
Abstract
Standard classification algorithms are often inaccurate when used in a wireless sensor network (WSN), where the observed data occur in imbalanced classes. The imbalanced data classification problem occurs when the number of samples in one class, usually the class of interest, is much lower than the number in the other classes. Many classification models have been studied in the data-mining research community. However, they all assume that the input data are stationary and bounded in size, so that resampling techniques and postadjustment by measuring the classification cost can be applied. In this paper, we devise a new scheme that extends a popular stream classification algorithm to the analysis of WSNs for reducing the adverse effects of the imbalanced class in the data. This new scheme is resource light at the algorithm level and does not require any data preprocessing. It uses weighted naïve Bayes predictors at the decision tree leaves to effectively reduce the impact of imbalanced classes. Experiments show that our modified algorithm outperforms the original stream classification algorithm.
1. Introduction
A wireless sensor network (WSN) is a distributed platform that collects data over a broad area. It has a wide variety of practical military, medical, and industrial applications [1]. The brain of a WSN is usually a decision-making algorithm that is capable of correctly mapping a set of newly collected observations from the sensors to one or more predefined categories. It uses a machine-learning algorithm to recall the classification of old data and classify the new data accordingly. There is no shortage of machine-learning algorithms available for decision making in WSNs [2, 3]. However, the imbalanced classification is a common problem. This problem occurs when the classifier algorithm is trained with a dataset in which one class has only a few samples and there are a disproportionally large number of samples in the other classes. This kind of imbalanced data causes classifiers to be overfitted (i.e., produce redundant rules that describe duplicate or meaningless concepts) and as a result perform poorly, particularly in the identification of the minority class. In WSN applications, these rare minority classes are often critical. Some WSN examples include, but are not limited to, transaction fraud detection, machine fault monitoring, environmental anomalies, atypical medical conditions, and abnormal habitual behaviors—situations where the class of interest is a small sample of unusual readings. Studies [4] have shown that using standard classification algorithms to analyze these imbalanced class distributions leads to poor performance. An imbalanced class problem may have another implication in WSN where it could be a symptom of producing traffic “hot-spot” in WSN. The energy consumption in the sensors may become imbalanced too, which leads to premature drainout for some local nodes. Some solution [5] has been proposed to better cluster the nodes and traffics although it is aimed at the energy level.
Most of the standard classification algorithms assume that training examples are evenly distributed among different classes. In practical applications where this was known to be untrue, researchers addressed the problem by either manipulating the training data or adjusting the misclassification costs. Resizing the training datasets is a common strategy that attempts to downsize the majority class and oversamples the minority class. Many variants of this strategy have been proposed [6–8]. A second strategy is to adjust the costs of misclassification errors to be biased against or in favor of the majority and minority classes, respectively. Using the feedback from the altered error information, researchers then [9, 10] fine-tune their cost-sensitive classifiers and postprune the decision trees in the hope of establishing a balanced treatment of each class in the new imbalanced data collected by the network.
The authors of this paper argue that replacing the traditional classifier with an optimized stream classifier is another effective solution. As mentioned above, the current techniques for dealing with imbalanced data require additional data preprocessing or feedback learning and pruning of a trained decision tree. Though they may be useful in minimizing the impact of imbalanced data, these pre- and postprocessing mechanisms require working through a whole database and their operations incur certain overheads in the data-mining environment, which may not be favorable in a WSN. In a wireless sensor network, data mining is done in real time with a compact device with limited memory and processing power called a sink, and most importantly the incoming data for classification training and testing are streaming in nature. These data streams are nonstationary data that may only be read one time at the intermediate nodes of a sensor network and are then forgotten. Furthermore, these nodes may be required to perform real-time classification as the data flows along the WSN. Fast prediction results with satisfactory accuracy must be propagated from node to node. In this dynamic environment, techniques based on data storage and feedback style after learning cannot be used to correct imbalanced data. On the other hand, it has been demonstrated that a stream classifier is a good candidate for WSN applications [11].
The contribution of this paper is a set of simple modifications that optimize an existing stream classification algorithm called Very Fast Decision Tree to handle the imbalanced class problem at the algorithmic level. One important extension is the use of weighted naïve Bayes predictors installed at the decision tree leaves. The assigned weights have the effect of countering the “biases” that are introduced by the problems of imbalanced class found in imperfect WSN data. The paper is organized as follows. Section 2 describes in detail the modifications that tackle the imbalanced class problem. In Section 3 a range of experiments is described, the “biased” datasets with imbalanced classes are introduced and the experimental results are discussed. Section 4 concludes the paper.
2. Optimizing the Very Fast Decision Tree
2.1. Motivation and Overview
Three special modifications are proposed to enhance the Very Fast Decision Tree (VFDT) algorithm. These modifications are embedded in line with the codes that implement the classification logic of the stream classifier. The modifications to reduce the imbalanced class problem are made in four phases: the training phase, where new nodes are created if the statistical criteria established in the learning from the labeled samples phase are met; the prepruning phase, in which the qualified nodes and branches are tested to see whether they can indeed improve the prediction accuracy (before they are added to the decision tree); the prediction phase where unseen samples are being categorized to predefined classes; and the pruning phase which uses the functional tree leaf [12]. The modifications are in the forms of simple computation and conditional checks that do not incur heavy resource consumption at the sensor nodes.
The improved version of VFDT is generally called the Optimized Very Fast Decision Tree with Functional Leaves (OVFDT-FL). Our previous work [13] shows that the OVFDT-FL prototype can classify data streams with the maximum possible accuracy with the minimum tree size. In this paper, OVFDT-FL is tested with imbalanced class data. The design of OVFDT-FL is given as follows.
OVFDT, which is based on the original VFDT design, is implemented using a test-then-train approach for classifying a continuously arriving data stream, even
S: A stream of sample X: A set of symbolic attributes G(·): Heuristic function using for node-splitting estimation δ: One minus the desired probability of choosing a correct attribute at any given node ℱ: A functional tree leaf strategy
HT: A decision tree (1) Let HT be a tree with a single leaf l (the root). Let (2) Let (3) FOR each class (4) // (5) FOR each value (6) Reset OCD: (7) // (8) END-FOR (9) END-FOR (10) Return HT with a single root

A test-then-train OVFDT workflow.
The training phase immediately follows the testing phase. Node-splitting estimation is used to initially decide if HT should be updated or not, depending on the number of samples received that can potentially be represented by additional underlying rules in the decision tree. In principle, the node-splitting estimation should apply to every single new sample that arrives. However, this would be too resource expensive and would slow down the tree building process. Instead, VFDT proposes a parameter
Two modifications are proposed for the training phase of OVFDT to manage imbalanced data classes. The first is to dynamically adjust the tie-breaking function in the splitting-node determination using the mean value of Hoeffding's bound. The growth of the tree is influenced by the mean value of the traffic fluctuation (which was found to correlate with Hoeffding's bound in our previous work) rather than the imbalanced data class. The second modification is to use prepruning to test if the leaf chosen to be split, and therefore increase tree growth, is indeed a valid choice given the imbalanced data class. In this way, we can assume that the expansion of the tree is a result of genuinely accurate predictions. Thus, postpruning on the decision tree is not necessary. Section 2.2 presents the details of the functional leaf strategy for handling the imbalanced data class, and the details of the modifications to the training phase are given in Section 2.3.
2.2. Functional Tree Leaf Prediction in Testing Phase
The sufficient statistics
For the actual classification, OVFDT uses
2.2.1. Majority Class Functional Tree Leaf
In the ODC vector, the majority class functional tree Leaf
2.2.2. Naïve Bayes Functional Tree Leaf
In the OCD vector
2.2.3. Weighted Naïve Bayes Functional Tree Leaf
In the OCD vector
2.2.4. Adaptive Functional Tree Leaf
In a leaf, suppose that
According to the functional tree leaf strategy, the current HT sorts a newly arrived sample (
(1) Sort S from the root to a leaf by HT. Update OCD in each node: (2) Switch (ℱ) (3) Case (4) Case (5) Case (6) Case (7) IF (8) ELSE (9) (10) Return
2.3. Dynamic Splitting Test and Prepruning in the Training Phase
The node-splitting control is modified to use a dynamic tie-breaking threshold τ, which restricts the attribute splitting at a decision node. The τ parameter traditionally is preconfigured with a default value defined by the user. The optimal value is usually not known until all of the possibilities in an experiment have been tried. Longitudinal testing of different values in advance is certainly not favorable in real-time applications. Instead, we assign a dynamic tie threshold, equal to the dynamic mean of the HB value at each pass of stream data, as the splitting threshold, which controls the node splitting during the tree-building process. Tie breaking that occurs close to the HB mean can effectively narrow the variance distribution. The HB mean is calculated dynamically whenever new data arrives and the HB value is updated.
The estimation of splits and ties is only executed once for every


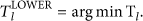
For resource-light operations, we propose an error-based prepruning mechanism for the OVFDT, which stops noninformative node splitting before it splits into a new node. The prepruning takes into account both global and local node-splitting errors.
Lemma 1 (Monitoring Global Accuracy).
The model's accuracy varies whenever a node splits and the tree structure is updated. Overall accuracy of a current tree model is monitored during node splitting by comparing the number of correctly and incorrectly predicted samples. The numbers of correctly predicted instances and otherwise are recorded as current global performance indicators. This monitoring allows the determination of global accuracy.
When a new instance arrives, it will be sorted to a leaf by the current HT structure before the node-splitting estimation. This is the “testing” phase in OVFDT. Suppose that
Lemma 2 (Monitor Local Accuracy).
The global accuracy can be tracked by comparing the number of correctly predicted samples with the number of incorrectly predicted samples. Likewise, comparing the global accuracy as measured at the current node-splitting estimation with the global accuracy measured at the previous splitting, means that the variation in accuracy is being tracked dynamically. This monitoring allows us to check whether the current node splitting is advantageous at each step by comparing it with the previous step.
Suppose that GainAccu is the gain in accuracy of the ith and the
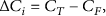

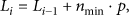


Figure 2 shows why our proposed prepruning takes into account both the local and the global accuracy in the incremental pruning. At the ith node-splitting estimation, the difference between correctly and incorrectly predicted classes was

Example of incremental pruning.
The optimal node splitting control consists of a dynamic tie for node splitting and a prepruning mechanism that tries to hold the tree growth in neutral with respect to the imbalanced class distribution. In each node-splitting estimation process, the Hoeffding bound (HB) value that relates to leaf l is recorded. The recorded HB values are used to compute the adaptive tie, which uses the mean of the values for each leaf l instead of a fixed user-defined value as in VFDT. Using all the prediction statistics gathered in the testing phase for implementing prepruning, Pseudocode 3 presents the pseudocode of the training phase used by OVFDT for building an upright tree.
(1) FOR each attribute (2) Compute (3) Let (4) Compute HB with δ (5) Let (6) END-FOR (7) IF ( (8) Replace l by an internal node splits on (9) Update Adaptive tie (10) FOR each branch of splitting (11) Add a new leaf (12) Let (13) FOR each class (14) (15) END-FOR (16) END-FOR (17) END-IF (18) Return updated HT
3. Experiments
3.1. Bias Generator
For our experiments, we adopted and customized massive online analysis (MOA), one of the most popular data stream-mining toolkits, by including the aforementioned modifications into the OVFDT algorithm. However, the latest version of the MOA simulation environment is not able to simulate a biased data stream with an imbalanced class. A bias generator was therefore written in JAVA code and integrated into MOA for the purpose of evaluating the performance of stream-mining algorithms under imbalanced class data. Using either a simple command-line console or a graphic user, of which an example is shown in Figure 3, the generator injected biased instances from a specific imbalanced class into a given ARFF file. The input parameters are as follows:
biased class index (BCI): the class index that the bias-added instances belong to, bias change from class index (CCI): the class index that the bias instances will replace, change reduction percentage (CP): the proportion of instances that will change to biased instances.
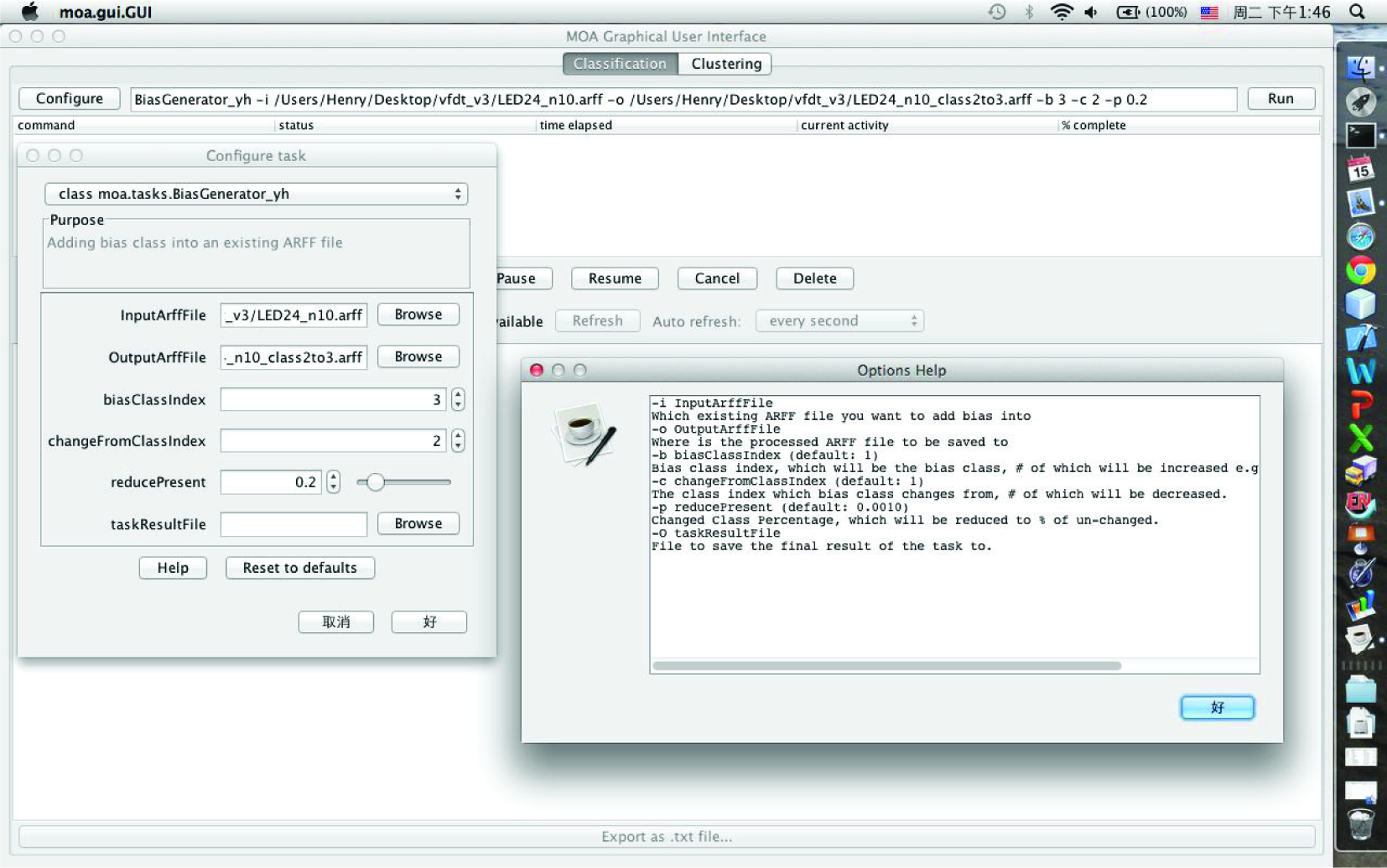
Snapshot of the Bias generator for generating data with imbalanced class, on MOA platform.
After the generator configuration, the instances with CCI class are replaced by BCI instances according to the CP setting. For example, in the snapshot below
3.2. Experiment Datasets and Visualization
Six datasets were used to test the performance of OVFDT + FL versus ordinary VFDT. The datasets included those generated by the biased simulator and naturally imbalanced real-life data downloaded from the UCI machine-learning archive (http://www.ics.uci.edu/~mlearn). Table 1 describes these experimental datasets in detail, and Figure 4 provides a group of class distribution visualizations.
Datasets with imbalanced class used in the experiment.


A collection of visualizations of the datasets that have different degrees of imbalanced class distribution.
The following charts visualize the bias-included datasets with the imbalanced class. The pie charts on the left show the class distribution in the full experimental datasets and the charts on the right show the class distribution being progressively updated as new data streams arrive. For example, from Table 1 we see that the biased classes in the LED24 dataset are Class 2 (18%) and Class 4 (18%). There are 80% more data samples for these two classes than for the other classes. Originally the data distributions over all classes were equal. The charts representing the other datasets show at least one class, which has a larger percentage of data distribution than others.
3.3. Experiment Results Comparing VFDT and OVFDT
VFDT is deemed to be a suitable candidate for real-time classification in wireless sensor networks, because of its incremental learning nature based on a test-and-train approach. In this paper, we extend the design of VFDT to OVFDT, which has superior mechanisms for dealing with imbalanced data classes. This following comparison is between VFDT and OVFDT, which use the same types of functional tree leaf in the imbalanced datasets. The goal is to observe the comparative impact of the imbalanced classes on VFDT and OVFDT. For VFDT, the fixed tie breaking threshold (range from 0 to 1) is an important predefined parameter τ, which controls the node-splitting speed. In the experiment, τ was set at different values from 0.1 to 1.0 to test several different trails of VFDT, as a priori information for τ values is unavailable until the model is actually put to the test. The number of correctly classified instances measures the accuracy over the total number of arrived instances.
The results show, on the one hand, that OVFDTAdaptive has better performance results than any other method, for imbalanced data streams. The highlighted areas in Figure 5 show that OVFDT consistently outperformed VFDT. OVFDTMC had lower accuracy than other functional tree leaf strategies in OVFDT. The advantage of the functional tree leaf approach is more apparent in the analysis of imbalanced data streams that have a significantly large bias in class distribution. This means that the modification at the testing phase is substantially effective, even when processing highly imbalanced data classes. On the other hand, the advantage of the other two modifications to the training phase, prepruning and dynamic node splitting, shows their usefulness in reducing the overfitting problem caused by imbalanced class data streams.
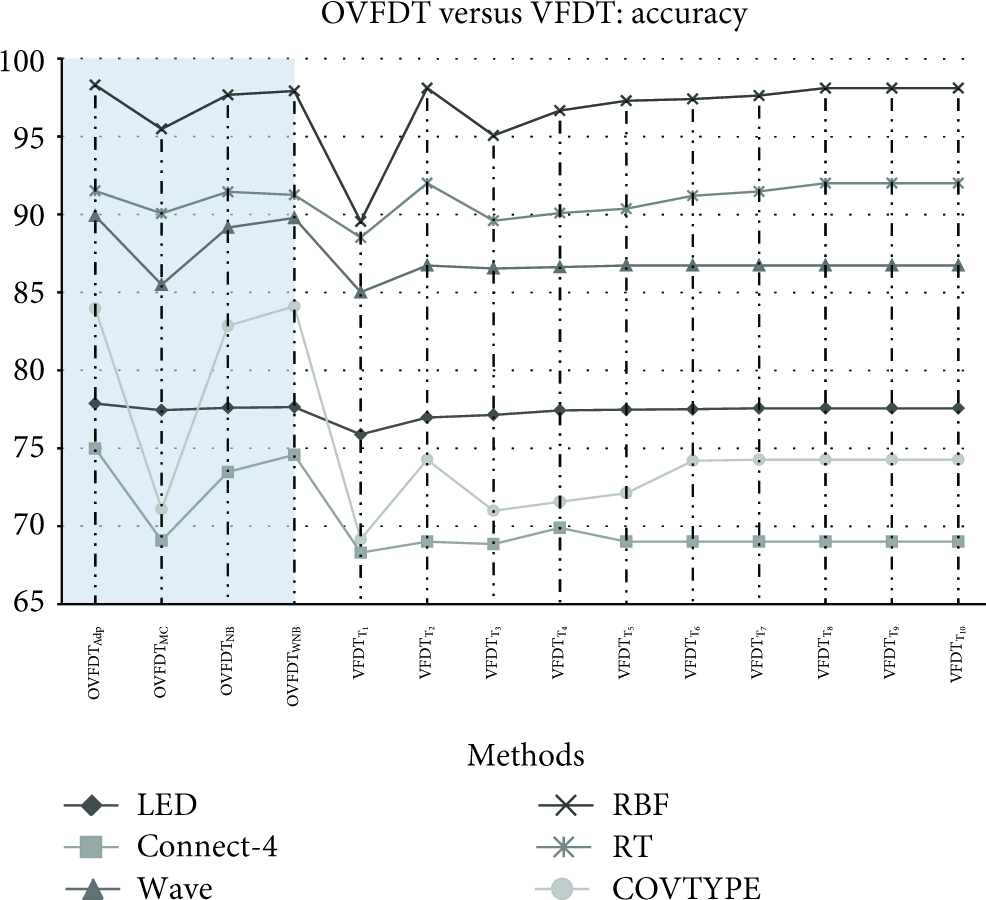
Accuracy of the classification experiments by VFDT and OVFDT with datasets of imbalanced data class.
The radar chart in Figure 6 demonstrates that OVFDT results in a much smaller tree size than VFDT in all cases. A small tree size means lower runtime memory requirements, which makes it suitable for operating sensor node devices in WSNs. Tree size is measured by the number of leaves in a decision tree. Ideally there should be just enough leaves and corresponding branch paths to correctly classify the samples. Having too many leaves is a symptom of overfitting, which results in a decision tree that cannot make meaningful predictions and uses up memory space.

Tree size of the classification experiments by VFDT and OVFDT with datasets of imbalanced data class.
As these experimental results show, OVFDT with a functional tree leaf handles imbalanced data streams more effectively than VFDT. For this reason, VFDT will not be considered in the following experiments. Instead, we will analyze in detail the experimental results of OVFDT using different types of functional tree leaves.
3.4. Experiment Results Comparing OVFDT Functional Tree Leaf Accuracy
Comparing the classification accuracy of four different types of functional tree leaves, we find that OVFDTMC always obtains the lowest accuracy and OVFDTAdaptive has consistently better accuracy than the other methods. In addition, OVFDTWNB is better than OVFDTNB in experiments that weight the probabilities of each attribute occurrence (see Figure 8).
Another good performance benchmark is the receiver operating characteristic (ROC), which is a standard method for analyzing and comparing classifiers when the costs of misclassification are unknown. In a stream-mining scenario, it is not possible to know the misclassification costs, because the mining process is incremental over running data streams, and does not analyze a full dataset. The ROC provides a convenient graphical display of the tradeoff between the true and false positive classification rates for two class problems [11]. In the decision tree classification, however, there are more than two classes. Therefore, we extend the standard ROC model to a multiclass ROC analysis to evaluate the tree learning algorithm's performance.
Suppose that there is a D -class classification system, with d-dimensional classes that need to be classified by the tree learning algorithm. A 
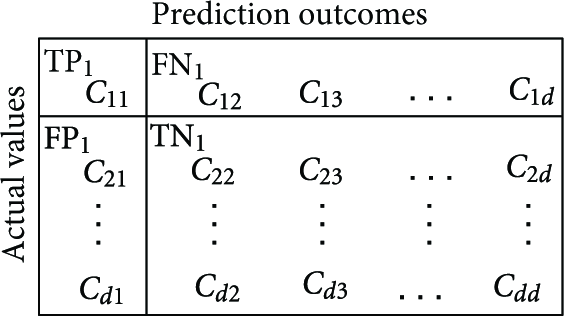
To use two-class ROC statistics, each class i to d in the multi-class ROC is assigned a negative or positive value. Samples with class i are positive; otherwise, negative. True positives (TP) are examples correctly labeled as positives. False positives (FP) refer to negative examples incorrectly labeled as positive. True negatives (TN) are negatives correctly labeled as negative. Finally, false negatives (FN) refer to positive examples incorrectly labeled as negative. Each class i can be converted into a two-class problem, with the corresponding values of True Positive (10), False Positive (11), False Negative (12), and True Negative (13) (see Figure 7):


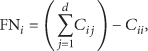


Tree size of the classification experiments by different FL types of OVFDT with datasets of imbalanced data class.
Precision-Recall is a well-known method of analyzing ROC. In pattern recognition, precision is the fraction of retrieved instances that are relevant, while recall is the fraction of relevant instances that are retrieved. The values of precision and recall range from 0 to 1. A precision score of 1 for a class i means that every item labeled as belonging to class i does indeed belong to class i. A recall score of 1 means that every item from class i was labeled as belonging to class i. Precision-Recall scores are not analyzed in isolation. F
β
-measure [12] is a weighted harmonic mean of the Precision-Recall measure. The F1-measure evenly weights precision and recall scores. The best value for the F1-measure is 1 and the worst score is 0. In addition, the true positive rate (TPR) and the false positive rate (FPR) are common benchmarks in ROC analysis:

We analyze the Precision-Recall for each class for all the imbalanced class datasets. Due to limited space, the detailed charts are given in the Appendix. The average Precision-Recall values are described in Figures 9, and 10.

Precision and Recall values of the classification experiments by different FL types of OVFDT with datasets of imbalanced data class.

F1-measure of the classification experiments by different FL types of OVFDT with datasets of imbalanced data class.
These charts illustrate that the average precision of OVFDTMC is worse than those of the other methods. OVFDTAdaptive obtains the highest precision in homogenous (nominal only and numeric only) datasets. All methods have the same average values of recall (the lines appear to overlap). We then apply the F1-measure to evaluate the experiment result. As the chart below shows, the value ranges from 0 to 1; OVFDTMC again has the lowest F1-measure value. However, because the datasets contained biased instances in imbalance classes, the average Precision-Recall analysis is not sufficient to determine accuracy. We must consider the Precision-Recall for the distributed class in every different data stream. From the above experiments, we observe that OVFDTAdaptive always achieves higher precision, recall, and F1-measure values than OVFDTMC, but this was not the case for OVFDTNB and OVFDTWNB.
4. Conclusion
Imbalanced data classification is a challenging problem that generally refers to a learning model created for a dataset that has far more samples in one class than in the others. In an ubiquitous environment such as a wireless sensor network, it is not uncommon for the data of interest to fall into a small minority class. Previous researchers have tackled this problem by using techniques that inevitably create additional computation overheads. These techniques usually include resampling the observations from a bounded archive so as to balance the imbalance. Others may resort to postpruning the decision tree and redistributing the classification costs in a backward-learning process. All of these proposed techniques worked well in traditional data mining but might not suit a real-time stream-mining scenario, where all the data arrive in a single pass; at a sensor sink it is neither practical nor feasible to archive a stationary set of data, let alone to resample.
In this paper, a novel solution is introduced at the algorithmic level, which is based on a popular stream-mining algorithm called the Very Fast Decision Tree (VFDT). Three modifications are proposed for VFDT as a means to reduce the effect of imbalanced class data. The modifications are implemented at the training phase prior to expanding the decision tree and at the testing phase, where prediction accuracy is fine-tuned by weighting the leaves of the decision trees according to the probabilities of the arriving data. The overall solution is called the Optimized VFDT with Functional Tree Leaf (OVFDT + FL). The mechanism of Function Tree Leaf is implemented by using weighted naïve Bayes predictors, installed at the decision tree leaves of the OVFDT. Specifically, perturbed datasets that include “biased” class distribution are used for experiments for illustrating the efficacy of the new algorithm. OVFDT + FL is shown to outperform VFDT in a series of experiments where datasets are deliberately biased by a custom-made data generator software program. In particular, two variants of FL called adaptive and weighted naïve Bayes performed consistently better than other techniques. OVFDT succeeded in minimizing the impacts of imbalanced class data, while maintaining high accuracy and a compact decision tree size. This contrasts with the known over-fitting problems of poor accuracy and huge tree size usually caused by imbalanced class data. The OVFDT + FL is validated as a good classification model for wireless sensor networks.
Footnotes
Appendix
Acknowledgments
The authors are thankful for the financial support from the research Grant “Real-time Data Stream Mining,” Grant no. RG070/09-10S/FCC/FST, offered by the University of Macau, FST, and RDAO.