
Abstract
A relation called approximate bisimulation is proposed to achieve behavior and structure optimization for a type of high-level datapath whose data exchange processes are expressed by nonlinear polynomial systems. The high-level datapaths are divided into small blocks with a partitioning method and then represented by polynomial transition systems. A standardized form based on Ritt-Wu's method is developed to represent the equivalence relation for the high-level datapaths. Furthermore, we establish an approximate bisimulation relation within a controllable error range and express the approximation with an error control function, which is processed by Sostools. Meanwhile, the error is controlled through tuning the equivalence restrictions. An example of high-level datapaths demonstrates the efficiency of our method.
1. Introduction
Intelligent transportation systems (ITSs) provide a substantial amount of convenience for daily life. However, with the ever-growing application demands, the scale of ITSs is increasing because ITSs must include an increasing number of features, which will lead us to a difficult situation when designing and verifying the system. With regard to this issue, there is a growing interest in researching how to reduce the scale of the elements in an ITS that involve hardware, software, and other components. In this paper, the research objective is circuit optimization. To achieve the behavior and structure optimization for circuits, the specific data exchange processes must be analyzed. Therefore, we must study circuits at a high level, called high-level datapaths. Complex high-level datapaths typically contain equivalent data exchange processes that are overly complex; worthwhile research on these datapaths considers either how to eliminate the superfluous portion of these processes, known as structure optimization, or how to simplify these processes, known as behavior optimization. In this paper, a novel method is established to address these optimization issues simultaneously for high-level datapaths. Equivalence verification is one of the most commonly used formal methods and is the basis for implementing this method.
There are several equivalent verification tools for circuits, but most of these tools are only suited for circuit verification at a low level, for example, binary decision diagrams (BDDs) [1], word-level decision diagrams (WLDDs) [2], and Taylor expansion diagrams (TEDs) [3]. These tools were all defined on standardized graphs, which have large exponential spaces and time complexities. As a result, verification methods that are based on algebraic methods, such as equivalence verification, have been proposed to solve these problems. Although these methods are very powerful when addressing low-level circuits, they are less suitable for addressing special problems for high-level datapaths. For high-level datapath verification, Smith and Micheli presented a polynomial method for component matching and verification and researched polynomials as allocating components [4, 5]. Moreover, they found a polynomial model for component matching at a high synthesis level [6]. Based on their studies, numerous other research efforts were performed; for instance, the algorithms were proposed to achieve lower costs and minimum timing, driven in high-level data flow synthesis with symbolic algebra [7–9].
For symbolic algebra, Buchberger demonstrated that useful research must combine a logic method with an algebraic method [10]. In 2006, Zhou also noted that combining these types of methods would be an effective way to verify a system's properties [11]. Based on these ideas, Yang et al. presented a polynomial description and provided a functional equivalence algorithm based on the Groebner bases for one type of high-level datapath, whose data exchange processes are shown by nonlinear polynomial systems. The algorithm was defined from the perspective of common solutions of nonlinear polynomial systems [12]. This work is the first to achieve the functional equivalence of a symbolic method for circuits, and the computing effort is less than that for BMDs or integer linear programming (ILP). However, the optimization is not complete; there is still some potential for improvement. Thus, we provide a more efficient method to achieve the equivalence verification for programs by Ritt-Wu's method in this paper because the characteristic set of a polynomial set achieved by Ritt-Wu's method is unique [13, 14]. Ritt-Wu's method is an algorithm for solving multivariate polynomial equations. It is based on a mathematical concept of characteristic set and powerful for mechanical theorem proving in elementary geometry; then it gives a complete decision process for certain classes of problems.
Equivalence relations require that the behaviors of two high-level datapaths be equivalent, which appears to be impossible using existing technology. For example, consider that we choose two different microwaves to heat bread there are two parameters that we must consider: temperature and time. If both of the ovens can raise the temperature to the same level, then the bread can be heated by the two microwaves. In this case, time is not the critical parameter; the fact that one value is 30.0 s and the other is 29.9 s does not matter. Therefore, these two microwaves can be considered approximately the same. In this case, one of the microwaves, which has a simple behavior and structure, can be used to approximately replace the more complex microwave. This example illustrates that an appropriate approximation can be accepted and provide optimization for different systems without causing a crucial influence. This idea is the key concept that we will utilize to optimize the behavior and structure below and provide a more appropriate relation for high-level datapaths in this paper.
To make this idea come true, an approximate method for a single high-level datapath has already been proposed; this proposal establishes, for the first time, an approximate relation for the corresponding branches in a single datapath [15]. However, this approach does not appear to be a good method for complex circuits that require a large amount of computing effort if we consider the circuits as a whole. Therefore, we must adopt a circuit partitioning method to divide the original datapath into several small blocks. For the circuits, there are already many different partitioning methods based on different demands [16, 17]; considering these methods, a new partitioning method based on an impact factor is proposed in this paper. After being partitioned, an appropriate description of the datapath must be given to research its behavior and structure. A labeled transition system is the basis for achieving this description. Based on this description, an equivalent relation must be proposed to achieve circuit optimization. For the equivalence relation, bisimulation has the best equivalence semantic in process algebra and will be chosen [18]. Bisimulation has been applied to optimize property verifications for different systems, such as hybrid systems and dynamical systems [19–25]. However, these optimizations still have an issue in that the computing effort could be too large because the original system has not been standardized. We will address this problem here.
In the next section, we will choose nonlinear polynomial sets to represent the data exchange process of a type of high-level datapath in the same way as Yang et al. [12]. To process these sets more conveniently, a datapath partitioning method is proposed to decompose a datapath into several small blocks. To achieve behavior and structure optimization, high-level datapaths are first modeled by polynomial transition systems. Then, a bisimulation relation is proposed. Standardized forms are achieved to determine the equivalence relation for high-level datapaths based on Ritt-Wu's method. In this process, the polynomial sets that correspond to datapaths are changed into triangular sets and provide a space to obtain an approximate relation with their processing nondegeneracy conditions. Subsequently, an error control function is proposed to represent the difference between the datapaths and is processed by a numerical method. Finally, we ensure that our approach obtains circuit optimization by presenting a case study. The proposed method can be used to optimize some circuits within ITS. Our framework is a natural generalization for a type of circuit in ITS that is based on a formal method. For this process, we used Maple and MATLAB as technical tools. The theories of polynomial algebra, polynomial representation of circuits, and algebraic transition systems are the bases of our method, which are mostly available in the literature [12–14].
2. Partitioning Method and Polynomial Transition System for a High-Level Datapath
In ITS, there are a variety of circuits that can be used to satisfy the variety requirement [26, 27]. When researching the circuits at a high level, their data exchange processes can be expressed by differential semialgebraic systems, differential systems, and polynomial systems, among others. In this paper, we mainly research the circuits for which the data exchange processes can be represented by nonlinear polynomial systems. We have already proposed an approximate method for a single high-level datapath of this type [15], which is suitable only for some simple datapaths. Based on traditional circuit partitioning methods [28–30], a new partitioning method is introduced in this section to divide a datapath into small blocks for a complex datapath.
2.1. Partitioning Method
Let IF (i, o) be an impact factor for a block in a datapath that sums the number of initial inputs i and final outputs o for this block. After being partitioned, the impact factor of every block is the same or similar. More complex blocks have higher impact factors.
Example 1. Figure 1 presents a datapath in which two inputs, x1 and x2, pass through an adder to achieve an intermediate variable v. Then, the output passes through a multiplier that has an additional input of x3, and then, the output y is obtained.
With a partitioning method, when the impact factor is equal to three, the datapath is divided into two blocks, as shown in Figure 2.
The computing effort and memory usage of these blocks are less than those of the entire datapath. Using previous studies [7, 12], the two blocks in Figure 2 can be described by the following two polynomial sets:

There is a similarity between a labeled transition system and a high-level datapath after being partitioned. The labeled transition system is composed of limited states and transitions, and every transition represents a relation between inputs and outputs. Because the data exchange processes of high-level datapaths are also described by the polynomial sets to represent the relation between the inputs and outputs, the high-level datapath can be modeled by a labeled transition system, referred to as a polynomial transition system, which is summarized as follows.

A datapath.

The datapath after being partitioned.
Definition 2. A polynomial transition system for a high-level datapath is represented by a tuple
a set Q of variables;
a set L of locations;
a set → of transitions; every transition is a tuple
l1 and l2 are pre- and post-locations of this transition; P is a first-order assertion represented by a nonlinear polynomial system over Q
I
∪ Q
M
∪ Q
O
, where Q
I
, Q
M
, and Q
O
represent the input, middle, and output variables, respectively;
a set Q0 of initial variables.
The polynomial transition system can be described as a state graph, which contains states and transitions. The entire exchange process between the datapath and polynomial transition system is illustrated in Figure 3.

The transformation process between a datapath and its polynomial transition system.
In Figure 3, if P1, P2, and P3 have solutions within the same value range and their solutions are equivalent, then the behaviors of these three blocks are identical. In this case, an interesting research topic is determining how to achieve the solutions for the blocks to determine their equivalence relations.
In this paper,
3. Equivalence Determination for High-Level Datapaths Based on Ritt-Wu's Method
For the majority of polynomial sets, the solutions cannot be achieved easily; as a result, it is difficult to determine their equivalence relations. To solve this problem, we use Ritt-Wu's method to standardize the behavior of high-level datapaths first, and we then obtain a standard and unique form to represent equivalence relations without calculating their solutions directly.
By comparing the Groebner basis with Ritt-Wu's approach used in this problem [12], we find that the Groebner basis always results in additional polynomials, which will require a large amount of storage space. In contrast, Ritt-Wu's method allows for simpler and more standardized polynomial sets. At the same time, Ritt-Wu's method is a linear combination of polynomial sets. Its operations are linear, and the degrees are lower as well. Therefore, this method requires less storage space and is more efficient than the Groebner basis.
Before using Ritt-Wu's method to process high-level datapaths, the order of the variables must be defined.
Definition 3. An order relation < is denoted as follows, on S i ∪ S m ∪ S o :
∀ x ∊ S i , ∀ z ∊ S m , ∀ y ∊ S o , then, x < z < y;
∀ x1, …, x n ∊ S i , then, x1 < · < x n ;
∀ y1, …, y n ∊ S o , then, y1 < · < y n ;
∀ z1, …, z n ∊ S m
∀ z
i
∊ S
m
, ∀ z
k
∊ S
m
, ∀ z
j
∊ S
m
, z
i
, z
k
, and z
j
represent input, middle, and output variables, respectively; then, z
i
< z
j
; ∀ m1, …, m
n
∊ z
i
, then, m1 < · < m
n
; ∀ n1, …, n
n
∊ z
j
, then, n1 < · < n
n
,
where DP(S i , S m , S o ) is a high-level datapath and S i , S m , and S o represent the input, middle, and output variables, respectively.
Theorem 4. Two blocks DP1(x, y, m) and DP2(x, y, n) are equivalent if
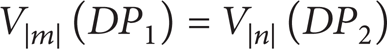
which equals

where all
Otherwise, it equals

Proof. It is well known that multivariate polynomial rings over fields are Noetherian; thus, the ideal I can be decomposed into the following:
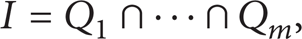
where Q i is a primary ideal.
Using Ritt-Wu's method, we obtain a variety decomposition: V(P) = ∪ i = 1 e V(P i ).
Each P i defines an unmixed algebraic variety. If V i = V(P i ), then the above decomposition can be rewritten as

By irreducible variety decomposition, a decomposition of the radical ideal
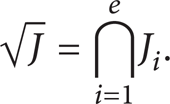
Thus,
At the same time,

Because V(Ideal (P)) = V(P), we have
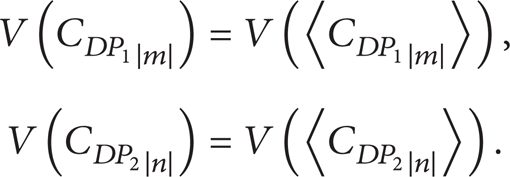
Therefore,
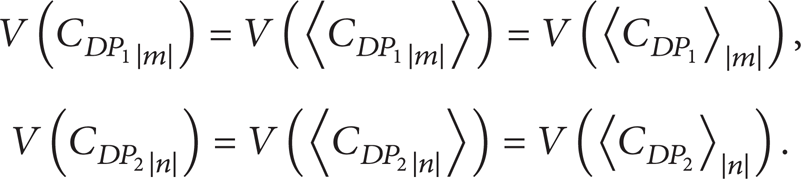
Thus, if
This theorem solves the problem of theoretical determination. It provides us with a unique form to determine equivalent relations for two blocks without calculating their solutions directly and allows our calculation method to be more enriched and strengthened in the process of determining the equivalence relations. With the equivalence determination for blocks, additional blocks can be reduced and complex blocks can be replaced with simpler blocks to achieve structure and behavior optimization. The framework for circuit optimization is illustrated in Figure 4.

Behavior and structure optimization based on equivalence.
4. Approximate Bisimulation for High-Level Datapaths
After achieving the equivalence relation for the corresponding blocks of a high-level datapath, we next investigate how the equivalence for the entire datapath can be determined.
4.1. The Definition of Approximate Bisimulation
Exact equivalence demands that the solutions of polynomial sets for two datapaths be identical without any error. This constraint appears to be too strict for datapaths in technology because many values of special variables are achieved only by approximation. Thus, in this section, we relax the equivalence restrictions to create a more appropriate relation within a suitable range for all of the datapaths, and we use this relation to achieve behavior and structure optimization. This process is illustrated in Figure 5.

Behavior and structure optimization based on approximation.
In the process of achieving optimization, bisimulation is applied to establish an approximate equivalence relation for the entire system, as illustrated in Figure 6.

Nonbisimular.
In this figure, because the dotted part of the left state graph does not have the same trajectory as the right transition graph, they are not equivalent with bisimulation. Bisimulation provides us with the most exact equivalence relation, which can be used to achieve equivalence relations for circuit optimization.
Let
Definition 5. A relation S
D
⊆ Q1 × Q2 is called an approximate bisimulation, where
Thus, DP1 and DP2 are approximately bisimilar, which means that the solutions of two nonlinear polynomial systems of corresponding blocks are approximately the same for DP1 and DP2.
If D > δ, then P1 and P2 are not approximately equivalent.
If
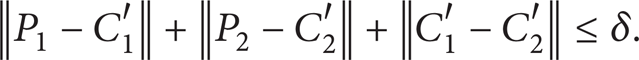
At the same time, the following hold.
If C1′ and C2′ can be changed into two datapaths, then P1 and P2 can be replaced with the simpler datapath in C1′ and C2′. Therefore, the behavior and structure of DP1 and DP2 are approximately optimized. Otherwise, C1′ and C2′ can be used to optimize the safety verification for P1 and P2. If C is safe, then
Because
Thus, P is safe.


If
C1′ and C2′ are the characteristic sets after ignoring some initials for C1 and C2; C1 and C2 are the irreducible characteristic sets of P1 and P2, respectively.
In this process, the initials of a characteristic set can be considered nondegeneracy conditions because their dimensions are always very low and negligible. For a datapath, an initial is the coefficient of a variable with a high order expressed by a complex unit. If an initial is ignored, then the complex unit is removed to reduce the design costs for the datapath.
With the above analysis, the calculation of approximate bisimulation can be established, which is provided in the next subsection.
4.2. The Calculation Algorithm of Approximate Bisimulation
If the variables of nonlinear polynomial systems of corresponding blocks in a polynomial transition system are the same after substitution, the calculation algorithm of approximate bisimulation for a high-level datapath can be established as follows (see Figure 7).
Approximate bisimulation for a high-level datapath.
Algorithm 6. The calculation of approximate bisimulation for a high-level datapath.
Input. A high-level datapath whose data exchange processes are represented by nonlinear polynomial systems.
Output. An optimized high-level datapath for the given high-level datapath.
Step 1. Change the high-level datapath into a polynomial transition system. Here, δ is the precision. A group branches according to the bisimulation relation. Suppose that the number of groups is m. Let a counter i = 1.
Step 2. Process the ith group first. Let the precision δ i in this group belong to
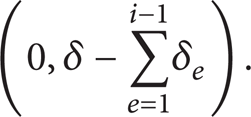
Step 3. Use Ritt-Wu's method to determine the relation of every two branches in this group.
Step 3.1. If the irreducible characteristic sets are identical, then these branches are equivalent. In this case, choose the simplest branch to replace all of the branches and go to Step 5. Otherwise, go to Step 3.2.
Step 3.2. If the errors are not more than δ i , then these branches are approximately equivalent. In this case, choose an appropriate branch of this group to replace all of the branches and go to Step 5. Otherwise, go to Step 3.3.
Step 3.3. Suppose that the number of branches is a; label them from 1 to a. Let a counter b = 1 and go to Step 4.
Step 4. Determine the relation between the bth branch and the other branches that form the b + 1th to the ath branch. Let the symbol of the nonlinear polynomial system corresponding to the jth branch be J j . Let
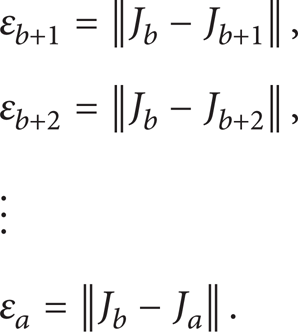
Select J j except J b to form a set A when the errors are larger than δ i . Let the element in A be labeled by K j . The remaining elements except J b form the set B. Let the element in B be labeled as O j . Go to Step 4.1.
Step 4.1. Let U = . The number of elements in A is l. Go to Step 4.2.
Step 4. 2. If there are
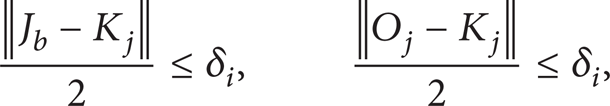
go to Step 4.2.1. Otherwise, U = A and go to Step 4.5.
Step 4.2.1. Select those elements for which the error of two of the elements is not more than 2δ i in A to form a new set A′. Merge A′, J b , and B into a set W. The remaining elements form a set U.
Step 4. 3. If there exist initials in A′, then go to Step 4.3.1. Otherwise, go to Step 4.3.2.
Step 4.3.1. The error caused by the initials of this element is not more than δ i ; then, the characteristic set of this element J w is used to replace all of the elements in W. Go to Step 4.4. Otherwise, go to Step 4.3.2.
Step 4.3. 2. Use the appropriate element J w in J b and O j to replace and merge all of the elements in J b and O j ; U = A, and go to Step 4.4.
Step 4. 4. Merge U and J w to form a new group to be considered as the new ith group. Let the number of branches of this new group be a, b = 2. If a > 2, then go to Step 4; otherwise, go to Step 5.
Step 4. 5. If there exist initials in B, then go to Step 4.5.1. Otherwise, go to Step 4.5.2.
Step 4.5.1. If the error caused by the initials of this element is not more than δ i , then the characteristic set of the elements in J w is used to replace all of the elements in J b and B; go to Step 4.4. Otherwise, go to Step 4.5.2.
Step 4.5. 2. Use J b to replace J b and B. Let J b be J w , and go to Step 4.4.
Step 5 (i + +). If i ≤ m, then go to Step 2; otherwise, end, and a new nonlinear polynomial transition system is obtained. Thus, the optimized high-level datapath for a given high-level datapath is achieved.
If there are several different high-level datapaths, then we process them with Algorithm 6 to achieve their optimized datapaths. Then, we consider these optimized datapaths to be nondeterministic branches in a new datapath; we determine the equivalent relation for the corresponding branches of this new datapath, choose a simpler branch to replace the complex branches, and achieve the final optimized high-level datapaths.
5. Error Calculation and Error Control Algorithm
This section discusses how to calculate the error, determine whether the error is within an allowable range, and decrease the error if it exceeds the precision requirement.
5.1. Error Control Function
Every point of the original and approximate systems in space can be expressed by a vector. For example,
Let M(x1, … x n ) and N(y1, … y n ) be polynomial systems; then,
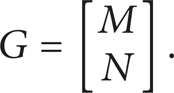
Let the gradient of G be denoted as ∇ G, and let
Positive growth: if θ < 90°, then
Negative growth: if θ > 90°, then

Positive and negative growth.
Therefore, the error is reduced when
Let D be an error; then, we can obtain
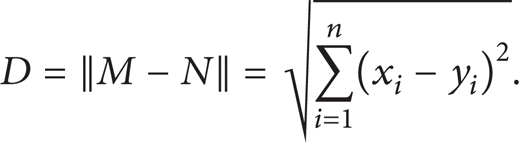
Let a(x) = [(x1 – y1)2, …, (x
n
– y
n
)2] be a vector that carries the relational information of the variables between M and N. Compare D with a(x). Suppose that G(x) = K × a(x) is an error control function. Here, ∇ G(X) is the gradient. For all x, y ∊

If we also want to minimize the error control function, then we must minimize the value of the coefficient, which is

Here, the value of each item in W, when interrelated with the relations between the two systems, is zero or one. For example, if the variables of the two systems are the same, then we only need to determine whether their outputs are identical. Therefore, we obtain a(x) = [(x1 – y1)2, …, (x n – y n )2], W = [0, …, 0, 1]. The values of W and a(x) are unique for every datapath. After achieving the value of K, the error is achieved by
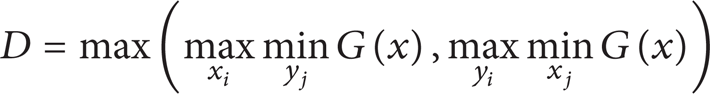
under the range of values of the variables.
For the nonlinear polynomial systems of datapaths, the number of polynomials may not be equal to the number of variables. To address this problem, we add a new polynomial 0 into the polynomial sets until the numbers of polynomials and variables become identical. The error control function is implemented in MATLAB by the optimization toolbox Sostools.
5.2. Error Control Algorithm
In Section 4, we find that there is a place to achieve an approximate datapath for the original datapath by processing the initials. If the error is large, then the previous ignored initials are readded into a characteristic set to obtain a new approximate characteristic set.
Breadth-first traversal is used in the following algorithm. The first layer and node are labeled by 0.
A description of the symbols used in the algorithm is as follows:
P: a polynomial system; C: the characteristic set for P; I: the initial set for C; D(M, N): an error between two datapaths M and N; δ: precision; n ← count (I, C): the number of polynomials in I is n, as counted by a function count; t ← Crn (r, n): there exist t different choices while adding r initials, t = C
n
r
, 1 ≤ r ≤ n – 1; get (C): obtain one item from C; getmax (C): obtain one item from C whose dimension is the largest dimension; set (M, N): merge M and N into one system; sumresterror (·): sum the remaining error except for the error caused by C; I
rt
: the initials added in the tth time while adding r initials; k: the subscript of the characteristic sets; m: the number of polynomials of each characteristic set; l[d]: the number of initials according to the characteristic sets in the dth layer; d: the depth of the current layer; finish: the symbol for the end.
Error control algorithm is as the following.
Algorithm 7. Achieve the approximate polynomial sets for the original polynomial sets and adjust the error within a precision level.
Input. Nonequivalent polynomial sets P1 and P2.
Output. Approximate polynomial sets P1′ and P2′.
Step 1. Initialize variables: m = 1, k = 1, r = 1, t = 0, and d = 0.
Step 2. Obtain the solution decomposition for P1 and P2 with Ritt-Wu's method:

where m = count (I, C1) and n = count (I, C2).
Let P = set (P1, P2) and S = set (C1, C2).
Step 3. Ignore all of the initials for C1 and C2. Obtain D1 = D(P1, C1), D2 = D(P2, C2), and D = D(C1, C2).
Step 4. If D + D1 + D2 < δ, C1 ≅ C2. Let P1′ = C1, P2′ = C2. Go to Step 4.1. Otherwise, go to Step 4.2.
Step 4.1. If C1 and C2 cannot be changed into datapaths, then the new approximate polynomial sets cannot be achieved; end. Otherwise, the simpler choice between C1 and C2 is chosen to replace P1 and P2; end.
Step 4.2. If S is an empty set, then C1 ≇ C2, P1 ≇ P2, and error = ∞; end. Otherwise, go to Step 5.
Step 5. Let

Step 6. If C is contradictory, then go to Step 9. Otherwise, go to Step 7.
Step 7. If finish = true, then go to Step 10. Otherwise,
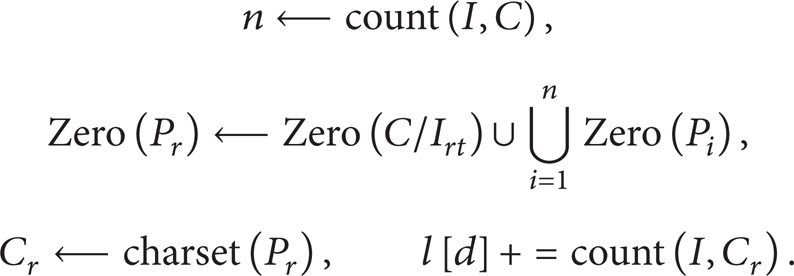
Go to Step 8.
Step 8. If D(P, P r ) + Terror < δ, then finish ← true and go to Step 7. Otherwise, r ← r + 1, t ← Crn (r, n), and go to Step 8.1.
Step 8.1. If r > n – 1, then go to Step 9. Otherwise, go to Step 7.
Step 9 (k + +). If k > m, then go to Step 9.1. Otherwise, go to Step 9.2.
Step 9.1. If l[d] = 0 and P1 ≇ P2, end. Otherwise, m = l[d], C ← C k , d ← d + 1, and l[d] = 0, and go to Step 6.
Step 9.2. C ← C k ; go to Step 6.
Step 10. If P1′ and P2′ can be changed into the datapaths P1′ ≅ P2′, then end. Otherwise, approximate datapaths cannot be achieved; end.
With this algorithm, the error can be controlled by readding the ignored initials. If the final error is still larger than the precision, then there is no approximate relation based on our method.
In the process of this algorithm, there is a critical step that requires special attention. The currently added initials may not be able to achieve our desired goal, which means that they cannot reduce the error when D > δ. This problem is caused by the relationship among the zeros of the polynomial sets, the characteristic sets, and their initials. Therefore, we must analyze the relationship so that we can choose the appropriate initials to decrease the error as soon as possible.
5.3. Choose the Appropriate Initials
Choosing the appropriate initials will allow us to reduce the computing efforts. With the relationship among the solutions of the polynomial sets, the characteristic sets, and their initials, there are three different types of functions for the added initials. Next, let P be a polynomial set for a block of a datapath. C is a characteristic set for P, and I = [I1, …, I r ] is the initial set for C. According to Ritt-Wu's decomposition,

Theorem 8. The function of added initials has three cases. The value ranges of the solutions are represented by circles.
C and I have no intersection. This type of initial cannot reduce the error. The solution relationship of P, C, and I is shown in Figure 9 (a).
C and I have an intersection, and I ⊂ C. The function of these initials can be divided into two cases, and the solution relationship of P, C, and I is shown in Figure 9 (b).
If I
i
⊂ P ∩ I, then these initials cannot reduce the error. If I
i
⊄ P ∩ I, then these initials can reduce the error.
C and I have an intersection, but if ∃ I i ∩ C = , the function of these initials has two different cases, and the solution relationship of P, C, and I is shown in Figure 9 (c).
If I
i
⊂ P ∩ I, then these initials cannot reduce the error by adding them. If I
i
⊄ P ∩ I, then there are two cases for the effect of the initials.
If I
i
⊄ C, then these initials cannot reduce the error. If I
i
⊂ C, then these initials reduce the error by adding them.
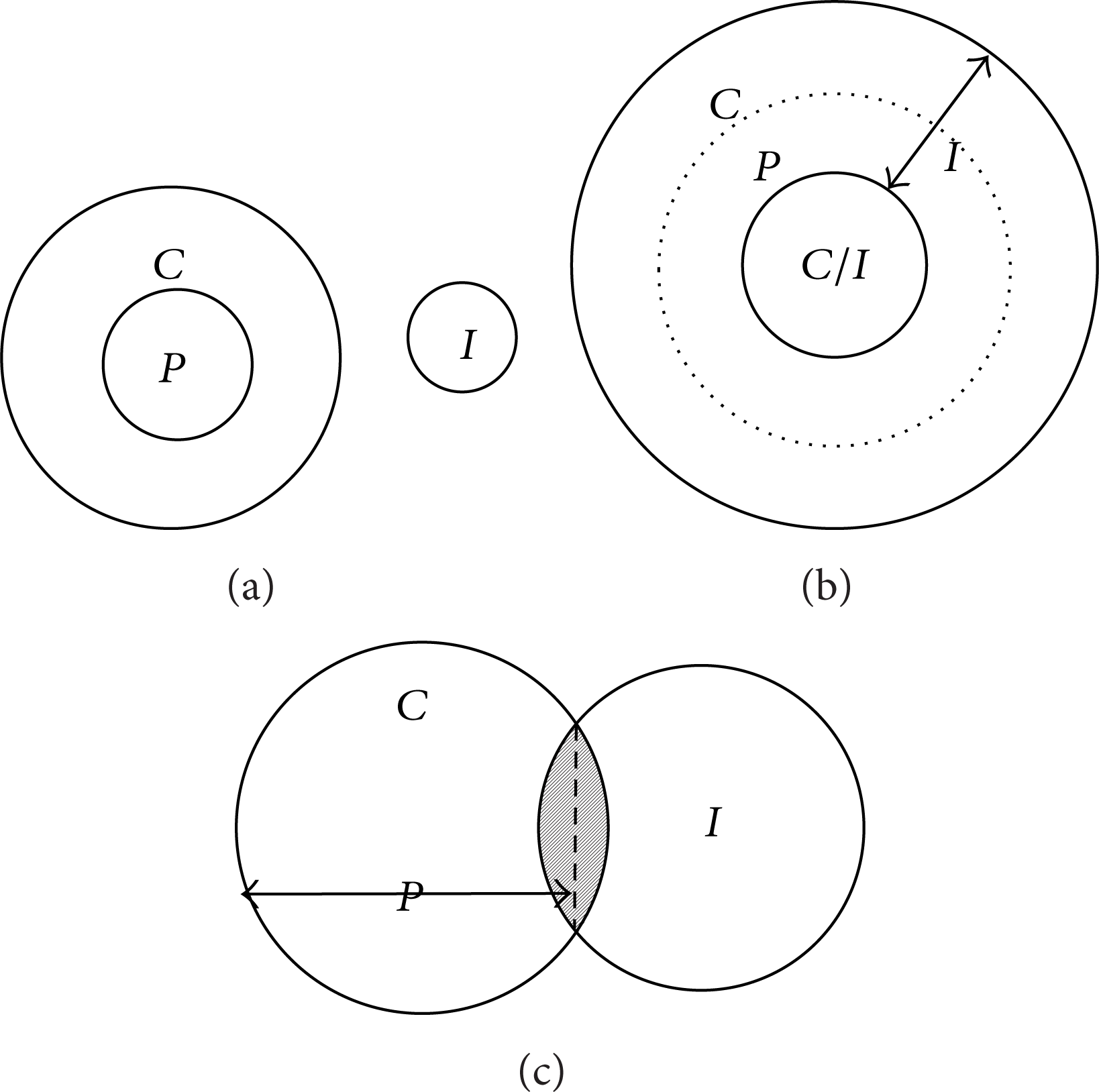
Solution relationship.
Using the above analysis, we can select the most appropriate initial to control the error as soon as possible.
6. Example Verification and Main Results
Let us consider two high-level datapaths DP1 and DP2 in the ITS shown in Figures 10 and 11, where δ = 5e – 15. In these figures, DP1 and DP2 have complex units. The datapath partitioning method is applied to reduce the computing effort. The impact factor equals four, and then, DP1 is divided into four parts and DP2 is divided into two parts, as shown in Figures 12 and 13.

DP1.

DP2.

DP1 after being partitioned.
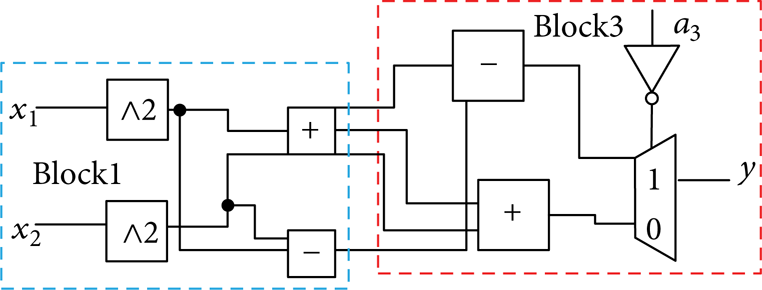
DP2 after being partitioned.
Blocks 1 and 3 for DP1 and DP2 are identical. Therefore, we only demand to determine the relationship among blocks 2, 3, and 4 for DP1. If these blocks are equivalent or approximately equivalent, then DP1 and DP2 are the bisimulation equivalent or approximate equivalent and we can replace DP1 with DP2.
The polynomial representations for DP1 are as follows:
Block 2 PB:
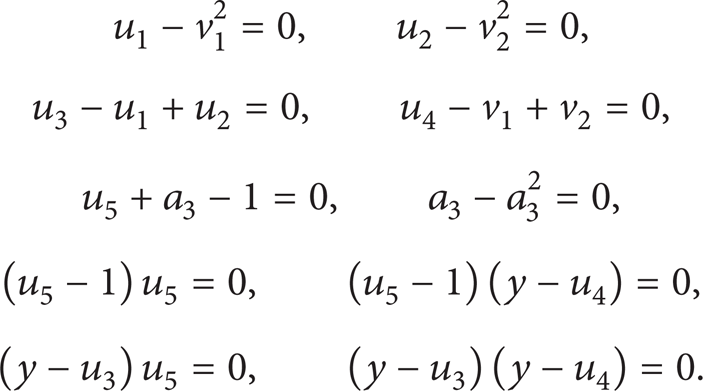
Block 3 PY:

Block 4 PG:

We compute the characteristic sets for these blocks by Ritt-Wu's method. The results are as follows after removing the middle variables:
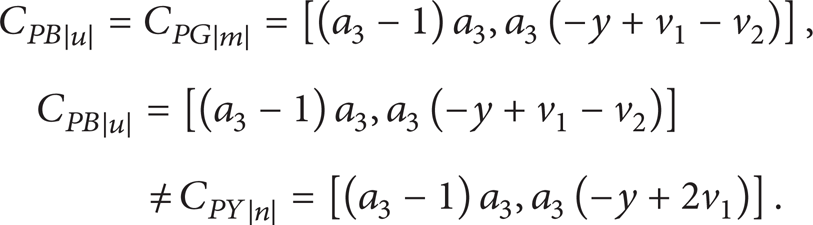
Thus, block 2 is equivalent to block 4.
However, for blocks 2 and 3, we must establish an error control function, check the value of the error, and determine whether the error is within the expected precision. The entire process is described below.
Let the variables ∊ [0, 1], and let the symbols of the variables {x, y, a} of the second system be changed to {x′, y′, a′} by a substitution rule to facilitate the calculation.
For P PB and P PY ,

Then,

After computation, the error control function is

D = max(G(x)) ≈ 6.1e – 15 > 5e – 15; thus, P PB and P PY are not approximate.
For C PB and C PY ,
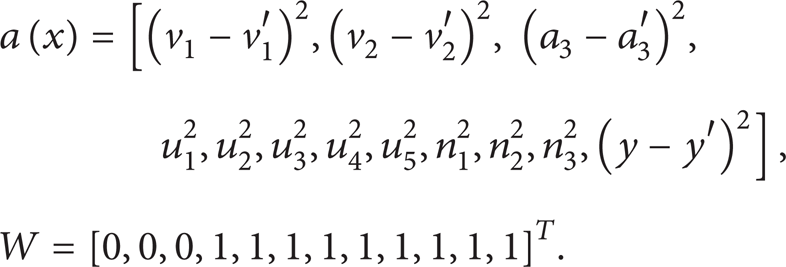
Then,

The error control function is
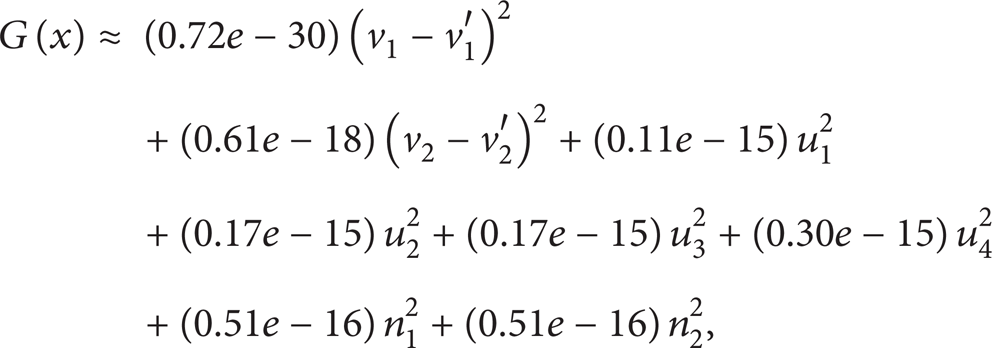
D1 = max(G(x)) ≈ 8.63e – 16.
For P PB and C PB ,
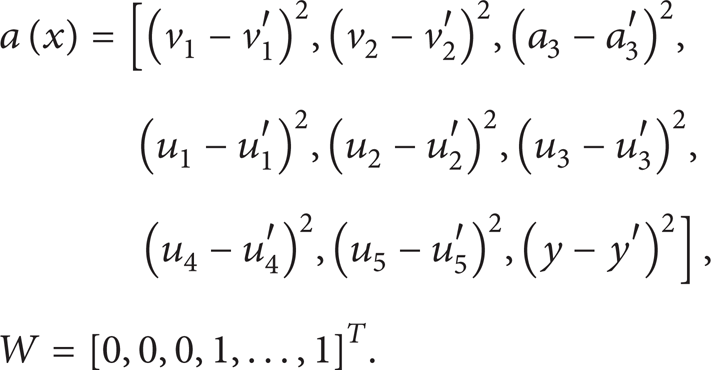
Then,

The error control function is

D2 = max(G(x)) = 0.
For P PY and C PY ,
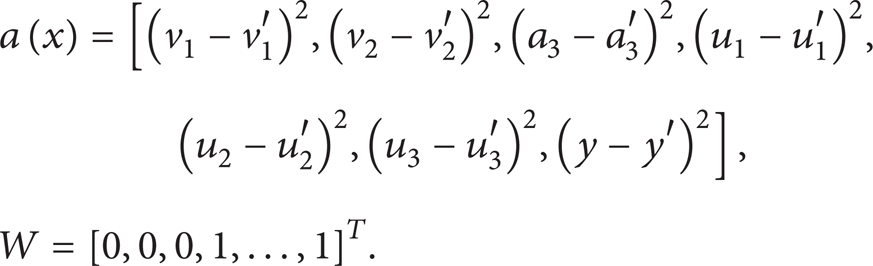
Then,
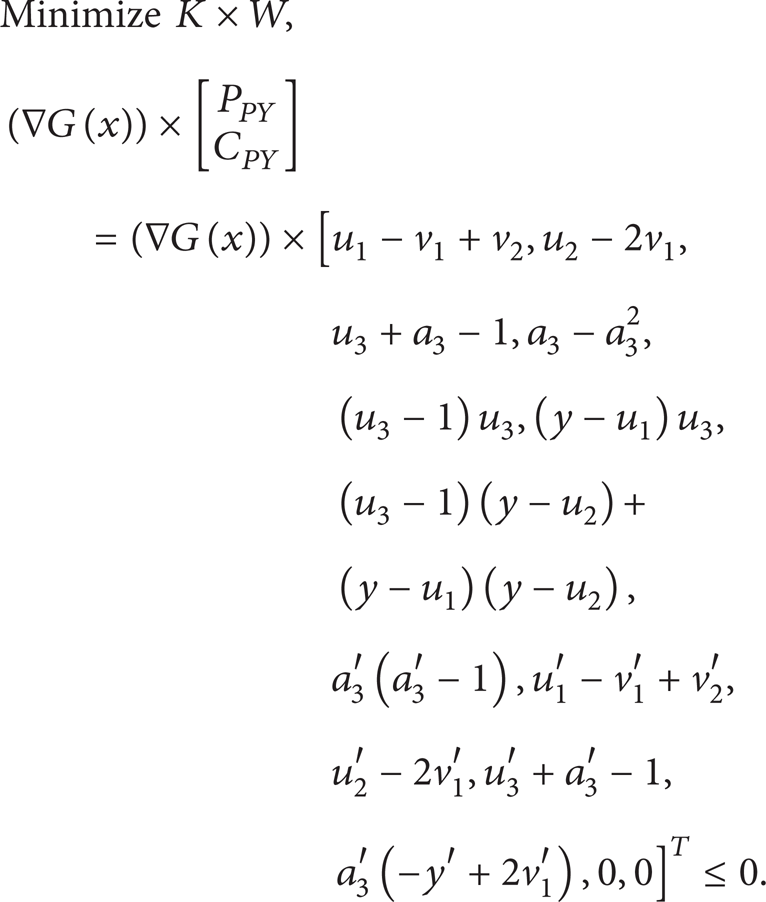
The error control function is

D3 = max(G(x)) ≈ 2.42e – 15. D = D1 + D2 + D3 ≈ 3.28e – 15 < 5e – 15; thus, C PB and C PY are approximate.
Therefore, we achieve two approximate systems C PB and C PY for PB and PY, respectively.
In Yang's paper, the equivalence verification for high-level datapaths is determined using the Groebner basis. The number of polynomials and the computing effort are given in Figure 14 when processing blocks 2, 3, and 4 for DP1 using the Groebner basis and the Ritt-Wu method.

Results.
Figure 14 illustrates that less computing effort is required with fewer polynomials. Ritt-Wu's method is better than the Groebner basis for the equivalence verification of datapaths. Because the Groebner basis is better than BMDs and ILP [12], our method is the best method among the methods considered for the equivalence verification process for circuits.
Furthermore, four results are achieved:
For P PB and C PB and P PY and C PY , their exact errors caused by ignoring initials are 0 and 2.42e – 15, respectively. Thus, our method is reasonable in that we consider initials as nondegeneracy conditions because their effects are always very small.
According to Ritt-Wu's method, C PB , C PY , and C PG are triangular sets; these sets are more standardized than P PB , P PY , and P PG . In this case, our method costs less in terms of computing effort when processing property verification is based on state because the systems are standardized first by a symbolic method.
The exact error can be calculated through the error control function. For example, when D(P PB , P PY ) ≈ 6.1e – 15 > δ, we get the approximate systems C PB and C PY for P PB and P PY with ignoring the initials of characteristic sets. The final error is 3.28e – 15, which meets the precision requirement. C PB and C PY cannot be changed into new datapaths, but they can be applied to optimize the property verification of circuits in the future, such as safety verification, because C is more standardized and its solutions is more than P.
With approximate bisimulation, block 4 can be removed in DP1′; thus, circuit optimization is achieved. Because the numbers of states and blocks are all reduced, the property verification based on the states can be optimized for the circuits.
7. Conclusion
In this paper, a new partitioning method is established to divide a type of high-level datapath in ITS into small blocks to reduce the computing efforts. Next, the datapaths are modeled by polynomial transition systems to provide a framework to research their behavior and structure. Then, an approximate bisimulation based on symbolic-numeric computation is proposed, which is used to obtain behavior and structure optimization for the datapaths. The result of the introduced example illustrates that the computing efforts caused by our new method are less than those of the Groebner basis, BMDs, and ILP in the equivalence verification process for circuits.
However, additional research on this topic is still required. Because some approximate polynomial systems cannot be turned into new datapaths, for example, C PB and C PY , we will investigate the readabilities for these approximate systems. At the same time, because the characteristic sets are more standardized than the original polynomial sets, they can be used to optimize the property verification for the circuits in ITS; this goal is briefly introduced in Section 4 and will be implemented in the future.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant no. 11371003, the Natural Science Foundation of Guangxi under Grants nos. 2011GXNSFA018154 and 2012GXNSFGA060003, the Science and Technology Foundation of Guangxi under Grant no. 10169-1, and the Scientific Research Project no. 201012MS274 from Guangxi Education Department.