
Abstract
We use a great deal of wireless sensor nodes to detect target signal that is more accurate than the traditional single radar detection method. Each local sensor detects the target signal in the region of interests and collects relevant data, and then it sends the respective data to the data fusion center (DFC) for aggregation processing and judgment making whether the target signal exists or not. However, the current judgment fusion rules such as Counting Rule (CR) and Clustering-Counting Rule (C-CR) have the characteristics on high energy consumption and low detection precision. Consequently, this paper proposes a novel Weight-based Clustering Decision Fusion Algorithm (W-CDFA) to detect target signal in wireless sensor network. It first introduces the clustering method based on tree structure to establish the precursor-successor relationships among the clusters in the region of interests and then fuses the decision data along the direction from the precursor clusters to the successor clusters gradually, and DFC (i.e., tree root) makes final determination by overall judgment values from subclusters and ordinary nodes. Simulation experiments show that the fusion rule can obtain more satisfactory system level performance at the environment of low signal to noise compared with CR and C-CR methods.
1. Introduction
As we know, we can only use one sensor or radar to detect target signal of one event source in ideal environment. In normal environment, we cannot do it well because of the affection of noise around, which would lead to false detection result. Instead, we can lay many sensors in ROI (Region of Interest), and they cooperate with each other to make final judgment for improving detection accuracy. Actually, wireless sensor network composed of large-scale distributed nodes would resolve the problem of target detection more effectively by determining whether there exists target signal based on sensor nodes' cooperation, and this is one of the most important applications on monitoring objective physical world. In ideal circumstance, how to estimate whether there exists target in ROI can be simplified to judge whether there exists target signal or not. However, practical environment is blended with a lot of random noises, and therefore, how to increase the target detection precision and reduce energy consumption in noisy sensor network environment will be the focus of this paper.
Many scholars have studied distributed target detection technique. Tenney and Sandell apply Bayesian theory to target signal detection [1]. In [2], Chair and Varshney point out that authors do not consider the data fusion among multisensors in [1], and then they set the corresponding weight value for each prior probability of detection on the basis of Zero-One decision fusion. In [3, 4], considering the criteria of Chair-Varshney, authors excogitate a kind of data fusion rule based on the correlation coefficient.
Niu and Varshney publish an algorithm based on Zero-One decision fusion-Counting Rule [5] in ICASs'05. They set the detection probability and false alarm probability of each sensor node to be the same. And thereby, Chair-Varshney criteria can be simplified to be the summation of judgment values (0 or 1) of all nodes. According to central limit theorem, Niu calculates the value of theory approximation of the detection performance. Katenka et al. put forward the fusion algorithm based on the Zero-One decision [6] of local vote. He takes full advantage ofthe collaboration features of neighbor nodes in wireless sensor network. Each node amends its judgment according to the judgments made by its neighbor nodes. In [7], Sung et al. put forward a new evaluation guide to describe the performance of target detection. And they contrive a distributed collaboration route method coalescing Kalman's data fusion and shortest path algorithm to convey the data of distributed target detection. In [8, 9], Yang et al. bring forward an energy efficient route algorithm of distributed target detection based on Neyman-Pearson rule. In the process of establishing math model of routing, authors consider the node energy consumption and the detection probability comprehensively, and then they analyze and compare the routing performance. References [10, 11] take advantage of the feature of tree structure and then discuss the performance of the distributed target detection model based on the network topology of the aggregation tree. Reference [12] achieves to the minimum probability of error and the maximum residual energy by multiobjective optimization method in order to optimize the decision threshold of each node under the distributed network topology environment. In [13], based on the mathematical model of multitarget detection, Ermis and Saligrama advance the method of target detection based on the process of Benjamin-Hochberg. And then they analyze the algorithm performance in an ideal environment. In [14], based on the Neyman-Pearson criterion, Aziz proposes a soft decision fusion algorithm differing from the traditional Zero-One decision fusion. He takes the confidence factor of each node as weighted value to fuse the data. In spite of transmitting more bytes of data and consuming more system energy, it can improve the efficiency of system detection significantly. Reference [15] presents a three-tier ocean intrusion detection system by using accelerometer sensors to detect intrusion ships, which exploits the spatial and temporal correlations of the intrusion to increase the detection reliability. Reference [16] proposes a fully distributed cut vertex detection mechanism called CAM, which can be applied in large-scale, highly dynamic overlay networks. In [17], authors considered the problem of adaptive radar detection of distributed targets in the presence of Gaussian noise with unknown covariance matrix. More precisely, they extend the ABORT (adaptive beamformer orthogonal rejection test) idea to the distributed targets resorting to the GLRT (generalized likelihood ratio test) design criterion. Reference [18] advances a PF-DTBD (particle filter based distributed track-before-detect) algorithm via fusing multisensor local estimated conditional PDF (probability density functions). They apply MKDE (multivariate kernel density estimation) technique to estimate sensors' local PDFs on the basis of finite particles set.
Firstly, this paper analyzes the related works about distributed target detection and then puts forwarda new method to improve the system detection efficiency on the base of consuming less energy in wireless sensor network. The specific mathematical expression of
The rest of this paper is organized as follows. Section 2 describes the system model, related definitions, and the process of clustering. And then we detail the decision fusion rule. Next we prove that the method is better than others by simulation tests. Finally we summarize the whole paper in Section 5.
2. System Model and Related Definitions
2.1. Signal Attenuation Model
We assume that the signal power emitted by the target or event source declines as the distance from the target grows. Here we choose polynomial decay model as attenuation model in ROI. The amplitude of signal that sensor node

2.2. Mathematical Model
The mathematical model of the distributed target detection is based on binary assumptions of probability and statistics theory. Due to the complexity of environment, we assume that the background noise is white Gaussian noise. In a noisy environment, the signal values detected by sensor nodes can be expressed as

Definition 1 (detection probability [DP]).
Under the condition that there exists target signal, we can use
Definition 2 (false alarm rate [FAR]).
Under the condition that there does not exist target signal, but we detect the signal and express as
2.3. Network Model of Clustering
We assume that the local sensors and data fusion center (DFC) are deployed in ROI of wireless sensor network randomly. The processes of clustering can be described as follow.
Network initialization: each node establishes its own neighbor list by broadcasting message. And DFC is the first-level cluster head of the whole network. In terms of one cluster-head chosen algorithm such as HeeD [19], DFC selects several sensor nodes from its neighbor list as its subcluster (the second-level) cluster heads. The rest of other neighbors of DFC become the normal nodes. After that, the second-level cluster heads select some relay nodes in the set of their respective neighbor lists simultaneously to the exclusion of those who have become the cluster heads, and then they send subcluster establishment messages to their respective relay nodes. Thereafter, relay nodes begin to choose the third-level cluster heads delegated from the second-level cluster heads according to the same cluster-head selection algorithm and build the precursor-successor relationship. Those who are neither relay nodes nor cluster heads would be maintained as normal nodes. The newly chosen cluster heads repeat step (3) and step (4) above until the clustering process of the entire network is finished. After building the different levels of subclusters, relay nodes are seen as the ordinary nodes, and the precursor-successor relationship between two clusters determines the order of communication of their respective cluster head nodes.
Thus, the process of clustering in ROI is shown in Figure 1, and actually it forms the network topology of tree structure where DFC becomes the root.

The process of clustering.
The ordinary nodes in precursor cluster transmit their respective judgments to the head of cluster, and then the head of clusters transmit their respective judgments to the head of successor cluster after fusing the judgments from its members. The path of transmitting the judgments data is shown in Figure 2.

The path of fusing data among the head of cluster.
3. Decision Fusion Rule
3.1. Three Kinds of Clusters
From the previous analysis, we can find that there exists the precursor-successor relationship among clusters. So during the decision fusion, different levels of clusters have different decision fusion methods.
Definition 3 (father and son cluster [FSC]).
For any two clusters
According to the relationship of precursorsuccessor among clusters, we can divide the clusters into three types, and they are precursor clusters, precursor-successor clusters, and successor clusters separately.
Figure 3(c) depicts the successor cluster whose head is data fusion center, and it has many subcluster head nodes and ordinary nodes. We assume that there are N clusters in the whole network, the precursor cluster set is
W-CDFA (Weight-based Clustering Decision Fusion Algorithm) is a decision fusion algorithm which fuses the weighted data of decision between clusters. We would discuss the decision fusion methods about the different kinds of clusters, described as Figures 3(a) and 3(b), respectively. Because that the successor cluster is the special case of precursor-successor cluster, its method of decision fusion is similar to the precursor-successor cluster.

Topology of three types of clusters.
3.1.1. Decision Fusion of the Precursor Clusters
For the precursor clusters, the method of decision fusion is simple relatively. Since the judging condition of the ordinary nodes in each cluster is equivalent, we set up the weighted factor to the same and to be 1. For each precursor cluster

Then local decision-making fusion rule of precursor cluster head can be simplified as

3.1.2. Decision Fusion of the Precursor-Successor Clusters
For the precursor-successor clusters (Figure 3(b)), the judgment of the father cluster head not only depends on the judgments of the ordinary nodes in cluster, but also relies on the judgment from its subcluster head nodes, and the decisions uploaded by each cluster members are not the same as the decisions uploaded by subclusters. Since the decision uploaded by the head of subcluster represents the results of all nodes, which would obtain the greater weight value. For any precursorsuccessor
Since the judgment of subcluster head depends on all judgments of ordinary nodes within subcluster or the judgments of ordinary nodes and its subcluster head nodes, the decision of subcluster head owns a greater correct probability than the ordinary nodes in the father cluster when each head of subcluster conveys its decision to father cluster head. We assume that the weight of the judgment uploaded by each subcluster head is the threshold of subcluster head; therefore, we can conclude that

So the decision fusion rule of precursor-successor cluster head is presented as below:
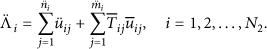
There are only ordinary nodes and DFC in the successor cluster, and it is the exception of the precursor-successor cluster. We assume that the decision threshold of the successor cluster is
3.2. Decision Threshold of Different Clusters
3.2.1. Decision Threshold of Precursor Cluster
Through above-mentioned description of the method of the decision fusion among three different types of clusters, we assume that the decision threshold of three different clusters are
We set the tolerance of false-alarm probability of all clusters in network is α, namely

Obviously,

The calculation formula of decision threshold of the precursor cluster
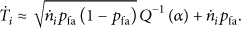
3.2.2. Decision Threshold of the Precursor-Successor Cluster
For the precursor-successor cluster

The precursor-successor cluster nodes have two categories: ordinary nodes and subcluster heads; we assume that a of
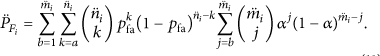


When the number of ordinary nodes in the precursor-successor cluster (
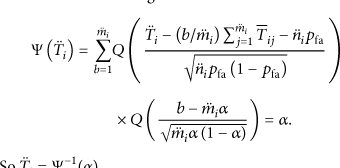
Since the successor cluster is just an exception of the precursor-successor cluster, so for the system decision threshold
4. Experiments and Simulations
We assume that the region of interest is a square with length of edge 100, the target signal is in the place with the coordinate (50, 50), the coordinate of data fusion center is (50, 50), and DFC is the head of all clusters. The sensor nodes are deployed densely in ROI which obeys the uniform random distribution. The random noise in ROI is Gaussian white noise, and it follows the standard normal distribution.
Utilizing the Monte Carlo random methods, the experiment scene is shown in Figure 4.

Experiment scene.
We divide the region of interest into 5*5 clusters; the length of each cluster edge is 20. In order to do experiment conveniently, we establish the precursor-successor relationship among those clusters based on tree clustering structure in Section 2.3. Shown in Figure 4, the number of the precursor cluster is 12; the number of the precursor-successor cluster (including the successor cluster of data fusion center) is 13. In the precursor-successor cluster, each cluster has only one father cluster, but it can have many subclusters. In all clusters, there is one precursor successor that has four subclusters, named as center cluster, there are two clusters that have three subclusters, and four clusters that have two subclusters, and six clusters that have only one subcluster. Each node closed to the cluster center of square is set as cluster head figured by solid circle. In order to facilitate the description, we set the label as 1-1, 1-2⋯1-5, 2-1, 2-2⋯ 2-5⋯5-4, and 5-5 in accordance with the order from left to right every line from the beginning of the upper left corner of ROI.
We calculate the decision threshold values of twenty-five clusters and display parts of them in Table 1. We assume that the tolerance of false-alarm probability of each node marked as
Threshold of different clusters.

From Table 1, we can conclude that the threshold of the whole system depends on that of every cluster; namely, the system model does not make final judgment simply based on independent clusters like C-CR. Actually, from Figure 4, it is clear that the decision of every successor cluster relies on ordinary nodes in cluster and its subclusters, and the relationship makes the system as a whole.
For different schemes, T for different values of N is shown in Figure 5. From the previous analysis, we know that the precursor-successor relationship determines that the decision of the successor clusters depends on the decision of their precursor clusters. And this method wipes off the effect of nodes whose judgment is 0, so the threshold of W-CDFA is fewer than that of CR. However, the threshold of C-CR depends on the number of clusters merely. We can conclude that the threshold of C-CR will not go beyond the number of clusters, so it is no worth discussing the threshold of C-CR in practical. In Figure 6, we show the relationship between the system-level threshold T and false alarm rate

T for different values of N.

T for different values of
We assume that noises in ROI are i.i.d (independent identical distribution) and follow the standard Gaussian distribution. Here we do 1000 times Monte Carlo experiments under the condition of SNR = 6 and SNR = 3, respectively. We can see the detection performance of CR, C-CR, and W-CDFA in Figures 7(a) and 7(b) and conclude that the detection capability of CR is the best. In [5], authors have derived that the performance of CR would be better with the growth of the number of sensor nodes. However, it is not useful in reality when the length of ROI is very large because that the energy consumption grows fast. The performance of W-CDFA proposed in this paper is better than C-CR. Because C-CR loses lots of useful information in its first fusion step, and this method does not utilize the relativity relationship among sensor nodes.

ROC of system through Monte Carlo (

Under the same condition of network, we assume that the total energy of network is 1 J. Figure 10 shows the change of remaining energy with the frequency of experiment testing. We can find that W-CDFA's energy consumption of all nodes is slower than CR and C-CR. It is easy to understand that the way of single hop communication will cost more energy than the way of multihop communication. This also is why the curve trend difference between CR and C-CR is remarkable in Figure 10. We enlarge one part of curve of C-CR and W-CDFA, and we can find there exists a tiny discrimination between them because the heads of clusters transmit their judgments to DFC directly in C-CR; however, the heads of cluster transmit their judgments to the successors and finally to DFC by the way of multihop communication in the W-CDFA rule.

Comparison of the remaining energy.
5. Conclusion and Discussion
In this paper, we propose a Weight-based Clustering Decision Fusion Algorithm based on the large-scale wireless sensor network to achieve more effective distributed target signal detection. Compared with other typical schemes, the most significant feature of this proposed method is the use of tree structure-based clustering algorithm to create the precursor-successor relationship among clusters and meanwhile derives the decision fusion criterion on signal judgment based on these relationships.
We can analyze and calculate the system-level false alarm probability from the beginning of the precursor clusters. Thereby we can obtain the system-level judgment threshold. In order to demonstrate that W-CDFA can realize better performance than C-CR, we set the simulation scenarios and experiments that take relationships among clusters into account. Simulation results show that the fusion rule can get satisfactory system-level performance at a low signal to noise ratio. Due to the exclusion of those useless data before making system level judgment, the system threshold in W-CDFA is lower than C-CR which is an important system performance guideline.
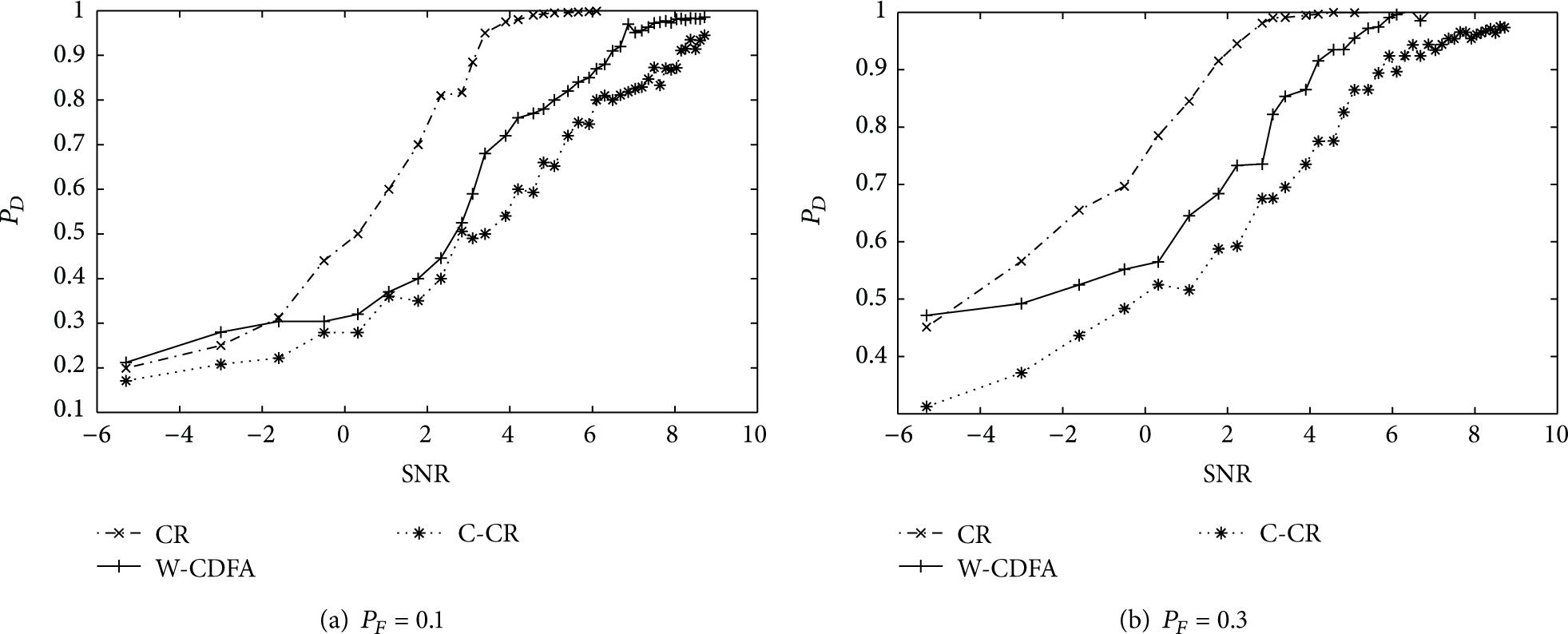
It is difficult to detect target signal in the noisy environment. As we know, the most important factor that affects detection performance is the signal to noise ratio (SNR). In Figure 9, we can find the performance of W-CDFA is better than CR, and C-CR with lower SNR and harsher condition (
For the purpose of convenience of simulation experiments, we even manual intervene the establishment of the precursor-successor relationships among clusters, but this intervention should be alleviated for the validity. In the future, those works will be further investigated.
Footnotes
Acknowledgments
The subject is sponsored by the National Natural Science Foundation of China (no. 61170065, 61003039), Scientific and Technological Support Project (Industry) of Jiangsu Province (no. BE2012183), Natural Science Key Fund for Colleges and Universities in Jiangsu Province (12KJA520002), Postdoctoral Foundation (2012M511753, 1101011B), Science and Technology Innovation Fund for higher education institutions of Jiangsu Province (CXZZ11-0409), Fund of Jiangsu Provincial Key Laboratory for Computer Information Processing Technology (KJS1022) and Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions (yx002001).