
Abstract
An immune relevant vector machine (IRVM) based intelligent classification method is proposed by combining the random real-valued negative selection (RRNS) algorithm and the relevant vector machine (RVM) algorithm. The method proposed is aimed to handle the training problem of missing or incomplete fault sampling data and is inspired by the “self/nonself” recognition principle in the artificial immune systems. The detectors, generated by the RRNS, are treated as the “nonself” training samples and used to train the RVM model together with the “self” training samples. After the training succeeds, the “nonself” detection model, which requires only the “self” training samples, is obtained for the fault detection and diagnosis. It provides a general way solving the problems of this type and can be applied for both fault detection and fault diagnosis. The standard Fisher's Iris flower dataset is used to experimentally testify the proposed method, and the results are compared with those from the support vector data description (SVDD) method. Experimental results have shown the validity and practicability of the proposed method.
1. Introduction
The system failure of a complex mechatronic machine is usually caused by the failure of its critical components. The nature of the fault diagnosis is to gain the correct feature parameters of the critical parts by monitoring the relevant internal and external signals. Therefore, intelligent fault detection and diagnosis are widely treated as a pattern recognition problems. In the problem, the normal state and the fault state are categorized as different kinds of patterns. A rational model is set up between the state features and different patterns, which is also addressed as the fault detection model and can intelligently recognize the working status of the devices.
The literature on the fault detection methods is very rich. Most of its parts are on the supervized learning methods, such as neural networks [1], support vector machines [2–4], relevance vector machine [5–8], naive Bayes [9–11], and decision tree [12]. Supervized learning methods require a sufficient number of fault data for training; however, fault data are usually insufficient in practice, particularly at the early stages of operation, where probably only normal data samples are available. Under this circumstance, the traditional intelligent diagnosis methods have their deficiencies: the fault diagnosis model can hardly be trained with only normal samples; moreover, the fault detection model trained with normal data together with only part of the failure data cannot identify unknown faults and always assigns them wrongly to some known categories.
Inspired by the “self/nonself” recognition principle in artificial immune systems, an immune relevant vector machine algorithm is proposed to solve the problems with traditional methods. This method combines the random real-valued negative selection (RRNS) algorithm and the relevant vector machine (RVM) algorithm, detecting the “nonself” mode with only “self” training samples. Based on the proposed algorithm and its utilization with other methods, accurate fault detection and unknown failure detection can be performed with only normal samples or incomplete training samples.
The remainder of this paper is organized as follows. The first section introduces the immune relevant nonself vector machine detection algorithm. The second section describes the fault detection model based on the immune relevant vector machine. In the third section, standard Fisher's Iris flower data are applied to experimentally verify the proposed algorithm and the model. The results are compared with other anomaly detection algorithms. The fourth section gives the conclusions.
2. Immune Relevant Vector Machine “Nonself” Fault Detection Algorithm
2.1. Definitions
Definition 1 (system state space). System state can be denoted by a feature vector

System state space is denoted as
Definition 2 (self space). The self space is a space of feature vectors with known target status, denoted as
Definition 3 (nonself space). The nonself space is the complement of the self space in the system state space, denoted by
Definition 4 (nonself detection). The nonself detection here includes both the anomaly detection and the multiclass fault diagnosis in the sense of the traditional negative selection algorithm. For the nonself detection problem, a state recognition function is estimated given a self sample set
Note that, for brevity, self data/samples denote data/samples in the self space, which refer to normal data or data of a known class, and nonself data/sample denote data/sample in the nonself space, which are abnormal data or data that do not belong to a given class.
2.2. Improved Normalization Method
Each dimension of the feature vector

where
The disadvantage of the previous method is as follows.
Space [0, 1] n is actually a self space after normalization using (2). Its boundary is either the maximum or the minimum value of the self samples, which cannot represent the whole system space. Therefore, the detectors generated in this [0, 1] n space cannot represent the nonself space.
The original samples must be normalized following the same procedure to guarantee their comparability, so as the unknown samples. However, the dimension of some feature vector of the unknown sample may exceed that of max[
For real-world applications, the range of the feature vector in the nonself space is unknown, and only part of the self space samples can be used to estimate the self space. It is very important to normalize the whole system state space before any other manipulations. An improved normalization method is proposed based on the RRNS and the RVM methods.
Let max[
Assumption 5. Assume that the self space is in the middle of the whole system state space. Range of feature vectors in the self space is 1/3 of the whole space. The nonself space occupies the rest larger 1/3 and the smaller 1/3 of the range [0, 1]. The following equations exist accordingly:
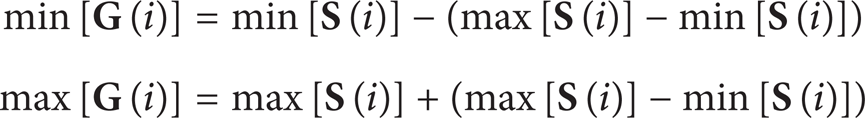

Assumption 6. Assume that

The following normalization is proposed based on Assumptions 5 and 6:
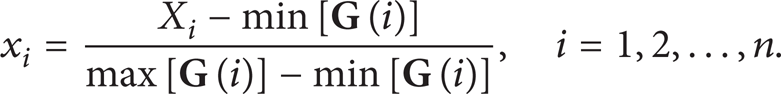
By substituting (3) into (6), the normalization equation related only to the self space samples is obtained, which is

After normalizing all the n dimensions, the feature vector,
Remarks. This algorithm combines RRNS and RVM, where the detectors generated by RRNS are considered as the set of nonself samples, together with the set of self space samples, serving as the two classes of samples for training the RVM classification model. The main purpose here is to construct a hyperplane for the classification between the self space and the nonself space.
The proposed normalization method maps the original self space into the center of the system state space surrounded by the nonself space. Therefore, it is possible to train and find the hyperplane separating the self space and the nonself space.
The normalized samples occupy the center 1/3 range. The self space and the nonself space are balanced in either the positive direction or the negative direction, which enables the training of the classifying hyper plane, that is, the smallest irregular hypersphere containing the self space samples.
After the training succeeds, the truncated samples and the results after truncation are considered as nonself samples. Therefore, the truncation does not affect the classification. The classification model can be applied in the whole
2.3. Immune Relevant Vector Machine (IRVM) Nonself Detection Algorithm
According to the mechanism of biological immune recognition, the traditional immune recognition algorithm generates a large number of detectors using different negative selection algorithms. The detectors are then compared with unknown state samples to detect anomaly. Although the method is simple and intuitive, its efficiency is usually low because the number of detectors is too large in practice, which inhibits the application of the method.
In the studies here, the detectors are generated as the nonself supervized learning samples because they are evenly distributed in the nonself space, which are then trained using RVM. Those are the most important ideas of the immune relevant vector machine nonself detection algorithm.
Figure 1 is the flowchart of the IRVM nonself detection algorithm, including the training phase and the detection phase. During the training phase, the training samples are the self space samples instead of the nonself space samples. Three steps are required during the training phase.
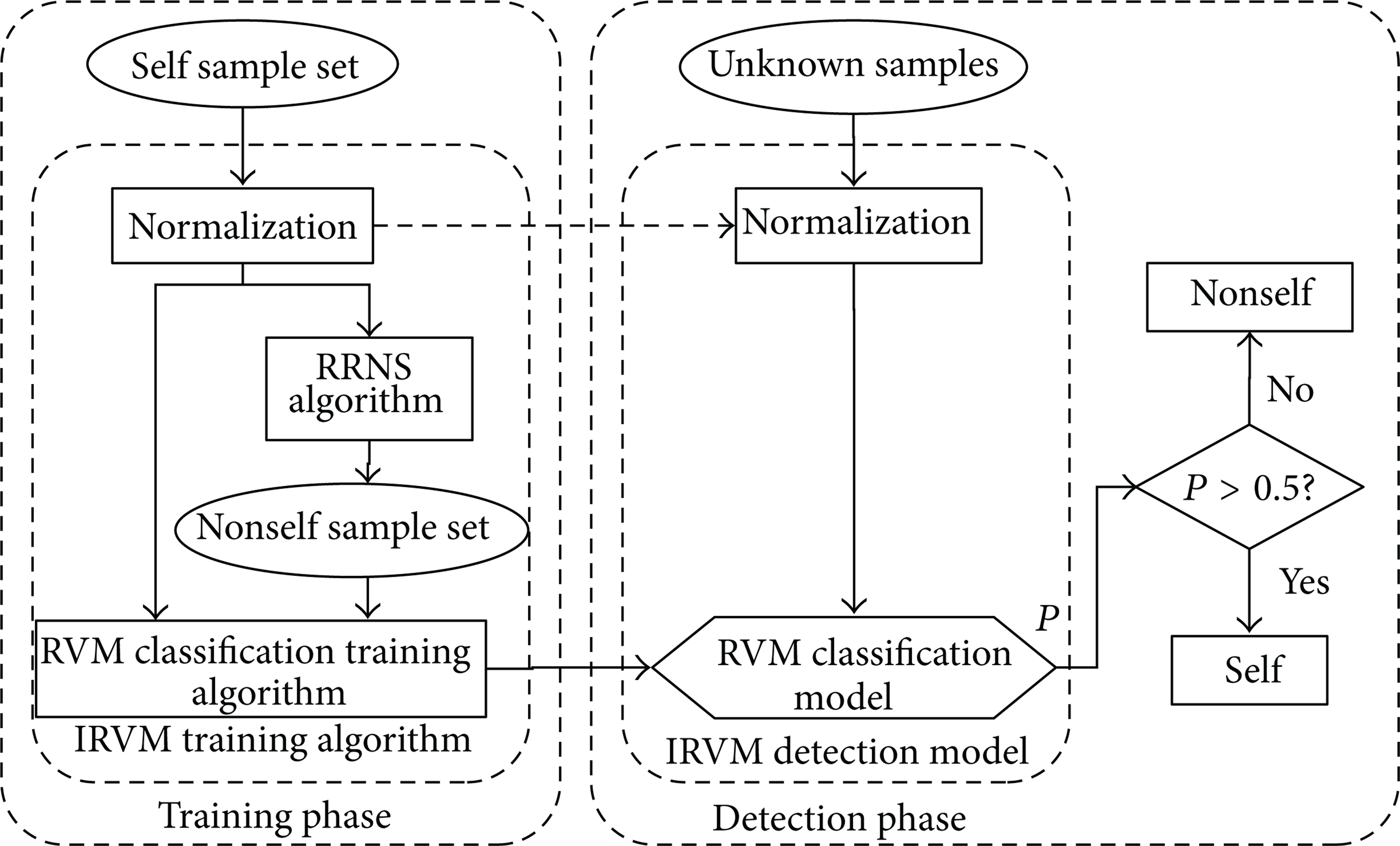
Flowchart of the relevance vector machine based nonself-detection algorithm.
Step 1. The system state space normalization: The self sample set is normalized according to (7), denoted as
Step 2. Nonself sample generation: A fixed number of detectors are generated in the system state space using RRNS based on the self sample set
Step 3. RVM classification model training: Merge the self sample set
The IRVM training algorithm can be considered as a combination of the normalization, RRNS, and the RVM classification algorithm, as shown in Figure 1. IRVM nonself detection algorithm requires only one class of training samples and can obtain the RVM classification model for two classes.
During the detection phase, RVM nonself detection model contains two parts, the normalization process and the RVM classification model training, whose output is the posterior probability. If the posterior probability is greater than 0.5, then the sample is a self sample, otherwise, a nonself sample.
The combination of RRNS algorithm and RVM algorithm in the IRVM nonself detection algorithm exploits the RRNS ability of simulating nonself samples in the nonself space and adopts the RVM advantages of being simple and fast at the same time.
3. Fault Detection and Diagnosis Based on Immune Relevant Vector Machine
3.1. Fault Detection Model Based on IRVM
Fault detection is a typical classification problem for two, since only the normal state and the fault state exist. The fault diagnosis model based on IRVM classification needs only the normal samples. The model treats the feature vector space under normal conditions as the self space and the feature vector under fault conditions as the nonself space.
The IRVM fault detection system is shown in Figure 2, including the model training phase and the online detection phase. Compared with Figure 1, the whole system is included in this figure.
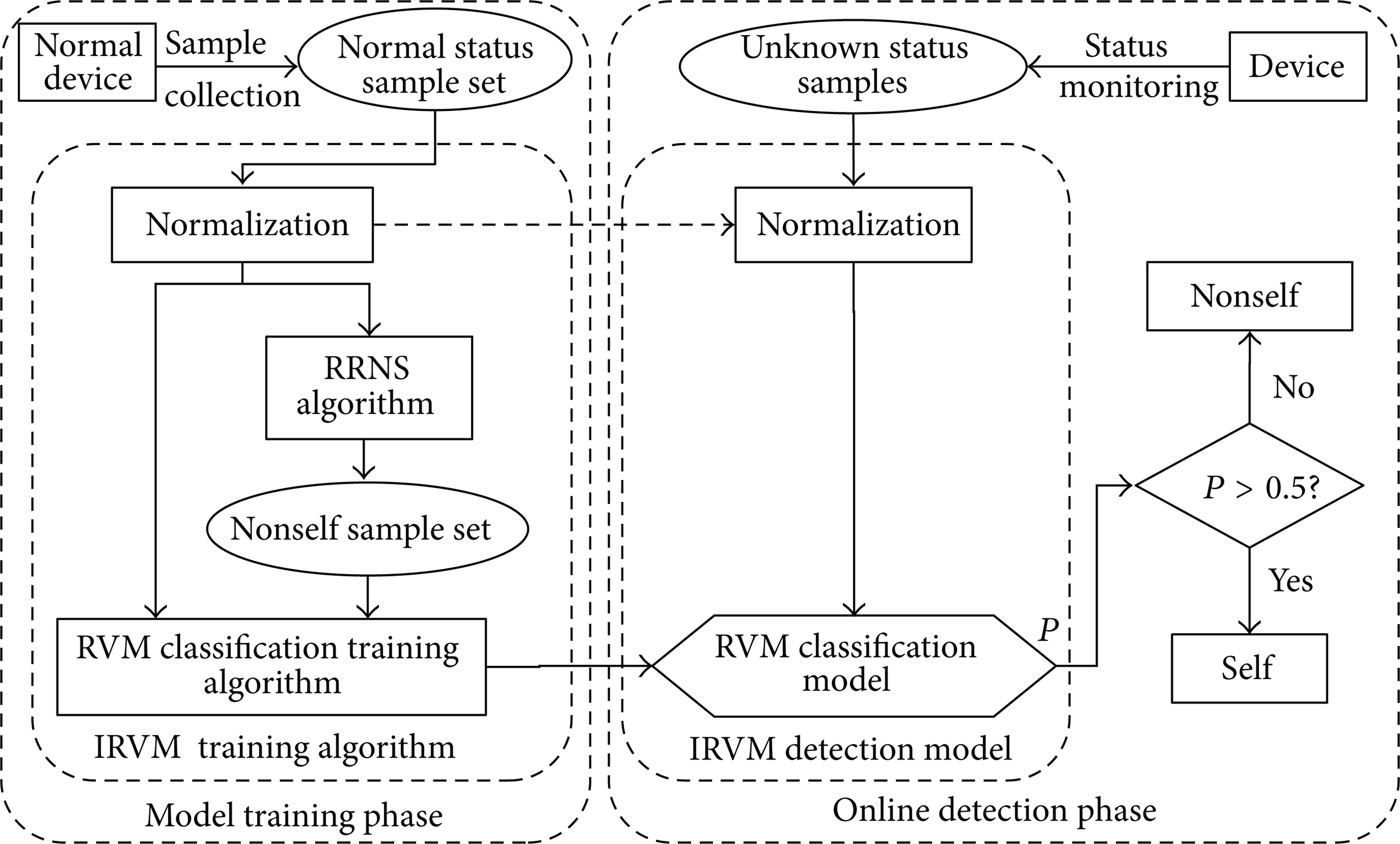
Immune relevance vector machine based fault detection system.
Two steps are included in the model training phase.
Step 1. A number of normal state samples are collected, the characteristic features are extracted, the feature vectors are constructed, and the set of normal samples is formulated. According to the real working conditions, different types of data may be collected to validate of the final detection model under different working conditions.
Step 2. The IRVM fault detection model is gained after the training of the normal state samples according to the IRVM training algorithm.
During the online fault detection phase, the state data are collected, the feature vectors are extracted, and the unknown state samples to be tested are then formed and input to the IRVM fault detection model. Whether the state is a fault state or a normal state is determined according to the posterior probability output.
3.2. Fault Diagnosis Model Based on IRVM
Traditional immune detection algorithm determines self and nonself modes and then detects anomaly. In many cases, to detect fault is usually not enough. The class of the faults and the level of faults need detection too, which forms a multi-class classification problem. Explanation on how to diagnose multiple fault classes using the immune relevant vector machine nonself detection algorithm is illustrated in the following paragraphs.
The framework of IRVM fault diagnosis model for multiple classes is plotted in Figure 3. The model is composed of multiple IRVM single class fault diagnosis models. Each IRVM single class fault diagnosis model is trained in the same way as that shown in Figure 2, while its training sample set is the fault sample set of one specific fault class instead of a normal sample set. During the training phase, one IRVM detection model for one class of failure is trained according to the IRVM training algorithm.
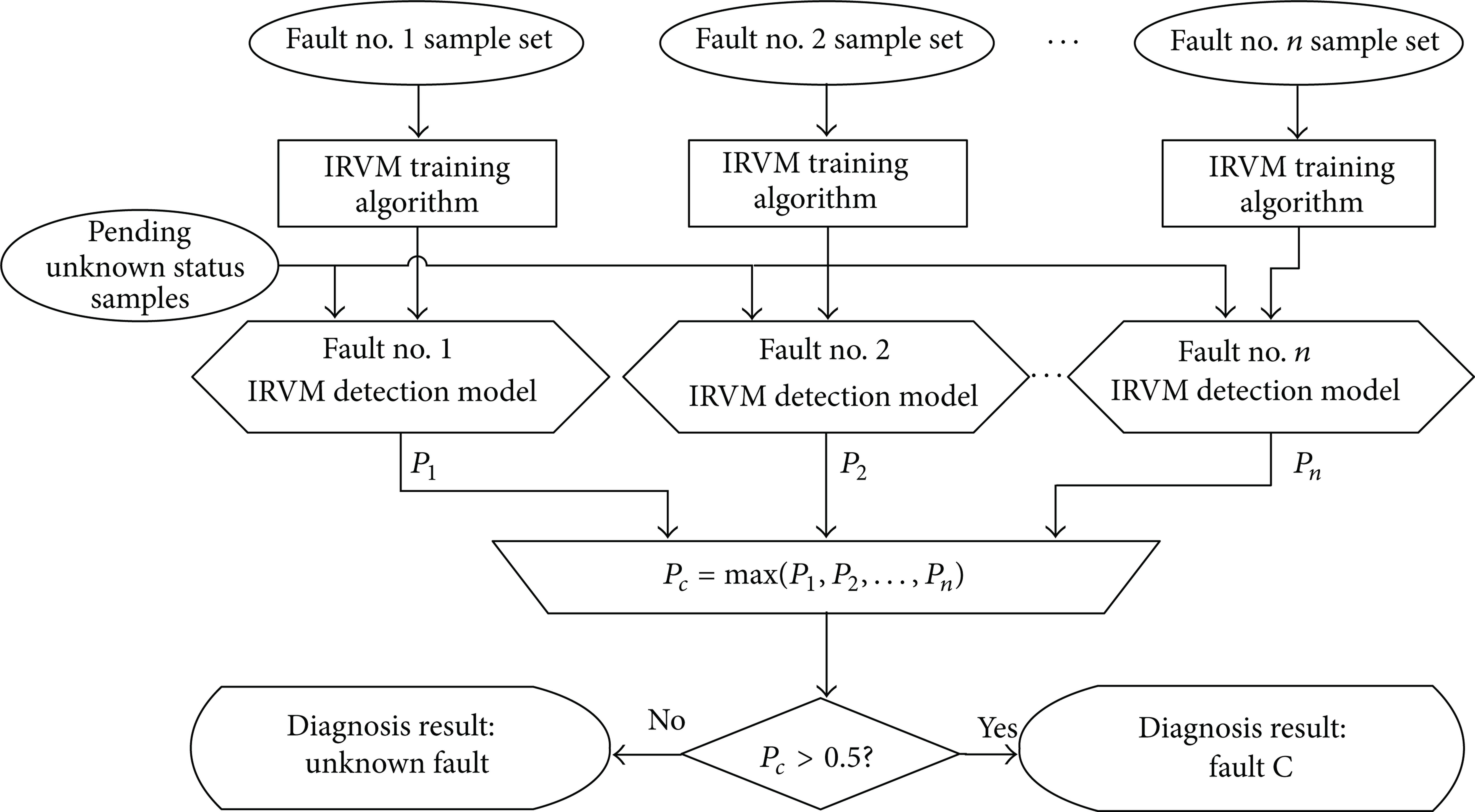
Principle of the construction of IRVM based multiclass fault diagnosis model.
For detecting multiple fault classes, the procedure is as follows: first of all, the unknown sample to be detected is input to every IRVM detection model. Then a posterior probability output is obtained connecting with one class of failure. Afterwards, the largest posterior probability is selected and the referred class becomes a candidate failure class. If the posterior probability is greater than 0.5, then the referred class of failure is the model output. Otherwise, if no class has the posterior probability greater than 0.5, then this testing sample does not belong to any known fault class and is detected as an unknown class.
The IRVM multi-class fault diagnosis model includes all target fault IRVM detection models together with a combinational detection rules:

The structure of the IRVM multi-class detection model is similar to that of the standard RVM one against All (RVM-OAA) algorithm, but the OAA method does not actually occupy the whole nonself space since it uses the samples other than the target samples as the nonself space sample, which may lead to misclassification of unknown classes and wrong diagnosis. Therefore, IRVM has better generalization ability than the RVM-OAA method.
4. Experimental Validation and Analysis
In order to verify the effectiveness of the IRVM nonself detection algorithm, the standard Fisher's Iris dataset is used for experimental verification and analysis. The experiment results are also compared with those of the support vector data description (SVDD) [15] method, another commonly used anomaly detection method in the area of fault detection.
4.1. Experiments on Model Verification with the Fisher's Iris Data
Fisher's Iris is a commonly recognized dataset for algorithm verification in the area of machine learning. The Iris dataset has four features of three types of irises. The three types of irises are Setosa, Virginica, and Versicolor. Each type of irises has 50 samples with a total of 150 sample data. The four features are the petal length, petal width, sepal length, and sepal width.
During the experiments, Setosa is considered as the self type, while Virginica and Versicolor are considered as the nonself types. Forty Setosa samples are randomly chosen as the training samples of the self space and the rest of the samples are all the testing samples. The experiment is repeated for 5 times to reduce the random error and carried on with 2 features (feature 1 and feature 2) and 4 features separately for visualizing the algorithm effectiveness. The 2-dimensional data distribution is shown in Figure 4. Figure 4(a) is the original data distribution and Figure 4(b) is the data distribution after the normalization.

Data distribution of the Iris dataset. (a) Original value. (b) Normalized value.
4.2. Results and Analysis
Tables 1 and 2 list the results for the 2-dimensional and the 4-dimensional Iris data, respectively. Tr. Err, Te. FP, and TE.FN are the training error rate, the testing false positive rate, and training false negative rate, respectively.
Results for the 2-dimensional Iris data.

Results for the 4-dimensional Iris data.

From Tables 1 and 2, the following conclusions are drawn:
IRVM does not have a training error while SVDD does.
Both IRVM and SVDD have a high accuracy for nonself testing samples; that is, both have low false negative rates. When all the 4 features are considered, the false negative rates are zeros, which indicates that the self set and the nonself set are highly separable.
IRVM has a better false positive rate than SVDD.
Generally, IRVM is more accurate and has better generalization ability when the self set and nonself set are highly separable.
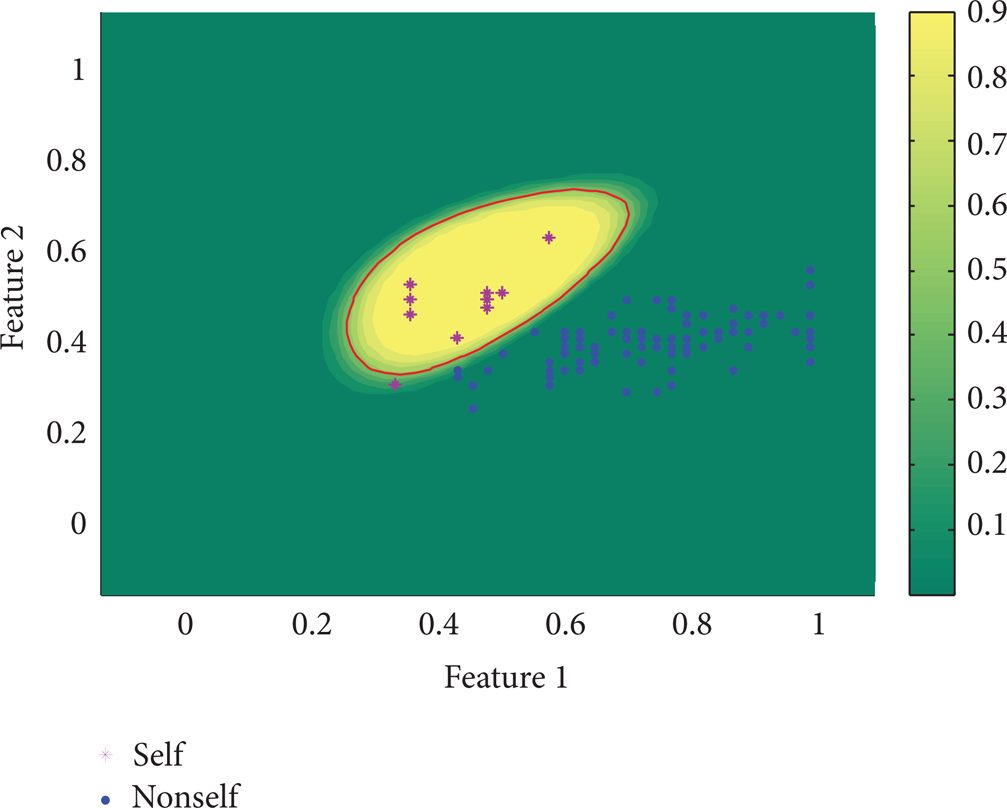
The RRNS-RVM training and testing results are depicted in Figures 5 and 6, respectively. Figure 7 is the comparative results using SVDD. Figure 5 shows the distribution of the self training samples, the distribution of nonself training samples using RRNS, as well as the dividing line of RVM model, the relevant vector points, and the posterior probability distribution. The following is seen:
RRNS can generate more evenly distributed nonself detectors, that is, nonself samples.
The dividing line from the classification model trained using IRVM wraps the self training sample set as a closed curve, separating the self space and the nonself space.
The improved normalization method balances the self space and the nonself space in every direction, which guarantees the training accuracy of the RVM model.

Training results of the IRVM experiment of Iris dataset.
Testing results of the IRVM experiment of Iris dataset.

Training and testing results of the SVDD experiment of Iris dataset.
Comparing Figures 5, 6, and 7, by observing the dividing lines of IRVM and SVDD, it is seen that IRVM has zero training error, while SVDD always has some training error. The reason is that IRVM is to find a closure through training, within which is the whole self sample space, while SVDD originates from anomaly detection, that is, to remove all the abnormal samples and minimize the false positive rate [16, 17]. Similarly, IRVM model has a much lower false negative rate than the SVDD model.
Iris dataset is a relatively simple and small dataset. The experiments here are basically for illustrative purposes. Interested readers may use several other datasets [18] to testify the performance of the proposed method.
5. Conclusions
In this paper, an immune relevant vector machine intelligent fault detection and diagnosis method is proposed, inspired by “self/nonself” recognition mechanism in the artificial immune systems. The method is able to handle the efficiency problem due to missing or incomplete fault samples in the traditional intelligent classification algorithm, since it combines the random real-valued negative selection (RRNS) algorithm in the artificial immune system and the relevant vector machine (RVM) algorithm. The detectors generated by RRNS are considered as the nonself training samples, which are used to train the RVM model together with the self samples. The detection model is then obtained requiring only the self samples. Based on the model and the method, the fault detection can be performed using only the normal samples, and the known and unknown faults can be identified accurately with incomplete training samples. The method proposed adopts the advantage of the RNSS algorithms and outranks the traditional immune algorithms with reduced computation load and improved efficiency.
Footnotes
Acknowledgments
This paper is supported by the National Natural Science Foundation of China under Grant 61175038, Shanghai Education Commission Project (nos. 12YZ010, 12JC1404100, 11CH-05).