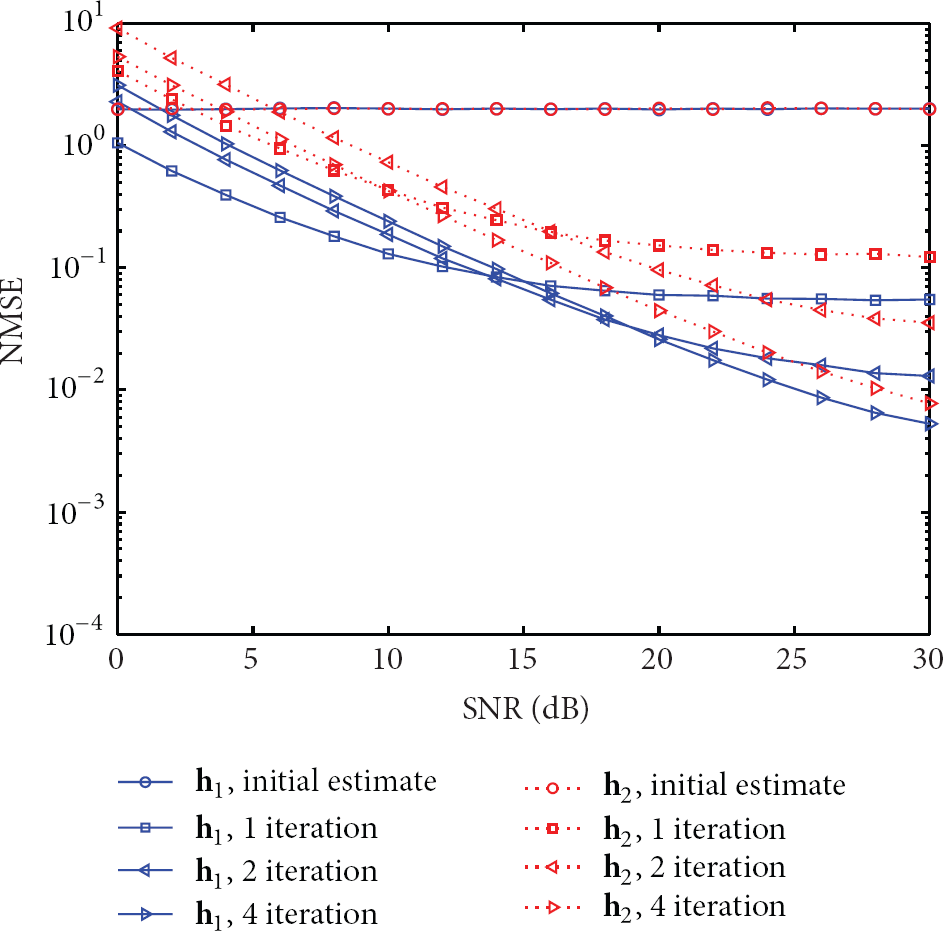
For cascaded channel estimation based on frequency domain processing at , the NMSE performance against SNR and number of iterations are shown in Figures 2 and 3, respectively. We can see that (1) the EM-based algorithm improves the estimation accuracy by iteratively refining the cascaded channel estimates and finally approaches the corresponding maximum likelihood solutions. After 4 iterations, the NMSEs of both and improve a lot from the initial estimates. The improvement in the first iteration is the most significant, and the improvement in the following iterations slows down. (2) The NMSE curve of estimation almost coincides with the NMSE curve of estimation completely. This is because in the cascaded channel estimation, and are symmetrical, so the estimation performance of and are the same. (3) The impact of iteration number on the NMSE performance is shown in Figure 3. Here we take the estimation of for example. In different SNR conditions, EM algorithm converges to the maximum likelihood solution within 10 iterations. When SNR is relatively low, the convergence of the EM algorithm is relatively fast. As SNR increases, the required iterations for convergence to the maximum likelihood solution increase accordingly.
Channel estimation NMSE versus SNR.
Channel estimation NMSE versus number of iterations.
For cascaded channel estimation based on time domain processing at , the NMSE performance against SNR and number of iterations are shown in Figures 4 and 5, respectively. The NMSE curves demonstrate the same trend with Figures 2 and 3.
Channel estimation NMSE versus SNR.
Channel estimation NMSE versus number of iterations.
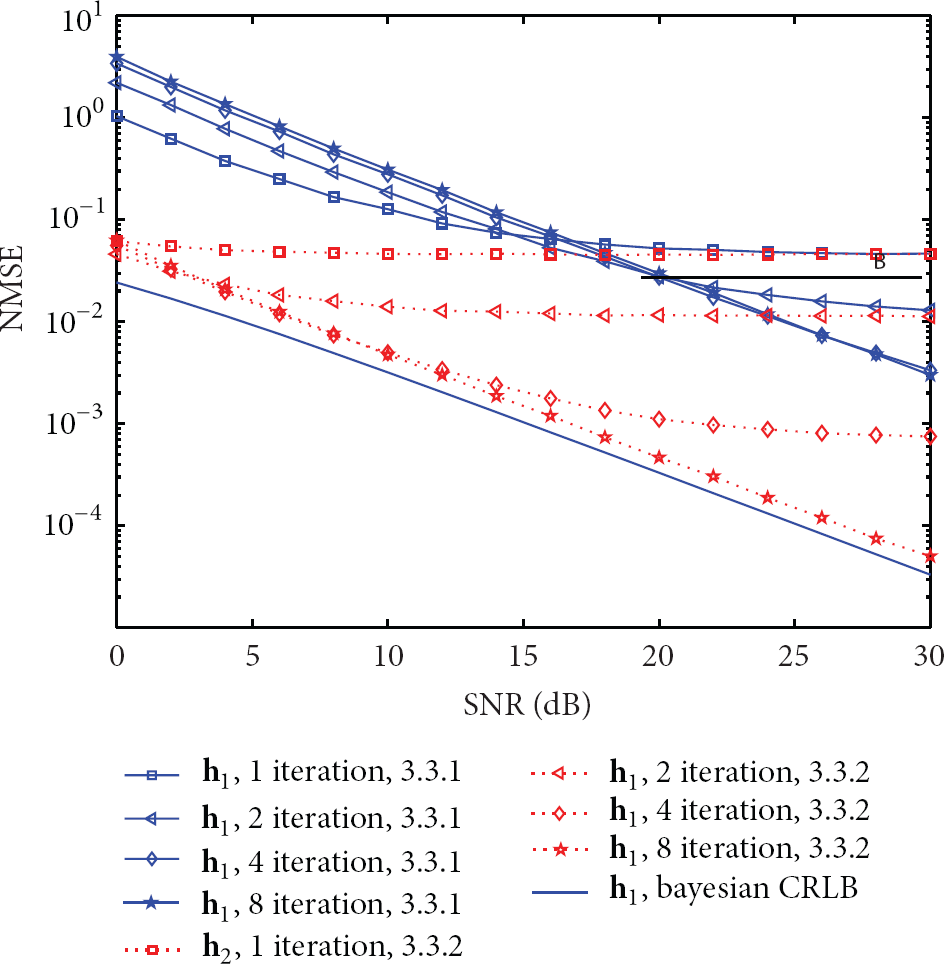
Figure 6 shows the NMSE performance comparison between the frequency domain processed estimation and the time domain processed estimation. The Bayesian CRLBs are exactly the same for the estimation of and , which are also plotted to measure the NMSE performance. We can see that (1) the frequency domain processed estimation converges to the maximum likelihood solution after 4 iterations, while the time domain processed estimation converges to the maximum likelihood solution after 8 iterations. When the number of iterations is the same, the estimation results of the time domain process are more accurate than the results of the frequency domain process and more close to the corresponding Bayesian CRLB.
Channel estimation NMSE versus SNR.
Figure 7 shows the NMSE performance comparison of the time domain processed estimation, when the power allocation between the subcarriers is not equal. The training sequences and are subject to the following constraints. For , the power for subcarriers from 1 to 32 is halved, while the power for subcarriers from 33 to 64 increases to 1.5 times the original value. The power allocation between subcarriers is just the opposite for . We can see that, compared with Figure 4, the unequal power allocation almost causes no change in the NMSE performance.
Channel estimation NMSE versus SNR.
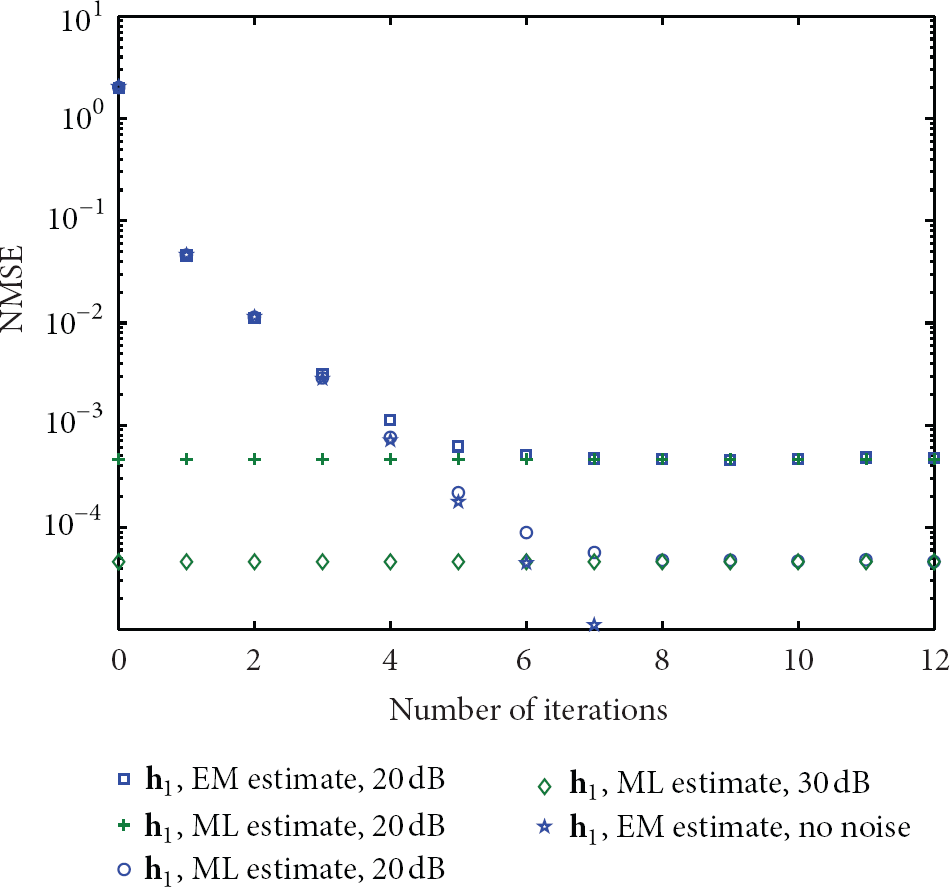
Figure 8 shows the NMSE performance of cascaded channel estimation without training sequence. We can see that the EM-based algorithm improves the estimation accuracy by iteratively refining the cascaded channel estimates. However, since is unknown to the receiver at , the convergence is slower than the counterpart in Figure 2. Moreover, the NMSE performance of estimation is worse than the NMSE performance of estimation, due to the inaccurate estimates of . With the increase of the number of iterations, the channel estimation results become more and more accurate, the estimates of becomes more and more accurate accordingly, which further improves the accuracy of channel estimation in turn.
Channel estimation NMSE versus SNR.
If it is possible to select a more accurate initial value to enable the EM iterations in the relay-based M2M two-way communications, the speed of convergence can be accelerated, and the performance of channel estimation can be further improved.
6. Conclusion
In this paper, we have investigated the EM-based cascaded channel estimation algorithm in relay-based M2M two-way communications, which converts the multiple-input channel estimation problem into two separate single-input channel estimation problems, leading to a considerable simplification in the computations involved and increasing the possibility of the realization of M2M communications. In the EM algorithm, the received signal at the source node is treated as the incomplete data, and the set of the two signal components from the two source nodes is modeled as the complete data. Conditioned upon the incomplete observations, the algorithm maximizes the expectation of log likelihood function defined over the complete data, by averaging over the unknown underlying parameters and using the current estimates of the cascaded channels. The algorithm iterates back and forth, using the current channel parameter estimates to decompose the received signal better and thus increase the likelihood of the next channel parameter estimates. Even in the absence of training sequence, the cascaded channel estimates can still be obtained through the iterations between the E-step and M-step. The Bayesian Cramér-Rao lower bounds have been derived under random parameters for cascaded channel estimation. The proposed method works well without channel statistical information, and the simulation demonstrates good agreement of the theoretical lower bound and the practical estimation performance.
Footnotes
Appendix
Acknowledgments
This research was partly supported by the National Science Foundation of China (Grant no. NFSC 61071083, and 61371073) and the National High Technology Research and Development Program of China (863 Program no. 2012AA01A506).
References
1.
ChoH.PuthenkulamJ.Machine to Machine (M2M) Communication Study ReportIEEE 802.16ppc-10/0002r6, May 2010
2.
Harbor Research ReportMachine-To-Machine (M2M) & Smart SystemsForecast 2010-2014, 2009
3.
3GPP Technical ReportSystem improvements for machine-type communications (release 10)TR 23.888, July 2010
4.
AndreevS.GalininaO.KoucheryavyY.Energy-efficient client relay scheme for machine-to-machine communicationProceedings of the 54th Annual IEEE Global Telecommunications Conference (GLOBECOM '11)December 20112-s2.0-8485720398810.1109/GLOCOM.2011.6133603
5.
GerasimenkoM.PetrovV.GalininaO.Impact of machine-type communications on energy and delay performance of random access channel in LTE-advancedTransactions on Emerging Telecommunications Technologies201324436637710.1002/ett.2631
6.
LiuT.SongL.LiY.HuoQ.JiaoB.Performance analysis of hybrid relay selection in cooperative wireless systemsIEEE Transactions on Communications20126037797882-s2.0-8485834250510.1109/TCOMM.2012.011312.110015
7.
HuoQ.SongL.LiY.JiaoB.A distributed differential space-time coding scheme with analog network coding in two-way relay networksIEEE Transactions on Signal Processing201260949985004
8.
RankovB.WittnebenA.Achievable rate regions for the two-way relay channelProceedings of the IEEE International Symposium on Information Theory (ISIT '06)July 2006166816722-s2.0-3904911459610.1109/ISIT.2006.261638
9.
PopovskiP.YomoH.Physical network coding in two-way wireless relay channelsProceedings of the IEEE International Conference on Communications (ICC '07)June 20077077122-s2.0-3854917507010.1109/ICC.2007.121
10.
CuiT.HoT.KliewerJ.Memoryless relay strategies for two-way relay channels: Performance analysis and optimizationProceedings of the IEEE International Conference on Communications (ICC '08)May 2008113911432-s2.0-5124909408410.1109/ICC.2008.222
11.
SongL.LiY.HuangA.JiaoB.VasilakosA. V.Differential modulation for bidirectional relaying with analog network codingIEEE Transactions on Signal Processing2010587393339382-s2.0-7795374455010.1109/TSP.2010.2046441
12.
SongL.HongG.JiaoB.DebbahM.Joint relay selection and analog network coding using differential modulation in two-way relay channelsIEEE Transactions on Vehicular Technology2010596293229392-s2.0-7795460262310.1109/TVT.2010.2048225
13.
GaoF.ZhangR.LiangY.-C.Optimal channel estimation and training design for two-way relay networksIEEE Transactions on Communications20095710302430332-s2.0-7035050464510.1109/TCOMM.2009.10.080169
14.
GaoF.ZhangR.LiangY.-C.Channel estimation for OFDM modulated two-way relay networksIEEE Transactions on Signal Processing20095711444344552-s2.0-7035049618710.1109/TSP.2009.2026537
15.
YangW.CaiY.HuJ.YangW.Channel estimation for two-way relay OFDM networksEurasip Journal on Wireless Communications and Networking201020102-s2.0-7824928783010.1155/2010/186182186182
16.
JiangB.GaoF.GaoX.NallanathanA.Channel estimation and training design for two-way relay networks with power allocationIEEE Transactions on Wireless Communications201096202220322-s2.0-7795326710910.1109/TWC.2010.06.090870
17.
PhamT.-H.LiangY.-C.NallanathanA.GargH. K.Optimal training sequences for channel estimation in bi-directional relay networks with multiple antennasIEEE Transactions on Communications20105824744792-s2.0-7694908734510.1109/TCOMM.2010.02.080431
18.
LiaoX.FanL.GaoF.Blind channel estimation for OFDM modulated two-way relay networkProceedings of the IEEE Wireless Communications and Networking Conference (WCNC '10)April 20102-s2.0-7795501465910.1109/WCNC.2010.5506621
19.
DempsterA. P.LairdN. M.RubinD. B.Maximun likelihood estimation from incomplete dataJournal of the Royal Statistical Society1977391138
20.
MoonT. K.The expectation-maximization algorithmIEEE Signal Processing Magazine199613647602-s2.0-003028704810.1109/79.543975
21.
SheuJ.-S.SheenW.-H.An EM algorithm-based channel estimation for OFDM amplify-and-forward relaying systemsProceedings of the IEEE International Conference on Communications (ICC '10)May 20102-s2.0-7795540216010.1109/ICC.2010.5502100
22.
LioliouP.VibergM.MatthaiouM.Bayesian channel estimation techniques for AF MIMO relaying systemsProceedings of the IEEE 74th Vehicular Technology Conference (VTC Fall '11)September 20112-s2.0-8375517075710.1109/VETECF.2011.6093283
23.
LioliouP.VibergM.MatthaiouM.Bayesian approach to channel estimation for AF MIMO relaying systemsIEEE Journal on Selected Areas in Communications201230814401451
24.
ZhangC.TangS.RenP.EM algorithm based channel estimation for amplify-and-forward relay networks with unknown noise correlationProceedings of the IEEE Vehicular Technology Conference (VTC Fall '12)September 20121510.1109/VTCFall.2012.6398964
25.
GeoffreyG.DavidS.Probability and Random Processes20013rdOxford University PressISBN 0-19-857222-0
26.
Van TreesH. L.Detection, Estimation, and Modulation Theory1968New York, NY, USAWiley
27.
SeidmanL. P.Performance limitations and error calculations for parameterestimationProceedings of the IEEE19705856446522-s2.0-0014712123
28.
ZivJ.ZakaiM.Some lower bounds on signal parameter estimationIEEE Transactions on Information Theory1969153386391
29.
MillerR. W.ChangC. B.A modified Cramr-Rao bound and its applicationsIEEE Transactions on Information Theory19782433984002-s2.0-0017972132
30.
Gill and LevitApplications of the Van Trees Inequality: The Bayesian Cramr-Rao Bound1995Bernoulli