
Abstract
In the environment of cloud computing, real-time mass data about high-speed rail which is based on the intense monitoring of large scale perceived equipment provides strong support for the safety and maintenance of high-speed rail. In this paper, we focus on the Top-k algorithm of continuous distribution based on Multisource distributed data stream for high-speed rail monitoring. Specifically, we formalized Top-k monitoring model of high-speed rail and proposed DTMR that is the Top-k monitoring algorithm with random, continuous, or strictly monotone aggregation functions. The DTMR was proved to be valid by lots of experiments.
1. Introduction
High-speed rail is the dominant overland transportation in the 21st century. As the largest country in Asia, China has built the longest high-speed rail while more rails are under construction. While high-speed rail is a collection of various advanced railway technology in an extremely complex system, the safety and capacity maintenance directly determine the service quality of high-speed rail. As an important component of high-speed rail information infrastructure, an intelligent environmental monitoring system based on cloud computing [1–3] can transmit real-time, time-varying, continuous, and massive data streams [4, 5] using wireless sensor networks [6] as well as high-speed network connecting with data center. Therefore, it is very important to study the real-time continuous query [7] algorithm for high-speed rail with massive data streams.
From the application, high-speed rail sensor equipment can be generally divided into two categories: real-time visibility and fault detection/prediction [8]. Real-time visibility is the basis of many advanced applications, which can enhance the railway network capacity, improve fuel efficiency, and asset utilization. This application needs regular measurement of various operating parameters associated with high-speed rail or passenger flow, so as to improve the overall operation of high-speed rail [9–11]. On the other hand, the application of fault detection is to monitor components of the high-speed rail (such as wheels and carriage) and avoid catastrophic events (such as derailment occurred). People can take corrective action before the accident when the key parts of high-speed rail trains, rail and the relevant geographic area are detected by sensors and intelligent devices [12, 13]. As shown in Figure 1, The perceivable equipment installed in the railway/train real-time monitor the railway environment/train conditions.

The perceivable equipment installed in the railway/train.
Top-k [14] query is to find k results with highest values according to the rank of a user-defined function. In monitoring high-speed rail data flow with the massive data transmission, Top-k is a very important query algorithm, which returns k most important results according to the sorting function in the potential data space. In the process of Top-k queries, system usually calculates the property of each object, and then utilizes a monotone sorting function to aggregate multiple property values as the weights of the object, finally returns k objects with highest weights as the results of a query. At the same time, in high-speed rail, being real-time is another important indicator to evaluate the Top-k query algorithm.
Processing architecture of stratified High-speed Monitoring data stream is shown in Figure 2. In the distributed systems with multiple data streams, the basic method to realize Top-k query is to send data streams from all nodes to a central node, which performs the calculation of the Top-k query. However, the requirement of this approach is often beyond the processing capacity of monitoring system while time delay also appears. Literature [15] discussed how to realize the on-line Top-k monitoring of effective data streams in distributed environments. Constraint relationship of monitored objects has been established in the remote data source. In the most of time, the global Top-k collection is same as the Top-k collection on each monitoring nodes. Communication among the nodes is triggered only when the constraints are changed. In this manner, network communication in the on-line Top-k monitoring is effectively decreased. However, the method in [16] needs to deliver the constraint-broken information to the entire Top-k collection. Paper [17] presented a more efficient distributed Top-k algorithm: MR, which significantly reduced the communication cost compared with the method in [16]. Furthermore, communication cost of MR is independent of the value of k. However, these two methods only use ascending functions as the sorting function, while a user-specified sorting function may be arbitrary in practical applications.
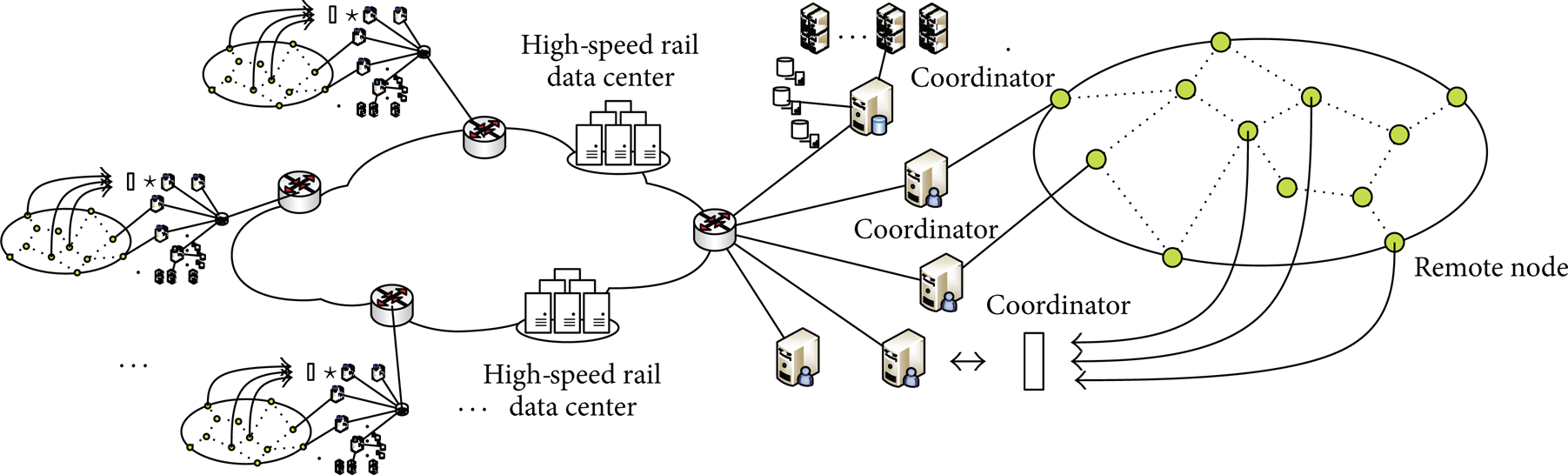
Processing architecture of stratified High-speed monitoring data stream.
This paper presents DTMQ (Distributed Top-k Monitoring Query) algorithm which supports any distributed Top-k monitoring with random, continuous or strictly monotone aggregation function. DTMQ maintains the Top-k result set based on establishment of the constraints on remote data flow. DTMQ communication among nodes is needed only when the constraints are broken while the communication occurs on partial nodes and is independent to k. The efficiency of DTMQ has been proved by synthetic data with normal distribution and Zipf distribution. Experiments show that the transmission volume of DTMQ is at least one magnitude scale lower than that of other algorithms. The main contribution of this paper is as follows.
It presents a formal model of Top-k monitoring with multiple high-speed rail data streams in the cloud computing environment.
DTMQ is proposed, which supports random, continuous, strictly monotone aggregation functions of Top-k monitoring.
The effectiveness of DTMQ is verified through a lot of experiments.
Sections 2, 3, and 4 introduces the relevant work as well as formal description of the problem. Section 5 explains design conception and optimization strategy of DTMQ algorithm. Besides, experimental results comparison is demonstrated in Section 6, while summary of the entire research is made in Section 7.
2. Relevant Works
The most famous Top-k query algorithm is the threshold algorithm (TA) first proposed by [18]. TA is efficient which is usually used for single data source, while it is not suitable for distributed system. On the basis of TA, the researchers have developed many Top-k query processing algorithms for distributed system. However, these algorithms are all like “snapshots”, which means they cannot support continuous queries over data streams.
Literature [19] discussed how to realize the on-line Top-k monitoring of effective data streams in distributed environments. Constraint relationship of monitored objects has been established in the remote data source. In the most cases, the global Top-k collection is same as the Top-k collection on each monitoring nodes. Communication among the nodes is triggered only when the constraints are changed. In this manner, network communication in the on-line Top-k monitoring is effectively decreased. However, the method in [20] needs to deliver the constraint-broken information to the entire Top-k collection, which still causes significant communication cost. Note that the highlighted parts have been stated in the introduction section and you need to double check the literature [15, 19].
Kawashima et al. [21] first proposed the sliding-window-oriented query processing method. Considering many existing Top-k query techniques, they developed a framework of Top-k query, which provides a compactible set of Top-k query. This set cannot only calculate Top-k query results, but also provide incremental maintenance. Leung et al. and Mouratidis et al. also proposed a SCSQ buffer strategy, which compresses the compactible set to reduce the complexity of space and time effectively [22, 23]. Wu et al. and Yang et al. [24, 25] solved the issue of Top-k query with incomplete data streams by generating multiple instances for the same object and applying the effective data cleaning method. In addition, Chu et al. [26] introduced a concept of Skyline analysis to obtain an accurate Top-k Skyline query and approximate e query algorithm.
Literature [27] discussed how to monitor k sensors with the highest values in sensor networks, while the property of the aggregation functions in Top-k monitoring was not involved. Top-k monitoring on a single data stream with multiple aggregation functions has been studied in [28–31], which focused on how to save CPU and memory source on each node, but did not consider the cost saving of network communication in distribution environments.
In practical applications, a user-specified sorting function may be random. In order to deal with the random sorting function, this paper presents an algorithm called DTMQ which supports any distributed Top-k monitoring with random, continuous or strictly monotone aggregation function. Furthermore, the communication cost of this new algorithm has been proved to be independent of k.
3. Terms and Definition
A wireless sensor network (WSN) consists of spatially distributed autonomous sensors to monitor physical or environmental conditions, such as temperature, sound, and pressure, and to cooperatively pass their data through the network to a main location. Therefore, data should also be processed by sensor networks in a distributed fashion. Usual techniques operate by forwarding and concentrating the entire data in a central server, processing it as a multivariate stream. Raw sensor data is shown in Figure 3.

2D/3D contour plot of raw sensor data.
A distributed Top-k monitoring model is presented in this section. In high-speed rail environments with many safety monitoring nodes, the top k values among the data streams should be identified according to the user-defined sorting functions. High-speed rail safety monitoring environment contains a large-scale monitoring system with m + 1 sensing nodes, a central coordinating node N0, and m remote monitoring nodes N1, N2, …, N m .
Definition 1. Given a set of remote monitoring nodes N1, N2, …, N m , and the current monitoring object set U = {O1, O2, …, O n }, objects to be monitored are denoted as O i ∈ U. Let V i, r be the monitoring value of N r by O i .
Definition 2. Let V i be the aggregation values of O i ∈ U in the central coordinating node N0, then we have V i = f(Vi, 1, Vi, 2, …, V i, m ), where f is a user-specified sorting function.
To simplify the problem, this paper only considers the situations with a continuous and strictly ascending function f where each node only needs to monitor—V i, r , and those situations will become as same as the situations with ascending f. Monitoring data and aggregation data are both assumed to be real, while V i, r > 0. It needs to be mention that not every object in U can be monitored by nodes. When object O i cannot be monitored by node N j , let V i, r = 0, which does not affect the universality of Definition 1.
Definition 3. Distributed Top-k monitoring continuously searches for a set T ⊆ U which satisfies: |T| = k and ∀ O t ∈ T, ∀ O s ∈ U – T, (V t ≥ V s ), where k is the set size of a given monitoring result set Top-k.
In practical systems, when T changes, the systems need to determine the new Top-k result set T′. During this process, the systems continue to set T as the current collection. Although this setting is not consistent with T′, the error is negligible because the required processing period is very short.
4. Problem Descriptions
4.1. Constraints
Constraints are discussed in this section. A Basic Distributed Top-k Monitoring (BDTM) which supports any sorting function transmits all data streams to calculate Top-k result set. However, in this process, the transmitted data is huge. In order to improve the communication efficiency, this paper established constraints based on remote data flow, and Top-k set can be maintained by this method. The basic idea of establishing the constraint is to ensure that the global optimal k objects are optimal objects in each node. Communication is needed only when the constraints are broken.
For any i between 1 and n, let δ i, r be the adjustment factor with respect to the object O i in object set U. This factor is used to adjust the weights of O i on both observing node N r (1 ≤ r ≤ m) and central coordinate node N0. From Definition 3, we have T ⊆ U and |T| = k.
Constraint. ∀ O i ∈ U, there exists f(Vi, 1 + δi, 1, Vi, 2 + δi, 2, …, V i, m + δ i, m ) = V i .
Constraint. ∀ N r (1 ≤ r ≤ m), ∀ O t ∈ T, ∀ O s ∈ U – T, there exists Vt.r + δt.r ≥ Vs.r + δs.r.
Proof. We will first prove that there exists an adjustment factor satisfying the above constraints for any Top-k result set. Because f is a strictly ascending function, it can be seen that μ i ≥ 0 which makes V i = f(Vk.1 + μ i , Vi, 2 + μ i , …, V i, m + μ i ) for ∀ O i ∈ T and V i = f(Vk, 1 + μ i , Vi, 2 + μ i , …, V i, m + μ i ) which makes δ i, r = Vk, 2 + μ i – V i, r (1 ≤ i ≤ m) for ∀ O i ∈ U – T. Then, the adjustment factor obtained in this manner satisfies the two constraints.
Next, we will prove that the set T satisfying the constraints is Top-k results set. From Constraint 2, ∀ N r (1 ≤ r ≤ m), ∀ O t ∈ T and ∀ O s ∈ U – T, there exists Vt.r + δt.r ≥ Vs.r + δs.r. Because f is a continuous and strictly ascending function; that is, for any r (1 ≤ r ≤ m), x r ≥ x r ′, we have f(x1, x2, …, x m ) ≥ f(x1′, x2′, …, x m ′). Therefore, from Constraint 1, ∀ O t ∈ T and ∀ O s ∈ U – T,

From Definition 3, the above set is Top-k results set.
Proof is complete.
5. Distributed Top-k Monitoring
This section presents a distributed Top-k monitoring algorithm DTMQ (Distributed Top-k Monitoring Query) with generally minimum refresh, which supports any continuous and strictly monotone aggregation function. By Theorem 4, in Top-k monitoring, we only need to obtain the set satisfying these two constraints.
During initialization, the initial result set Top-k can be obtained by TA algorithm, and then the Allocation function of the adjustment factor (see Algorithm 5) sets the adjustment factor satisfying both constraints.
In the monitoring process, when the constraints in monitoring node N
c
are broken, let C ⊆ U be sets of objects breaking the constraints in the monitoring node N
c
, which is named as the conflict set. Let C
T
= T ∩ C be the down conflict set, and C
s
= (U – T) ∩ C be up conflict set. Let I be the set of objects with higher aggregation values in

The description of DTMQ algorithm is as follows.
Algorithm 5 (DTMQ). One has the following.
Step 1. N c sends a constraints-rebuilding request to N0, which contains conflict set C and its monitoring value in node N c , and two boundary value B c and H c .
Step 2. When N0 obtains the data from node N r (r ≠ c), which includes the conflict set C, the monitoring values of the objects in C in node N r , and two boundary values (B r and H r ), it then calculates the aggregation value of the objects in C. Compute set I, and apply function Allocation to re-distribute adjustment factor. Update Top-k results set, which is T′ = (T – C T ) ∪ I, and transmit it to all other nodes.
Function Allocation. Consider the following.
Input is C, N, {B r }, {H r }, {V i, r }, {δ i, r }.
Output is {δ i, r ′}.
Calculate the aggregation value of each object O i in conflict set C:

Compute Interpolation factor a i of each object O i in conflict set C, to make

Compute the adjustment factor of each object O i in node N r in conflict set C:
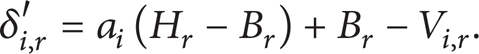
Because f is a continuous and strictly ascending function, then we have that ∀ O i ∈ C, a i satisfying line 2 in Allocation can be obtained by analytical or iterative methods. Iterative method only needs to calculate approximate solutions. The difference between V i ′ (the value of V i when a i has been used) and V i are recorded by the central coordinating node. This paper assumes a i to be an exact solution.
The validity of GMA algorithm is proved next. That is: adjusting factor generated by Allocation satisfies the constraints in Section 3. Moreover, communication cost of DTMQ will be proved to have no relationship with k.
Proof. Since Allocation function is only involved in adjustment of the objects in C, we only need to prove that aggregation values of objects in newly generated C keep unchanged. Proof is complete.
Proof. There are two different conditions because T′ = (T – C T ) ∪ I.
∀ O t ∈ T – C T , ∀ O s ∈ U – T – CU – T, because allocation does not change O t and adjustment factor of O s , as well as the constraints are not broken by O t or O s , Constraint 2 is still available.
∀ O t ∈ I, ∀ O s ∈ C – I, from the definition of I, we have V t ≥ V s . Due to the line 2 and line 3 of Allocation function, O t and O s satisfies Constraint 2 because f is a strictly ascending function.
Let H = f(H1, H2, …, H m ), and B = f(B1, B2, …, B m ). From the definition of H r and B r , we have H r ≥ B r . ∀ O t ∈ T – C T , ∀ O s ∈ C – I, from the definition of I, V t ≥ H ≥ V s , because f is a strictly ascending function, we have ∀ O s ∈ C – I, a s ≤ 1, that is, ∀ O t ∈ T – C T , ∀ O s ∈ C – I, O t and v satisfies Constraint 2.
∀ O t ∈ I, ∀ O s ∈ U – T – CU – T, from the definition of I, V t ≥ B ≥ V s , because f is a strictly ascending function, we have ∀ O t ∈ I, a s ≥ 0, that is, ∀ O t ∈ I, ∀ O s ∈ U – T – CU – T, O t and O s satisfies Constraint 2.
In all, ∀ O t ∈ T′, ∀ O s ∈ U – T′, O t and O s satisfies Constraint 2.
Proof. DTMQ communication is needed only when the constraints are broken. In the process of rebuilding constraints, DTMQ only needs to obtain C and two boundary values from each monitoring node, and transmit the new adjustment factor in C to other monitoring nodes. C Only contains conflict objects, while the size of C is unrelated to k. Therefore, communication cost of DTMQ is independent of k. Proof is complete.
6. Experimental Performance
In order to verify the effectiveness of the proposed algorithm, simulated experiments on the algorithm have been conducted. In the experiments, DTMQ was compared with BDTM described in Section 3, and the performance was evaluated by the communication cost.
Synthetic data were used in the experiments. Two datasets containing 50000 bytes were constructed, which followed the Normal distribution and the Zipf distribution (factor 0.8), respectively.
The experiments only discuss common addition, multiplication and mixed operation. The following three kinds of functions have been used as the aggregation function:
f1(x) = x1 · x2, where x i denotes the number of request received in a sliding window of 1 hour. f1(x) denotes the situation with aggregation function being multiplication.
f2(x) = x1 · x2 + 2x3, f2(x) stands for the situations with aggregation function being mixed operation of addition and multiplication.
f3(x) = (x1 + x2)/2 + (x3 + x4 + x5)/3. f3(x) represents the situation with aggregation function being addition of mean values.
The experiments were done with Intel i5 2.5 GHz CPU, 2G DDB memory, CentOS operating system. The simulated test program has been developed using Java programming. The experimental results are shown in Figure 4.

Normal distribution/Zipf distribution.
Figures 5 and 6 show test result under the k = 20 Normally distributed dataset and Zipf distributed dataset. From Figures 5 and 6, the transmission volumes of DTMR is lower than that of BDTM by at least one magnitude scale (the ordinate is the logarithm). This is because the DTMR communication among the nodes only appears when the constraints are broken and the communication just involves several related nodes, whereas BDTM requires all the data are transmitted to the N0.

Comparison of DTMR and BDTM on the normal distribution data sets.
Comparison of DTMR and BDTM on Zipf distribution data sets.
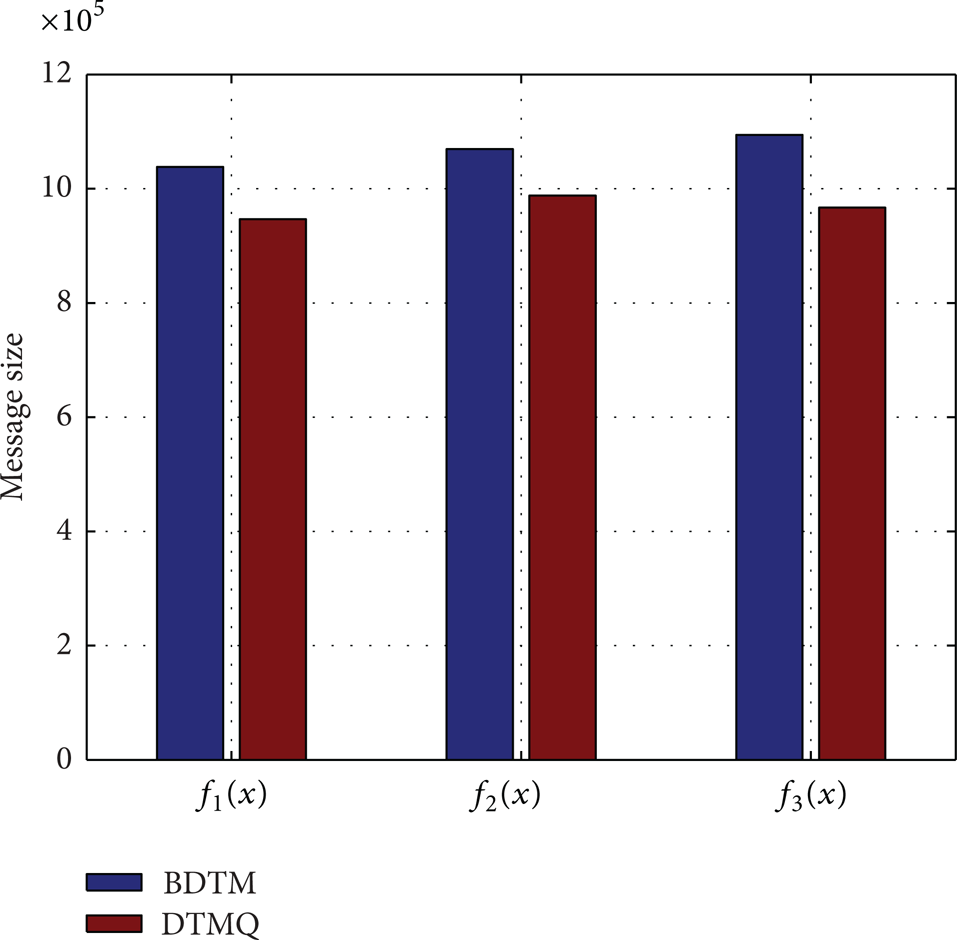
This paper verifies the performance of DTMR under different k values. Figures 7, 8, and 9 shows experimental results of the aggregation function f1(x), f2(x), f3(x) on a Normally distributed data collection. The performance on Zipf data sets is similar, which is not listed here to save space. From Figures 7–9, the communication cost of DTMR is independent of k. In other words, it will not increase when k becomes larger.

f1(x) under different k values.

f2(x) under different k values.

f3(x) under different k values.
7. Conclusions
This paper studied how to realize the general and efficient distributed Top-k monitoring to continuously monitor top k values among massive data streams in the high-speed rail monitoring. User-specified sorting functions in practical application may be arbitrary. In this paper, we propose a general distributed Top-k monitoring algorithm: DTMR, which supports random, continuous or strictly monotone aggregation functions. DTMR maintains the Top-k result set based on the constraints established from remote data stream. DTMR communication among the nodes only appears when the constraints are broken and the communication just involves several related nodes. The communication costs are independent of k. The efficiency of DTMR has been proved using the practical data and simulated data. Experimental results show that the transmission volume of DTMR is lower than that of other algorithms by at least one scale magnitude. The future research will focus on developing methodology to divide the sliding window to conduct parallel Top-k queries and decreasing the impact of high-speed rail uncertainty.
Conflict of Interests
The authors declare that they have no financial and personal relationships with other people or organizations that can inappropriately influence their work and there is no professional or other personal interest of any nature or kind in any product, service, and/or company that could be construed as influencing the position presented in, or the review of, this paper.
Footnotes
Acknowledgments
This study was supported by the National Natural Science Foundation of China (Grant no.: 61272029), National Key Technology R&D Program (Grant no.: 2009BAG12A10), independent subject of State Key Laboratory of Rail Traffic Control and Safety, Beijing JiaoTong University (Contract no.: RCS2009ZT007), and it is partially supported by the MOE key Laboratory for Transportation Complex Systems Theory and Technology School of Traffic and Transportation, Beijing JiaoTong University.