
Abstract
Wireless sensor network has been applied to many areas for a long time. A new kind of wireless sensors equipped with a camera and a microphone has been emerging recently. This kind of sensor is called wireless multimedia sensor (WMS) because it can capture and process multimedia data such as image, sound, and video. The visual monitoring network is a typical scenario of WMS application. Massive data would be produced in a short time because of the intensive WMS deployment. Many data aggregation and compression technologies have been proposed for addressing how to transfer data efficiently. However, data aggregation technologies need highly efficient router algorithm, and compression algorithms might consume more computation time and memory because of the high complexity. This paper applies data deduplication technology to this scenario. It can eliminate the redundant data from raw data to exploit the network bandwidth efficiently. Moreover, a chunking algorithm with low computation complexity is presented in this paper, and its efficiency has been proved through the experiments.
1. Introduction
Wireless sensor network (WSN) consists of a large number of spatially distributed autonomous sensors which are connected by wireless communication. It is mainly used for dynamic acquisition of physical information within the network coverage which will be delivered to users later. Currently, WSN is widely applied to the capture, processing, and transmission of the data such as temperature, light intensity, humidity, and gas concentration [1, 2]. In the recent years, as the production level of sensors improves, additional camera, microphone, and other functional devices are installed on traditional wireless sensors and enable them to capture, process, and transfer multimedia information such as image, sound, and video, so that users can obtain improved physical information which is more vivid and more accurate. This new kind of sensor can be called wireless multimedia sensor (WMS). Wireless multimedia sensor network (WMSN) consists of WMS nodes, gateway nodes with storage, sink nodes, and so on. Then, a typical WMSN architecture is proposed in [3], as shown in Figure 1. WMSN is widely used in many areas including visual monitoring, individual positioning, industrial control, intelligent transportation, environmental monitoring, smart home, and telemedicine [3–5].

A typical system architecture of WMSN.
Multimedia sensor nodes have limited resources such as energy capacity of battery, storage space, and computing power, while the information they acquire features large data size and high requirement for computing. The data in-network processing technology [6, 7], as one of the key technologies used to save bandwidth and network energy in data-centered WMSN, can eliminate the redundancy of source data and minimize the data traffic between nodes by applying data fusion technology or data compression. The data fusion technology uses different routing methods to combine data packages and eliminate redundant data from them. This technology relies on three basic modules:routing algorithm, data fusion, and data presentation [6]. However, in addition to the advantage of high data aggregation, the application of data fusion technology may also lose raw data structure, while data compression can prevent this problem. Data compression has been applied to WMSN, and the compression algorithm can be divided into two categories:distributed data compression scheme and local data compression scheme. The proposed data compression algorithm is the extension of data fusion technology in multiple-hop network topology, and compression algorithms are applied to the entire network [8, 9]. Other compression algorithms independently perform data compression on local node, so they do not depend on intensive network or routing algorithm and are more suitable for sparse sensor network [10, 11]. The data compression scheme can reduce the amount of data transmission in sensor networks to save bandwidth and energy consumption; however, as compression algorithm is relatively complicated and needs more computation time and memory, the energy cost of nodes that apply compression algorithm is much higher than that of nodes without using compression algorithm [12].
Event-based monitoring scenario is a typical application of WMSN. When the triggering condition of an event is met, the wireless multimedia sensor node will capture the image data at that moment and upload the real-time data to the storage device of gateway node. Then, the gateway node collects data from different sensor nodes and transmits the data to the cloud for storage and backup through sink node based on corresponding strategies [13]. In this scenario, the WMS node deployment in WMSN is very intensive and will produce a large amount of data in a very short period. These data have distinctive characteristics so it is suitable for applying data deduplication technology to this scenario. Data deduplication can effectively eliminate the redundant data to reduce the multimedia data traffic between nodes and improve the bandwidth utilization of WMSN. At the same time, its computation complexity is less than that of compression, which means less computation energy consumption. The chunking algorithm is the key factor that impacts the effect of deduplication. Basic sliding window (BSW) algorithm is one of the classical chunking algorithms. This paper proposes a specific chunking algorithm based on BSW. The algorithm can decrease system overhead and increase deduplication efficiency by merging continuous redundant chunks. In contrast with BSW, the experiment results will show how efficient the new algorithm is. The rest of this paper is organized as follows. Section 2 firstly describes the background of data deduplication and introduces BSW algorithm. A continuous redundant chunk-merging algorithm is proposed in Section 2.4; Section 3 performs a simulation experiment and takes the basic sliding window algorithm for comparison to analyze the advantages and disadvantages of both; Section 4 will draw a conclusion.
2. Data Deduplication
Data deduplication [14] is firstly applied in the field of storage backup to reduce storage costs and improve storage space utilization. The technology segments the source data S into a continuous chunk set
Data deduplication can be divided into file level, block level, and byte level according to operating granularity. The block level can be divided into fixed-size chunk and variable-size chunk. The smaller the granularity is, the more redundant data are removed, but the implementation complexity and system overhead also increase accordingly. The redundant data that file level can eliminate is the least, but it is easy to achieve. The byte level has the best deduplication effect, but its overhead is extremely expensive and difficult to implement. If fixed-size chunks are used, their matching probability will be greatly reduced due to fixed boundary. In monitoring networks, the position of multimedia sensor is generally fixed, so the images have a small amount of information changes. Good variable-size chunking algorithm can separate duplicate and nonduplicate information as much as possible to reduce the transmission amount of duplicate information. The content-based chunking algorithm applies sliding window technology to determine the boundary of the chunk based on file content. It can control the impact of update on data partitioning within a small range, so that only several chunks near the update location will be affected while other chunks remain unchanged. Therefore, this chunking algorithm is very suitable for the scenario above.
This section will first introduce basic sliding window algorithm and will propose an improved continuous redundant chunk-merging algorithm. Then, the advantages and disadvantages of both methods are analyzed in terms of system overhead.
2.1. Basic Sliding Window Algorithm
The process of basic sliding window algorithm [15] is as follows: a window with fixed size is moved cross the data, and, at every position in the data, a Rabin fingerprint [16] of data in the window is calculated. If an rf-Match appears in position k, then k is declared as a chunk boundary. Repeat these steps until it reaches the end of data. Finally, a sequence of chunks
Definition 1.
A Rabin fingerprint for a sequence of bytes
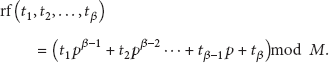
Definition 2 (rf-Match).
For a given sequence
2.2. Analysis of Duplicate Data
In order to analyze the redundancy degree of the image data captured from the monitoring network, we simulated a scenario in the laboratory, where a path was left in the middle and fixed objects were placed at both sides. Excluding the impact of light change, a CMOS camera was fixed to monitor the scenario. If any objects appeared on the path, the camera would capture the images at that moment and store them in external storage immediately. We asked different groups of testers to move on the path, and a total of 300 monitored images were collected. All image data were stored in nondestructive bitmap format (BMP; resolution 640*480; bit depth 16 bits). The file name was numbered in ascending order:
We made two groups of experiments. Group 1 applied byte comparison tool and took the 0th image as the benchmark to compare it with the remaining 299 images and record the number of bytes at identical parts. The experimental results are shown in Figure 2. It can be seen that, compared to the initial scenario, only the image value on the path is changing in other images, and nearly 78% of pixels in average remain unchanged. We call this part of data as redundant data that can be eliminated, namely, duplicate data.
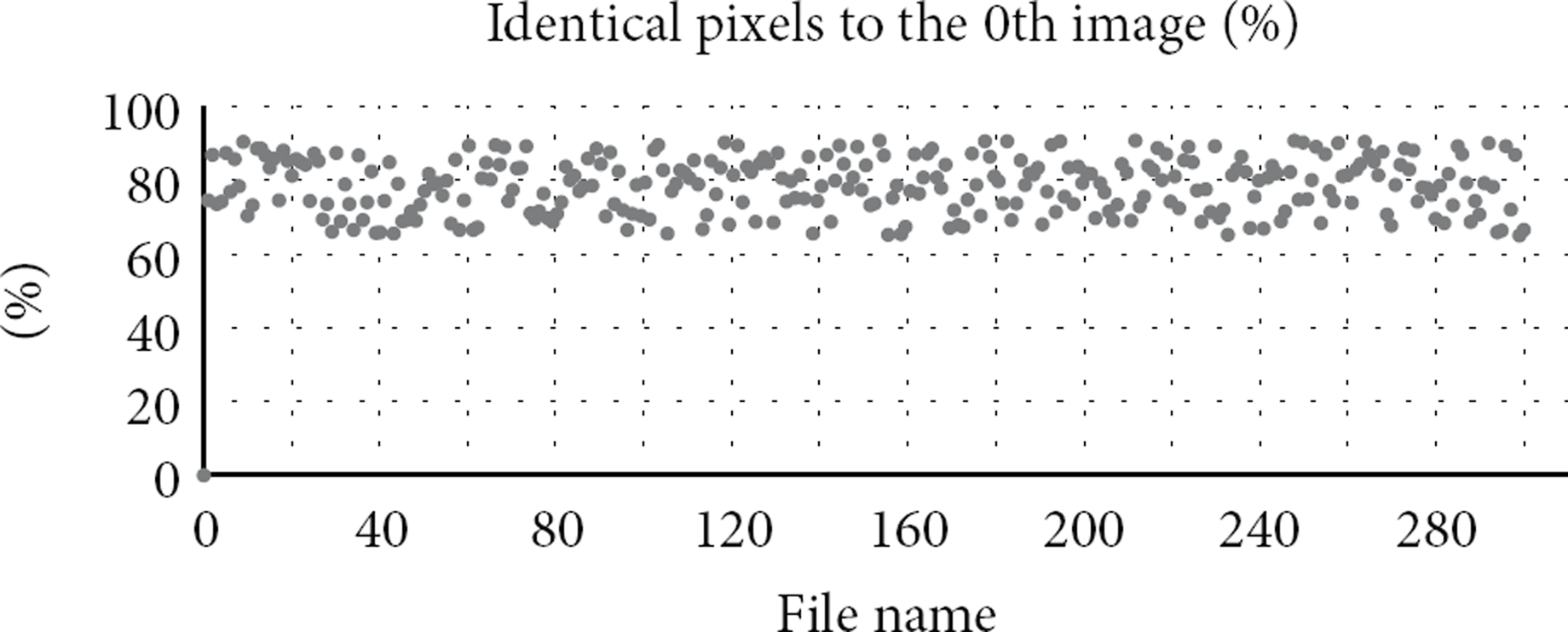
Percentage of identical pixels to the 0th image.
Group 2 was used to verify the validity of BSW algorithm. In Group 2 experiment, BSW algorithm was used to segment all images and count the frequency that each chunk appeared. Theoretically, if the frequency is greater than 1, this means that the content of this chunk is only required to transmit one time. Before the BSW algorithm is implemented, three parameter values M, r, and l should be determined firstly. M determines the possibility of collision for Rabin fingerprint value, r directly affects the final size of chunk, and l determines the minimum chunk size. We built a hash table in memory to store the content of chunk, the 512 bytes SHA1 of chunk, and the frequency chunk appeared. The BSW algorithm was then implemented. Each time a new chunk was generated, the hash table was queried one time. If there were identical chunks, only one chunk was stored and its frequency was added as 1. If BSW algorithm was applied to segment the byte sequence set
Considering that the sensor memory capacity was limited, we chose
Chunk statistics of Group 2 experiment (

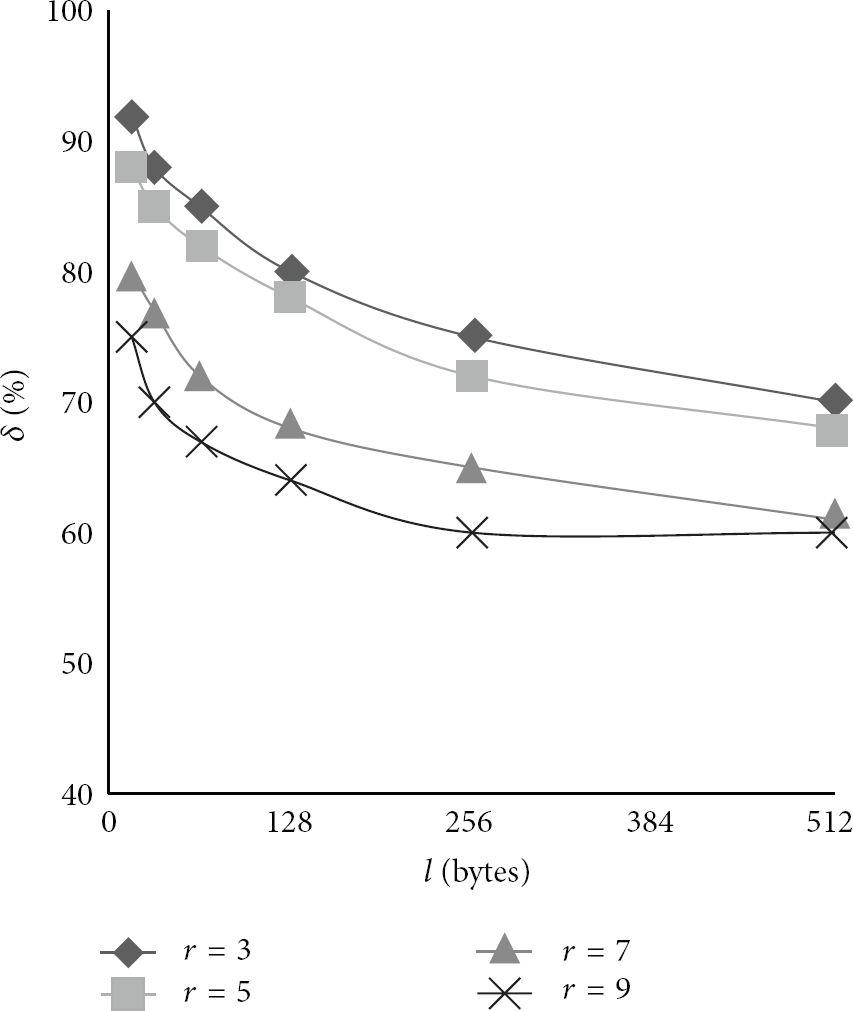
Impact of r and l on the ratio of duplicate chunk in S.

Impact of r and l on elimination rate of hash table.
2.3. Evaluation Indicators
In this section, we introduce an evaluation indicator mentioned in [17] for evaluating our works.
For two byte sequences P and Q, use
For a byte sequence S, H(S) denotes the chunk sequence
For the given threshold t, if (
Definition 3.
Assume that S is a byte sequence;
Definition 4.
For a defined V(S), the algorithm overhead index α is defined as follows:

With chunking algorithm, if duplicate data and nonduplicate data are divided into one chunk, the duplicate data in this chunk is an extra cost because it should not be stored and transmitted. V is the average number of bytes used to evaluate the overhead. The parameters r and l in Definition 2 can be adjusted to make V smaller, but this will also increase the metadata overhead, so μ is introduced to balance the overall cost. μ is the average chunk size which is inversely proportional to the metadata overhead and proportional to V. By calculating the ratio of V and μ, a comprehensive evaluation on chunking algorithm and cost of metadata can be achieved.
2.4. Continuous Redundant Chunk-Merging Algorithm
The chunks created by the BSW algorithm in Section 2.2 are not equal in size. The chunk size has very large impact on the algorithm effect, so we try to improve BSW algorithm by adjusting the chunk size. Group 2 experiment in Section 2.2 has recorded all chunks sizes. 79% chunk size is less than the average chunk size. If smaller chunks can be merged to reduce the total number of chunks, the average chunk length μ will increase; thus the overhead index α will decrease. For our simulation scenario, most of the pixels are basically unchanged. BSW algorithm is a content-based chunking algorithm, so the boundary between chunks is stable. For example, Figures 5(a) and 5(b) shows two continuous image files. The nonduplicate bytes part concentrates in one area, and the chunk boundary does not change in the first and the last duplicate bytes parts, so we declare that the chunk boundary is stable. If we merge the first three chunks and the last three chunks in Figures 5(a) and 5(b), respectively, total number of chunks will drop from 20 to 12, average chunk size μ will rise by 66%, and overhead index α will reduce by 39.7%.
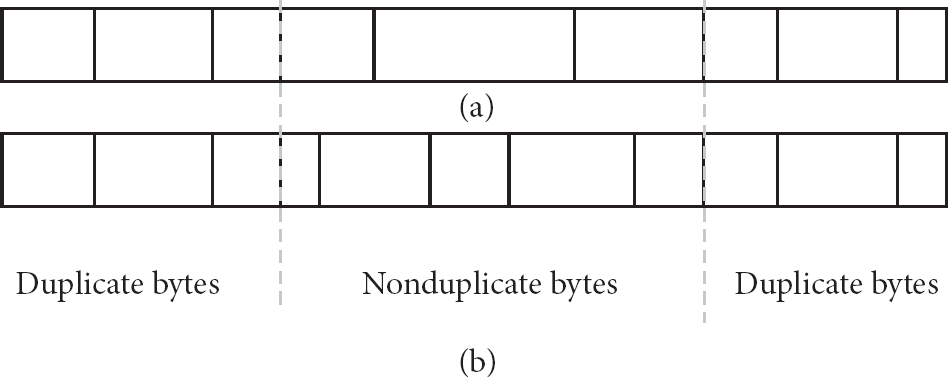
Example of stable chunk boundary.
We propose a continuous redundant chunk-merging (CRCM) algorithm. The algorithm works as follows: first, to determine the chunk boundary by applying BSW algorithm on files. Each time a new chunk is generated, the hash table is queried to determine whether the chunk has been stored before. If stored, the chunk will be sent to a data stack. If not stored, the algorithm continues to look for the next chunk and then repeat the above steps until meeting the end of file. The algorithm merges chunks according to the following rules: if the total length of chunk in the stack is greater than the threshold L, then merge all chunks in the stack to form a new chunk and insert it into the hash table. The detection of chunk merging is performed when a new chunk is generated.
Because the chunk boundary is stable, the probability of merging the same continuous redundant chunks is reasonably great when segmenting different files by applying CRCM algorithm. The algorithm effect is related to the threshold L and metadata costs. These will be discussed through the experiment in Section 3.
3. Result and Discussion
When wireless multimedia sensor is used for experiments in the simulation scenario, the following questions should be considered:
hardware specification of WMS, construction of wireless multimedia monitoring network, data synchronization between nodes.
Computing power, storage capacity, and battery life of WMS have been improved greatly. The energy consumption of WMS is mainly in data processing, storage access, image acquisition, network communication, and so forth. Stargate [18] is a product of MEMSIC, and its hardware specification is Intel PXA-255Xscale 400 MHz CPU, 64 MB SDRAM, and 32 MB flash storage. Meantime, it also supports embedded Linux operating system and IEEE802.11 wireless communication protocol. Therefore, it is enough to complete some complicated computing tasks.
The wireless multimedia monitoring network composed of multiple WMS independently collects data and transmits information to sink node through gateway node. The computing power and storage capacity of gateway node are both far greater than those of WMS nodes. Multiple WMS can eliminate duplicate data together with gateway node at the same time, and the effect will be better, but this brings about a new problem of data synchronization between nodes. Some proposed synchronization methods such as distributed data deduplication [19] can address this problem.
This section will continue the experiment in the simulated scenario in Section 2.2. The chunking algorithm was replaced with CRCM algorithm, and then the evaluation was performed in terms of overhead index and PDR.
The WMS nodes in the experiment adopted the engineering board based on ARM9 architecture, equipped with 200 MHZ CPU, 64 M SDRAM, 1 GB flash storage, and onboard QuickCam camera. The maximum image resolution was 640 × 480, and the operating system was embedded Linux (2.4.19). Gateway node used DELL VOSTRO 3560 laptop, specification was the following: Intel i7-3632QM 2.2 GHz, 8 G RAM, and 250 GB hard of which drive. WMS node and gateway node used the IEEE802.11 wireless protocol to communication.
In the experiment, WMS node was used to monitor the simulation scenario. Any changes in the scenario would trigger sensors to capture and transmit real-time information to gateway node. CRCM algorithm was used for image chunking before the transmission of WMS node. Only those nonduplicate data chunks were transmitted. For duplicate chunks, only their index values were transmitted. The details of data synchronization between nodes would not be mentioned here.
Firstly, we observe the impact of threshold L on overhead index by running CRCM algorithm (see Figure 6). L is the multiple of the average chunk size of current file, that is,

Impact of L on overhead index.
Metadata cost is another system overhead, so it must be involved in our evaluation. We focused on the metadata storage cost. WMS node's storage capacity is limited, so duplicate chunk data cannot be stored locally forever. Therefore, local metadata storage will encounter the problem of hash table elimination. We conducted four groups tests on different memory size allocated for hash table. The results were shown in Figure 7, and we can find that the ratio of hash table elimination by running CRCM was less than that of BSW algorithm, because BSW algorithm generated more chunks which needed more hash table items. According to our WMS hardware capacity, we considered 20 M would be a better choice in this scenario.

Ratio of hash table elimination by running CRCM versus BSW on different memory size.
The computation complexity of both BSW algorithm and CRCM algorithm is much less than that of compression. The most time-consuming calculation is Rabin fingerprint calculation. Recalling rf in Definition 1, for fast execution, we can define an iterative formula as follows:

4. Conclusion
In wireless multimedia sensor networks, massive data needs to be transmitted to the cloud storage. This paper applies data deduplication technology to WMSN. In the simulated monitoring scenario, this paper puts forward a continuous redundant chunk-merging algorithm by taking the characteristics of scenario data into full consideration. The algorithm considers the computing power and storage capacity of sensor hardware. Compared with BSW algorithm, it effectively reduces system overhead through experiments.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (61373015 and 61272422), The Research Fund for the Doctoral Program of High Education of China (Grant no. 20103218110017), the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD), and the Fundamental Research Funds for the Central Universities, NUAA (Grant nos. NP2013307 and NZ2013306).