
Abstract
Neighbor discovery for moving individual is considered an important technology submitting to location-based service (LBS), which includes such things as recruitment flow of information, logical localization, and health monitoring. Based on the tradeoff between universality and accuracy of neighbor discovery, we propose the environmental characteristics participatory extraction method benefiting to mobile individual discovery. First, we fuse lightweight accelerometer, light sensors, and microphone collaboratively. Furthermore, support vector machine (SVM), Tanimoto coefficient, and Manhattan distance are used to calculate three kinds of fingerprint similarity, respectively, and then the principal component analysis based method reduces data dimension in order to obtain neighbor similarity rank. Finally, the experiment data are collected by 25 volunteers, and trace-driven simulations show that Euclidean distance error is below 4.69 and the convergence time is within 0.75 s.
1. Introduction
The proliferation of mobile devices and wireless has fostered the demand of context aware application, in which localization and emergency navigation are emerging applications with significant research and social values [1–3], at the same time, vehicular ad hoc networks (VANETs) have recently reemerged as one of promising research areas for safety and connectivity in road networks [4]. Urban sensing, participatory sensing, and moving individual clustering can provide rich contextual information for mobile applications such as social networking and location-based services (LBS) [5]. Moving individual neighbor discovery has thus become one of the key factors in mobile service quality. Among existing LBS technologies, combining radio frequency (RF) fingerprinting, based on Wi-Fi or cellular signals, with the inertial sensors (e.g., accelerometer, compass, and gyroscope) featured in smartphones has received great attention [1, 4, 6–9]. Sensors embedded in smartphones can detect and gather information regarding location, acceleration, orientation, rotation angle, and so forth. Some applications plan to share this information in online social networks by recording users' behavior characteristics and the dynamics of everyday activities (such as commuting) and enabling search services associated with the users' physical environment. Mobile services closed to moving individual neighbor discovery include mobility-based recruitment, logical localization, and environment detection.
Based on some shortcomings and insufficiency of existing methods, we propose the environmental characteristics participatory extraction method for moving individual neighbor discovery by means of a smartphone based lightweight sensors. Smartphone has 3-axis accelerometer, light sensor, and microphone commonly, keeping open, which are participated by users passively. At the same time, users are willing to provide fingerprint characteristics on the premise of not revealing their privacy. We fuse lightweight accelerometer, light sensors and microphone collaboratively. We use support vector machine (SVM), Tanimoto coefficient, and Manhattan distance to calculate three kinds of fingerprint similarity, respectively, and then the principal component analysis is used to reduce data dimension in order to obtain neighbor similarity rank, and the experiment data is collected by 25 volunteers to test the moving individual neighbor discovery method.
As a basic component which might be frequently invoked by LBS on energy-constrained mobile phones, it needs to meet several stringent design requirements.
High Accuracy. As a generic framework that many other applications would potentially rely on, it should accurately detect the neighbor similarity.
Real-Time. Mobile individual should receive neighbor similarity response promptly. An outdated detection result may be less valuable for many instantaneous applications.
Universality. It should avoid relying on an a priori knowledge or site survey, special sensors, or explicit user feedback to ensure wide applicability.
In this paper, we address these requirements by means of leveraging participatory extractive to mobility sensing. Our contributions can be summarized as follows. First, the proposed method uses the commercial inertial sensors on the smartphone to extractive ambiance information without any label. Second, we design an iterative neighbor similarity algorithm which considers behavior similarity, spatial-temporal similarity, and background similarity. Third, we introduce the principal component analysis to excavate the critical factor evaluating the neighbor similarity rank. Finally, we recruit 25 volunteers to construct a crowded scenario, and trace-driven simulations demonstrate that Euclidean distance error is below 4.69 and the convergence time is within 0.75 s.
The remainder of the paper is organized as follows. The related work is introduced in Section 2. The problem description of moving individual neighbor discovery is discussed in Section 3. Section 4 details the system design process and fingerprint similarity measure and integration approach. The evaluation and performance results are described in Section 5. Some problems are discussed in Section 6. Section 7 concludes the paper.
2. Related Work
Improving accuracy and latency of neighbor discovery is a long-standing problem in ad hoc network (e.g., sensor network, social network, and delay-tolerant network) and has been approached from different directions. Techniques range from protocol optimizations for data collection in sensor network [10] or Wi-Fi access point scanning in wireless network [11] to techniques that leverage multiple built-in sensors on commercial smartphone [12–14] to classify the people activities.
Since most smartphones come with both Bluetooth and Wi-Fi and most current proximity-based applications need proximity detection to the cheaper Bluetooth radio, Searchlight [10] proposes an asynchronous discovery protocol based on periodic awake slots of probing. Since Searchlight employs a random component to shift each awake time, it will run hard when the service starts. ZiFi [11] utilizes ZigBee radios to identify the existence of Wi-Fi networks through unique interference signatures generated by Wi-Fi beacons. However, ZigBee infrastructure is an extra input with nonignorable overhead.
Extensive work have taken advantage of smartphones built-in GPS, GSM, and inertial sensors to sense contextual information, detecting people's daily behaviors, and achieving logical localization that provides real-time services for people living and working. TagSense [15] have introduced a smartphone-based approach to automatic image tagging system, IODetector [16] uses light sensors, magnetic sensors, and cellular network sensed signal to detect indoor/outdoor environment. However, all these belong to static recognition, without considering that we could make use of environmental characteristics participatory extraction to track moving individual and find its neighbors.
Collecting and mapping the Wi-Fi access points or GSM base stations named war-driving have been deployed in prior work. War-driving requires cost massive money and time. Moreover, war-driving data easily become unreliable and outdated over time.
3. Problem Description
The tracking of individual movement plays an important role in human's health and daily life, especially the terrorists, people living with virus, and real-time tracking of bus in intelligent transportation. An example scenario is shown in Figure 1; the super user as shown in the pentagram is called target and moves forward along the purple route on the important traffic road, and the target meets with the standing, the walking, the running, the cycling, or the motoring at different times via Bluetooth. As a fastest growing LBS service, he wants to invite some people to participate the mobile gaming for waiting vehicle or digging same flavor person nearby for appropriate food.

Example scenario.
Bluetooth does not need to anchor and fingerprint database comparing with global positioning system (GPS), GSM. Compared with Wi-Fi, using Bluetooth has several advantages. First, although lots of mobile devices are equipped with Wi-Fi modules nowadays, its popularity is still far beneath that of Bluetooth. Currently, there are total 3 billion Bluetooth devices in the market. Nearly 80% mobile phones and close to 100% of the smart phones are equipped with Bluetooth devices. Furthermore, Wi-Fi devices consume much more energy than that of Bluetooth. The energy consumed by Wi-Fi devices in idle status is 76 times more than that of Bluetooth in the same status [17]. Moreover, even the energy consumed by Wi-Fi devices in idle status is 5 times more than that of Bluetooth devices in scanning status which is the most energy-consuming part for Bluetooth devices. Bluetooth does not need to pay fees; the device name changes infrequently as well as finding surrounding equipment is default and does not need to establish and keep connection [18]. For the devices carried by mobile users, which is energy sensitive, energy-efficient Bluetooth is obviously a better option. Figure 2 shows the energy consumption, respectively, corresponding to different statuses in Table 1. Behavior, light, and background audio fingerprint are collected by means of a smartphone based lightweight sensors, which are upload to a central server at the same time; then the server merges and calculates similarity with the target ones, so as to realize neighbor discovery of moving individual.
Bluetooth time consumption versus status.


Bluetooth power versus status.
Before we present the design of moving individual neighbor discovery in detail, we formally define the relevant conception studied in this paper. There are the stationary, walking, cycling, running, and motoring, which are indicated by clusters
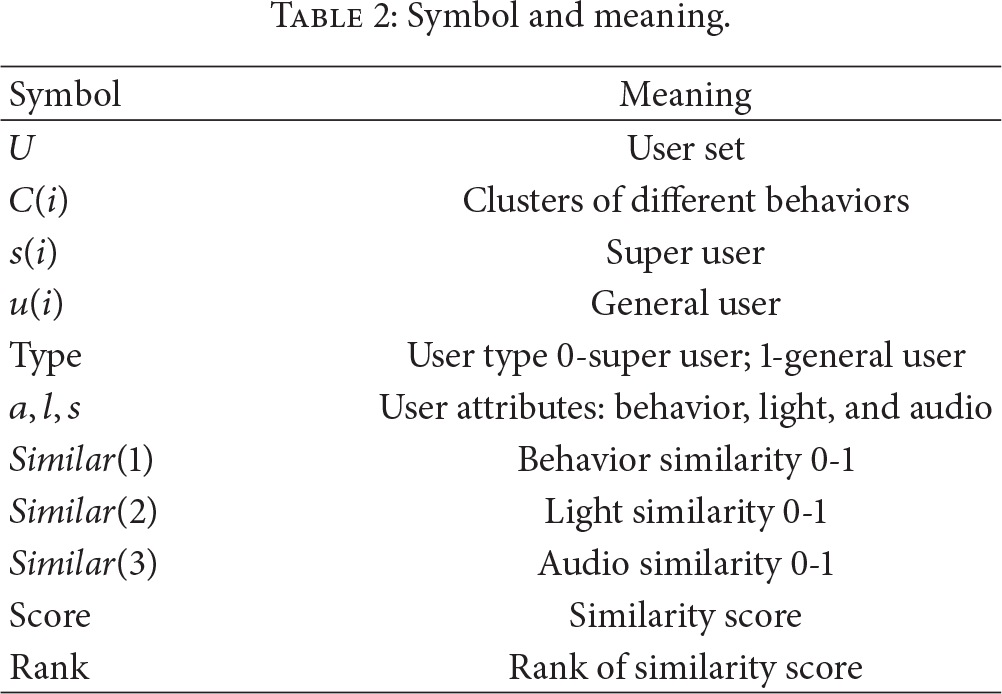
Symbol and meaning.
Input: User set U Output: score, rank (1) Judge the number of super user user in set U; (2) Determine the super user belongs to which kinds of movement behavior (3) According to the step (4)–(6) cluster the super user one by one; (4) To extract behavior, light audio fingerprint of general users; (5) Calculate behavior, light and audio similarity; (6) Data dimension reduction by means of principal component analysis method, get integrated similarity score and rank; (7) Repeat step (4)–(6) until neighbors of all the super user are sorted.

Scene. (a) Model and (b) neighbor ambiguity.
Definition 1.
Neighbor ambiguity is shown in Figure 3(b) in
Definition 2.
The person who gets the highest score in principal component analysis method is called optimal neighbor.
4. Moving Individual Neighbor Discovery
In this section, we first introduce the system architecture and the design details for each component. Then we specify how to aggregate the outputs obtained from each component and generate a final decision, which is provided to upper layer applications through a service interface.
4.1. Multidimensional Sensing Data Extraction
Figure 4 illustrates the system architecture of moving individual neighbor discovery. To meet stringent design requirements, it utilizes a series of lightweight sensors for the neighbor discovery. It primarily makes use of three types of lightweight detectors: behavior detector, light detector, and audio detector. Behavior detector uses accelerometer to collect behavior data. To meet real-time, we adopt SVM to detect behavior, based on the tradeoff between precision and convergence speed, this paper experiments with the appointed and random training set, the search, and empirical parameters. Light detector adopts light sensors to sense ambient light signals. It also utilizes other two lightweight sensors, the proximity sensor and the system time clock, to assist the detection. Audio detector captures ambient audio signals to determine the surrounding environment type. In the rest of this section, we will describe the design details of each component.
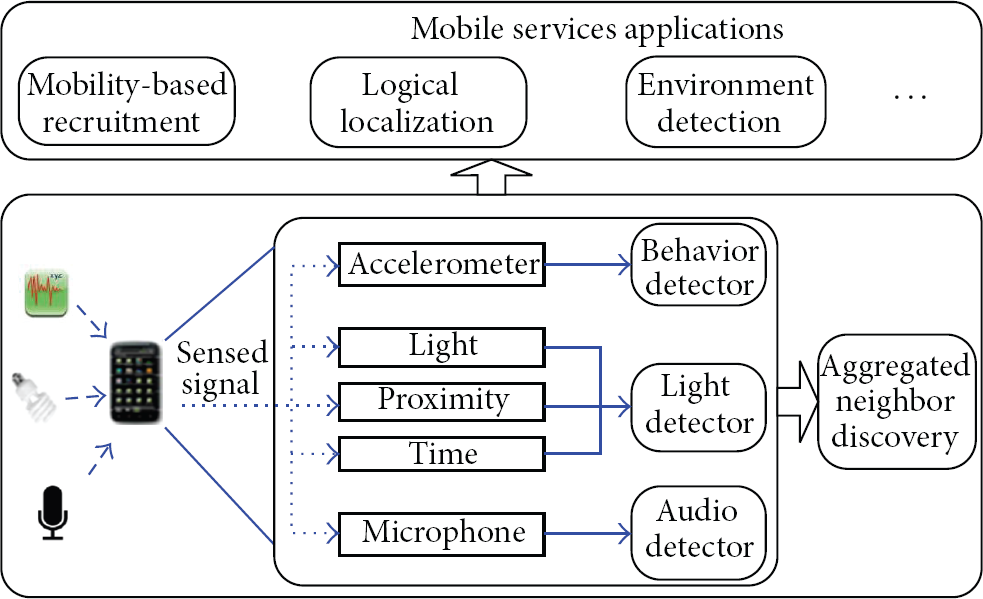
Moving individual neighbor discovery system architecture.
4.2. Moving Environment Characteristics Determination
4.2.1. Moving Individual Behavior
Selection of sensor which senses individual behavior has a great impact on energy consumption and recognition accuracy of smartphones in behavior detector. Bluetooth sensors are not ubiquitous in outdoor settings. Static Bluetooth beacons mainly exist in indoor settings. Relying on Bluetooth signals exhibited by mobile phones has its own problems. For instance, it is difficult to distinguish whether an individual is moving or if the environment around them is changing (other people carrying devices are moving). Hence, Bluetooth does not provide the accuracy needed for the modes being distinguished [19]. In terms of GSM and Wi-Fi, these features act as a proxy for the speed of an individual, and when speed is similar, as is the case with slow moving traffic, biking, and walking, these features are not as discriminative, and they depend on the density of network end points (cell towers and access points). Accurate human behavior recognition, supporting both indoor (underground) and outdoor mobility [20], is best provided by a combination of GPS (for computing velocity), Wi-Fi localization (for detecting location changes where GPS is unavailable), and accelerometer (for detecting movements directly). However, constantly sampling these sensors will quickly drain the batteries of even the latest generation of smartphones. Thus, for smartphone applications, power efficiency is of great concern, so behavior recognition must be designed to expend as little energy as possible. At the same time, we need to propose a solution that does not depend on the hardware facilities to improve scalability. This paper proposes that we use low-power accelerometer to collect data and detect moving individual behavior.
This paper divides outdoor user behaviors into five categories: stationary, walking, running, cycling, and motoring, which is a multipattern recognition problem actually. SVM and neural networks can be used for pattern recognition. Compared with neural networks, SVM solves the high-dimensional data model construction problems more effectively under the limited sample condition, and it has some advantages including generalization ability, converging to global optimum, and dimension insensitivity. Compared with traditional method, SVM has obvious advantages, and the idea of optimal separating hyperplane can improve the classification accuracy, which is a convex quadratic programming problem, avoiding local optima and introducing kernel function theory, and overcoming the “curse of dimensionality” problem. So we choose SVM to recognize human behavior.
The basic idea of SVM is to construct an optimal classification function for two types of problems, to make them separate without error, keeping maximum interval between them. We use Lagrange to solve the quadratic programming problem. Only a few Lagrange multipliers are not equal to zero in the solution; the corresponding sample is support vector. Finally we achieve classification of entire acceleration data set by training support vectors.
For linearly separable classification problems, the decision function is as follows:
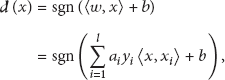
For linearly inseparable classification problems, we adopt Kernel function theory which can covert low-dimensional linearly inseparable into high-dimensional space linearly separable. We use inner product kernel function 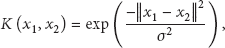
In this experiment, the precision is seen as behavior similarity between general and super user Similar(1). The selection of training set and parameters mainly depend on the experience and experimentation, and we need to find a unified guidance method in order to shorten training time and achieve higher accuracy. This paper experiments with the appointed and random training set, the search, and empirical parameters as described in Section 5.
4.2.2. Space-Time Characteristics
Light detector adopts light sensors to capture ambient light signals. It also utilizes other two lightweight sensors, the proximity sensor and the system time clock, to assist the detection. Common similarity measure methods include Tanimoto coefficient [9] and cosine similarity. Tanimoto coefficient is also called generalized Jaccard coefficient, is an extension of cosine similarity, at the same time, and is widely used to calculate document data similarity. It requires less shared items than cosine similarity. So we use Tanimoto coefficient to measure the similarity Similar(2) as show in (3), here the light intensity is converted to vector space. Besides, super user could detect many general ones, calculating similarity, respectively:
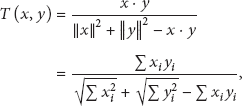
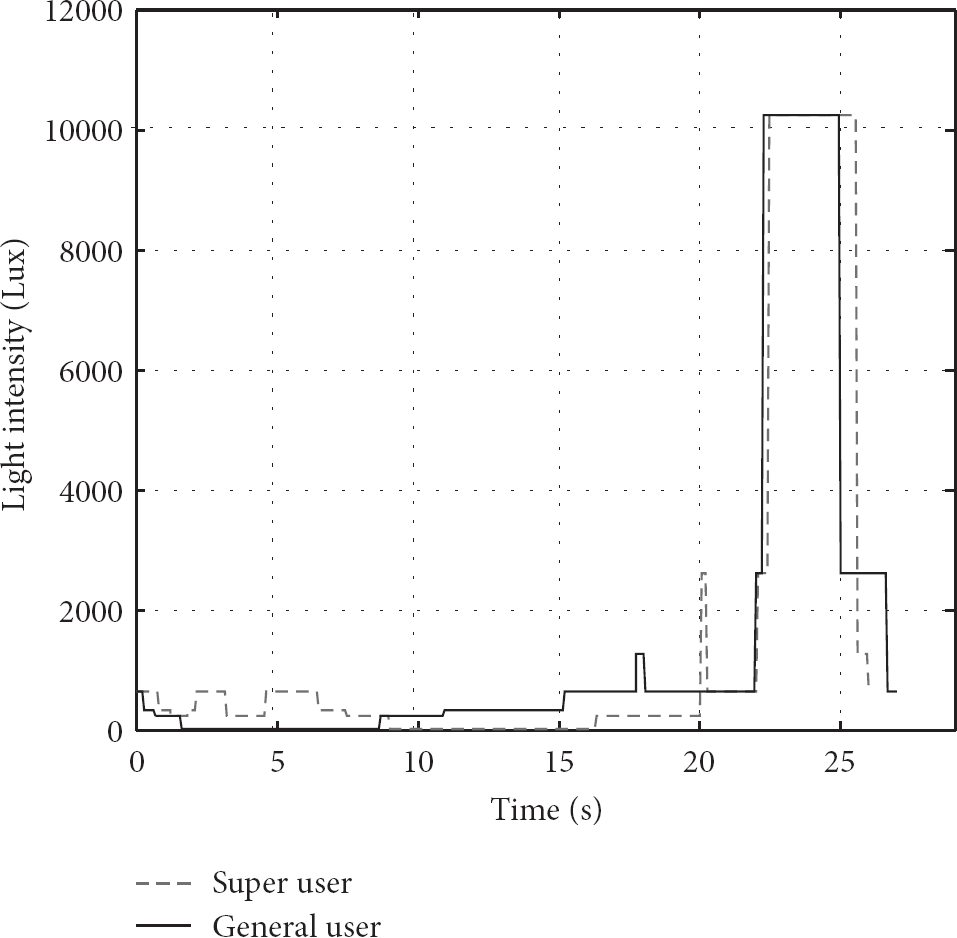
Light fingerprint.
4.2.3. Background Sound
We have detected behavior and light similarity, while the ambient sound in a place can be suggestive of the type of place [14]. Some places play loud music in the background versus others that are quieter. We recorded the ambient sound of 3 types of place using the phone microphone. Sample frequency is set to 20 Hz. First, we try to distinguish the type of environment by comparing probability density function or box plot of audio signal, as shown in Figures 6 and 7; however, both speech and noise have overlapping part (as shown in dotted box). Then we have observed that signal energy under different sample windows presents a clear step, as shown in Figure 8, so we uses Manhattan distance of audio signal energy to distinguish different environments. Note that the energy E of a time domain signal 

Probability density function of audio signal.

Box plot of audio signal.

Audio signal energy versus sample window (Si: silent; Sp: speech; No: noise).
Manhattan distance is mostly used for space distance measure of multidimensional data. Manhattan distance between two n-dimensional vectors 
4.3. Moving Individual Fingerprint Similarity
We have obtained fingerprint similarity between target and neighbors through the above three kinds of detector. Further we need to put into three kinds of fingerprint similarity to a new integrated similarity variable. Usually, samples are mapped from input space to a low-dimensional space by linear or nonlinear transformation in order to gain a compact low-dimensional representation of original data set. According to the problem characters, this paper adopts principal component analysis method for data dimension reduction.
The mathematical model of principal component analysis is as follows:
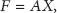

The proposed model needs to satisfy the following conditions:
the variance of
Through data dimension reduction, 3-dimensional fingerprint similarity X is represented by the principal component
Figure 9(a) introduces fingerprint similarity distribution box plot. Pareto chart in Figure 9(b) shows variance contribution rates of principal component, with a rectangular coordinate system. The left ordinate indicates frequency number, the right indicates frequency, the analysis line represents cumulative frequency, and horizontal axis indicates influence factors of similarity, according to the influence degree (occurrence frequency) arranged from left to right. Principal component comprehensive score and rank are shown in Figure 10.

PCA principal component analysis. (a) Box plot of variable distribution and (b) Pareto chart.

Score and rank of PCA.
5. Evaluation
We implement and evaluate a prototype system on the Android platform with three different types of mobile phones (Samsung Galaxy S2 i9100, HUAWEI T8828, and HTC Sensation G14) to collect behavior, light, and audio signal. Instructions were given as to the duration of each activity, and 25 volunteers were advised to perform each behavior, including stationary, walking, running, cycling, and motoring. The volunteers concentrated on one transportation mode at a time and performed all five consecutively during their data collection session. The total amount of data collected across all 25 individuals was 125 hours, comprised of 1 hour of data per behavior. The results of the assessment focus on three factors: (1) to do in-depth analysis for training set and parameters selection of behavior detection; (2) to compare similarity sorting error for different numbers of general user and analyze precision, universality, and scalability of neighbor discovery; (3) the running cost of moving individuals neighbor discovery.
5.1. Training Set and Parameters Selection
Training set and parameters selection of behavior detection have an important effect on precision and convergence speed, and this paper adopts combination of the appointed, random training set and empirical, search parameter. Then we calculate average precision and convergence time of 20 groups experiments, as shown in Figure 11. Although the method of parameters optimization can improve the precision, the convergence time is exponential growing, based on the balance between precision and convergence time. We use the combination of appointed training set empirical parameters.
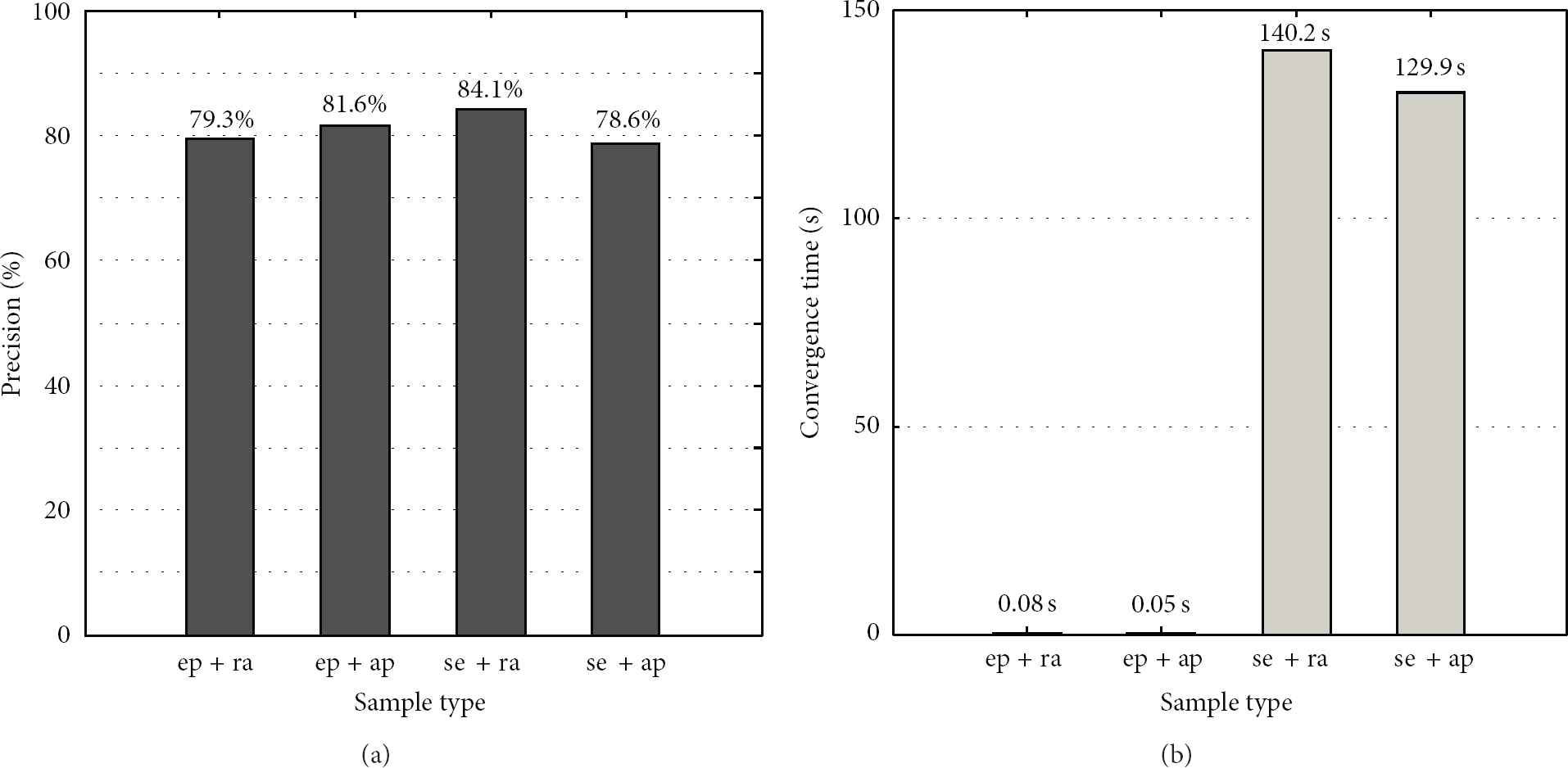
Precision of behavior recognition and convergence time (ep: empirical parameter, se: search parameter, ra: random training set, and ap: appointed training set). (a) Precision; (b) convergence time.
5.2. Number of User Impact
We evaluate precision and scalability of moving individual neighbor discovery by Euclidean distance error of similarity sorting. Five groups of experiments, respectively, include similar points 5, 10, 15, 20, and 25. The result compared with the real similarity sorting is shown in Figure 12. Euclidean distance error is maximum, only 4.69 when the similar points is 25, while it is minimum, only 2, when similar points is 5. Figure 13 shows the real and measuring comparison when similar points is 20; therefore, number of users has little impact on experiment.

Euclidean distance error versus number of similarity.

Comparison between measurement and true value.
Besides behavior, light and sound information has been considered in this paper. There are many other properties, such as wear, hobbies, weather, and building materials. About scalability of user attributes, multidimensional data can achieve data dimensionality reduction through principal component analysis method. Experiments are implemented on three different types of mobile phones built-in ubiquitous sensors, without prior knowledge, site survey, and explicit feedback, which satisfy universality.
5.3. Running Cost
Finally we evaluate time overhead for moving individual neighbor discovery. The behavior, light, and sound detection and principal component analysis conduct 20 groups of experiments, respectively. Figure 14 introduces time consumption comparison of three components and principal component analysis. The results show that each component consumes time that is all below 0.2 s, and dimension reduction is basically all within 0.3 s; only the first experiment data needs to be trained, as you can see it consumes longer time, but also under 0.45 s, and the total elapsed time is under 0.75 s. From the above experimental analysis, we can see that our method satisfies real-time.

Convergence time of moving individual neighbor discovery.
6. Discussion
According to different living habits and customs, the users may place their phones differently such as in hand, in pocket, in purse, or in a backpack, which causes the inertial deviation for behavior analysis. When we collect light and audio fingerprint, we must ensure that the light sensor and the microphone are effective, so in this context, we do not need to consider that the positions of smartphones have an impact on behavior detection.
Once the number of super user increases, we need to judge all super users belonging to certain clusters again, so that computational complexity is greatly increasing. In further work, we consider that at the first time, we judge whether the new super user belongs to the same cluster with the original one, if they belong to the same cluster, so no need to redefine, while we can also increase the super user agency, partly clustering, in order to reduce computational complexity, so as to achieve the purpose of providing services to each other.
7. Conclusion
We present the design and implementation of a moving individual neighbor discovery system, which efficiently takes input from accelerometer, light, and microphone to derive the neighbor discovery information. We use the appropriate similarity measure and principal component analysis method to calculate and integrate similarity information. Experimental results prove the validity of this method. Our method cannot only be used in services recommendation applications, recommending the same types of services to community groups, for example, a gym push fitness programs for persons who do exercises regularity. The experiment data was collected from 25 volunteers, and the results show that Euclidean distance error is below 4.69 and the convergence time is within 0.75 s.
Footnotes
Acknowledgments
This research is supported in part by National Natural Science Foundation of China under Grant nos. 61303233 and 61272466 and the Science and Technology Research and Development Program of Qinhuangdao nos. 2012021A045 and 2012021A046. The authors sincerely appreciate the suggestions and feedback from anonymous reviewers.