
Abstract
An efficient and rapid method for car detection in video is presented in this paper. In this method, rear side view of cars is used in the detection phase. And in combination with histograms of oriented gradients (HOG) which is one of the most discriminative features, a linear support vector machine (SVM) is used for object classification. Besides, in order to avoid car missing, Kalman filter is used to track the objects. It is known that the calculation of HOG is complex and costs the most run time. So the processing time in this method is decreased by using information of objects' areas from the previous frames. It is shown by the experimental results that the detection rate can reach 96.20% and is more accurate when choosing the fit interval number such as 5. It is also illustrated that this method can decrease the calculating time on a large degree when the accuracy is about 94.90% by comparing with traditional method of HOG combining with SVM.
1. Introduction
Robust on-road vehicle detection and tracking is a key issue for developing a driving assistance system and safe driving in urban area. Due to huge class variability in objects' appearance, there is very big challenge using optical sensors in on-road multiobjects detection and tracking [1]. Usually, background subtraction method [2, 3] and frames subtraction [4] are used to detect moving objects based on video. For example, Collins et al. take an algorithm named VASM [5], and Zhu et al. get the different regions for the background update of background subtraction based on frames subtraction [6]. Both of them improve the rate and accuracy of detection to a certain extent. However, the key of background subtraction method and frames subtraction is a relatively stable background image. But the images of vehicle video change constantly. So the aforementioned two methods are useless for us. Also, some people use shadow to get the size and position of vehicles [7]. But this method depends on the light too much. It will have a giant impact on detection when the brightness changes. Some people use histograms of oriented gradients (HOG) [8–10] features to detect the vehicles. HOG features can be used to detect objects while the background and the brightness are changing. However, the traditional method to compute HOG features always spends too much time. So finding a rapid and efficient way to deal with this problem is very important.
In this paper, in combination with histograms of Oriented Gradients (HOG) which is one of the most discriminative features, a linear support vector machine (SVM) is used for object classification. Besides, in order to avoid car missing, Kalman filter is used to track the objects. In order to save the computing time, an efficient method is presented which uses the feedback information from the previous frames to reduce the detection scopes. This method can improve the detection efficiency greatly while ensuring the detection accuracy.
2. Car Detection Based on Histograms of Oriented Gradients (HOG) Features
At present, the approach that combined HOG with SVM has been widely applied to image recognition and achieved a great success especially in object detection. In this paper, linear SVM classifier with HOG features is used to realize classification and recognition. In detection phase, two important methods are feature description and classifier training.
2.1. Histograms of Oriented Gradients (HOG)
Histogram of oriented gradient (HOG) is a method of intensive descriptors used for local overlapped images and constitutes features which are obtained by calculating the local direction of gradient. The HOG described method has the following advantages compared with other features: (1) HOG is represented by the structural characteristics of the edge (gradient) and thus can describe partial shape information; (2) the translation and rotation impact quantized on the position and direction of the space can be suppressed to a certain extent; (3) taking the method that uses the local normalized histogram can offset the influence of light change. If HOG features are taken as local descriptors, car features can be constituted by computing local direction of the gradient. So the local direction of the gradient is the key factor to constitute car features. The gradient of the pixel of (x, y) in an image can be denoted as
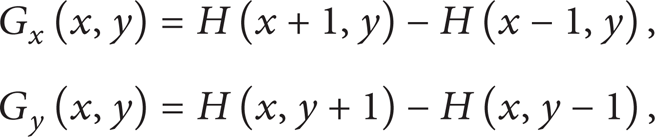
where G x (x, y) denotes the horizontal direction gradient of input image pixel, G y (x, y) denotes the vertical direction gradient, and H(x, y) denotes the pixel values. Then the gradient magnitude and direction of (x, y) can be represented as
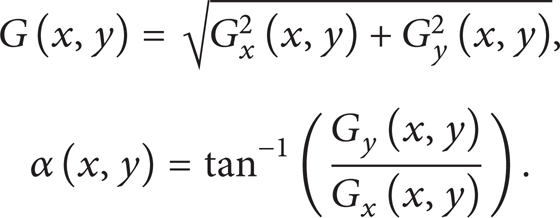
In our experiment, the size of images we select is 64*64. The procedure of extracting HOG features is as follows.
First, an image is inputted which is one of the sample library or the regions of interest (ROI).
Second, the gradient is calculated using [anjan10] and median filter to perform filtering.
The third step is computing the vertical and horizontal gradient of the image and the gradient direction and magnitude of every pixel.
Fourth, the range of 0°–180° is divided into 9 equal parts, so there are 9 channels in total. Because one block has four cells (2*2 cells), there are 4*9 = 36 features in each block. In the image of 64*64, there will be 7 scanning windows in both horizontal direction and vertical direction when scanning image with 8 pixels. So, the number of features in the image of 64*64 is 36*7*7 = 1764.
Fifth, it is got that the statistics of every pixel in each cell of their histogram of orientated gradient.
Sixth, in step four, there are 9 equal parts that are divided from 0°–180°. Now each part has its summation of the gradient. Therefore, we have a series of vectors. Then we should normalize these vectors in blocks. The normal method of normalization is as follows:
Finally, combine all these vectors processed above and get a series of vectors, which are HOG features of this image.
2.2. Support Vector Machine (SVM)
SVM [11–13] is based on the development of statistical learning theory and has a relatively good performance. Through the learning process, SVM can automatically find a support vector classification which has better discrimination ability and construct a good classifier.
In this paper, the method based on the linear SVM combining HOG features is used to realize classification and recognition. The nature of linear SVM is that in the case of the samples which are linearly separable, a hyperplane, which can separate the training samples completely, is found out.
In order to get good performance, the classifier is trained in three steps. Fisrt, 11953 positive samples are manually made and 94982 negative samples are automatically generated by using image frames without vehicles. All the samples are scaled to the size of 64*64 and then used for classifier training. Second, since some easy cases can usually be correctly classified, the training process should focus on the difficult samples. Thus, the false positive and false negative samples after the first round of training are selected to train the classifiers one more time. This may take few rounds. At last, all trained HOG features are combined to train the final SVM classifier.
3. Car Tracking Based on Kalman Filter
In this paper, Kalman filter [14–16] is introduced for object tracking. It can help system improve the accuracy of car tracking and decrease the losses of frames. The filter estimates the process state at some time and then obtains feedback in the form of noisy measurements.
The Kalman filter is based on a state equation and an observation equation. The state equation and the observation equation are given by the following:


In the formulas, x k and xk – 1 denote the state vector of k – 1 moment and k moment; z k denotes the observation vector of k moment; Ak, k – 1 stands for the state transition matrix from k – 1 moment to k moment; H k stands for the observation matrix; ξ k stands for the system noise, ξ k ∊ N(0, Q k ); η k stands for the observation noise, η k ∊ N(0, R k ). Q k , R k is the variance of ξ k and η k .
Usually, there are two parts of Kalman filter. The first one is prediction. It is based on the state equation (3) and used to get the prediction of state vector and error covariance. The prediction part is shown as follows.
State vector prediction equation is as follows:
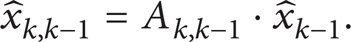
Error covariance prediction equation is as follows:

The second one is correction. It is based on observation equation (4) and used to correct the prediction vector and get the x k and the minimum error covariance matrix. The correction part is shown as follows.
Kalman filter gain equation is as follows:
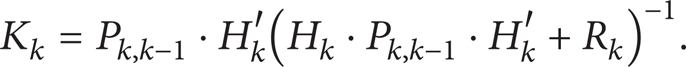
Correction state vector is as follows:
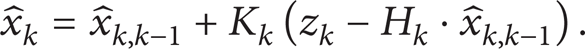
Correction error covariance matrix is as follows:

According to the principles of Kalman filter, the position of object can be predicted in the next frame. Thus, it is realized that Kalman filter can be introduced into object tracking to improve the accuracy of tracking and decrease the rate of object undetected.
4. New Method
According to the experiments, a great number of times are spent on calculating the HOG features while processing each video frame. To solve this problem, an advanced method is developed to deal with it in this paper.
It is known that the objects only occupy a small part in the picture and more regions are useless. Therefore, it can save much time in which the HOG features in useless regions are not computed. Our method is divided into four steps which are as follows.
Compute the HOG features in whole picture at first frame. Get objects without missing.
According to the information obtained from the first frame, set the regions of interest (ROI) in the second frame, compute the HOG features only in these regions, detect the objects that are related to those in the first frame, record their sizes and coordinates, and then set new ROI. In next few frames, repeat these operations.
It may make mistakes computing the HOG features only in ROI because new objects will appear in other areas. To avoid this problem, the HOG features in whole picture are calculated in some predetermined frames (such as 5, 10, 15, …) every few frames (such as when interval number is 5).
Occasionally, some objects are undetected in few frames. In order to avoid the missing objects, Kalman filter is used to track them and get higher accuracy.
The algorithm flow is shown in Figure 1.

Flow chart of setting regions of interest.
Now, four images are used to illustrate this new method. In the following images, there are three cars and the most of the regions is useless. It is unnecessary to calculate HOG features in the whole image. The areas where objects locate are valuable for us. So removing the useless regions is very important to decrease the calculation time.
Figure 2(a) shows the original image. Compute HOG features in the whole image and three cars are detected. The detection result is shown in Figure 2(b) with blue rectangles. The tracking result is shown in Figure 2(c) with yellow rectangles. Then set the regions of interest (ROI) in next frame based on the feedback information of the detection results of this frame. The regions are shown in Figure 2(d) with red rectangles.

Set the regions of interest (ROI).
The red rectangles are the ROI and objects will most likely appear in these regions in the next frame. So we only need to compute HOG features in the ROI except for the entire image. Thus, the calculation time will be decreased much by using the aforementioned method.
5. Experiments
In our experiments, a clip of vehicle video taken in realistic environment is chosen as test material. Through the experiments, our advanced method is adopted that is mentioned above to detect running vehicles on the road. In the experiments, interval number is taken as a variable parametric to test the relation between efficiency and accuracy. It is shown from the experimental results that the larger the interval number, the less the time cost. But it is also shown that the detection accuracy would decrease with the interval number increasing. In the following example, the interval number is chosen as 0, 5, 10, and 15.
In the start frame 3241 shown in Figure 3, there are three cars. The left and the middle car in this frame have been detected and tracked in previous frame. The right car just appears in this frame. According to our method, HOG features are not computed in the whole picture in frame 3241. So the new appearing car cannot be detected in this frame.

Detection and tracking results in frame 3241 when the interval number is 0.
If some relatively small interval numbers are chosen, such as 5, 10, and 15, the right car will be detected firstly in frames 3246, 3251, and 3256. Here is the reason. In frame 3241, the algorithm computes HOG features in the entire image. When the interval number is 5, 10, and 15, it will compute HOG features in the whole image next time in frames 3241 + 5 = 3246, and 3241 + 10 = 3251, 3241 + 15 = 3256. The results are shown in Figure 4. It is suggested by the results that when one of 5, 10 and 15 was selected as interval number, the method can achieve better detection and tracking performance.

Detection and tracking results when the interval number is 5, 10, and 15.
However, if 30 is chosen as the interval number, our method will compute HOG features in the whole picture again in frame 3271 after frame 3241. Because the car is going to disappear from frame 3267, there is only a half of the car in frame 3271. Thus, the car cannot be detected. They are shown in Figures 5 and 6. Based on these results, the case of missing detection would probably happen if the interval number is over large.

The detection result in frame 3267 when the interval number is 30.

The detection result in frame 3271 when the interval number is 30.
In order to solve this problem, we conduct several experiments based on different interval numbers. At first, the common method is used. Then our new approach is adopted and HOG features are computed in the whole image each 5, 10, 15, and 30 frame. The resolution ratio of the test video is 640*480 in our experiments. The duration of the video is 8 minutes and 50 seconds. Its frame rate is 18 frames per second. The experiments are carried out on a computer with AMD Athlon (tm) X2 250 Processer, MMX, 3DNow (2 CPUs), ∼3.0 GHz, and 3.25 GB RAM. The results are shown in Table 1.
Experimental results of time consuming and detection accuracy.
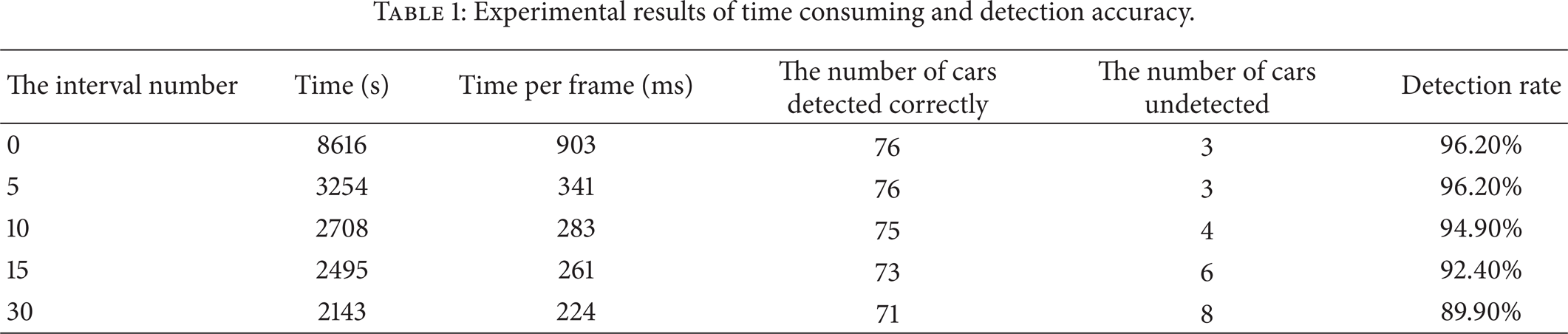
It is presented in Table 1 that the calculation time is reducing with the interval number becoming larger, while the detection rate is decreasing though they all have good detection performance. What is more, the calculation time is reduced about 2.65 times when the number of the interval frames changes from 0 to 5. It has greatly reduced the cost time. But the computation time is reduced only tens of milliseconds when the interval number changes from 5 to 10, 10 to 15, or 15 to 30. It is not much improved. So it is unnecessary to use a huge interval number to have a shorter time. Considering about detection rate, choose 10 as the interval number. Under this condition, the method can have both a short time and a high detection rate.
6. Conclusion
This paper presents a method based on vehicle video for multivehicles detection. It uses HOG features to describe the objects and linear support vector machine (SVM) to realize classification and recognition. In order to reduce the computation time, a new method is provided in which the computation time is reduced by reducing the detection areas of the current frame through the feedback information of the previous frame. According to the experimental results, the computation time is greatly reduced and the detection rate is high with low interval number. Therefore, when a balance point is got, our method will have higher efficiency and better accuracy.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Footnotes
Acknowledgments
This work is supported by Project of Beijing Municipal Commission of Education (no. KM201210009008) and Natural Science Foundation of China (no. 61103113).