
Abstract
A manifold adaptive kernel semisupervised discriminant analysis algorithm for gait recognition is proposed in this paper. Motivated by the fact that the nonlinear structure captured by the data-independent kernels (such as Gaussian kernel, polynomial kernel, and Sigmoid kernel) may not be consistent with the discriminative information and the intrinsic manifold structure information of gait image, we construct two graph Laplacians by using the two nearest neighbor graphs (i.e., an intrinsic graph and a penalty graph) to model the discriminative manifold structure. We then incorporate these two graph Laplacians into the kernel deformation procedure, which leads to the discriminative manifold adaptive kernel space. Finally, the discrepancy-based semi-supervised discriminant analysis is performed in the manifold adaptive kernel space. Experimental results on the well-known USF HumanID gait database demonstrate the efficacy of our proposed algorithm.
1. Introduction
In the past two decades, gait recognition has become a hot research topic in pattern recognition and computer vision, owing to its wide applications in many areas such as information surveillance, identity authentication, and human-computer interface. While many algorithms have been proposed for gait recognition [1–5], the most successful and popular approaches to date are the average silhouettes-based methods with subspace learning. The common goal of theses approaches is to find a compact and representative low-dimensional feature subspace for gait representation, so that the intrinsic characteristics of the original gait image are well preserved. Representative algorithms include principal component analysis (PCA) [6], linear discriminant analysis (LDA) [6], locality preserving projection (LPP) [7], and marginal Fisher analysis (MFA) [8].
PCA aims to generate a set of orthonormal basis vectors where the samples have the minimum reconstruction error. Since PCA is an unsupervised method, it is optimal in terms of reconstruction, but not for discriminating one class from others. LDA is a supervised subspace learning approach which seeks the projection directions that maximize interclass scatter and at the same time minimize intraclass scatter. When the label information is available, LDA usually outperforms PCA for pattern classification tasks. However, LDA has a critical drawback: its available feature dimension is limited by the number of classes in the data. To overcome this problem, Tao et al. proposed the general averaged divergence analysis (GADA) [9] framework and the maximization of the geometric mean of all divergences (MGMD) [10] method, respectively. In addition, in order to efficiently and robustly estimate the low-rank and sparse structure of high-dimensional data, Zhou and Tao [11] developed “Go Decomposition” (GoDec) method and proved its asymptotic and convergence speed. While these algorithms have attained reasonable good performance in gait recognition, face recognition, and object classification, they are designed for discovering only the global Euclidean structure, whereas the local manifold structure is ignored.
Recently, various researches have shown that images possibly reside on a nonlinear submanifold [12–14]. Therefore, gait image representation is fundamentally related to the manifold learning, which aims to derive a compact low-dimensional embedding that preserves local geometric properties of underlying high-dimensional data. The most representative manifold learning algorithm is locality preserving projection (LPP) [7], which aims to find the optimal linear approximation to eigenfunctions of the Laplace-Beltrami operator on the data manifold. Since LPP is originally unsupervised and does not take the class label information into account, it does not necessarily work well in supervised dimensionality reduction scenarios. By jointly considering the local manifold structure and the class label information, as well as characterizing the separability of different classes with the margin criterion, marginal Fisher analysis (MFA) [8] delivers reasonably good performance in many pattern classification applications. While the motivations of these methods are different, they can be interpreted into a general graph embedding framework (GEF) [8] or the patch alignment framework (PAF) [15]. In addition, the discriminative information preservation (DIP) [16] algorithm was also proposed by using PAF. Although the above vector-based dimensionality reduction algorithms have achieved great success in image analysis and computer vision, they seriously destroyed the intrinsic tensor structure of high-order data. To overcome this issue, Tao et al. [17, 18] generalized the vector-based learning to the tensor-based learning and proposed the supervised tensor learning (STL) framework. More recently, it has been shown that the slow feature analysis (SFA) [19] can extract useful motion patterns and improve the recognition performance.
In general, the supervised dimensionality reduction approaches are suitable for pattern classification tasks when there are sufficient labeled data available. Unfortunately, in many practical applications of pattern classification, one often faces a lack of sufficient labeled data, since the labeling process usually requires much human labor. Meanwhile, in many cases, large numbers of unlabeled data can be easier to obtain. To effectively utilize the labeled and unlabeled data simultaneously, semisupervised learning [20] was proposed and introduced into the dimensionality reduction process. The motivation behind semisupervised learning is to employ a large number of unlabeled data to help build more accurate models from the labeled data. In the last decades, many semisupervised learning methods have been proposed, such as transductive SVM (TSVM) [21], cotraining [22], and graph-based semisupervised learning algorithms [23]. In addition, motivated by the recent progress in Hessian eigenmaps, Tao et al. [24] introduced the Hessian regularization into SVM for semisupervised learning and mobile image annotation on the cloud. All these algorithms only considered the classification problem, either transductive or inductive. Semisupervised dimensionality reduction has been considered recently, the most representative algorithm is semisupervised discriminant analysis (SDA) [25], which aims to extract discriminative features and preserve geometrical information of both labeled and unlabeled data for dimensionality reduction. While SDA has achieved reasonably good performance in face image and image retrieval, there are still some problems that are still not properly addressed till now.
The original SDA is still a linear technique in nature. It can only extract the linear features of input patterns, and it fails for nonlinear features. So SDA is inadequate to describe the complexity of real gait images because of viewpoints, surface, and carrying status variations.
The original SDA suffers from the singular (small sample size) problem, which exists in high-dimensional pattern recognition tasks such as gait recognition, where the dimension of the samples is much larger than the number of available samples.
To address the above issues, we propose a novel manifold adaptive kernel semisupervised discriminant analysis (MAKSDA) algorithm for gait recognition in this paper. First, we reformulate the optimal objective function of SDA using the discrepancy criterion rather than the ratio criterion, so that the singular problem can be avoided. Second, the discrepancy-based SDA is extended to the nonlinear case through kernel trick [26]. Meanwhile, the discriminative manifold adaptive kernel function is proposed to enhance the learning capability of the MAKSDA. Finally, experimental results on gait recognition are presented to demonstrate the effectiveness of the proposed algorithm.
In summary, the contributions of this paper are as follows.
We propose MAKSDA algorithm. MAKSDA integrates the discriminative information obtained from the labeled gait images and the manifold adaptive kernel function explored by the unlabeled gait images to form the low-dimensional feature space for gait recognition.
In order to avoid the singular problem, we explore the discrepancy criterion rather than the ratio criterion in the kernel space.
We have analyzed different parameter settings of MAKSDA algorithm, including the kernel function type, the nearest neighbor size in the intrinsic graph, and the nearest neighbor size in the penalty graph.
The remainder of this paper is organized as follows. Section 2 describes how to extract the Gabor-based gait representation. Section 3 briefly reviews SDA. In Section 4, we propose the MAKSDA algorithm for gait recognition. The experimental results are reported in Section 5. Finally, we provide the concluding remarks and suggestions for future work in Section 6.
2. Gabor Feature Representation of Gait Image
The effective representation of gait image is a key issue of gait recognition. In the following, we employ the averaged gait image as the appearance model [1, 2], since it can employ a compact representation to characterize the motion patterns of the human body. In addition, the Gabor wavelets [27], whose kernels are similar to the 2D receptive field profiles of the mammalian cortical simple cells, exhibit desirable characteristics of spatial locality and orientation selectivity. Therefore, it is reasonable to use Gabor functions to model averaged gait images. Partialarly, the averaged gait image is first decomposed by using Gabor filters; we then combine the decomposed images to give a new Gabor feature representation, which has been demonstrated to be an effective feature for gait recognition.
The Gabor filters are the product of an elliptical Gaussian envelope and a complex plane wave, which can be defined as follows:

where μ and ν define the orientation and scale of Gabor filters, respectively, z = (μ, ν),
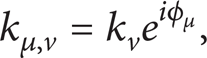
where
The Gabor filters defined in (1) are all self-similar since they can be generated from one filter (the mother wavelet) by scaling and rotating via the wave vector kμ, v. The term
In this paper, following the conventional settings, we use Gabor filters at five scales

The real part of the Gabor filters at five scales and eight orientations.

The magnitude of the Gabor filters at five scales and eight orientations.
The Gabor feature representation of a gait image is obtained by convolving the Gabor filters with the averaged gait image. Let AT (x, y) be the averaged gait image; the convolution of the gait image AT and Gabor filters ψμ, v(z) can be defined as follows:

where z = (x, y), * represents the convolution operator, and Oμ, ν(z) is the convolution result corresponding to the Gabor filters ψμ, v(z). As a result, the set
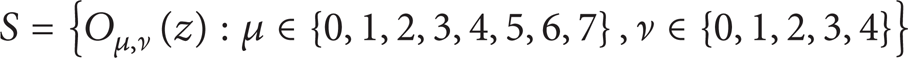
forms the Gabor feature representation of the gait image AT (z). As can be seen, for each averaged gait image, we can obtain 40 Gabor-filtered images after convolving the averaged gait image with the Gabor filters. In addition, as suggested in [28, 29], in order to encompass different spatial frequencies (scales), spatial localities, and orientation selectivity, we concatenate all these representation results and derive the final Gabor feature vector. Before the concatenation, Oμ, ν(z) is downsampled by a factor ρ to reduce the space dimension and normalize it to zero and unit variance. We then construct a vector out of the Oμ, ν(z) by concatenating its rows (or columns). Now, let Oμ, νρ(z) represent the normalized vector constructed from Oμ, ν(z); the final Gabor feature vector Oρ can be defined as follows:
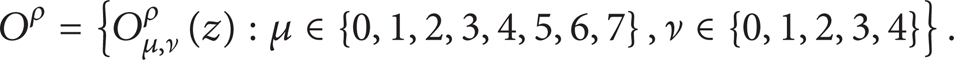
Consequently, the vector Oρ serves as the Gabor feature representation of the averaged gait image for gait recognition.
3. Brief Review of SDA
Given a set of l labeled samples {x1, …, x l }, each of them has a class label c i ∊ {1, …, C} and m unlabeled samples {xl + 1, …, xl + m} with unknown class labels. Let l + m = n and x i ∊ ℝ D ; the optimal objective function of SDA is defined as follows:

where S b and S t denote the between-class scatter matrix and total scatter matrix, respectively. According to the graph perspective of LDA in [7, 8], S b and S t can be defined as follows:

where X = [x1, …, x l ] and the weight matrix W is defined as follows:
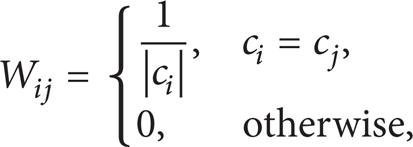
where
In addition, the regularizer item J(U) is used to model the manifold structure. By using locally invariant idea of manifold learning, J(U) is defined as follows:
where L = D – S is the graph Laplacian, D is a diagonal matrix given by

By substituting (7) and (9) into (6), we have

Then, the projection vector U is given by the maximum eigenvalue solution to the generalized eigenvalue problem:

Although SDA has exploited both discriminant and geometrical information for dimensional reduction and achieved reasonably good performance in many fields, there are still some problems that are not properly addressed until now.
SDA suffers from the singular problem in gait recognition, since the number of gait images is much smaller than the dimension of each gait image.
SDA is a linear technique in nature, so it is inadequate to describe the complexity of real gait images. Although the nonlinear extension of SDA through kernel trick has been proposed in [25], it still has two shortcomings: (1) it suffers from the singular problem and (2) it adopts the data-independent kernels which may not be consistent with the intrinsic manifold structure revealed by labeled and unlabeled data samples.
To fully address the above issues, we propose a novel manifold adaptive kernel semisupervised discriminant analysis (MAKSDA) algorithm for gait recognition in the following section.
4. Manifold Adaptive Kernel SDA (MAKSDA) Algorithm
Although SDA can produce linear discriminating feature, the problem of numerical computation for gait recognition still exists; that is, the matrix (XX T + βXLX T ) in (12) may suffer from the singular problem. In this paper, the discrepancy criterion [30–32] is proposed as an alternative way to avoid the singular problems of SDA, since the ratio criterion can be well solved by the discrepancy criterion. Then, the discrepancy-based SDA can be defined as follows:
Then, maximizing Q(U) is equivalent to maximizing S
b
and minimizing
Since we can freely multiply U by some nonzero constant, we assume

Let

Then, the SDA problem can be transformed into finding the leading eigenvectors of matrix (XWX T – XX T – βXLX T ). Since no matrix inverse operation needs to be calculated, the discrepancy-based SDA successfully avoids the singular problem of the original SDA.
Let the column vectors U1, U2, …, U d be the solution of (15) ordered in terms of their eigenvalues λ1, λ2, …, λ d . Thus, the SDA embedding is given by y i = U T x i , where y i denotes the lower-dimensional feature representation of x i and U = (U1, U2, …, U d ) is the optimal projection matrix of SDA.
Although the above discrepancy-based SDA algorithm avoids the singular problem of the original SDA algorithm, it is still a linear algorithm. It may fail to discover the nonlinear geometry structure when gait images are highly nonlinear. Thus, in order to solve the nonlinear problem, the discrepancy-based SDA needs to be generalized to its nonlinear version via kernel trick. The main idea of kernel trick is to map the input data into a feature space with a nonlinear mapping function, where the inner products in the feature space can be easily computed through a kernel function without knowing the nonlinear mapping function explicitly. In the following, we discuss how to perform the discrepancy-based SDA in reproducing kernel hilbert Space (RKHS) and how to produce a manifold adaptive kernel function which is consistent with the intrinsic manifold structure, which gives rise to the manifold adaptive kernel SDA (MAKSDA).
To extend SDA to MAKSDA, let φ: x ∊ ℝ
N
→ φ(x) ∊ F be a nonlinear mapping function from the input space to a high-dimensional feature space F. The idea of MAKSDA is to perform the discrepancy-based SDA in the feature space F instead of the input space ℝ
N
. For a proper chosen φ, an inner product
Let S b φ, S t φ, and Jφ(U) denote the between-class scatter matrix, the total scatter matrix, and the regularizer item in the feature space, respectively. According to (7) and (9), we can obtain

where φ(X) = [φ(x1), φ(x2), …, φ(x n )] and the definition of L is similar to the definition in Section 3.
Then, according to (13), the optimal objective function of MAKSDA in the feature space F can be defined as follows:

with the constraint

To solve the above optimal problem, we introduce the following Lagrangian multiplier method:

with the multiplier λ.
Let

Since any solution U ∊ F must be the linear combinations of φ(x i ), there exist coefficients α i (i = 1, 2, …, n) such that

where φ denotes the data matrix in F; that is, φ = φ(X) = [φ(x1), φ(x2), …, φ(x
n
)], and
Substituting (21) into (20) and following some algebraic transformation, we can obtain

where K denotes the kernel matrix K = φ T (X)φ(X) and its element is K ij = K(x i , x j ).
Thus, the MAKSDA problem can be transformed into finding the leading eigenvectors of (KWK – KK – βKLK). Since no matrix inverse operation needs to be computed, MAKSDA successfully avoids the singular problem. Meanwhile, each eigenvector α gives a projective function U in the feature space. For a new testing data sample x, its low-dimensional embedding can be computed according to
From the above derivation procedure, we can observe that the kernel function K plays an important role in the MAKSDA algorithm. The traditional kernel-based methods commonly adopt data-independent kernels, such as Gaussian kernel, polynomial kernel, and Sigmoid kernel. However, the nonlinear structure captured by those data-independent kernels may not be consistent with the discriminative information and the intrinsic manifold structure [33]. To address this issue, in the following, we discuss how to design the discriminative manifold adaptive kernel function of MAKSDA, which fully takes account of the discriminative information and the intrinsic manifold structure, thus leading to much better performance.
Let V be a linear space with a positive semidefinite inner product (quadratic form) and let E: H → V be a bounded linear operator. In addition, we define

Sindhwani et al. have proved that
Given the data examples x1, x2, …, x n , let E: H → ℝ n be the evaluation map
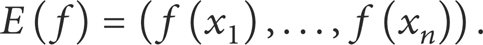
Denote

where M is a positive semidefinite matrix. Let K x denote
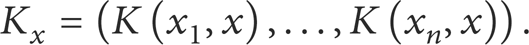
Reference [33] has shown that the reproducing kernel
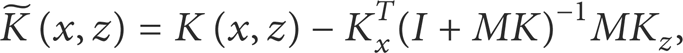
where K denotes the kernel matrix in H and I is an identity matrix. The key issue now is the choice of M, so that the deformation of the kernel induced by the data-dependent norm is motivated with respect to the discriminative information and the intrinsic manifold structure of gait images.
In order to model the discriminative manifold structure, we construct two nearest neighbor graphs, that is, an intrinsic graph G c and a penalty graph G p . For each data sample x i , the intrinsic graph G c is constructed by finding its k1 nearest neighbors from data samples that have the same class label with x i , and putting an edge between x i and its neighbors. The weight matrix W c on the intrinsic graph G c is defined as follows:
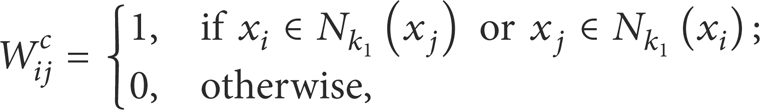
where N k 1 (x i ) denotes the data sample set of the k1 nearest neighbors of x i that are in the same class.
Similarly, for each data sample x i , the penalty graph G p is constructed by finding its k2 nearest neighbors from data samples that have class labels different from that of x i and putting an edge between x i and its neighbors from different classes. The weight matrix W p on the penalty graph G p is defined as follows:

where P
k
2
(c) denotes a set of data pairs that are the k2 nearest pairs among the data pair set
To encode the discriminative information, we maximize margins between different classes. The between-class separability is modeled by the graph Laplacian defined on the penalty graph:

where L
p
= D
p
– W
p
is the Laplacian matrix of the penalty graph and the ith element of the diagonal matrix D
p
is
To encode the intrinsic manifold structure, the graph Laplacian provides the following smoothness penalty on the intrinsic graph:
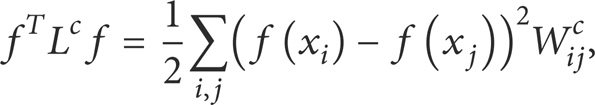
where L
c
= D
c
– W
c
is the Laplacian matrix of the intrinsic graph G
c
and the ith element of the diagonal matrix D
c
is
We minimize (33) to retain the intrinsic manifold structure information and maximize (32) to make the data samples in different classes separable. Thus, by combining discriminative information and the intrinsic manifold structure information together, we can set M in (29) as

Then, by substituting (34) into (29), we eventually get the following discriminative manifold adaptive kernel function:

As can be seen, the main idea of constructing discriminative manifold adaptive kernel is to incorporate the discriminative information and the intrinsic manifold structure information into the kernel deformation procedure simultaneously. Thus, the resulting new kernel can take advantage of information from labeled and unlabeled data. When an input initial kernel is deformed according to (35), the resulting manifold-adaptive kernel function may be able to achieve much better performance than the original input kernel function. In this paper, we simply use the Gaussian kernel as the input initial kernel.
In summary, by combining the above discussions, we can outline the proposed manifold-adaptive kernel SDA (MAKSDA) algorithm as follows.
Calculate the initial kernel matrix K: K
ij
= K(x
i
, x
j
) in the original data space. Construct an intrinsic graph G
c
with the weight matrix defined in (30) and calculate the graph Laplacian L
c
= D
c
– W
c
. Construct a penalty graph G
p
with the weight matrix defined in (31) and calculate the graph Laplacian L
p
= D
p
– W
p
. Calculate M and the discriminative manifold-adaptive kernel function
Replace K in (24) with

Compute the eigenvectors and eigenvalues for the generalized eigenproblem (36). Let the column vector

where the discriminative manifold adaptive kernel
Now, we obtain the low-dimensional representations of the original gait images with (37). In the reduced feature space, those images belonging to the same class are close to each other, while those images belonging to different classes are far apart. Thus, the traditional classifier algorithm can be applied to classify different gait images. In this paper, we apply the nearest neighbor classifier for its simplicity, and the Euclidean metric is used as the distance measure.
The time complexity analysis of MAKSDA is outlined as follows. Computing the input initial kernel matrix needs O(n2). Constructing the intrinsic graph and the penalty graph needs O(k1n2) and O(k2n2), respectively. Computing the discriminative manifold adaptive kernel matrix and the generalized eigenproblem needs O(n3). Projecting the original image into the lower-dimensional feature space needs O(dn2). Thus, the total computational complexity of MAKSDA is O(n3), which is the same as the traditional kernel SDA algorithm in the kernel space.
5. Experimental Results
In this section, we report experimental results on the well-known USF HumanID gait database [1] to investigate the performance of our proposed MAKSDA algorithm for gait recognition.
The system performance is compared with the kernel PCA (KPCA) [34], kernel LDA (KLDA) [35], kernel LPP (KLPP) [36], kernel MFA (KMFA) [8], and kernel SDA (KSDA) [25], five of the most popular nonlinear methods in gait recognition. We adopt the commonly used Gaussian kernel as kernel function of these four algorithms. In the following experiments, the Gaussian kernel with parameters
We carried out all of our experiments upon the USF HumanID gait database, which consists of 1870 sequences from 122 subjects (people). As suggested in [1], the whole sequence is partitioned into several subsequences according to the gait period length Ngait, which is provided by Sarkar et al. [1]. Then, the binary images within one gait cycle are averaged to acquire several gray-level average silhouette images as follows:

where

Some original binary images and the average silhouette images of two different peoples in the USF HumanID gait database.
In this paper, to perform gait recognition, the averaged gait image is decomposed by Gabor filters introduced in Section 2. We combine the decomposed images to give a new Gabor feature representation defined in (5), which is suitable for gait recognition. Our use of the Gabor-based feature representation for the averaged gait-image-based recognition is based on the following considerations: (1) Gabor functions provide a favorable tradeoff between spatial resolution and frequency resolution, which can be implemented by controlling the scale and orientation parameters; (2) it is supposed that Gabor kernels are similar to the 2D-receptive field profiles of the mammalian cortical simple cells; and (3) Gabor-function-based representations have been successfully employed in many machine vision applications, such as face recognition, scene classification, and object recognition.
In short, the gait recognition algorithm has three steps. First, we calculate the Gabor feature representation of the averaged gait image. Then, the Gabor feature representations are projected into lower-dimensional feature space via our proposed MAKSDA algorithm. Finally, the nearest neighbor classifier is adopted to identify different gait images. As suggested in [1–3], the distance measure between the gallery sequence and the probe sequence adopts the following median operator, since it is more robust to noise than the traditional minimum operator. Consider

where LS P (i), i = 1, …, N p , and LS G (j), j = 1, …, N g , are the lower-dimensional feature representations from one probe sequence and one gallery sequence, respectively. N p and N g denote the total number of average silhouette images in the probe sequence and one gallery sequence, respectively.
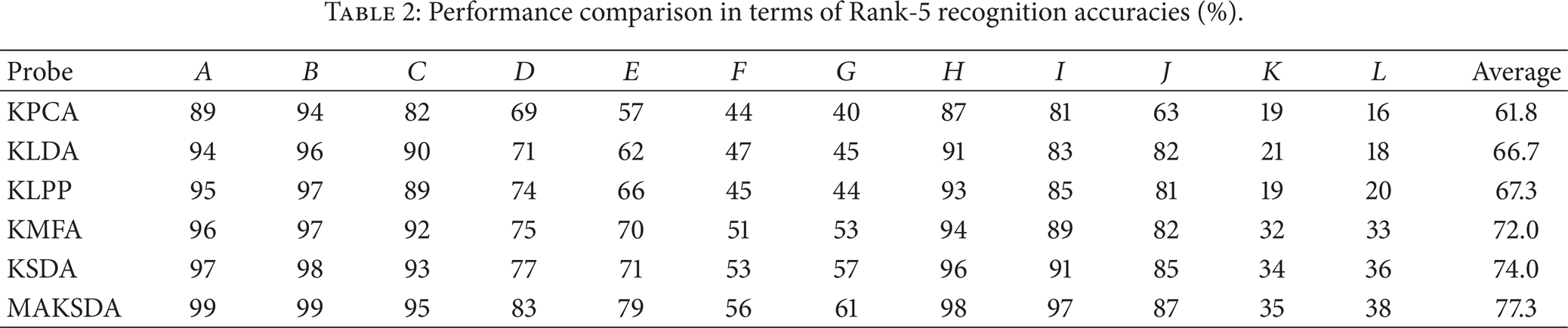
Three metrics (the Rank-1, Rank-5, and Average recognition accuracies) are used to measure the recognition performance. Rank-1 means that the correct subject is ranked as the top candidate, Rank-5 means that the correct subject is ranked among the top five candidates, and Average denotes the recognition accuracy among all the probe sets, that is, the ratio of correctly recognized persons to the total number of persons in all the probe sets. Tables 1 and 2 show the best results obtained by KPCA, KLDA, KLPP, KMFA, KSDA, and MAKSDA. From the experimental results, we can make the following observations.
Our proposed MAKSDA algorithm consistently outperforms KPCA, KLDA, KLPP, KMFA, and KSDA algorithms, which implies that extracting the discriminative feature by using both labeled and unlabeled data and explicitly considering the discriminative manifold adaptive kernel function can achieve the best gait recognition performance.
KPCA obtains the worst performance on the USF HumanID gait database even though it is a kernel-based method. The possible reason is that it is unsupervised and only adopts the data-independent kernel function, which are not necessarily useful for discriminating gait images with different persons.
The average performances of KLDA and KLPP are almost similar. For some probe sets, KLPP outperforms KLDA, while KLDA is better than KLPP for other probe sets. This indicates that it is hard to evaluate whether manifold structure or the class label information is more important, which is consistent with existing studies [37, 38].
KMFA is superior to KLDA and KLPP, which demonstrates that KMFA can effectively utilize local manifold structure as well as the class label information for gait recognition.
The semisupervised kernel algorithms (i.e., KSDA and MAKSDA) consistently outperform the pure unsupervised kernel algorithms (i.e., KPCA and KLPP) and the pure supervised kernel algorithms (i.e., KLDA and KMFA). This observation demonstrates that the semisupervised learning can effectively utilize both labeled and unlabeled data to improve gait recognition performance.
Although KSDA and MAKSDA are all the nonlinear extensions of SDA via kernel trick, MAKSDA performs better than SDA. The main reason could be attributed to the following fact. First, MAKSDA avoids the numerical computation problem without computing matrix inverse. Second, KSDA adopts the commonly used data-independent kernel functions; thus the nonlinear structure captured by these kernel functions may not be consistent with the intrinsic manifold structure of gait image. For MAKSDA, it adopts the discriminative manifold-adaptive kernel function; thus the nonlinear structure captured by these data-adaptive functions is consistent with the discriminative information revealed by labeled data as well as the intrinsic manifold structure information revealed by unlabeled data.
MAKSDA obtains the best recognition performance on all the experiments, which implies that both discriminant and geometrical information contained in the kernel function are important for gait recognition.
Performance comparison in terms of Rank-1 recognition accuracies (%).

Performance comparison in terms of Rank-5 recognition accuracies (%).
We also conduct an in-depth investigation of the performance of Gabor-based feature with respect to different parameters, such as the number of scales and orientations of Gabor features. In this study, we adopt the default settings; that is, we have 40 Gabor kernel functions from five scales
Average Rank-1 and Rank-5 recognition accuracies (%) under different Gabor parameters.

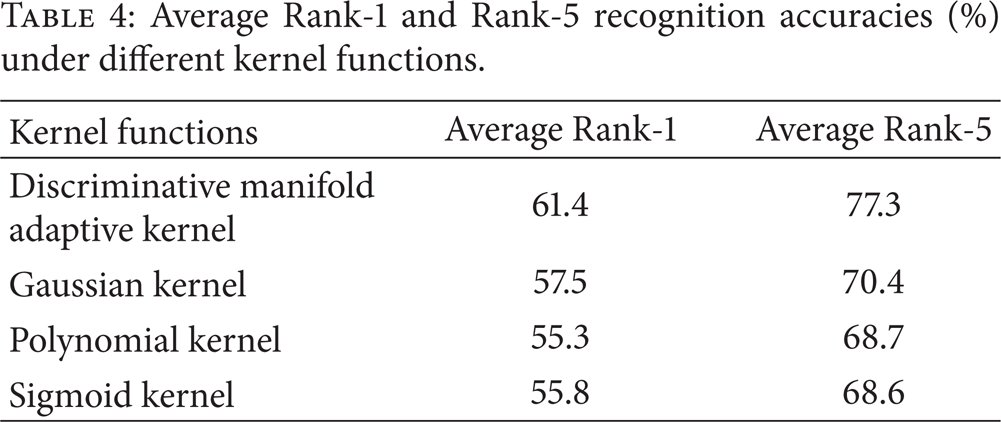
The construction of the kernel function is one of the key points in our proposed MAKSDA algorithm. Our proposed MAKSDA algorithm adopts the discriminative manifold adaptive kernel function to capture the discriminative information and the intrinsic manifold structure information. Of course, we can also use other kinds of traditional kernel functions, such as Gaussian kernel, polynomial kernel, and Sigmoid kernel. To illustrate the superiority of our proposed discriminative manifold adaptive kernel function, we test the average Rank-1 and Rank-5 recognition accuracies under different kernel functions. The experimental results are shown in Table 4. As can be seen, our proposed discriminative manifold adaptive kernel function achieves the best performance, while the rest kernel functions have comparative performance. The superiority of discriminative manifold adaptive kernel is due to the fact that it is the data-dependent kernel, and the nonlinear structure captured by it may be consistent with the intrinsic manifold structure of gait image, which has been shown very useful for improving the learning performance by many previous studies. However, Gaussian kernel, polynomial kernel, and Sigmoid kernel are all data-independent common kernels, which might not be optimal in discriminating gait images with different semantics. This also demonstrates that simultaneously considering the local manifold structure and discriminative information is essential in designing kernel SDA algorithms for gait recognition.
Average Rank-1 and Rank-5 recognition accuracies (%) under different kernel functions.
In addition, our proposed MAKSDA algorithm has two essential parameters: the number of nearest neighbor k1 in the intrinsic graph and the number of nearest neighbor k2 in the penalty graph. We empirically set k1 to 6 and k2 to 15 in the previous experiments. In this section, we investigate the influence of different choices of k1 and k2. We vary k1 while fixing k2 and vary k2 while fixing k1. Figures 4 and 5 show the performance of MAKSDA as a function of the parameters k1 and k2, respectively. As can be seen, the performance of MAKSDA is very stable with respect to the two parameters. It achieves much better performance than other kernel algorithms when k1 varies from 4 to 8 and k2 varies from 10 to 20. Therefore, the selection of parameters is not a very crucial problem in our proposed MAKSDA algorithm.
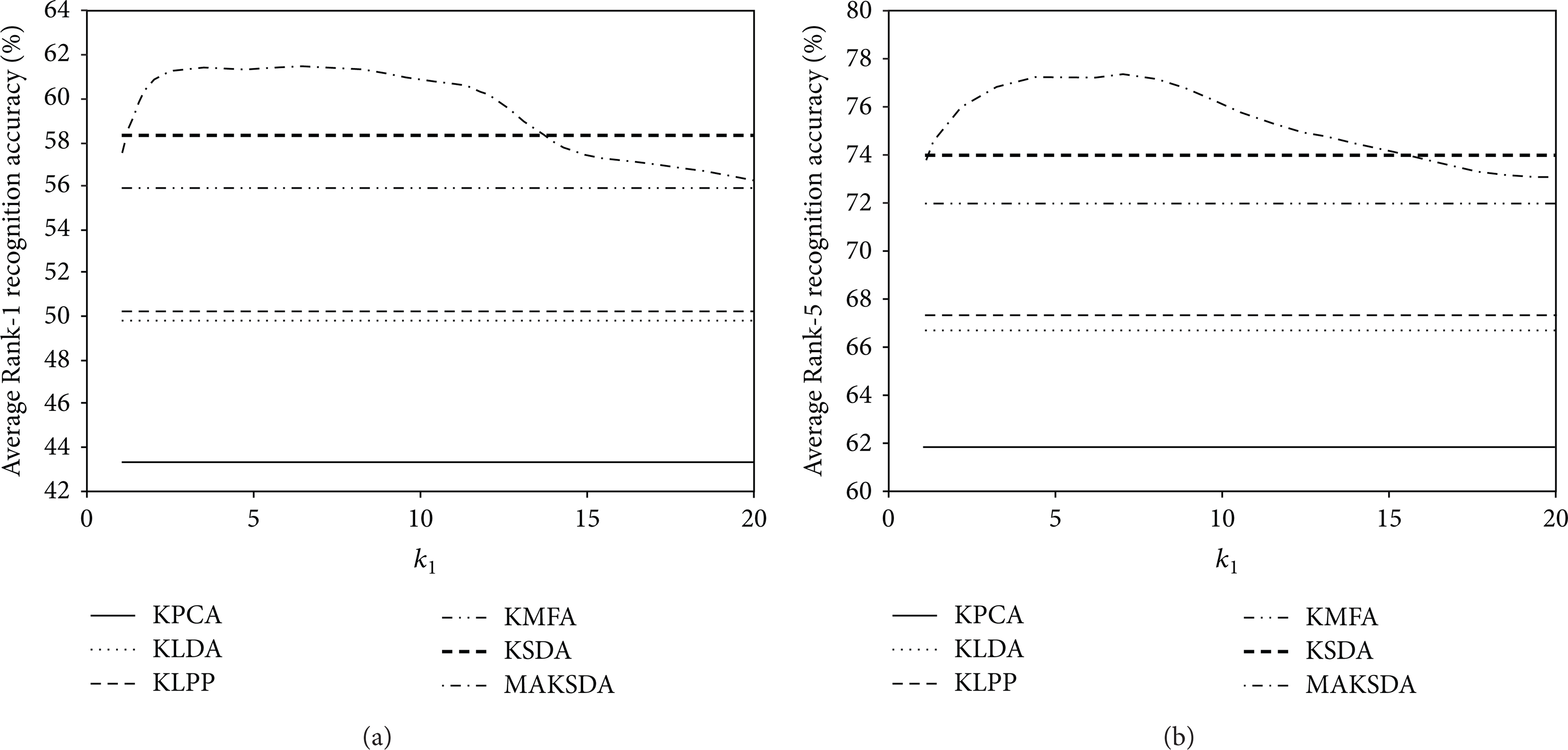
The performance of MAKSDA versus parameter k1: (a) Average Rank-1 recognition accuracy versus k1; (b) Average Rank-5 recognition accuracy versus k1.

The performance of MAKSDA versus parameter k2: (a) Average Rank-1 recognition accuracy versus k2; (b) Average Rank-5 recognition accuracy versus k2.
6. Conclusions
We have introduced a novel manifold adaptive kernel semisupervised discriminant analysis (MAKSDA) algorithm for gait recognition. It can make use of both labeled and unlabeled gait image to learn a low-dimensional feature space for gait recognition. Unlike the traditional kernel-based SDA algorithm, MAKSDA not only avoids the singular problem by not computing the matrix inverse, but also can explore the data-dependent nonlinear structure of the gait image by using the discriminative manifold adaptive kernel function. Experimental results on the widely used gait database are presented to show the efficacy of the proposed approach.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Footnotes
Acknowledgments
This work is supported by NSFC (Grant no. 70701013), the National Science Foundation for Post-Doctoral Scientists of China (Grant no. 2011M500035), and the Specialized Research Fund for the Doctoral Program of Higher Education of China (Grant no. 20110023110002).