
Abstract
This survey addresses the existing state of knowledge related to vision-based mobile robots, especially including their background and history, current trends, and mapless navigation. This paper not only discusses studies relevant to vision-based mobile robot systems but also critically evaluates the methodologies which have been developed and that directly affect such systems.
1. Introduction
A robot is defined as a programmable, self-controlled device. It is in essence a machine which is able to function in place of a living agent [1]. Mobile robots have a long history. Shakey, the world's first mobile robot, was developed in the late 1960s at SRI's Artificial Intelligence Centre (Stanford Research Institute) [1]. Not surprisingly, it has had a substantial influence on present day robotics. Shakey was equipped with various sensors and driven by a problem-solving program called “STRIPS,” and used algorithms for perception, world modelling, and actuation. Low-level action procedures were responsible for moving, turning, and path planning tasks. The high-level program could make and execute plans to achieve goals. Another example of an early robot is CART which was developed at Stanford University in 1977 by Hans Moravec as part of his doctoral thesis [2]. However, CART was very slow, not because it was slow-moving by design, but because it was “slow-thinking.”
The main reason for this was the difficulty of processing vision data using slow computer processors [3]. Another well-known example was Rover developed at Carnegie Mellon University (CMU) in the early 1980s. Rover was equipped with a camera and was able to perform better than CART. Nevertheless, its thinking and acting were still very slow [4]. In the last decade, the main developments in the area of robotics have come through technological breakthroughs in the areas of computing telecommunications, software, and electronic devices. These technologies have facilitated improvements in intelligent sensors, actuators, and planning and decision-making units which have significantly increased the capabilities of mobile vehicles. The latest trend in robotic intelligence is toward imitating life, for instance in evolutionary robots and emotional control robots.
Another area of technological challenge for the next decade is the development of microrobots and nanorobots for medical applications. On top of this, a paramount challenge will be to find an appropriate balance between human-assisted systems and fully autonomous systems and to integrate technological capabilities with social expectations and requirements [1].
Vision-based indoor mobile robot navigation has been studied for decades and is one of the most powerful and popular sensing method used for autonomous navigation. Compared with other on-board sensing techniques, vision-based approaches to navigation continue to demand attention from the mobile robot research community, due to their ability to provide detailed information about the environment which may not be available using combinations of other types of sensors. The great strides achieved in the area of vision-based navigation systems are significant; however, there is still a long way to go. Two important survey papers that have been published review various aspects of the progress made so far in vision for mobile robot navigation [5, 6]. This paper mainly discusses their classification of vision-based navigation systems and attempts to reveal the appropriate state-of-the-art for the indoor environments. A corresponding schema, summarizing state-of-the-art of vision-based navigation, is illustrated in Figure 1. According to the given figure (see Figure 1), there two methods are developed based on map, namely: map-based and map-building-based approaches which will be detailed in the following section.
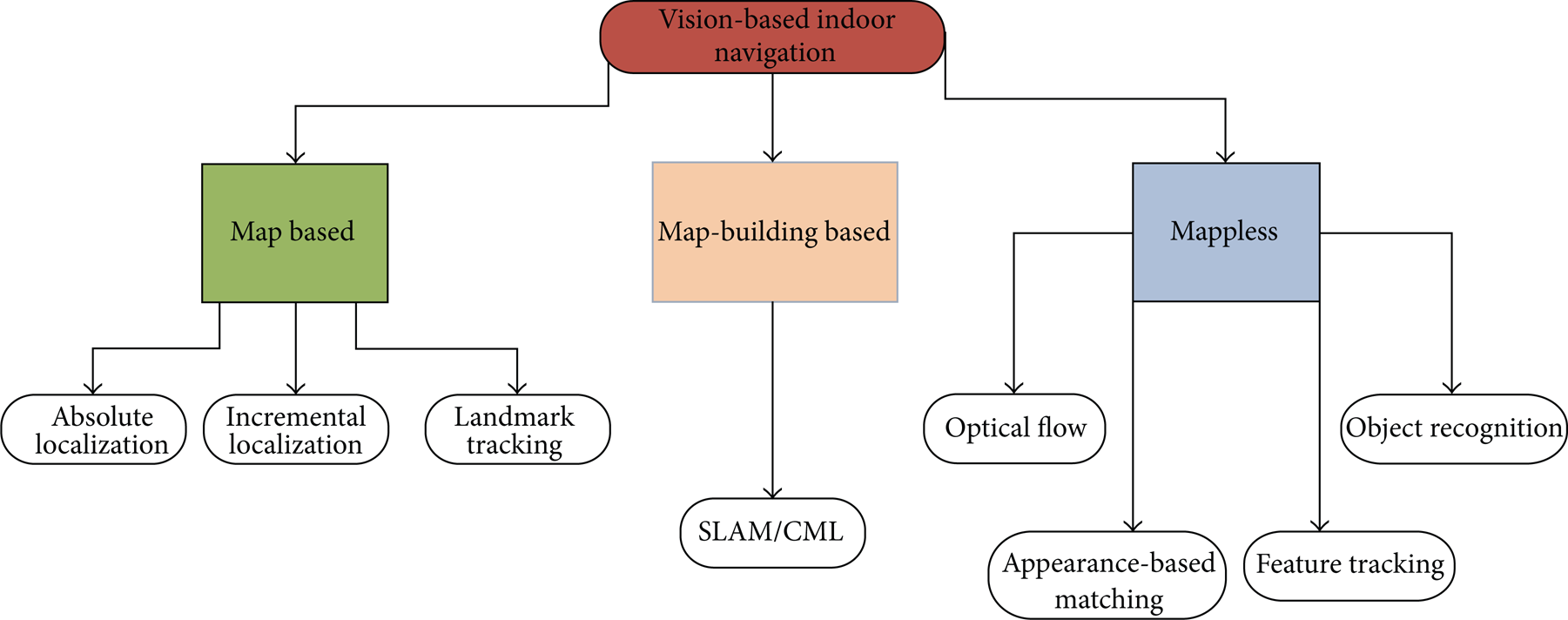
Vision-based indoor mobile robot navigation techniques.
2. Vision-Based Navigation Using Map
This section aims to detail techniques employing or constructing map to complete navigation problem especially for indoor environments. The first part of this section will introduce map-based navigation approaches in which the robot requires either a metrical or topological map to achieve the given navigation tasks. The second part will highlight the map-building-based methodologies which construct and adapt maps to navigation problems simultaneously. To understand these concepts, a simple analogy was described in [7], and a similar analogy including a daily life scenario is described next. In the scenario it is assumed that a visiting researcher is in Newcastle city centre and needs to return to the Stephenson Building (Newcastle University, Claremont Road) where his office is located. There are various methods that he can follow to reach the office. First, he could memorize the number of steps walked from the university, and he could return by counting the same number of steps. This would be dead-reckoning navigation. He could also buy a map of the environment in order to reach the goal, as in map-based navigation. However, this solution entails that somebody has previously named the streets and have drawn the map. Alternatively, he could also draw his own map using map-building navigation while exploring the city, but this would cost a lot of time and effort. Finally, he could look around trying to find the Claremont Tower and then try to approach it keeping the top of the tower in his field of view (map-less navigation). The goal is to reach the tower, since he knows that Daysh Building is next to it. Autonomous navigation architectures utilize some of these solutions to track a trajectory towards the required goal. Dead-reckoning navigation is the cheapest method and essentially includes an odometry system. However, this solution may include many mechanical problems that produce an increasing error which is unacceptable in long-term navigation. So, an additional perception system is mandatory. Vision is perhaps the most broadly researched perception system.
2.1. Map-Based Navigation
Many techniques employ metric or topological maps to navigate. Navigation techniques need certain knowledge of the environment, and maps may contain different degrees of detail, varying from a complete CAD model of the environment to a simple graph of interconnections between the elements in the environment. One of the key classification criteria in this approach depends on the type of map. For instance, metric-based maps generally favour techniques which produce an optimum, while qualitative methods such as topological maps employ identifiable gateways or landmarks to produce a route.
The main idea behind map-based navigation is essential to provide the robot with a sequence of landmarks expected to be found during navigation, and the task of the vision system is then to search for and recognize the landmarks observed in an image. When the landmarks are recognized, the robot can employ the map to estimate its own position (self-localization) by matching the observation (image) against the expectation (landmark) description in the database. The steps of vision-based localization can be divided into four steps [5].
Acquiring Sensory Information. Acquiring images with associated devices.
Detect Landmarks. Extracting edges, smoothing, filtering, and segmenting regions.
Matching. Identifying landmarks by searching possible matches using the database based on predefined conditions.
Calculate Position. Whenever a set of matches is obtained, the system needs to calculate the position using the observed landmarks' positions in the database.
The start position of the robot is unknown under absolute localization methods. Accordingly, the system must provide exact matching between the current and expected data, derived purely from the entire database. This self-localization problem has been solved either using deterministic triangulation or Monte Carlo-type localization [5, 6]. A detailed implementation of the Monte Carlo localization method to localize a mobile robot without knowledge of its starting location was proposed [8]. Incremental localization assumes that, at the beginning of the navigation, the position of the robot is known approximately. In such cases, the localization algorithm basically keeps track of uncertainties in the robot's position as it executes motion commands and, when the uncertainties exceed a limit uses its sensors for a new fix on its position [5]. The FINALE system is a good example of being able to achieve incremental localization using a geometrical representation of space and a mathematical model of uncertainty regarding the location of the robot [9]. Stereo vision is also preferred by researchers in order to reduce errors [10]. Christensen et al. [11] employed CAD models to represent the working space combined with stereo vision to reduce errors [11].
The final method is landmark tracking in which landmark tracking algorithms determine the position of the robot, detect landmarks on the camera image, and track them in the successive scenes. Landmarks can be artificial or natural. In both cases, the robot needs to recognize the landmarks in order to be able to track them [12–14]. Kabuka and Arenas [12] was the first employing artificial landmark tracking for vision-based navigation. A good example of natural landmark tracking-based navigation was proposed in [13] in which a landmark detection technique that assures stable detection even under variable brightness and an obstacle measurement technique that combines obstacle region segmentation with stereo vision were proposed.
2.2. Map-Building Based Navigation
Sometimes modelling an environment could be difficult particularly if one also has to provide metrical information. An alternative navigation strategy, the map-building-based approach, has been used in both autonomous and semiautonomous systems that entails searching the environment and building a representation of it.
One of the earliest attempts at a map-building technique was carried out by the Stanford CART Robot equipped with a camera. Subsequently, an interest operator algorithm was improved to detect 3D coordinates of the images [15]. The system basically demonstrated the 3D coordinates of the objects, which were stored on a grid having 2 m cells. The map was updated at each iteration; and obstacles were also shown in the map. But the most important problem with the whole system was performance, which took five hours to go 20 metres. Visual navigation studies, employing map-building-based strategies, from the late 1990s to the present, have focused on two methodologies, namely: simultaneous localization and mapping (SLAM) or concurrent mapping and localization (CML) [6]. These methodologies principally propose solutions to automatically overcome the problem of the exploration and mapping of any unknown environment, which essentially entails three simultaneous tasks comprising navigation, mapping, and localization. Vision-based SLAM/CML algorithms mainly employ stereo vision as primary sensor. Se et al. implemented a vision-based mobile robot localization and mapping system in which the robot was equipped with a stereo system to build a 3D map so as to localize simultaneously in 3D [16]. The map was represented as a scale invariant feature transform (SIFT) feature database. It was constantly updated frame by frame and was adaptive to dynamic environments. An alternative and efficient solution to the SLAM problem based on a pair of stereo cameras has also been recently proposed which employs 3D landmarks to localize the robot, as well as constructing an occupancy grid for safe navigation [17]. Other map-building-based navigation techniques are those that impose a human-guided training stage. In such solutions, a human operator guides the robot through an unknown environment. During this process, the robot records images with a stereo camera and constructs the 3D map incrementally. After the map is built, the robot tracks extracted features and computes the optimum path [18].
3. Mapless Navigation
This section discusses a representative selection of mainly reactive visual-based navigation techniques in which navigation is performed without any prior description of the environment. Mapless navigation is scarcely new compared with the previously defined solutions, but new projects using vision systems have been developed in several directions in the last few years. In the systems surveyed in this section, no maps are ever created. The robots can navigate by observing and extracting relevant information about the landmarks in the environment. These elements can be objects such as desks, boxes, and doorways. The mapless visual navigation techniques discussed here are classified in accordance with the main vision technique or types of clues used during the navigation which are optical flow, appearance based, and object recognition navigation techniques based on feature tracking (see Figure 1) [5].
3.1. Optical Flow for Robot Navigation
Optical flow is defined as the motion of all the surface elements from the visual world. When a person moves through the world, the objects in the visual environment flow around this person. The human visual system can detect that person direction of travel from the movement of these objects. Optical flow can be defined as the apparent motion of features in a sequence of images, as shown in Figure 2. It is believed that when the insect is in relative motion with respect to the environment. Accuracy and the range of operation can be altered by changing the relative speed. For instance, features such as “time-to-contact” (depending on speed) are more relevant than distance when it is necessary to avoid an obstacle [5]. Bernardino and Santos-Victor developed an optical flow-based navigation system imitating the visual behavior of bees, called robee, and was equipped with a stereo vision system, mimicking the centring reflex behaviour used by a bee to navigate safely [19]. The robot localizes itself using the difference between the velocity of the image seen with the left eye and the velocity seen in the right eye. If the difference is close to the zero, the robot keeps moving forward. However, if the velocities are different, the robot moves toward the side whose image changes with a lower velocity. Several successful navigation systems have been recently inspired by this centring reflex and implemented to navigate a mobile robot through an unknown indoor environment. For instance, a mobile robot platform utilizing a binocular vision system to estimate optical flow in some way emulates corridor following behaviour to navigate [20]. Duchon et al. implemented a monocular vision-based navigation system based on optical flow algorithms and action modes (behaviours). Simulation and real experiments revealed that the system was capable of navigating in a maze whilst successfully avoiding obstacles [21]. Since then, several optical flow-based control algorithms integrated into a behavioural model have been implemented to be used in real-time applications [22–25].

Motion estimation, (a) source image, (b) destination image, (c) motion estimation, and (d) estimated flow vectors.
Additionally, a simple but efficient optical flow-based visual-based navigation system was developed in [26] under the DARPA-Mobile Autonomous Robot Software (MARS) program. The proposed technique first estimates image edge maps by detecting Laplacian of Gaussian (LOG) zero crossings. Afterwards, the edge maps of consecutive frames are used by a patch matching procedure to calculate corresponding optical flow.
3.2. Appearance-Based Methods
Appearance-based methods fundamentally rely on the idea of memorizing the working environment. The main idea is to store images or templates of the environment and associate these images with commands that will steer the robot to its final destination [5]. These methods mainly consist of two procedures. The first one is the training phase in which images or prominent features of the environment are stored as model templates. The models are labeled with certain localization information, which are then associated with appropriate steering command. Secondly, in the navigation stage, the robot has to identify the environment and localize itself by matching the current image with the stored templates [6]. The main problems with the method are to find an appropriate algorithm for the representation of the environment and to define the on-line matching criteria [5, 6].
Beginning in the late 90s, a well-known example of this method was proposed in which the robot merges visual information and their azimuths to build up a representation of its location which is used to estimate the best movement to reach the goal. Another popular technique derived from this approach is the view-sequenced route representation which primarily focuses on route construction using a sequence of images and a template matching algorithm to guide robot navigation. Captured images are used to form a sequence of images. Each image in the sequence is associated with the motions required to move to a corresponding destination. This approach basically introduces the concept of visual memory [27]. Multidimensional histograms provided by the statistical analysis of images are an alternative method to guide mobile robots in appearance-based strategies. Statistical data, including that related to colour, edge density, and texture, are utilized to build a multidimensional histogram database. The recognition of the environment during the navigation stage is achieved by matching the multidimensional histogram of the current image with the multidimensional histogram of the stored templates. This technique consumes less computational resources than when using correlation algorithms [28]. Recent groundbreaking research has proposed an entirely qualitative method in which feature points are automatically detected and tracked throughout the image sequence. In the teaching phase, the (KLT) feature tracker computes the displacement and minimizes the sum of the squared differences between consecutive image frames. The feature coordinates in the replay phase are compared with those computed previously in the teaching phase in order to estimate the steering commands for the robot. Experimental results revealed that the capability of autonomous navigation in both indoor and outdoor environments was successful with the proposed method [29].
An important concept in visual-based mobile robot navigation is the idea of visual homing, inspired by insect behaviour. Insects are able to return to important places in their environment by storing an image of the surroundings while at the goal, and later computing a home direction from a match between this snapshot image and the currently perceived image. For instance, an agent employing a visual homing algorithm captures an image at the home location. It then attempts to return to this location from a nearby position. It compares the current image with the snapshot and infers the direction to the location of the goal from the disparity between these images. It is considered that these aspects of insect behaviour can be a basis for the development of robust navigation algorithms for mobile robots [30].
Visual homing is an appearance-based navigation strategy whose homing algorithms are based on image-based holistic methods using disparities between whole images to compute homing vectors. Image warping is a popular method which is considered to be one of the most reliable visual homing methods for indoor use in this category. It involves calculating the set of all changes in position and orientation between the current and snapshot images. Warping methods distort the current image as if the agent would move according to certain movement parameters. The space of possible movement parameters is then searched for the parameter combination leading to the warped image that is as similar as possible to the stored image. In order to achieve this, warped images are compared to stored image using a pixel-by-pixel correlation measure. The current home vectors are determined based on the strongest similarity between those images [31]. A new and simple visual homing algorithm has been recently proposed where the home position is considered as a charging station [32]. The algorithm basically utilizes the root mean square (RMS) difference and exclusive or (XOR) functions to compare current and snapshot images. The paper reveals that it is possible to implement homing algorithms which allow a robot, fitted with a panoramic camera, return to a reference position from any starting point in an area [32].
3.3. Object Recognition
For the appearance-based approaches previously mentioned, the robot is only able to access few sequences of images that help it to reach its final destination or use predefined images of target goals that it can use to track and pursue. An alternative method has been proposed which essentially employs a symbolic navigation approach instead of memorizing the environment [33, 34].
In this case, the robot utilizes symbolic commands such as “go to the corner in front of you” or “go to the main exit.” For instance, a command such as “go to the corner in front” informs the robot that the landmark is a corner and the path points straight ahead. The robot builds a map called an “s-map” which is a 2D grid that stores the projections of the observed landmarks as they are recognized. After the location of the landmark is projected into the s-map, the robot generates the path using GPS-like path planner and employs odometry to reach the goal [5].
3.4. Navigation Techniques Based on Feature Tracking
Tracking the motion of moving elements, including lines, corners, or specific regions in a video sequence has become a popular and robust way of performing navigation. Techniques inspired from tracking are called feature-based approaches which, in essence, determine the trajectory and motion of the robot by tracking and finding relative changes in the position of extracted features [6].
This category can also include feature-based visual homing strategies. Feature-based methods fundamentally segment snapshot and current images into landmarks and background. To operate successfully, feature-based navigation algorithms must extract the same features from snapshot and current images (the feature-extraction problem). Each feature extracted from the snapshot image must then be paired with a feature from the current image (the correspondence problem). The feature extraction and correspondence problems are difficult to solve in cluttered environments in real-time, since the appearance of landmark changes with viewpoint [31].
One of the earliest studies regarding feature tracking systems introduced a fruit tracking system employing the size and position of a valid fruit's regions in colour images, to control the motion of a fruit-picking robot [35]. Trahanias et al. implemented a robotic system that is able to extract landmarks automatically in indoor environments, using a selective search for landmark patterns which relies both on the workspace and the distinctiveness of the objects in the environment [36]. A KLT tracker-based homing schema was rooted in the extraction of very low-level sensory information, namely, the bearing angles of corners. This was implemented on a robotic platform to evaluate the results [37]. Alternatively, in most cases, feature tracking-based navigation algorithms do not provide an obstacle avoidance module, which must therefore be implemented by other means depending on the problem. For instance, Li and Yang proposed a behavioral navigation architecture for mobile robots, which utilized a robust visual landmark-recognition system based on genetic algorithms to guide the robot, which used a fuzzy-based obstacle avoidance system and ultrasonic range finder [38].
Two images of the same planar surface in space are related by a homographies. This concept has many practical applications, including mobile robot navigation. In a recent study, Guerrero et al. introduced a method based on homographies computed between current images and images taken in a previous teaching phase with a monocular vision system. The vertical lines (features) were used to estimate the homographies, which are automatically extracted and matched. A complete homography motion can compute rotation and translation up to a scale factor [7]. Besides, a simple bearing only measurement technique relying on monocular vision is proposed with odometry readings in which the reference image and the current image are compared to enhance the localization accuracy of the robot [39]. The scale invariant feature transform (SIFT) method, detailed in Figure 3, is a milestone among techniques to detect the features of images or relevant points, and nowadays it has become a method commonly used in landmark detection applications [40, 41]. The SIFT extracts features that are invariant to image scaling, rotation, and illumination. During the robot navigation process, invariant features which have been detected are then observed from different points of view, angles, and distances and under different illumination conditions and thus become highly appropriate landmarks to be tracked for navigation.

Pons et al. employed the SIFT algorithm for feature-based homing, and are utilized to recover the misalignment of orientation between the current and goal positions. Finally, a home vector between these two positions is calculated using the SIFT matches as a correspondence field [42]. Another original paper using SIFT matchingpresents a method for search and localization of objects with a mobile robot. The recognition mechanism of the method is based on receptive field cooccurrence histograms and SIFTS matching [43]. Guzel and Bicker have recently proposed a new SIFT-based algorithm which is inspired from a visual homing strategy and adapted to a behavioural architecture to overcome goal-based navigation problems [44].
Another popular robust local feature detector is speeded up robust features (SURF) which is first presented by Bay et al. in 2003. It is mainly inspired by the SIFT descriptor. However, the standard version of SURF is several times faster than SIFT [45]. Pictographs are widely used in a general environment. Accordingly, a novel navigation system has been recently developed for indoor service using SURF algorithm to detect pictographs [46]. A similar study was presented by Hirose et al. in 2011, detecting pictographs with SURF for robot navigation [47].
In an alternative study, SURF algorithm is used to improve the performance of appearance-based localization methods. Experiments were conducted by using several omnidirectional images [48]. Other corresponding studies can be found in references [49, 50].
A comprehensive research has been recently presented by Martinez-Garcia and Torres [51]. They developed an indoor/outdoor visual odometry scheme for a wheeled mobile robot based on a single passive vision sensor. The authors propose an algorithm which is able to track multiple naturally selected landmarks featured by regional descriptors. The algorithm is in essence an improved version of the maximally stable extremal regions descriptor (MSER). Furthermore, this study was improved by evaluatıng other popular invariant descriptors such as SIFT, Quick SHIFT and feature points extraction algorithm Harris corner detection (HCD) [52], and the fast corner detection (FCD) [53]. Experimental results performed in both indoor and outdoor environments with a mobile robot prove the robustness and consistency of the proposed algorithm. One of the most important criteria in feature tracking-based navigation systems is the computational time consumed by the algorithm. Accordingly, researches have been focused on performance improvement in corresponding algorithms. The most efficient way of performance increment is to parallelize the code or to execute the application on multiprocessor architectures. Various techniques have been proposed to increase parallelism of streaming applications. For instance, Wang et al. have recently presented a comprehensive method in order to reduce schedule length and energy consumption on multiprocessor system-on-chips (MPSoCs). They proposed an ILP design to generate an optimum objective task schedule [54]. Alternatively OpenMP architecture is a robust way of accelerating existing invariant descriptors [44, 55, 56]. The architecture generates multiple threads for parallel programming in a public, shared memory environment.
Visual servoing is another important concept which can be included in this category and is defined as the capability to employ visual information to control the pose of the robot's end-effectors relative to a target object or a set of target features. The task can also be defined for mobile robots, where it becomes the control of the vehicle's pose with respect to specific landmarks. Thus, Szenher defined the feature-based visual homing algorithms as a type of image-based visual servoing [31]. There are two main approaches for visual servoing systems, namely: position-based visual servoing (PBVS) and image-based visual servoing (IBVS) [57]. PBVS algorithms solve the trajectory problem in workspace. However, in IBVS, the control commands are deduced directly from image features. Kim and Oh have proposed an intelligent mobile robot navigation architecture comprising both of these servoing methods to guide a mobile robot [58]. The IBVS module estimates the motion planning directly from the image space so as to keep the target object always in the field of view. As well as this, the PBVS module is employed to conduct an image-to-workspace transform to plan an optimal pose trajectory directly in the Cartesian space. Another study focuses on docking an AUV to an underwater station with a single standard camera and visual servoing strategy [59].
3.5. Obstacle Avoidance Systems Using Qualitative Information
Obstacle avoidance techniques classified essentially entail extraction of qualitative image characteristics and their interpretation [6]. They are basically defined as sensor-based obstacle avoidance systems which process every item of online sensor data to estimate free and occupied space. These methods are considered useful in avoiding having to compute accurate numerical data such as distance and position coordinates. Lorigo et al. proposed a low resolution vision-based obstacle avoidance architecture consisting of three-dependent vision modules for obstacle detection. These modules were associated with edges, red, green, and blue (RGB) colours, and hue, saturation, and value (HSV) information. The data from these modules was analyzed by a fourth module so as to simultaneously generate motion commands [60]. Ulrich and Nourbakhsh proposed a similar vision-based obstacle avoidance strategy based on monocular vision. The strategy essentially involves assigning each pixel as either obstacle or ground according to its colour appearance [61].
Saitoh et al. integrated this obstacle avoidance technique into a centre followed-based mobile robot navigation architecture. The system does not need prior knowledge of the environment and employs a low cost monocular vision camera as the only sensor needed to navigate the robot safely [62]. The robot has a basic navigation strategy so that it moves towards the centre of the corridor until it encounters an unexpected obstacle. When any obstacle is detected, the robot attempts to avoid it or stops depending on the size of the obstacle. If the robot manages to pass the obstacle successfully, it then localizes itself toward the centre.
ROBOCUP competition has become quite popular and has attracted the attention of many researchers in recent years. The detection of an opponent robot and the ball are two challenging tasks which must be solved efficiently. Fasola and Veloso proposed using image colour segmentation techniques for object detection and grayscale image processing to detect the opponent robots [63]. Guzel and Bicker proposed a new method inspired from feature matching principal and combined Sift-based feature detection and conventional appearance-based method using a fuzzy inference system [64]. The control architecture of the proposed navigation architecture is illustrated in Figure 4.
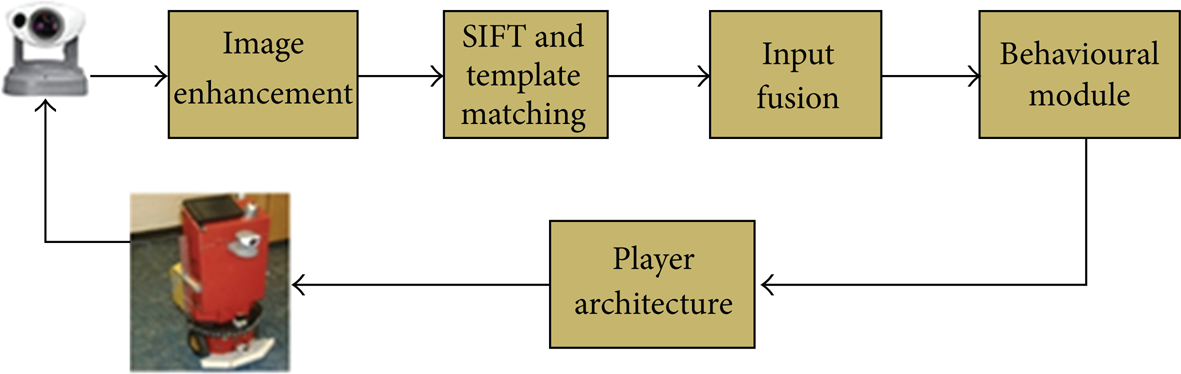
Control architecture of the obstacle avoidance algorithm [64].
NASA's twin Mars Exploration Rovers (MERs), Spirit and Opportunity uses a local path planner (GESTALT) equipped with stereo cameras to evaluate terrain safety avoid obstacles [65]. Despite that GESTALT performed well when guiding the rovers around narrow and isolated hazards, it failed when clusters of closely spaced, nontraversable rocks form extended obstacles. To address this problem, a new technology was proposed at the Jet Propulsion Laboratory. According to which Field D* global path planner has been integrated into rover's software which allows simultaneous local and global planning during navigation. This resulted in better obstacle avoidance and navigation around hazards [66].
A comprehensive review paper about this issue can be found in [67]. The paper introduces major milestones in the development of computer vision for autonomous vehicles over the last decades. Besides, it discusses the design and performance of computer vision algorithms used on Mars in the NASA/JPL Mars Exploration Rover (MER) mission. The paper reveals that the MER mission has been achieved far beyond its primary objectives. The three computer vision algorithms developed for the mission, namely: stereo vision, visual odometry for the rover, and feature tracking for the lander. Despite the limitations of processors deployed, they performed consistently and made significant contributions to the project.
This section details the algorithms and method using mapless strategies for vision-based robot navigation. To summarize this approach, it can be stated that mapless strategies do not require any explicit representation of the working environment where navigation is to occur.
Principally, these strategies involve recognizing objects found in the environment or tracking those objects using visual clues or observations. Alternatively, motion estimation techniques are widely used in this category. Section two, on the other hand, addresses the strategies using or constructing map for navigation. First, map-based techniques have been introduced which basically employs geometric models or topological maps of the environment. Despite providing fast, robust, and consistent solutions to many problems, they are highly dependent on static maps of working environments which limits the operational capability of the algorithms in this group. Finally, map-building-based strategies have been discussed in which sensors are used to construct geometric models or topological model of the environment. These maps are then used to navigate the robot through corresponding environments. Map-building-based strategies can allow autonomous vehicles to navigate through dynamic environments. However, algorithms used in this group cost a lot of time and effort to obtain a robust model of the environment. Besides, vision-based modelling is challenging, comparing with other sensor systems.
Overall, despite challenges in designing and implementation, mapless strategies developed so far resemble human behaviour more than other approaches and have become applicable to any indoor environment consisting of corridors and doorways.
4. Conclusions
Vision is potentially the most powerful sensing capability in providing reliable and safe navigation. Vision-based navigation techniques are fundamentally classified based on localization techniques. This paper has surveyed each group individually, and as well as vision-based obstacle avoidance techniques are placed under a new section. This paper, inspired from two detailed literature study [5, 6], is essentially the selection of the most outstanding contributions surveyed in the area of vision-based robot navigation. One of the most important differences of this study is that this paper mainly focuses on mapless navigation strategies which are not highlighted and detailed in previously published surveys. Table 1 shows an overview and the most outstanding publications referenced in this survey.
Summary of milestones in visual navigation.
