
Abstract
Wireless sensor networks offer a distributed processing environment. Many sensor nodes are deployed in fields that have limited resources such as computing power, network bandwidth, and electric power. The sensor nodes construct their own networks automatically, and the collected data are sent to the sink node. In these traditional wireless sensor networks, network congestion due to packet flooding through the networks shortens the network life time. Clustering or in-network technologies help reduce packet flooding in the networks. Many studies have focused on saving energy in the sensor nodes because the limited available power leads to an important problem of extending the operation of sensor networks as long as possible. However, we focus on the execution time because clustering and local distributed processing already contribute to saving energy by local decision making. In this paper, we present a cooperative processing model based on the processing timeline. Our processing model includes validation of the processing, prediction of the total execution time, and determination of the optimal number of processing nodes for distributed processing in wireless sensor networks. The experiments demonstrate the accuracy of the proposed model, and a case study shows that our model can be used for the distributed application.
1. Introduction
Wireless sensor networks are generally composed of sensor nodes capable of detecting, processing, and transmitting. Sensor nodes collect environmental data, such as temperature, humidity, sound, vibration, or magnetic field strength, and send information that is processed from the collected data to the sink or base station. The data collected from the sensors are converted to digital data via analog-to-digital converters, and the sensor node identifies surrounding information, for example, object location or environmental event. The environmental information is used for forecasting certain events, monitoring disasters such as earthquakes and forest fires, or military purposes.
The traditional wireless sensor networks have been designed such that an external computing system makes decisions with data from the base station. The network lifetime in this type of architecture decreases because of relaying packets on the network and shrinks dramatically around the base station. Over the past decades, various methods to solve this problem have been studied based on distributing and sharing process resources. Distributed in-network processing can increase network lifetime and decrease the response time for events [1, 2].
The various wireless sensor network applications, such as tracking objects, detecting intruders, and monitoring structural health, generate many data packets on networks. Distributed processing or in-network processing reduces the number of packets to the base station by extracting information from measured raw data. More energy is required for transmitting and receiving data via radio frequency than for sensing and processing. Reducing packets into the network contributes to increasing network lifetime because it removes packet duplication caused by relaying packets to the base station [3].
Wireless sensor networks have different features from existing computing environments. A sensor node is small and has low computing power and very limited wireless bandwidth. Hence, the total execution time for distributed processing is affected by the data size and transmission rate. In particular, the low bandwidth of ZigBee that is used in a well-known sensor mote, such as MICAz of the University of California, Berkeley, affects the total execution time [4].
The energy efficiency and fairness of a network has been considered an important subject in the existing research concerning distributed or in-network processing. The execution time of the distributed processing has received little attention, though it is important to design energy-efficient sensor network applications. In this paper, we will focus on the total execution time estimation of processing and how to determine the optimal number of processing nodes based on a proposed estimation method in a low-bandwidth wireless network [5].
In Section 2, we describe clustered wireless sensor networks which bring the benefits in response time and energy consumption. Our proposed processing model is described in Section 3. In the network model we studied, how to validate it based on total execution time, the total execution time estimation model, and the cluster size for optimization of the execution time are discussed. We evaluate the accuracy of our estimation model in the experiment with the MICAz sensor mote in Section 4. A case study using a fast Fourier transform is presented in Section 5. Finally, we conclude the paper in Section 6.
2. Cluster in Wireless Sensor Network
Wireless sensor networks take the role of a bridge between the real world and the computing world. Distributed measurements are used in various areas including environmental monitoring, vehicle detection for transportation, detection of disaster, industrial safety management, military operation, and smart spaces [6].
Most sensor network applications need to be real time. Figure 1 shows the value changes according to time of a task with deadline D in real-time systems. If the detected data are not processed on time, the value of the processed results will decrease in a soft real-time system of Figure 1(a) and become zero in a hard real-time system of Figure 1(b). If the processing delay affects safety, the value of the results can be negative such as Figure 1(c) [7].

Value changes according to time.
Consider the sensor network application that detects an intrusion and takes a video of the area. Sensor nodes report to the sink node whenever a movement of a human, an animal, or some kind of object is detected, and the sink node decides whether it is an intruder based on the reported raw data. If the movement is identified as an intruder, the sink node sends the action command. The actions can be turning on a camera and taking a video. If the sink node takes action after the object has moved out of the area, the camera would not be able to record a video of the detected object [8].
Similarly, a structural health monitoring application checks the vibration frequency for detecting structural damage such as cracks. The collected vibration data are sent to the sink node, which analyzes the vibrations with signal processing techniques such as a Fourier transform. If structural damage is detected, the sink node should take action to alert the structural management system. However, if it takes a long time to relay data to the sink node, the action cannot be executed on time.
As described earlier, the real-time property is important for many wireless sensor network applications. However, it is difficult to obtain a fast real-time system. It may be impossible in some cases because the sensor nodes typically have insufficient resources and are deployed in harsh environments occasionally. Clustering techniques can be a solution for these wireless sensor network applications. The distributed processing or in-network processing of a cluster does not report all raw data. Instead, the node that has raw data processes data with neighbor nodes cooperatively.
The process of reporting data to the sink node suffers from not only end-to-end delay by multihop communication but also greater energy consumption in particular cases. The research [9] compared the performance of nonclustered and clustered sensor networks. They evaluated two types of “bit-hop metrics,” which count the total number of bit transmissions in the network (

where E is the total energy consumption by transmission,

From (2), we find the fact that the ability of clustered wireless sensor networks to outperform their nonclustered counterparts is conditioned by the values of Q, c, and α. Furthermore, they discussed two special cases, that is,
In order to obtain high performance from clustered wireless sensor networks, the value of correlation α should be high. If α is controllable, the performance efficiency of clustering can be improved. In the research [9], the cluster head (
The local distributed processing model with clustering proposed in this paper can be an alternative to control α for improvement of the network performance in terms of energy consumption. In this model, the
3. Cooperative Processing Model
3.1. Network Model
Wireless sensor nodes have very limited resources, including computing power, memory, and network bandwidth. This is a considerable difference between the distributed in-network processing of wireless sensor networks and the existing computing environments. In particular, we should consider low network bandwidth when designing in-network processing applications. According to the data size, distributed processing could be slower than execution on a node.
We consider a distributed processing model in a cluster in a wireless sensor network, which is composed of a root node that has data to be processed and n processing nodes that process divided data from the root node. We assume the following statements to simplify our execution time estimation model.
The root node and processing nodes are located at the one-hop distance for direct communication.
Transmission errors are not considered. It is assumed that the handling of transmission errors is performed at the sublayers of communication stack.
The root node transmits divided data to all processing nodes in order from node 1 to node n.
The data transmission time from the root node to each processing node is identical because the divided data has the same size.
The network channel is preempted by one node at a specific time; that is, the number of nodes transmitting is one.
The size of the data from the root node and returned data from a processing node after processing is equal.
All processing nodes perform the same task.
The execution time on each processing node is identical because the data size and task are the same on each node, respectively.
Figure 2 presents a processing model to cooperate in a proposed cluster. When the root node prepares data, it creates a cluster with n processing nodes and transmits divided data with the same size to each processing node in order. The propagation time for a chunk data is defined as
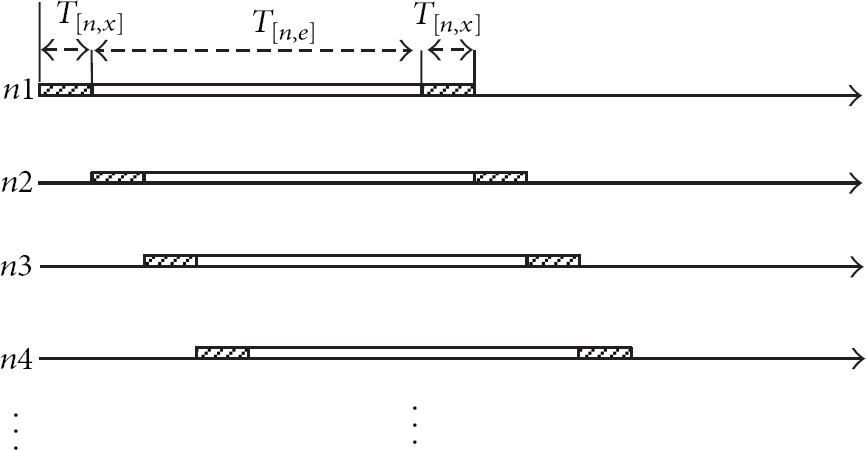
Timeline of cooperative processing.
3.2. Processing Validation
Consideration of the minimum execution time given the network bandwidth is needed before planning to build a distributed wireless sensor network application. As we mentioned, typically wireless sensor networks are operated under low bandwidth, which affects the total execution time (T). We use this minimum execution time (
It is impossible that T is less than propagation time for the whole data including data scattering and gathering. Therefore, distributed processing takes more time than processing on a single node if

where L is the size of all data on the root node and B is the network bandwidth.
3.3. Total Execution Time
The total execution time can be calculated for two different cases according to two time points: point
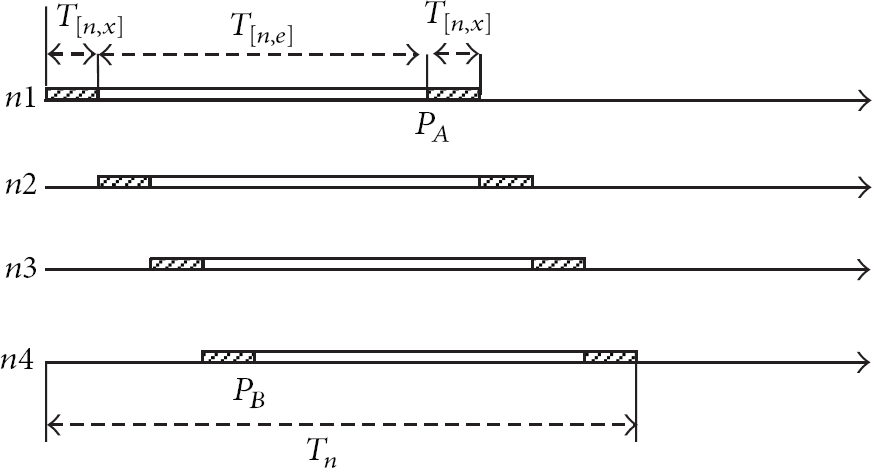
Timeline when

Timeline when
Figure 3 shows the first case with 4 processing nodes, in which
The second case is presented by Figure 4, which is when

Therefore, the total execution time (

3.4. Optimal Number of Processing Nodes
We measured the execution time when adding processing nodes. From Figure 5, the distributed processing performance does not improve with the addition of processing nodes. The inclusion of additional sensor nodes to processing leads to the wastage of network resources. We define the optimal number of processing nodes as the point at which an increase in the number of nodes does not decrease the total execution time.

Measured execution time.
When

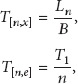
where,
Consequently, the optimal number of processing nodes can be estimated as
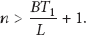
3.5. Implementation Issues
To apply the proposed execution estimation model to design a software system for a wireless sensor network, the following issues should be considered.
3.5.1. Premeasuring
and B
The proposed method is based on data transmission time
3.5.2.
Estimation
In (7), we assume that
4. Experimental Environment
We measured transmission rates with the same packet size and protocol before evaluating the accuracy of our proposed model. Then, we calculated the total execution time and the optimal cluster size with the measured transmission rate and the data size. We compared the calculated results and the measured data via experiments. The experiments were conducted with TinyOS 2.x and a MICAz mote of UC Berkeley [10, 11].
4.1. Transmission Rates
The transmission rates are needed for our proposed equations. We measured the transmission time for the various data sizes. Figure 6 presents the sequence by which the application sends data and how to measure the transmission time. TinyOS is an event-driven operating system. When the application tries to send data, the scheduler returns the status immediately and signals the SendDone events after finishing transmission. Our implementation sends data in the SendDone event handler in divided packets repeatedly.

Sequence for measuring transmission rates.
The base station sets the timestamp after sending a command to the node implemented for the transmission task. Then, the base station calculates transmission rates after receiving all packets.
The measured transmission rates are presented in Table 1. In our other experiments, we used the measured average value of transmission rates as the network bandwidth.
Measured transmission rates.
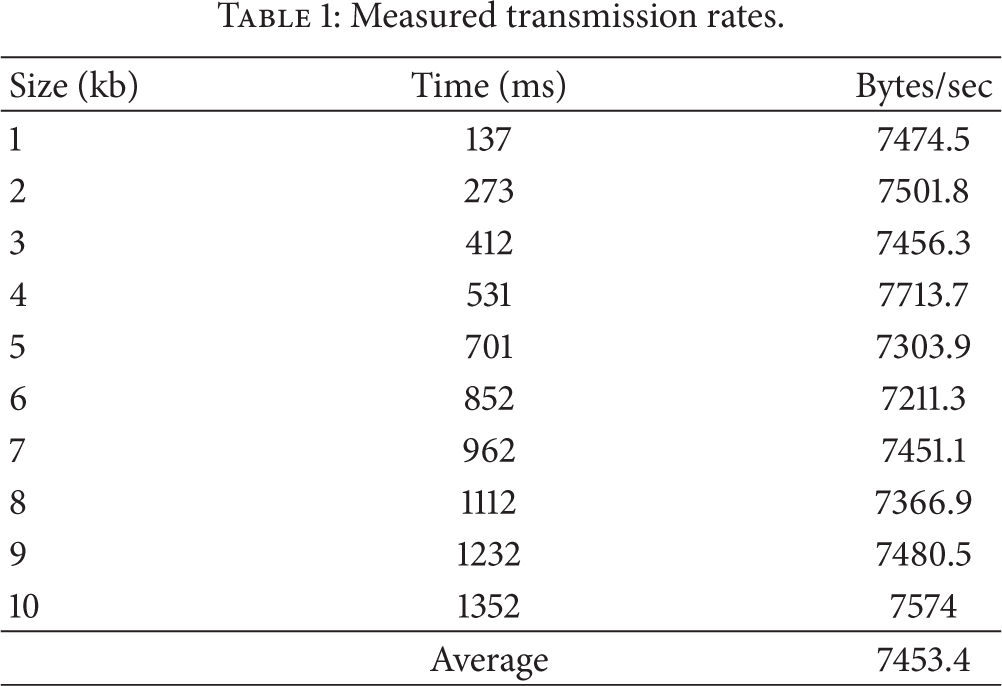
4.2. Validation
We propose a validation method to identify whether the total execution time of the distributed processing is shorter than that for processing on a single node. System designers could use the proposed method to check distributed performance with their own parameters. This experiment was conducted with a fixed data size (
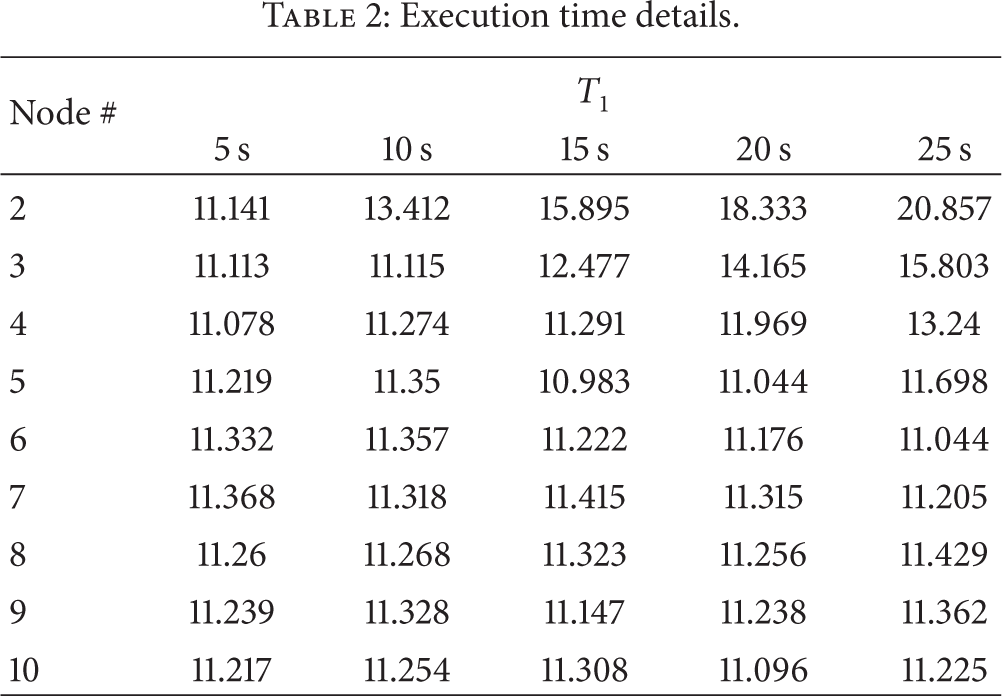
Figure 7 shows the measured execution time, and the details are presented in Table 2. Some results were even worse than
Execution time details.

Execution time with fixed data size.
4.3. The Optimal Number of Processing Nodes
The optimal number of processing nodes was defined as the point after which there was no performance improvement in execution time. Figures 8 and 9 represent the measured total execution time and optimal number of nodes for each case. The optimal point is calculated via our proposed model.

Measured

Measured
The first experiment was conducted with fixed
4.4. Execution Time Estimation
We measured the total execution time by varying the number of processing nodes. Figure 10 shows the measurements and the calculated

Measured and estimated execution time (
No other tasks were included in the experiments, so the results have negligible error. For practical applications, the network status and other tasks should be considered.
5. Case Study: 2D FFT
The fast Fourier transform (FFT) is widely utilized for signal processing applications such as structural health monitoring and multimedia processing. We implemented a distributed 2D-FFT application and evaluated our model for this application. Data sizes of
As we discussed in Section 3.5,
The total execution time for a

Total execution time for
In this case, the optimal number of processing nodes is estimated to be 13 via (8), and
From the results, the average error was found to be 1.2 seconds, and the trends in the total execution time bear a strong resemblance. At 16 processing nodes, the total execution time was the minimum for both the measured and estimated cases.
Figure 12 presents the results for a

Total execution time for
6. Conclusions
Wireless sensor networks provide an environment for distributed processing. The limited resources of the sensor nodes create a difficulty in designing a distributed system. For this reason, we have studied a distributed processing model in wireless sensor networks.
In this paper, we proposed a distributed processing model in wireless sensor networks. The methods to estimate the total execution time, validate distributed processing in terms of the execution time, and calculate the optimal number of processing nodes for distributed processing in wireless sensor networks were described.
We demonstrated the accuracy of the proposed model through experiments. First, the transmission rate was measured and was then used for the other experiments. Next, validation in terms of time was demonstrated. Through the validation equation, a system designer can decide whether distributed processing is needed or not. The experiments to confirm the optimal number of nodes were carried out with various options. The estimated optimal numbers of nodes were indicated with high accuracy. In the experiments for execution time estimation, the average error of the model was found to be as small as 0.36 seconds.
We implemented a 2D-FFT application and demonstrated that our model can be used for the application in the case study. The experiments had more errors than previous experiments because the proposed model does not consider other tasks on the node, and the real transmission rates are not identical all the time.
In our future research, the cost analysis in time and energy between centralized system and our proposed cooperative processing model will be performed. Furthermore, we will study the distributed processing model for multihop clusters and perform more experiments for other applications to improve the model.
Footnotes
Acknowledgment
This research was supported by the Ministry of Science, ICT & Future Planning (MSIP), Republic of Korea, under the Convergence Information Technology Research Center (C-ITRC) support program (NIPA-2013-H0401-13-1002) supervised by the National IT Industry Promotion Agency (NIPA).