
Abstract
Data aggregation techniques have been proposed for wireless sensor networks (WSNs) to address the problems presented by the limited resources of sensor nodes. The provision of efficient data aggregation to preserve data privacy is a challenging issue in WSNs. Some existing data aggregation methods for preserving data privacy are CPDA, SMART, the Twin-Key based method, and GP2S. These methods, however, have two limitations. First, the communication cost for network construction is considerably high. Second, they do not support data integrity. There are two methods for supporting data integrity, iCPDA and iPDA. But they have high communication cost due to additional integrity checking messages. To resolve this problem, we propose a novel Hilbert-curve based data aggregation scheme that enforces data privacy and data integrity for WSNs. To minimize communication cost, we utilize a tree-based network structure for constructing networks and aggregating data. To preserve data privacy, we make use of both a seed exchange algorithm and Hilbert-curve based data encryption. To support data integrity, we use an integrity checking algorithm based on the PIR technique by directly communicating between parent and child nodes. Finally, through a performance analysis, we show that our scheme outperforms the existing methods in terms of both energy efficiency and privacy preservation.
1. Introduction
With the proliferation of advanced technologies of mobile devices and wireless communication, wireless sensor networks (WSNs) are increasingly attracting interest from both industry and research institutes [1–3]. Because sensor nodes have limited resources (i.e., battery and memory capacity), data aggregation techniques have been proposed for WSNs [4–9]. However, the wireless communication can be overheard, and consequently data privacy in sensor networks is a crucial issue. Although data aggregation schemes that preserve data privacy have been proposed, they have the following limitations. First, the communication cost for network construction and data aggregation is considerably expensive. Second, the existing schemes do not support data integrity due to communication loss. Since the existing privacy-preserving schemes do not support privacy preservation and integrity protection simultaneously, it is necessary to carefully design an effective data aggregation scheme for recent applications of WSNs, such as military and environmental monitoring, where both privacy and integrity of the sensed data should be provided [10].
To resolve these problems, we propose a new energy efficient and privacy preserving data aggregation scheme in WSNs. To reduce the communication cost for preserving data privacy, we propose a seed exchanging algorithm for data aggregation. The seed generated by this algorithm is used not only to conceal the sensed data but also to preserve data privacy without additional message exchanges during the data aggregation step. For data privacy preservation, we also utilize a Hilbert-curve based technique, where it is difficult to obtain the actual sensed data, even if attackers try to overhear it, because the data being sent can be changed by using a unique Hilbert value. For providing data integrity, we propose an integrity checking algorithm based on a private information retrieval (PIR) technique. Upon receiving aggregated data from child nodes, a parent node starts an integrity checking algorithm in which the parent node generates a message based on the PIR technique by multiplying two large prime numbers. By sending a PIR message to child nodes, the parent node can verify the aggregated data. Our integrity checking algorithm is more efficient than the existing schemes since it checks the data integrity between child and parent nodes, instead of checking all data during the communication. Therefore, our scheme requires low communication cost and yields an accurate aggregate result even in reasonably dense networks.
This paper is organized as follows. In Section 2, we present related work on privacy preserving aggregation schemes in WSNs. In Section 3, we provide both considerations and attack models for designing an efficient privacy preserving aggregation scheme. In Section 4, we propose a new privacy preserving data aggregation scheme including a seed exchange algorithm in WSNs. In Section 5, we present a performance analysis of our scheme. Finally, we draw conclusions and suggest future work in Section 6.
2. Related Work
In this section, we present the existing data aggregation schemes for supporting data privacy and data integrity in WSNs. Privacy preserving data aggregation schemes include CPDA, SMART, Twin-key, and GP2S. He et al. [11] proposed a Cluster Based Private Data Aggregation (CPDA) method in which a cluster header aggregates data from cluster members. The CPDA method first constructs clusters to perform intermediate aggregations. All nodes include a head node within a cluster and then share M public seeds, where M is the number of cluster members. Next, each node generates
He et al. [15] also proposed iPDA and iCPDA schemes to support integrity checking in WSNs, by extending their previous schemes, SMART and CPDA, respectively. To the best of our knowledge, the schemes are the first to address both privacy preservation and integrity protection for data aggregation in WSNs. The iPDA scheme utilizes the data slicing and assembling technique of SMART to preserve data privacy. It protects data integrity by utilizing a node disjoint between two aggregation trees rooted at the query server, where each node belongs to a single aggregation tree. When the aggregated data from both aggregation trees are compared, the query server accepts the aggregate result if the difference in the aggregated data from the two aggregation trees does not deviate from the predefined threshold value. Otherwise, it ignores the aggregated result by considering it as polluted data. However, iPDA has some shortcomings. First, it is impractical to compare aggregated values of two node-disjoint aggregation trees, because it cannot be expected that all nodes will reply to all requests, due to the unreliability of a WSN. Second, for a secure communication channel from adversaries, all sensor nodes use secret keys to encrypt their all data slices before sending it to their
It is thus necessary to design a new data aggregation scheme that supports both data privacy and data integrity. The new scheme should be reliable and efficient in terms of energy consumption, propagation delay, and the accuracy of the aggregated result.
3. Design Considerations
In this section, we present requirements for a data aggregation scheme to support both data privacy and data integrity. The desired data aggregation scheme should satisfy the following criteria.
Data privacy: privacy concern is one of the major obstacles to civilian applications for wireless sensor networks. Curious individuals may attempt to gather more detailed information by eavesdropping on the communications of their neighbors. It is increasingly important to develop data aggregation schemes to ensure data privacy against eavesdropping. Data integrity: since data aggregate results may be used to make critical decisions, a base station needs to guarantee the integrity of the aggregated result before accepting it. Therefore, it is crucial that data aggregation schemes can protect the aggregated results from being polluted by attackers. Efficiency: data aggregation achieves bandwidth efficiency through in-network processing. In integrity-protecting private data aggregation schemes, additional communication overhead is unavoidable to achieve additional features. However, the additional overhead must be kept as small as possible. Accuracy: an accurate aggregate result of sensed data is generally desired. Therefore, we should take accuracy as a criterion to evaluate the performance of integrity-protecting private data aggregation schemes. When accurate aggregate results are needed, schemes based on randomization techniques are not applicable.
On the other hand, there exist multiple potential attacks against a data aggregation scheme. Some attacks aim at disrupting the normal operation of the sensor network, such as routing attacks and denial of service (DoS) attacks. A number of previous efforts have addressed these behavior-based attacks. In this paper, our major concern is the types of attacks that try to break the privacy and/or integrity of aggregate results, rather than worrying about those attacks. We assume that a small portion of sensor nodes can be compromised and focus on the defense of the following categories of attacks in wireless sensor networks.
Eavesdropping: in an eavesdropping attack, an attacker attempts to obtain private information by overhearing transmissions over its neighboring wireless links or colluding with other nodes to uncover the private information of a certain node. Eavesdropping threatens the privacy of data held by individual nodes. Data pollution: in a data pollution attack, an attacker tampers with the intermediate aggregate result at an aggregation node. The purpose of the attack is to make the base station receive a wrong aggregate result with large deviation from the original result, which leads to improper or wrong decisions. In this paper, we do not consider the attack where a node reports a false reading value, and we assume that the impact of such an attack is usually limited. By using privacy preservation measures, individual sensory data are hidden. However, not only the sensory data but also the aggregated value of a small group of sensors must be in a reasonable range. This implies that if a malicious user pollutes the individual sensory data (at a lower level in the aggregation tree), it can be easily detected since this introduces a large deviation from the original data. Therefore, a more serious concern is the case where an aggregator close to the root of the aggregation tree is malicious or compromised.
In this paper, our goal is to design a reliable and efficient data aggregation scheme in terms of energy consumption, propagation delay, and accuracy of the aggregated result by following these design considerations.
4. Data Aggregation Scheme to Enforce Data Privacy and Data Integrity
In this section, we present a novel Hilbert-curve based data aggregation scheme that supports both privacy preservation and integrity protection for wireless sensor networks. In order to support data privacy, we first provide a data privacy preserving algorithm by using sensor nodes' seeds and Hilbert-curve values. A seed exchange algorithm is applied to reduce the number of messages during data aggregation. In order to support data integrity, we provide a private information retrieval (PIR) [16–19] based integrity checking algorithm that communicates between a child node and its parent node by exchanging a PIR message and its response message.
4.1. Privacy Preserving Algorithm
For wireless sensor networks, we provide a novel privacy preserving algorithm by using a Hilbert-curve technique [20] and seed exchanges among sensor nodes. Our privacy preserving algorithm is performed through three phases: a network construction phase, a data encryption phase, and a data transmission phase. In the network construction phase, each node determines its sibling nodes, parent node, and child nodes by sending broadcast messages. Each node exchanges a seed to other nodes among its sibling nodes. In the data encryption phase, each node changes the sensed data into a value by using its generated seed and the received seeds. The changed value is encrypted by the Hilbert-curve algorithm. Finally, in the data transmission phase, each sensor node sends the aggregated data to a parent node where all the data from child nodes are merged with its encrypted data. A sink node aggregates all data of sensor nodes in the network. We explain each step in detail in the following.
4.1.1. Network Construction Phase
Our privacy preserving algorithm chooses a tree-based topology to perform intermediate aggregations. Note that we do not use a clustering-based topology because it is affected by the communication range between cluster heads and it suffers from a large amount of messages for constructing network. First, a sink node triggers a query by sending a HELLO message generated from a message flooding scheme [21], as shown in Figure 1(a). Upon receiving the HELLO message, a sensor node determines whether the HELLO message is from the sink node or not. If a sink node is located within its communication range, the sensor node receives the HELLO message from the sink node and sets the sink node as a parent node. Otherwise, the sensor node waits for a certain period of time to receive the HELLO message from its sibling nodes and then selects one of the sibling nodes as a parent node by broadcasting a JOIN message. The sink node forwards the HELLO message to its sibling nodes with its corresponding level (Figure 1(b)).
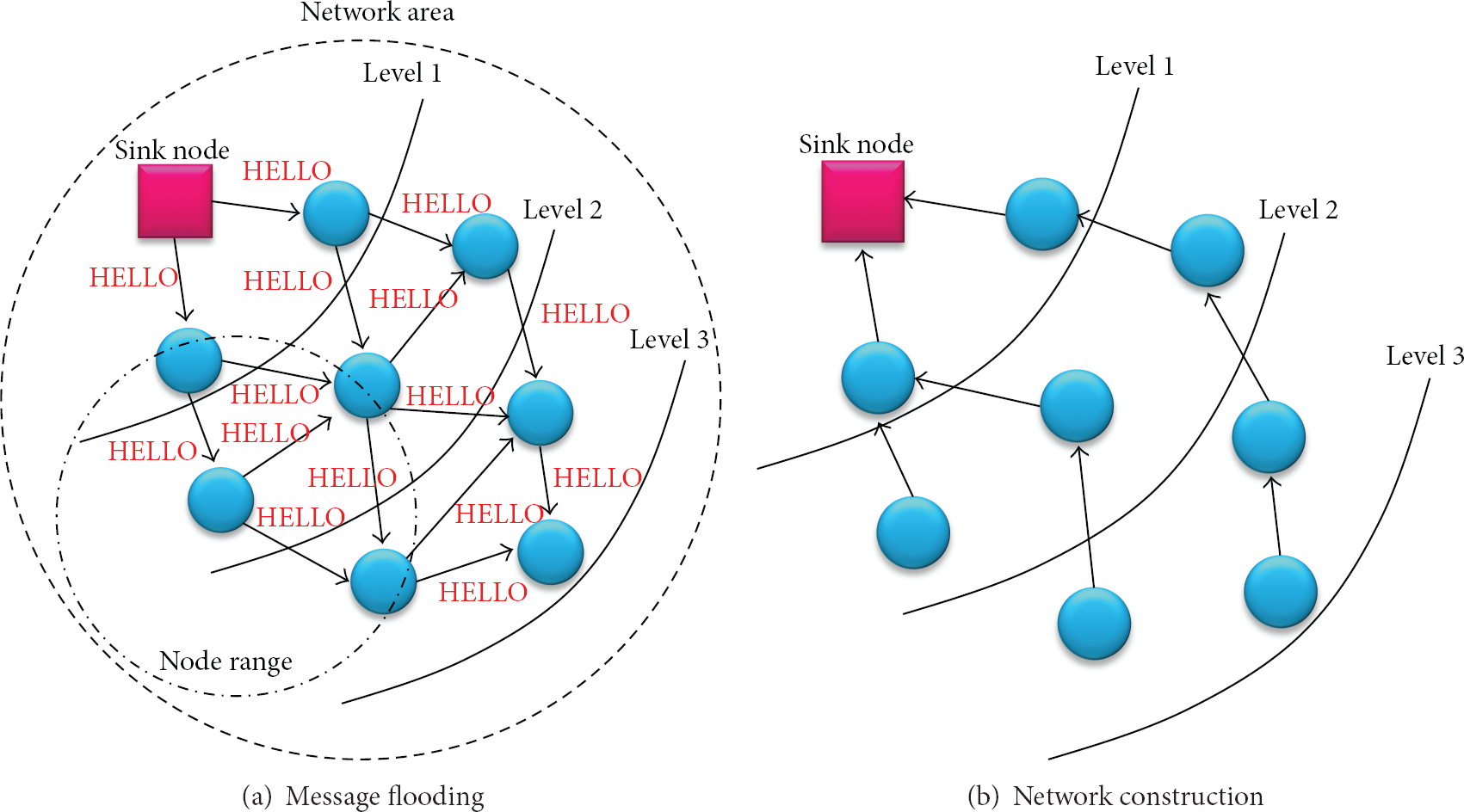
Network construction.
In this procedure, we set the maximum number of child nodes so as to avoid network imbalance. If the network has imbalance, the sensor node of the imbalanced area may consume more energy than the other areas. Therefore, we define the maximum number of child nodes as given below.
Definition 1.
Let the Error Rate be the average rate of message loss from a sensor node, and let a weight (α) be a value for the density of a sensor network. The maximum number of child nodes C is defined by the following equation, where Network Area is the size of the network and Communication Range is the communication boundary reachable from a sensor node

(1) If (A node is Sink node) { (2) Flooding(initLevel, base_stationID);exit;} (3) Wait until receiving HELLO message; (4) If (a node receives message from a sensor node)
4.1.2. Data Encryption Phase
After constructing a sensor network, each node generates random seed data for seed exchange. For this, we utilize an elliptic-curve key exchange algorithm that exchanges its own data by using a public elliptic curve, an arbitrary point, and its secret constant key. Figure 2 shows the flow of the elliptic key exchange algorithm. First, a source node and its neighboring node (receiving node) set a private constant key, for example, pSender and pReceiver. Second, each node makes a result R by multiplying an arbitrary point (E) and the private constant key having a public elliptic curve. Third, each node transmits the result R to the neighboring node. Finally, it calculates the seed data by multiplying R with its private constant key. The seed data are the sum of x-coordinate and y-coordinate, because the elliptic curve is a 2-dimensional equation. Because the elliptic key exchange algorithm allows each node to communicate without unnecessary messages, its own data can be protected from an attacker during communication.
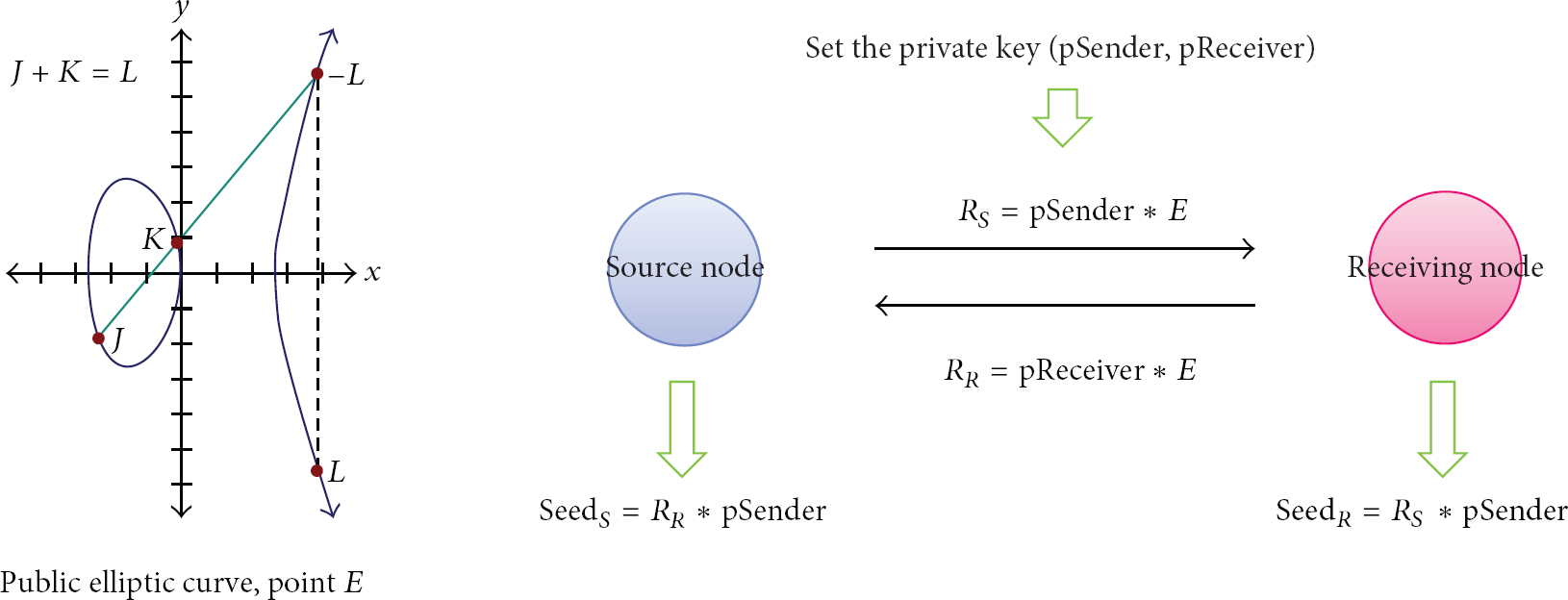
The overall flow of the elliptic key exchange algorithm.
The seed is used for hiding the original data from an adversary. The principle underlying our seed exchange method is as follows. The original data can be changed by extracting some part of a seed value, which is sent to other nodes. Some part of the seed value is also added from another node. As a consequence, the sensed data can be hidden among seed exchange group members. The following equation shows the final sending value from each node for data aggregation, where m is the number of seeds received from other nodes. Figure 3 shows a sensed data encryption result on each sensor node after exchanging a seed:
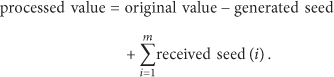
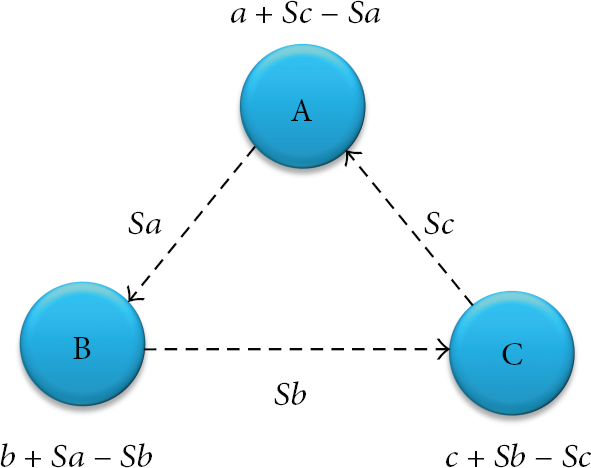
Original data change by seed exchange from three nodes.
To process a user's query, a parent node aggregates its changed data and all data received from its child nodes. Next, the parent node transforms the aggregated result into two-dimensional encrypted data by using the Hilbert curve [15]. The Hilbert curve, which was proposed by G. Peano, transforms N-dimensional data into 1-dimensional data. The Hilbert curve is a continuous fractal space-filling curve that gives a mapping between 1D and 2D space to preserve locality. The coordinates of a point (x, y), that is, projected to the unit square can be changed into a distance value from the start point to this point. To adapt the Hilbert curve to our algorithm, we assume that each sensor node transforms the one-dimensional sensed value into two-dimensional data. Here, the one-dimensional value is the aggregated value after applying the seed exchange algorithm for each node group. The two-dimensional data are the coordinate of the aggregated value along with the Hilbert curve in

Example of data encryption.
4.1.3. Data Transmission Phase
In the data transmission phase, each node sends the encrypted data to its parent node. The parent node then analyzes the encrypted data (e.g., key, curve direction, and curve level), that is received from the child node. If the curve direction and level of its child node are different from its own curve direction and level, the node should transform the received value based on its curve direction and level. In this way, a sink node aggregates all of the encrypted data from the hierarchy of nodes. To avoid communication loss of wireless sensor networks, we utilize a Time Division Multiple Access (TDMA) method [22] for data transmission. Definition 2 explains the principle to decide the start time of data transmission. Each child node sends the encrypted data at its own transmission time. Algorithm 3 shows our data aggregation algorithm. We start data aggregation from leafNode (lines 1~2). For aggregation, an intermediate node (InternalNode) can receive the data from its child node and reencrypt the data with its own data (lines 3~11). In this way, all encrypted data of sensor nodes reach a sink node. Finally, the sink node sends the aggregated data to the service client (lines 12~15).
Definition 2.
Assume that child nodes are

4.2. Integrity Checking Algorithm
Our integrity checking algorithm is performed through three phases: a PIR message construction phase, a PIR response phase, and an integrity checking phase. In the PIR message construction phase, upon receiving the encrypted data from a child node, the parent node constructs a PIR message and sends the message to the child node to check data integrity. In the PIR response phase, a child node responds with a result message by calculating row values based on the PIR message received from its parent node. Finally, in the data integrity checking phase, the parent node checks whether the data from its child node are valid by comparing two values, that is, the first received value and the second value.
4.2.1. PIR Message Construction Phase
A parent node generates a PIR message to verify the value processed from its child node. The PIR technique was proposed to guarantee the exact result without revealing a client's desired information [18]. For this, it partitions the whole data space into a regular grid of
Definition 3.
A set of QR and QNR.
Let

However, the PIR technique is not suitable for sensor networks because its communication cost is very high while sending the whole domain partitions. To adapt the PIR technique to our algorithm, it is necessary to downsize the
Algorithm 4 shows our PIR message construction algorithm. First, a parent node randomly selects a subtracted value x and calculates a modified value y (line 1). Second, the node converts y into two-dimensional data (line 2). Third, the parent node selects large prime numbers p and q in order to obtain the set of QR and QNR. A cell whose Hilbert ID is the same as the modified value y is set to be QNR and the others are set to be QR (lines 3–9). Finally, the node sends x and the group of the QR and QNR values (line 10).
4.2.2. PIR Response Phase
In the PIR response phase, a child node makes a response message by using both its processed data and the PIR message from its parent node. First, the child node finds a Hilbert value that is the same as the modified value y by subtracting x from the original data. A PIR response message consists of k values that represent k number of rows in
Definition 4.
Assume that the data set of row

The representative value of each cell can be calculated by using (6) based on Definition 3 and Jacobi Symbol

Algorithm 5 shows our PIR response message construction phase. First, a child node extracts x from its processed value (line 1). Second, the child node finds the Hilbert ID of the result (lines 2-3). Third, the child node generates
4.2.3. Integrity Checking Phase
In the integrity checking phase, a parent node analyzes the PIR response message and determines whether the received data from its child node is valid. The parent node checks the QR and QNR of the received data by using the selected two prime numbers (in the second phase) and Jacobi symbol. If the received data are valid, there exist
4.3. Example
To protect both data privacy and data integrity, our scheme performs six phases: network construction phase, data encryption phase, PIR construction phase, PIR response phase, data integrity checking phase, and data transmission phase. In the network construction phase, each node sets the information of its sibling nodes, parent node, and child nodes. In Figure 5(a), a sink node A triggers a query by a HELLO message. Upon receiving the HELLO message, sensor nodes B and C determine whether the HELLO message is from the sink node. When B and C receive the HELLO message from A, they set sink node A as its parent node. And other sensor nodes, that is, D, E, F, G, and H, wait for a certain period of time to receive a HELLO message from its neighbors. Upon receiving the HELLO message from any node, the node selects one of the neighboring nodes as its parent node by broadcasting a JOIN message. Figure 5(b) shows the constructed sensor network. After constructing the network, each node exchanges a seed with one node among its neighboring nodes located within its communication boundary. Figure 3 shows the process of the seed exchange. Each node changes sensed data by using the generated seed and the received seeds. All sensor nodes calculate the seed for aggregation, that is,

Construction phase.
In the data encryption phase, the changed value is encrypted by a Hilbert curve algorithm to send the sensed data (or aggregated data) to the parent node. By selecting the direction and the level of the Hilbert curve, we can encrypt it as a tuple of

Encrypted data for value 14 (direction = Bottom, level = 2).
In the data integrity checking phase, a parent node determines whether the data received from its child node are valid by comparing the first received value with the second value. For example, for the received data
5. Performance Analysis
In this section, we present performance results of both our scheme and existing schemes, in terms of communication overhead, data propagation delay, and integrity checking. For the experiment, we use a TOSSIM simulator [23] running on a TinyOS operating system [22] and a GCC compiler. We make use of 100 sensor nodes that are randomly distributed in a 100 m × 100 m area. As presented in directed diffusion, we use a receiving power dissipation of 395 mW and transmitting power dissipation of 660 mW. Table 1 shows our environment for implementation and Figure 7 shows three types of sensor node distributions for the experiment.
Environment for implementation.

Our PIR message structure.


Three types of sensor node distributions.
5.1. Experimental Results with Data Privacy Preserving Schemes
We compare our Hilbert-curve based data aggregation scheme (HDA) with CPDA, SMART, Twin-Key, and GP2S, in terms of the number of transmission messages and the average lifetime of the sensor nodes. Here, the number of sensor nodes ranges from 10 to 100. Figure 8 shows the communication overhead with respect to a varying number of sensor nodes. The number of transmission messages in all schemes is increased as the number of sensor nodes increases. This is because when the number of sensor nodes is large, every sensor node in the WSN is capable of sensing data and hence a large number of messages should be transmitted. However, our scheme outperforms the existing schemes by about 10%–20%. The reason for this is that our scheme does not need to generate unnecessary messages during data aggregation since each sensor node can transform only its own data whereas the existing schemes require an additional message for privacy preservation. Figure 9 shows the number of transmission messages with respect to different distributions of sensor nodes. Figure 10 shows the number of transmission messages with a varying communication boundary when the number of sensor nodes is 100. In both figures, our scheme outperforms the existing schemes because it does not require unnecessary messages in all the cases. In particular, our scheme, SMART, and GP2S show consistent performance regardless of the type of distributions and the communication boundary. This is because they are less affected by the placement of sensor nodes owing to the use of a tree topology. Meanwhile, CPDA and Twin-Key are strongly influenced by both the type of distributions and the communication boundary, because they make use of a clustering method.

Number of transmission messages with varying number of nodes.

Number of transmission messages with respect to distributions of sensor nodes.

Number of transmission messages with respect to communication boundary.
Figure 11 shows the average lifetime of the sensor network with varying number of sensor nodes in the WSN. In this analysis, we measure the time until the number of sensor nodes, whose energy is completely consumed, is greater than 50% of all sensor nodes. The lifetime of all the schemes decreases as the number of sensor nodes increases. This is because the number of messages generated in the network is proportional to the number of messages required for data aggregation. However, the lifetime of our scheme becomes 100%~125% longer than those of all the existing schemes, because our scheme can reduce unnecessary messages during data aggregation.

Lifetime of sensor network with varying number of nodes.
5.2. Experimental Results with Data Integrity Schemes
We compare our data integrity validation HDA scheme (iHDA) with iCPDA and iPDA in terms of the number of transmission messages per query round, the average lifetime of sensor nodes, and the attendance ratio of sensor nodes. Figure 12 shows the communication overhead with respect to varying number of sensor nodes in a WSN. The number of transmission messages for iPDA, iCPDA, and our scheme is increased as the number of sensor nodes increases. Our scheme outperforms the iPDA and iCPDA schemes because the existing schemes generate unnecessary messages during data aggregation in the network. That is, each sensor node generates only two additional messages for privacy preservation and integrity checking in our scheme whereas the iPDA and iCPDA schemes generate six and four messages, respectively. Due to numerous messages exchanges among sensor nodes, there is a high rate of data collisions in the existing schemes. Therefore, the iPDA and iCPDA schemes are very expensive in terms of communication overhead because the number of messages generated in the network is very large for successful data transmission. Figure 13 shows the average lifetime with respect to varying number of sensor nodes in the WSN. The dissipated energy for all three schemes is increased as the number of sensor nodes increases. This is because every message generated in the network requires energy to reach the sink node. However, in terms of lifetime, our scheme shows 35~130% better performance than iPDA and iCPDA schemes. The reason is that the iPDA and iCPDA schemes generate too many unnecessary messages for data aggregation to enforce both integrity protection and privacy preservation. In the existing schemes, every sensor node becomes active to send its messages for a longer time.

Number of messages generated by iPDA, iCPDA, and our scheme.

Average lifetime for each sensor node.
Figure 14 shows the attendance ratio of sensor nodes for data aggregation. During data aggregation, a sensor node sends the sensed data (or aggregated data) to its parent node. The attendance ratio of sensor nodes in our scheme is about 100% whereas both iPDA and iCPDA have some sensor nodes that do not take part in data aggregation. Because a given sensor node in the iPDA and iCPDA schemes has to communicate with at least six and two neighboring nodes, respectively, some sensor nodes cannot participate in data aggregation. Therefore, our scheme shows the best performance among the three schemes.

Attendance ratio of sensor node for data aggregation.
6. Conclusion and Future Work
Recently, as advanced technologies of mobile devices and wireless communication proliferate, wireless sensor networks (WSNs) have increasingly attracted interest from various applications including military and environmental monitoring. Moreover, since sensor nodes have limited resources, such as battery and memory capacity, many data aggregation techniques have been proposed for WSNs. However, the wireless communication can be easily overheard, and thus the provision of a data aggregation scheme to support data privacy is a challenging issue in WSNs. Although several data aggregation schemes have been proposed to preserve data privacy, they have the following limitations. First, the communication cost for network construction and data aggregation is considerably expensive. Second, only a part of the existing methods supports data privacy. In addition, it is necessary to assure that the aggregated data are not polluted by an unauthorized third party. For this, we propose a new data aggregation scheme for enforcing both data privacy and data integrity in WSNs. Our scheme makes use of a seed exchanging algorithm to reduce the communication cost for preserving data privacy. It also utilizes an integrity checking algorithm based on a private information retrieval (PIR) technique. From our performance analysis, we show that our HDA scheme achieves 100%–300% longer network lifetime and about a 10% better attendance rate for the aggregated data than the existing privacy preserving schemes. In addition, our iHDA scheme achieves 40%–160% better performance in terms of network lifetime and about a 16% better participation rate for the aggregated data. As future work, we plan to verify that our scheme is efficient in WSNs by applying it to a real environment.
Footnotes
Acknowledgments
This research was supported by Sharing and Diffusion of National R&D Outcome funded Korea Institute of Science & Technology Information (KISTI) (K-13-L02-C02-S02). And this research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (2010-0023800).