
Abstract
Data replication is a known redundancy used in fault-tolerant distributed system. However, it has the problem of mutual exclusion of replicated data. Mutual exclusion becomes difficult when a distributed system is partitioned into two or more isolated groups of sites. In this study, a new dynamic algorithm is presented as a solution for mutual exclusion in partitioned distributed systems. The correctness of the algorithm is proven, and simulation is utilized for availability analysis. Simulations show that the new algorithm, ancestral dynamic voting algorithm, improves the availability and lifetime of service in faulty environments, regardless of the number of sites and topology of the system. This algorithm also prolongs the lifetime of service to mutual exclusion for full and partial topologies especially for the situations where there is no majority. Furthermore, it needs less number of messages transmitted. Finally, it is simple and easy to implement.
1. Introduction
In distributed systems, the redundancy of data or data replication is a well-known approach to achieve fault tolerance [1], increase availability of data base [2], decrease the response time of service and communication costs [3], and to share loads by distributing the computational loads over multiple sites rather than imposing them to a singular site [4]. Besides these advantages, data replication allows distributed systems to have concurrent access to sites for common data. If multiple sites simultaneously modify the common data, there are different contents of the same data in the distributed system leading to data inconsistency. Mutual exclusion (MutEx) aims to prevent data inconsistency when multiple sites are persuaded to access the same data at the same time.
Solutions for distributed MutEx are categorized into two main classes [5] which are token-based algorithms [6–9] and permission-based algorithms [5, 10–16]. In the first class, a particular message known as token circulates in the distributed system [5] and only the site that has the token is permitted to enter the critical section (CS). The other class, permission-based algorithms, utilizes the permission from multiple (usually the majority) sites so that the failure of one site (or more, depending on the algorithm) is tolerable.
Permission-based algorithms are categorized into coterie-based and voting-based. Coterie is a set of sites which require permission to commit an update. Every site in the coterie must issue permission so that a site can enter its CS. However, voting relies on permission from a predetermined number of sites regardless of which site agrees on commitment.
Nowadays, distributed systems face new requirements as they migrate to large scale applications. Social networks, sensor networks, and Internet of Things are instances of applications for distributed systems in which limitations on the number of sites or types of topology are not acceptable. Voting has a higher degree of replication, with no limitations on the number of sites and no need for complicated computations. There is a higher ability to face dynamic changes in the system [17] and easier implementation for large scale systems. However, coteries are not suitable for large number of sites because the number of coteries becomes large with 5 sites or more, unless they use heuristics otherwise, voting is very time consuming for six or more sites [18]. Therefore, the higher number of messages transmitted is an issue with voting algorithms. Moreover, some voting algorithms are limited by topology issues, and, in some other algorithms, nonrealistic assumptions are considered when using site information.
In addition to consistency issues for distributed systems, partition tolerance and availability are other concerns (refer to [19] for more details). In this study, a new algorithm is introduced for partitioned distributed systems, based on dynamic voting algorithms. Similar to other voting based algorithms, every single site that wishes to access CS must issue and broadcast its request to a group of connected sites or distinguished partition (DP). The site enters its CS if no site in the DP sends a rejection. This algorithm guarantees MutEx. It is deadlock free and needs fewer messages transmitted. It also can tolerate a higher number of faults and has a higher availability when facing consecutive failures. Furthermore, this new algorithm is simulated. Its availability and number of messages are compared to major partition tolerant voting algorithms.
The remainder of this paper is organized as follows. Section 2 has background and literature review on static and dynamic voting algorithms for distributed MutEx. Section 3 deals with the new proposed voting algorithm; proof of correctness is discussed in Section 4, while Section 5 presents the experimental results and performance analysis of dynamic voting algorithms. The number of messages transmitted is also discussed in this section. Finally, the conclusions and future works are explained in Section 6.
2. Background and Literature Review
Two types of voting-based algorithms, static and dynamic, are utilized for MutEx in distributed systems. The simplest form of static voting algorithm is majority voting presented by Thomas [4]. This algorithm performs a majority voting among all the sites in the distributed system and uses a different strategy to lock the mechanism (including semaphore [20] and monitor [21]) or timestamps [22, 23]. A site requests to enter the CS to update replicated copies of data if and only if it gets the permission from the majority of n sites, that is,
Static voting algorithms [2, 4] use predetermined information on sites and distributed systems. This information is fixed during the system's life time. In case of emergency or failure, the algorithm is not able to change its policy. There are some situations where the distributed systems are partitioned into two or more isolated groups of sites [5, 11] with no intersection between isolated groups. These groups are known as partitions. All sites inside a partition can communicate with one another, but they cannot communicate with other sites in other partitions [28]. If static algorithms are used for these situations, the partitions can have parallel access to CS because the sites inside each partition look at the partition as an integrated system, when in fact they belong to a partition among multiple partitions of a distributed system.
In a partitioned distributed system, if there is no majority partition, every site must reject incoming update requests to avoid data inconsistency. In this case, the distributed system is halted until a recovery or repair process is executed and a DP is found. This interruption decreases the availability of MutEx and is known as the problem of halted states [5, 29]. This problem cannot be solved by static voting algorithms because they do not have adaptability with dynamic changes of system connectivity.
Dynamic voting algorithms [30–32] are the main solutions to avoid halted states. They increase the availability of distributed MutEx in partitioned distributed systems [29] and utilize two main mechanisms to prolong MutEx either by increasing the vote (or the priority) of a partition to be higher than the other partitions or by enabling the algorithm to service noncritical applications during the halted state (e.g., [33]). In this study, the first mechanism is discussed in terms of the most successfully referred partition becoming the DP and when the problem of halted states is prevented or decreased. Major dynamic voting algorithms are group consensus [29], autonomous reassignment [29], dynamic linear [30, 31], hybrid [31, 34], and dynamic weighted voting [32], all of which have been designed based on majority voting, either directly or indirectly.
Group consensus requires a coordinator to assign each site a number of votes and allows only the group with the majority of votes to perform the requested operation [29]. Once a site has discovered the failure of the coordinator, it initiates itself as a candidate for coordination. This site becomes the new coordinator and installs new votes if and only if at least the majority of sites sends consensus. A sequence number is assigned to each site. The sites with the latest data always have the greatest sequence number. Vote reassignment [18, 35, 36] is done by using the information sent by other sites on the topology of the system [29] in such a way that at the most one partition forms the majority partition.
Autonomous reassignment [29] solves the problem of group consensus for the single coordinator by having the distribution of the algorithm on every site in the distributed system. Therefore, each site is responsible for managing its vote [29]. A mechanism is required to restrict a site from changing its vote arbitrarily and making the MutEx at risk. To do so, each site must obtain an approval of a certain number of sites prior to every assignment. Autonomous reassignment is more flexible, simpler, and quicker than group consensus; however, it has a lower degree of fault tolerance [29]. Although this algorithm has some benefits including a lower number of messages, faster action, and flexibility, it requires knowing the global information on the total number of votes (including the votes of sites in other partitions). This requirement is not realistic as it contradicts the concept of isolated partitions [11].
As a pessimistic technique to deal with partitioning, dynamic linear algorithm [30] is proposed with the aim of increasing the availability of MutEx in distributed systems, in addition to guaranteeing MutEx. In this algorithm with n sites owning replicated data, two parameters including version number (VN) and the number of sites or site copies (SC) are considered in the latest update and are assigned to each site
Hybrid voting utilizes static voting for nonfaulty conditions and switches to dynamic voting once partitioning occurs. The aim of hybrid voting [31] is to increase the availability of dynamic linear in situations where the number of sites with the current copy of data is exactly
In dynamic weighted voting [32], each site has a predefined weight and a DP with greater accumulative votes (weights) in comparison with the sum of corresponding associated weights to the site(s), with the maximum version number [32]. Every site keeps the information on version numbers and weights of other sites at the time of partitioning. A coordinator is responsible for forwarding the update request to the sites in the majority partition and to determine the commitment or rejection of an update [32]. As a result, dynamic weighted voting is a centralized algorithm which has a lower degree of fault tolerance in comparison with distributed algorithms. A difficulty with this approach is the obtaining of fair and proper values for the weights. If a weight of a site is very great, the partition including the site is always considered as a DP. Hence, even failed sites get repaired and can rejoin the partition even if they are not useful for the consensus.
Studies in [37, 38] introduce two forms of hybrid mutual exclusion algorithms as a combination of token-based and permission-based algorithms. The study in [37] uses Maekawa's quorums [24] for every site in the distributed system. In the first phase, a site broadcasts messages to its quorum asking for its permission. Once permission is received, it creates a token message. Subsequently, the algorithm needs to form a logical tree with the token holder as its root. Once the token holder releases CS, it sends the token to one of its children in the tree. This algorithm guarantees MutEx as long as no failure of sites or links happens. It does not consider fault tolerance and partitioning of network. Another hybrid MutEx algorithm is suggested in [38]. It is basically a token-based algorithm which uses tokens to get the permission of CS and utilizes coteries (similar to quorums) to reduce the number of communication. It should be noted that hybrid MutEx is for group MutEx.
All voting algorithms are capable of enhancing the availability of distributed systems to achieve MutEx. However, they are inefficient to keep the system available in case of consecutive failures (e.g., Gifford's weighted voting [2] and Thomas's majority voting [4]) or for complicated calculations (e.g., autonomous reassignment [29], hybrid voting [34], and Davcev's dynamic voting [32]) or for accurate knowledge about the topology of the distributed system (e.g., group consensus [29]). A preliminary study [39] on ancestral dynamic voting (ADV) algorithm shows improvement in the availability of distributed systems where the sites or links are vulnerable to fail. ADV guarantees MutEx in partitioned distributed systems. It is simple and does not need special assumptions on the number of sites or topology of the network. In this study, fault tolerance, lifetime of service, and number of messages were investigated according to link failure and site failure, partially and fully connected topologies, and two different configurations of the system (fresh start and consecutive); however, only availability had been discussed in [39].
With token-based and some static algorithms which use logical topology structure, ADV does not need to know the topology. ADV uses the ancestor to give privilege to a partition among multiple partitions. The sites are not required to obtain the permission from all the sites in DP to enter CS. Therefore, ADV is different from primary copy [40, 41] and coordinator cohort [42] in which one primary site is set and permissions are issued for CS. The situation is different to the extent of using a nonfixed coordinator in every cycle and voting technique for decision making. Furthermore, issues related to network partitioning are not pointed out in coordinator cohort and primary copy.
3. Ancestral Dynamic Voting (ADV) Algorithm
In this study, ADV aims to work with any topology, whether the topology was partially or fully connected. To avoid parallel access of sites to CS, CS_Flag was utilized. Ancestor is a label for a site that establishes the latest successful commitment and the number of sites with replicated data of between 0 and n. In a distributed system comprising n sites, each site is labelled as
ADV is distributed among all the sites, and the failure of one or more sites cannot interrupt the service as long as the ancestor of each voting cycle is up. A site is supposed to communicate with the others, unless it failed or is disconnected. For a single site, the failure of other sites is not distinguishable from its corresponding links' failure, unless a special fault detector is utilized. However, in this study, timeout for detection of failures (similar to [43]) is used. It is assumed that the ancestor does not fail during CSing, but it can disconnect or leave the current partition to form a new DP.
The main assumption of ADV is that the sites, update their information the same way as what the establisher has sent for them. They do not behave arbitrarily as reported in general Byzantine problem. The definition of a partition is similar to other voting algorithms; that is, an isolated group of sites cannot communicate with the sites outside the group. There is no assumption on how the sites are connected, and there is no single coordinator in the system. Sites do not need to know the information of other partitions and only act based on their partition information.
A distributed system initially forms one partition P; however, some sites or links may be timely disconnected from the partition due to failures. Every single site k sees this partition from its point of view as partition
CS_Flag announces a site status when regarding the CS. Initially, all the sites are in the normal state, that is, CS_Flag = 0. A site goes to CS state, that is, CS_Flag = 1, once it receives the permission from other sites for CS. CS_Flag is set in two cases: when it is the establisher of the current voting cycle or when a site has been asked by other sites to participate in voting (i.e., received Msg1). In the first case, if CS_Flag has been already set, to avoid data inconsistency, the site has to send back a rejection message to the sender. Therefore, the establisher finds the concurrent access to CS and rejects the request.
3.1. Structure of the Algorithm
In this study, ADV is executed by three subprocedures. The first procedure is for initialization that is performed by every single site in the distributed system. The second procedure is executed by a site which needs to update shared data and generates requests for CS. The third procedure is event handler and performs proper actions once an event is triggered. The sites are normally waiting for incoming requests, whether from an application or from other sites. Therefore, ADV is an event triggered algorithm.
Each request carries at least the label of the sender or receiver(s) and the content of the message. Five types of messages are defined in ADV. They are as follows:
Msg1: request to enter CS, Msg2: permission, Msg3: request to update data structures and release CS, Rejection: rejection of a CS request, Failure: reporting a site failure to other sites.
Figure 1 summarizes the relations between messages and site states. Three messages as seen in Figure 1 are transferred for a successful update of CS.

Relation between messages and site states.
There are two timers including request_timer and release_timer which trigger the events of failure. The request_timer is embedded in the ancestor's routine and detects failure or disconnection from other sites to which the request for CS has been sent, whereas the release_timer is utilized to detect disconnection or partitioning of a site from the ancestor. The value of the request_timer is selected according to the network communication delays. The release_timer is longer than the request_timer because it includes at least two network communications delays and a longer time duration while the other site is in CS. The relation between these timers is delineated in Figure 2.

Relation between request_timer and release_timer.
3.1.1. Initialization of Sites
Procedure ADV_initialize sets initial variables on every site in the network and is called up before event handling by ADV. To avoid ambiguity, the first time ancestor of the partition is assumed to be the first site, that is,
As every site has its own view of its partition, it is good to indicate the view of a site
Void }
3.1.2. Generating CS Request
When a site needs to update replicated data, it performs procedure ADV_CSing by sending its request to all its partition mates. Other sites may give priority to concurrent incoming requests for CS by considering the requesters' version numbers. Therefore,
Void request_timer –; { Number-of-attempts –; } } } }
Procedure 2
3.1.3. Event Handling
All the sites are normally waiting for an event from other sites or even themselves. When an event arrives, an event handler decides on the event based on the type of message delivered to the site. Procedure ADV_EventHandler is executed on every site, as seen in Procedure 3.
Void CS_Flag=0; } } } } }
Procedure 3
When
Site
Void CS_Flag=1; // it releases CS and broadcasts it to partition P release_timer –; //no CS release has arrived from //time-out } } }
If no message arrives before the release_timer's timeout,
For procedure Vote_reply, the establisher of CS request receives replies (i.e., Msg2, VN, and Anc) from other sites in partition
Void } } } }
Procedure 5
Every site that receives Msg3 updates its information to new
Void CS_Flag=0; }
Procedure 6
It is always possible for a repaired site to rejoin the distributed system or to update if its data are obsolete. Obsoleteness can occur due to link failures or failures of sites during update commitment. In this case, the obsolete or failed site must send its update request to a site through which it connects with the partition.
If a site
The concept of DP in ADV depends on the existence of the ancestor. If the ancestor fails, ADV interrupts to service other sites. This problem is common in algorithms based on the coordinator. To detect and elect a new ancestor, some techniques such as [29] can be added on ADV.
4. Proof of Correctness
This section proves that ADV can solve the problem of MutEx in partitioned distributed systems and prevent deadlocks. The algorithm works correctly if every site updates its information. The following shows the theorems and proofs.
Theorem 1.
ADV guarantees MutEx in a nonpartitioned distributed system.
Proof.
As long as no failure occurs, a distributed system is nonpartitioned. This proof is discussed in two states: initial state and normal states.
(1) In Initial State. In a nonpartitioned distributed system, initially every site considers
(2) In Normal States. For a nonpartitioned distributed system, MutEx is not guaranteed if the two sites
Theorem 2.
ADV guarantees MutEx in partitioned distributed system.
Proof
(1) In Initial State. Initially one site
(2) In Normal State. When a distributed system is partitioned into two partitions Site Similar to Theorem 1, by using the method of contradiction, Theorem 2 can simply prove that two partitions with two different ancestors do not exist in two different partitions
Theorem 3.
ADV is deadlock free.
Proof.
One reason for deadlock to occur is waiting loops, when sites
The other reason for deadlock is waiting for infinity to enter the CS. ADV benefits by having the release_timer so that
Based on the philosophy of partitioned distributed system, except for one partition, there are some partitions whose sites should not enter CS. In fact, this definition indicates that the sites in the nondistinguished partition must starve! Thus, in MutEx algorithms for partitioned distributed system, starvation freedom is not realistic. The only privilege for these types of algorithms is higher availability of MutEx.
5. Experimental Results
For more clarity, ADV algorithm is shown in Figure 3 which shows a distributed system with 5 sites. The links which are displayed with dashed lines have already failed because

A distributed system with two partitions.
Scenario 1. Site 4 has received an update request (current
Scenario 2.
Scenario 3.
Scenario 4.
For the purposes of simulation and experimental results, ADV, dynamic linear, and hybrid voting algorithms are discussed as follows. One effective point on fault tolerance of an algorithm is coordination. A centralized coordinated algorithm is vulnerable to fail because the coordinator is a single point of failure. Reliability and availability of the system are always functions of the reliability and availability of the coordinator. Therefore, these algorithms are avoided, except when they are required due to the limitations of implementation or when the algorithms are utilized to upgrade or improve the performance of old-fashion systems. For this study, group consensus and dynamic weighted voting are ignored in the analysis and comparison. Autonomous reassignment can be a good candidate for analysis; however, it needs to know the total number of votes including the votes of sites in other partitions. This condition is not realistic or possible in many real situations. For this reason, it is also neglected in this study.
The remainder of this paper discusses dynamic voting algorithms including hybrid and dynamic linear which are utilized for analysis and comparison. Table 1 displays the results of 5 consecutive tests on ADV, hybrid, and dynamic linear voting algorithms.
Comparison of ADV, dynamic linear and hybrid voting algorithms for 5 consecutive tests.

Test numbers are presented in the first column. System configuration, and information required by each voting algorithm is perceived in the second column, including the site that has received the update request (establisher). A request can be examined if and only if a nonfaulty establisher has obtained the request. The version numbers (VN), site copies (SC), distinguished sites (DS), and the ancestor of each site (Anc) have been presented in the system configuration. If dynamic linear voting is taken into account, SC and VN need to be known, whereas ADV needs VN and Anc. Obviously, VN, SC, and DS are essential for hybrid voting.
In Test 1, the system is in the initial condition. When the version numbers are zero, there is no ancestor and the site copies. The distinguished site refers to all the other sites with common data.
When a link fails, site
In Test 3, the system's condition is similar to the former test, except that the establisher is changed to
Another partitioning happens in Test 4 with
Hybrid algorithm improves the availability of dynamic linear algorithm if less than the majority of the current sites remains. The sites have higher repair rate versus failure rate (the probability of repair is thus much more than the failure). Since
In this section, the benefits and weaknesses of ADV versus hybrid and dynamic linear algorithm are analysed. Different scenarios of failure injection, topology, and simulation environment are presented. However, the performance measures used for the comparison and analysis should be discussed, as in the following section.
5.1. Performance Measures
Two main measures are used for the analysis and comparison of dynamic voting algorithms including the number of messages transmitted and availability of MutEx. Availability has widely been used in analysis and comparison of dynamic voting algorithms and is defined as the probability that an update request can be serviced at any time, t [34]. This measure requires not only a partition existence but also the capability of at least one site in the partition to be operational in order to service the request. A second definition measures availability as the proportion of time during which a distributed system services the requests either as critical or noncritical. By using this definition, synchronization delays are the time during which a process enters the CS, till the next process coming into the CS [16]. Interruption periods during connectivity changes (as discussed in [17]) should also be taken into account. However, issues relating to synchronization and delays are not taken into account in this study. In this paper, a simplified version of the first definition is used. Availability is measured by the number of times that a distributed system can service a request and update replicated data successfully [39].
Though the availability improvement of MutEx is the main objective of this study, it can be compromised by high message transmissions. For a higher number of sites, a higher number of messages are required to be transmitted. A high number of message transmissions for every commitment cause extra communication cost, more time for sites to process messages, and traffic increase in the network. The effective time dedicated to service updates and query requests is then affected. Therefore, there should be a tradeoff between these two measures.
At least 3 messages are required for ADV algorithm to commit or reject an update request, with 2 out of 3 messages for communication between the application and establisher. The establisher can be any of nonfaulty sites in the distributed system. One more message is enough for update commitment or rejection if the establisher is the ancestor or if it does not agree on an update. Otherwise,
Dynamic linear and hybrid algorithms require
5.2. Simulation of Test Harness
Software simulations are used in this section to study the availability of dynamic voting algorithms dealing with high rate of failures. In the simulation environment, the issues related to interruption during connectivity changes [17] are not taken into account. The simulation of voting algorithms is considered as event-driven. An event-driven simulation implies that the algorithm acts or reacts if a change occurs, whether a message is received or required to be sent. This assumption already has been used in the simulation of protocols in the distributed systems [44–46] and in dynamic voting algorithms [29]. MATLAB can be used effectively for the purpose of simulation. The toolboxes of distributed computing and real time also can be utilized or linked to this study's simulator for future works.
Simply, all sites are assumed to have common data. The sites are labelled as
5.2.1. Fresh-Start Simulation
In fresh-start simulation, at the start of each simulation run time, the failed sites or links are restored to their original form, except for their version numbers, ancestors, and other information needed for the voting algorithms to work properly. Fresh-start simulation is used to find out which algorithm works better generally and how the algorithm reacts to the sudden changes of connectivity and the number of failures. The results of fresh-start simulation are discussed based on the number of sites when random failures are injected and the number of failures when the number of sites is fixed. Simulations are also presented for two types of topology: fully connected and partially connected (random topology).
(1) Fully Connected Topology. Figure 4 illustrates the availability of ADV, dynamic linear, and hybrid voting algorithms in a fresh-start simulation versus simulation times. In this system, 4 sites are assumed. Uniformly, 0 to 3 sites may fail.
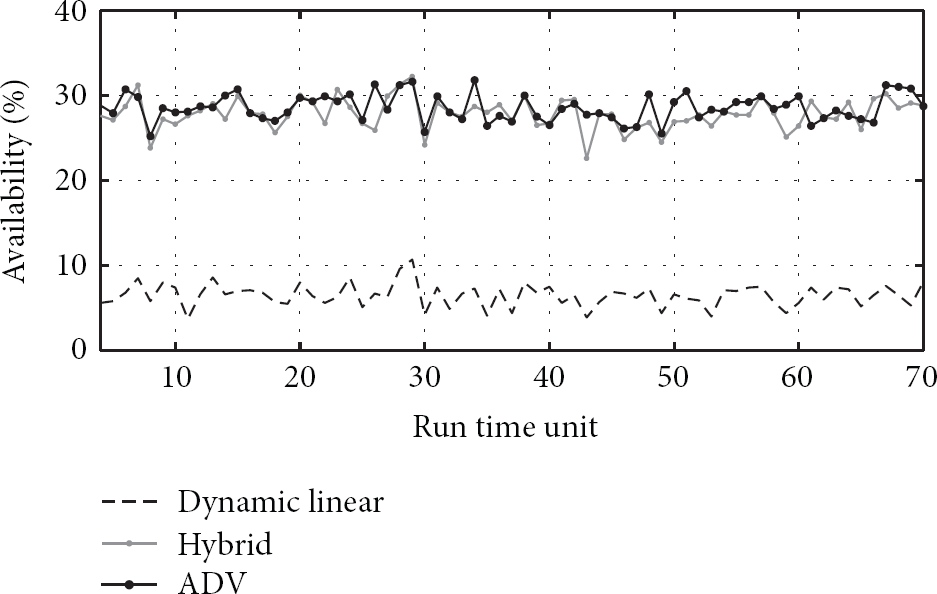
Availability comparison of ADV, dynamic linear, and hybrid voting algorithms [39].
The availability of ADV and Hybrid algorithms is seen to be much higher than Dynamic Linear voting algorithm, due to the possibility of the service having less than the majority of the current sites. For the same reason, ADV and Hybrid algorithms compete for a higher level of availability. However, the magnified plot in Figure 4 and the comparison of mean availability of algorithms in Figure 5 demonstrate the improvement of ADV algorithm to average 59.83% and 2.86%, compared to Dynamic Linear and Hybrid algorithms respectively. Similar results to Figures 4 and 5 were obtained in simulations for 10 and 100 sites, although with different percentages of improvement. The mean availability of ADV, Dynamic Linear and Hybrid voting algorithms were obtained for 1000 runs as presented in Figure 6 and showed the higher availability of ADV compared to other algorithms.

Availability of ADV and hybrid voting algorithms for 50 run times [39].

Mean availability of ADV, dynamic linear, and hybrid voting algorithms for 1000 runs [39].
Answer to the question “why ADV loses the competition in some scenarios” can be found in the selecting of DP. A DP depends on the ancestor in each voting cycle. Although the ancestor changes dynamically once an update is committed, it can be the single point of failure in some situations.
Figure 7 displays results similar to the previous scenario, in terms of the number of failures. This figure shows the availability of dynamic voting algorithms dealing with a specific number of failures.

Availability of ADV, dynamic linear, and hybrid voting algorithms relating to the number of failures, after 1000 runs for each scenario.
Definitely, the availability of algorithms decreases for a higher number of failures. ADV has the highest availability for a full connected system comprising 4 sites. When 4 sites are in a partition and suddenly 2 failures are injected, the probability of forming a partition with 2 sites increases. hybrid algorithm can improve dynamic linear algorithm for cases with
Figure 8 presents the availability of dynamic voting algorithms for random failure injections from 0 to maximum 5% of sites. Though ADV shows lower availability compared to dynamic linear and hybrid algorithms, its availability never goes below 95.5%. It is noted that in simulations of hybrid voting in [31], at the most 2% of the sites (with a simple estimation) may have failed. The results for 2% were also analysed, but the plots were very close and their differences were not distinguishable for display.
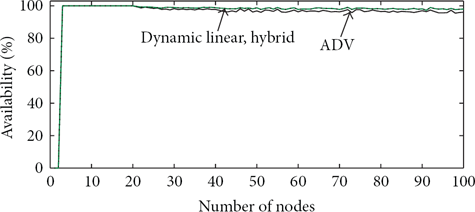
Availability of dynamic voting algorithms for low rate of failure in terms of number of sites after 1000 runs for each scenario.
In Figure 9, the availability of dynamic voting algorithms is presented for an environment with a high rate of failure. Less than 50% of sites are supposed to have failed, that is, the situations where no majority exists in the distributed systems. It is perceived that ADV acts much better than other dynamic voting algorithms.

Availability of dynamic voting algorithms for high rate of failure in terms of number of sites, after 1000 runs for each scenario.
Figure 9 shows an interesting finding. Although the purpose of dynamic voting algorithms was to resolve the problem of majority voting in dealing with partitioning, many of them including dynamic linear and hybrid algorithms were designed based on the concept of majority voting. When the number of sites becomes high, if no majority is found, at the most the majority of the sites cannot do any work and is interrupted. Figure 9 demonstrates that the majority-based voting algorithms still have the weakness of majority voting for a large number of sites.
(2) Partially Connected Distributed System. This section deals with partially connected distributed system. It investigates the availability of algorithms with topology changes in the distributed system. Real distributed systems frequently face topology changes due to transient failure of sites or links.
The availability of dynamic voting algorithms can be analysed based on link failure and site failure. The sites are potentially up when links fail; however, in many cases they are not able to communicate with other sites. For the sender of a request, the failure of a site is not distinguishable from the failure of one or more links [47]. Normally only site failures are treated as network partitions until repair time [33, 48]. The aim of analysing partially connected topology is to show how dynamic algorithms can tolerate link failures. It can be understood from the simulation results in [31] that hybrid and dynamic linear voting algorithms can be used for different topologies of distributed systems and ADV algorithm.
Sites are initially considered as nonfaulty and may fail in scenarios similar to fully connected simulation. Link failures occur in random fashion at the beginning of each simulation cycle. They are not changed during the injection of site failures.
In Figure 10, a distributed system comprising 10 sites is analysed in which the sites are randomly connected to one another to form nonfully connected topology. The other simulation parameters are similar to those in Figure 7.

Availability of voting algorithms for a partially connected distributed system consisting of 10 sites after 1000 runs in respect to the number of failures.
In real distributed systems the number of sites is normally more than 10 sites. This scenario is found in Figure 10, with 100 sites having failure rates from 0% to 50%. These rates are a quite large failure injection, as seen in Figure 11.

Availability of voting algorithms for a partially connected distributed system consisting of 100 sites after 10000 runs in respect to the percentage of failures.
Figures 10 and 11 show that the higher number of faulty sites leads to less availability of dynamic algorithms. The higher number is expected to happen for fully connected topology, but the major difference is the lower availability of dynamic linear and hybrid algorithms compared to ADV in a partially connected system. When links fail, many sites lose their connections to other sites. Although the sites are up and receive requests, they cannot obtain the majority of the consensus of the current sites and must reject the update request. Therefore, ADV is more available than hybrid or dynamic linear algorithms.
5.2.2. Consecutive Failures
The purpose of consecutive simulation is to investigate how long a distributed system can tolerate failures and continue to service. In this scenario, in every cycle at most, one failure is injected and sites are not repaired. Therefore, there are no sudden changes in the system's condition, and the system's configuration can be changed smoothly.
Figure 12 shows the availability of dynamic voting algorithms versus the lifetime of service for MutEx. The system is considered fully connected. However, when the simulation was repeated for partial topology, the results were similar. In this scenario, 10 to 100 sites are assumed. In every cycle, zero or one extra failure is injected into the system and a site is uniformly chosen as the establisher. To have a general view, each scenario of fault injection was iterated 1000 times.

Life time and availability of voting algorithms for consecutive failures, with 10–100 sites in distributed system. In each run, the maximum number of extra injected fault was 1. Each fault injection scenario was simulated 1000 times.
In every run, maximum only one new site fails. It means that there are some consecutive scenarios without any extra failure, compared to their previous runs. The choice of the candidate site for the failure in each scenario was based on random distribution. For this reason, the plots were jagged for some coordination.
It is obvious that ADV continues to service all scenarios. In other words, ADV prolongs the life time of the service, as it does not depend on the majority or any precondition on the number of sites. As a scale for the distributed system, ADV shows longer life time compared to other algorithms.
The comparison of the availability for 10 sites shows that the availability degradation for hybrid and dynamic linear algorithms started when the number of failed sites reached a majority or near a majority of sites. On the other hand, hybrid and dynamic linear algorithms had 100% availability when the majority of the consensus existed. In other words, the number of failure was less than 5.
ADV shows total performance improvement compared to dynamic linear and hybrid algorithms; however, the availability of ADV slightly degrades in a fully connected distributed system with a low rate of failure (Figure 8). The choice of ADV in this situation depends on a tradeoff between the availability and advantages of ADV compared to dynamic linear and hybrid algorithms. ADV is a simple and message efficient algorithm. Furthermore, its time complexity is comparable to dynamic linear and hybrid algorithms. Figure 13 presents the lowest time complexity of ADV versus other algorithms in the same scenario as in Figure 8.
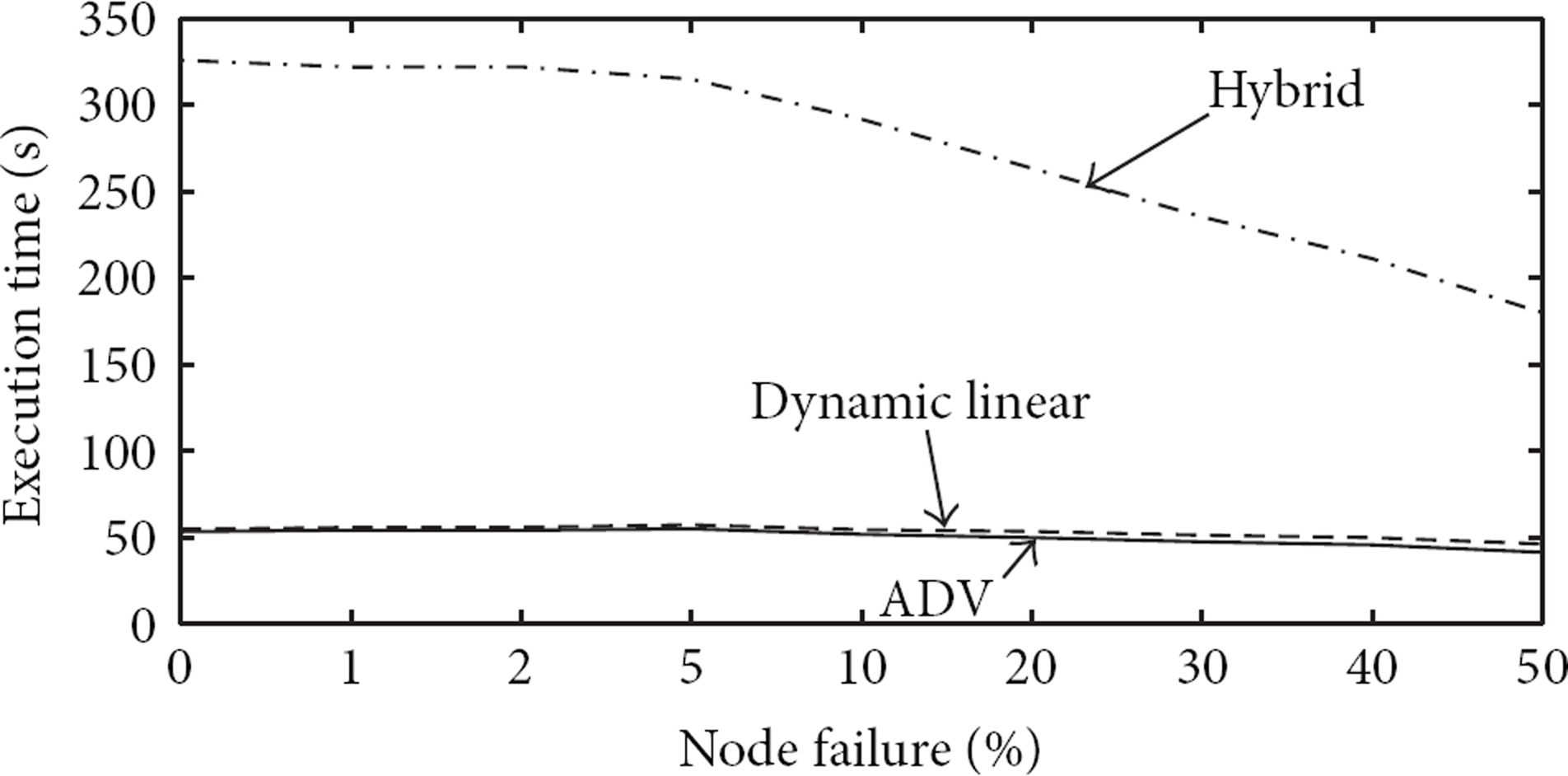
Time complexity of ADV versus dynamic linear and hybrid algorithms for fully connected system in terms of percentages of failures.
The results of simulations show that ADV generally increases the availability of MutEx in two situations. In a faulty environment the sites are vulnerable to fail or have dynamic changes in the system's topology. The causes are the failure of links or mobility of sites.
A challenge seems to be with ADV: if the ancestor is a single site and access to other sites for CS depends on its life, the ancestor has the same problem as the token with a single point of failure. However, ADV and token-based algorithms have some fundamental differences. Firstly, it is noted that a token is a particular message that is turned via system sites. Obviously the reliability of a token depends on many environmental parameters. A token is a specific message which is naturally more vulnerable to fail, whereas the ancestor is an independent site. Normally, reliable components are utilized to establish sites (e.g., servers, data base, I/O, and OS). Therefore, the probability of failure of a site is not comparable to a single message. Secondly, in each voting cycle, the establisher of the current cycle is chosen as the new ancestor. The ancestor is then not a constant site, and its role switches to other sites dynamically.
6. Conclusions and Future Works
ADV algorithm improves the mean availability of partitioned distributed systems by increasing the probability of the access to the CS regardless of the majority's existence in partitions. This algorithm uses the latest successful site to update a requested data as the ancestor of the current voting cycle. Among the isolated partitions in the distributed system, a partition that has the latest ancestor is chosen as the DP and is allowed to update the requested data. This algorithm does not rely on the logical structure of the network and improves the availability in the following situations.
Topology of the distributed system is random. Topology is fully connected. There is a high probability of failure and high number of sites.
This algorithm also prolongs the lifetime of service to MutEx for full and partial topologies. It guarantees MutEx and deadlock freedom. It is very simple to understand and implement. Moreover, it needs fewer numbers of messages to be transmitted in response to every update commitment. It also does not have the limitations of majority-based algorithms in dealing with a large number of sites and high rate of failure. It achieves higher availability especially for the situations where there is no majority.
In future works, a combinational algorithm can be designed based on ADV, dynamic linear, and hybrid algorithms. These algorithms are ideal for situations with low and high failures. A large number of sites and any form of topology can also be considered with easy design and implementation in mind.
Footnotes
Acknowledgments
This study was supported in part by Research University Grant (RUGS) no. 05-01-12-1648RU and Fundamental Research Grant (FRGS) no. 03-01-12-1115FR. The authors acknowledge the comments of the reviewers. The authors declare that there is no conflict of interests regarding the publication of this paper.