
Abstract
It is of great significance to conduct researches on the message diffusion process for the node coverage problem, which can be generally abstracted as a random sampling model in the cooperative communication systems including the ad hoc and unstructured P2P networks. However, the message diffusion in the ad hoc network is not a completely independent random process. When forwarding the messages, the nodes will be influenced by such factors as degrees, visit times, and network connectivity. But the random sampling model does not take these factors into consideration, resulting in the overestimated node coverage degree. Discussing the message diffusion process of the cooperative communication systems like ad hoc network, this paper analyzes the causes of the inaccuracy problems of random sampling model and solves the problems by specially introducing the factors such as node degree and visit times. As for the E-R random network topology, it validates the effectiveness of the model proposed herein in contrast with the simulation experiment results. Compared with the random sampling model, the model proposed herein coincides better with the simulation results of the ad hoc network message diffusion process in the condition of network connectivity and its accuracy can meet the requirements for 3 and 5 visits.
1. Introduction
The nodes of ad hoc and unstructured P2P networks which are the autonomous, peer-to-peer, multihop systems need to forward messages from other nodes as well as their own messages to realize the resource sharing and cooperative communication. The searching and positioning of nodes and resources in the ad hoc network are completed by transmitting the search message within the network. Therefore, the research of message diffusion model plays an important role in the cooperative communication systems like ad hoc network [1]. Also in the social network, the message diffusion model can be used to analyze the transmission process of gossip messages by means of the social relationships of the crowd.
The main objective of analyzing the message diffusion model in the cooperative communication systems is generally to solve the problem of how many messages should be forwarded to reach the specific number of all the nodes or the specific number of messages which are given to confirm the ratio of nodes receiving the messages. In general, it is desperately expected to cover as many nodes as possible with few messages, which is the typical node coverage problem [2].
There are similar researches on node coverage conducting the keyword research through message diffusion in the unstructured P2P network [2, 3]. Although the distances of nodes in the physical networks are quite long, the specific overlay network topology can be built to achieve the link in logics to directly transmit the messages to the remote nodes to improve the efficiency of message diffusion. Take the small world network for instance; its topological structure is just between the regular network and the random network and is characterized by the small network diameter and high node aggregation, resulting in the fast speed of message transmission. Because the message diffusion process of unstructured P2P network is not limited by the physical distance, it is significant to analyze the effects of topological features of the coverage network on the efficiency and costs of message transmission to study the node coverage problems.
But in ad hoc network, the nodes can dynamically join and leave, and sometimes they even can be movable, just like in the vehicular ad hoc network and mobile sensor network; therefore, the topological structure of the whole network is dynamic and random. And the computing and storage capacity of ad hoc nodes are too weak to receive the whole topological structure and the distribution of other nodes and resources [4], let alone building the overlay network. In addition, the communication capability of ad hoc nodes is limited and they are incapable of remote communication. In this condition, the message diffusion process is limited by the physical distance, so the message can just be transmitted to as many nodes as possible through the neighbor nodes. During this process, response time and message overhead are taken into consideration from the perspective of system performance. Methods including flooding [5, 6], random walk [7–13], and multiple random walks [14, 15] can be adopted. The flooding model is fast but its message overhead is huge. The major methods, random walk and multiple random walks, show great performance in node coverage and message overhead, but their response speeds are low.
Generally speaking, when random walk is used in transmitted messages in the ad hoc network, the ultimate state of node coverage, if the number of nodes in the network is large, can be analyzed by the random sampling model including random pick [16, 17] and coupon collector's problem [18, 19]. But forwarding messages in the method of random walk or multiple random walks is not completely equal to “independent random sampling.” In fact, the forwarding of message is usually connected with the current node state: the probability of visiting a new node in the way of message forwarding is related to the unvisited nodes in the current network as well as the current state of the forwarding nodes. But the independent random sampling process will not take the latter into consideration; thus, when the node coverage rate at a certain time point is analyzed, the estimated value may be high.
This paper makes use of node degree and visit times to solve the problems existing in the random sampling model. The simulation experiment results show that the message diffusion model proposed herein of ad hoc network is in accordance with the reality in the condition of high node coverage.
Section 2 discusses the current problems of the random sample model. Focusing on the node coverage in the message diffusion process, Section 3, based on the normal model, explores the effects of node degree and visit times to obtain the model proposed herein. Validating the effectiveness of that model through simulation experiments, Section 4 studies the identical degrees of the theoretical values and the simulation experiment results in the networks of different scales and node degrees. Section 5 makes the conclusion.
2. Random Sampling and Its Shortcomings
At present, the random walk and multiple random walks are two major methods in the research of the cooperative communication networks like ad hoc network. Both methods assume that nodes take the paths different from the message receiving paths to forward messages and messages randomly picked from all the paths (but for the coming paths) to leave the nodes. The only difference between them is that the multiple random walks have multiple paths for messages to leave. In addition to this, there is no essential difference. When the number of nodes is large enough in the network, the limit of node coverage can be analyzed by the random pick [16, 17] and coupon collector's problem [18, 19]. Node coverage herein refers to the rate of nodes reached by the messages in the network.
2.1. Random Pick Model
Random pick model can be generally described as follows: there are n balls in the box and one ball will be taken out and then returned to the box at a time. After x times, will u balls be taken out without repetition? The general result of this question [16, 17]: in the initial condition of
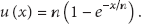

2.2. Coupon Collector's Problem
Coupon collector's problem is another typical random sampling process [19], which can be generally described as follows: if there are n kinds of coupon and each kind of coupon has an equal chance to be taken out, the x times will be needed to collect u kinds of coupon on condition that one coupon will be taken out at a time.
As we all know, x, number of times to collect n kinds of coupon, is the function equation of n:





2.3. Problems of Random Sampling Model
This shows that the limit of node coverage can be quantitatively analyzed by random sampling models including random pick model and coupon collector's problem if there are numerous nodes in the ad hoc network (
Random sampling model is a limit model instead of a process description model, which is the first problem we may encounter in the analysis process of ad hoc network node coverage. Moreover, the node coverage of ad hoc network will change in the message diffusion process. This message diffusion process is not a completely independent random process, so nodes, when forwarding the messages, will be influenced by node degree and network connectivity. The probability of forwarding the messages to the new nodes will depend on the undiscovered nodes in the network as well as the current state of the forwarding node. However, random sampling model just assumes that these two samplings are independently random, without taking into consideration the probability that the current nodes may have been visited for many times. As a result, the estimated value may be high if the random sampling model is used to estimate the ad hoc network node coverage at a certain time point.
3. Improved Ad Hoc Message Diffusion Model Based on Visit Times
When analyzing the node coverage process of cooperative communication systems like ad hoc network, the random sampling model does not take the current node state into consideration; in order to solve this problem, this paper introduces the factors such as node degree and visit times. First, presenting a general algebraic model to conduct the quantitative analysis on the node coverage of ad hoc network message transmission, this part analyzes the effects of node degree and visit times on the node coverage to propose the modified model herein.
3.1. General Algebraic Model
Suppose that ad hoc network topology is in compliance with E-R random model [20], as shown in
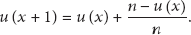



3.2. Parameter Modification
General algebraic model can conduct quantitative analysis on the node coverage at a certain time point in the message forwarding process of cooperative communication systems like ad hoc network. But it does not consider the node degree, resulting in the overestimated value of node coverage. The general algebraic model assumes that, with x messages having been transmitted to u nodes, the probability of message transmitted to new nodes, according to (8), equals the ratio of the number of unvisited nodes and the total number of nodes, that is,
So the probability of the message forwarded to new nodes is related to the current node degree. When the message visits the node again, the higher the node degree, the higher the probability that the message forwarded through unvisited links, and finally the probability of reaching new nodes will be close to the probability of the unvisited nodes in the network, that is,
This paper changes (8): if x messages are forwarded to u nodes, the probability that the messages forwarded to new nodes through unvisited links will be
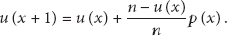
Before presenting the computing method of d: node degree;
As a result, the computing equation of

3.3. Effects of Visit Times
From (13), we may find it is necessary to define 2 parameters to calculate the value of
(1) Probability of Nodes Visited for Multiple Times. If u nodes are covered after x messages are forwarded, then the probability of any node i visited for j times is
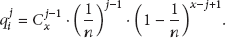
(2) Probability That There Are Unvisited Links after the Nodes That Have Been Visited for Multiple Times. It is necessary to consider multiple conditions of visit times j to calculate the probability of unvisited links after the nodes that have been visited for multiple times

Effects of visit times on the old and new states of node link.
(i)
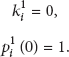

The node state changes to state b, shown in Figure 1(b), and the number of visited links is 2, which means that the message takes 2 different links to reach and leave the node. Because of the only state to transfer the path, after the first visit of the node, the probability that the number of visited links changes from 0 to 2 is

(ii)
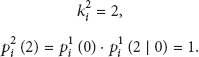
At this time, the node randomly picks one link to forward the message which can only take the left

After the message leaves the node again, its link state will change to the third condition in Figure 1(c, (
(a)
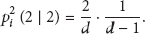
(b)

(c)
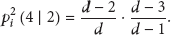
(iii)

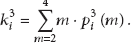

After the message leaves the node thirdly, the node state will change from state

(iv)
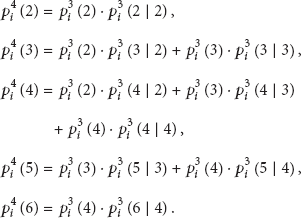




(iv)


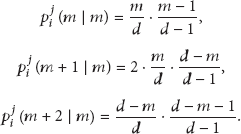
3.4. Message Diffusion Model Based on Visit Times
According to Sections 3.2 and 3.3, integrate (12), (13), (14), and (33) to obtain the improved model herein:

Different from the general algebraic model shown in (8), this modified model, when forwarding messages, considers the effects of the current state of node, namely, the visit times of the nodes, on the forwarding probability in the next step. In some extreme conditions, all the links of the current node are visited, so no unvisited link will be reached in the next step. However, in the random pick or coupon collector's problem, every pick of link is independent, not considering the node state. So this modified model will more accurately describe ad hoc network message diffusion process, especially when the node coverage is high.
4. Experiment and Analysis
4.1. Experimental Environment and Parameter Setting
To validate the ability of this model proposed herein to describe the message diffusion process of ad hoc network, this paper compares the theoretical value of quantitative analysis and the results of simulation experiments to test the deviation. Before presenting the specific experimental results and analyses, it defines the determination processes of simulation experiment environment and parameters.
(1) Experimental Environment. Focusing on the problems of random sampling model in the process of describing the message transmission of ad hoc network, this paper proposes the factors like node degree and visit times for improvement. In order to verify the improved results, it calculates the quantitative analysis results of random sampling model and the model proposed herein in different parameters in Matlab 7.12. Coupon collector's problem of the sufficient sampling space n and u is equal to the random pick model; therefore, this paper takes the theoretical value of coupon collector's problem for analysis.
Both coupon collector's problem and random pick model present the theoretical calculation results, so this paper, based on NS-2 V2.29 network simulation platform, simulates the message diffusion process of ad hoc network. To simulate the ad hoc network of different scales, n, the node number in the network, is set as 1000, 2000, and 3000 and the network topology is in compliance with E-R random graph model [20]. This paper emphasizes the message diffusion process, so the simulation does not consider the delay and packet loss and each message data packet is 1 Byte. When the experiment starts, one node is randomly selected from n nodes as the message source and transmits the message to other nodes. All the nodes that receive the message will forward the message again at the same time slot and the experiment ends when the message has been forwarded for
(2) Node Visit Times— j . As shown in (35), this modified model proposes 2 key parameters
According to (14), in the network of n nodes, if x messages are forwarded and cover u nodes, which means the node coverage is

Relationship between node visit times j and node coverage
We can see that most nodes have been visited for only 1-2 times in the condition of low node coverage
(3) Node Degree— d. As mentioned in Section 3.1, this paper assumes that the ad hoc network topology is in compliance with E-R random model; as
According to the nature of E-R random model [20],
if if if
In consequence, the node number n and node link probability p of the ad hoc network must satisfy the condition

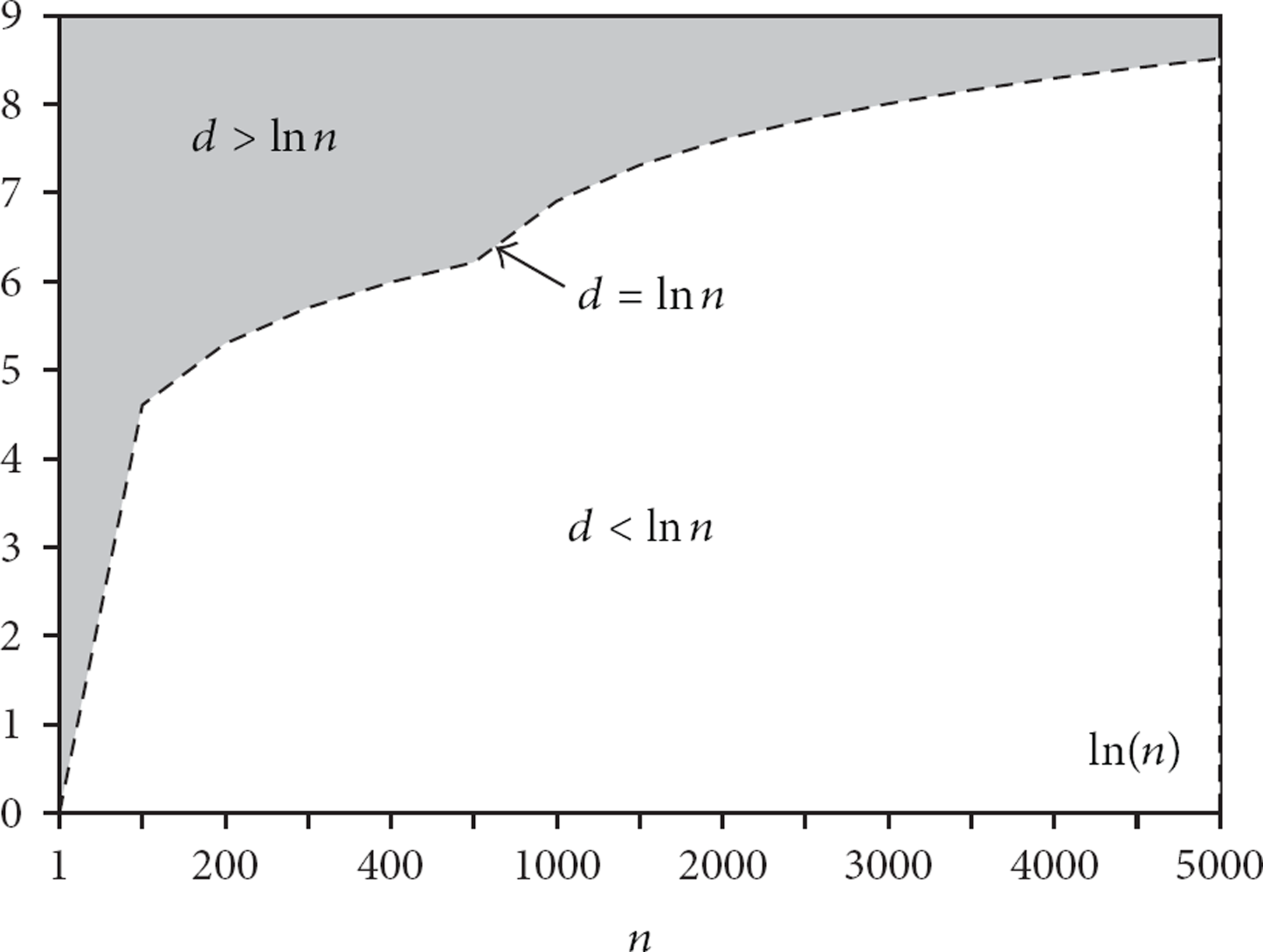
Relationship between
4.2. Results and Comparison
Figures 4(a)–4(c) show the message diffusion simulation experiment results in the conditions of
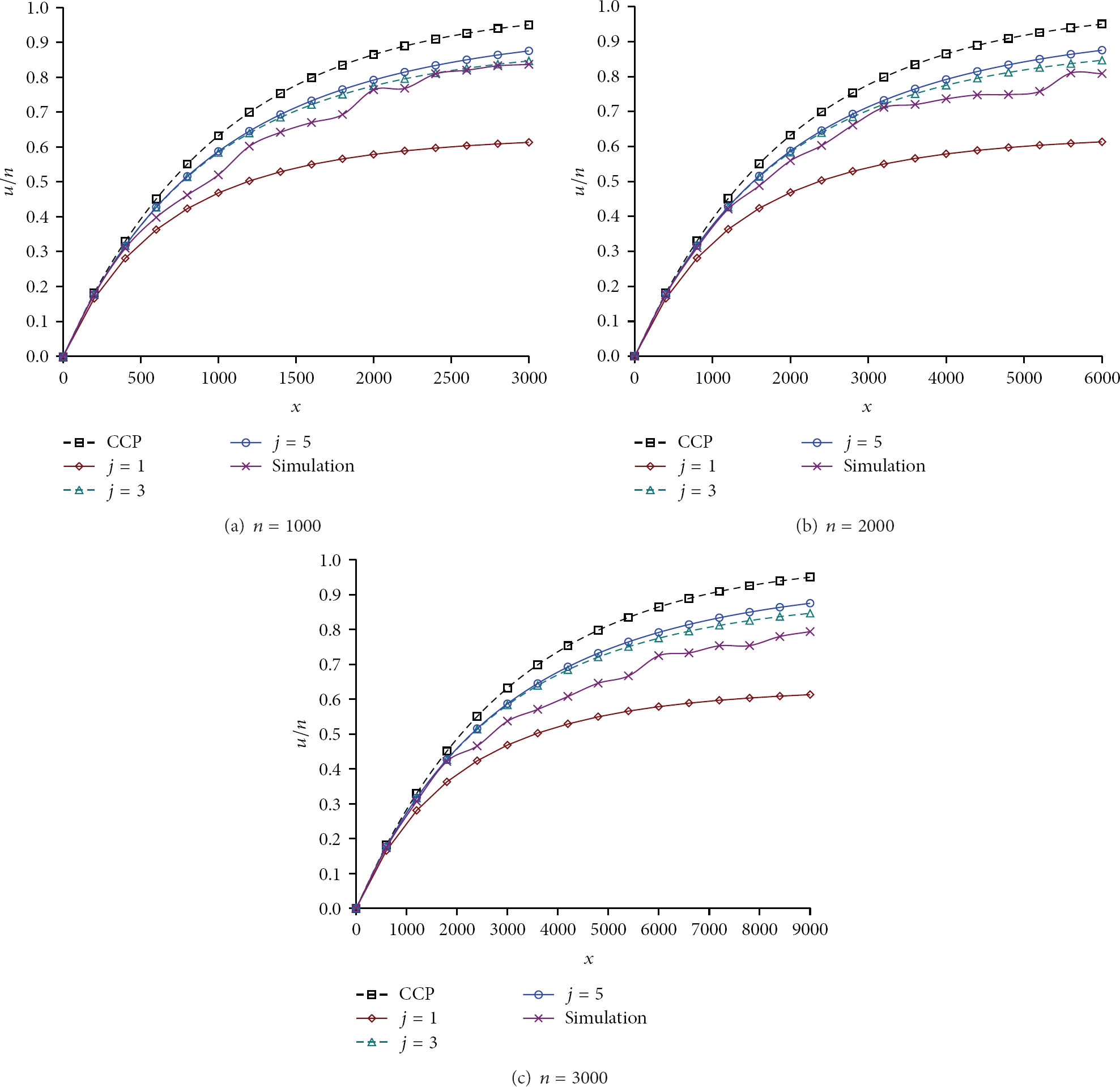
Comparison between the theoretical values and simulation results of message transmission of ad hoc network of different scales
x-axis represents x: the total number of messages forwarded as the simulation experiment continues, and y-axis represents
From Figures 4(a)–4(c), we may find that, random sampling model taking coupon collector's problem as representative will overestimate the node coverage in any conditions. When node visit number equals 1
In addition, in Figures 4(a)–4(c), the deviations of the simulation experiment results and the theoretical results of
According to the analysis of Section 4.1, to ensure the link of the experimental network topology, d, the average node degree, must satisfy the requirement of

Comparison between the theoretical values and simulation results of message transmission of ad hoc network of different scales
Also from Figures 5(a)–5(c), we may see that the random sampling model overestimates the node coverage in any case. If j equals 1, the proposed model will underestimate the node coverage. Compared with Figure 4, Figure 5 shows a small deviation with no problems of Figure 4(c). This means that, in the research process of ad hoc network message diffusion, our model, taking the node visit times and node degree into consideration, is more modified than the random sampling model in the condition of network connectivity; compared with the random sampling model, the result is closer to the real result with sufficient accuracy.
5. Conclusion
In the cooperative communication systems like ad hoc network or the unstructured P2P network, the message diffusion process can be abstracted as the random sampling model. But message diffusion process is not a completely independent random process; nodes, when forwarding the messages, will be influenced by node degree and network connectivity. However, the random sampling model does not take into consideration the condition that the current node may have been visited for times. So the estimated value may be high if the random sampling model is used to estimate the ad hoc network node coverage at a certain time point. With the increase of node coverage and message number, the random sampling is no longer an accurate model.
Exploring the message diffusion process of cooperative communication systems like ad hoc, this paper analyzes the causes of the inaccuracy of random sampling model and specifically introduces factors like node degree and visit times to solve the problem. It validates the effectiveness of the model proposed herein by comparing its results with the simulation experiment results. Our results are just from random graph network model, while, in the practical application, the general network structure is similar to the “small world” network and power law network. The quantitative analysis of message diffusion in this network topology is still a challenge, which will be the focus of our research in the future.
Footnotes
Acknowledgments
The work is supported in part by the National Science Foundation of China under Grant nos. 61070169 and 61070170, the Natural Science Foundation of Jiangsu under Grant no. BK2011376, the University Science Research Project of Jiangsu Province under Grant no. 11KJB520017, and the Application Foundation Research of Suzhou of China under Grant nos. SYG201118 and SYG201238.