
Abstract
Five-plunger pumps are widely used in oil field to recover petroleum due to their reliability and relatively low cost. Petroleum production is, to a great extent, dependent upon the running condition of the pumps. Closely monitoring the condition of the pumps and carrying out timely system diagnosis whenever a fault symptom is detected would help to reduce the production downtime and improve overall productivity. In this paper, a rough set approach of mechanical fault diagnosis is proposed to identify the five-plunger pump faults. The details of the approach, together with the basic concepts of the rough sets theory, are presented. The rough classifier is a set of decision rules derived from lower and upper approximations of decision classes. The definitions of these approximations are based on the indiscernibility relation in the set of objects. The spectrum features of vibration signals are abstracted as the attributes of the learning samples. The minimum decision rule set is used to classify technical states of the considered object. The diagnostic investigation is done on data from a five-plunger pump in outdoor conditions on a real industrial object. Results show that the approach can effectively identify the different operating states of the pump.
1. Introduction
In many fields of nature science, society science, engineering, and so forth, there are many uncertain and imperfect data needed to be processed. The data collected from the real systems usually include not only useful information but also noisy data. That is, they are inaccurate, even incomplete. It is not practical to just eliminate or dodge this uncertainty by using some hypothesis mathematically. On the contrary, over the past decades many theories and techniques have been developed to deal with incompleteness and uncertainty in information analysis scientifically. Among them, the most successful ones are fuzzy set theories [1, 2] and the Dempster-Shafer evidence reasoning [3, 4]. However, additional information and prior knowledge are needed when they are used to solve some problems. For example, the membership functions are determined by experience and judgement of the experts in certain fields, and the basic probability assignment and statistical probability are sometimes not easy to be obtained, which means that the treatment of the uncertain information of the running conditions of the pump, to some extent, is subjective. In 1982, Pawlak, a Poland researcher, presented the rough sets theory [5] which is a mathematical tool depicting the imperfectness and uncertainty. It can analyze the imprecise, inconsistent, and incomplete information effectively. It can also process the data and also reason and mine the knowledge implied in the data to reveal the potential laws. This theory has strong practicability. Having been studied and developed for more than 20 years, it has great progress both in theoretical and practical application. Rough sets have been used in the areas of inductive reasoning, number logic analysis and redact, building predictive model, decision support, process control, machine learning, database mining, automatic classification, pattern recognition, and so forth.
Five-plunger pump is widely used in oil field to recover petroleum due to its reliability and relatively low cost. It is a typical reciprocating machinery, consisting of many rotating and back-forth motion parts. Diagnosis and isolation of the faults of a five-plunger pump is a challenging problem, because the pump's dynamic responses, generated by a wide range of possible impulsive sources, are very complex. Common techniques used for a pump or reciprocating machinery fault detection include time and frequency domain analyses for either vibration signals [6, 7] or acoustic emission (AE) signals [8]. In recent years, newly developed signal process methods and artificial diagnosis approaches have been paid more attention to. Wavelet transform [1] and local wave method [9] are utilized to extract diagnosis features from the vibration acceleration measured at the hydraulic-end or the dynamic-end of a pump. Expert system using adaptive order tracking technique and artificial neural networks [10], combined method based on wavelet transformation, fuzzy logic and neuron networks [1], wavelet packet analysis and BP and RBF networks [11, 12], local wave time-frequency spectrum and support vector machine (SVM) [9], and evidence theory for fusing the results from several single-source and multi-feature [3, 13] have been studied for fault diagnosis in a pump or reciprocating machinery.
However, in condition monitoring and fault diagnosis of the five-plunger pump, the raw knowledge collected from the pump may contain uncertainty, which can be imprecise or incomplete. Imprecise information refers mainly to raw knowledge that is fuzzy, conflicting, or contradictory. For example, the opinion about the performance of a pump perceived by two engineers could be different. This would introduce inconsistency to the raw knowledge concerning the performance of the pump. On the other hand, incomplete information refers mainly to missing data in the raw knowledge which can be caused by the unavailability of equipment or oversight of operators. This imprecise and incomplete nature of raw knowledge is the greatest obstacle to automatic rule extraction. The ability of acquiring decision rules from empirical data or the environment is an important requirement for both natural and artificial organisms. In artificial intelligence, decision rules can be acquired by performing inductive learning. Many developed techniques such as decision tree learning, neural network learning, and genetic algorithm-based learning could be introduced to carry out such a task.
In this paper, a novel approach based on the rough sets theory to fault diagnosis, which aims at identifying the basic events occurring in the running condition of the pump, is proposed. As the proposed approach involves subjective judgements by domain experts, which may be inconsistent or sometimes contradictory, rough sets theory is adopted. It uses the information offered by the testing data themselves and does not need the prior knowledge. Also it can represent and process the imperfect information. And on the premise of retaining the principal information of the pump running conditions, it can reduce the fault features, find a simpler representation of knowledge in the form of decision table, and drive diagnostic rules only from the facts presented in the data.
2. Basic Notions of the Rough Set Theory
In this section, only a short reminder of the basic notions of the rough sets theory is given. These concepts should be useful for us to understand the analysis of the considered diagnostic problem performed in the next sections. For a more exhaustive presentation of the rough sets theory, readers can refer to several researches [5, 14, 15] devoted to this theory.
2.1. Equivalence Relation and Lower/Upper Approximation
The concept of “knowledge” has different meanings in different categories. In rough sets theory, the “knowledge” can be referred to as the ability of classification. According to their characteristic differences, the ability to distinguish the objects on the basis of imprecise information about them is considered some kind of “knowledge.” In other words, in the process of classification, the objects, whose characteristic information is not too different, can be classified into same class. The relation between them is named the indiscernibility relation, also called equivalence relation. Imprecise information causes indiscernibility of objects. The indiscernibility relation is very important in rough set theory. It deeply reveals the granular structure of the knowledge and is the basis of other concepts. Here the knowledge can be considered a family of equivalence relations. It partitions U, which is a set called the universe, into a series of equivalence classes. Rough sets theory extends the classical sets theory. It implants the knowledge of classification to the sets. Whether one object α belongs to a set X, depending on the knowledge, can be sorted to three cases: (1) the object α belongs to X certainly, (2) α does not belong to X certainly, and (3) α may or may not belong to X. Sets are partitioned according to the knowledge related to U, thus, therefore, are relative, not absolute.
Let U be the universe, and let R be an equivalence relation on U, that is, the knowledge related to U. The pair A = (U, R) is called an approximation space. R will be called indiscernibility relation, if x, y ∊ R, x, y will be indistinguishable in A.
Equivalence classes of the relation R will also be called elementary sets (or atoms) in A. The set of all atoms in A will be denoted by U/R. Every finite union of elementary sets in A will be called a composed set in A. The family of all composed sets in A will be denoted as Com (A). The family of all composed sets is closed under intersection, union, and complement of sets.
Assuming that x is an object in U and R(x) represents set of the objects which have strong relationship with x, all the objects in R(x) have similar attributes to x. Briefly, R(x) is an equivalence relation decided by x. If one certain set of equivalence relation R is not able to be represented by union of the elementary sets, it is called rough set.
Rough sets theory processes the uncertainty on the basis of concept of lower/upper approximation. Let X be a certain subset of U. The union of all elementary sets contained in X consists of the lower approximation of R(X), in symbol R*(X). The union of nonempty set of all elementary sets intersection with X consists of the upper approximation of R(X), in symbol R*(X). The mathematic representation is

where Φ is an empty set.
As a matter of fact, R*(X) is the greatest set composed by all elementary sets which surely belong to X, judged by the available knowledge. It is also called positive domain, records pos (X) = R*(X), while negative domain of X, records Neg (X), is a set composed by all subsets which do not surely belong to X judged by the available knowledge. Obviously, Neg (X) = U – R*(X). R*(X) the least composed set may be containing X. The set Bnd (X) = R*(X) – R*(X) is called the boundary of X. If Bnd (X) is an empty set it is a crisp set with respect to R, while if Bnd (X) is nonempty it will be a rough set with respect to R. Lower (upper) approximations are discernibility, which depicts the approximation property of a set having a vague boundary.
2.2. Information Table and Its Reduction
The data analysed by rough sets theory concern a set of machine running states described by a set of multivalued features or symptoms. They are called condition attributes. In the considered diagnostic problems, the data about the objects (technical states) are represented in a structure called information system.
Suppose that an information system S can be described as an ordered quadruple

where U is the universe of S—elements of U are called objects; Q is the union of condition, denoted by C, and decision attributes, denoted by D (i.e., Q = C ∪ D); V(= ∪ q ∊ Q) is a set of values of attributes—V q will be called the domain of q, and ρ: U × Q → V is a description function, such that ρ(x, q) ∊ V q for every q ∊ Q and x ∊ U.
As an example, Table 1 shows the details of eight observations. Each of the observation can be associated with a set of attributes, namely, C1, C2, and C3 which represent noise level, vibration level and machine temperature, respectively. Noise level is evaluated by the RMS value of the noise magnitude measured with sound-level meter. Vibration level is estimated by the peak amplitude of vibration acceleration collected with accelerometer. Machine temperature is tested by thermoelectric sensor.
Information table for diagnosis.

Let Q be a finite set representing the observed symptoms of a machine malfunction on the universe of the performance of a machine, U, with
U = {x1, x2, …, x8},
Q = {Noise level (C1), Vibration level (C2), Machine temperature (C3), Machine malfunction (D)},
V C 1 = {High, Normal}, V C 2 = {High, Normal}, V C 3 = {Low, High, Very high}, D = {Yes, No}.
And information function ρ is given by the table (Table 1) called information table.
The rows of the information table are objects being considered, and the columns are the attributes for each of the objects. There are two kinds of attributes in the information table, namely, the condition (C1, C2, C3) and decision (D) attributes. These attributes will be employed to depict the equivalence relations between the objects. And U/C1 = {{x1, x2, x3, x4}, {x5, x6, x7, x8}} is a discretion of U by the attribute C1. Any subset in U/C1 is called an equivalence relation of C1. That is, the objects x1, x2, x3, and x4 are in indiscernibility relation with respect to C1. The other subset in U/C1 is also indiscernible each other. While U/{C1, C2} shows the intersection of the subsets of U/C1 and U/C2 (U/C2 = {{x1, x3, x6, x7, }, {x2, x4, x5, x8}}). Thus, the elementary subsets are {x1, x3}, {x2, x4}, {x6, x7}, and {x5, x8} determined by attributes C1 and C2. The diagnosis problem is described as generating a decision algorithm, denoted by DS (U/D), from the information system (S) that relates elements of U/C to that of U/D. The attributes can be combined to form decision rules.
For the classification and diagnosis, all the condition attributes in S are not necessary. Some of them, however, are superfluous. The result of the decision will not be influenced if the superfluous condition attributes are removed. An intersection of the minimal subset of the attributes is called the core. A subset P ⊂ Q is a reduction of Q in S if Q-P is superfluous in Q and P is independent of S; the corresponding system S′ = (U, P, V, ρ′) is called reduced system (ρ′ is the restriction of ρ to set U × P).
Moreover, the reduced information system can be identified with the information table. From the information table a decision algorithm can be derived. The decision algorithm consists of a set of decision rules which are logical statements (if…then…). As an example, using the attributes displayed in row 1 in Table 1, the following decision rule can be induced.
If the noise level and vibration level are high, and the machine temperature is low, then the machine is in the condition of malfunction.
Such an approach can be realised using the bespoke basic concepts of rough sets theory as follows.
Step 1. Set up an information (attribute-decision) table according to the specific domain knowledge.
Step 2. Compute the reduction of the condition attributes with respect to the decision attributes.
Step 3. Compute the core value of each decision rule and eliminate redundant rules.
Step 4. Generate the minimal rule set.
Step 5. Determine the logical rules according to the minimal reduction.
In the example shown in Table 1, the elementary sets defined by attributes C2 and C3 may be {x1}, {x2, x3, x6, x7}, {x4}, {x5}, and {x8}, while the subsets of the indiscernibility defined by C1, C2, and C3 are similar to that defined by attributes C2 and C3. So it can be said that the attribute C1 is superfluous and can be eliminated. A minimum set of condition attributes in which no superfluous attributes are included then can be obtained and used for diagnosis correctly, as shown in Table 2. The decision “machine malfunction”, however, is not dependent on the attributes C2 and C3 completely because the decision for class x5 conflicts with class x2. The condition attributes are the similar one by one in this case, so the decisions are not distinguished by the attributes. For these situations, the lower/upper approximation in rough sets theory can be employed to handle the conflictions. If we consider nondescript class, we will get the lower/upper approximation as shown in Tables 3 and 4, respectively.
Reduced decision table for classifying.
Lower approximation.

Upper approximation.

The rules determined by the lower approximation of the decision are inevitably valid, while the rules from the upper approximation may be interpreted deterministically or nondeterministically. From the Table 3, the certain rules are as follows.
Rule 1. If vibration level is high, and the machine temperature is low, then the machine is in the condition of malfunction.
Rule 2. If vibration level is high, and the machine temperature is very high, then the machine is in the condition of malfunction.
Rule 3. If vibration level is normal, and the machine temperature is low, then the machine is not in the condition of malfunction.
Rule 4. If vibration level is high, and the machine temperature is high, then the machine is in the condition of malfunction.
And the probable rules obtained from Table 4 are as follows
Rule 1. If vibration level is high, and the machine temperature is low, then the machine is in the condition of malfunction.
Rule 2. If vibration level is normal, and the machine temperature is high, then the machine may be or may not be in the condition of malfunction.
Rule 3. If vibration level is high, and the machine temperature is very high, then the machine is in the condition of malfunction.
Rule 4. If vibration level is normal, and the machine temperature is low, then the machine is not in the condition of malfunction.
Rule 5. If vibration level is high, and the machine temperature is high, then the machine is in the condition of malfunction.
3. Case Study for Five-Plunger Pump Fault Diagnosis
The basic concept to apply the rough set theory to diagnose the pump faults is that the real information of characteristics for a verity of fault sorts serves as the condition attributes C, and the types of the fault module samples will be the decision attributes D in information system. We can set up the information table according to the real situation of the fault samples and then analyse the set of decision attributes, whether they are determined by the condition attributes, namely, whether there exists the dependence between C and D, shortly C ⇒ D. If the relation C ⇒ D exists it means that the decision set can be defined by category of condition attribute set. We can then calculate the condition set C whether the decision attributes are independent, remove a condition attribute according to whether it will damage the compatibility of the information table and abstract the diagnostic rules to diagnose the faults.
3.1. Construction of Condition Attributes for the Pump Fault Diagnosis
Vibration signals are extensively used in mechanical diagnostics. The reason for the wide use of vibration analysis may be due to the better understanding of vibration mechanism of machine operation and that the change in vibration signal can be easily attributed to the dynamic characteristics of the machine and its fault conditions. Of course, the five-plunger pumps generate vibration during their normal operation. Moreover, the vibration process is a good carrier of the pump and condition-related information, and we are measuring this as vibration signals and transforming it (by FFT operation), to obtain symptoms of condition.
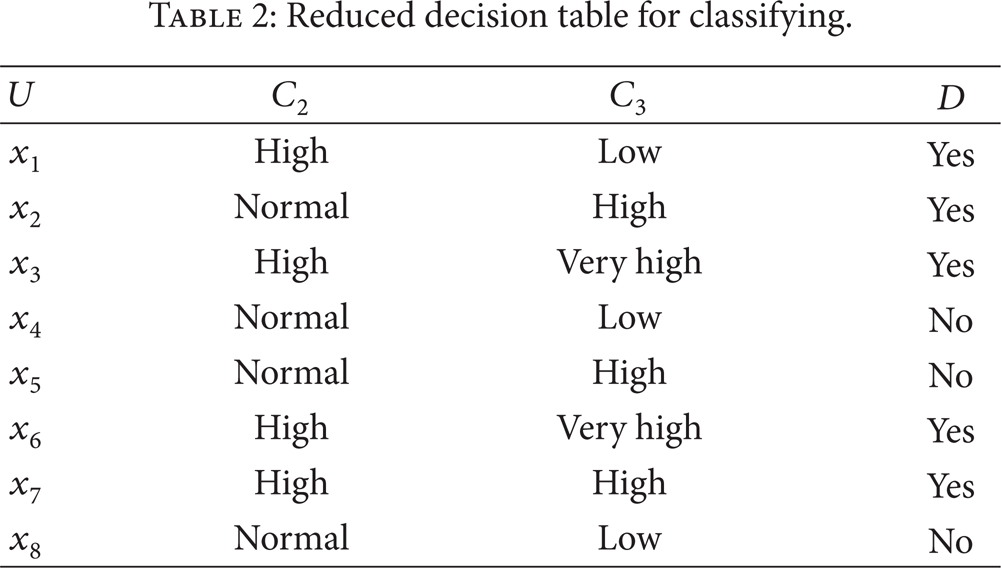
The testing work was carried out on an in-use pump in Tuha oil field in China. Under the consideration of the potential damage to the five-plunger pump and economic cost the faults were simulated mainly in the hydraulic-end of the pump during the experiment. Vibration signals were collected for both normal condition, and several different abnormal conditions. The accelerometers were mounted on the housing at the hydraulic-end of the pump. The crank shaft of the pump was running at approximately 370 rpm (6.17 Hz). The sampling rate was 2000 Hz. Figures 1 (a) and 1 (b) show the magnitude plot of the FFT of the vibration data (the frequency spectra of vibration signals).

Frequency spectra from different vibration signals for different conditions. (a) Normal condition and (b) comprehensive faults both on the second and third inlet valves.
Figure 1 is an example of two typical frequency spectra derived from a dynamic vibration signal collected from the hydraulic-end. This figure shows a fault spectrum and a nonfault spectrum. It is clear that in this case (as well as many others) differences between spectra are quite straightforward. Designing automatic diagnostic tools for these cases is not a problem. Difficulties arise when the differences between signals (and spectra) representing different faults are much more subtle. Figure 2 is an example of two spectra representing well-developed faults of different nature that look similar. In this case, there is a considerable amount of uncertainties and a rigorous and finely tuned automatic diagnostic tool is required.

Two frequency spectrum representing well-developed faults of different nature that looks similar. (a) and (b) Damage on the second plunger and forth exhaust valve, respectively.
Not only are individual samples of frequency spectra representing different faults often rather similar, but also the variability within a group of spectra that represent the same fault is often significant. Figures 3 (a) and 3 (b) show two frequency spectra that represent the same sample fault. The challenge is to provide early detection capability as well as distinction between fault types with a low risk of false alarms.
Two frequency spectra that represent the same sample fault; (a) and (b) failure both on the second inlet valve.
In the fault diagnosis of the pump, the frequency spectra of the vibration signals contain complicated information of the running condition. To ensure the reliability of the rough set theory for the fault diagnosis of the pump, it is important to extract the condition attributes from the frequency spectra of the vibration signals.
The vibration energies of the horizontal direction in the hydraulic-end of the pump mainly concentrated on the 3 frequency bands: 0–60 Hz, 90–190 Hz, and 300–500 Hz. In the rest of the frequency range 500–800 Hz, there is little of energy distribution with almost no changes in level. The impulse amplitude modulation due to the load variation through the crank shaft revolution (6.17 Hz) is evident. As shown in the above figures, the range where the energy occupies in the frequency spectra is wide and the impulse peaks of frequency spectra are numerous and appear as clusters. These demonstrate the hydraulic pulsation caused by reciprocating motions of the plungers of the pump, the impact impulses excited by the open and shut-off of inlet and exhaust valves in the hydraulic-end of the pump, and the periodic impact vibration caused by the motions of the rotational and reciprocating parts. Due to the subtle changes of the fine frequency structure in vibration signal spectra, direct application of spectra would result in a difficult interpretation and the main events would be difficult to isolate. However, we know that, when the fault of the pump occurs, the changes of the vibration of excitation resource not only lead to changes in each class fault pattern but also result in changes in the overall energy content of the signal which will lead to an increase or decrease in the general spectrum level. So we can utilize these changes to extract features of the frequency components from the spectra and then employ the fuzzy diagnostic method to identify the conditions of the pump. The values of the constituent parts of the frequency band can represent the energy level of the vibration signal in the frequency domain.
Eight features are selected from the frequency spectra obtained from the vibration signals tested on the horizontal direction of the hydraulic-end of the pump. These features are defined as follows.
f1: 5 kHz peak energy, to perform the peak energy analysis of the vibration signal, a three-step method is proposed, consisting of (a) using a band-pass filter of high cut-off frequency, for example, 5 kHz, to extract the lower and higher components from the acquired signal in time domain by removing the other events, (b) demodulating the reserved time signal, (c) transforming the demodulated signal to the frequency domain obtaining the 5 kHz spectrum, and then selecting the highest magnitude as the 5 kHz peak energy.
f2: 5 kHz total peak energy.
f3: the peak magnitude in the frequency range of 0–36 Hz which is mainly excited by the unbalance reciprocating motions of the plungers. The revolution of the crank shaft is 317 rpm (6.17 Hz), so the frequency of the plunger motion is about 31 Hz (5 × 6.17).
f4: the peak magnitude in frequency range of 37–66 Hz. This frequency range represents the vibration frequency of the open and setting-down of inlet and exhaust valves and the changes of the direction of the impulse forces applied by the changes of the motions of the plungers.
f5: the peak magnitude in range of low-middle frequency section of 67–100 Hz.
f6: the peak magnitude in range of middle frequency section of 101–250 Hz.
f7: the peak magnitude in range of middle-high frequency section of 251–500 Hz.
f8: the peak magnitude in range of high frequency section of 501–800 Hz.
The features 5 to 8 are all of the harmonics of the frequency components of motions of the crank and plungers. These eight eigenvalues compose the crisp universal set F = {f1, f2, f3, f4, f5, f6, f7, f8} of the condition features. Table 5 shows the eight eigenvalues for normal running condition and different types of faults simulated in the hydraulic end of the pump. Four major types of mechanical faults, namely, failure on the second inlet valve, failure on the second plunger assembly, damage on the forth exhaust valve, and comprehensive faults both on the second and third inlet valves, are considered here. Among them, failure on plunger assembly is the most common fault that contributes nearly 56% of the pump faults. Inlet valve and exhaust valve are easily damaged components which account for about 11% and 13% of the pump faults, respectively. There are 14 sample sets representing 5 different types of the conditions given in Table 5. These 5 different types of conditions denote the decision set of fault causes D = {d i } (i = 1, 2, 3, 4, 5). The decision attributes can be described as

Simulated data of the different fault conditions of a five-plunger pump.
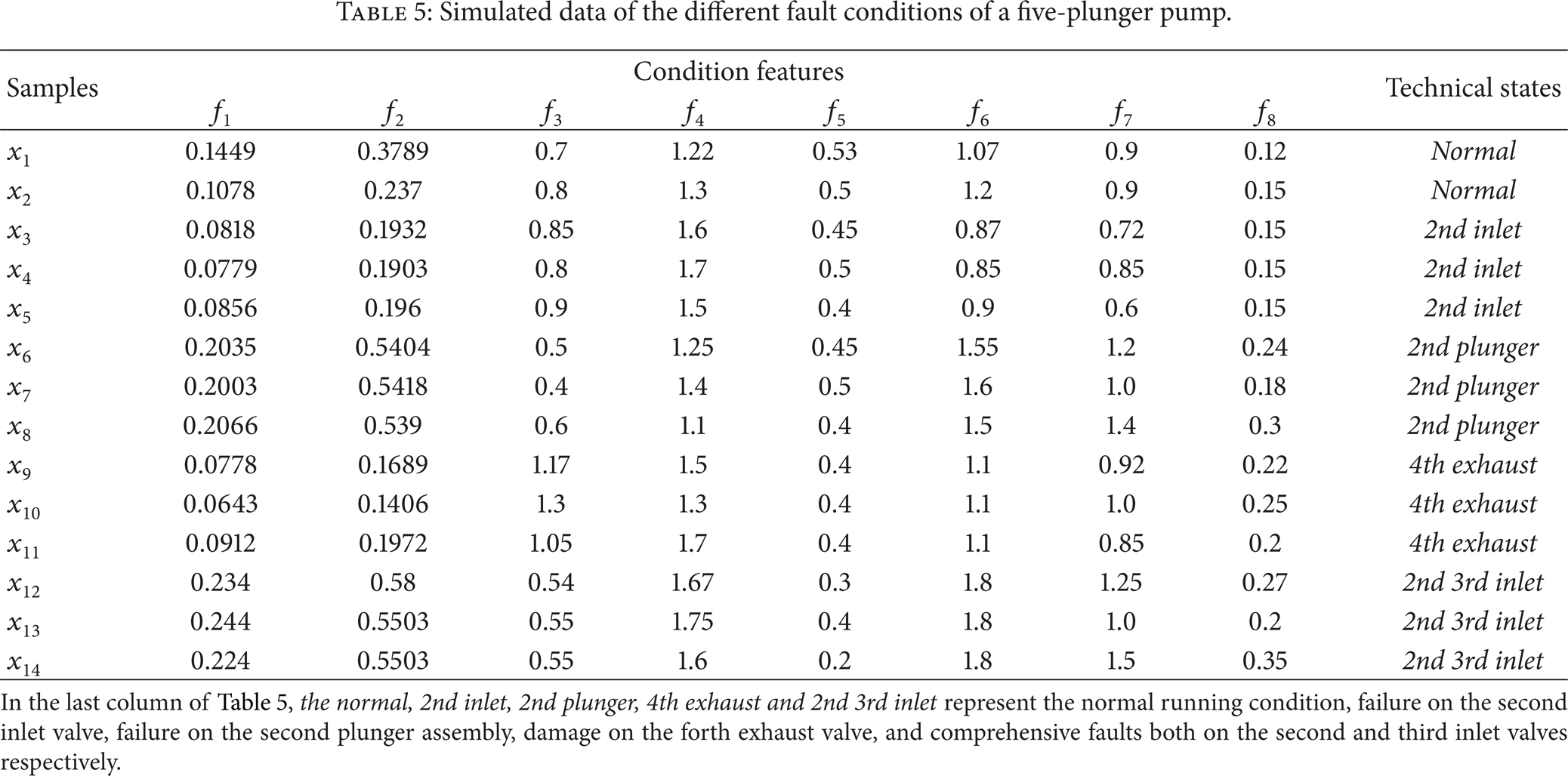
In the last column of Table 5, the normal, 2nd inlet, 2nd plunger, 4th exhaust and 2nd 3rd inlet represent the normal running condition, failureon the second inlet valve, failureon the second plunger assembly, damage on the forth exhaust valve, and comprehensive faults both on the second and third inlet valves respectively.
3.2. Discretization of Continuous-Valued Attributes for the Pump Fault Diagnosis
It can be seen from Table 5 that the condition attributes are continuous variables. They take on numerical values and have a linearly ordered range of values. When dealing with the data of the attributes in the pump diagnosis in the context of rough sets methodology, only the discrete-valued attributes can be used to select the group of condition attributes [15, 16]. So the range of a continuous-valued attribute should be partitioned into subranges. Such a process is known as discretization. However, discretization should be done in such a way to provide useful classification information with respect to the classes within an attribute's range. That is, the purpose of the discretization of continuous-valued attributes is to translate the continuous values into some qualitative characters which are compatible with the information table. This translation involves a division of the original domain into some subintervals and an assignment of qualitative codes to these subintervals. Definition of boundary values of the subintervals can influence considerably the quality of the classifications. Basically, a threshold value, T i (i = 1, 2, …, N, N is the maximum group number of the condition attributes), for a continuous-valued attribute, c i , is first determined. The set c i < T i (the value of attribute c i which is less than T i ) is assigned to a certain code, while c i ≥ T i (the value of attribute c i that is greater than or equal to T i ) is assigned to the other code. Such a threshold value, T i , is called a quantization parameter. More specifically, given an information system, S, which is composed of M training examples, the discretization of a continuous-valued attribute, c i , can be based on maximum covariance between the classes for the selection of a quantization parameter, to partition the domain range of c i into two subdomains. Using a criterion of the consistency of classification it is possible to judge the consistence between the information systems before and after discretization. The details of the algorithm are as follows.
Initiate the number of classes, m = 2.
Set the initial number of condition attribute, n = 1.
Sort the training samples according to the condition attribute values of nth dimension from the smallest to the largest.
Classify the condition attributes sorted of the nth dimension.
Take boundary value of the condition attributes of adjacent two classes as the quantization parameter. Thus, for each continuous-valued attribute, M-1 evaluations will take place. (Analysis shows that the potential quantization parameter for partitioning the continuous-valued attribute will not lie between a pair of training samples with the same class in the sorted sequence. In other words, the best quantization parameter always lies between a pair of training samples belonging to different classes in the sorted sequence. This means that the evaluation of a potential quantization parameter will only be carried out when a pair of training samples with different classes is spotted.)
Quantitate the continuous-valued condition attributes using the quantization parameter of these two condition attributes and then calculate the covariance, σm, n, between them for mth class.
Partition the set of training samples into two subsets at each candidate quantization parameter; compute the consistency of classification of the resulting partition. The consistency, denoted by Q U (X), can be formalized as follows:
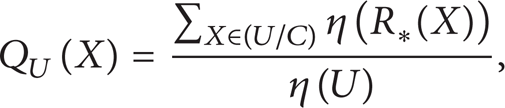
where R*(X), the lower approximation of X, is the set of all elements of U which can be certainly classified as elements of X using the set of attributes C · η(R*(X)) and η(U) denote the cardinality of the sets R*(X) and U, respectively. The criterion of the consistency of classification (4) gives the ratio of all correctly classified objects to all objects in the system. At first, the consistency of classification for continuous-valued attributes should be computed. Then that of the discrete-valued attributes can be searched for, ensuring the same quality.
Let n = n + 1, then return to Step 3 until the final dimension condition attributes.
When m ≤ M1, a given positive integer value, check whether the parameter table is comparative or not. If it is not compatible, let m = m + 1 and return to Step 2. When m > M1, let m = m + 1, and return to Step 2, until m = M2, maximum number of the technical classes, and M1 < M2.
According to the relationship of m and σm, n, σm, n will increase with m increasing for mth dimension condition attributes until m = m0, then it will decrease with m still increasing. So the optimum classification number is at the turning point m0 on the curve m-σm, n.
Again check whether the parameter table it is compatible or not. If it is not, then let m0(n) = m0(n) + 1, and return to Step 2, until it is compatible.
Let the condition symptoms be training samples, and let the eight features of the frequency spectrum, of the vibration signal be the condition attributes, that is f i = c i (i = 1, 2, …, 8), in fault models, respectively. The algorithm mentioned above is used first to determine the quantization parameters of each continuous-valued condition attributes presented in Table 5, with the optimum quantization parameters being shown in Table 6. Then the original values of the features can be translated into subintervals coded by numbers 1, 2,… with the determined quantization parameters. As a result of this translation the so-called coded information table, Table 7, is obtained which is further analysed. The rows in Table 5 describe the training samples of fault classes, and the columns represent the attributes of the samples. Tables 6 and 7 have the same format.
Quantization parameters of the continuous-valued condition attributes.

Coded information table for fault diagnosis.
3.3. Derivation of the Diagnosis Rules
In Table 7, there are 30 objects in the universe of discourse or condition discrimination domain U. This means that the information table for the fault diagnosis of the pump is composed of 30 implied diagnosis rules. These rules, however, are not completely meaningful in the practical diagnosis work. According to rough sets theory, the diagnosis rules can be directly extracted by calculating and reducing the data in the information table. Any set of limited decision, expressed by decision logical language (C ⇒ D), is called decision algorithm [15, 17, 18] or abbreviated as algorithm (C, D). All sets which cannot be omitted in the algorithm (C, D) compose the core of algorithm (C, D), expressed by core (C, D). The core values of the algorithm of the condition attributes in the information table can be computed by the following equation:

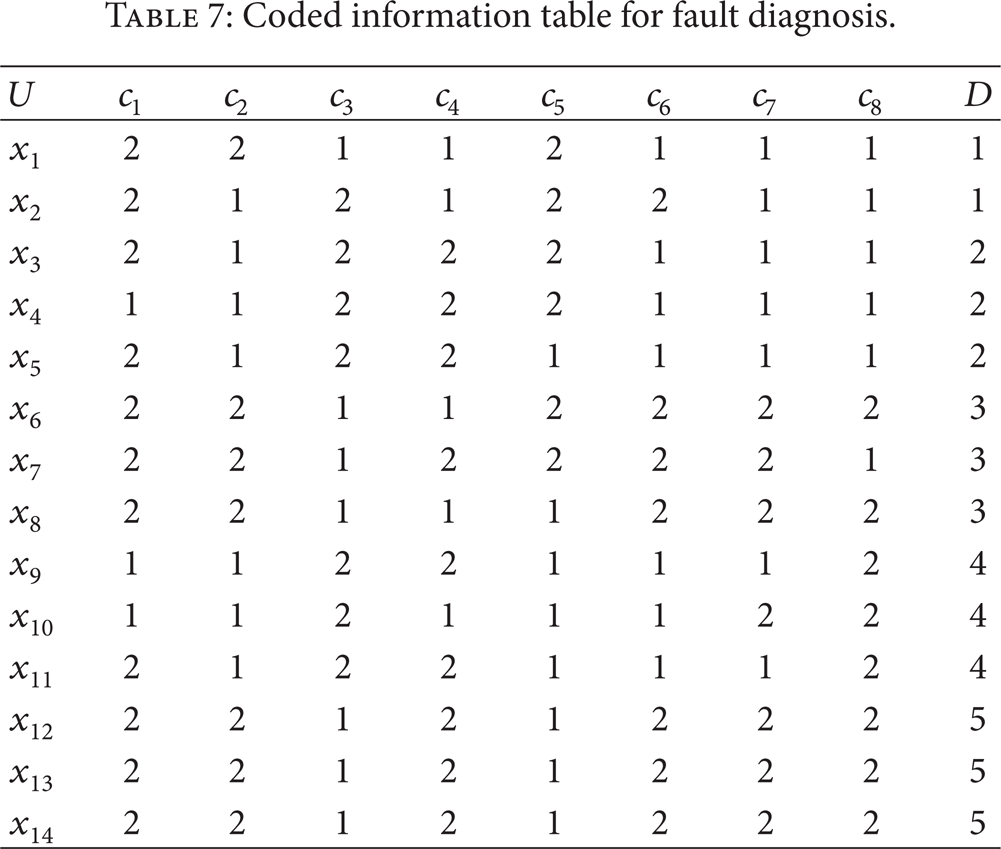
where Red (C, D) is all reduction family of the condition attributes. Through computation, it is found that the condition attributes c1, c2, c3, c5, c6, and c7 are redundant. This means that the information table will be compatible when removing the condition attributes c1, c2, c3, c5, c6, and c7, respectively, thus, the three reductions {c2, c4, c8}, {c3, c4, c8}, and {c3, c6, c8} can be obtained and the core values are c4 and c8. That is
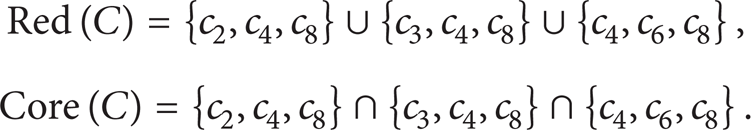
The reduction {c2, c4, c8} will be discussed in the following paragraph, while the meanings of the rest of the reductions are similar. After removing the superfluous condition attributes, the decision rule in the reduced information table can be deduced, that is, to compute the core of diagnosis rules C ⇒ D:

where Red (C ⇒ D) is the set of all reduction C ⇒ D. The reduced diagnosis rules through the computation with (5) and (7) are shown in Table 8. The symbol (*) in Table 8 indicates that the influence of the values of the condition attributes on the fault diagnosis can be ignored.
Reduced information system for the pump fault diagnosis.

The fault diagnosis rules in Table 8 can be expressed with decision logical language.
Rule 1. (c2 = 1) and (c8 = 1) ⇒ D = d1 = 1.
Rule 2. (c2 = 1) and (c4 = 2) and (c8 = 1) ⇒ D = d2 = 2.
Rule 3. (c2 = 2) and (c4 = 1) and (c8 = 2) ⇒ D = d3 = 3.
Rule 4. (c2 = 2) and (c4 = 2) and (c8 = 1) ⇒ D = d3 = 3.
Rule 5. (c2 = 1) and (c8 = 2) ⇒ D = d4 = 4.
Rule 6. (c2 = 2) and (c4 = 2) and (c8 = 2) ⇒ D = d5 = 5.
The above rules can be translated into the logical statements (if…then…). For example, the meaning of the rule, (c2 = 1) and (c4 = 2) and (c8 = 1) ⇒ D = d2 = 2, is as follows.
If 5 kHz peak energy (c2) is less than 0.3 and the peak magnitude in frequency range of 37–66 Hz (c4) is equal to or larger than 1.4 and the peak magnitude in range of high frequency section of 501–800 Hz (c8) is less than 0.2, then the fault of the pump takes place likely on the second inlet valve.
Similar analysis can be carried out to derive reasonable rules for fault diagnosis when a pump has been detected. This shows that the proposed approach is able to gather a set of rules, which describes the general pattern of decision making by domain experts. With the rules extracted, a knowledge-based system can be developed to diagnose the pump faults.
3.4. Test Result Analysis
With the rules described above, the technical states of the pump can be diagnosed. Some of the test samples corresponding to normal running and with various fault conditions of the pump are shown in Table 9. Based on the sample data of the pump under different conditions, the coded condition attributes in the form of an information table (Table 10) are established by the discretization algorithm discussed in Section 3.2. The reduction and the core of the pump with different running conditions are then determined. This result in a minimum attribute set for diagnosing the pump faults. Both the minimum coded condition attributes and one decision attribute (D) are depicted in Table 11. Based on the rules extracted, the final diagnosis results of the detected pump can be discussed as follows.
Samples diagnosed of the pump.

Discretization attributes of the samples in Table 9.

Diagnosis results for different fault types.

Rule 1. Because the peak magnitudes in frequency range of 37–66 Hz (f4 = 1.38) are less than 1.4 (c4 = 2) and the peak magnitude in range of high frequency section of 501–800 Hz (f8 = 0.14) of sample y1 is less than 0.2 (c8 = 1), the sample y1 represents the pump in normal condition (d1 = 1).
Rule 2. Because 5 kHz peak energies (f2 = 0.2292 and f2 = 0.1845) are less than 0.3 (c2 = 1), the peak magnitudes in frequency range of 37–66 Hz (f4 = 1.74 and f4 = 1.65) are larger than 1.4 (c4 = 2), and the peak magnitudes in range of high frequency section of 501–800 Hz (f8 = 0.11 and f8 = 0.13) are less than 0.2 (c8 = 1) of samples y2 and y9, the samples y2 and y9 are detected as the fault of the pump takes place likely on the second inlet valve (d2 = 2).
Rule 3. Because 5 kHz peak energies (f2 = 0.6403, f2 = 0.7211, and f2 = 0.5785) are larger than 0.3 (c2 = 2), the peak magnitudes in frequency range of 37–66 Hz (f4 = 1.35, f4 = 1.37, and f4 = 1.24) are less than 1.4 (c4 = 1), and the peak magnitudes in range of high frequency section of 501–800 Hz (f8 = 0.25, f8 = 0.31, and f8 = 0.26) of samples y3, y7 and y8 are larger than 0.2 (c8 = 2), the samples y3, y7, and y8 can be diagnosed as the fault on the second plunger assembly of the pump (d3 = 3).
Rule 5. Because 5 kHz peak energies (f2 = 0.1604, f2 = 0.1771 and f2 = 0.1784) are less than 0.3 (c2 = 1) and the peak magnitudes in range of high frequency section of 501–800 Hz (f8 = 0.27, f8 = 0.25, and f8 = 0.24) of samples y4, y10 and y11 are larger than 0.2 (c8 = 2), the samples y4, y10, and y11 indicate that the pump runs under abnormal condition withfault on the forth exhaust valve (d4 = 4).
Rule 6. Because 5 kHz peak energies (f2 = 0.5009 and f2 = 0.5697) are larger than 0.3 (c2 = 2), the peak magnitudes in frequency range of 37–66 Hz (f4 = 1.66 and f4 = 1.58) are larger than 1.4 (c4 = 2), and the peak magnitudes in range of high frequency section of 501–800 Hz (f8 = 0.31 and f8 = 0.33) of samples y5 and y6 are larger than 0.2 (c8 = 2), the samples y5 and y6 show that the faults of the pump take place likely on the second and third inlet valves at the same time (d5 = 5).
According to the rules, we can reach all the diagnosis results. It can be seen from Table 11 that the decision results of the samples diagnosed are identical to the experiment results (Table 9). Generally, the diagnostic results are quite right. We would like to point out that the samples used here are not sufficient but are practically enough to illustrate the strategy with rough sets theory and how the original data set is transformed into a diagnostic information system directly.
4. Conclusion
This work shows that the basic concepts of rough sets theory provide a way to recognize and diagnose the pump faults. A practical case is used to illustrate the effectiveness of the technique. It is found that the preferential information about certain condition of the pump can be obtained easily and an adapted information table can be constructed readily by using the rough set approach. With the adapted information table established, the minimal diagnostic rule set that exits in a training data set can be obtained to classify technical states of the considered object. This rough approach makes a maintenance engineer in an oil field able to carry out fault diagnosis in an efficient manner and to know what kind of fault information is unimportant or redundant, which will not influence the fault diagnosis result, being missed or mistake occurred. The diagnostic investigation is done on data froma five-plunger pumpin outdoor conditions on a real industrial object. Results show that the new approach can effectively identify different operating states of the pump, which will supply as a basis for the detection and diagnosis of the pump faults.
Footnotes
Acknowledgments
This research was supported by science research plan in Education Department of Shaanxi Province of China (Program no. 07JK365). The author is grateful to Tuha Petroleum Company of China for their kind provision of access to the five-plunger pump and the test-bed. The author would also like to express her appreciation for the useful suggestions put forward by Professors Wei Wang and Xiaohong Zhao of Xi'an Shiyou University.