
Abstract
Monitoring performance and energy constraint are two conflicting aspects in wireless sensor networks. In order to save battery power in very dense sensor networks, some redundant sensors can be put into the sleep state while other sensor nodes remain active for the sensing and communication tasks. However, if the energy consumptions for some nodes are more than those of the others, these nodes would lose effectiveness earlier than the remaining ones, which subsequently causes the coverage holes. Because of the uneven node scheduling problem in the sensing areas and the partitions of communication network, the coverage holes further influence the sensing and communication qualities and the network life. In this work, we propose the uneven sleeping problem (USP) happening in the coordinated node scheduling in wireless sensor networks. We analyze the key factors that may lead to USP. We design a new metric which can better measure and evaluate USP. This new metric takes the influence of the boundary effects on node schedule into consideration. We experimentally evaluate the performance of our proposal. The results show that our metric can effectively identify the boundary sensor nodes that deserve equal chances of sleep; it thus reduces the number of dead sensors and can help achieve a longer network lifetime than existing methods.
1. Introduction
A wireless sensor network is typically composed of a large number of tiny, low-powered sensor nodes equipped with data processing, sensing, and communication capabilities that communicate with each other through single or multihop wireless links for monitoring the surveillance field. Wireless sensor networks have been extensively used in a variety of domains, for example, environmental observation, military monitoring, healthcare, and commercial applications [1]. The sensor nodes usually operate on an unattended manner and are battery powered. However, it is usually hard to renew or recharge the battery after deployment, due to environmental situations or cost concerns. Therefore, energy efficiency has been a very challenging task in achieving long lifetime in large-scale sensor networks.
Coordinated node scheduling plays a critical role that exploits the redundancy of sensor nodes to minimize the number of active nodes while preserving some properties of the network. The problem of sensor scheduling to maximize the network lifetime while guaranteeing the sensing coverage and network connectivity has been extensively addressed in the literature [2, 3]. Network coverage is the central consideration for the sensor scheduling methods that conserve energy by powering off redundant nodes while still assuring network coverage.
Energy consumption rates in different parts of the network should be even or almost even. Thus all nodes throughout the network area have about the same lifetime. Otherwise, some parts of the network may die much sooner than the others. If some critical parts of the network run out of battery early, it may lead to early dysfunction of the entire network, even if other parts of the network still have a lot of residual energy. In this paper, we propose the uneven sleeping problem and a new metric to be used in coordinated node scheduling for wireless sensor networks.
The remainder of this paper is organized as follows. In Section 2, we present related work on coordinated sensor scheduling problems. Section 3 describes network model and introduce the uneven sleep problems. In Section 4, we present detailed analysis on uneven sleep problem and give new metric for proposed node scheduling scheme. Experimental results are given in Section 5. Finally, we give a summary and future work in Section 6.
2. Related Work
From perspectives of network configuration, network performance, network parameters, and models for recognizing redundant nodes, we categorize coordinated node scheduling into four types shown in Figure 1.

Taxonomy for coordinated node scheduling.
In the initial steps of WSN deployment, the status of the nodes can be scheduled according to preconfigured node location or distance information, to determine the coverage of the network node density. Coverage redundancy discrimination is a key step in coordinated node scheduling. It aims to identify the coverage redundant nodes and hibernate them alternately. There are generally two ways to detect redundant nodes, which are location-based and location-free techniques. We will address these two types of techniques in the following.
2.1. Location-Based Coordinated Nodes Scheduling
Location-based node scheduling can guarantee full (100%) coverage of the network, meaning that the monitor environment will be covered with all the active nodes. In paper [2], the authors define a “sponsored area” as the largest area a node can be covered by some communication neighbor. If the sensing area of a node can be covered by the combined sponsored areas of all of its communication neighbors, then this node can be shut down. In [3], the neighbors of a node are expanded to an area of a circle of radius
Zhang and Hou [5] adopted a crossed redundancy detection method and proved that the full coverage network must be connected if the radius of the node's communication area is no less than 2 times of the radius of its sensing area. Under the assumption that the location information of each node is available, they proposed an Optimal Geographical Density Control (OGDC) algorithm. Xing et al. [6] extended the above work, and proposed the Coverage Configuration Protocol (CCP) algorithm that maximizes the number of hibernate nodes under the constraint of k-coverage and k-connection. They found that when the communication radius is 2 times of that of the sensing area, a k-coverage network is still k-connected.
All the above methods require the exact location information of the nodes to compute the coverage area and assure the full coverage. This is very challenging when designing an economic WSN of high density. In real-world applications, it is not mandatory to guarantee the complete coverage, and it is acceptable to sacrifice some of the coverage requirements for performance improvement.
In [7], the authors presented a dynamic node scheduling method, given that existing node scheduling methods always require static 1- or k-coverage. This method can adjust the status of network coverage on the fly. Concerning the boundary effects of circle coverage, the authors in [8] developed an improved circle coverage density control algorithm.
Hefeeda and Ahmadi in [9] proposed a new probabilistic coverage protocol, considering that the sensing ability may be influenced by the external application environment. In [10], a probabilistic k-coverage protocol was proposed that used heuristic greedy algorithm to decide the smallest set of active nodes. Shi et al. [11] gave two coverage algorithms based on probabilistic sensing models, for the consideration that the detection of an event is influenced by factors such as the distances between nodes, the physical characteristics of the nodes, the number of neighbors, and so on.
Exact location information is needed by all the above methods. To acquire such location information, people must have GPS, directional antennas infrastructures, or positioning devices. This constraint not only results in high cost, high complexity, and more energy consumption but also reduces the benefits brought by the node scheduling algorithm. Still, it is difficult to apply them to large-scale application for low purity of the current positioning devices.
2.2. Location-Free Coordinated Nodes Scheduling
Considering the problems with location-based scheduling algorithms, location-free coordinated node scheduling algorithms have been developed which are independent of the location information when scheduling and scheduling the nodes. This type of methods is economic and can be applied in applications that do not require strict network coverage rate. For these methods, the number of neighbor nodes or the distance information are usually used to detect redundancy.
Tian and Georganas in [12] first proposed the location-free redundancy detection model. They set a redundancy threshold based on the number of neighbors or the nearest distance within the sensing area. A node will hibernate if the number of nearest neighbors or the distance is smaller than the threshold. This method is simple and easy to implement. But it only guarantees partial coverage. Still, it does not consider the situation whether the neighboring nodes can fully or partly cover the monitoring area when this node is shut down. Consequently, the monitoring quality is not guaranteed.
Gao et al. in [13] analyzed the lower and upper bounds of complete node redundancy and proposed to compute the redundancy probability using the number of neighbors within the sensing area. Lightweight Deployment-Aware Scheduling (LDAS) [14] is an improvement of [13]; a number of nodes will be closed when the number of nearby working nodes reaches the threshold. Besides being location free, this new method can guarantee the network connectivity. The constraints of this method are as follows: the senor nodes should be uniformly distributed and each node can get the number of its neighbors.
Yen and Cheng in [15] proposed Range-Based Sleep Scheduling (RBSS) that determines the redundancy using the distance between the node and its neighbors. It assumes that the density of the sensor nodes is large enough to become independent of the exact location information. While still assuring the complete network coverage and connectivity, it searches an optimal model from the nodes already deployed to maintain as less working nodes as possible. However, the energy cost of the method is imbalanced for it does not consider the energy consumption during the voting for start and coordinated nodes. Still, the early expiration of boundary nodes reduces the coverage area. In consideration of the imbalanced energy consumption problem, the authors in [16] presented a multistart and energy-adaptive strategy to do coverage control. Their method tackles the above-mentioned problem of the early expiration of boundary nodes.
Younis et al. in [17] designed a location-unaware coverage (LUC) method that utilizes the density between the node and its 2-hop neighbors to detect redundancy.
Location-based coordinated node scheduling can guarantee high coverage rate but requires special devices to obtain this location information, which reduces the benefits from node hibernation, whereas location-free coordinated node scheduling just needs information of the distance between the nodes and the number of nodes, so it cuts the corresponding extra costs.
3. Network Model and Problem Description
In this section, we first describe the network model and introduce the definitions and notations used in the paper. Next, we define the problem to be solved in this paper. Finally, we explain our motivations for this work.
3.1. Network Model
In a typical monitoring application where massive tiny sensor nodes are deployed, let the sensor nodes be uniformly distributed in the monitoring field. Let the sensing area of a senor node be a circle of radius r. Then, each sensor node can only monitor the environment and detect events within its sensing circle. A point is covered if and only if it locates in at least one sensor node's sensing circle. If and only if all the points in a region are covered, the region is covered.
For simplicity, we assume that there are N homogeneous sensor nodes deployed within the monitored region A, denoted by a set
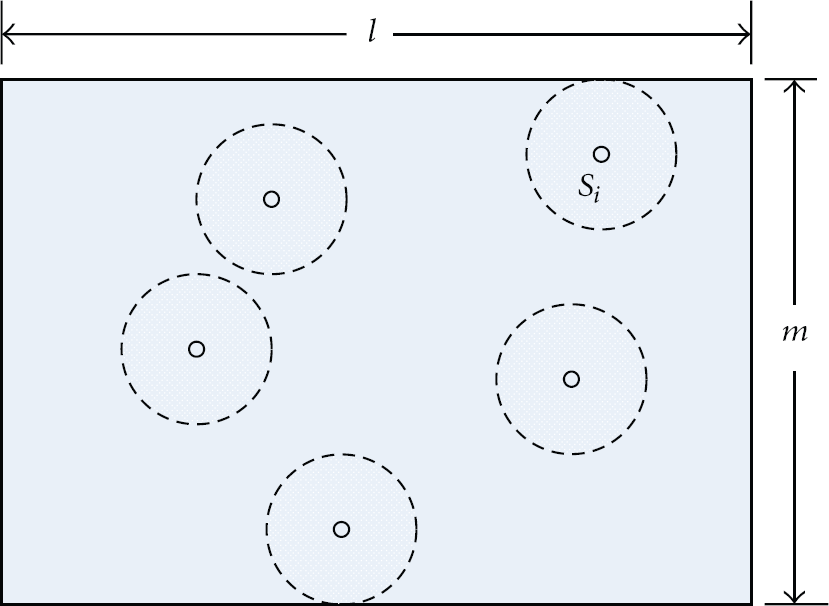
Monitored region.
Below we give the definitions used in this paper.
Definition 1 (Boundary Nodes).
Let

Definition 2 (Interior Nodes).
The interior nodes of monitored region A, denoted by

Definition 3 (Redundancy Rate).
The redundancy rate is the size of the intersection area between the sensing area of node

Definition 4 (Coverage Redundancy Node (CRN)).
A node
Definition 5 (Effective Coverage Area (ECA)).
The intersection area of sensor nodes' sensing coverage and the monitor region, denoted as
3.2. Problem Definition
For a densely deployed monitoring application, the coverage redundancy nodes should be switched to sleep state in turn, to prolong the network lifetime while still preserving some properties of the network. The challenge is that, some nodes in

Uneven sleep problem.
In Figure 3, 100 sensor nodes are randomly deployed in a circular area with radius
3.3. Motivation
The task of node scheduling will be trivial if it is done in a centralized way. Under this assumption, it will be easy to determine which nodes are the boundary nodes and internal nodes and whether their sensing areas are covered by their neighbors or not and then decide which nodes should go to sleep or stay active. However, due to the energy constraints and the energy-cost considerations, this scenario is impractical for most monitoring applications. In the next section, we analyze several factors that influence the uneven sleep problem and derive instructions to stop the wretched cycle of energy holes. Under the analysis, we propose an improved node scheduling scheme which can alleviate the uneven sleep problem.
4. Problem Analysis and Proposed Approach
4.1. Problem Analysis
The failure of sensor nodes due to energy exhaustion or physical destruction may lead to the shrinkage of sensor coverage. The coverage holes can hardly be avoided in monitoring application because of the geographic environments or the uneven energy consumption problem even in the high-density deployment. In this section, we first give analysis on why the nodes that are in
We divide the monitored region A into three subregions,

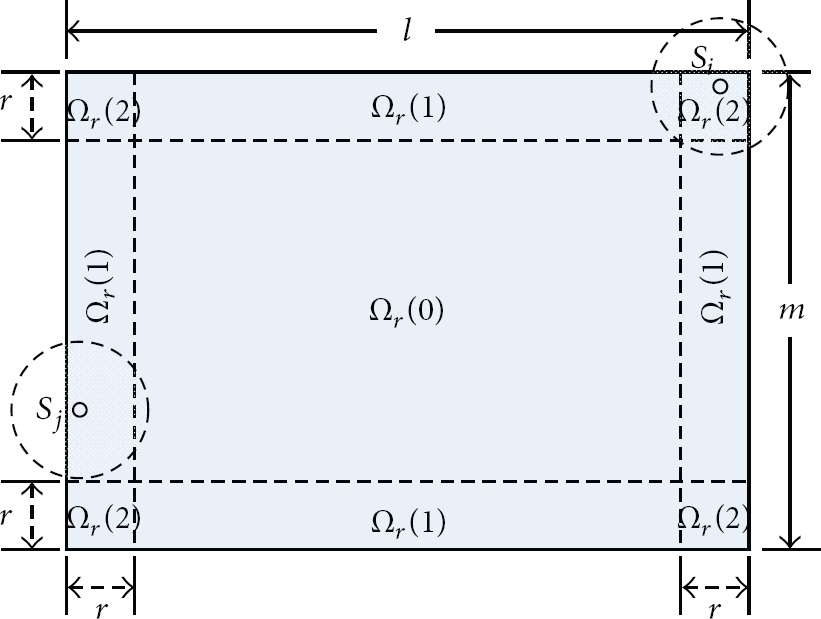
The subregions of monitored area.
In Definition 4, we give ECA to illustrate the relationship of nodes' sensing coverage and the monitored region. For subregion
The problem illustrated above is the main reason for the uneven sleep problem occurring on the boundary nodes. The sensor nodes may also fail for reasons such as nonuniform deployment or environment influence (such as animals trample, the damage of the rain, etc.). It is clear that the network lifetime will decrease when the uneven sleep problem arises. In the next section, we give a proposed approach to mitigate the uneven sleep problem.
4.2. Proposed Approach
In this section, we propose our approach which is an improvement based upon LDAS which schedules nodes without location information [14]. The proposed node scheduling scheme is divided into a few identical rounds, as shown in Figure 5. Each round starts with (i) neighbor discovery, (ii) redundancy evaluation, and (iii) node scheduling where the off-duty nodes will go to sleep and save energy.
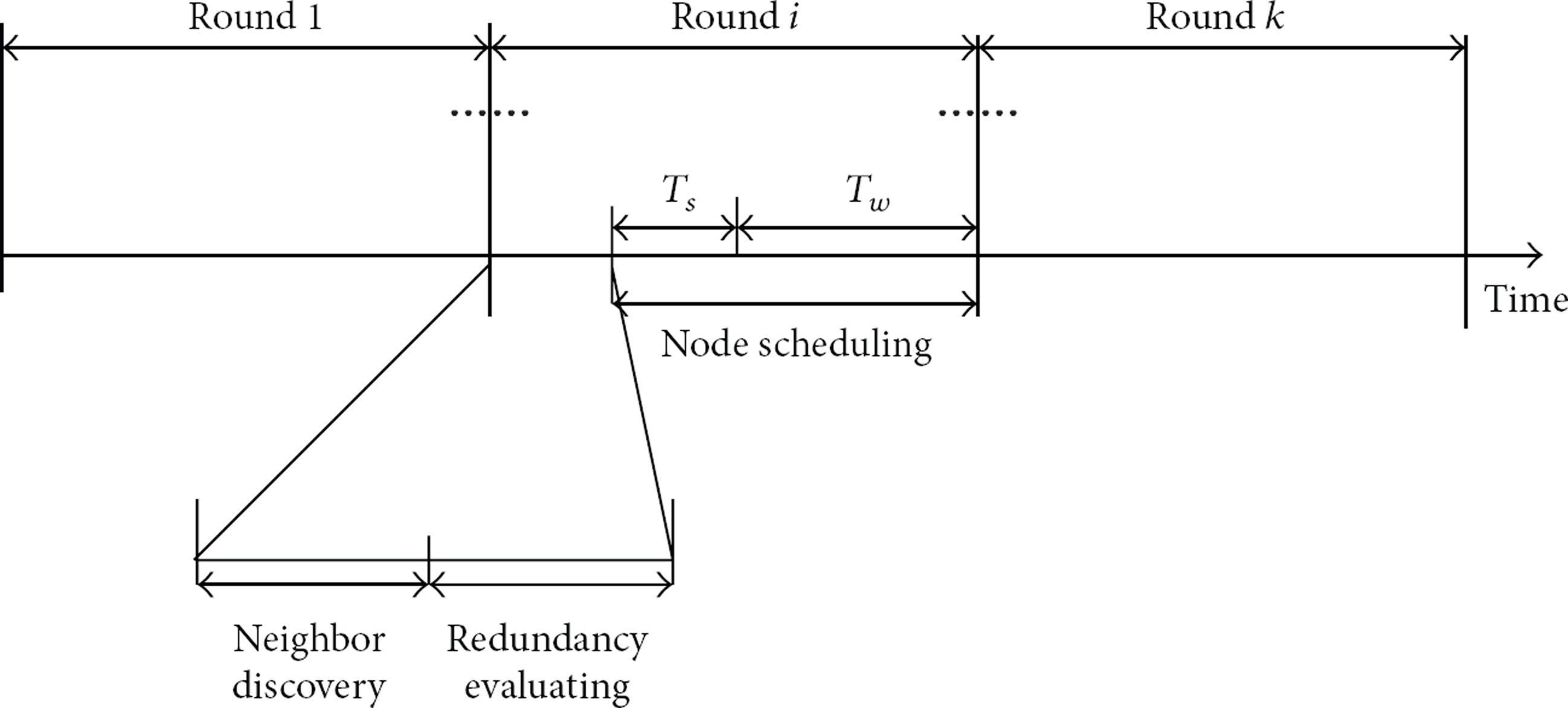
proposed node scheduling.
4.2.1. Neighbor Discovery Phase
To obtain neighbor node information, each node broadcasts a hello message, which contains the node's position information or number of neighbors, to its one-hop neighbors at the beginning of neighbor discovery stage. This way, a sensor node

4.2.2. Redundancy Evaluation Phase
In LDAS, redundancy evaluating is based on the number of neighbors. The percentage of a sensor's sensing area that is covered by its n random neighbors is not smaller than
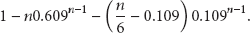
The expectation area that is not covered by random neighbors is

For more detailed proof, the readers can refer to [14].
To determine which nodes are coverage redundancy nodes, it is needed to compute the redundancy rate. A node has more chance to enter sleep state if the redundancy rate satisfies application requirement. For a node with sensing area of radius r, the redundancy rate is defined as

As stated in Section 4.1, the boundary nodes in monitored area encounter the problem of border effects. To solve the uneven sleep problem in node scheduling, we should take border effects into consideration. As shown in Figure 3, we give the expected coverage area that an arbitrary sensor is located in three sub-regions (see our work published in [18] for further details):
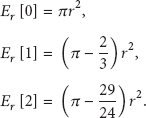
Then we can get the expected coverage area of the sensor, with sensing range being r and the sensor nodes being uniformly distributed in
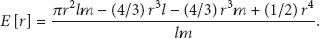
Taking border effects into consideration, we use the node's expect coverage area to replace the nodes coverage area to decide whether the node is a coverage redundancy node. Finally, we have the following formula:

4.2.3. Node Scheduling Phase
In node scheduling phase, each node has three states: active state, presleeping state, and sleep state.
We assume that all the nodes are in active state in the beginning of the network. Since all the nodes are scheduled round robin, here we only describe the scheduling process in one round. There are 5 steps in one round.
Step 1. If the current node is active, there are two cases to consider. If there is data in the network, process the data; otherwise, go to step 2.
Step 2. Determine whether the current node is a coverage redundancy node using the techniques given in Section 4.1. If yes, go to step 3; otherwise, return to step 1.
Step
3. Send a pre-sleeping message to the neighbors of the current node and start the latency timer
Step
4. The current node listens to messages from the neighbors. If within
Step
5. The current node begins to sleep for
5. Performance Evaluation
We refer to our proposal as expectation-based LDAS, or ELDAS for short. In order to validate the effectiveness and correctness of ELDAS, we conduct experiments using MATLAB. We measure the performance of ELDAS in terms of two aspects: (1) the relationship between the network coverage ratio and network lifetime and (2) showing the network coverage damaged by uneven sleep problem owning to border effects. In the experiments, we randomly deploy 200–300 sensors in two-dimensional terrain with
Figure 6 gives the relationship between the simulation time and network coverage.

Network coverage with different redundancy rates.
In Figure 6, there are 200 sensor nodes in the monitoring area. We test the relationship between network lifetime and coverage by setting the node coverage redundancy to be 90% and 80%, respectively. We observe that the coverage ratio of ELDAS is usually better than that of LDAS, for both node coverage redundancy rates.
Figure 7 gives the influence of the number of sensor nodes to network coverage ratio and lifetime, when the node coverage redundancy rate is 90%.
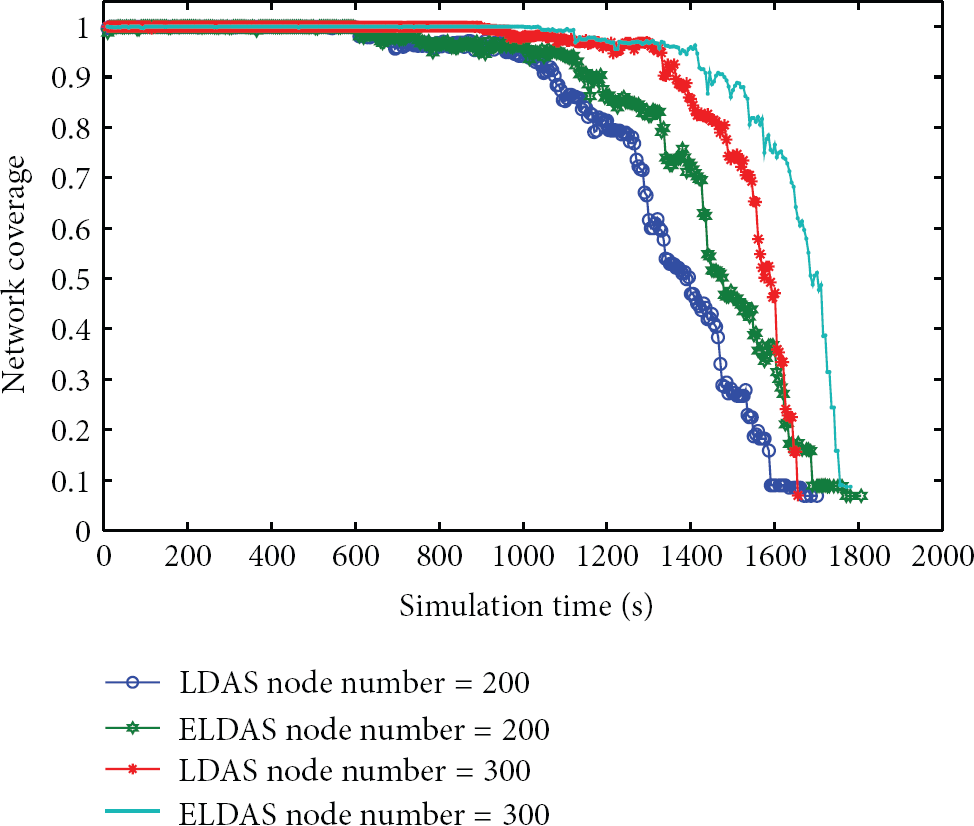
Network coverage with different node numbers.
In order to illustrate the uneven sleep problem in node scheduling, we use the energy consumption variance to measure the energy consumption imbalance.
We use both the mean value and variance of network energy to measure the energy balance status of a node scheduling method at time t:
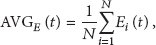

The energy consumption rate can be measured by the mean energy value, but it is not sufficient because the boundary sensor nodes or center nodes will run out of energy earlier than the rest nodes, whereas the mean energy value remains high. To this end, we also need the energy variance metric to better reflect the energy consumption balance status and validate whether the node scheduling algorithms can handle the coverage holes problem effectively.
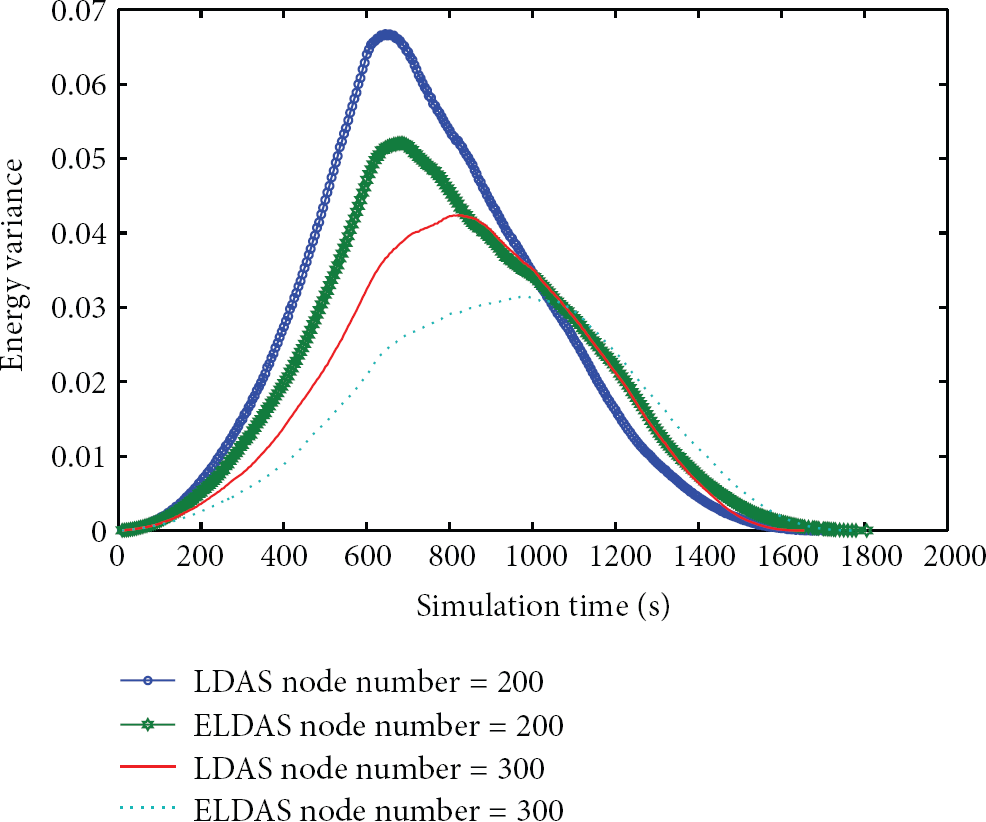
Figure 8 compares the network energy consumption variances of ELDAS and LDAS, when the node redundancy ratio is 90%, the radius of the sensing area is
Energy variance.
For node energy consumption, the lower the energy consumption variance, the better the network energy consumption balance. In Figure 8, we observe that ELDAS has smaller variance values and thus better energy consumption performance than LDAS. This is because LDAS can lead the boundary nodes to be in a serious uneven sleep problem, whereas ELDAS can effectively alleviate this problem such that the network energy consumption can be balanced, resulting in prolong the network lifetime.
6. Conclusion and Future Work
In this paper, we propose the uneven sleeping problem that happens during coordinated node scheduling in wireless sensor networks. To solve this problem, we analyze the important factors that may cause the uneven sleeping problem. More importantly, we propose a new metric to better model USP and a new node scheduling algorithm. Experiments show that, without influencing the network performance, our proposal can alleviate the uneven sleeping problem, reduce the influence of boundary nodes, and prolong the network lifetime. Although we only test our metric in the node scheduling approach in [14], this new metric applies to other node scheduling algorithms as well.
For the future work, we will research the redefinition of network lifetime. Network lifetime cannot be effectively reflected; people have proposed various such definitions though. In fact, network lifetime is a very comprehensive and systematic issue; yet few people have paid enough attention to this issue. Most node scheduling methods focus on extending the network lifetime, but it is unclear how they define network lifetime and measure the energy-cost balance.
Footnotes
Notations and Definitions
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grants no. 61300215, Key Scientific and Technological Project of Henan Province under Grant no. 122102210053, and Jiangsu High Technology Research Key Laboratory for Wireless Sensor Networks under Grants no. BM2010577.