
Abstract
The prevalence of Radio Frequency Identification (RFID) technology requires Privacy-Preserving Authentication (PPA) protocols to prevent privacy leakage during authentication. Existing PPA protocols employ the per-tag authentication, in which the reader has to sequentially authenticate the tags within the detecting region. Such a processing pattern becomes a bottleneck in current RFID enabled systems, especially for those batch-type processing applications. In this paper, we propose an efficient authentication protocol, which leverages the collaboration among multiple tags for accelerating the authentication speed. We also find that the collision, usually being considered as a negative factor, is helpful media to enable collaborative authentication among tags. Our protocol, termed as Multiple-tags privacy-preserving Authentication Protocol (MAP), authenticates a batch of tags concurrently with strong privacy and high efficiency. The analytical and simulation results show that the efficiency of MAP is better than O(
1. Introduction
RFID technology has been involved in many daily applications [1]. RFID tags can be embedded in passports, ID cards, credit cards, and logistical labels to perform remote identification, as well as facilitate applications such as device-free activity monitoring [2] and fast inventory [3]. RFID tags usually contain or relate to sensitive information of the tag owners or carriers. If the sensitive information on a tag is exposed, the privacy of the tag holder will be jeopardized. Recently, Privacy-Preserving Authentication (PPA) protocols [4–6] are proposed to enable authentication for tags without leaking private information. Generally, each tag shares some secrets with the reader. During authentication, the reader interrogates a tag with a nonce. The tag responds with a message computed with the shared secrets and the nonce to authenticate itself to the reader. Upon this response, the reader searches in the backend database to find a match record for the tag and determine the validity of the tag. If the tag is legitimate, the reader emits a message to authenticate itself to the tag. Utilizing cryptographic functions and nonces, PPA protocols can strengthen privacy protection.
Most PPA approaches are designed for the per-tag scenario, where a reader can only authenticate one tag at each time. Due to cost concern, an RFID tag is usually designed to be extremely resource limited, even with less power than in sensor-based data collection applications [7]. Thus, the tag cannot afford complex cryptographic functions, such as asymmetric cryptographic functions. Thus, current RFID tags usually adopt relatively low-cost cryptographic algorithms, for example, the lightweight hash functions [8] or HB protocols [9], to perform the authentication. However, it is proven that a large system with strong indistinguishable privacy and constant complexity requires public key cryptography in [10], where the indistinguishable privacy (ind-privacy) means that none can link a tag and its behavior without learning its internal states. The proof also implies that the authentication complexity of PPA protocols is at least
The above dilemma motivates us to change the perspective of enhancing privacy and improving efficiency for PPA protocols. Before presenting our protocol, we report the following important observations.
Essentially, batch-type authentication pattern is more suitable for current RFID applications. Many RFID applications have urgent requirements for batch processing. For example, in port logistics applications, items are usually arranged in containers. The customs authorities need to check or even real-timely monitor the cargos to avoid hiding of dangerous goods. It would be impractical and time consuming to open the containers and authenticate the goods one by one. What is more, the tags on goods may have sensitive business information unwilling to be leaked. These needs also arise when express companies deliver valuable goods, where privacy leakage may cause reputation defamation of the customers. If batch-type PPA protocols are available, the urgent needs of efficient and private authentication can be satisfied. When facing multiple tags, an RFID reader needs an anticollision process for communicating and dealing with each individual tag. Although being efficient, existing anticollision approaches cannot meet the requirement of privacy protection. Thus, the anticollision process should be performed anonymously. The result of the anonymized anticollision process, however, is helpless to the authentication process. Simply combining these two processes is inefficient for real RFID systems. In addition, a large number of operations are redundant for processing multiple tags if employing PPA protocols with the per-tag pattern, which also incurs a time waste, as will be shown in Section 3.1. To resist the tracking attack, it is an intuitive way to employ multiple tags for confusing the attackers, as will be shown in Section 6.1. But we cannot fully utilize this feature if adopting the per-tag authentication pattern. If we can allow multiple tags to collaboratively protect themselves in PPA authentication, their privacy can be enhanced.
With the above observations, we introduce the concept of tag collaboration to RFID systems. A group of tags can cooperate to obtain better privacy protection. Furthermore, the collaboration can improve the efficiency of RFID authentication. We thereby propose a protocol to allow a batch of tags to collaboratively authenticate themselves to the reader. The protocol also meets the urgent need from real RFID applications. Our protocol, termed as Multiple tags privacy-preserving Authentication Protocol (MAP), has three major merits.
MAP allows multiple tags to perform collaborative authentication. Particularly, we leverage the collision, which is commonly considered as a negative impact on RFID authentication, to perform collaboration. The collaboration accelerates the authentication process and hides each individual tag in the group. MAP can effectively defend against compromising attack, in which an adversary tries to distinguish uncompromised tags based on the secret information obtained from compromised tags and provide strong privacy for multiple tags. We define a notion of m-strong-ind-privacy, as a refinement of ind-privacy, to evaluate the privacy strength of multiple tags' authentication. We prove that MAP can provide m-strong-ind-privacy. With this feature, the possibility that adversaries successfully break the indistinguishable privacy of tags is mitigated to be negligible. Therefore, our scheme provides strong privacy protection for practical RFID applications. MAP also provides security and privacy protection in terms of confidentiality, cloning resistance, tracking resistance, timing-based attack resistance, and forward secrecy. We present the theoretical upper bound, lower bound, and mean time cost of MAP's authentication efficiency. The results show that the authentication efficiency of MAP is better than
The rest of this paper is organized as follows. We discuss the related works in Section 2. In Section 3, we present our observations and motivations in authenticating multiple tags. We present the details in the design of MAP in Section 4. In Section 5, we discuss the performance of MAP. In Section 6, we present the security and privacy analysis. In Section 7, we provide some possible variants and improvements. At last, we conclude the work.
2. Related Works
2.1. Existing PPA Protocols and Their Limitations
Recently, Privacy-Preserving Authentication (PPA) protocols [4–6] are proposed to protect private information for RFID users. Those approaches aim to provide authentication for tags without leaking their private information, for example, the IDs stored in tags.
Early PPA protocols organize tags (or keys of the tags) in a linear structure [11, 12]. The linear structure results in
Besides the linear organization, tags can be organized in a virtual tree-based structure [19, 20]. In a tree-based approach, each tag is attached to a leaf node. Each node in the tree keeps a random key. A tag holds the keys on the path from the root to the corresponding leaf node. During an authentication, the reader sends a query and the tag generates ciphers using its keys. Upon the ciphers, the reader performs a Depth-First-Search (DFS) in the key tree for locating a path with correct keys that can successfully match those ciphers, and hence authenticating the tag. In this way, the reader can authenticate a tag with an
Existing PPA protocols are designed for authenticating a single tag at a time, which is suitable for per-tag scenario. The per-tag pattern, however, can hardly provide high efficiency and privacy simultaneously, which implies a need of adopting public key cryptography [10]. Unfortunately, the adoption of public key cryptography is prohibitively expensive for most tags due to the capability and resource limitations. Some researchers suggest weaker privacy models for per-tag authentication [23, 24].
Recently, some works emerged dealing with multiple tags' identification and thus are related to this work [25–28]. Yang et al. [25] propose to aggregate the responses from a batch of tags on corresponding readers, and then the aggregated responses enable probabilistic verification for the batch of tags. Bianchi [26] extends this approach and employs Bloom Filter to achieve a more general framework. These two works focuses on the reader-to-server process procedure, while our approach focus on the searching process for authenticating tags with privacy concern. Zheng and Li [27] propose a fast tag searching protocol which is efficient and scalable for multiple tags. However, this work focuses on tag identification other than authentication. Sheng and Tan [28] study the group authentication problem with heterogeneous RFID network. In this work, more advanced computational RFID tags are introduced helping regular tags to be authenticated to the reader.
2.2. Existing Anticollision Algorithms and Limitations
On the other hand, many anticollision algorithms, such as [29–32], have been proposed to arbitrate collisions of multiple tags. There are two major categories of anticollision algorithms, framed-slot-based approaches (also known as ALOHA-based approaches), and tree-based approaches. In an ALOHA-based approach, a reader first sends query command claiming how many slots in a detecting frame. Then each tag randomly selects a slot and transmits the ID within the chosen slot. In some slots, a collision may inevitably happen. The reader will repeatedly launch the detecting process until every tag can be identified without collisions. The tree-based anticollision protocols allow the reader to actively declare a filter. According to the filter, a set of tags are required to report their IDs in a slot, and others keep silent. In this way, the reader can decode responses and identify tags. In [29], historical information obtained from the last identification process is used in current identification process to decrease collisions. In [30, 31], a counter facilitates tags to evade collisions. The tags with a counter 0 respond the query and choose a value, for example, 0 or 1, for their counters in the next round if they collide. In [32], the authors propose a method for multiple readers to interrogate tags with near-optimal number of time slots.
Being effective in collision arbitration, the above designs, however, are unsuitable for protecting privacy, since the IDs are all in plain text during the anticollision process. Although the authors in [33] propose a pseudo-identifier to enable private anticollision, the pseudo IDs cannot help the reader to know the real ID of the tags. Thus the reader has to conduct another search procedure for locating the tags and getting their keys needed for authentication.
3. Observations and Motivation
3.1. Observations on Redundancy and Possible Treatments
In real RFID applications, it is common that a batch of tags is within the detecting region of a reader. The reader employs an anticollision process to distinguish those tags and then communicates with each of them for performing PPA authentication. Indeed, the combination of anticollision and authentication is inefficient.
Firstly, current PPA protocols are mainly designed for per-tag scenarios, where the searching process for different tags' keys contains many redundant computation and comparison operations. We demonstrate this fact via an example of a typical tree-based authentication protocol [20]. The keys are arranged in a key tree, as illustrated in Figure 1. The protocol is performed as shown in Figure 2. In Figure 1,

Tree-based architecture.

Typical tree-based protocol.
In Figure 1, if
Secondly, the anticollision and authentication processes are generally conducted separately. In the existing works, the result of anticollision cannot be reused by the authentication process. Since existing anticollision mechanisms are designed without considering privacy protection, if a tag uses its real identifier in the anticollision process, the privacy will be broken. To meet the need of privacy, a tag can only use anonymized ID, for example, a pseudo-identifier, in the anticollision process. Nevertheless, the reader cannot leverage anonymized ID to locate the tag in the database in the PPA authentication process. If the anticollision information is generated and utilized without privacy leakage, the authentication process can be accelerated by reusing the result of anticollision.
3.2. Motivation
Based on above observations, our motivation is to enable the collaboration of multiple tags to concurrently achieve privacy-preserving collision arbitration and fast authentication.
We still employ the example in Figure 1 to explain our strategy. Consider two tags
In fact, a legitimate reader knows the keys of all tags; that is, it knows the keys at each branch in the key tree. This fact allows us to leverage precomputed results to accelerate the authentication. In Figure 1, with these known parameters, R can compute the possible hash values of

Anticollision with one bit.
Based on the above analysis, we find that combining private anticollision and authentication processes is feasible. In particular, the length of each tag's response message to the reader can be minimized to one bit.
4. MAP Design
4.1. Overview
The MAP has four components: system initialization, tags authentication, updating, and system maintenance.
MAP also initializes a virtual tree to organize keys for tags. Except the root, each virtual node in the tree contains a key. Each leaf node is assigned to a tag. Hence, the depth of the tree is
To enable concurrent authentication for multiple tags, the authentication of MAP contains two phases, anticollision of multiple tags and authentication of individual tags. During the former phase, tags return one-bit responses to the reader. If more than one branch replies, the reader splits the entire tree (or a branch of the tree) into two subtrees (or subbranches). The reader then informs the tags on one subtree (or subbranch) to continue performing the MAP protocol, and the tags on the other subtrees (or subbranches) to hold.
For each subtree (or sub branch), the reader recursively executes the MAP protocol. When arriving at a leaf node in the virtual tree, MAP launches its authentication component, in which the reader mutually authenticates a tag.
After a successful mutual authentication between the reader and a tag, the keys of the tag will be updated and hence synchronized at both the tag and the reader. When updating the keys, MAP employs a cryptographic hash function with the current key and two random nonces as inputs to generate a new key.
In addition, MAP provides maintenance function to deal with tags' joining and leaving. Utilizing this component, the expired tags can also be renewed.
4.2. System Initialization
MAP employs a sparse tree, denoted as S, to initialize and maintain the keys for all tags. We use δ and d to denote the branching factor (2 for binary tree) and depth of S, respectively. For the simplicity of explanation, we choose the branching factor of 2. As shown in Figure 1, assuming there are N tags
When initializing a tag
4.3. Tags Authentication
The tags authentication of MAP is different from existing protocols. This component has two phases: anticollision of multiple tags and authentication of individual tags, as illustrated in Algorithm 1. On the reader side, the corresponding authentication is recursively executed on the key tree, as performing a depth-first-search (DFS). This is supported by the remount subcomponent.
// At non-leaf depth R randomly selects a branch, sends ( R records ( Tags which match Tags not match wait and record Go to depth x; // Authentication sub-component plus updating. R sends a timestamp then replies ( R computes a hash value for R accepts R updates R sends M as a random number; // if match // Remount R chooses the max While exists such R sends to tags ( R deletes the pair stored related to R continues to tags-authentication at depth
4.3.1. Anticollision
The anticollision process starts from the root of the key tree. At each virtual node, the reader R conducts one round of communication with the tags in its detecting range. In the anticollision process, prior works usually require a tag to respond with the whole hash value computed using its key and ID. Instead, MAP requests the tag to reply with only ONE bit in each round of interaction, as illustrated in Figure 3. The requested bit is in the highest position of those bits that differ. Algorithm 1 illustrates the interactive communication. We use
At each non leaf depth
To choose a branch related at depth
Upon receiving the query, a tag
The anticollision is an important part of authentication process, processing multiple tags at the same time. Based on this, MAP provides multiple tags style authentication, other than sequential authentication in which the authentication procedure for each tag does not overlap.
4.3.2. Authentication
When arriving at a leaf node, R starts the authentication subcomponent with
(1) R sends a query to
(2) Upon this query,
(3) R compares I to the hash value computed using corresponding key stored in the database. If the two hash values are identical, the reader accepts the tag as a legitimate one. Otherwise, R treats the tag as illegal. For a legal tag, the reader sends
Note that the key in the leaf node may not match the corresponding tag's key. In this case, R has to search through the entire database to check if a matching key can be found. If such a key is found, the tag is accepted as legitimate. In this way, even a tag which is desynchronization attacked and thus has a big timestamp can also be authenticated. This can prevent attackers from distinguishing tags by whether they can be accepted.
(4) Upon M,
A collision may happen when two tags choose an identical leaf node. At this time, there is more than one tag responding to the reader. Their signals will collide and cannot be correctly decoded. This can happen when a tag's random choices match the path of the other tag from root to leaf. The possibility is
4.3.3. Remount
After authentication and updating of a tag, the whole tag authentication process is remounted for unprocessed tags according to their “holding” sequence in descending order. R finds out the max counter
We illustrate the above process by using the example of authenticating
4.4. Updating
After a successful mutual authentication between the tag and reader, the updating process follows, as illustrated in Algorithm 1. MAP only updates the leaf keys for multiple tags environments, where a leaf key is the key on the leaf node. There are two reasons. First, in our protocol the keys on nonleaf nodes are only used for navigation. Second, as analyzed in [22], updating keys for tags without changing the sharing relationship of keys among tags will not increase the difficulty for adversaries to successfully conduct compromising attacks. We also allow a tag to be renewed in the system maintenance component, as an updating method which also updates the tag's location and the corresponding keys in the virtual tree for better privacy.
R updates the keys for a tag after a successful authentication of the tag. At the corresponding leaf node, a new leaf key is generated as
4.5. System Maintenance
Users may want to insert, renew, or withdraw their tags. The system maintenance component deals with these requests.
If a new tag joins in the system, R initializes it by assigning it to an empty leaf node and generates the necessary keys for it. If a tag is withdrawn, R simply deletes the information on corresponding nodes related to the tag from S.
We also allow a tag to be renewed for better security and privacy. The permission is controlled by the manager. When a tag is permitted to be renewed, it is first withdrawn by the reader. Then the reader treats the tag like a new one and inserts it into the system. After being renewed, the new keys and related path in the key tree have no relation with the old ones.
5. Performance Analysis
In this section, we analyze the performance of MAP, considering both communication and computation costs. We theoretically analyze the costs and give the corresponding upper bound, lower bound, and mean value. We also launch a simulation. Then we compare the performance of MAP with two combination solutions.
5.1. Theoretical Analysis
In MAP multiple tags are authenticated concurrently; thus, we care about the average time costs derived from costs for all tags divided by the number of tags. In Section 5, when we mention a cost for each tag, we are meaning such an average time cost for each tag.
There are cases when the tags to be authenticated cover the least branches. Then paths of these tags cover a full subtree and a single path from the root of this subtree to the root of system tree S, as
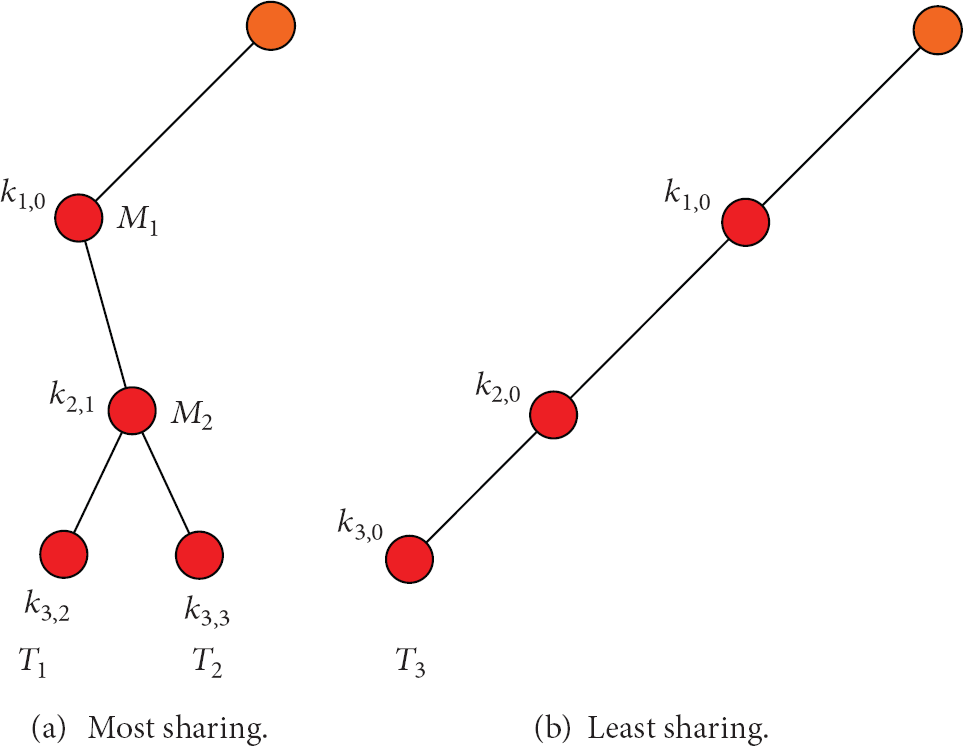
The different sharing scenarios.
Contrarily, when the tags cover the most branches, respecting no path being shared, as
For theoretic comprehensibility, we consider time cost for transferring hash values in communication cost. For compute cost, we consider only cost for computing hash values at both reader end and tag end. For the overall cost considering overheads, we give a simulation result in Section 5.2.
When tags cover the least branches, the minimum communication and compute cost are computed as follows. Theoretically, they are the lower bound of MAP in terms of time cost. Indeed, both of them are in O(1) complexity:

When each tag covers the most branches, there is only one tag to be authenticated. Thus, we get the maximum costs. We denote the maximum communication and compute cost as
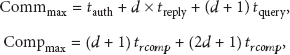
When tags cover all branches, supposing the cover probability is unique, we get the mean communication and computing costs as follows:

Both Commmean and Compmean are strict monotonic functions of
Considering the minimum authentication cost, without anticollision or updating, for a single tag in traditional tree-based protocol, it will need to compute, transmit, and verify at least
5.2. Simulation
We compared the average processing time of MAP to two simple combination solutions. Both the two solutions use the slot-count (Q) selection algorithm in EPC C1G2 UHF Air Interface Protocol Standard [31] for anticollision. The PPA protocols for these two solutions are the typical tree-based protocol [20] and RWP protocol [22] with O(1) complexity. In all protocols, both tag side and reader side employ SQUASH (SQUaring haSH), which is proposed by Shamir in [8], to compute hash values. SQUASH needs only several hundred gate equivalents (GEs) and is appropriate for low cost RFID tags. We consider the overall time cost including communication cost and search cost. The communication cost includes the cost for transmitting commands and data with overheads such as wait time, time out, frame sync, and preamble. Note that, compared to other kinds of wireless communication such as WiFi, the messages exchanged between the reader and tags are very short. Thus, the overheads are not negligible. All the command formats, data formats, and link timing follow the standard. In search cost, we consider compute cost for hash values by both reader and tags. We assume the reader can process 223 times 64 bits SQUASH in a second in average. For the tag, we assume it can process one time SQUASH in 67.75 us and 242 us. We make these two assumptions based on the link timing requirements specified in the standard.
In our simulation, the forward data rate is 40 Kbps and the backward data rate is 320 Kbps. We suppose that there are 220 tags in the system. We choose tags randomly and repeat the whole process 100 times for average results.
In Figure 5, we give the result for 1000 tags. The simulation result shows that MAP gains a better efficiency than typical tree-based protocol. The average time cost of tree-based protocols is about 2.2 times to 4.2 times that of MAP. The efficiency of MAP asymptotically approaches the RWP protocol with O(1) complexity as the size of the tag set approaches 1000. The simulation result is in accordance with the theoretical analysis. That is because in MAP computing and communication are shared between all tags. Moreover, during anticollision subcomponent tags respond with only 1 bit to save communication cost. That is why MAP outperforms typical tree-based protocol when tag size is small.

Comparison on performance for 1–1000 tags.
According to the performance result in [26], for 1000 tags in a system with 105 tags at 40 Kbps forward rate, achieving 1% erroneous decision, the SEBA approach [25] needs 41 minutes, while the SEBA+ approach [26] needs about 4 minutes. Utilizing MAP, it takes about 1000 × 104.05 × 10−6 s = 11.22 s. which is less than SEBA and more than SEBA+. However, the result in [26] considers only the message transmission time, leaving out the nonnegligible computation time and the communication overheads such as wait time, time out, frame sync, and preamble. Moreover, MAP provides accurate authentication with no error probability. Thus, MAP is a good choice in performance for the authentication of multiple tags.
6. Security and Privacy Analysis
In this section, we analyze the security and privacy characters of MAP. Because our approach is tree based, we focus on resistance to compromising attack which has the most serious impact on conventional tree-based approaches [23]. We prove that MAP is m-strong-ind-private, showing that MAP satisfies strong privacy protection in multiple tags scenario. We also show the abilities of MAP in terms of confidentiality, cloning resistance, tracking resistance, timing-based attack resistance, and forward secrecy.
6.1. Compromising Attack
Compromising attack is the most effective way for crashing tree-based protocols. That is because tags organized in tree-based structures share keys with each other. When an adversary A compromises some tags and thus obtain their secret keys, A can deduce the secret keys of other tags. In conventional tree-based protocols, a legitimate reader splits a tag from other possible ones level by level and finally authenticates it on the leaf, using its keys on related levels. An adversary can also distinguish tags and further track them in this way with keys from the compromised tags. For detailed analysis, please refer to [14, 21].
Our analysis is based on the works in [10, 14, 18, 21, 23, 34]. The notion of strong ind-privacy defined in [23], which is equivalent to the destructive-privacy defined in [34], is very similar to the strong privacy provided by MAP, except that MAP focuses on privacy protection for multiple tags. The existing privacy models are designed for one-tag-one-reader authentication scheme and focus on distinguishability privacy between TWO tags only. They are not fit for the multiple tags scenario in MAP, where the reader cannot communicate to a tag before anticollision subcomponent.
We define a new model for multiple tags environments, including four oracles, Request(·, ·, ·), Send(·,·), Relay(·,·), and Compromise(·) to formulate the attacks to the tag sets and reader. Assume we have a tag set
Request(
Send(R,
Relay(
Compromise(
The compromising attack on MAP, denoted by
Step 1.
The adversary A compromises
Step 2.
A chooses a target tag T that has not been compromised. A can query T or act as a man-in-the-middle between T and the reader R polynomial times. Note that A cannot compromise T. According to the secret keys A gains in Step 1, A can compute outputs of these keys and compare to them T's outputs. In this way A can determine which of T's keys equal to A's known keys.
Step 3.
The system gives a tag set
We denote


Definition 1.
The advantage of adversary A in the compromising attack is defined as
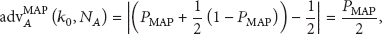
Definition 2 (M-strong
-ind-privacy).
An RFID protocol PRO is m-strong(
M-weak(ε,
The above two privacy notions can be simply denoted as m-strong-ind-privacy (MSIP) and m-weak-ind-privacy (MWIP), where the letter “m” is the abbreviation of multiple tags. When

The privacy levels.
The above model is dedicated for classifying the privacy protection in multiple tags scenarios. Intuitively, it is easier for a tag to hide in a set than to behavior indistinguishably to another tag. Thus, the above model is a model weaker than the privacy models for one-reader-one-tag scenarios.
However, if the authentication protocol does not take this advantage, then the protocol cannot provide better privacy in scenarios with multiple tags than in one-reader-one-tag scenarios, no matter how many tags are there to be authenticated. For example, in the OSK [12] protocol, one desynchronized tag cannot be accepted by a legitimate reader. Thus, a desynchronized tag can still be distinguished in a tag set, saying nothing of hiding in the set. As a result, the OSK method cannot provide m-strong-ind-privacy or m-weak-ind-privacy.
In the tree for MAP, when A is not aware of all keys in both branches, A does not know the
Theorem 3.
The MAP protocol is MSIP private.
Proof.
We perform the compromising attack with MAP protocol as follows.
We denote tags in
Case 1. A does not succeed in previous

Case 2. A does not succeed in previous

Case 3. A does not succeed in previous

The overall probability of A definitely knows whether


The possibility A succeeds in either subset is
Considering that
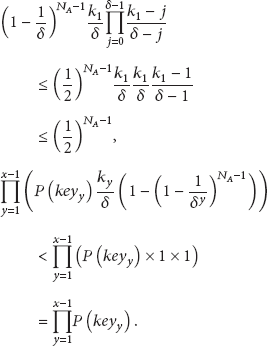

The right part of the inequality is a monotonically decreasing function of
Assume a RFID system of 220 tags with
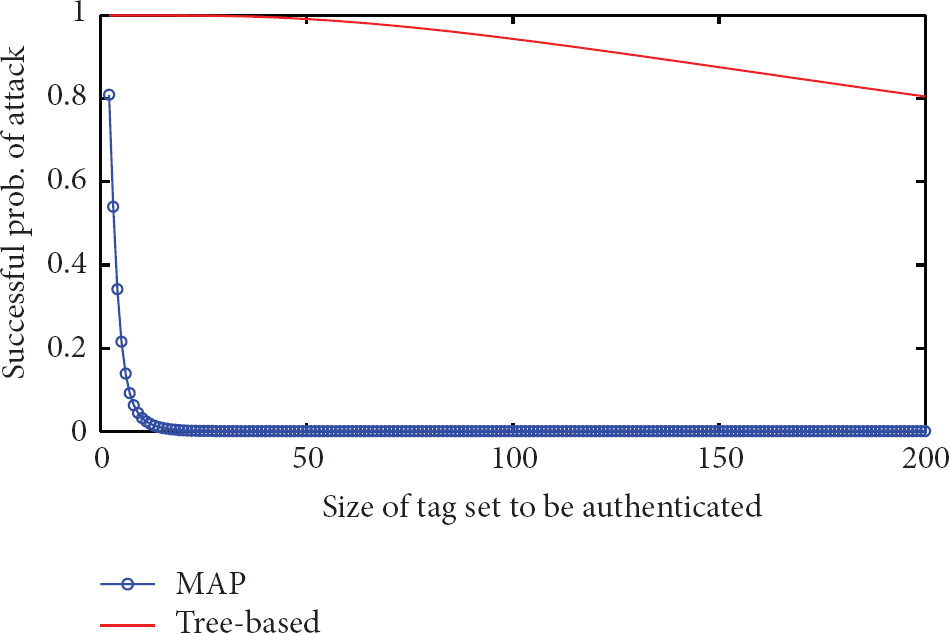
Comparisons on defending against compromising attack.
We can find that for both protocols the possibilities that A succeeds reduces when
6.2. Confidentiality
In MAP, all information from a tag is sent as the value of a cryptographic hash function or a part of such a hash value. According to the preimage resistance property of cryptographic hash functions, the adversary cannot know the origin information.
6.3. Cloning Resistance
In cloning attack, an adversary records responses from a tag and replay them to fool legitimate readers. In MAP, the
6.4. Tracking Resistance
In Section 6.1, we focus on tags' path keys and present that MAP can resist compromising attack in scenarios with multiple tags. For any leaf key, it uniquely belongs to an individual tag. The adversary A never knows a tag's leaf key unless compromising it. When performing authentication subcomponent, a tag computes a hash value with its leaf key and the session tokens. This authentication message varies each time, and A cannot link the messages to a tag without knowing its leaf key.
MAP resists against compromising attack in multiple tags scenarios. However, when a batch only has a few tags,
An adversary A may launch the Denial of Service (DoS) attack between a legitimate reader and tags. In this attack A firstly exhausts the timestamp in a tag. Then A can relay the tag's response to a legitimate reader to see if the tag is accepted and further track the tag by observing the result. This attack is not feasible to MAP because desynchronized tags can also be accepted employing MAP, as presented in Section 4.3.2. Besides, we recommend the system to thwart the response speed of the tags which are under attack. Then, a counter with an acceptable bit length is enough to avoid the timestamps of the tags run over a predefined threshold.
6.5. Timing-Based Attack Resistance
An adversary may time the processing cost of a tag to identify the status of this tag and further distinguish it from other tags [35]. This kind of attack is a new general attack which can even break the privacy of proven private RFID authentication protocols. MAP can defend against such attack. The reason is that the authentication process for each tag in MAP corresponds to the same procedure. From root to leaf, each branch selection corresponds to no sequential computation of tags. Instead, the tags do concurrent computation at each level. In this way, the observable behavior of each tag is hard to distinguish. The problem in traversing the traditional binary tree, which causes different searching cost, does not happen in MAP. On the other hand, the thwart method used in MAP does not raise rapid increase in the response. Thus, the thwarted tag's behavior is hard to distinguish, especially when the tag set is large and the predefined threshold is big enough.
6.6. Forward Secrecy
An adversary A can record the messages sent by R or tags. And A can compromise tags to obtain their current keys. Forward secrecy requires that the information in previous messages will never be revealed. In MAP, the leaf keys are updated after each successful authentication. The forward secrecy is thereby guaranteed. For the nonleaf keys, they are not used for data transfer but only for navigation. In addition, they will be updated when a tag is renewed. Thus, MAP does not update the nonleaf keys at each authentication and such a process does not damage the forward secrecy.
7. Possible Variants and Improvements
The storage requirement of MAP for a system larger than 216 tags may be larger than 1 k bits. This cost is practical for nowadays RFID tags. For ultra-low storage, path keys can be computed employing SQUASH with the unique leaf key and identifier of the tag as inputs. This would decrease the storage requirement to
MAP focuses on the interaction between tags and reader, as well as reader-server side search accelerating. On the other hand, the SEBA [25, 26] like protocols focuses on the reader-to-server communication, as well as the server side probabilistic verification. Thus, a possible future work is to combine and gain profit from both of the two styles of multiple tags protocols.
8. Conclusions and Future Work
In this work we propose a Multiple tags privacy-preserving Authentication Protocol, MAP, to authenticate multiple tags concurrently. By enabling anticollision functionality in authentication process, MAP eliminates the redundant efforts wasted in anticollision processes and authenticating tags. Tags in MAP respond concurrently with 1 bit to conduct the authentication for better privacy. MAP is m-strong-ind-private, which is a variant of ind-privacy we define for multiple tags scenarios. MAP can effectively mitigate the impact of compromising attack, in multiple tags scenarios, to an acceptable extent. Employing MAP, the successful tracking probability of adversaries for tag set larger than 8 is below 0.05 and will deduce rapidly to 0 as the size of the tag set enlarges. The efficiency of MAP is better than
Footnotes
Acknowledgments
The authors would like to thank Ling Zhu and Xingjing Wang for the efforts paid in coding for the simulations. This work is supported by Program for Changjiang Scholars and Innovative Research Team in University (IRT1078), the Key Program of NSFC-Guangdong Union Foundation (U1135002), National Natural Science Foundation of China (61303221 and 61373175), the Fundamental Research Funds for the Central Universities (K5051303021), and the Scientific Research Startup Foundation for Young Teachers of Donghua University (13D211205). Part of this work has been presented at IEEE International Conference on Mobile Ad-hoc and Sensor Systems (IEEE MASS), October 17–22, 2011, Valencia, Spain.