
Abstract
In many surveillance application scenarios of wireless video sensor networks (WVSNs), a number of video sensors are deployed, and multidimension monitored the visual information in a region of interest, forming multiview videos. Since the power, computing capability, and bandwidth are very limited in WVSNs, the conventional multiview video coding method is no longer applicable. So multiview distributed video coding (MDVC) emerged and developed rapidly. In this paper, we propose a new multiview video coding and postprocessing framework for multiview videos. First, in coding scheme, motion intense regions (MIRs) and nonmotion intense regions (NMIRs) based on sum of absolute difference (SAD) criteria are distinguished. For the MIR, the side information (SI) is generated by fusion temporal SI and interview spatial SI at the pixel level. But for the NMIR, the temporal SI is directly use as the ultimate SI. Then, to further improve the quality of the decoded image, an image postprocessing scheme is designed by using deblocking and deringing artifact filters on decoded image. Finally, a set of experimental results show that the proposed fusion SI approach can bring improvements up to 0.2–0.5 dB when compares with only temporal SI used. The subsequent decoded videos postprocessing simulation proves that the proposed postprocessing scheme can provide an additional improvement of about 0.1 dB to the decoded video sequences.
1. Introduction
Nowadays, with the rapid development of wireless communication and microelectronics technologies, a series of devices and systems relevant with wireless network and video techniques, such as wireless video sensor networks (WVSNs), wireless IP camera, mobile video phone, dense camera arrays, satellite communication systems, and television systems for multiview virtual meeting, have wide application prospects. These kind of video equipment or systems have a common feature, that is, the computing, data storage, and power consumption capacity are all limited, but all abilities in receiving ends are very powerful. Meanwhile, along with the demand for high-quality multimedia/video surveillance, environmental monitoring, and industrial process control, and more and more video sensors are used in WVSNs. In WVSNs, a number of video sensor nodes are deployed and multidimension shot visual information in a region of interest. As a result, the visual information retrieved from adjacent video senor nodes is called multiview video, which usually exhibit high levels of correlation and give rise to considerable data redundancy in the network.
In fact, multiview video is a kind of video, which has interactive manipulation functions and stereoscopic impression. It is the video record acquired from video sensors placed under a particular array in a same scene and provides the capability of scene roaming and viewpoint selection for users. Since all video sensors shoot the same scene from multiple views, the video network contains a large number of interview statistical dependencies, high-quality images/videos could collect by combining intraview (motion estimation), and interview prediction (disparity estimation). Although the multiview video technology provides a richer viewing experience than traditional video technology, it needs to deal with a huge amount of data, and this brings new challenges to the data compression. Traditional video coding standards, such as MPEG-x and H.26x [1], mainly rely on the hybrid architecture, and encoder uses motion estimation to fully exploit the video sequences of time and spatial correlation information. Since the heavy computing burden of the motion estimation and compensation task in these video compression standards, the encoder is overwhelmingly more complex than the decoder; for example, the H.264/AVC encoder/decoder complexity ratio is in the order of 10 for basic configurations and can grow up to 2 orders of magnitude for complex ones [2, 3]. So traditional standardized video coding technologies are difficult to meet the low-complexity coding of the new video application in WVSNs.
To address this above requirement, distributed video coding (DVC) which first practical schemes proposed in [4, 5] is a solution because it is based on Slepian-Wolf [6] and Wyner-Ziv theories [7] and relies on a new statistical framework, instead of the deterministic approach of conventional coding techniques. DVC allows shifting the complexity from the encoder to the decoder and encoding with very low complexity then gives the decoder the task to exploit the source statistics to achieve efficient compression. DVC is also well suited for camera/video sensor networks, where the correlation across multiple views can be exploited at the decoder, without communications between the cameras/video sensor nodes [8]. This kind of coding scheme for multiview distributed videos is called multiview distributed video coding (MDVC).
No matter the conventional DVC or MDVC is, the side information (SI) generation is the key link in coding framework. But different from traditional monoview DVC, the SI generation of MDVC can be computed not only from previous and next decoded frames in the same view but also from frames in other spatially proximal views. Meanwhile, DVC and MDVC as source compression and coding scheme transform coding have over the years emerged as the dominating compression strategy. Transformations are decomposition and representation of the image information. Energy of transformed image focused on the transform domain determines the object of quantization coding, which is the core part of image and video coding. However, the transformation itself will not bring about distortion and losses of image information. The distortion segment of image and video coding is quantization process. In traditional image and video coding, standards such as JPEG and JPEG 2000 and video compression standards such as H.26x, the discrete cosine transformation (DCT), and quantization based on divided image blocks all lead to coding effect. So in this paper, we study the MDVC coding and propose a new MDVC framework, which is constituted by video coding scheme and image postprocessing scheme in WVSNs. Our main contributions include the following.
Based on the video sensor characteristic of WVSNs, we present a new MDVC scheme, which not only contains the temporal SI fusion but also includes the spatial SI fusion method.
For distortion issue caused by quantization processing of image and video coding, to further improve the quality of decoded video, image postprocessing based on spatial, using deblock effect and dering effect on the decoded video is designed.
The remainder of this paper is organized as follows. Section 2 discusses some previous works on DVC and MDVC which motivated our work. Section 3 introduces the proposed multiview distributed video coding scheme. Section 4 describes the image postprocessing scheme in the decoder. The performance evaluations of the proposed framework are presented in Section 5. Finally, conclusions and future work are derived in Section 6.
2. Related Works
DVC is the important application of distributed source coding (DSC) for video coding. The theoretical basis of DSC is Slepian-Wolf theorem [6] and Wyner-Ziv theorem [7]. Theory of Slepian-Wolf shows that even if correlated sources are encoded without getting information from each other, coding performance can be as good as dependent encoding if the compressed signals can be jointly decoded. Wyner-Ziv theory extends this conclusion to the lossy source coding with side information. The Slepian-Wolf and Wyner-Ziv theorems suggest that it is possible to compress two statistically dependent signals in a distributed way (separate encoding, joint decoding), approaching the coding efficiency of conventional predictive coding schemes (joint encoding and decoding). Based on these theorems, DVC has emerged and became a hot research topic rapidly [4, 5, 9–12]. The typical DVC solutions are Berkeley WZ video codec [4, 11] and Stanford WZ video coding architecture [5, 10]. The Berkeley WZ video coding solution is mainly characterized by block-based coding with decoder motion estimation, works at block level, and does not require a feedback channel; the Stanford architecture is mainly characterized by frame-based Slepian-Wolf coding, typically using turbo codes, and a feedback channel to perform rate control at the decoder.
Along with the rise of distributed camera/video network and the development of Multiview video coding, the architecture of DVC is considered using in multiview video coding [13–17]. In [13], DVC strategy is first extended to multiview video coding, and a more flexible side information generation algorithm considering both temporal and view-directional correlations is proposed to achieve high prediction accuracy. In [14], video sensors are arranged in an array to monitor the same scene from different view points. The impact of disparity fields at the central decoder and how to estimate the centralized disparity compensation at the decoder to improve the efficiency of the video sensor networks are discussed. In [15], based on multiview videos and DVC, a scheme for coding video surveillance camera networks is introduced. Then a new fusion technique between temporal side information and homography-based side information is proposed to improve the rated-distortion performance. In [16], based on WVSNs, a low-complexity video compression algorithm that uses the edges of objects in the frames to estimate and compensate for motion is put forward, and two schemes that balance energy consumption among nodes in a cluster on a WVSN are proposed. In [17], based on wireless multimedia sensor networks (WMSNs), a power-rate-distortion (PRD) optimized resource-scalable low-complexity multiview video encoding scheme is proposed, and resource allocation achieved at the encoder while optimizing the reconstructed video quality is discussed.
From the above existing works in DVC and MDVC, lots of outstanding accomplishments have achieved, but there are some shortcomings still existing; for example, some coding architectures need feedback channel to perform rate control at the decoder, which would result in a large amount feedback loops. Obviously, this is unrealistic when the sensor node scale of WVSNs is very tremendous. Another example, in the encoder, the type of the more than half of the encoded frames is traditional intracoded in current most MDVC schemes. The coding of these frames is complexity and inefficiency. Moreover, using the image postprocessing technique could effectively improve the quality of decoded video in decoder, which is rarely involved in existing MDVC scheme. Meanwhile, based on turbo or LDPC, the Wyner-Ziv frame of MDVC in all regions without distinction, the side information is all fused by the temporal SI and interview spatial SI.
For the above problems, in this paper, we propose an improved MDVC coding and postprocessing framework. First, in the encoder of main perspective, according to the Sum of absolute difference (SAD) criteria, we differentiate the motion intense regions (MIRs) and the nonmotion intense regions (NMIRs) of a raw video frame and encode severally. In the decoder, for the MIR, the side information (SI) is generated by fusion temporal SI and interview SI. But for the NMIR, we directly use the temporal SI, the scheme utilizes motion compensated temporal interpolation (MCTI) to generate temporal SI. After the above steps in frame SI generation, we process the image postprocessing of the single decoded frame. Then mix the decoded frames in order to produce the decoded video.
3. Proposed Multiview Distributed Video Coding Scheme
In this section, we present a new MDVC scheme for WVSNs. First, we introduce the principles of DVC, then the frame and coding structure, the temporal, and spatial SI calculation techniques based on SAD criteria, and SI mask fusion method of this proposed MDVC scheme is described.
3.1. Principles of DVC
As we know, the principles of DVC are Slepian-Wolf [6] and Wyner-Ziv [7] theorems. The rate boundaries defined by the Slepian-Wolf theorem for the independent encoding and joint decoding of two statistically dependent discrete random independent and identically distributed (i.i.d.) sources are illustrated in Figure 1.

Rate boundaries defined by the Slepian-Wolf theorem.
In Figure 1, X and Y are two i.i.d. random variables/sequences; that is, the raw signals,
Subsequently, Wyner-Ziv theorem extended the Slepian-Wolf theorem by characterizing the achievable rate-distortion region for lossy coding with SI. Wyner-Ziv theorem studied a particular case of distributed source coding, asymmetric coding, that deals with lossy compression of source X associated with the availability of the Y source at the decoder but not at the encoder, and Y (or a derivation of Y) is known as side information. A conclusion is derived that, typically, there is a rate loss incurred when the side information is not available at the encoder. But when performing independent encoding with side information under certain conditions, that is, when X and Y are jointly Gaussian, memoryless sequences and a mean-squared error distortion measure are considered. There is no coding efficiency loss with respect to the case when joint encoding is performed, even if the coding process is lossy. The structure of Wyner-Ziv codec is shown in Figure 2. Together, the Slepian-Wolf and Wyner-Ziv theorems suggest that it is possible to compress two statistically dependent signals in a distributed way, namely, separate encoding, joint decoding, approaching the coding efficiency of conventional joint encoding, and decoding predictive coding schemes. And in general, DVC uses Wyner-Ziv coding scheme as its lossy particular case [18, 19].

The structure of Wyner-Ziv codec.
3.2. Frame and Coding Structure of the Proposed MDVC
In this section, based on the sensor characteristic of WVSNs, we propose a feasible MDVC scheme, which could be regarded as an extension of conventional DVC. In a WVSN, video sensors are separated at certain distances and angles by each other. All nodes synchronized shoot the same scenario in an area of interest of WVSN, and the relevant video sequences are produced. Then the encoder, that is, the video sensor node, encodes the captured sequences in order independently. In encoder, MDVC does not use the complexity encoder for encoding, and interview does not perform data communication. It exploits the source statistics of intraview and interview to obtain high quality decoded video, so it is superior to traditional multiview coding. The frame and coding structure of the proposed MDVC scheme is shown in Figure 3. Multiview video frames are classified into two categories: key frames and Wyner-Ziv frames, noted by K and WZ, respectively. The

Successive timestamp frame structure for MDVC scheme in a WVSN.
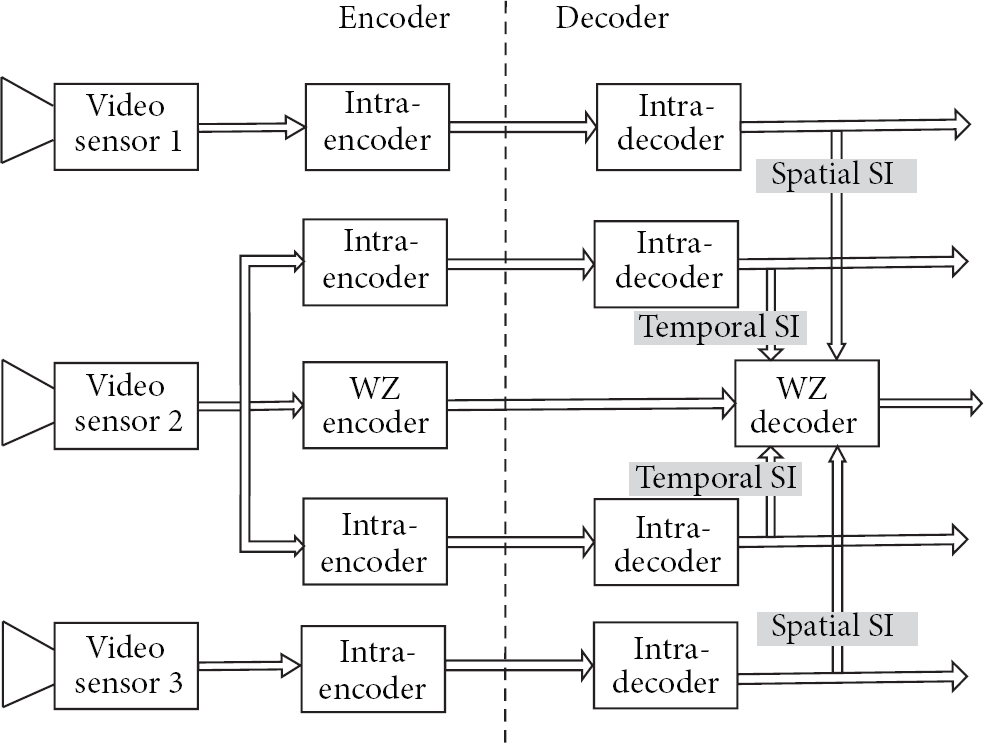
A sample of Wyner-Ziv frame coding scheme in MDVC.
3.3. MDVC Scheme Based on the SAD Criteria
The key technique of the MDVC is about exploiting both temporal and interview correlations in an efficient way. Most of the existing works on DVC/MDVC are based on on turbo or LDPC, the Wyner-Ziv frame coding in all regions without distinction, motion estimation techniques cannot accurately predict the area which are more intense exercise. The decoder needs to request more feedback information, thus not only the rate increases, but the decoded image is still not accurate enough. For this problem, we propose an improved MDVC scheme based on SAD criteria.
In some video sequences, motion vector of many macroblocks is equal to zero or very small, so only a small part of macroblocks has large moving. For the macroblocks with motion vector same as being zero or very small, motion compensated temporal interpolation (MCTI) can make a good predictive coding performance. While for other intense motion macroblocks, decoder needs to use information from other cameras. In the encoder of Wyner-Ziv frame, according to the SAD criteria, we can get the motion intense regions (MIRs) and the nonmotion intense regions (NMIRs). For the MIR, the side information is generated by fusion temporal side information and inter-camera side information at the pixel level. Inversely, for the NMIR, we directly use the temporal side information. Encoder uses SAD criteria to get MIR and NMIR macroblock and mark the MIR macroblock. Suppose that

The detailed block diagram of the encoder/decoder of the proposed MDVC Scheme based on SAD criteria is illustrated in Figure 5. We use two video sensor views to present the encoding and decoding process of Wyner-Ziv frames for brevity. The K frames of the second view are encoded and decoded by conventional intraframe scheme, while for the WZ frames, according to the SAD criteria, we get MIR (
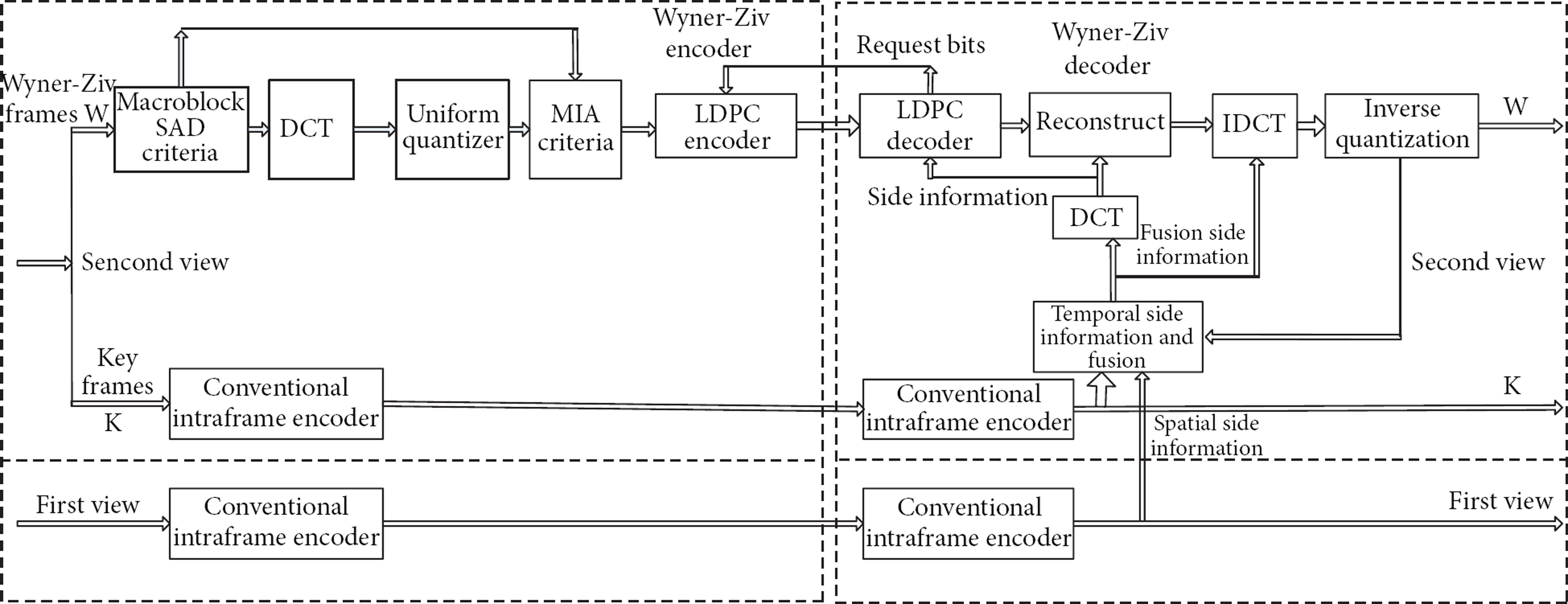
Block diagram of the encoder/decoder of the proposed MDVC Scheme based on SAD.
3.4. Side Information Generation by Fusing
Unlike DVC, the generation of SI in MDVC must synthetically consider the temporal SI and interviews spatial SI. In this paper, for the temporal SI, we choose to use motion compensated temporal interpolation (MCTI) technique estimating temporal motion vector from the previous frame towards the forward frame. Then, the motion vectors are interpolated at midpoint to generate the SI [13, 15].
For the interviews spatial SI, in the scene of WVSN, all nodes synchronized monitor the same scenario in an area of interest, and the video sensor network contains a large number of interview statistical dependencies. The position and view of the cameras have been fixed; homography matrix [20] could be used to generate the interview SI from other cameras. The homography is a

Harris corner and edge detector [22] also could be used in iteratively calculating and adjusting the parameters in homography of two video sensor nodes. Then, we can use homography to generate the spatial SI of the Wyner-Ziv frame in adjacent sensor view.
When the temporal SI and spatial SI of a preparing Wyner-Ziv frame have generated, we present a binary masks fusion method to generate SI according the MIR or NMIR type of macroblocks transmitted from encoder. Figure 6 shows how to fuse the binary masks from two interview sensors, which is done by a simple logical OR operation. We look for the pixel that predicts Wyner-Ziv frame better from both side information. In binary mask, 0 represents that the pixel from the same position of interview SI is reliable and 1 represents that the pixel from the same position of temporal SI is reliable. In the fusion process of the MIR, we take a simple difference operation between the current pixel from the previous key frame and the pixel an the same position from interview SI to obtain a value of A and take a simple difference operation between the current pixel from the previous key frame and the pixel at the same position from Temporal side information to obtain a value of B. If

Side information fusion of Wyner-Ziv frame in decoder.
4. Decoded Image Postprocessing Based on Spatial Domain
In Wyner-Ziv DVC and MDVC, quantification is a significant step. But the quantization matrix or quantization coefficient adopted in quantization process would affect the quality of image decoding. In image processing, the most common divided blocks processing technique, discrete cosine transforms (DCT), and quantization could lead to coding artifacts, such as blocking and ringing artifacts. In this section, we try to conduct the image postprocessing for the video decoded from the proposed MDVC by using filtering techniques.
4.1. Deblocking Filter
The quantization process for DCT coefficients causes the blocking effect during image and video coding. Because the quantization error is different in each block, the coding based on blocks, for example,
The algorithm of deblocking filter along the border of the
To eliminate the blocking effect more powerful, in this paper, according the satisfied condition of near pixels at the border of
Suppose that

where

If present pixels
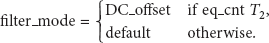
Suppose that
4.2. Deringing Effect Filter
The coarse quantification of the high-frequency components of image results in ringing effect. If high-frequency components, which corresponding to the strong edges of image, such as high contrast, occur quantization error, the nearby region of the strong edges would appear to be fake edge. The core of the ringing effect eliminating algorithm is how to distinguish the ringing and real edge. The most common method is examining the edge of image first, then using low-pass filter screening the no-edge pixels to achieve the objective of eliminating ringing effect.
The deringing effect filter includes threshold determination, identifier evaluation and adaptive smoothing. Every pixel in
In threshold determination module, first, we divide the
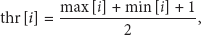

Calculate the dynamic range of 4 luminance blocks, and number the block, which has maximum dynamic range; as
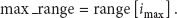
Revise the threshold of 4 smaller blocks by (9). Consider

In identifier evaluation module; after threshold determined, the following operations are all in original
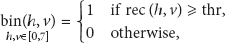
where
Adaptive smoothing module is constituted by adaptive filtering and numerical pruning two parts. Calculate the binary identifiers of all the pixels in the 3×3 window, whose center is current pixel. If all binary identifiers are “1” or “0”, this region is smoothed area, so to filter this current pixel by smooth filtering. The reconstructed value after filtering

where
In order to prevent excessive handling of pixel, the gray level difference

where OP denotes quantization parameter and
5. Performance Evaluation
In this section, we design some simulations to evaluate the effectiveness of the proposed coding and postprocessing framework by using public and representative multiview video sequences.
We use the two multiview sequences: “Exit” and “Vassar” which are made public available by Mitsubishi Electric Research Laboratories (MERL) [23]. For reasons of computation complexity, the spatial resolution was halved from VGA (
To evaluate the rate-distortion performance of our proposed scheme, we compare the following five schemes:
H.263+ “I-I-I-I”: H.263 intraframe coding (I-I-I-I). H.263+ codec uses TMN8 [26].
H.263+ “I-P-I-P”: H.263 interframe coding (I-P-I-P). Like H.263+ “I-I-I-I” scheme, the codec used also is TMN8, but in different coding options.
Only Temporal SI: MDVC with only temporal SI used in side generation.
Only Temporal SI: MDVC with only spatial SI used in side generation.
Fusion SI: MDVC with fusion temporal and spatial SI used in side generation.
The luminance PSNR performance as a function of the different average bit rate for the two multiview sequences “Exit” and “Vassar” is shown in Figures 7 and 8, respectively. We can find that the proposed MDVC scheme has significantly better performance 2-3 dB than that of H.263 intraframe coding, and MDVC system is less than the overall complexity of the H.263+ coding. Although there is still a performance gap between H.263 interframe coding and our proposed MDVC scheme, our scheme is easier at encoder which is fit for WVSNs. The proposed fusion SI approach can bring improvements up to 0.2–0.5 dB when compared to the MDVC with only temporal SI used in the same average bit rate. Our proposed MDVC scheme can gain more accurate motion estimation in the intense motion region, to save a lot of computing time. Figures 9(a) and 9(b), respectively, is 15th decoded frame (WZ frame) of “Exit” sequence and “Vassar” sequence using our proposed MDVC scheme; Figures 10(a) and 10(b), respectively, is 15th decoded frame (WZ frame) to “Exit” sequence and “Vassar” sequence using temporal SI. From the comparisons, it can be seen that the decoded frame in fusion SI in MDVC is significantly better than nonfusion scheme, for instance, only temporal SI scheme.
Luminance PSNR versus average bit rate for different coding schemes of “Exit” multiview sequences.
Luminance PSNR versus average bit rate for different coding schemes of “Vassar” multiview sequences.

The decoded 15th frame in proposed fusion SI scheme. (a) “Exit”. (b) “Vassar”.

The decoded 15th frame in only Temporal SI scheme. (a) “Exit”. (b) “Vassar”.
For evaluating the performance of postprocessing framework proposed in this paper, we set up a comparison experiments with the postprocessing and without postprocessing for the decoded multiview sequences. The comparison results of

The decoded 15th frame in only Temporal SI scheme. (a) “Exit”. (b) “Vassar”.
6. Conclusions and Future Work
In this paper, we proposes an improved coding and postprocessing framework for multiview distributed video in WVSNs. In coding scheme, through distinguishing the motion intense regions and the nonmotion intense regions based on sum of absolute difference criteria, the coding scheme encodes macroblocks adaptively, and a fusion temporal and spatial side information is adopted to improve the quality of side generation in the decoder. To further enhance the quality of decoded video sequences, a postprocessing scheme is designed to get more additional compression gain. Experiments demonstrate the validity of the proposed framework.
In the postprocessing scheme, we enforce the image postprocessing based on spatial domain without considering time relevance of the previous and next frames, so the image quality gain we got in this scheme is limited. In our future work, we would consider talking about the postprocessing based on temporal filtering to guarantee the temporal continuity in the reconstructed video sequences to get higher video quality and more compression gain.
Footnotes
Acknowledgments
This work is supported in part by the National Natural Science Foundation of China under Grant nos. 61171053, 61300239, and 61373137; the Doctoral Fund of Ministry of Education of China under Grant no. 20113223110002; the Science & Technology Innovation Fund for Higher Education Institutions of Jiangsu Province under Grant no. CXZZ12_0480.