
Abstract
Video sensor networks are formed by the joining of heterogeneous sensor nodes, which is frequently reported as video of communication functionally bound to geographical locations. Decomposition of georeferenced video stream presents the expression of video from spatial feature set. Although it has been studied extensively, spatial relations underlying the scenario are not well understood, which are important to understand the semantics of georeferenced video and behavior of elements. Here we propose a method of mapping georeferenced video sequences for geographical scenes and use contextual random graphs to investigate semantic knowledge of georeferenced video, leading to correlation analysis of the target motion elements in the georeferenced video stream. We have used the connections of motion elements, both the correlation and continuity, to present a dynamic structure in time series that reveals clues to the event development of the video stream. Furthermore, we have provided a method for the effective integration of semantic and campaign information. Ultimately, the experimental results show that the provided method offers a better description of georeferenced video elements that cannot be achieved with existing schemes. In addition, it offers a new way of thinking for the semantic description of the georeferenced video scenarios.
1. Introduction
The notion of wireless multimedia sensor networks (WMSNs) is frequently reported as the convergence between the concepts of wireless sensor networks and distributed smart cameras [1]. As a result, an increasing number of video clips is being collected, which has created complex data-handling challenges [2]. Further, some types of video data are naturally tied to geographical locations. For example, video data from traffic monitoring may not contain much meaning without its associated location information. Therefore, most potential applications of a WMSN require the sensor network paradigm to support location-based multimedia services as well as manipulate large scale data at the same time to provide a high quality of experience (QoE), which raises an important issue. How to investigate an intelligent processing method for georeferenced multimedia? Although the question has been extensively addressed theoretically, the method of mapping video sequences to geographical scenes remains to be described. On the other hand, with the growth of geographic information system (GIS) whose major growth area is the convergence between GIS and multimedia technology, a new paradigm named video-GIS emerged [3–5]. The major researches facing video-GIS are the coding of georeferenced video and the content and types of services that should be provided by georeferenced video. Further improvement of these processes is contingent on deeper understanding of video, as well as improved understanding of the spatial relationship of geographic space. It is due to the necessity of using video-GIS to visualize the relationship between the video analysis methods and the real geographical scene, resulting in georeferenced multimedia intelligent processing method based on context-based random graphs.
Georeferenced video is fundamental process in video-GIS development. Prior research activities on georeferenced video technologies and applications have been conducted. Most of them make use of video and GPS sensors. In [6, 7], Stefanakis and Peterson and Klamma et al. proposed a unified framework for hypermedia and GIS. Pissinou et al. [8] explored topology and direction under the proposed georeferenced video. The work of Hwang et al. and Joo et al. [9, 10] defined the metadata of georeferenced video, which support interoperability between GIS and video images. In the field of georeferenced video search, Liu et al. [11] presented a sensor-enhanced video annotation system, which searches video clips for the appearance of particular objects. Ay et al. proposed the use of geographical properties of videos [12], while Wang gave a method of time-spatial images to extract the basic movement information [13]. Although single media have been studied extensively, its semantics in geographic space are poorly understood. How to determine the spatial relationship of video elements is one of the most important operations on georeferenced video. For instance, a moving video element changes its position, shape, size, speed, and attribute values over time. Understanding the changing process and rules of these attributes is of important significance to the geographical description of the video.
Many techniques for video event recognition have been proposed. As the work on model-driven methodology which has become well established and approached maturity, the most common and popular conceptualization of fusion systems is the SVM model [14, 15]. However, such methodology not only cannot solve the problems, such as multi-instance, diversity, and multimodal, but needs a large number of training samples. Most previous studies to date have used data-driven method [16] which has been carefully designed to signal clear and distinct semantic of the videos [17–21]. In our event recognition application, we observe that some events may share common motion patterns. Though involved in pattern discovery, data-driven method also contributes to social network during pattern discovery [22–25]. These works have showed a high accuracy in the differentiating of video and its semantic extraction frame. However, most multimedia applications are unknown and uncertain, which are extremely difficult to meet the requirements of real-time stream processing.
Previous studies have shown that multimedia intelligent processing method is important to the development of video-GIS and have achieved inspiring progress. However, these solution methods have suffered from the classical ensemble average limitation presented by the analysis of low-level characteristics. Therefore, the spatial data gathered are sometimes inconclusive and, in part, contradictory. These algorithms usually build or learn a model of the target object first and then use it for tracking, without adapting the model to account for the changes in the appearance of the object, for example, large variation of pose or facial expression, or the surroundings, for example, lighting variation. Furthermore, it is assumed that all images are acquired with a stationary camera. Such approach, in our view, is prone to performance instability, and thus it needs to be addressed when building a robust visual tracker.
To overcome these problems, we will begin by looking at some valid models, which are suitable for georeferenced video understanding and behavior analysis. In this paper, we propose a new event recognition framework for consumer videos by leveraging a large amount of videos. As we know, graph structure provides a complex, dynamic, and robust framework for assembling complex relationships involved in the objects [26], which is suitable for our goal. Thus, multiple random behaviors are presented in certain movement, making the graph structure unsuitable for describing the real video scenario. To circumvent this problem, random graph model has been taken into consideration, which can be seen as a rather simplified model of the evolution of certain communication net [27]. In our research, it could simplify the analysis of the interaction between video objects substantially for revealing the new insight into the relationships between objects and its complex interaction. Our analysis focuses on describing spatial relationships bound to objects using random graph grammar in georeferenced video, developing a scientific analysis of behavior and structured methods of georeferenced video understanding.
2. Preliminary
Surveillance video data is mostly non-ortho image data so that it does not match up with the geography scene vector data using the traditional method. To solve this problem, a mapping method of video scene imaging data to geography scene vector data is adopted in the paper, as showed in Figure 1. Firstly, the virtual viewpoint camera is constructed by the camera interior and exterior parameters. Secondly, geography scene virtual imaging can be gained from geography scene vector data using the process of model transformation, viewpoint transformation, and pruning according to the computer graphics rendering process, with the corresponding relationship between an object in virtual imaging and vector object. Thirdly, the image matching technology based on the features that have invariant character for translation, scale and rotation is used to match the geography scene virtual imaging and video image. Finally, the corresponding relationship between video image and vector data is established using that between an object in virtual imaging and vector object, with the purpose of accomplishing the mapping of video scene to objects in geography scene.
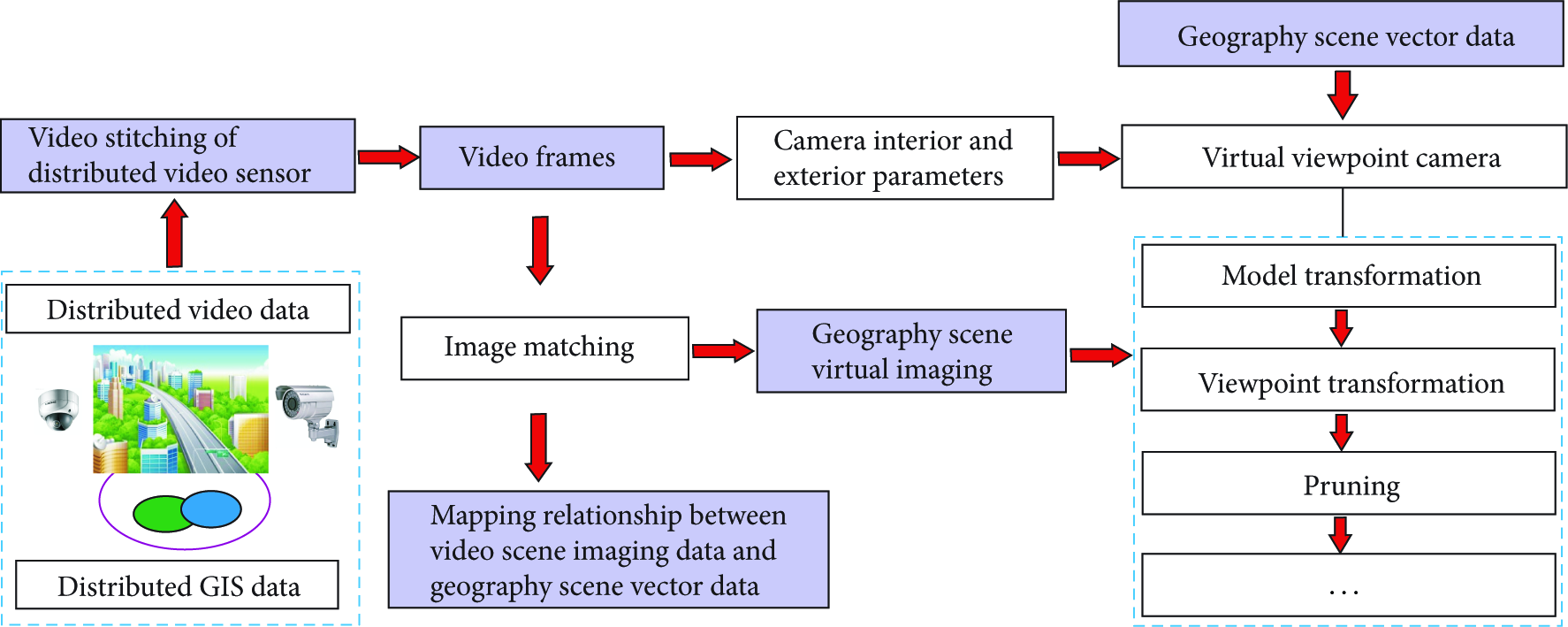
Process of the mapping relationship of video scene imaging data to geography scene vector data based on virtual viewpoint.
In the following part, we will introduce several preliminary key steps.
2.1. Selection Algorithm of Multicamera Based on Spatial Correlation and Target Priority
Multicamera surveillance system should not only gain detecting and tracking information of motion element of the single camera, but also make the coherent dynamic scene description using all the observations to some extent. Meanwhile, every motion element could be tracked by cameras simultaneously. How to select cameras for tracking a specific target is particularly important in video sensor networks. Based on the spatial correlation [28] and target priority, the paper proposes a selection algorithm of multicamera with task allocation optimized to achieve the automatic selection according to the target priority at each moment.
The algorithm is based on the assumption that a camera with no task carries out the basic single camera tracking which has lower power consumption, and the high-priority task could be preempted when bending. The selection algorithm of multicamera is shown as in Algorithm 1.
(1) begin (2) (3) Find (4) Add corresponding (5) for each (6) for each (7) (8) end for (9) (10) add (11) end for (12) return (13) end
The set of images
2.2. Organization of Video and Location Data
We have put forward a coding model of video-GIS that is comprised of video and camera's position in conjunction with its view direction and distance. Thus, the location data can be collected automatically by various small sensors to a camera, such as a GPS and a compass (see Figure 2). This eliminates manual work and allows the annotation process to be accurate and scalable. Therefore, we investigate the real-time collection, coding, and integration of video information and GPS information on the SEED-VPM642 platform, and finally we can obtain two different bit-rate location-based streaming media. The lower bit-rate one can be positioned to the wireless network broadcast live, and the higher one can be positioned to the hard disk storage.

Experimental hardware and software to acquire georeferenced video.
In the coding of video-GIS, we need to calculate the three-dimensional coordinate of the video object [29]. As video-GIS coding based on mobile sensor cannot calculate single video frame by three-dimensional control field, the most effective way is using digital map and spatial geometrical relations (see Figure 3).

Geometry for calibrating multiple sensors.
Therefore, the geometric relationship among GPS, posture sensor, imaging space, and object space should be built. It is assumed that the axis of imaging space

In detail,
For acquiring a more precise spatial locating information, we need to get the GPS information and attitude information generated by a posture sensor at least. Therefore, the spatial locating information is described by the combination of GPS and angle direction elementary (Heading, Pitch, and Roll), which obtained by Micro Inertial Measurement Unit (MIMU), as shown in Table 1.
Sample of GPS and MIMU.

As shown in Table 1, there are two kinds of the spatial locating information:
GPS information: such as UTC time and longitude latitude; angle direction elementary information: including Heading, Pitch, and Roll.
2.3. Digital Map-Based Image Resolution
The features of digital maps are expressed by a two-dimensional plane on the vertical projection of the vector data. From the standpoint of this work, the video image is a raster data expression of the feature in the height direction of the information, and video image can also be expressed as the data format of the dotted line surface after the vector processing. Video images and digital map on the point, the line, and the corresponding expression of the surface can be shown at Table 2.
Correspondence between video images and digital map.

From the view of technology, we subject map-based image resolution to a three-dimensional measurement challenge and then use single-frame video images and digital map matching to define the changes in three steps. The first step is feature extraction of dense range image, which aims to extract the features of point and line. Under the premise of the full calibration to video frame, we can identify the particular characteristics of extracted target to meet the special requirement. For instance, the corners of building or telegraph pole as a fixed line characteristic for the expression of video image is perpendicular to the target. Once formulated, the second step is to combine the line characteristics into the characteristics of the surface using texture information. The third step is matching with digital map vector data. The contents include a variety of different matching points, points and lines, a line and a line, and the line and the plane between form and technique, which is shown in Figure 4.
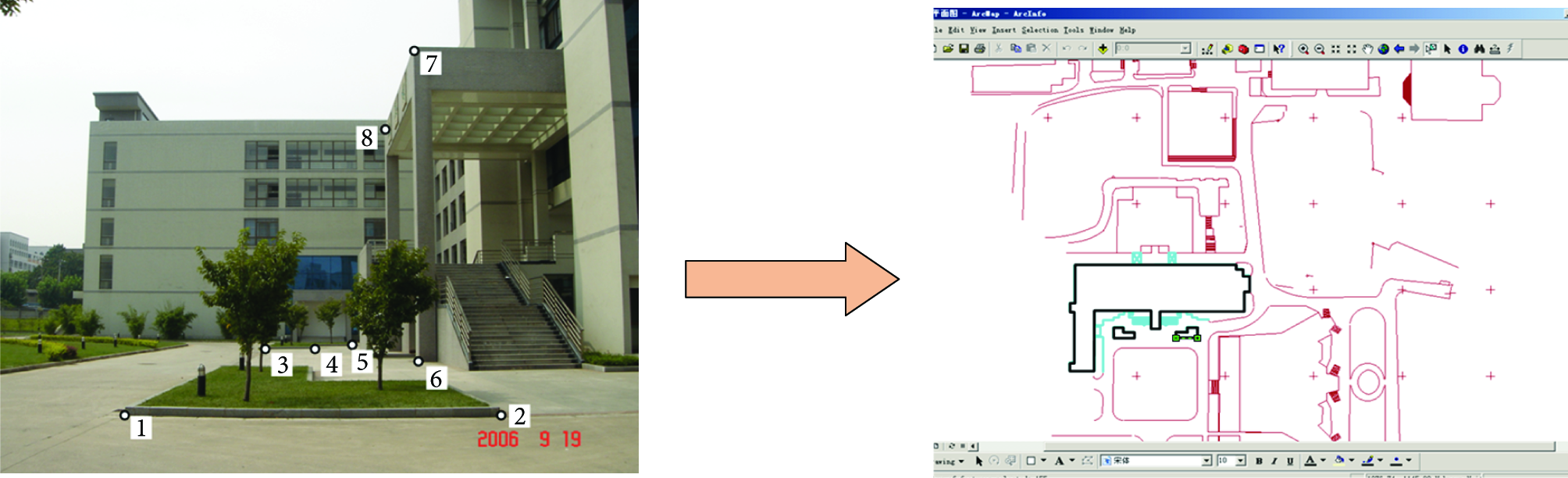
Mapping from Image to Digital Map.
3. Syntactic Structure
3.1. Syntactic Description of Motion Element
Video motion element mainly refers to the entity objects that could be identified clearly in visual and are important in morphology, such as pedestrians in video surveillance. The description methods of motion element are mainly based on color and texture at present, which is difficult to support the definition of motion element, behavior analysis, and behavior understanding. For a better description of the dynamic characteristic of the video motion element, the paper first gives a definition to some related concepts of motion element.
Definition 1.
State. The state is an abstract of attributes owned by motion element and is a static description of the condition and activity of a motion element at a certain time.
(a) Appear. The emerging motion element is newly appear and distinguished from the existing ones in the specific area of geographical boundary, and the state of which is called Appear. Then the motion element starts to be detected and tracked. Appear instance is regarded as the first instance of motion element.
(b) Disappear. In contrast with the Appear state definition, Disappear means the state of disappearance in the geographical boundary specific area or the untraceable state within a specific time, which is viewed as the last instance for the state description. Disappear state is the signal of canceling motion element detection and tracking.
(c) Stop. Stop S is defined on triple

The definition of Stop.
(d) Move. Within the scope of spatial constraint, Move M is a general designation of connecting the other three basic states in a continuous motion process of motion element. An instance of Move can be represented as
Definition 2.
Behavior Attribute. Behavior description of a single typical motion element mainly includes spatial location and speed. Spatial location can be defined as
Definition 3.
Relation. Relation is an incidence relation of mutual influence between two motion elements in the same time subspace T.
Definition 4.
Spatial Relation. Spatial Relation includes measuring relation, direction relation, and topological relation. Spatial Relation
Definition 5.
Visual Feature. In the georeferenced video stream, the visual characters of one motion element, including color, texture, and shape, will be dynamically changed with the time T. Therefore, the changes of visual characters of a motion element within the scope of spatial constraint should be described accurately [30]. And the visual characters mainly include Color, Texture, Shape, and Size. Texture can reflect the structure mode and gray space distribution formed by local pixels in motion element, while the low-level features can clearly define and describe the motion element.
3.2. Behavior and Interaction of Motion Element
In the georeferenced video stream, Behavior of the motion element within the specific scope of spatial constraint represents the behavior state sequence, as shown in Figure 6. Let the state set of Behavior be a BehaviorState, and the typical element is τ with the definition as follows:


Behavior state sequence of motion element.
As one of the expression forms of motion element in the video stream, Interaction represents the mutual influence or joint action caused during the course of the Relation of two behavior state instance. The necessary condition for establishing the interaction relationship is the two incidence relation between the two behavior state instances that exist at the same time. It can be defined as five-meshes

Under the influence of temporal subspace T and spatial relation
Due to the close correlation of spatial relation at any time point 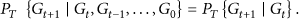
Meanwhile, the measuring value P of interaction between the two motion element established Relation can be computed based on the planar spatial distance Distance, velocity magnitude, and direction angle, including the current topology at time point

A diagram of interaction relation.
In the georeferenced video stream, the dynamic update function of interaction relation within the scope of spatial constraint is shown as follows:
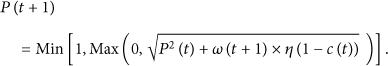
Among them, 
4. Semantics and Formalization of Georeferenced Video
For the accurate description and behavior understanding of motion elements in the georeferenced video stream, the paper proposes an analysis method based on sparse random graphs with the purpose of observing the character evolution with time and presents an indicating and measuring method of video motion element with dynamic topology structure information based on context-sensitive sparse random graph grammar.
4.1. Formalization of Georeferenced Video
Random graph 
Each edge of random graph G is mutually independent; namely, any two vertexes that established incidence relation connected independently with probability P. As the spatial relation will be dynamically changed during the movement with the time factor, it is necessary to describe the motion state and interaction relationships within specific spatial area using random graph. Context-sensitive sparse random graph grammar can be defined as five-meshes
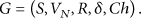
Among them, S is the root vertex that an initial vertex of semantic event in the georeferenced video stream. There is only one S vertex in the video event sequence. Vertex
The motion element vertex of random graph can be defined as follows:

4.2. Evolution Rule
As a posterior method, dynamic process of motion elements in the video stream can be visually described and showed based on sparse random graph. The temporal and spatial evolution model of motion element is able to describe the basic character and dynamic process of spatial relation accurately. The essence of dynamic evolution process of sparse random graph is the continuous transition process of state space in random graphs.
Therefore, the state transition function of sparse random graph can be defined as a mapping relation

Among them,
The dynamic evolution process of sparse random graph includes its character update of motion element vertex
Input: sparse random graph detection and recognition information; Output: return (1) IF (2) Create first node S & Add S to (3) End IF (4) While (5) IF (6) Find nearest node (7) Create new edge E( (8) Add (9) End IF (10) For (11) IF (12) Remove (13) Delete edge of (14) End IF (15) Update (16) End For (17) For (18) IF Flag← getRestriction( (19) Delete edge of (20) Else IF Flag← getAttract( (21) Add new edge of (22) End IF (23) End For (24) For (25) IF (26) (27) Else Update other P of (28) End IF (29) End For (30) Return
We can get the corresponding dynamic evolution model of sparse random graph using the evolution rule algorithm. Step (2) in the algorithm shows the creating and adding root vertex S, and
4.3. Random Subgraph
Cohesion of random subgraph refers to the close relation of motion element. To measuring close relation, the paper introduces the concept of structural entropy. As a measuring method of messiness and randomness of the state, structure entropy is related closely to the compactness of random subgraph. The higher the compactness is, the lower the structure entropy value will be.
If vertexes
4.4. Early Warning of Video Event
Using the numerical calculation method of interaction relationship, abnormal behavior and emergency in video can be distinguished based on random graph grammar, and the possible special situation can be early warned. There are two different threat levels generated by video event: notify and alarm, which is shown in Figure 8.

Notify and Alarm processing of video event.
The paper is mainly to detect the unexpected crowd incident and conflict in the massive video events and proposes a novel two-layer discriminate method, which consists of individual attribute layer and group attribute layer. Once occurring video abnormal event, the corresponding real-time status of random graph must be described, which can be expressed as follows.
(1) Individual Attribute Layer. The owned velocity of multiple random graph nodes has modified radically in per unit of time T, and the relevant movement direction has also changed significantly.
Specifically speaking, the detection and selection of variation range or interval of movement attributes in random graph can use sliding window. In the continuous movement attribute value
(2) Group Attribute Layer. The multiple interaction and distance values among random graph nodes in groups fluctuate greatly, or the multiple numerical variations of interaction relationship in random subgraph are changed significantly. The discriminant analysis of video abnormal event is achieved according to the check whether the change rate of parameter value 
Once either circumstance occurred, it must be entering the next notify phase.
When entering the notify discriminative phase, the random subgraph showing diffusion or flocking status makes numerical calculation. Using the computing method of structure entropy value, the corresponding random subgraph status is measured, and the entropy value 
The warning degree
The discriminate method based on the random graph is defined as graph-based reasoning (GBR) in the paper, while the improved GBR fused with traditional CBR method is GBR-C. The intelligent analysis for different video scenes plays an important role in the real-time detection of video abnormal behaviors and mass incidents. The instantaneous status information of video motion element is integrated with the random graph model and summarizes the random subgraph patterns and behavior rules with a statistical description. In violation of the behavior regularity of common video events, it is a latent exceptional event, and extracts the features of video motion elements involved which are recorded in object layer stream for the efficient retrieval of content-based video.
5. Experiment and Analysis
In order to verify the feasibility and availability of the proposed framework, space information of a motion element is extracted at real-time based on the detection and tracking [31, 32]. According to the dynamic change situation of space semantics, a timing description method using random graph grammar depicts the event development of video stream clearly.
5.1. Interaction Description
Interaction is the mutual incidence relation among motion element. For the accurate description of the dynamic change process of interaction relation, interaction P should be calculated real-time based on the spatial information in experimental video including planar spatial distance, velocity magnitude, and direction angle. And the calculation results of real-time interaction update function

Dynamic change process of interaction relation.
In Figure 9, function
The previous results show that it can accurately depict the dynamic varying changes of the interaction relation of video motion elements. However, the accurate depiction is an indispensable premise for the description of the georeferenced video stream.
5.2. Georeferenced Video Stream Description
Based on the richer spatial semantic of motion elements in the georeferenced video stream, we can realize the intelligent parsing of georeferenced video content using context-sensitive sparse random graph grammar. The spatial relationship of motion elements in image space is transformed to that of object space, and the motion status and interaction relation can be depicted using random graph. The continuous transition process of inner state space in random graph is enforced with the dynamic evolution process of sparse random graph.
With the spatial reference data, the sparse random graph evolution processing based on the monitoring target is achieved. And the consecutive people emerged within the video surveillance range are labeled as A, B, C, and D which are shown in Figure 10. As soon as the moving object appears, a new random graph node will express it; when it leaves the surveillance confine, the corresponding node will disappear while the edge set constituted by the interaction that associated with the node is set to null. Using our video test data, the evolutionary process and timing evolving description diagram of the video clip trim from frame 1041 to frame 1712 is shown in Figure 10.

Timing evolving description diagram of the georeferenced video stream.
We can see that the timing evolving description diagram can be constructed by the automatic intelligent analysis and calculation of a video clip, and it verifies the correctness and effectiveness of the evolution rule algorithm of sparse random graph. Within the scope of the specific geographical space, the time-varying attributes of random graph nodes are visual displayed, such as behavior state, spatial location, and movement parameter. And the basis recorded information of each video motion element is shown in Algorithm 3.
State=“2” //Behavior State frame=“612” //Current Frame Number timeDelay=“612” //Duration PixelX=“198” PixelY=“211” //Image Space Coordinate LoctX=“45” LoctY=“60” //Object Space Coordinate DeltX=“0.85” DeltY=“0.24” //Relative Distance Speed=“(0.85, 0.24)” //Speed InteractionNum=“1” //Interaction Relationship Number Interaction=“ // VF=“0” Other=“0”/
Among them, the basic information consists of attribute information, spatial location information, and other movement parameter, which are shown in Algorithm 3. The attribute information State indicates the behavior status of the video motion element with succinct expressional number 0, 1, 2 and 3, which are described respectively with the four basic behavior

Structural description of video motion feature.
The automatically generated file mainly consists of two parts: the configuration data and content data. The movement status information about motion element Object in the georeferenced video stream is described in detail in the content data part while the basic attribute information about testing video clip in configure data part. In the continuous period of time series, movement status information of each motion element including the behavior state sequence, real-time spatial location information, and the statistical information about interaction relation can be queried directly from the XML file. It also provides a novel simple nonlinear indexing for the understanding and description of video content.
5.3. Performance of Video Event Warning
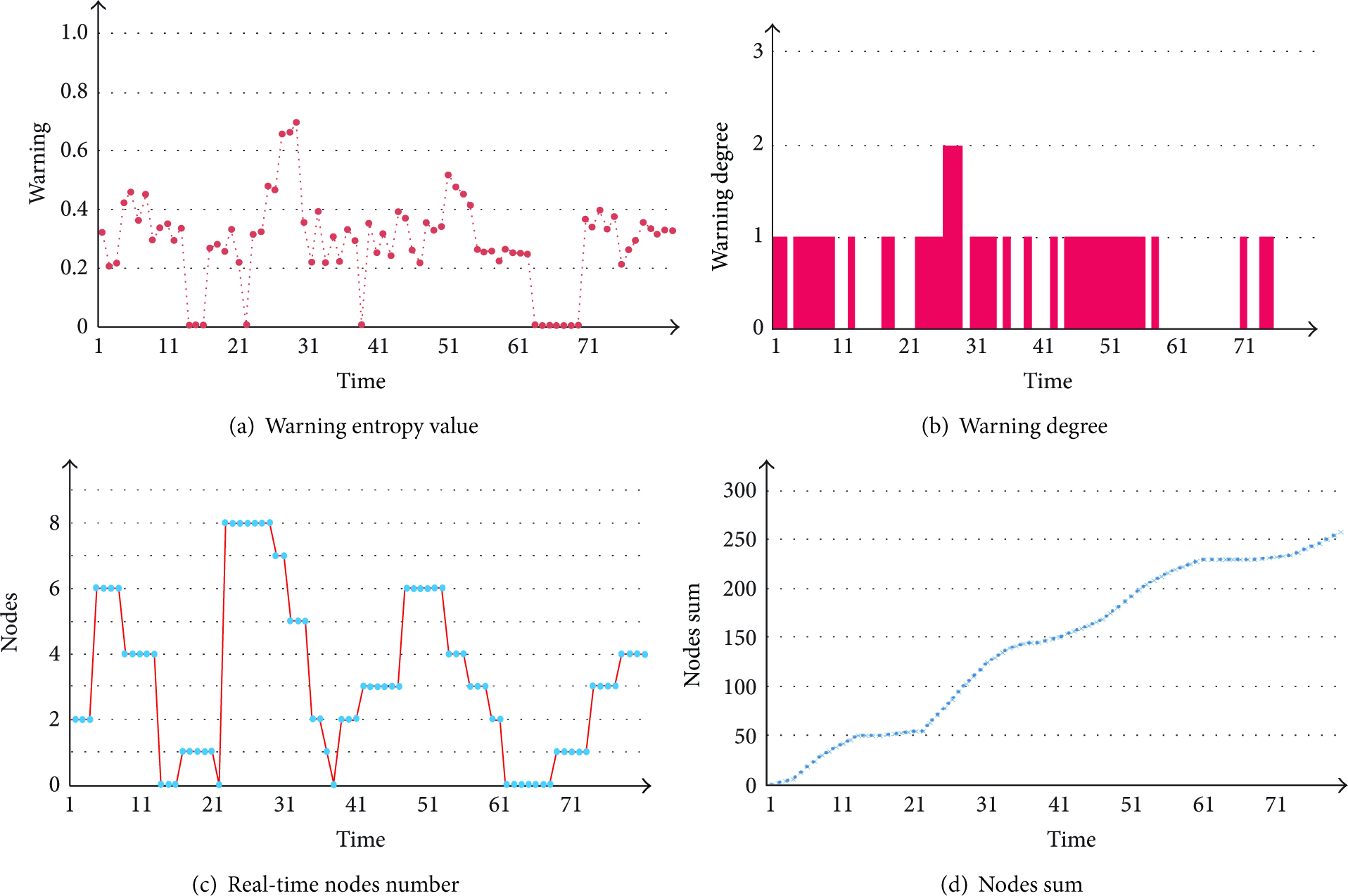
To validate the proposed early warning method of video abnormal behavior and emergency, we analyzed the performance of various attributes using the video test data which involves a crowd video scene. Experimental analysis mainly contains the real-time warning entropy value of random subgraph, warning degree, and real-time changes of corresponding subgraph node number and the total graph node number, which are shown, respectively, in Figure 12. And the horizontal axis indicates the video running time with 10 seconds as a scale unit.
Structural description of video motion feature.
As can be seen from the previous illustration, the warning entropy value of real-time random subgraph using the computing method of structure entropy value is due to random fluctuations in Figure 12(a). According to the warning degree of video abnormal behavior and emergency, three different warning threshold intervals are set in our test. And the Warning2 degree occurred between 252 and 270 seconds shown in Figure 12(b). The Warning1 indicates the early warning degree in most of the time, which means that video abnormal event will be emerged. Figure 12(c) shows the real-time nodes number of random subgraph in the video surveillance scope while Figure 12(d) shows the total graph node number.
5.4. Performance Comparisons of Intelligent Analysis Methods
In this section, we compare the proposed method with other methods, such as the Coarse-Grained SVM, Fine-Grained SVM [15], and MKL [19]. Using the three sample videos (Table 3) which involve some events that contain a group of people interact with each other, we carry out the comparison study. And all the chosen samples are considered as the labeled training data within the target domain.
Three test sample videos.

GBR accomplishes a concise numerical calculation and avoids the problems of computing complexity in the traditional CBR method. In Tables 4, 5, and 6, we compare the performance of GBR, GBR & CBR, with other methods using three different videos.
Comparison of crossing sample A with different methods.

Comparison of flocking sample B with different methods.

Comparison of conflict sample C with different methods.

From Tables 4, 5, and 6, we observe that GBR extends the processing time in a common detection of video event, but the forecasting accuracy of video abnormal behavior and emergency increased significantly with lower computation and complexity. Therefore, the energy consumption of sensors will be reduced which is consistent with the transmission costs, especially in the nonrecurring flocking emergency with complex video event modeling.
6. Conclusion
In summary, findings from the present study are all based on low-level visual features, which mean that there was a shortage of spatial constraints and coupling analysis with geography environment. It is necessary to establish the relationship between video analysis method and the real geographical scene. A georeferenced video analysis method is proposed based on the context-based random graph. The data are obtained using a wireless network of environmental sensors scattered at the supervising area and a vision sensor monitoring the same geographical area. Experimental results prove that the proposed description method of georeferenced video using random graph is feasible and efficient. Through the intelligent parsing of the georeferenced video data stream, we can get a novel visual description method using random graph which can clearly depict the development clue of video scenes and also offer the possibility to browse the video stream quickly. Meanwhile, random graph can be used as an effective nonlinear indexing for the content-based video indexing and browsing application.
As a future work, we will propose the enhancement of the implemented algorithms with alternative combination rules and the fusion of audio and video to deal with the uncertainty, imprecision, and incompleteness of the underlying information. In addition, large amounts of data should be conducted to set various parameters, such as thresholds, false alarm rates, and fusion weights.
Footnotes
Acknowledgments
The work is supported by the National Natural Science Foundation of China (41101432 and 41201378), the Natural Science Foundation Project of Chongqing (CSTC 2010BB2416), and the Education Science and Technology Foundation of Chongqing (KJ120526).