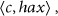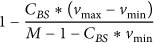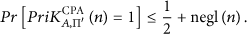Wireless sensor networks (WSNs) are composed of sensor nodes with limited energy which is difficult to replenish. Data aggregation is considered to help reduce communication overhead with in-network processing, thus minimizing energy consumption and maximizing network lifetime. Meanwhile, it comes with challenges for data confidentiality protection. Many existing confidentiality preserving aggregation protocols have to transfer list of sensors' ID for base station to explicitly tell which sensor nodes have actually provided measurement. However, forwarding a large number of node IDs brings overwhelming extra communication overhead. In this paper, we propose provably secure aggregation scheme perturbation-based efficient confidentiality preserving protocol (PEC2P) that allows efficient aggregation of perturbed data without transferring any ID information. In general, environmental data is confined to a certain range; hence, we utilize this feature and design an algorithm to help powerful base station retrieve the ID of reporting nodes. We analyze the accuracy of PEC2P and conclude that base station can retrieve the sum of environmental data with an overwhelming probability. We also prove that PEC2P is CPA secure by security reduction. Experiment results demonstrate that PEC2P significantly reduces node congestion (especially for the root node) during aggregation process in comparison with the existing protocols.
1. Introduction
Wireless sensor networks (WSNs) integrate microelectro-mechanical systems (MEMSs) technology, sensor technology, and communication technology. WSN can sense, transport and process different environmental data in its deployment area by hundreds of sensor nodes with limited computation and energy capacities. WSNs have been extensively used in military surveillance, environmental monitoring, production control, and real-time traffic monitoring [1].
Because WSNs are usually deployed in remote, unattended, or even hostile environment, the energy of sensor nodes is not easy to get replenished. Hence, how to reduce energy cost and prolong the network lifetime has become key issues for WSNs [2, 3]. It is generally believed that power consumption of each sensor node tends to be dominated by data transmission. According to [4], energy cost of transmitting a single bit of data is equivalent to that of 800 instructions. Data aggregation [2, 5] mechanisms avoid transmitting environmental data through in-network process of summarizing and combining sensor data, thus reducing the amount of data transmission and effectively maximizing network lifetime.
Data confidentiality [6–11] is crucial in many WSN applications, like military surveillance. If data confidentiality is compromised, the sensitive information collected will be leaked to adversary. However, there is a conflict between data aggregation and data confidentiality protocols [12]: data aggregation prefers to operate on plain data and confidentiality protection requires data to be encrypted. Extensive secure data aggregation research [6–11, 13–15] has been conducted. Data aggregation protocols usually cannot operate on encrypted data such that intermediate node has to decrypt packets received from downstream, aggregate the plaintext data with its own, encrypt the aggregated result, and forward to upstream.
Two common approaches to preserve data confidentiality without decryption/encryption are homomorphic encryption [7, 8, 10], and secret perturbation [6, 9, 11]. Homomorphic encryption is an encryption transformation that allows direct computation on encrypted data. However, end-to-end security of symmetric homomorphism [7] is easily compromised if any node is corrupted and the computational cost and communication overhead of asymmetric homomorphism [8, 10] are not preferable. In comparison, secret perturbation-based schemes add a perturbation to the value of each reporting node using shared secret key with base station (). retrieves the final aggregation result by removing all these perturbation. Since the key shared between each node and is unique, adversary will not compute other nodes' sensed data or intermediate aggregation result if one key is compromised.
has to know which sensor nodes have provided measurement before it can correctly remove the perturbations brought by these sensor nodes. A straightforward solution is to require every node participating/not participating in aggregation process to report its ID, according to the proportion of nodes satisfying 's query.
However, this approach may bring high extra overhead. Feng et al. [9] proposed a family of secret perturbation-based schemes that can protect sensor data confidentiality while trying to minimize the number of ID to be transferred. In FSP scheme, every sensor node must reply a perturbed actual or dummy data item, no matter the node has satisfying data or not. will simply subtract hash value for every sensor node to compute final aggregation result, and communication overhead caused by ID transmission is avoided. However, it requires all sensor nodes to report data no matter whether they have data satisfying the query. This may result in high extra communication overhead when only a small number of sensor nodes have data to report and communication overhead caused by extra perturbed data can be much larger than that of forwarding ID. Hence, in their ideal scheme O-ASP, aggregating node first has to compute whether overhead of transmitting ID and perturbed data or overhead of transmitting all perturbed data is larger. Either way, O-ASP endures high communication overhead, and it is unrealistic for each sensor node to know the membership and topology of the whole network, and it knows whether each of these nodes has data satisfying each particular query.
Moreover, the transmission of nodes' ID makes [9, 11] not suitable for the scenario shown in Figure 1, where we want to monitor the activities of tanks and battleships, and there is a long path to travel through before aggregation result gets to . To achieve this goal, a cluster or a tree of sensor nodes is deployed in the battlefield, while is in a secure location away to collect data reported by sensors. All data has to be forwarded on a long path from the targeted area to . For [9, 11], ID list is transmitted such that the energy is wasted on the long path, and “single point of failure” could happen if there are not enough nodes on such path. The application scenarios in military surveillance also include the case that US army uses REMBASS to collect data (like ground motion, sound, infrareds, and magnetic fields) and forward the aggregation result to command center. PEC2P fits in this scenario and does not have any requirement on the type of data.
An example of environmental surveillance system in battlefield.
In this paper, we present perturbation-based efficient confidentiality preserving protocol () which can protect data confidentiality without transmitting any ID information. Generally, we use one-way hash function as perturbation added to the environmental data. Since usually has powerful computational capability in WSNs, we propose to trade computation consumption at for energy cost of sensors and introduce a new approach for to compute and tell which nodes have actually sensed data and contributed to the aggregation process after receiving the final aggregation result. Our approach specifically fits for scenarios where aggregation result has to travel a long path before arriving at . In summary, contribution of this paper includes the following.
We draw attention to the ID-list transmitting problem in WSNs and propose the first approach which does not require forwarding any node ID but computing and selecting by . As a result, communication overhead is reduced and reporting nodes' information is further hidden.
We avoid using the random number r verified by commonly applied authenticated broadcasting, thus reducing network delay. Instead, we update the secret key of all reporting nodes after each data aggregation to keep indistinguishability from adversary.
We prove that our protocol is CPA secure by security reduction.
We measure the performance of our protocol through both theoretic analysis and experiments on TinyOS [16]. We analyze the accuracy of and compare its communication overhead with existing protocols.
2. Related Work
Girao et al. proposed CDA [7] using symmetric key-based privacy homomorphic encryption. In their approach, sensor nodes share a common symmetric key with the which is hidden from aggregators, and aggregators can perform aggregation functions directly on the ciphertext instead of carrying out costly decryption and encryption operations. Symmetric homomorphism has the advantage of fast computation. However, secret key is shared among all nodes such that data confidentiality is lost once a sensor node and its shared key are compromised.
Mykletun et al. [8] investigated several additive homomorphic public-key encryption schemes and their applicability to WSNs. In general, these schemes preload public key in sensor nodes and aggregate encrypted data. Then can decrypt aggregation result by its secret key. Albath and Madria [10] proposed an ECC-ElGamal based homomorphic encryption scheme to achieve confidentiality for in-network aggregation in wireless sensor networks. Even if the adversary compromises a node and obtains the public key, it cannot obtain the plaintext of intermediate aggregation results. Hence, public key-based homomorphic encryption schemes are resilient to node compromise attacks. However, the computational cost and communication overhead of public key encryption scheme are not quite tolerable for WSNs, especially when sensors are collecting diverse statistics (like temperature, humidity, and pressure).
Castelluccia et al. [6] first proposed an additively homomorphic encryption scheme which simply adds secret key k to environmental data x as ciphertext . Each node has a unique secret key such that one node's corruption does not affect the data confidentiality of other nodes. Castelluccia et al. [11] improved their scheme in [11] by proposing a simple and provably secure encryption scheme that allows efficient additive aggregation of encrypted data. Each reporting node i encrypts plaintext data as: . The security of their scheme is based on the indistinguishability property of a pseudorandom function (PRF). However, ID-list of sensors has to be transferred and cannot be aggregated.
Feng et al. [9] tried to alleviate the ID-list problem and proposed a family of secret perturbation-based schemes that can protect sensor data confidentiality without disrupting the additive data aggregation result. BSP and FSP are two basic schemes which take nonredundant reporting approach and fully reporting approach, respectively. The ideal scheme O-ASP assumes that each sensor node knows the membership and topology of the whole network, and it knows whether each of these nodes has data satisfying each query. Then, computes aggregation and communication cost of two approaches for each cell before selecting one. To overcome the unrealistic assumption, D-ASP is proposed to enable nodes to make decisions based only on their locally available information, and interactions only take place within a cell or between neighboring cells. However, it is difficult for nodes to decide whether to report their ID with locally available information and it makes no difference when the number of reporting nodes is the same as nonreporting nodes. It also causes extra communication cost and network delay for waiting and deciding.
PRDA [15] pointed out that the transmission of sensor node IDs along with aggregated data packets increases the communication overhead of the network. Therefore, it keeps a table that consists of sensor node IDs and their corresponding small index numbers in each data aggregator. After the cluster forming, data aggregator generates the index table and sends it to . During data aggregation, instead of sending 2-byte sensor node IDs, data aggregators send corresponding index numbers. can find the ID of sensor nodes in the index table. However, index numbers are only used within clusters.
Although existing schemes tried to reduce the amount of IDs, they still suffer from related communication cost, and dropping ID or sending false ID will lead to compute false aggregation result.
Our work requires no ID to be forwarded and achieves a good trade-off between confidentiality and efficiency by adopting perturbation. With this improvement, we manage to simultaneously preserve data confidentiality and significantly reduce overall communication overhead, avoiding high energy consumption in aggregation phase.
3. System Model
3.1. Network Assumption
We assume a multilevel sensor network tree that consists of N (less than 1000) sensor nodes and certain amount of relay nodes. Sensor nodes are deployed in areas of interest, and they can sense and aggregate data. Both tree and cluster topologies can be applied in aggregation structure. In this paper, we use aggregation tree to illustrate our protocol. Aggregation tree could be formed as in TAG [4]. Relay nodes just forward messages, and they consist of a long path from targeted areas to . The powerful with transmission range covering the whole network is capable of broadcasting messages to all nodes directly. Each sensor node has a unique ID picked from the set . After the aggregation tree is formed, each sensor node monitors its surrounded environment to generate environmental data which is an integer ranging from . Environmental data (e.g., temperature) can be converted to integers if necessary. Each reporting node and aggregator sends their messages up the aggregation tree. The message has the following format:
where c is the number of reporting nodes in network and is the sum of environmental data and perturbation.
3.2. Design Goals
When designing confidentiality protection schemes, we aim to achieve the following goals.
Data accuracy: can correctly retrieve the sum of environmental data with an overwhelming probability.
Data confidentiality: the aggregation result should only be known by and is CPA secure.
Efficiency: the protocol should help to reduce communication overhead and prolong the network lifetime.
Definition 1 (Chosen Plaintext Attack).
In this attack, the adversary has the ability to obtain the encryption of plaintexts of its choice. It then attempts to determine the plaintext that was encrypted in some other plaintext [17].
Definition 2 (Negligible Function).
A function F is negligible if for every polynomial , there exists an N such that for all integers , it holds that . An equivalent formulation of the above is to require that for all constants c, there exists an N such that for all , it holds that .
We define an experiment for any private-key encryption scheme , any adversary A, and any value n of security parameter.
The CPA Indistinguishability Experiment.
A random key k is generated by running .
The adversary A is given input and oracle access to , and outputs a pair of messages of the same length.
A random bit is chosen, and then a ciphertext is computed and given to A. We call c the challenge ciphertext.
A continues to have oracle access to , and outputs a bit .
The output of the experiment is defined to be 1 if , and 0 otherwise. (A succeeds if ).
Definition 3 (CPA secure).
A private-key encryption scheme has indistinguishable encryptions under a chosen-plaintext attack (or is CPA secure) if for all probabilistic polynomial-time adversaries A there exists a negligible function negl such that:
3.3. aAttacker Model
We assume the existence of a global probabilistic polynomial time (PPT) adversary, which can choose to compromise a small subset of nodes and obtain all secrets of these nodes. With oracle access, it can also obtain the ciphertext for any chosen plaintext from any of the uncompromised nodes. Once the adversary compromises a sensor node, it will obtain its secret key and may modify, forge or discard messages, or simply transmit false aggregation results.
In this paper, we do not consider stealthy attacks [18] where the attacker's goal is to make the accept false aggregation results while not being detected. Also, we do not consider the denial-of-service (DoS) attack in various protocol layers [19, 20] where the adversary prevents the querier from getting any aggregation result at all. However, if a node does not respond to queries, it is clear that something is wrong, and solutions can be implemented to remedy this situation. Sybil/node replication attacks [21] or “wormhole” formation [22, 23] are beyond the scope of this paper.
4. PEC2P
The proposed scheme mainly consists of bootstrapping phase, data aggregation phase, and result retrieving phase.
4.1. Bootstrapping Phase
In bootstrapping phase, modulus is stored in all nodes, and so is a collision-resistant cryptographic hash function and a PRF .
We further assume that first runs Algorithm 1 such that a unique initialization vector is generated, and secret key is stored in 's local record and node i.
Algorithm 1: Bootstrapping algorithm.
begin
randomly pick master key ;
for to do
;
store in ;
store in and node i;
end
4.2. Data Aggregation Phase
Each sensor node in targeted area may behave as a sensing node, an aggregator, or combined. To simplify the discussion, we assume that each node can perform one role of sensing or aggregating without the loss of generality. Any node with combined role can be logically split into a sensing node and an aggregating node. As shown in Figure 2, aggregator C both senses data and aggregates data from downstream. It is divided into sensing node and aggregating node . After the transformation, only leaf nodes sense environmental data.
An example of data aggregation phase.
In aggregation phase, when a targeted event happens or disseminates a query, each leaf sensor node i with environmental data runs Algorithm 2 to compute individual aggregation result . First, i inputs environmental data , then sets and since it has no children nodes. Second, i forwards the result to its parent node for data aggregation. Finally, i updates its secret key . Other leaf senor nodes remain hibernated.
Algorithm 2: Perturbation algorithm.
begin
Input: environmental data ;
;
;
;
;
return;
end
During each aggregation, upon receiving a message from one of its children nodes for the first time, each aggregator i starts a timer t and collects other messages before t fires. Then, it runs Algorithm 3 to compute partial aggregation result . First, i computes partial count and partial perturbed data . Then i forwards the result to its parent node. Aggregators receiving no messages from downstream just remain hibernated. Note that we count number to trace the contributing nodes in ; hence, synchronization among sensors is not needed.
Algorithm 3: Aggregation algorithm.
begin
;
mod M;
return;
end
Definition 4.
is a set of reporting node's ID, and these nodes are node i's children nodes.
To show how our scheme works, we take Figure 2 as an example. Node B and D are leaf sensor nodes with their own environmental data and . Node C is divided into and such that runs Algorithm 2 and node runs Algorithm 3 respectively. Aggregator A just forwards messages after aggregating data received from B and C. obtains the final aggregation result: and .
4.3. Result Retrieving Phase
In result retrieving phase, after receiving final aggregation result , runs Algorithm 7 to retrieve ID list and actual aggregation result. First, orderly selects a list of nodes and corresponding shared keys from the N nodes, and computes
if , and then will admit that is the actual aggregation result and update secret keys for the found nodes. If not, will continue searching.
To improve searching efficiency for , we can first divide the network into clusters of trees each containing part of N nodes. Further analysis is in Section 5.3.
5. Analysis and Experiments
5.1. Accuracy Analysis
Theorem 5.
has a probability of at least
in finding the correct combination in result the retrieving phase, given the environmental data in the range , the hash value in the range , and modulus M is .
Proof.
We assume that is the uniform distribution over , and then is independent of . The probability of is . When : , , then we believe the probability of is .
Thus, adding environmental data together will result in a number in the range , and the aggregation result is in the range . If the result is valid, it has to belong to range . Then, the probability that accepts a false aggregation result is at most
If we have 1024 nodes in the network and the data sensed from the environment is in the range , we use SHA-1 as our hash function, and the output is in the range . We can calculate the probability that accepts a false aggregation result is which can be ignored.
We have implemented using simple WSN experimental system to sense temperature in lab. Characteristics of SimpleWSN node is shown in Table 1.
Characteristics of simple WSN node.
CPU 8-bit
8 MHz
Storage
10 Kbytes RAM
48 Kbytes FLASH
Communication
2.4 GHz
Bandwidth
250 Kbps
Operating system
TinyOS
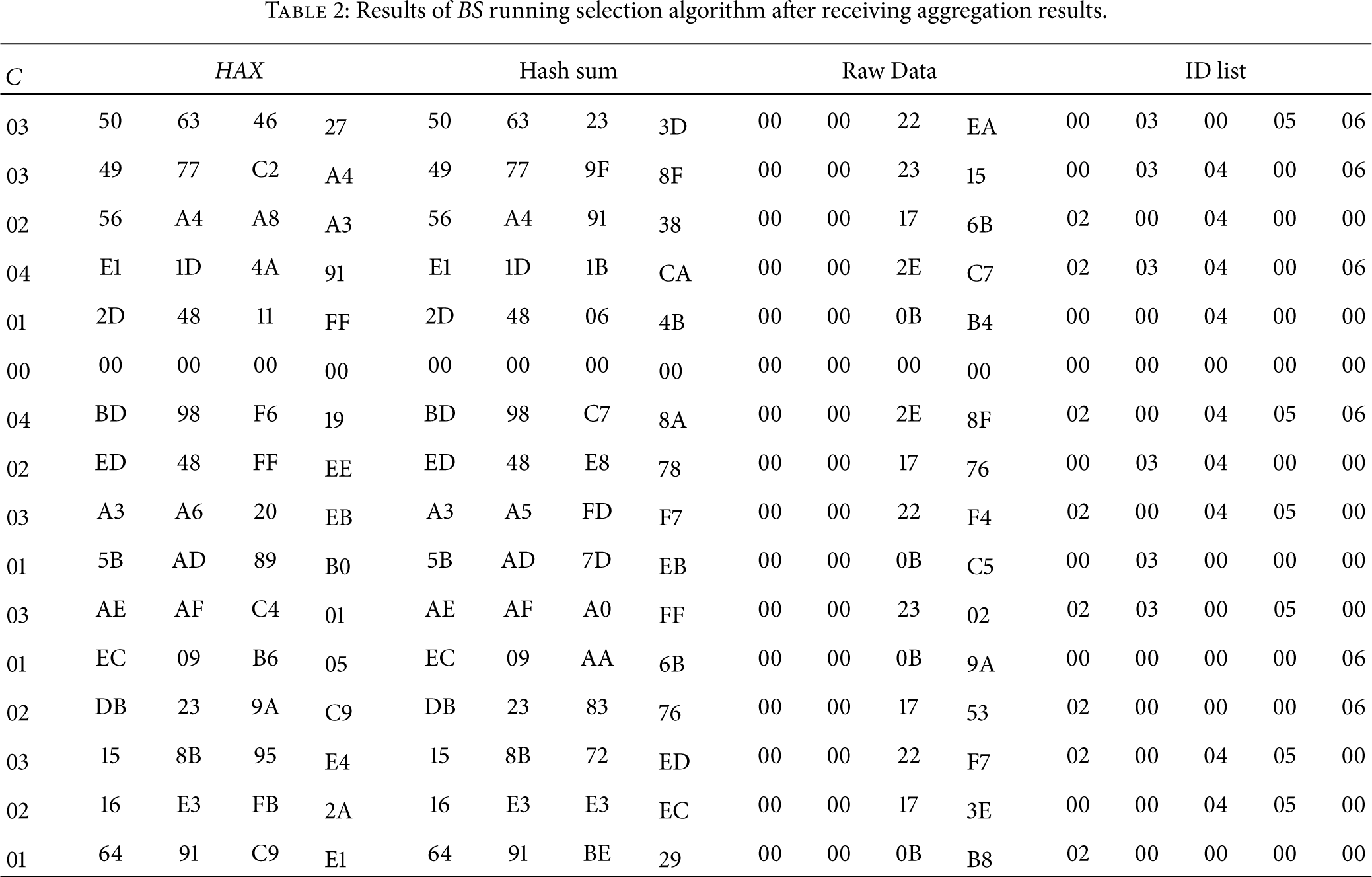
Results are shown in Table 2. has ID ′01′, and sensor node's ID ∈ {′01′, ′02′, ′03′, ′04′, ′05′}. Column 1 displays the number of participating nodes C from aggregation result . Column 2 displays the perturbed data from . Column 3 displays the sum of hash value computed by . Column 4 displays the sum of environmental data after searching and subtracting the sum of hash value from . The IDs of found nodes are shown in column 5. The temperature sensed is hexadecimal integer. We use Temperature , provided by the SimpleWSN experimental platforms, to transform environment data to floating-point number which represent the Celsius degree. The average temperature is about 30 degrees Celsius in our experiment. The results justified the accuracy of such that if we subtract data in column 3 from data in column 2, we will end up with data in column 4. The results verified that both the exact IDs and actual aggregation result are retrieved correctly.
Results of running selection algorithm after receiving aggregation results.
C
HAX
Hash sum
Raw Data
ID list
03
50
63
46
27
50
63
23
3D
00
00
22
EA
00
03
00
05
06
03
49
77
C2
A4
49
77
9F
8F
00
00
23
15
00
03
04
00
06
02
56
A4
A8
A3
56
A4
91
38
00
00
17
6B
02
00
04
00
00
04
E1
1D
4A
91
E1
1D
1B
CA
00
00
2E
C7
02
03
04
00
06
01
2D
48
11
FF
2D
48
06
4B
00
00
0B
B4
00
00
04
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
04
BD
98
F6
19
BD
98
C7
8A
00
00
2E
8F
02
00
04
05
06
02
ED
48
FF
EE
ED
48
E8
78
00
00
17
76
00
03
04
00
00
03
A3
A6
20
EB
A3
A5
FD
F7
00
00
22
F4
02
00
04
05
00
01
5B
AD
89
B0
5B
AD
7D
EB
00
00
0B
C5
00
03
00
00
00
03
AE
AF
C4
01
AE
AF
A0
FF
00
00
23
02
02
03
00
05
00
01
EC
09
B6
05
EC
09
AA
6B
00
00
0B
9A
00
00
00
00
06
02
DB
23
9A
C9
DB
23
83
76
00
00
17
53
02
00
00
00
06
03
15
8B
95
E4
15
8B
72
ED
00
00
22
F7
02
00
04
05
00
02
16
E3
FB
2A
16
E3
E3
EC
00
00
17
3E
00
00
04
05
00
01
64
91
C9
E1
64
91
BE
29
00
00
0B
B8
02
00
00
00
00
5.2. Security Analysis
We assume that each sensor node shares a unique key with and a common one-way hash function H is used. When an event happens, all nodes which are collecting environmental data will add the hash value computed on to the environmental data x. Intuitively, since key is only shared between node i and , other node cannot successfully compute with the probability ϵ that is not negligible. And it is also difficult for adversaries to compute the correct hash value of any given x. Hence, both privacy and confidentiality are achieved. We will prove this by security reduction. First, we construct an encryption scheme (Algorithm 4).
Algorithm 4: Construction .
/*Define a private-key encryption scheme for messages of
length L and key of length n as follows:*/
(i) Gen: on input , choose uniformly at
random and output it as the key.
(ii) Enc: on input a key and a message
, output the ciphertext:
(iii) Dec: on input a key and a ciphertext
, search for matching set S and output the
plaintext:
(iv) Addition of Ciphertext: given two ciphertext
and , output as
aggregation ciphertext:
Lemma 6.
Algorithm 4 is CPA secure if H is a pseudorandom function (PRF). One has
Proof.
If we replace the hash function H in Algorithm 4 with a truely random function F, we can have a new construction . It is obvious that
If H fulfills the requirement, then is the uniform distribution over . Therefore, (6) holds.
Theorem 7.
is secure against CPA hash function if the following distributions are to be identical:
Proof.
Proof for the nonhashed scheme. we assume that adversary A attacks (CPA) with success probability . Now, we can construct a fast algorithm to “break” Construction , and tries to achieve its goal by running A as in Algorithm 5.
Security of the Hashed Version. Only a few modifications to this security proof are needed in order to prove the security of the hashed variant. First, in Algorithm 5, all ciphertext are of now generated using the hashed values of k. Second, the security proof of the hashed scheme relies on the fact that and are identical distribution. If H fulfills the requirement, then is the uniform distribution over . Consequently, the two distributions are identical. This thus concludes the proof that the hashed scheme is semantically secure. Thus, is CPA secure.
Algorithm 5:.
/* tries to break */
(1) initiates other nodes and has access to N oracle .
(2) A implements l times and obtain the ciphertext of message .
(3) forwards the queries to the network and return to A.
(4) A outputs two messages , , sending them to .
(5) A random bit is chosen and makes an encryption query for to and get back challenge ciphertext
.
(6) If is from the node which holds secret key k, then returns to A.
(7) A output a bit and returns it to .
(8) outputs .
(9) Else outputs with the probability of and outputs with the probability of .
(10) Output 1 if and output 0 otherwise.
5.3. Efficiency Analysis
For a reporting leaf node, the computational cost only consists of one hash computation and one modular addition. For an aggregator, the computational cost consists of the sum operation of count and sum of perturbed data. If an aggregator has reporting data, it also has one hash computation.
We assume that there are N sensor nodes in reporting area and aggregation tree has a branching factor d of 3. Perturbed data . We choose the packet format used in TinyOS [16], and the packet header is 56 bits. Data is in the range of . Let count length, ID length, and append length be bits. We consider two different scenarios: (1) only nodes at the lowest level may have data satisfying 's query and (2) nodes at each level may have data satisfying ’ query.
O-ASP [9] is designed based on an ideal and unrealistic assumption that each sensor node knows the membership and topology of the whole network and it knows whether each of these nodes has data satisfying each particular query. In each aggregation, a decision node (say ) first compares the communication cost of [All-reporting] and [Non-redundant-reporting] for each cell and then decides which strategy will be chosen.
In Claude_09 [11], in the data aggregation phase, for scenario (1), each reporting node sends bits of message to its parent node, and nodes at second lowest level decide which group if IDs to send: the reporting nodes' IDs or the nonreporting nodes' IDs. For scenario (2), each reporting node will send bits of message.
For , in the data aggregation phase, for scenarios (1) and (2), each reporting node sends bits of message to its parent node, and the same length of message will also be sent from aggregators. No ID is transmitted in the aggregation tree.
We show the number of bits sent by leaf node in Table 3. Then, we calculate the average/maximum/minimum communication overhead in aggregation phase for Claude_09 and PEC2P in Table 4. In minimum case, reporting nodes are located in the high levels of aggregation tree, and we can find them through breadth-first search. In maximum case, reporting nodes should be located from the lowest level to higher levels. Tables 5 and 6 list the number of bits sent per node for each level with Claude_09 and PEC2P.
Number of bits sent per node for leaf node.
Protocol
Number of bits
O-ASP [All]
O-ASP [Non]
Claude_09
PEC2P
ID: node ID; h: header; Per: perturbed data; N: number of nodes in network.
Theoretical analysis of total communication overhead.
(a)
Claude_09
Average
Minimum
Maximum
PEC2P
Average
Minimum
Maximum
(b)
Claude_09
Average
Minimum
Maximum
PEC2P
Average
Minimum
Maximum
Note: only nodes at the lowest level may have data satisfying 's query.
; d: degree; N: number of nodes in network; and if or .
ID: node ID; header + data + appendedBit; count + header + data + appendedBit.
: ; : ; : ; , and .
Note: nodes at each level may have data satisfying 's query.
; d: degree; N: number of nodes in network; and if or .
ID: node ID; ; .
: ; : ; : ; , and .
Number of bits sent per node for each level with Claude_09 scheme.
Level
Number node
A (100%)
A (90%)
A (70%)
AV (100%)
AV (90%)
AV (70%)
HBH-A
HBH-AV
No-Agg
1
3
75
949.8
2699.4
100
974.8
2724.4
73
97
68859
2
9
75
366.6
949.8
100
391.6
974.8
72
94
22932
3
27
75
172.2
366.6
100
197.2
391.6
70
91
7623
4
81
75
107.4
172.2
100
132.4
197.2
68
87
2520
5
243
75
85.8
107.4
100
110.8
132.4
67
84
819
6
729
75
78.5
83.8
100
103.5
108.1
65
81
252
7
2187
75
67.5
52.5
100
90
70
63
63
63
Note: only the nodes in the lowest level may have data satisfying 's query.
Number of bits sent per node for each level with PEC2P scheme.
Level
Number Node
A (100%)
A (90%)
A (70%)
AV (100%)
AV (90%)
AV (70%)
HBH-A
HBH-AV
No-Agg
1
3
87
87
87
112
112
112
73
97
68859
2
9
87
87
87
112
112
112
72
94
22932
3
27
87
87
87
112
112
112
70
91
7623
4
81
87
87
87
112
112
112
68
87
2520
5
243
87
87
87
112
112
112
67
84
819
6
729
87
86.9
84.7
112
111.9
109
65
81
252
7
2187
87
78.3
60.9
112
100.8
78.4
63
63
63
Note: only nodes in the lowest level may have data satisfying 's query.
Figures 3 and 4 show the trend of communication overhead in two different scenarios.
Communication overhead with different probability of reporting data when only nodes in the lowest level may have data satisfying ’ query.
Communication overhead with different probability of reporting data when nodes at each level may have data satisfying ’ query.
We assume that only the nodes in the lowest level have a probability of to sense environmental data. Results are shown in Figures 5(a), 5(b), and 5(c).
Bandwidth consumption in data aggregation phase when only nodes in the lowest level may have data satisfying ’ query.
We further assume that all nodes in aggregation tree has a probability of to sense environmental data. Results are shown in Figures 6(a), 6(b), and 6(c).
bandwidth consumption in data aggregation phase when nodes at each level may have data satisfying ’ query.
Results show that, compared with existing protocols, can greatly reduce communication overhead in aggregation phase. We notice that the major communication overhead is caused by transferring the hash value which was computed by SHA-1 in the comparison. Performance can be further optimized by choosing other hash functions with shorter output in case of lower security level requirement.
Result Retrieving Algorithm Test. We used a computer with a Pentium(R) D CPU of 3.40 GHZ and 2.00 GB memory to test Algorithm 7. Since sensor nodes are relatively uniformly distributed and their communication range is from 50 meters to 100 meters, a local event will be detected by a small group of sensor nodes. Therefore, we choose to use a small N. Results show that choosing 5 nodes from 10 nodes only needs 8 milliseconds and choosing 10 nodes from 20 nodes only needs approximately 2 seconds. In WSNs, the capability of is more powerful than our experimental computer; thus, the searching time will be shorter in real applications. To make the search efficiently, we can first divide the network into clusters of trees.
6. Conclusion
Confidentiality protection and energy efficiency are two conflict, but equally crucial requirements in WSNs. To achieve a trade-off between these two goals simultaneously, remains a challenge. We propose to protect data confidentiality which also achieves energy efficiency. Specifically, we need no ID list and use one-way hash function as perturbation added to the environmental data. Since usually has powerful computation capacities, we utilize to the fullest and let it compute which nodes have actually contributed to the aggregation process after receiving the final perturbed aggregation result. Consequently, we manage to preserve data confidentiality, avoid high energy consumption, and obtain lower overall communication overhead. Analysis and experiments have also been conducted to evaluate the proposed protocol. The results show that our protocol provides confidentiality protection for both raw and aggregated data with an overhead lower than that of the existing related protocols. can be adopted to tree/cluster-based aggregation and any protocol using ID-list transmission. We focus on collecting the number of contributing nodes and its perturbed data, instead of how the information is gathered. For uniformity, we use tree topology in our paper. We also did cluster-based comparison with existing protocols, and the results show no significant difference.
<bold>Algorithm 7:</bold> Result retrieving algorithm.
begin
; ; ;
for to do
;
fori: C to do
;
Matching();
ifthen
return;
/*search times*/
for to do
for to do
ifthen
;
/*find the last in */
ifandthen
; ;
Matching();
ifthen
return;
; ;
/*The last is in the last position, then
move the last continuous s to the first
found before them*/
ifandthen
/how many s should be moved*/
;
/*from behind*/
for to 0 do
ifthen
;
/*found the empty position and
move the newly found and the
continuous s*/
else
/*newly found /
;
/continuous s new location*/
;
for to 0 do
ifthen
;
;
;
/*searching ends*/
;
/*move the continuous s*/
ifthen
for to
do
;
for to
do
;
;
Matching();
ifthen
return;
; ;
end
Acknowledgments
This paper is supported by the National Natural Science Foundation of China (nos. 61272512, 61003262, and 61100172), Program for New Century Excellent Talents in University (NCET-12-0047), and Beijing Natural Science Foundation (no. 4121001).
References
1.
AkyildizI. F.SuW.SankarasubramaniamY.CayirciE.Wireless sensor networks: a surveyComputer Networks2002384393422
LiM.LiuY.Iso-Map: energy-efficient contour mapping in wireless sensor networksIEEE Transactions on Knowledge and Data Engineering20102256997102-s2.0-7794991443710.1109/TKDE.2009.157
4.
MaddenS.FranklinM. J.HellersteinJ. M.HongW.Tag: a tiny aggregation service for ad-hoc sensor networks36Proceedings of the 5th Symposium on Operating Systems Design and Implementation ACM SIGOPS Operating Systems Review (OSDI ′02)2002131146
5.
AkkayaK.DemirbasM.AygunR. S.The impact of data aggregation on the performance of wireless sensor networksWireless Communications and Mobile Computing2008821711932-s2.0-3964912058010.1002/wcm.454
6.
CastellucciaC.MykletunE.TsudikG.Efficient aggregation of encrypted data in wireless sensor networksProceedings of the 2nd Annual International Conference on Mobile and Ubiquitous Systems—Networking and Services (MobiQuitous ′05)July 20051091172-s2.0-3374952520910.1109/MOBIQUITOUS.2005.25
7.
GiraoJ.WesthoffD.SchneiderM.CDA: concealed data aggregation for reverse multicast traffic in wireless sensor networksProceedings of IEEE International Conference on Communications (ICC ′05)May 2005304430492-s2.0-24144459865
8.
MykletunE.GiraoJ.WesthoffD.Public key based cryptoschemes for data concealment in wireless sensor networksProceedings of the 41st IEEE International Conference on Communications (ICC ′06)July 2006228822952-s2.0-4254915954510.1109/ICC.2006.255111
9.
FengT.WangC.ZhangW.RuanL.Condentiality protection for distributed sensor data aggregationProceedings of the 27th IEEE International Conference on Computer Communications (INFOCOM ′08)20086876
10.
AlbathJ.MadriaS.Secure hierarchical data aggregation in wireless sensor networksProceedings of IEEE Wireless Communications and Networking Conference (WCNC ′09)April 2009162-s2.0-7034917949510.1109/WCNC.2009.4917960
11.
CastellucciaC.ChanA. C. F.MykletunE.TsudikG.Efficient and provably secure aggregation of encrypted data in wireless sensor networksACM Transactions on Sensor Networks2009531362-s2.0-6765103046510.1145/1525856.1525858
12.
OzdemirS.XiaoY.Secure data aggregation in wireless sensor networks: a comprehensive overviewComputer Networks20095312202220372-s2.0-6754911845610.1016/j.comnet.2009.02.023
13.
HuL.EvansD.Secure aggregation for wireless networksProceedings of the 3rd IEEE Symposium on Applications and the Internet Workshops (SAINT ′03)Washington, DC, USAIEEE Computer Society384
14.
MahimkarA.RappaportT. S.SecureDAV: a secure data aggregation and verification protocol for sensor networksProceedings of the 47th IEEE Global Telecommunications Conference (GLOBECOM′04)December 2004217521792-s2.0-18144428307
15.
OzdemirS.XiaoY.Polynomial regression based secure data aggregation for wireless sensor networksProceedings of the 54th IEEE Global Telecommunications Conference (GLOBECOM ′11)201115
16.
KarlofC.SastryN.WagnerD.TinySec: a link layer security architecture for wireless sensor networksProceedings of the 2nd International Conference on Embedded Networked Sensor Systems (SenSys ′04)November 20041621752-s2.0-26444574670
17.
KatzJ.LindellA. Y.Modern Crytography2008Chapman & Hall
18.
PrzydatekB.SongD.PerrigA.SIA: secure information aggregation in sensor networksProceedings of the 1st International Conference on Embedded Networked Sensor Systems (SenSys ′03)November 20032552652-s2.0-18844457825
19.
McCuneJ. M.ShiE.PerrigA.ReiterM. K.Detection of denial-of-message attacks on sensor network broadcastsProceedings of the 25th IEEE Symposium on Security and Privacy (SP ′05)May 200564782-s2.0-27544432072
20.
WoodA. D.StankovicJ. A.Denial of service in sensor networksComputer2002351054622-s2.0-003679392410.1109/MC.2002.1039518
21.
NewsomeJ.ShiE.SongD.PerrigA.The Sybil attack in sensor networks: analysis and defensesProceedings of the 3rd International Symposium on Information Processing in Sensor Networks (IPSN ′04)April 20042592682-s2.0-3042785862
22.
ParnoB.PerrigA.GligorV.Distributed detection of node replication attacks in sensor networksProceedings of the 25th IEEE Symposium on Security and Privacy (SP ′05)May 200549632-s2.0-27544460282
23.
BrandsS.ChaumD.Distance-bounding protocols839Proceedings of the Workshop on the Theory and Application of Cryptographic Techniques on Advances in Cryptology (EUROCRYPT ′93)1994Springer344359Lecture Notes in Computer Science