
Abstract
Wireless sensor networks (WSNs) are a fundamental building block of many pervasive applications. Nevertheless the use of such technology raises new challenges regarding the development of reliable and fault-tolerant systems. One of the most critical issues is the detection of corrupted readings amidst the huge amount of gathered sensory data. Indeed, such readings could significantly affect the quality of service (QoS) of the WSN, and thus it is highly desirable to automatically discard them. This issue is usually addressed through “fault detection” algorithms that classify readings by exploiting temporal and spatial correlations. Generally, these algorithms do not take into account QoS requirements other than the classification accuracy. This paper proposes a fully distributed algorithm for detecting data faults, taking into account the response time besides the classification accuracy. We adopt the Bayesian networks to perform classification of readings and the Pareto optimization to allow QoS requirements to be simultaneously satisfied. Our approach has been tested on a synthetic dataset in order to evaluate its behavior with respect to different values of QoS constraints. The experimental evaluation produced good results, showing that our algorithm is able to greatly reduce the response time at the cost of a small reduction in classification accuracy.
1. Introduction
Wireless sensor networks (WSNs) are a pervasive computing technology that is experiencing broad diffusion and use in many ICT applications both in the industrial and research fields [1]. The typical WSN is composed of several resource-constrained devices (sensor nodes) capable of sensing environmental quantities, such as light intensity, air humidity, and temperature; even though their nature allows for significant flexibility, thanks to the possibility of performing small on-board computations and of cooperating with each other, such nodes are also prone to faults of different natures that could weaken their effectiveness as a pervasive sensory tool.
Malfunctions may be due to several causes, such as harsh environmental conditions, resulting into hardware failures; power outages, producing incorrect sensory readings or possibly altering communications; or sensor miscalibrations, having an effect on the ADC transducer; consequently, they may be classified according to the architectural level they affect the most, that is, Network level, Node level, or Sensor level [2]. Network faults include loss of connectivity, routing loops, and congestion, and they affect the exchange of data among nodes, so they are perceived as link failures. Node faults are malfunctions of the main components of the sensor node, that is, radio, CPU, battery, and memory; they include unexpected resettings, meaningless values of sensed data, and poor quality of transmissions, and they are perceived as link failures and data failures. Sensor faults only affect the quality of sensed data and are always perceived as data failures.
In order to understand the factors that may negatively affect the QoS provided by a WSN, it is important to capture the root cause of a fault; this often represents a challenge for the researcher and requires the adoption of artificial intelligence techniques [3, 4]. Research has traditionally focused on the task of fault detection, and in this work we specifically address data faults, which occur when gathered data does not provide a reliable representation of the monitored physical phenomenon; in this case, transmission and processing of these data clearly constitute a waste of energy and time and the overall QoS gets worse. On the contrary, early detection of data faults helps reducing the amount of sensory data to be processed by high-level systems, and in-network fault detection is in fact a crucial functionality for many WSN-based applications [5].
A high accuracy of the fault detection algorithm contributes to address the reliability requirements of WSN applications; however, this is not the only relevant requirement of such a type of pervasive system; other significant requirements may be a low communication latency, a long WSN lifetime obtained through energy consumption reduction, and so on.
To the best of our knowledge, works proposed in the literature coping with the fault detection problem neglect other QoS requirements. Here we propose QoS-aware fault detection (QAFD) implemented as a distributed in-network algorithm, that has the aim of not only maximizing the accuracy of the fault detection but also minimizing the response time for such a task; we address the issue of combining these two different and contrasting goals by exploiting the constrained Pareto optimization. Each node is left free to decide whether to cooperate with its nearby nodes by exchanging its readings with them; the cooperation increases the accuracy of the detection; instead, the noncooperation reduces the response time. The fault detection is performed by running probabilistic inference on a Bayesian network distributed over the whole WSN; the distributed architecture makes the system highly reactive to changes in the monitored phenomena and allows the reduction of the computational effort required to the single node. The Bayesian network structure is also adapted at runtime to reflect the choice of cooperating or being not performed by sensor nodes; the more complex the structure, the higher the classification accuracy of the WSN; the simpler the structure, the lower the response time.
2. Related Works
Fault detection is a widely studied topic in WSN research, but its correct definition differs from that which is generally adopted in other fields. According to the classical point of view in statistics and data mining, a data fault corresponds to a data pattern not complying with a well-defined normal behavior [6]. This definition does not apply to WSNs, because in such context we are usually unaware of the ground truth; thus, the data fault definition can be modified as a “data pattern not conforming to the expected behavior of the monitored quantity.”
Many works in the WSN literature extend such a definition by providing a complete taxonomy of data faults occurring in wireless sensor nodes. The authors of [2] classify data faults as temporal or spatial anomalies; the former class includes high variability, frozen outputs, and out-of-bound errors; the latter class includes calibration errors and a burst of values that differs from that of the average in the neighborhood. Temporal anomalies can be detected locally by considering temporal series of data gathered by a single node, while the detection of spatial anomalies mandatorily requires the comparison of a single sensory measurement with data gathered by surrounding nodes. Also the authors of [7] propose a similar classification of data faults by distinguishing among short (single or multiple values of out-of-bound readings), noise (data with high variance), and constant (frozen output); for the purpose of our work, we adopted the latter taxonomy.
Fault detection algorithms are usually classified with respect to two different perspectives: architectural and methodological [2]. The architectural perspective distinguishes two types of approaches: Centralized [8, 9] and Distributed [10, 11]. In a centralized architecture, data flow from sensor nodes to the base station that performs fault detection by analyzing the whole amount of received data; this approach is limited by the resources of the base station that constitute a single point of failure. Moreover, faults are discovered only after their transmission, thus causing a waste of energy and time inside the WSN. In a distributed architecture, sensor nodes monitor their status and label their readings as corrupted or not; if a reading is classified as corrupted, it could be locally discarded. The classification accuracy of such approaches is usually lower than that of the centralized ones; nevertheless, the fault detection occurs earlier with respect to centralized approaches, since it is not necessary to wait for the complete data transmission toward the base station.
From a methodological point of view, it is possible to distinguish between Threshold-based approaches [11, 12] and Classification-based approaches [13–15]. The former class uses thresholds to perform fault detection; just as an example, consider the majority voting schemes and the cluster-based method, where thresholds are used to separate readings in “good” and “corrupted.” Such approaches are generally not much expensive in terms of computational and time resources, but the classification accuracy is highly dependent from the chosen threshold values; thus, performances are quite unpredictable unless an extensive empirical tuning is performed in order to find the optimal threshold values. The latter class avoids the use of thresholds; thus, no human intervention is required to correctly tune the classifier. As an example, in these categories we can find Bayesian Networks and Neural Networks approaches; in both cases, during an offline learning phase, a model is automatically learnt from raw data, while an online algorithm exploits the learnt model in order to perform fault detection. Such methods are computationally and time expensive, but their classification accuracy is predictable, since it is determined by the learning phase.
A great weakness for each of the described approaches is that they present a fixed computational complexity, strictly dependent from the adopted method; moreover, the computational complexity highly affects the ideal upper bound of classification accuracy. As a consequence, in noisy scenarios or when achieving a high classification accuracy is very important, it is suitable to adopt a more precise approach, even if it is more resource demanding. On the contrary, in less dynamic scenarios or when the focus is on the response time, it is more convenient to adopt a less expensive approach even if the classification accuracy is lower. To the best of our knowledge, none of the works presented in the literature seems suitable to be adopted in every type of scenario, and to support a tunable ranking of QoS requirements (for instance, a real-time scenario may require a priority on response time rather than on classification accuracy). None of them is able to tune the classification accuracy and the computational complexity against the response time. In order to design a data-fault detection algorithm that is able to fuse different QoS requirements, we formulated such a task as a multiobjective problem and we adopted the Pareto optimization in order to deal with different and typically contrasting objective functions. The use of that theoretical framework is not totally new in the WSN research field; indeed, it has been adopted for many different purposes. The authors of [16] define a set of metrics for evaluating network performances with respect to reliability, lifetime, and coverage; the proposed experimental evaluation showed that the set of all possible solutions can be easily clustered and one of the identified clusters is the Pareto optimal with respect to the considered qualitative dimensions. Finally, the authors of [17] cope with a multiobjective problem in an heterogeneous sensor network, and in that case the goal is to find the trade-off between the number of active sensor nodes and the network energy consumption.
3. Proposed Approach
We propose a distributed algorithm for detecting corrupted sensory readings by means of a Bayesian network distributed over sensor nodes. In such inference overlay network, the belief about the correctness of sensory readings is updated thanks to communications among nodes. The use of a large Bayesian network allows for obtaining a high classification accuracy, but, at the same time, it might cause a high response time; for such a reason, our system uses the Bayesian networks with dynamic structure in order to be able to adapt them according to the characteristics of the specific WSN deployment field. This adaptivity is obtained by allowing each sensor node to choose the set of neighbor nodes to cooperate with and possibly also to choose to not cooperate at all. In the latter case, the sensor node tries to detect its own corrupted sensory readings by exploiting only temporal correlation among local measurements. On the contrary, if a node chooses to cooperate with its neighborhood, shared information is used as an additional evidence so that each node can also exploit spatial correlation for classifying its own readings. These independent and dynamic decisions drive the fault detection system toward the configuration that represents the best trade-off among all possibly contrasting application goals, such as high classification accuracy and low response time. Our distributed QoS-aware fault detection algorithm (QAFD) is composed of two main building blocks: a fault detection algorithm, based on the Bayesian networks, and a QoS-aware optimization algorithm, periodically affecting the structure of the Bayesian networks. It is worth noting that both the fault detection and the QoS-aware optimization are locally performed in every sensor node. Figure 1 shows the interaction between these two logical blocks within a single sensor node. The fault detection block takes as an input the sensory reading to be classified and the set of neighbor nodes to cooperate with. Such block, besides classifying the latest sensory reading, produces a set of QoS indices, namely, the classification accuracy and the response time. Such indices are then used by the QoS-aware optimization block for modifying the cooperating node list for the next step.

Block diagram of QAFD algorithm.
Figure 2 shows the dynamic arrangement of the overlay communication graph performed by the QAFD, in a simple running example. Let us suppose that at time

The dynamic arrangement of the overlay communication graph for five sensor nodes at different time instants.
3.1. Fault Detection
Fault detection is solved using distributed inference over a Bayesian network built on top of the cooperation network. The distributed inference algorithm takes as an input a set of readings gathered by sensor nodes and provides the classification of readings into corrupted and uncorrupted ones. A first convergecast phase builds an initial estimate of the belief about reading classification, and a further broadcast phase refines such belief by adding information gathered over the whole cooperation network.
The bayesian networks are represented by a directed acyclic graph made up of random variables

In our system, each sensor node implements a small Bayesian network composed of one hidden variable c representing the (estimated) class of the current sensory reading and a set of observable variables representing the evidence probabilistically deriving from the true value of c. Observable variables can therefore be considered as features related to the spatiotemporal correlations among readings.
Fault detection finds the combination of values for the hidden variable of each node that maximizes its a posteriori probability, given the evidence. We demonstrated, in a previous work [18], that the maximum a posteriori (MAP) approach is highly suitable to be implemented in WSNs, since it avoids the use of fixed thresholds and it is not too computationally expensive for sensor nodes.
Let

The Naive Bayes classifier, for a single node, including only local observed variables (a), and two Naive Bayes classifiers linked by shared observed variables (b).
Besides the local observed variables, the evidence variables include a set of shared observed variables, representing the spatial correlations among readings. If i and j are two cooperating nodes, then they share a set of variables
There is a mapping between the current communication graph and the whole Bayesian network. The Bayesian network can be obtained from the communication graph by replacing each sensor node with a Naive Bayes structure and each communication link

Evolution of the Bayesian network for a simple network composed of five sensor nodes.
The definition of the adopted fault detection method is completed by specifying the hidden and observed variables and method of the MAP problem solving.
Definition 1.
The hidden variable c takes values in the set
According to the taxonomy proposed in [7] we define a
Definition 2.
Local observed variables are represented by a vectorial function of the last K readings of a single node, and they are defined as
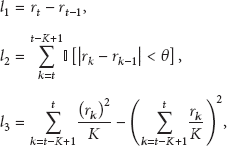
where
Although the previous set is not exhaustive and other features could be added to improve the classification accuracy, we found it is sufficient to recognize many temporal correlations among readings.
Definition 3.
Shared observed variables are represented by

The shared variables set
Definition 4.
The maximum a posteriori problem corresponds to finding the solution array,

where
In order to solve this problem, we adapted the well-known “max-product” inference algorithm [20] to the Bayesian networks. The pseudocode for the QAFD fault detection algorithm is shown in Algorithm 1. It includes two main phases: (i) a convergecast phase, estimating the probability distribution over all possible classes for each sensed reading, and (ii) a broadcast phase, determining the final class labeling. Since the communication network is arranged as a tree, we assume that any sensor node is aware of being a leaf, a root, or an intermediate node. In order to take into account the latency of the algorithm, we also included a variable that tracks the number of hops (between any node and the root of the cluster) required for computing the class label.
Convergecast
Compute local features using (2); Compute local belief using (5); Send the last reading Receive the last reading of j; Compute shared features using (3); Compute the parent's reading belief Receive Compute Send Compute optimal class label
Broadcast
Send Send 0 as latency; Receive Receive latency Compute optimal class label Compute Compute Send Send
Output
The convergecast phase starts whenever fresh readings are to be classified. Each sensor node of the cluster computes the local features

Such quantity represents the belief about the class of the sensory reading at node i, only considering local evidence. Successively, sensor nodes exchange their own readings with their direct neighbors, so they can compute also shared features as in (3).
Each node i, with the exception of root node, sends a message to its parent j containing the parent's reading belief computed as follows:

The matrix

where the product is replaced by 1 if i has no children.
Root node r terminates the convergecast phase and computes its optimal class assignment as follows:

Then, the root node starts the broadcast phase, during which optimal classes

and it then propagates such quantity to its children. This phase ends at leaf nodes and produces the solution of the MAP problem.
The performance of the QAFD fault detection algorithm can be evaluated through the probability of correct classification,

It is also worth pointing out that the conditional probability tables, namely,
3.2. QoS-Aware Optimization
The fault detection algorithm is performed starting from a given structure of the communication network, defined in terms of clusters. The classification accuracy and the response time highly depend on the size of network clusters. In order to find the optimal cluster structure, we propose a dynamic and distributed algorithm that charges sensor nodes with determining neighbor nodes to cooperate with, on the basis of QoS indices associated with different configurations. The main goal is to find the network configuration representing the best trade-off among several application-driven QoS goals and constraints.
This QoS-aware optimization is performed through the Pareto optimization that allows to consider multiple objective functions, possibly contrasting and with noncomparable units of measurement.
Our system can be seen as a complex system where each agent interacts with the environment by taking decisions

A Pareto optimal decision is defined as a decision that is not dominated by any other decision as follows:

The set of the Pareto optimal solutions constitutes the Pareto optimal front.
In addition to multiple objective functions, a real application may be characterized by a set of constraints about QoS requirements. We take into account these constraints by representing them as points in the QoS metric space; namely,
In our approach, each sensor node i is an agent of the overall system (the WSN), and it has to periodically choose the subset of neighbor nodes to cooperate with. If
The following of this section specifies all the components of our QoS-aware optimization.
Definition 5.
The decision d for node i is defined as a pair of values
Each decision of the node i corresponds to a single atomic action affecting its cooperating node list,
Definition 6.
The QoS metrics vector corresponding to a decision d is defined as

Such metrics are used for predicting the goodness of each possible decision d. The first metric,
In order to define the second metric, it is necessary to consider that the response time of the inference algorithm is proportional to the number of hops between i and the furthest node in its cluster; in the worst case i is a leaf of the tree representing the cluster topology, so the response time for node i will be at most equal to the maximum value of the response time (
The satisfiability of a decision is verified by checking that the corresponding metrics vector is not dominated by the constraints; that is
In summary, node i evaluates the impact of changing its cooperating node list by forecasting the values of the future QoS metrics for the decisions of connecting or disconnecting from each node
Pareto Optimal Front Generation
mark i as pareto optimal; mark add i to Pareto Optimal front;
Pareto Optimal decision
set set
Output
Definition 7.
The constraints array is defined as
Figure 5 shows, in our running example, the Pareto optimization performed by the sensor node 2 at time

Example of a two-dimensional Pareto optimization; the x-axis represents the response time, while the y-axis is the classification error.
In conclusion, QAFD algorithm is composed of two main blocks: a fault detection block activated for each sensory reading and a Pareto optimization modifying the communication graph over which the fault detection is performed, occurring with a period of T time steps. The QAFD is intended as a fully distributed algorithm where each sensor node runs the same program whose pseudocode is summarized in Algorithm 3.
the last K readings; list; v, the array of constraints. the probability of error;
Fault detection
Run Fault detection
Pareto optimization
Compute QoS metrics Accept d only if Accept all d as admissible; Run QoS-aware Optimization Update
Output
4. Experimental Results
This section describes the experimental evaluation of our QAFD algorithm, with the aim of proving that our approach allows sensor nodes to adapt their behavior with respect to the imposed QoS requirements and the dynamics of the real deployment scenario.
We simulated a tree-arranged WSN characterized by depth 16 and branch factor 3 and composed of 100 sensor nodes gathering temperature measurements every 30 seconds for two days. In order to build the simulated dataset we used 10 Mica2Dot sensor nodes as real generators of readings and then modified this basic dataset by adding 10 different Gaussian noise signals,
short:
noise:
constant:
where
Different scenario dynamics have been simulated by generating three different corrupted datasets where the amount of data faults corresponds, respectively, to 20%, 30%, and 40% of total number of readings. In each dataset, different classes of faults were mixed in equal parts. For each dataset, we used the first day of readings as a training set to learn conditional probability tables for the Bayesian network, while the second day was used as the test set.
4.1. Comparison with Benchmarks
The performances of QAFD algorithm, with different QoS constraints, were compared against two benchmarks, corresponding to the max-product inference algorithm over two different static network topologies. The first topology corresponds to a fully connected network, that is, a single cluster where 100% of nodes cooperate; here the average response time is static and corresponds to 28 hops, and the classification accuracy achieves its upper bound. The second one corresponds to a network where none of the nodes cooperate; that is, the number of clusters is equal to the number of nodes; in this benchmark the average response time is equal to 0 and the classification accuracy drops to its lower bound.
We want to show that the adaptive behavior of QAFD makes it able to meet the imposed constraints, while paying a small cost in terms of the possibly unconstrained metrics; at the same time, although the static topologies achieve better performance with respect to one QoS requirement, they dramatically worsen the other one. We adopted two different sets of QoS constraints; namely

Sensor nodes run the Pareto optimization every
Performances are evaluated by using the two considered QoS metrics, namely the classification accuracy (a value between 0 and 1) and the response time (measured in numbers of hops), averaged over time windows of size T and over all the networks nodes.
Figure 6 compares the performances of the four considered configurations in three different scenarios. As expected, the “100% cooperating node” configuration always achieves the best classification accuracy and the worst response time in every scenario, while the “0% cooperating node” configuration is the best for response time and the worst for the classification accuracy.
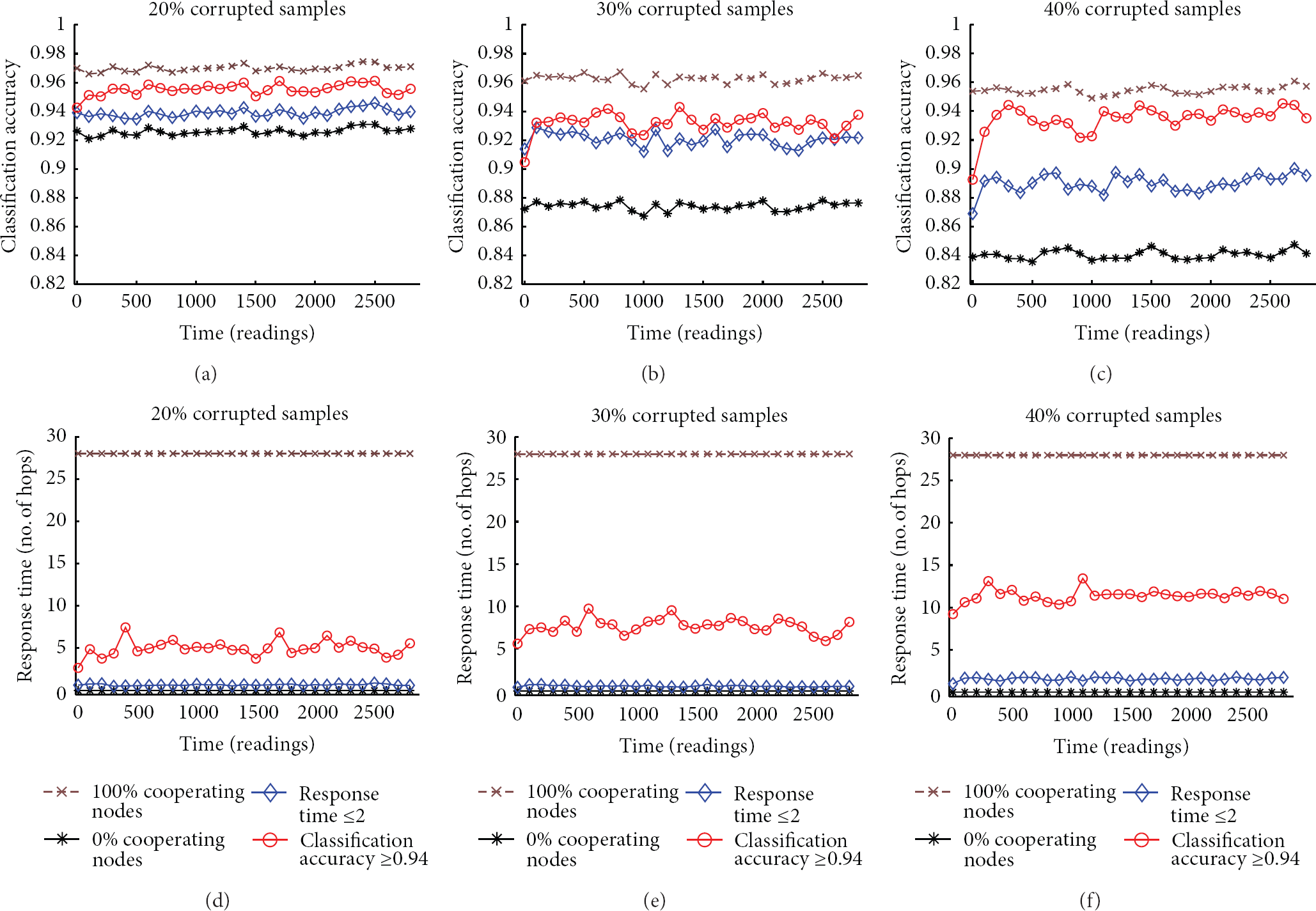
The performance of QAFD for two different constraints compared with two fixed network topologies while the amount of corrupted samples spans from 20 to 40 percent.
Analyzing the performance of QAFD with a constraint over the classification accuracy (
Analogously, QAFD with a constraint over the response time (
4.2. Adaptivity of QAFD to Different Scenarios
We aim to demonstrate the adaptability of QAFD to different scenarios, namely, to different percentages of corruption in sensory data. This adaptability corresponds to tuning the unconstrained QoS metrics in order to satisfy the constrained ones.
Figures 7 and 8 show this property by comparing the performances of QAFD, respectively, with constraints

A comparison among the average response time values for different amounts of corruption with constraint on classification accuracy.

A comparison among the average classification accuracy values for different amounts of corruption with constraint on response time.
Such results show that QAFD is able to find the correct trade-off among the QoS metrics, satisfying the imposed constraints and also taking implicitly into account the dynamics of the real deployment scenario.
4.3. Relationship between Response Time and Classification Accuracy
Obtained experimental results allow a qualitative analysis of the relationship between response time and classification accuracy in three different scenarios, as shown in Figure 9. The plots shown were obtained by averaging values obtained in the four settings described in previous experiments.
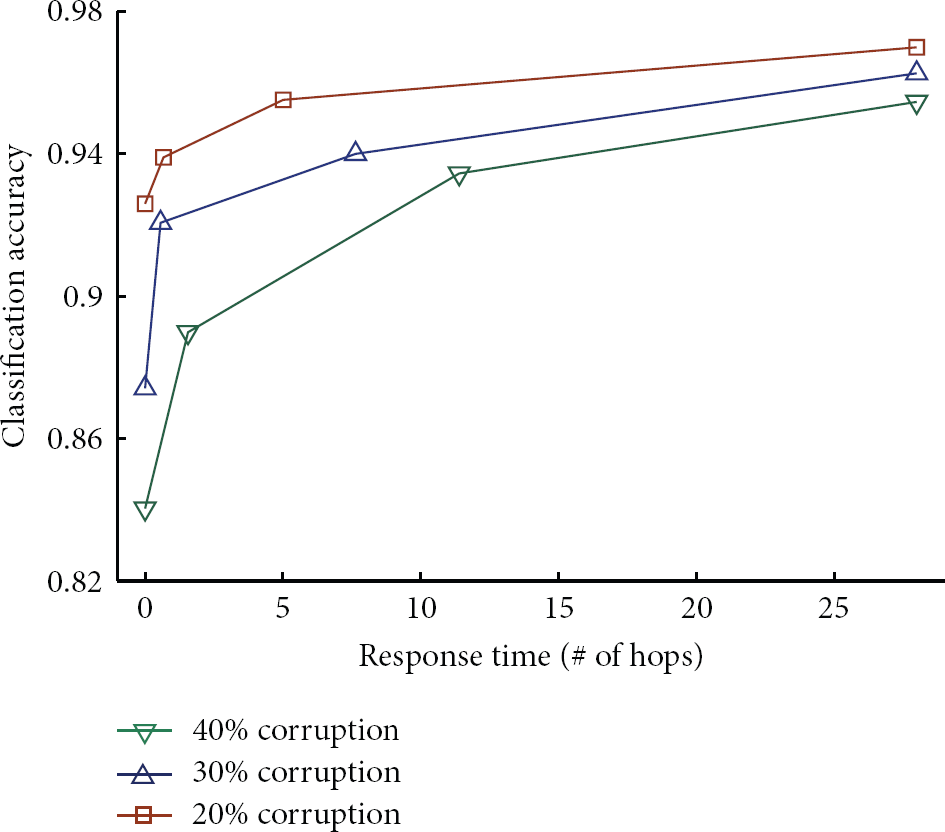
Average response time and accuracy for the three considered scenarios.
Trends are quite similar for all the three scenarios: the minimum value of the classification accuracy is obviously achieved for singleton clusters; on the contrary, a fully connected network gets the maximum of the classification accuracy.
A small increase of the allowed response time, for small cluster size, corresponds to great increase of the classification accuracy. This behavior is more visible when the corruption amounts to 20%; in this scenario a response time proportional to 5 hops corresponds to a classification accuracy very close to its maximum value.
The three plots tend to asymptotically reach their maximum value as the response time increases. Such evidence allows us to deduce that farther nodes have a small influence on the choice of the correct class label; this behavior is strictly related to the characteristic of the monitored physical quantity (e.g., the temperature) and simply means that the spatial correlation decreases as the distance between nodes increases.
5. Conclusion
This paper proposed a distributed fault detection algorithm for WSN, which is able to find the optimal trade-off among different and possibly contrasting QoS requirements. Even if we considered only classification accuracy and response time, many other QoS requirements could be considered, provided that the corresponding metric is defined.
The fault detection algorithm we proposed performs a probabilistic inference on the Bayesian networks distributed over the wireless sensor nodes. A QoS-aware Pareto optimization algorithm allows to adapt the Bayesian network structure according to the considered QoS metrics.
Experimental results showed the capability of our system to dynamically tune its behavior, also according to different dynamics of the real deployment scenario, and to optimize QoS metrics if compared with that of other static approaches.
In a future work we are going to include metrics related to network energy consumption and link quality that are other relevant QoS requirements is of WSN applications.