
Abstract
An ultrasonic sensor-based personalized multichannel audio rendering method is proposed for multiview broadcasting services. Multiview broadcasting, a representative next-generation broadcasting technique, renders video image sequences captured by several stereoscopic cameras from different viewpoints. To achieve realistic multiview broadcasting, multichannel audio that is synchronized with a user's viewpoint should be rendered in real time. For this reason, both a real-time person-tracking technique for estimating the user's position and a multichannel audio rendering technique for virtual sound localization are necessary in order to provide realistic audio. Therefore, the proposed method is composed of two parts: a person-tracking method using ultrasonic sensors and a multichannel audio rendering method using MPEG Surround parameters. In order to evaluate the perceptual quality and localization performance of the proposed method, a MUSHRA listening test is conducted, and the directivity patterns are investigated. It is shown from these experiments that the proposed method provides better perceptual quality and localization performance than a conventional multichannel audio rendering method that also uses MPEG Surround parameters.
1. Introduction
Recently, a wide range of multimedia technologies for accessing multimedia content through digital TVs (DTVs), personal media players (PMPs), and digital cameras is rapidly being developed. This development is particularly evident in the field related to broadcasting services, which has made progress toward more realistic and immersive broadcasting services [1–5]. To this end, a representative next-generation broadcasting service that supports realistic and immersive multimedia is currently entering the spotlight in the form of 3-dimensional television (3DTV) technologies [5–7].
3DTV is a technology that is being used to provide realistic and stereoscopic video content to users and can be further classified into either stereoscopic or multiview methods. Stereoscopic 3DTV is currently being produced and sold on the market and has become an essential component for watching 3D movies at home. As an alternative to glassless 3DTV, however, multiview-based 3DTV is emerging as an attractive option, since it not only delivers more realistic visual content to users, but it also has a wider viewing range. Thus, there is a great deal of ongoing research associated with multiview TVs in attempts to miniaturize the screen size and reduce the price [7].
Multiview broadcasting renders the video sequences captured by a set of cameras from different viewpoints. By rendering these video sequences on a multiview monitor or a multiview TV, users can experience 3D effects from different viewpoints without requiring 3D glasses [7]. Under a multiview broadcasting framework, however, the transmitted multichannel audio signal must also be realistically rendered at different viewpoints in order to increase both the visual and auditory realism. To realize such an audio service, two sequential processes are necessary: (1) tracking the user's viewpoint and (2) rendering the multichannel audio specifically at the user's position.
Thus, this paper proposes a person-tracking-based multichannel audio rendering method for multiview broadcasting services, in which person tracking is performed using ultrasonic sensors, and multichannel audio rendering is performed using MPEG Surround parameters.
The remainder of this paper is organized as follows. Following this introduction, Section 2 briefly explains a multiview broadcasting system. Next, Section 3 proposes an ultrasonic-based person-tracking method for a personalized audio service. After that, Section 4 describes a conventional parameter-based audio rendering method and then proposes a new rendering method using MPEG Surround parameters on the basis of the constant power panning law. Section 5 then evaluates the performance of the proposed method in terms of perceptual audio quality and audio localization. Finally, this paper is concluded in Section 6.
2. Multiview Broadcasting System
Figure 1 presents a schematic diagram of a multiview and multichannel audio broadcasting system. As shown in this figure, the broadcasting system is composed of two parts: the first part acquires and transmits multiview images and multichannel audio contents, and the second part renders and plays the resultant multiview images and multichannel audio. In the first part, multiview videos consist of video sequences that are simultaneously captured by a set of cameras placed according to different viewpoints, which can be then encoded using a video encoder such as H.264. On the other hand, multichannel audio contents are recorded using multiple microphones or a microphone array, which are then encoded using an audio codec such as MPEG-2 advanced audio coding (AAC). Next, both video and audio contents are transmitted to a multiview receiver via a broadcasting network. In the second part, the transmitted multiview video contents are processed and rendered to generate 3D contents that are adjusted to the particular viewpoint of each user. Similarly, multichannel audio is rendered for each viewpoint and played through 5.1 multichannel loudspeakers or stereo headphones.

Schematic diagram of a multiview and multichannel audio broadcasting system.
3. Ultrasonic Sensor-Based Person Tracking
In this section, we describe how the viewpoint of a user can be estimated in order to deliver audio effects appropriate to a particular viewpoint, as mentioned in Sections 1 and 2. Recently, a number of methods pertaining to person tracking have been reported [8–12], which are commonly classified into two categories: vision-based tracking and active sensor-based tracking. The former tracks a person's eyes or face [8–12], and the latter tracks a person's position using sensors such as an active badge, a radio frequency identification (RFID) device [11], or other sensors [12, 13]. It should be noted that vision-based tracking methods have a disadvantage in terms of processing time, since they are based on image-processing techniques. However, active sensor-based tracking methods can be implemented with less processing time than vision-based tracking methods but require sensors for estimating the viewpoint of each user. However, it has been shown that tracking methods utilizing ultrasonic devices can provide a comparatively high accuracy and are relatively inexpensive compared to RFID tags or other active badge devices [14, 15]. Consequently, in this paper, a person-tracking system using ultrasonic devices is constructed, which consists of two ultrasonic transducers and an ultrasonic receiver for person tracking.
Figure 2 presents the block diagram of a person-tracking system for estimating the user's viewpoint, where an ultrasonic receiver attached to the user's headphones or clothes receives an ultrasonic signal from two ultrasonic transducers. The distance between the ultrasonic receiver and each transducer is estimated and then delivered to a person-tracking server over Bluetooth. Finally, the server estimates the viewpoint using a triangulation technique.

Block diagram of an ultrasonic sensor-based person-tracking system.
Figure 3 shows how to calculate the view position or coordinate of the user by using the two ultrasonic sensors. The detailed procedure for person tracking is as follows. First, the relative distance between the ith ultrasonic sensor and the receiver,

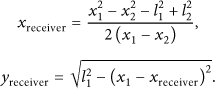
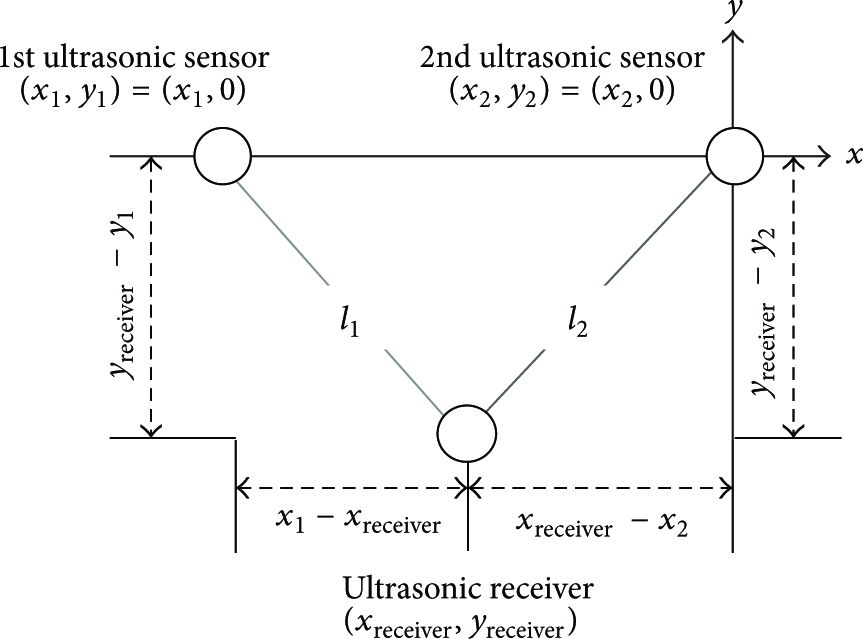
Calculation of the coordinates of a user's view position using two ultrasonic sensors and an ultrasonic receiver.
4. Parameter-Based Audio Rendering
Figure 4 presents the block diagram for the proposed parameter-based audio rendering method which is based on the constant power panning law using MPEG Surround parameters [16, 17]. In this figure, panning gains in the proposed method are first calculated according to the user's viewpoint, and N different channel level difference (CLD) parameters are extracted from the audio bitstream after applying a CLD parser. Next, the CLD parameters are transformed into absolute gain values, that is, six channel power gains for the 5.1 audio channels. The relationship between the scale factors for the CLD parameters and channel power gains are given by [16, 18]

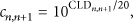

Block diagram of the proposed audio rendering method using MPEG Surround parameters.
Next, the channel power gains are modified depending on the panning gains calculated from a particular viewpoint, and the modified channel power gains are finally converted back into CLD parameters to create a modified bitstream for the MPEG Surround decoder.
There have been several approaches proposed for audio panning in the MPEG Surround parameter domain [19–23]. For example, the constant power panning law was directly applied to the channel power gains according to the desired panning angle [20, 21]. However, in such a direct application, the panned sound image was incorrectly localized or disappeared when the desired panning angle was larger than the aperture angle among the speaker pairs. The source of this problem was due to the fact that audio rendering coverage was limited to the aperture angles between two speakers and each transformed channel power gain was only related to two adjacent channels.
To remedy this problem, the proposed method applies the constant power panning law to the channel power gains according to the minimum aperture angle, instead of the desired panning angle. This change is especially effective when the desired panning angle is larger than any other aperture angle among the speaker pairs. In this section, a conventional channel power gain modification method in [20, 21] is reviewed, and then the proposed method is described in detail.
4.1. Conventional Channel Power Gain Modification
To track the user's viewpoint as stated in Section 3, the angles to be panned are computed and denoted as

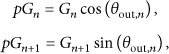
Schematic diagram of the relationship between the panning and aperture angles in a 5.1-channel speaker configuration, where C, L, R,
However, the conventional audio panning method described previously has some drawbacks. First, due to the sine-law amplitude panning method [24], possible panning angles in the conventional method are limited by the aperture angle of each pair of loudspeakers. Second, the conventional method does not consider the interchannel coherence (ICC) parameters for panning, though the ICC parameters play an important role in providing the spatial diffuseness of audio quality as well as localization performance at low frequencies [20].
4.2. Proposed Channel Power Gain Modification
In this section, a new audio panning method is proposed to overcome the drawbacks of the conventional method. Figure 6 shows the procedure for the proposed channel power gain modification method. In this figure, each panning angle calculated from the user's viewpoint,

Procedure of the proposed parameter-based audio panning method applied to 5.1-channel audio.
Next, similar to (5), the proportion of



Finally, panned CLDs are obtained from both the conventional and proposed modification methods and are reestimated from the panning gains using the following equations:

Structure of MPEG Surround decoding tree.
5. Performance Evaluation
To evaluate the performance of the proposed audio panning method, the perceptual quality and localization performance were compared to those obtained using the conventional method. During these experiments, a multiple stimulus with hidden reference and anchor (MUSHRA) test [25] was conducted in order to evaluate the perceptual quality, and a directivity pattern analysis was used to evaluate the localization performance.
5.1. Perceptual Quality
For the MUSHRA listening test, we used the following as references and candidates: (1) a hidden reference, (2) a 7 kHz low-pass filtered anchor, (3) a 14 kHz low-pass filtered anchor, (4) audio signals processed by conventional CLD-based audio panning [20, 21], and (5) audio signals processed by the proposed CLD-based audio panning. Three music genres (classical, rock, and heavy metal) were selected as audio signals, and ten people with no hearing problems participated in these experiments.
Figure 8 illustrates the experimental results of the MUSHRA test. When the panning angle was smaller than the minimum aperture angle, for example, at a 30° panning angle, the proposed method had audio quality comparable to the conventional method, except for classical music signals. The reason why the MUSHRA score for classical music signals processed by the conventional CLD-based panning method was slightly higher than that by the proposed CLD-based panning method was that classical music signals were less dynamic than those from other genres such as rock and heavy metal. In other words, while the conventional method computed panning gains once every pair of channels by applying (6), the proposed method computed each panning gain by taking into account more than two channels as shown in (10). Thus, it resulted in perceptual degradation in classical music signals. In spite of such an artifact, it was found that the spatial impression for panned audio processed by the proposed method was more stable than that by the conventional method.

MUSHRA test results at panning angles of (a) 30° and (b) 60°.
On the other hand, when the panning angle was larger than the minimum aperture angle, for example, at a 60° panning angle with a 30° minimum aperture, the audio quality of the panned audio processed by the conventional method notably degraded. Even if the proposed method had smaller MUSHRA score for classical music signals than the conventional method, it was also found that the participants heard unnatural artificial noise due to incorrect panning when the panning angle was larger than the minimum aperture.
5.2. Localization Performance
To evaluate the localization performance, panned audio with only one channel signal was played, and the frequency response was measured using a dummy head. The directivity patterns for panning angles of 0°, 30°, and 60° were then analyzed. The amplitudes of the frequency responses at 500 Hz were measured by rotating the dummy head about 10°. For this experiment, a KU100 dummy head [26] was used.
Figure 9 shows the directivity patterns of the panned signals for 30° and 60° at 500 Hz. To estimate the position of the sound image localization, it was assumed that the sound image was localized at the position exhibiting maximum power. As illustrated in this figure, the measured power became maximal at a rotated position of about 90°, which corresponds to a forward-facing direction when no audio panning was applied. Similarly, the measured power became maximal at a rotated position of about 120°, relative to the panned direction, when an audio panning of 30° was applied. It can also be seen that the directivity pattern of the conventional method is correctly presented for a panning angle of 30°. However, when the panned angle was increased to 60°, the polar pattern of the conventional method was not correctly presented, whereas the directivity pattern obtained by the proposed CLD-based panning method shows that the audio signal rotated in the correct direction, although there were localization errors at around 5°–10°.

Comparison of directivity patterns for the proposed panning method at panning angles of 0°, 30°, and 60°.
6. Conclusion
In this paper, an ultrasonic sensor-based personalized multichannel audio rendering method was proposed to increase audio realism in multiview broadcasting services. To this end, a real-time person-tracking method was first developed by using two ultrasonic transducers and an ultrasonic receiver in order to estimate the viewpoint of a user. Secondly, a parameter-based audio panning method using MPEG Surround parameters was proposed to increase the auditory realism. In the proposed method, panning gains were calculated according to the user's viewpoint that was already estimated by the ultrasonic-based person-tracking method. Next, five different channel level difference (CLD) parameters were extracted from the audio bitstream after applying a CLD parser. Finally, the CLD parameters were transformed into six channel power gains for the 5.1 audio channels. In fact, the proposed method applied the constant power panning law to the channel power gains according to the minimum aperture angle, instead of the desired panning angle that was used for a conventional panning method. Thus, the proposed method could be more effective than the conventional method when the desired panning angle was larger than any other aperture angle among the speaker pairs. In order to evaluate the performance of the proposed audio panning method, the perceptual quality and localization performance using an MUSHRA test and a directivity pattern analysis, respectively, were carried out. Consequently, it was shown from the tests that the proposed audio panning method achieved better average MUSHRA score and localization performance than the conventional audio panning method.
Footnotes
Acknowledgment
This work was supported in part by the National Research Foundation of Korea (NRF) Grant funded by the Korea government (MEST) (no. 2012-010636).