
Abstract
One of the fundamental requirements for visual surveillance using nonoverlapping camera networks is the correct labeling of tracked objects on each camera in a consistent way, in the sense that the observations of the same object at different cameras should be assigned with the same label. In this paper, we formulate this task as a Bayesian inference problem and propose a distributed inference framework in which the posterior distribution of labeling variable corresponding to each observation is calculated based solely on local information processing on each camera and mutual information exchanging between neighboring cameras. In our framework, the number of objects presenting in the monitored region does not need to be specified beforehand. Instead, it can be determined automatically on the fly. In addition, we make no assumption about the appearance distribution of a single object, but use “similarity” scores between appearance pairs as appearance likelihood for inference. To cope with the problem of missing detection, we consider an enlarged neighborhood of each camera during inference and use a mixture model to describe the higher order spatiotemporal constraints. Finally, we demonstrate the effectiveness of our method through experiments on an indoor office building dataset and an outdoor campus garden dataset.
1. Introduction
Recently, there has been increasing research interest in wide-area video surveillance based on smart camera networks with nonoverlapping Field of View (FOV). The cameras in the networks are not only able to capture video data, but also capable of local processing and mutual communication. They usually work cooperatively for discovering and understanding the behavior of some interested objects, for example, pedestrians and vehicles, in the monitored region. One of the fundamental prerequisite for achieving this goal is the correct labeling of the observations of objects captured by each camera nodes in a consistent way. That is, the observations assigned with the same label are assumed to be generated form the same object. In this paper, we assume that the detection and tracking problem within a single camera view has been already solved, and we call some interested quantities extracted from the tracked object as a virtual “observation;” see Figure 2.
Consistent labeling of tracked objects in nonoverlapping camera networks is, however, a rather challenging task. First, the object's appearance often undergoes large variations across disjoint camera views due to significant changes in view angle, lighting, background clutter, and occlusion. The different objects may appear more alike than that of the same object across different views. This makes the labeling of objects based solely on appearance cues to be very difficult. Second, for large scale application, it is unrealistic to transmit all video data collected by cameras in the networks to a central server for labeling inference due to the limitation of communication bandwidth and camera node energy. Even through smart camera can analyse the local video and transmit only extracted features, the central server will become overwhelmed quickly when the number of objects and measurements increases because of the combinatorial nature of labeling problem. Thus, distributed algorithms are preferred rather than centralized one. Third, the uncertainty in the number of objects presenting in the monitored region makes the labeling problem even more difficult, as we should infer not only the label for each tracked object but also the number of possible labels, that is, how many objects are moving in the region, at the same time.
1.1. Related Works
A lot of works have been proposed to answer the above challenges. In the community of object reidentification research, huge amounts of efforts [3–8] are devoted to matching objects across different views based on the unreliable appearance measurements. However, the results are still far from satisfactory and the outputs of reidentification algorithms are always in the form of a list of top ranked candidates, which can not be used directly for consistent labeling. Recently, some works have been shown [9] in which spatiotemporal cues, such as the capturing time and moving direction, are exploited to improve matching accuracy. But in [9], the authors only consider matching problem between a pair of views, and extending it to camera networks is not a trivial matter.
The problem of consistent labeling in camera networks using both appearance and spatiotemporal cues has been widely investigated, under the name of data association [1, 10], trajectory recovery [11], or camera-to-camera tracking [12–17]. Some authors try to solve the problem by optimally partitioning the set of observations collected by the camera networks into several disjoint subsets, such that the observations in each subset are believed to come from a single object. The difficulty caused by the exponential growth of the partition space is tackled by making appropriate independence assumptions and leveraging efficient optimization algorithms, such as Markov Chain Monte Carlo [11, 14], Max-Flow Network [15], or Multiple Hypothesis Tracking [16, 17]. On the other hand, it is more attractive to treat the problem in a Bayesian framework [1, 10], in which each observation is assigned with a labeling variable, and the posterior distribution of the labeling variable is inferred, conditioned on all evidence made in whole networks. The resulting marginal distribution of labeling variable contains the complete knowledge about which object the observation has originated from. However, doing inference in the joint labeling space is usually intractable and the authors have to resort to some assumed independence structure and approximate algorithms such as Assumed Density Filter [1, 10].
The above approaches are all centralized, making them not suitable for using in large-scale camera networks for reasons mentioned before. Recently, distributed solutions of consistent labeling problem, which involves only local information processing and exchanging while being able to achieve the same or similar labeling accuracy as their centralized counterparts, have attracted many research interests. Considering the appearance observations made in the networks as i.i.d. samples drawn from a mixture model, and treating the labeling variables as missing data, various appearance-based distributed labeling methods have been proposed under framework of distributed EM [18–21]. However, these algorithms always perform poorly when observing conditions vary largely across camera views, as they assume that the appearance of a single object follows a unimodal distribution. To improve the labeling performance, exploiting the spatiotemporal information is necessary. Unfortunately, unlike the case of traditional wireless sensor networks [22–28] or camera networks with overlapping FOVs [29–31], where the dependence of involved variables in spatial-dimension (intrascan dependence) and temporal-dimension (intrascan dependence) can be modeled separately, the spatial and temporal evidence made in nonoverlapping camera networks are tightly coupled. This precludes the use of most existing distributed inference or optimization algorithms for traditional WSN and overlapping camera networks. In our recent works [2], based on the nonmissing detection assumption, we use a spatiotemporal tree to model the dependence of involved variables, and use belief propagation algorithm for calculating the posterior probability of labeling variable, which can be viewed as observation ownership in E-step of the distributed EM framework. Compared with traditional distributed EM, significant performance gain has been obtained by the effective using of spatiotemporal information.
1.2. Our Contributions
The main limitations of the work in [2] are (i) the number of objects under tracking needs to be known beforehand and (ii) the appearance of a single object is assumed to follow a Gaussian distribution. In this paper, we propose a new distributed Bayesian inference framework for consistent labeling of the tracked objects in nonoverlapping camera networks, which nicely overcomes the above limitations.
In our method, under the same nonmissing detection assumption as in [2], the posterior distribution of each labeling variable conditioned on all appearance and spatiotemporal measurements made in the networks is calculated, based solely on local inference on each camera nodes and belief propagation between neighboring cameras. This is possible because the nonmissing detection assumption ensures that when the label of an observation made on a specific camera is inferred, all relevant information made by the networks have been summarized in the belief states of labeling variables corresponding to observations already generated on the camera's neighbors. Here, neighboring cameras refer to cameras connected by an edge in the topology of camera networks, see Figure 1.
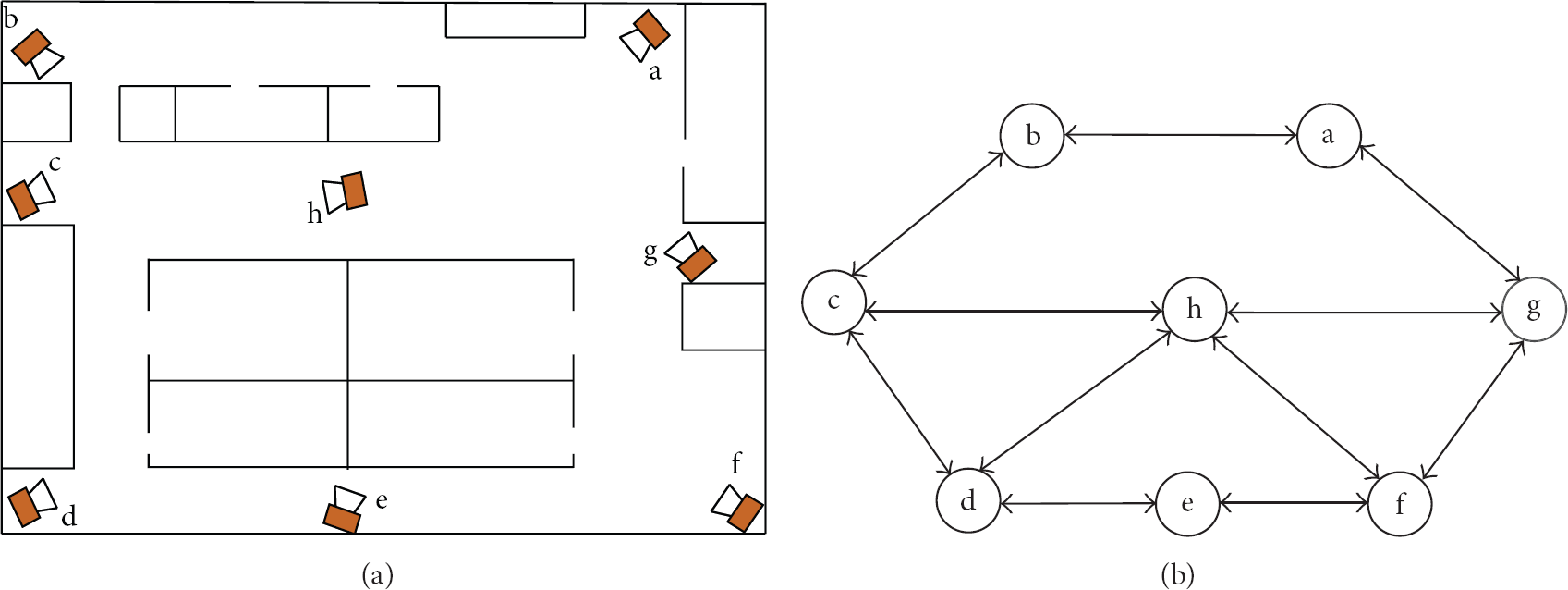
Smart camera networks and their topology.

Observations made by camera node. (a) Video frames collected by camera when an object is passing by. (b) Appearance observation: the color histogram of the object region segmented from frames. (c) Spatiotemporal observation: the time and direction of the object's entering in or leaving from the camera's FOV.
Unlike [2], we do not prespecify a fixed number of possible objects, that is, a fixed sampling space for each labeling variables. Instead, we allow each newly arriving observation to ignite a new possible object, or equivalently, to add a new element in the sampling space, as we notice the fact that each observation is either originated from a previously observed object or from a newly appeared one. Based on the nonmissing detection assumption mentioned before, the sampling space of current labeling variable is determined in an online and distributed manner on each camera, by combining the sampling spaces of labeling variables already generated on neighboring cameras. Through the propagation of sampling spaces, it can be shown that each camera always performs inference in a space consisting of identifiers of all possible objects that may produce the current observation.
In addition, in this work, we discard the Gaussian assumption of object appearance used in [2]. Instead, we only assume that two observations are “similar” if they originate from the same object. Here, saying that two observations are similar in appearance implies higher rank in the output list of some appearance-based object reidentification algorithm such as [3–8]. Consequently, two observations of the same object that look quite different in original color space due to variance in illuminating conditions may get higher similarity score by leveraging advanced techniques developed in object reidentification community. Spatiotemporal similarity is determined by the level of fitting of the spatiotemporal part of two observations to the spatiotemporal model, which is learned from training data or prespecified according to the prior knowledge of monitored region. In our Bayesian frameworks, the likelihood of observation is defined in terms of above similarity measures between observation pairs, through which the information made in the whole camera networks is injected elegantly into the process of labeling inference.
Conceptually, the sampling space of labeling variables will grow unlimited, with the accumulation of observations, which may prevent the algorithm from being used in large-scale applications. However, it is notable that in most cases, the time separation between two successive observations of the same object cannot be arbitrarily large, and the number of objects is much smaller than that of observations. Accordingly, we set a limit of memory depth for each camera node by discarding the oldest observation, and control the size of sampling space of labeling variable by deleting elements with negligible posterior probability. In this way, we obtain an inference algorithm with constant computational and memory requirement, at very little cost of labeling accuracy.
Although many excellent works exist for object detection and tracking in single view, reliable detection in a crowded scene is still a challenging task. Sometimes missing detection may happen and the nonmissing detection assumption underlying our method is violated. We alleviate this problem by considering an enlarged neighborhood of camera, and assuming that object has been detected at least once in this neighborhood before it arrives to the current camera. We use a mixture model to describe the uncertainty in object moving path caused by observation missing and modify the evaluation of spatiotemporal likelihood, leading to improved robustness of the algorithm against missing detection.
Extensive experiments are conducted on two datasets collected by our nonoverlapping camera networks: the office building dataset and campus garden dataset. Comparisons are made with two closed related inference-based consistent labeling algorithms. The results demonstrate that: (1) compared with centralized inference algorithm [1], our method shows significant superiority in execution speed, and achieves comparable labeling accuracy; (2) compared with distributed inference algorithm [2], our method provides the ability to estimate the number of moving objects and also shows obvious improvement in labeling accuracy; and (3) by considering the higher order neighborhood, our method gives satisfactory results in case of missing detections.
2. Problem Formulation
Suppose that multiple objects are moving in a large area monitored by N smart cameras with nonoverlapping field of views, as shown in Figure 1. Here, the number of moving objects is not fixed in time and is unknown to us. We assume that each camera node has limited resource for computation, storage, and communication, and synchronized internal clocks that allow the nodes to share a common notion of time. The camera networks can be represented as a graph
A clip of video is collected by camera when an object is passing through its FOV. We assume that the collected video clip has been summarized into a single virtual observation
For each observation
3. Inference Algorithm
In this section, we present our distributed Bayesian inference framework for consistent labeling. We show how to determine the sampling space of each labeling variable in Section 3.1 and how to perform inference in that space in Section 3.2. We present a distributed online algorithm with constant computation and memory requirements in Section 3.3 by limiting the memory depth of camera and maximum number of objects. Finally, we discuss the problem of missing detection and alleviate it by enlarging the camera's neighborhood.
3.1. The Sampling Space
We denote the sampling space of labeling variable x as
Suppose that at time step k, an observation
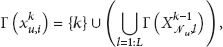
3.2. The Posterior
In this subsection, we will discuss how to calculate the belief state; that is, the posterior distribution of the labeling variable over its sampling space, conditioned on all observations made in the whole networks up to the current time step. To clarify the interobservation dependence, for each
Using the Bayes rule, the joint belief state of

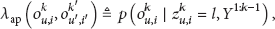
The term


The prior in (2) can be factorized as follows:



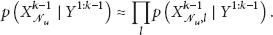
By summarizing out the auxiliary variable

3.3. Limiting the Computational Cost
From (1), we can see that the sampling space of labeling variable increases linearly with inference step. At step k, updating the belief state over sampling space costs
As older observations are less likely to be the immediate predecessor of the current one, for inference in step k, camera u only collects the M most recent observations and the corresponding belief states from its neighbors. That is, we set a memory depth of M for each camera. Typically, the number of objects is much less than the number of observations made in the networks. Thus, limiting the size of sampling space by an appropriately chosen H will not seriously affect the inference performance. At step k, we prune the sampling space
(1) For step (2) Cameras (3) Await the event of object detection (4) Collect information from neighbors: observations (5) Determine the sampling space of (6) Calculate the belief of (7) End parallel (8) End for.
3.4. Missing Detection
In the above discussion, we assume that objects can be detected reliably by smart cameras. In practice, however, false alarm and missing detection are always encountered due to unfavorable observing conditions. For consistent labeling, the problem of false alarm can be dealt with simply by deleting observations with likelihood below a specified threshold. On the other hand, the problem of missing detection is more critical and difficult to treat, because in this case the neighboring structure of the camera networks topology is destroyed, and the assumption underlying our distributed inference is violated. Thus, for the sake of briefness, we focus on missing detection only in this paper.
We partially overcome the problem of missing detection by considering information on the enlarged neighborhood of camera u when the label of observation made on u is inferred. We denote the enlarged neighborhood as
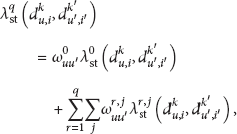
To apply the inference algorithm to the case of missing detection, we only need to replace the zero-order neighbors
4. Results
4.1. Experiment Settings
In this section, we report the experimental results of the proposed algorithm in two different disjoint multicamera surveillance scenarios. Object detection within a single view is based on the background subtraction and shadow removal algorithm as proposed in [32]. Object tracking in each camera is based on the probabilistic, appearance-based tracking algorithm as proposed in [33]. When a person is passing through the FOV of a camera, an observation is extracted from the collected video as described in Section 2.
Scenario 1: Office Building Experiment. The experiment in scenario 1 was conducted with ten cameras mounted in an office building, five in the first floor and five in the second floor. The camera layout and the corresponding topology are shown in Figures 3(a) and 3(b). A total of 300 observations originated from 10 persons are extracted from the 70-minutes video data collected by the cameras in the networks. The main challenges are the significant variations in illumination and view angles. For example, the areas covered by camera B, E, and I are clearly dim due to the lack of lighting. And the view angles at stairs, C and F, are quite different form those at other camera sites.
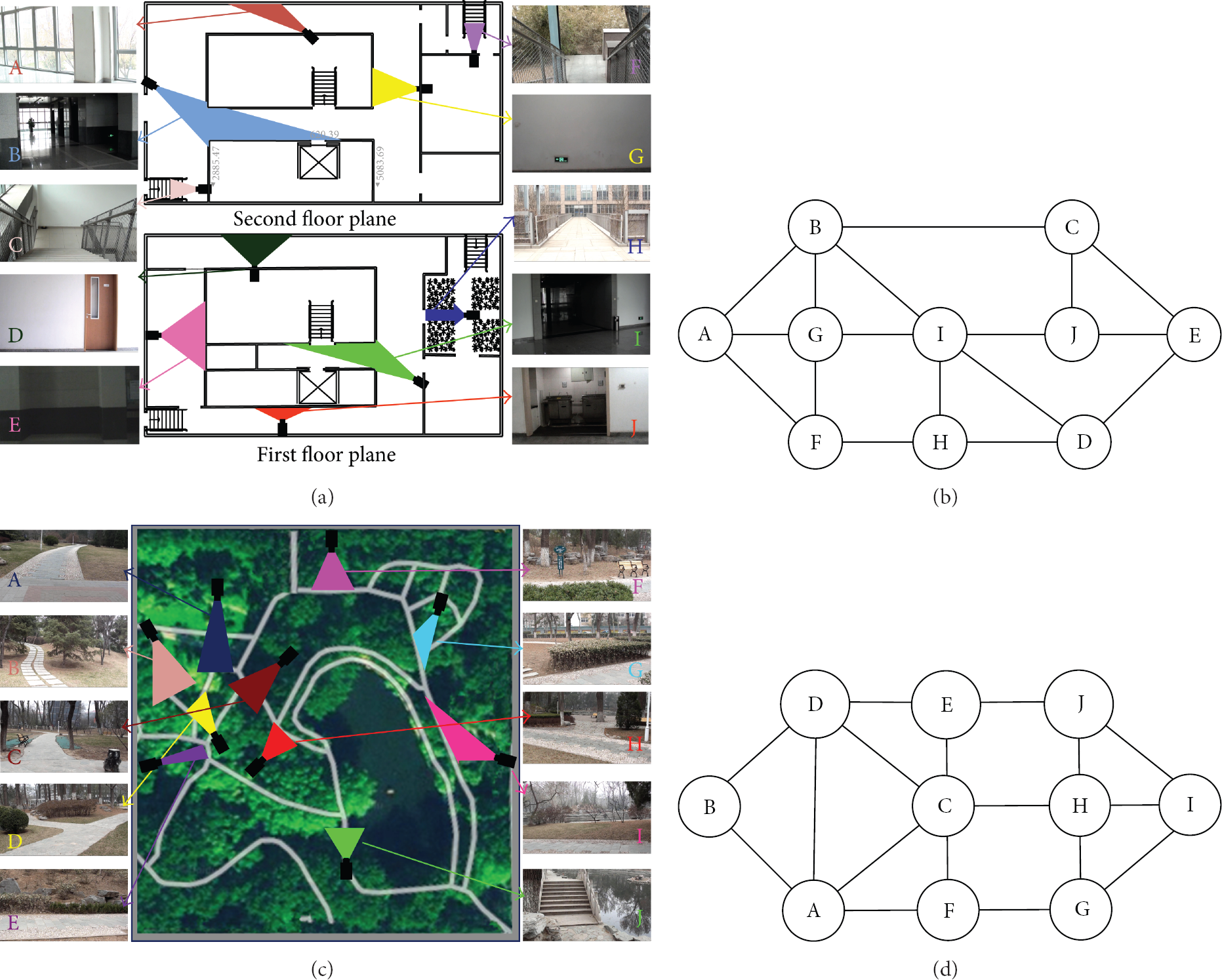
Experiment settings. (a) Office building layout. (c) Campus garden layout. (b) and (d) Corresponding topology.
Scenario 2: Campus Garden Experiment. The camera networks used in this experiment consist of ten cameras mounted in our campus garden, and the layout and corresponding topology are shown in Figures 3(c) and 3(d). During the experiment, 14 persons are present in the monitored region. We gather altogether 300 observations of them from 90-minutes video collected by the camera networks. In outdoor scenario, the illuminating conditions at each site are similar, but the monitored region is larger and the distance between cameras is longer than that of indoor case. Consequently, the variation of traveling time is large and the discriminating power of traveling time cue is decreased.
Before conducting experiments, the observations extracted from about five hours-long video data collected by the camera networks are manually labeled and used for learning the CBTF and traveling time model

CBTF curve between camera A and B in office building experiment.
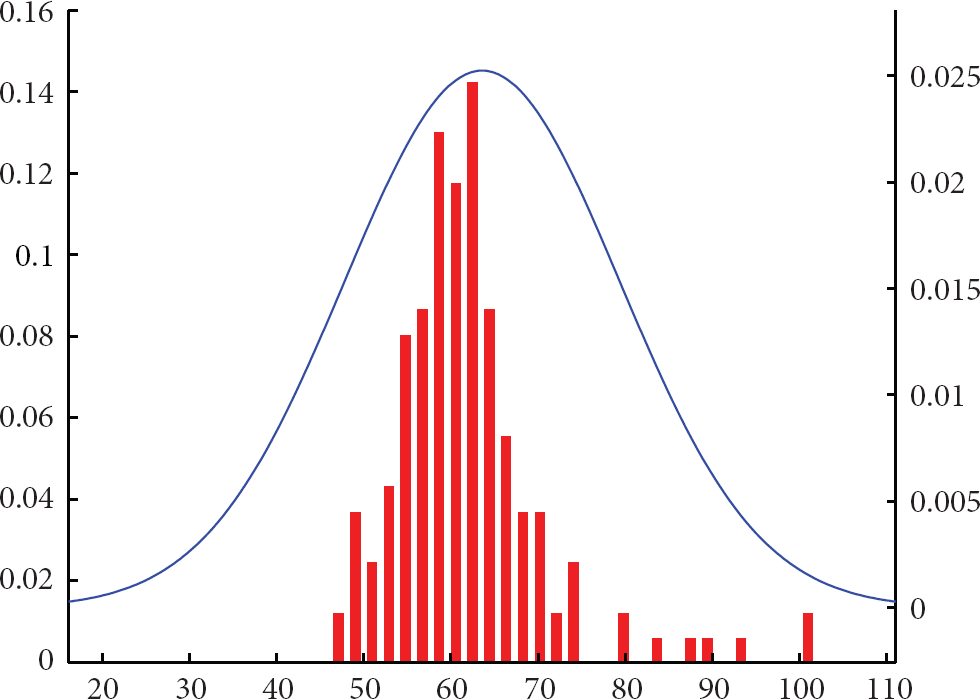
The traveling time histogram between cameras A and C in campus garden experiment and the fitted Gaussian distribution.
4.2. Evaluation Criteria
We use the following measures to evaluate the algorithms: the estimated number of objects K, the precision P, recall R, and F-measure of the reconstructed trajectories. Let
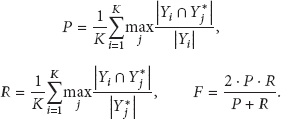
To evaluate the speed of the labeling algorithm, we measure its execution time
4.3. Results
We apply our method to the two datasets. In Office Building experiment, we set the memory depth as
Results on office building data (

Results on campus garden data (


Marginal distribution of labeling variable. Each column corresponds to one observation, sorted in time order. The true label of each observation is depicted by red star. Grayscale corresponds to the posterior probability of labeling variables. Black represents probability 1, and white 0. (a) Results on office building dataset and (b) results on campus garden dataset.

Selected frames in Office Building experiment. Column corresponds to camera site and row corresponds to time instant. Detected person is shown with bounding box, the label of which is shown in the text box. Left-top, true label; right-top, result of Zajdel [1]; left-bottom, result of Jiuqing and Qingyun [2]; right-bottom, our result.

Selected frames in Campus Garden experiment. Column corresponds to camera site and row corresponds to time instant. Detected person is shown with bounding box, the label of which is shown in the text box. Left-top, true label; right-top, result of Zajdel [1]; left-bottom, result of Jiuqing and Qingyun [2]; right-bottom, our result.
Comparison with Centralized Inference Algorithm [1]. A closely related method to ours was proposed in [1], in which the joint distribution of observations and hidden variables is encoded by dynamic Bayesian networks, and the posterior marginal of labeling and counting variables are inferred by using the Assumed Density Filter. By inferring the counting variables, the number of objects can be estimated from observations automatically. In [1], the appearance of a single person under different camera sites is assumed to follow a single Gaussian with Normal-Inverse Wishart distributed mean and covariance parameters, allowing the appearance model to be updated analytically. However, the inference algorithm in [1] is centralized, and the computational and memory cost increase rapidly with number of observations. To make it executable on our datasets, we limit the memory depth of the central server to 25 for both experiments, and set the maximum number of objects as 15 and 20 for the two experiments, respectively. It is obvious in Tables 1 and 2 that the speed of [1] is much slower than ours, mainly due to its centralized nature. It is also noticeable that the centralized method [1] does not show superiority to our distributed method on the Office Building data in terms of labeling accuracy, due to the unrealistic appearance assumption and truncating of history observations during inference. In fact, for centralized inference, a much deeper memory is required to ensure that the true predecessor of the current observation is reserved. But this will lead to unacceptable computational and memory cost.
Comparison with Enhanced Distributed EM [2]. We also compare our method with [2], in which a distributed inference algorithm based on the same nonmissing detection assumption as ours is proposed to calculate the posterior distribution of labeling variables conditioned on both appearance and spatiotemporal observations. The appearance of a single person is assumed to follow a single Gaussian, which is updated in the M-step of distributed EM framework. The method in [2] is offline, and requires the number of objects to be prefixed. In our experiments, we set the maximum object number as 15 and 20, respectively, run EM 30 iterations, and initialize the appearance model by k-means clustering. As shown in Tables 1 and 2, [2] cannot estimate the number of persons correctly in both experiments, and gives significantly lower labeling accuracy than our method. The inferior performance of [2] can be attributed to its single Gaussian assumption on appearance and its blindness in choosing the sampling space of labels. In experiments, we observe that by using [2], the trajectory of a single person tends to break into several pieces especially when his/her appearance undergoes obvious changes across camera sites, and consequently more trajectories are recovered than the ground truth. In contrast, our method only assumes that the appearance of a single person at each pair of neighboring cameras is “similar” to each other after the CBTF transform. By using CBTF, the variations in lighting conditions across different camera sites can be partially compensated. This assumption seems more reasonable than that in [2], and results in an improved labeling accuracy. For example, in Figure 7, person e presented consecutively in row 6, column I, row 8, column D, and row 12, column H. The method in [2] cannot correctly label the person at camera I mainly due to the weak lighting condition. However, our method can give correct results in this case. Of course, if the observing angle or the attitude of person varies significantly, simple appearance features such as brightness histogram used in this paper are not enough. In this case, more robust appearance features and advanced similarity evaluation techniques (such as in [3–8]) are required. It is noticeable that our framework is rather flexible in that these new similarity evaluation techniques can be easily incorporated into the inference framework by modifying the likelihood function.
4.4. Missing Detection
In our experiments, no missing detection occurs as the scenes are relatively sparse. However, in practice, the interested objects may be missdetected due to occlusions in crowd or the low quality of the video. To verify our method in these cases, we randomly delete some of the observations, and apply the proposed algorithm (0-order spatiotemporal model (4)) and its modification (1-order spatiotemporal model (11)), respectively, to the remaining part of the two datasets. The average F-measure of 10 trials is shown in Figure 9. As expected, when missing detection occurs, the labeling accuracy of 0-order model-based algorithm decreases rapidly. When 40 observations are deleted randomly (corresponding to a 13% missing rate), 0-order method gives F-measures of 59% and 62% for the two datasets. In contrast, by enlarging the neighborhood, 1-order method can achieve F-measures of 77% and 82% in this case. This can be attributed to the fact that in case of missing detection, the real predecessor of current observation is more likely to exist in higher-order neighborhood than in 0-order neighborhood; hence, a correct link is more likely to be established by considering higher order neighborhood.
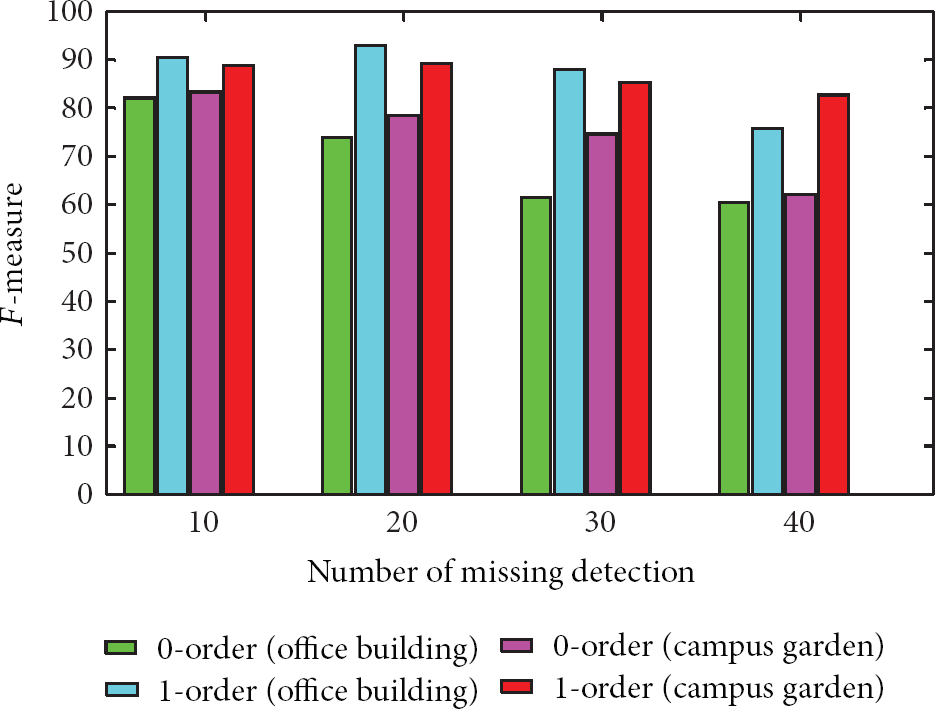
F-measure in case of missing detection. X-axis: the number of missing detections. Legend: 0-order (office building) means result of our algorithm with 0-order model applied to Office Building data, and so on.
4.5. Discussion
In our experiments, the scenes are rather sparse, so that the persons can be easily segmented and tracked within a single view by standard multiobject tracking algorithms. When the scene becomes crowded, more occlusions will occur. This leads to the following two problems. First, occlusions may lead to missing detections. We have addressed this problem in last subsection by considering higher-order neighborhood and using mixture spatiotemporal model. Second, in case of heavy occlusion, it is more difficult to segment and extract accurate features of persons. In this case, the performance of our method will deteriorate. This is a limitation of our method. In the future, we will try to use more advanced pedestrian detection technique and more reliable feature extraction algorithms to deal with crowded scenarios.
In our method, we use both appearance and spatiotemporal cues for inference, which are complementary to each other. However, the use of traveling time cue is an option of both benefits and downside. If the variation in walking speed of persons under tracking is not very large, using traveling time cue can improve the labeling performance. On the other hand, if some person walks extremely fast or slow, using traveling time evidence may deteriorate the performance. In our experiments, there is no running action, but there is some short pause between camera sites, which makes the traveling time cue less reliable. In these cases, the inference relies mostly on the appearance cue, and another spatiotemporal cue, that is, the moving direction of persons, which impose strong constraints on person's trajectory. In our experiments, we find that in most cases, our method can label observation correctly even when some short staying occurs.
However, in practice, person may move arbitrarily slow, for example, hiding in the unmonitored region for a long time. In fact, if a person has a long-time staying when he/she traveled from one camera to another, the traveling time likelihood evaluated by (5) is approaching zero. In this case, the labeling result is very likely to be incorrect. To cope with this problem, we consider the following traveling time model:

In Table 3, “app + Gaussian + direction” means that we use the appearance, moving direction and traveling time models; that is, (3), (4), and (5) for inference, “app” means that we use only appearance model, and “app + Uniform + direction” means that we replace the Gaussian traveling time model (5) with the uniform model (13). It can be seen from the table that in case of possible long-time staying, the labeling results based on Gaussian traveling time model are very poor, mainly due to the unrealistic traveling time assumption. And labeling based only on appearance information is also unsatisfactory. In contrast, by using the uniform traveling time model, spatiotemporal information can be used in an effective way, and significant improvement in labeling accuracy is achieved. This demonstrates the flexibility of our frameworks. We can choose proper models according to the situation without changing the algorithm.
F-measure on simulated datasets (%).

4.6. Failure Case
In our experiments, most of the observations can be labeled correctly. This is mainly originated from the complementarity between the appearance and spatiotemporal evidences. However, if both of them are direct to wrong associations, or the two kinds of evidence contradict each other and the evidence leading to correct answer is not strong enough, incorrect labeling tends to occur. For example, as shown in Figure 10, observations 1 and 2 on camera A were originated from person e and c, respectively. And observation 3 on camera E was originated from person e. Actually, observation 1 is the true predecessor of observation 3. However, as persons b and d look quite similar, the appearance cue is somewhat misleading. As shown in the figure, the appearance similarity between observations 1 and 3 is 0.0042, and that between 2 and 3 is 0.0231. On the other hand, since observations 1 and 2 were generated on camera A very closely in time, the spatiotemporal evidence is less discriminating. Indeed, the spatiotemporal similarity between observations 1 and 3 is 0.0515, while that between 2 and 3 is 0.0230. Consequently, the overall similarity between observations 1 and 3 is less than that between 2 and 3, and we find that the observation 3 is mislabeled as c by our algorithm.
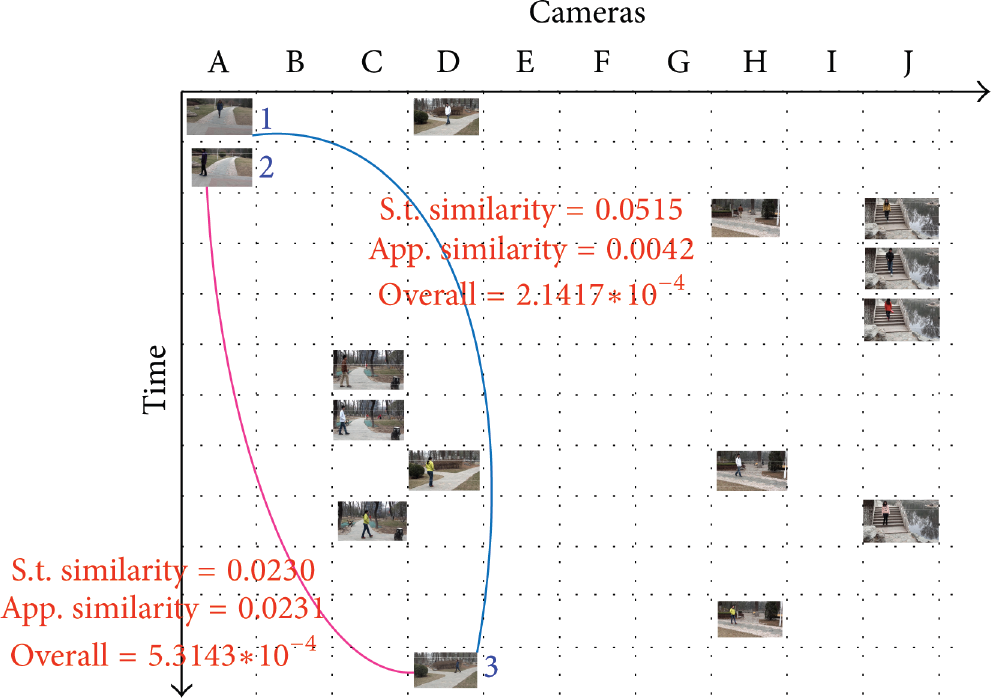
A typical failure case.
5. Conclusion
In this paper, we present a distributed Bayesian inference framework for consistent labeling of tracked objects in nonoverlapping camera networks. In this method, each camera in the networks performs inference on labeling variables over the online determined sampling space, based on local information and that collected from its neighbors. The similarity between pairs of observations is used for defining likelihood function in the framework, making it very flexible and particularly suitable in case of large observing condition variations across camera views. To cope with missing detection, we enlarge the neighborhood of each camera from which it collects information during inference and use a higher order mixture model to evaluate spatiotemporal likelihood, leading to improved robustness of the algorithm. The effectiveness of the proposed method is verified on two real datasets. In the future, we plan to investigate how to extend the use of our method to more realistic scenarios, in which the size of networks is larger, the duration of video collection is longer, and the camera scene is more crowded.
Footnotes
Acknowledgments
The authors are grateful to the student volunteers for their participation in the tracking experiments. This work is supported by the National Natural Science Foundation of China, under Grant no. 61174020. The authors would like to thank the anonymous reviewers for their valuable suggestions for improving the quality of the paper.