
Abstract
The service-oriented architecture is considered as a new emerging trend for the future of wireless sensor networks in which different types of sensors can be deployed in the same area to support various service requirements. The accuracy of the sensed data is one of the key criterions because it is generally a noisy version of the physical phenomenon. In this paper, we study the node selection problem with data accuracy guarantee in service-oriented wireless sensor networks. We exploit the spatial correlation between the service data and aim at selecting minimum number of nodes to provide services with data accuracy guaranteed. Firstly, we have formulated this problem into an integer nonlinear programming problem to illustrate its NP-hard property. Secondarily, we have proposed two heuristic algorithms, namely, Separate Selection Algorithm (SSA) and Combined Selection Algorithm (CSA). The SSA is designed to select nodes for each service in a separate way, and the CSA is designed to select nodes according to their contribution increment. Finally, we compare the performance of the proposed algorithms with extended simulations. The results show that CSA has better performance compared with SSA.
1. Introduction
Sensing is considered as one of the most important technologies especially in the emerging big data era. Nodes with sensing ability can be deployed everywhere in the world including airspace, ground, and underwater environment due to their cheapness, simplicity, and small size. Moreover, the wireless radio allows these sensor nodes to be organized into a network, which is generally named as Wireless Sensor Networks (WSN) [1], and local information about the environment is then sensed and reported to the base station in a periodical manner. It is obvious that the wireless sensor networks will create a huge number of data with time ongoing and the number of network increasing. Accordingly, one challenging issue is how to utilize these various wireless sensor networks in the future big data era.
The current wireless sensor networks are generally data-centric or application-centric, which means that each sensor node serves for one special application. However, with the number of different applications increasing rapidly, heterogeneous wireless sensor networks appear and they might be located in the same physical areas providing different data-collection functions. How to connect these heterogeneous wireless sensor networks efficiently is still a pioneering work in the future ubiquitous computing environment due to several observations. Firstly, two different applications may be interested in the same collected data, and it is unnecessary to place two separate nodes with identical sensing devices but different tasks. Secondary, in case that one application is concerned with several different types of sensed data simultaneously, such a requirement is not guaranteed since current solutions work only in a separate way. Finally, the emergence of powerful sensors, which can provide different types of data sensing, has introduced new issues in the research of wireless sensor networks since they can support different applications simultaneously.
Accordingly, the service-oriented architecture appears as a new emerging trend for the future of wireless sensor networks, in which sensor networks are considered as the services provider and sensors as the data sources for these services [2]. Users and programmers can access the service-oriented wireless sensor networks by using a simple service-oriented interface and utilizing encapsulation of the low-level implement details. Services in wireless sensor networks may be the sensing capabilities for example, temperature and humidity or software components provided by nodes, for example, the operations of in-network data aggregation, time synchronization, and data processing [2–5]. The data sensing of nodes can also be defined as the sensing services, and sensed data as the service data similarly. Furthermore, the sensor nodes can be equipped with multiple types of sensing units used to collect environmental information. For example, the MICA2 mote [6] can provide services such as light, sound, and vibration.
In the heterogeneous applications scenarios, different types of sensors can be deployed in the same area to support various service requirements. Figure 1 shows an example of a service-oriented wireless sensor network including eight sensor nodes. The sensed sources are assumed to be located at positions

An example of a service-oriented wireless sensor network in which service
The accuracy of the sensed data is one of the key criterions while choosing nodes to provide required service. It is also known that sensor nodes are generally designed under the guideline of cheapness and simplicity and that they are mostly deployed in a dynamic and rough terrain for continuous environmental monitoring. The sensing equipment on sensor nodes is expected to be unreliable and the collected data to be distorted. Furthermore, some physical attributes exhibit a gradual and continuous variation over the two-dimensional Euclidean space due to the diffusion property and, thus, each observer has different distorted data. To collect all related data around the same sensing sources can help to eliminate or minimize the distortion. However, it might lead to heavy energy consumption in the network. Some applications only are concerned with approximate observations rather than exact results [7, 8], and it is unnecessary to gather data from all nodes in the network in this case. It shall also be mentioned that the diffusion property of physical attributes results in spatial correlation among sensed data observed by nodes closer to the same sensing source. Exploiting the spatial correlation can help to improve the network performance by selecting a subset of nodes to provide the required service with data accuracy guaranteed [9, 10].
Although the service-oriented architecture for the wireless sensor networks has already been introduced recently in related works [4, 5, 11–14], most of them are concerned with the practical architecture framework, such as middleware and platforms. Some works [13, 14] considered the node scheduling to support services query with network lifetime prolonged, and some others are concerned with the spatial correlationship among the sensed data with the service unconsidered [15–17]. To provide accurate service to users is an important issue and it is generally one criterion for the applications. In this paper, we focus on the heterogeneous service supporting problem in the future wireless sensor networks and aim at providing efficient node selection algorithms with data accuracy guarantee for the service-oriented sensor networks. Different from previous works, we consider the data accuracy for services by following the observation that sensed data is a noisy version of the physical phenomenon. And we have explored the data accuracy according to their spatial correlation for the same sensing sources.
Due to the inaccuracy and spatial correlation of the sensed data, it is a new and challenging issue to provide the required services with data accuracy guarantee in an energy-efficient way for the service-oriented wireless sensor networks. So far, as we know, this is the first paper concerned with both the data inaccuracy and spatial correlation in the sensor networks, and we aim at providing node selection algorithms so as to improve the network performance. The main contributions of this paper are summarized as follows. (1) We have proposed the node selection problem with data accuracy guarantee for service-oriented wireless sensor networks via bipartite graph and formulated it as an integer nonlinear programming problem to illustrate its NP-hard property. (2) We have also presented two efficient heuristic algorithms for this problem; namely, Separate Selection Algorithm (SSA) and Combined Selection Algorithm (CSA) with low-time complexity.
The rest of this paper is organized as follows. In Section 2, we summarize the related works. Section 3 describes the system model and the problem formulation. Sections 4 and 5 have introduced the integer nonlinear programming formulation and two heuristic selection algorithms. Section 6 describes and analyzes the simulation results. We conclude this paper in Section 7.
2. Related Works
This paper focuses on the node selection problem in service-oriented wireless sensor networks. Several works have been done to develop service-oriented architecture specific to the sensor networks, and the architecture has shown many advantages in the heterogeneous applications scenarios. Gračanin et al. [2] proposed a service-centric model that focuses on services provided by a wireless sensor networks and views a wireless sensor networks as a service provider. This model consists of mission, network, region, sensor, and capability layers. Within each layer, there are four planes or functionality sets: communication, management, application, and generational learning. Rezgui and Eltoweissy [4] introduced the service-oriented architecture as an approach for building a new generation of open, efficient, interoperable, scalable, application-aware sensor-actuator networks. In this vision, sensor-actuator networks would not be deployed to provide sensing and actuation capabilities to a specific application but, rather, to provide sensing and actuation services to any application. King et al. [5] developed a service-oriented sensor and actuator platform called Atlas, which enables self-integrative, programmable pervasive spaces. This platform has shown the advantage of improving communication and interoperability between heterogeneous devices in pervasive computing environments. Authors of [11] proposed TinySOA, a service-oriented architecture that allows programmers to access wireless sensor networks from their applications by using a simple service-oriented API via the language of their choice. The main advantage of TinySOA is relieving application developers from dealing with the low-level technical details of the wireless sensor networks to get sensors data. Corchado et al. [12] proposed a service-oriented telemonitoring system for healthcare using heterogeneous wireless sensor networks, which aimed at improving healthcare and assistance for dependent people.
It is an important issue to provide services efficiently with resource-constrained sensor nodes. Node scheduling is considered as an efficient technique to implement the service-supporting schemes, in which sensor nodes should be selected to provide requested services. Recently, Wang et al. [13] investigated the service-availability-aware sleep scheduling design in service-oriented wireless sensor networks. The purpose of this study is to minimize the energy consumption and guarantee that enough sensors are active to ensure service availability at all times. The authors had proven this problem to be NP-hard and presented heuristic linear-programming based-solutions. However, they assumed that each service has a known requirement on the number of active sensors based on the historical service composition requests in the system, which may not be the case in practice. Furthermore, they only consider the sleep scheduling design for the sensors in the service provider overlay network and neglect the routing cost of service data. Authors of [14] try to identify the service composition that is less likely to be invalid in the near future due to nodes going to sleep mode. The goal is to minimize the recomposition cost. They make use of the dynamic programming to reduce total service composition cost when the minimum number of required service composition solutions is derived. However, the dynamic programming is unsuitable for large-scale problems.
The distributed nature of wireless sensor network results in spatial correlation among the sensed data. And data accuracy is accordingly influenced by the spatial correlationship. Under different assumptions, researchers have proposed several mathematical models for spatial correlation in wireless sensor networks. Some [18] assume that the sensed data follow diffusion property, and some [17] use an empirically obtained approximation function for the joint entropy of sensed data. The most commonly used model is the jointly Gaussian [9, 19, 20], which assumes the data to be jointly Gaussian with the correlation being a function of the distance. The jointly Gaussian model is easy to use and analyze. However, the chief limitation is that it forces the joint probability density function of the data values to be jointly Gaussian. Some researchers [21] use variograms to analyze spatial correlation in wireless sensor networks. The proposed model is Markovian in nature and can capture correlation in data irrespective of the node density, the number of source nodes, or the topology. Furthermore, this model derives the data value at a node from other correlated nodes whose data values have already been derived. However, it is not always the case that a given spatial process will be Markovian. Some others proposed correlation model for specific applications, such as soil moisture measurement in wireless underground sensor networks [10]. The presence of spatial correlation among sensor network data has been exploited for solving different problems. The authors in [15] proposed a traffic model for wireless sensor networks, which takes into account the statistical patterns of node mobility and spatial correlation. In [16, 17], spatial correlation was used to design energy-efficient data aggregation algorithms. Ma et al. [16] proposed a distributed clustering algorithm based on the dominating set theory to choose the cluster heads nodes and construct clusters by measuring the spatial correlation between sensors. Pattem et al. [17] studied the correlated data gathering problem and followed the idea of using an empirically obtained approximation function for the joint entropy of sources.
It is important and challenging to provide different services with data accuracy guaranteed through unreliable sensors nodes. Fault tolerance is one of the most important techniques, which has been taken into consideration in many works [22–27]. Han et al. [22] addressed the problem of deploying minimum number of relay nodes to achieve diverse levels of fault tolerance with higher network connectivity in the context of heterogeneous wireless sensor networks. However, they adopted the network model that in which nodes possess different transmission radius, while all of the relay nodes use an identical transmission radius. Banerjee et al. [23] investigated the event detection scheme with fault tolerance for multiple events occurring simultaneously. They proposed the use of polynomial-based scheme that addresses the problems of event region detection by having an aggregation tree of sensor nodes. However, their work is limited to static sensor and the network topology cannot adapt to the dynamic nature of simultaneous events with varied priorities.
Our work in this paper is concerned with the node selection algorithms, which is similar to the works that aim at dealing with node selection and assignment problems. Cai et al. [28] addressed the multiple directional cover sets problem of organizing the directions of sensors into a group of nondisjoint cover sets to extend the network lifetime. The directional sensors are different from common sensors that have a limited angle of sensing range. The authors proved this problem is NP-complete and presented three heuristic approaches. Lin et al. [29] proposed an adaptive energy-efficient multisensor scheduling scheme for collaborative target tracking in wireless sensor networks. The challenging issue of this problem is how to achieve energy efficiency and track reliability while satisfying the tracking accuracy requirement. In their algorithm, a number of sensors are selected to form a temporary tasking cluster, and the optimal sampling interval is determined to satisfy the given tracking accuracy. Johnson et al. [30] considered sensor-mission assignment problem in wireless sensor networks. In this problem, multiple missions compete for sensor resources. They showed that this problem is NP-hard even to approximate, and presented several heuristic algorithms. Liu et al. [31] studied the topology control problem using a probabilistic network model. They attempted to find a minimal transmission range for each node while the global network reachability satisfies certain threshold. Different from these previous works, we aim at providing efficient node selection algorithms with data accuracy guaranteed for the service-oriented wireless sensor networks by exploring the spatial correlation among the sensed data and the advantages of diverse services provided by different sensor nodes.
3. System Model and Problem Formulation
In this section, we have firstly introduced the network model for the service-oriented wireless sensor networks. Secondly, we have described the spatial correlation model for single as well as multiple services in the network. Finally, we have formulated a definition for the node selection problem with data accuracy guaranteed in the service-oriented wireless sensor networks.
3.1. Network Model
We consider a wireless sensor network in the plane with stationary nodes
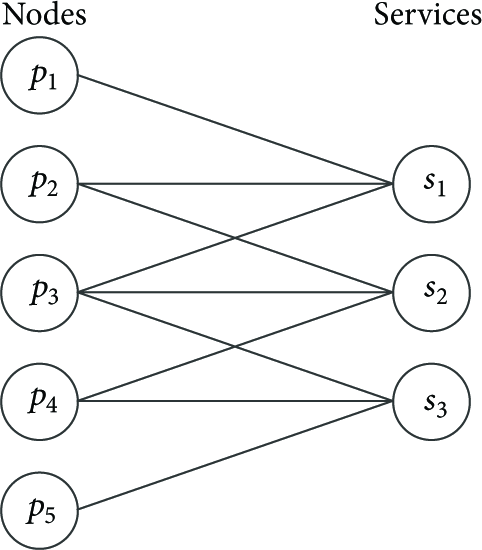
An example of the bipartite graph in which each service is supported by three distinct nodes.
To be convenient, the symbols used in this work are summarized in Table 1.
Description of the symbols.

3.2. Spatial Correlation Model
Researchers have proposed several mathematical models for spatial correlation in wireless sensor networks under different assumptions. Pattem et al. [17] proposed to use an empirically obtained approximation function for the joint entropy of sensed data. In [18], the sensed data is assumed to follow the diffusion property and the diffusion is formulated as a function of the distance. The jointly Gaussian is adopted in many related works [9, 19, 20], which assumes the data to be jointly Gaussian with the correlation as a function of the distance. The jointly Gaussian model is easy to use and analyze by forcing the joint probability density function of the data values to be jointly Gaussian. Jindal and Psounis [21] analyzed the spatial correlation among sensed data by using variograms in wireless sensor networks. The proposed model is a special case of Markov random field. In this model, the data value at a node is derived from other correlated nodes whose data values have already been derived. However, it is not always the fact that a given spatial process will be Markovian. In this paper, we are concerned with the data accuracy with the spatial correlation model. The jointly Gaussian model proposed in [9] has considered the measurement noise of nodes and given the distortion function, which is suitable for our problem.
In the senor networks, the observation result of each node is in fact a noisy version of the physical phenomenon located at the sensing source, and it can be modeled as Gaussian random variable Vof zero mean and variable 
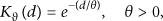
The collected data by the sensor node 
According to [9], the distortion of the estimation for V is formulated as
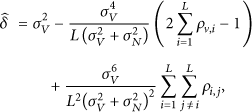
We use 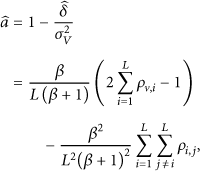
3.3. Problem Definition
In this paper, we study the problem of node selection in the service-oriented wireless sensor networks with the data accuracy requirement guaranteed for the services. The number of nodes is considered as the optimizing object due to the following considerations. Firstly, there are fewer packets to be transmitted in the network if we select less number of nodes to provide services, which is also helpful to reduce the energy consumption. Secondarily, it will increase the collision probability in the contention-based wireless network if too many nodes are kept awake, and significant retransmission cost and additional delay occur accordingly. Finally, it helps to reduce the overhead of data transmission to allow one node to provide multiple services simultaneously. In case that the data of different services is correlated, it can be compressed into a smaller packet; even in the uncorrelated case, it can still be transmitted in a single packet, and thereby it is helpful to reduce overhead in the network [32].
In this paper, we aim at providing node strategies with the number of selected nodes minimized. Let
4. Integer Nonlinear Programming Formulation
In this section, we present an Integer Nonlinear Programming (INLP) formulation for the node selection problem. Integer programming is a mathematical optimization or a feasibility program in which some or all of the variables are restricted to be integers. INLP is a special case of integer programming, where some of the constraints or the objective functions are nonlinear. INLP is considered as an efficient technique to solve the optimization problem with nonlinear constraint, so that it is feasible to express the node selection problem as INLP. This paper is concernd with the node selection problem, and the objective is to minimize the total number of selected nodes with nonlinear data accuracy constraint. We use the following set of binary integer (0 or 1) variables and constraints in the INLP formulation.
(1) Variables 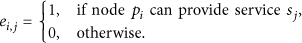
(2) Variables 


In order to satisfy the required data accuracy for all services in the network, we have the following constraint:

(3) Variables 

Then the node selection problem discussed in this paper can be formulated as
5. Heuristic Algorithms
Heuristic algorithms are generally considered as an important way to solve the NP-hard problem. In this section, we propose two heuristic algorithms for the node selection problem in the service-oriented wireless sensor networks, namely, the Separate Selection Algorithm (SSA) and the Combined Selection Algorithm (CSA).
5.1. Separate Selection Algorithm (SSA)
The basic idea of the Separate Selection Algorithm (SSA) is that we select a minimum number of nodes for each required service with the data accuracy guaranteed in a separate way, and the union of selected nodes for all services is considered as the problem solution. The key process for the SSA is how to select nodes for each service. Here we follow the idea with which nodes are selected in a sequence way, and in each step, we will choose the node that is potential to improve the data accuracy.
Assume that the current node selection solution is In case that In case that In case that In case that
The pseudocode for SSA is listed in Table 1. In Line 1, the set of selected nodes
We illustrate the SSA algorithm by an example given in Figure 3. As we can see from Figure 3(a), the network has four nodes and each service is supported by three distinct nodes. The required data accuracy for each service is listed on the right side; for example, the required data accuracy of
An example of the execution of SSA algorithm. (a) The node-service bipartite graph
5.2. Combined Selection Algorithm (CSA)
The previous proposed SSA tries to select nodes for each separate service based on the criterion of data accuracy increment. However, some nodes will provide several services simultaneously in the wireless sensor networks, and this multiservice property can help to improve the performance of node selection strategies if we simply select one multiservice node to improve the data accuracy required by different services. As we can see from Line 4 in Algorithm 1, we intend to select the candidate node that is already chosen to provide some other service in SSA algorithm, which means that nodes with multiservice property are more preferred in SSA algorithm during node selection process. However, this separate selection process is not always efficient especially in some cases. For example, the sample network given in Figure 3 can obtain a better solution than the solution found by SSA. If we do not select
1: 2: 3: 4: Calculate data accuracy increment select the one identical increment, the node included in 5: If no such a candidate is found, the algorithm stops with no solution found; 6: 7: 8: 9:
In this paper, we aim at minimizing the number of selected nodes with the data accuracy guaranteed for all services in the network. There are two important factors that will influence the number of selected nodes; that is, the number of services and the service quality of each node. Intuitively, it helps to reduce the number of selected nodes in case that they can provide more kinds of services since more nodes are potential candidates during the selection process. However, nodes might have poor data accuracy when they are far away from the sensing source although they can provide the required services. It means that we shall consider the data accuracy as well as the number of services simultaneously during the node selection process.
The basic idea of the CSA is described as follows. Initially no nodes are selected and the final solution is an empty set. Then, nodes are chosen and added into the final solution in a sequence way. In each step, we intend to select the node with maximal contribution increment to all services in the network (which will be discussed in details below in this section). This process continues until the data accuracy for all services is satisfied, and finally we can obtain the selected nodes as well as the services provided by each node for the problem.
Assume that 
Let 
So far we have introduced the basic node selection process for the CSA. However, the algorithm can be further optimized. In case that the algorithm selects one node with maximum contribution increment, this node will provide each service that helps to improve the data accuracy. However, the node with multiservice and maximum contribution increment might have poor data accuracy increment for some services. Although the node that provides poor data accuracy increment can still improve the data accuracy, the data accuracy increment is so small that it needs to select more nodes to guarantee the required data accuracy. Therefore, we can further reduce the number of nodes by removing some already selected nodes that are with poor data accuracy increment for some services. Let us consider an example that two services are supported by two nodes, in which
The pseudocode for CSA is listed in Algorithm 2. In Line 1, the set of selected nodes
1: 2: 3: If for each service 4: Calculate data accuracy increment and 5: If no such a candidate is found, the algorithm stops with no solution found; 6: 7: 8: 9: Calculate 10: If no such a candidate is found, 11: 12: 13: 14: 15:
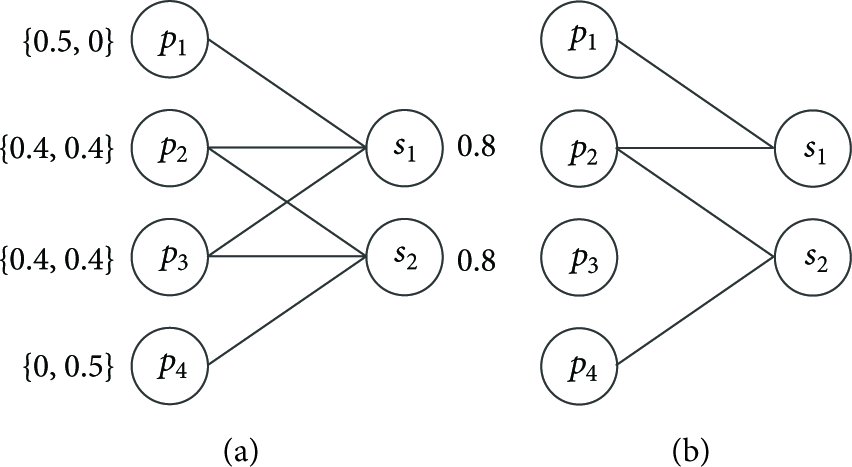
We illustrate the execution of CSA algorithm during one round of the iteration process by an example given in Figure 4. In this example two services are supported by four nodes. The node-service bipartite graph

An example of the execution of CSA algorithm during one round of the iteration process. (a) The node-service bipartite graph
5.3. Complexity Analysis
Lemma 1.
The time complexity of SSA is
Proof.
During the outside for loop, the algorithm selects nodes for each service
Lemma 2.
The time complexity of CSA is
Proof.
During the outside while loop, the algorithm will firstly check each node
6. Simulation Results and Analysis
In order to evaluate the actual behavior of the above algorithms, we have relied on the experimental simulation to show its performance. In this section, we have firstly introduced the building process of our simulation and then analyze the impact of spatial correlation parameters θ and SNR β on the results. Finally, we compare the performance of SSA and CSA in different environments.
6.1. Simulation Setup
We use MATLAB as the platform tool that is used popularly in simulation of wireless networks. The scenarios are built in a square area 500 m × 500 m. The sensor nodes are random placed as well as the sensing sources. Here we assume that each sensing source is dedicated to one special service. Given the sensor nodes and the sensing sources, in the next step we need to decide the set of services provided by these nodes. Here we adopt the randomly model to determine whether node
6.2. Impact of Spatial Correlation Parameters θ and SNR β
In this part, we analyze the impact of spatial correlation parameters θ and SNR β on the performance of the SSA and CSA. The spatial correlation parameters θ and SNR β are two parameters in the spatial correlation model, which we have introduced in Section 3.2. The spatial correlation parameter θ denotes the correlation of sensed data between the distances among sensor nodes. As we can see from formula (2), the larger θ indicates a high degree of spatial correlation; that is, the nodes in a network provide strongly correlated service. The SNR β denotes the noise strength that will affect the distortion of service. It is obvious that the larger β will result in low distorted sensed data; that is, the services provided by nodes are more accurate. As we can see, the two parameters θ and β will affect the sensed data, which in turn influences the selection results.
The first set of experiments is concerned with the impact of spatial correlation parameter θ on the number of selected nodes. The simulation is done with 300 nodes and 10 services, and the SNR β is assumed to be 10 dB and q be 0.5. The spatial correlation parameter θ varies from 500, 1000, and 2000 to 5000, and we study the average number of the selected nodes compared with the change of services' accuracy requirement

Impact of spatial correlation parameter θ,
The second set of experiments is concerned with the impact of signal-to-noise ratio β on the number of selected nodes, which is illustrated in Figure 6. The simulation is done with 300 nodes and 10 services, and spatial correlation parameter θ is assumed to be 2000 and q be 0.5. The SNR parameter β varies from 5 dB, 10 dB, and 15 dB to 20 dB, and we study the average number of selected nodes compared with the change of services' accuracy requirement

Impact of SNR β,
6.3. Performance Comparison between SSA and CSA
So far as we know, this is the first works concerned with the node selection algorithms with data accuracy guaranteed for the service-oriented wireless sensor networks. Most of the related works [28–31] focused on different research issues, such as target tracking, and topology control. Wang et al. [13] had proposed a scheduling algorithm for the service-oriented wireless sensor network, but it did not consider the data accuracy. In this section, we compare the performance of SSA and CSA in different scenarios with varied accuracy requirement, number of nodes n, number of service m, and the value of q, respectively.
Figure 7 has shown the number of selected nodes with SSA and CSA when the accuracy requirement

Comparison of SSA and CSA with different data accuracy requirements.
The second set of simulations is done to show the impact of network size on the number of selected nodes. The simulation is done with 300 nodes and 10 services, and spatial correlation parameter θ is assumed to be 2000, data accuracy requirement

Comparison of SSA and CSA with different network size.
The third set of simulations focuses on the impact of the number of services in the network on the number of selected nodes. We use the similar parameters in the second set of simulations. As we can see from Figure 9, CSA runs better than SSA with different value of m although it is not so significant when m is close to 5.

Comparison of SSA and CSA with different number of services.
The fourth set of simulations focuses on the probability q on the number of selected nodes by varying q from 0.1 to 0.9. We also use the similar parameters in the second set of simulations. In fact, the parameter q indirectly represents the number of services provided by nodes in the network. As we can see from Figure 10, the number of the selected nodes is rather close with SSA and CSA when q is small enough. Particularly, the SSA is even slightly better than CSA when
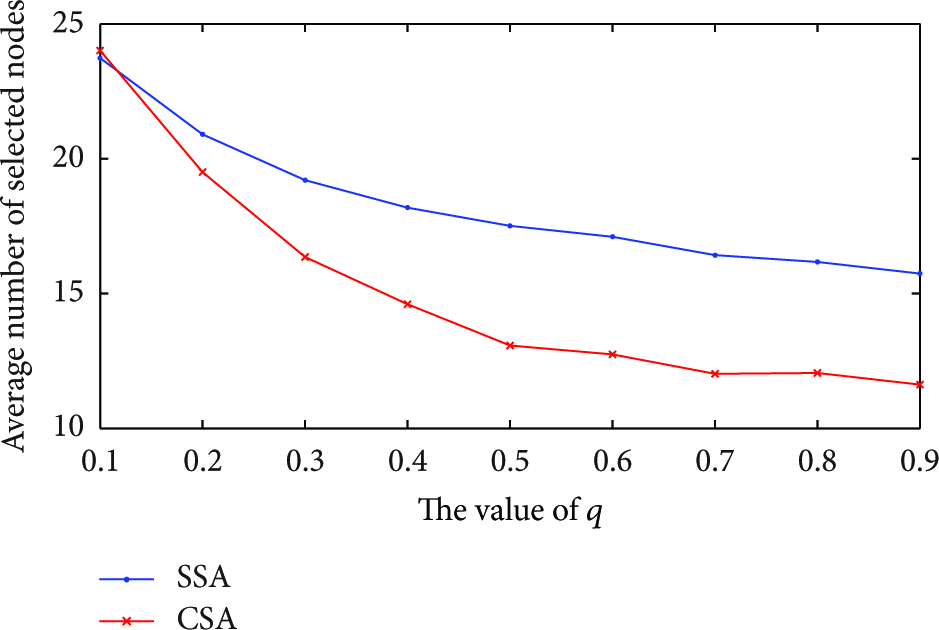
Comparison of SSA and CSA in different value of q.
7. Conclusion
To provide various services is one important trend for the future wireless sensor networks, and the service-oriented architecture allows different services supported simultaneously in the same physical area in which one sensor can provide different kinds of service. Quality of services, such as data accuracy, is one of the key criterions for applications because the sensed data is generally a noisy version of the physical phenomenon. The spatial correlation among the sensed data makes it possible to select a subset of nodes to provide the required services while the data accuracy is guaranteed, which is obviously helpful to improve the performance of the wireless sensor networks. We are concerned with this issue in this paper and have formulated the node selection problem into an Integer Nonlinear Programming (INLP) problem. We also have developed two heuristic algorithms, namely, Separate Selection Algorithm (SSA) and Combined Selection Algorithm (CSA) for the problem. In the future work we are to develop efficient scheduling schemes for the node selection process and aim at providing a solution for the service-oriented wireless sensor networks with the network lifetime maximized. The temporal correlation is also important to optimize the network performance. We also plan to explore energy-efficient scheduling schemes for service-oriented wireless sensor networks with both spatial and temporal correlation considered.
Footnotes
Acknowledgments
This work is supported by Fujian Provincial Natural Science Foundation of China under Grant no. 2011J01345, the Development Foundation of Educational Committee of Fujian Province under Grant no. 2012JA12027, the National Science Foundation of China under Grant no. 61103275, and the Technology Innovation Platform Project of Fujian Province under Grant no. 2009J1007.