
Abstract
Mobility is a common character of the emerging RFID-based internet-of-things. However, most of prior RFID anticollision algorithms ignore the movement of tags, which can degrade the identification performance seriously and even result in tag starvation problem. This paper presents a novel anticollision algorithm named Query Splitting-based Anticollision (QSA) for mobile RFID-based internet-of-things. By designing adaptive query, QSA reduces the number of collisions efficiently and makes it possible to identify multiple mobile tags without rollback. In QSA, we propose a query stack technology to avoid the rollback operation caused by new arriving tags, which solves the tag starvation problem under mobile environments. The performance evaluation shows that the proposed algorithm takes fewer timeslots and has better performance in identifying mobile tags.
1. Introduction
Radio frequency identification (RFID) is a contactless wireless communication technology. The scope for using this technology boosts as RFID tag becomes a low-cost device due to mass production [1]. As the rapid proliferation of RFID tags, it has given rise to various concepts that integrate the physical world with the virtual one. One of the most popular concepts is the Internet-of-Things (IoT), a vision in which the Internet extends into physical entities. In the IoT, RFID is the foundation to connect the things together [2].
RFID systems consist of a reading device called reader, and multiple tags which are attached to physical entities in the IoT. The reader is typically a powerful device with ample memory and computational resources. On the other hand, tags vary significantly in their computational capabilities. Among tag types, passive ones are emerging to be a popular choice for large scale deployments due to their low cost [3]. For passive tags, they respond only at reader commands with the energy provided by the reader [2, 4].
In RFID systems, the reader usually needs to communicate with multiple tags. If there are multiple tags in a reader's interrogation zone, the reader receives the responses from these tags simultaneously. For a reader, it is not able to distinguish exact information from the interfered wireless signals, which is called collision. Collision is a serious problem in RFID systems since the reader will not receive the messages rightly once collision occurs [5]. An example is shown in Figure 1. Simultaneous responses transmitted by multiple tags collide, resulting in an increase of identification delay, even failure of reading the tags. Therefore, an efficient anticollision algorithm is required to reduce collisions and to achieve fast identification.

The tag collision with mobile tag.
The tag collision problem becomes more serious in mobile RFID-based IoT. The physical entities with tags are often mobile, which facilitates competitive advantage through benefits such as improved efficiency, increased visibility, reduced cost, and many others [6]. The mobile devices can be part of numerous products, gadgets, and vehicle parts [7]. These devices close the gap between the real word and its virtual representation via, for example, seamless identification and integration with other wirelessly-embedded devices and their surroundings.
However, the mobile devices result in new challenges for anticollision problem. One of the challenges is tag starvation. For example, as shown in Figure 1, the reader is processing the collision caused by Tag 1 to Tag N. Assuming the reader has partitioned the tags for several rounds and will identify one tag out right now. If Tag
In this paper, we will deal with the “tag starvation” and performance problem for anticollision in mobile IoT. By the design of query stack and query rules, the proposed anticollision algorithm avoids repetition operations and decreases the collisions consequently. In summary, our contributions include the following.
We characterize the problem of anticollision in mobile environment, which is more practical for the emerging IoT technology. We propose a novel anticollision algorithm named Query Splitting-based Anticollision (QSA) for mobile RFID-based IoT, which solves the problem of tag starvation and performance degradation resulted from the tag mobility. Simulation and analysis evaluate the efficiency of the proposed algorithm. The results show the better performance of the proposed algorithm to the prior methods.
The rest of this paper is organized as follows. Section 2 outlines preliminary, includes background, related work. Section 3 presents the problems for mobile tags. Section 4 gives the detailed design of our algorithm. The simulation results are provided in Section 5. Finally, Section 6 concludes the paper.
2. Preliminary
2.1. Collision Detection
Code technologies are widely used for collision detection. Manchester code is one of the most popular technologies for RFID systems [5]. In Manchester code, the value of one bit is defined as the voltage transition within a bit window. A bit “0” is coded by a positive transition, while a bit “1” is coded by a negative transition. In RFID systems, if two (or more) tags transmit different values simultaneously, the positive and negative transitions of the received bits cancel each other out. This state is not permissible in Manchester code during data transmission and is recognized as an error. Therefore, Manchester code makes it possible to “trace a collision to an individual bit” and “find where the collided bit is” [8].
Figure 2 shows an example of Manchester code for collision detection. The IDs of tag 1 and tag 2 are “10101100” and “10001001,” respectively. When tags 1 and 2 send their IDs simultaneously using Manchester code, the decoded data from the interfered signal received by the reader is “

Collision detection with Manchester code.
Manchester code can be utilized to detect the collision bits, but the tags should be strictly synchronized. Fortunately, the tags in passive RFID systems are all driven by the reader with both energy and the same clock frequency.
2.2. Anticollision Algorithms
Many researches have focused on the issue of anticollision including tag-driven and reader driven procedures [9]. Tag-driven anticollision protocols function asynchronously [5]. For example, in Aloha-based protocols [10], time is divided into slots and each tag randomly transmits its ID in each timeslot. The tags continuously retransmit their IDs until the reader acknowledges their transmission. However, the Aloha-based protocols have several serious problems. For example, a specific tag may not be identified for a long time, leading to the so-called “tag starvation” problem. The performance of Aloha-based protocols is sensitive to the number of tags. Furthermore, it is very difficult to predict the number of tags in mobile environments, if not impossible.
For reader-driven anticollision protocols, they function synchronously, since all tags are controlled and checked by the reader simultaneously. Therefore, the reader can avoid tag starvation under static environments. Furthermore, they can be categorized into Binary Tree algorithm (BT) [11–13] and Query Tree algorithm (QT) [14–16].
2.2.1. Binary Tree Algorithm (BT)
BT performs collision resolution by splitting collided tags into disjoint subsets. These subsets become increasingly smaller until they contain one tag. Each tag has a random binary number generator. For example, in Figure 3, tags with a counter value of zero are considered to be in the transmit state; otherwise, tags are in the sleep state. After each timeslot, the reader informs tags whether there is a collision or not. If there was a collision, each tag in the transmit state generates a random binary number. Tags will become in sleep state after being identified.

Binary tree based anticollision procedure.
As can be seen that the average number of timeslots to identify the first tag is

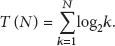
The time consumption is the most serious defect since it has not recorded the history information, which results in a large amount of repeat operations.
2.2.2. Query Tree (QT)
Query tree (QT) algorithms store tree construction at the reader, and tags only need to have a prefix matching circuit. The reader transmits a serial number to tags, which they then compare against their IDs. The tags whose IDs equal to or lower than the serial number respond to the reader's command. The reader then monitors tags reply bit by bit using Manchester code, and once a collision occurs, the reader splits tags into subsets based on collided bits. The reader then transmits another query by replacing the most significant collided bit with “0” and sets the other bits to “1.” This procedure stops until a single tag has been selected out.
Rollback Query Tree (RQT) is proposed to reduce the average number of timeslots for identifying the tags. During the partition operation, these records are saved at the reader. Thus, the anticollision can avoid the repeating operations based on the saved information when the reader tries to select out the next tag. The timeslot number of RQT is

3. Problem for Identifying Mobile Tags
In static environments, Rollback Query Tree reduces the number of timeslots to deal with collision in RFID systems. However, both tag starvation and delay problems occurred in mobile environments. If one tag enters the reader's interrogation zone when the reader is processing the entered tags, some obtained results might be destroyed by the new arrived tag. The total number of identifying tags is

If the increased time is greater than the interval time between the arriving tags, the existing tags might not be processed in a long time since the reader has to reexecute the rollback operations for the new arrived tags. Therefore, tags starvation problem will happen if the following condition is met:

In the following, we take an example to illustrate the rollback caused by a new arriving tag. As shown in Figure 4, there are already four tags (IDs: 10100011, 11100010, 11100011, and 11110010) in the reader's interrogation zone. After two rounds of query (named

Rollback problem for the new arrived tag.
4. QSA: Query Splitting-Based Anticollision for Mobile IoT
4.1. Overview of the Anticollision Algorithm
Firstly, a set of queries Broadcast the current query in Q to all tags. When receiving the responses from tags:
if the reply is string w without “x” bits, then select and process the tag with ID w; if a collision is detected; that is, the reply is string w with “x” bits, then set the next query in Q; if there is no reply from tags, do nothing. Update Q according to the received responses.
Repeat the above procedure until Q is empty. In this procedure, four commands (REQUEST, SELECT, READ-DATA, and DESELECT) are adopted as defined in Table 1.
Definition of commands.

For tags, let
As can be seen from the above procedure that the key problem is how to design the query scheme, our main idea is to keep the history records which can avoid rollback of the done operations.
4.2. Design of Adaptive Query
4.2.1. Query Stack Design for Rollback Operation
As shown in Table 1, REQUEST is the query command for the reader to split tags into subsets. To reduce the total timeslots for identifying all tags, we design a query stack structure to implement the rollback operations during query process. “Push Query” and “Pop Query” are the two basic operations of query stack. Each query response is pushed into query stack if and only if the response includes “x.”
We also take the example in Figure 4 to explain the stack operation. The response is “

Query stack for new arrived tags.
Once a response includes no “x,” the reader will select this tag (using the command SELECT as shown in Table 1) and read the selected tag (using the command READ-DATA as shown in Table 1). After that, the reader will pop one element from the query stack. For example, when the new arrived tag “01100011” has been processed, the element “
4.2.2. Rule Design for Query Condition
The rule for query command is one of the most important designs in QSA. As shown in Table 2, the rules can be presented as two kinds. One is for the obtained response, and the other is for the pop stack.
Rule design for query condition.

( 1) Rule for Obtained Response. When the reader receives response including “x” bits, the next query condition should be set according to the collision bits in the response. The second line in Table 2 shows the rule for this kind of obtained response.
In the first iteration, all bits are set as “1,” that is, Max(ID), to collect the responses from all tags. For example, the parameter is “11111111” for eight bits ID. In the following iteration, the highest bit “x” is set as “0”; the bits which are lower than the highest “x” are all set as “1.” According to the setting of “x” bits, we can draw the following theorem.
Theorem 1.
Rule for obtained response implements binary splitting for multiple tags.
Proof.
The response is a string 
Then, there is at least one tag whose kth bit is “1” and at least one tag whose kth bit is “0.” Otherwise, the kth bit cannot be “0.” Therefore, REQUEST “≤
This rule can reduce the query scope by dividing the responding tags into two catalogs until only one tag respond.
( 2) Rule for Pop Stack. After one tag is selected and processed, the top element is popped out. This element includes “x” bit. The rule for pop stack deals with the problem of setting these bits, which is shown in the third line of Table 2. Note that it cannot be the first iteration in anticollision process (“cannot happen” in Table 2) since the stack is empty at the beginning.
To the popped element, there are two situations: without new arrived tag and with arrived tag when it pushed into the stack. For the situation without new arrived tag, all bits are set as “1” in order to include all unprocessed tags; that is,
Whether there is new arrived tag or not, it can be judged according to the following formula:

Theorem 2.
If the highest “x” bit of the first stack element is higher than that of the second stack element, that is, the condition of formula (7) is met, there must be new arrived tag.
Proof.
According to rule for obtained response, the reader first processes the tags whose highest “x” bit is “0.” Therefore, only when the higher “x” bit is processed, it is possible for lower “x” to be processed. Thus, the highest “x” always decreases as the distance to the top of query stack. However, it is possible that the “x” can be at any bit if new tags arrive. That is to say, formula (7) is a result caused by new arrived tags.
For example, as shown in Figure 5, the highest “x” bit in the top stack element Stack_3 is 8, and that in Stack_2 is 1. Formula (7) meets and there is new arrived tag. In the example, the query for Stack_2 element “
4.3. The Procedure of the Proposed QSA
Based on the design of query stack and query rule, we describe the procedure of the proposed QSA algorithm in the following. In QSA, the reader first broadcasts the query with the parameter (max_ID) and receives the replies from all tags in its interrogation zone. If the received response of this query includes “x,” the tree can be divided into the left subtree and the right subtree according to the highest bit “x.” In the left subtree, the highest “x” bit is “0,” and that of the right tree is “1.” The procedure of the anticollision algorithm is shown in Figure 6. It mainly includes three parts: process the left subtree, process the right subtree, and read one tag.

Flow chart of the proposed QSA algorithm.
4.3.1. Process the Left Subtree
If there is “x” in the received response, the reader begins to process the left subtree. Firstly, the reader pushes the response which has “x” bits into the query stack. We design this query stack which can record the entrance to the right subtree. Then, it sets the query condition according to the rule for obtained response in Table 2. Finally, the reader broadcasts the query with the set condition, which enables a new round communication.
4.3.2. Read One Tag
If the received response has no “x” bit, there is no collision and a single tag is identified. The reader will select this tag and read data from it. After the tag is processed, command “DESELECT” will make this tag keep silent state in the following.
4.3.3. Process the Right Subtree
After one tag is read, the algorithm will begin to process the right subtree. Firstly, the top element of the query stack is popped out, and it is set according to the rule for pop stack. As described in previous Section, there are two possibilities, that is, with new arrived tag and without new arrived tag when setting the query condition. If there is new tag which causes higher “x” bit, the query will enter the left tree process after receiving the response. Otherwise, the process will further deal with the right subtree. Note that the process will end until the query stack is empty, which means that all tags have been identified already.
5. Simulation Results
To evaluate anticollision performance, we compare the time consumption and identification efficiency of the proposed QSA algorithm with that of two representative schemes Query tree (QT) and Rollback Query Tree (RQT). Under mobile environments, we measure the number of timeslots used to read out all tags. Firstly, we fix mobile velocity of the tags and evaluate the results. The mobile velocity of tags is set as the following rule: a group of five tags enter the reader's interrogation zero at the interval of five timeslots.
Figure 7 shows the results of collision numbers under various numbers of tags. As can be seen that QT meets the most number of collisions, since it has not recorded the query results during the procedure of finding the least tag ID. RQT always takes more collisions than the proposed QSA algorithm, which is consistent with formula (4). Both 64 bits and 128 bits tag ID in Figures 7(a) and 7(b), the proposed QSA takes the least number of collisions, which illustrates the efficiency of the QSA since it overcomes the rollback operations when new tags arrive.

The number of collisions versus various numbers of tags. (a) Tag ID is 64 bits; (b) tag ID is 128 bits.
To identify the tags as soon as possible, the algorithm should keep high identification efficiency. Identification efficiency is defined as the ratio of the number of success timeslots to the total timeslot number. Higher identification efficiency means less wasted timeslots for collisions. Figure 8 describes the comparison of identification efficiency between RQT and the proposed QSA. The identification efficiency of QSA is higher than that of RQT. It validates the analysis of number of consumed timeslots in Figure 7(a). The identification efficiency of the proposed QSA especially decreases slowly as the tag number increases. While the RQT is of lower identification efficiency when the tag number increases. For example, the identification efficiency of the RQT is below 45% when the tag number is 300.

Identification efficiency.
From the theoretical analysis, it can be known that the mobile velocity will affect the results of collisions. Finally, we evaluate the impact of tag mobile velocity. In this experiment, total 200 tags enter the reader's interrogation zone at different intervals, which varies from 1 to 5 timeslots. The same with the above experiments, five tags come into the reader's interrogation zone at a pointed timeslot. As can be seen from Figure 9, the proposed QSA achieves the least number of collisions under all intervals of entering tags. An interesting change happens in QT scheme: the collision number increases firstly and then decreases. It is because the tag number increases quickly at the smaller interval of entering tags, which causes more collisions. The gap between RQT and the proposed QSA increases as the interval increases. It indicates that the velocity of mobile tags will cause different rollback operations in RQT, while it is eliminated in our QSA algorithm.

The number of collisions versus various mobile velocities.
6. Conclusions
Collision is considered as one of the most important issues that affect the identification process in RFID systems. Mobile tags of IoT especially induce new problems such as performance degrade and tag starvation. In this paper, we propose a novel anticollision algorithm named QSA to solve these problems. The proposed QSA can overcome the problems resulted from mobile tags efficiently. Compared to prior schemes, the QSA presents a better performance at different mobile velocity and various tag numbers.
Footnotes
Acknowledgments
This work is supported in part by the National Natural Science Foundation of China under Grant nos. 61106036, 61173169, and 61272147, in part by the science and technology projects of Hunan province, and in part by State Key Laboratory of Computer Architecture, Institute of Computing Technology, Chinese Academy of Sciences.