
Abstract
This paper proposes a scheme to enhance localization in terms of accuracy and transmission overhead in wireless sensor networks. This scheme starts from a basic anchor-node-based distributed localization (ADL) using grid scan with the information of anchor nodes within two-hop distance. Even though the localization accuracy of ADL is higher than that of previous schemes (e.g., DRLS), estimation error can be propagated when the ratio of anchor nodes is low. Thus, after each normal node estimates the initial position with ADL, it checks whether the position needs to be corrected because of the insufficient anchors within two-hop distance, that is, the node is in sparse anchor area. If correction needs, the initial position is repositioned using hop progress by the information of anchor nodes located several hops away so that error propagation is reduced (REP); the hop progress is an estimated hop distance using probability based on the density of sensor nodes. Results via in-depth simulation show that ADL has about 12% higher localization accuracy and about 10% lower message transmission cost than DRLS. In addition, the localization accuracy of ADL with REP is about 30% higher than that of DRLS, even though message transmission cost is increased.
1. Introduction
Many applications of wireless sensor networks such as object tracking, environment and habitat monitoring, intrusion detection, and geographic routing rely on the location information of sensor nodes [1]. To provide accurate position information of sensor nodes, each sensor node can be equipped with GPS [2]. In many applications, however, it is not possible that all sensor nodes are equipped with GPS economically and technically. For examples, GPS signal hardly reaches to all nodes when wireless sensor networks are deployed in underground structure or underwater environments, where a sensor node must estimate its position from various information of other nodes that are possibly equipped with GPS or estimate their positions from others as well. A localization refers to a process for determining the position of users or wireless devices without using positioning hardware device as GPS [3, 4].
Localization schemes are categorized into two classes: range-based positioning scheme and range-free positioning scheme. A range-based positioning scheme measures the distance or the angle between sensor nodes and estimate positions using triangulation, trilateration, and multilateration algorithms. Typical range-based positioning schemes include Time of Arrival (ToA) [5], Time Difference of Arrival (TDoA) [6], Angle of Arrival (AoA) [7], Received Signal Strength Indicator (RSSI) [8], and RSS-based localization using direction calibration [9]. The range-based positioning schemes require additional devices to measure the distance or the angle between sensor nodes. Some range-based positioning schemes are sensitive to temporary interference of signal such as noise and fading. They are unsuited to massive wireless sensor networks. A range-free scheme estimates positions using connectivity information between sensor nodes [10–20]. Among the range-free positioning schemes are Centroid [10], Convex Position Estimation (CPE) [11], and Distance Vector-Hop (DV-Hop) [12] methods. The range-free positioning schemes, however, suffer from high message transmission cost to gather the connectivity information and high computational cost to estimate positions of sensor nodes. In addition, they have shown high position estimation error compared to other methods.
Distributed Range-free Localization Scheme (DRLS) [21] improved localization accuracy of normal nodes by utilizing anchor nodes within two-hop distance. The scheme used grid scanning algorithm to estimate the initial position of a normal node and tried to improve the estimation accuracy by vector-based refinement. The vector-based refinement, however, could inaccurately decide the position of normal nodes depending on the relative position of anchor nodes and needs square-root calculations requiring high computation power. In addition, a normal node can infer an incorrect localization when it estimates its position from other normal nodes due to the lack of neighbor anchor nodes. The incorrect localization of a normal node deteriorates the localization of another normal node so that the error is propagated over the networks.
This paper proposes an Anchor-based Distributed Localization (ADL) scheme and its Reducing Error Propagation (REP) scheme. The ADL devises a grid scanning algorithm of two-hop anchor nodes instead of the vector-based refinement of DRLS, which reduces the computational cost occurred by the refinement of DRLS and improves the accuracy of the localization. The ADL with REP enhances the initial estimation of a normal node that does not have anchor nodes within two-hop and reduces the impact of the error propagation frequently occurred with a sparse anchor nodes deployment. Our contributions in this paper are as follows.
We designed a basic ADL to improve the accuracy of the localization and reduce the computational cost, and proposed an REP scheme based on ADL to decrease the propagation error in the sparse anchor nodes deployment, as previous work [22, 23]. In this paper, we organize the ADL with REP and then develop the various simulation environments to evaluate our scheme from the several points of view. The results via in-depth simulation show that the basic ADL has about 12% higher localization accuracy and about 10% lower message transmission cost than DRLS. In addition, the localization accuracy of ADL with REP is about 30% higher than that of DRLS, even though message transmission cost is increased.
The remainder of the paper is organized as follows: Section 2 presents preliminary study and previous work. Section 3 details our proposed scheme. Section 4 discusses simulation results. Finally, Section 5 concludes the paper.
2. Preliminaries and Related Work
2.1. Assumptions and Definition
The purpose of the proposed scheme is to provide more accurate localization by applying a range-free localization scheme. In the range-free localization scheme, we assume that a sensor network consists of normal nodes and anchor nodes, where the normal nodes do not know their position but the anchor nodes are able to acquire their positions via external positioning device such as GPS. All sensor nodes including the normal node and the anchor node are randomly deployed in a sensor field, and they do not move after the initial deployment. In addition, each sensor node has a unique ID and the same data transmission radius [21].
In the proposed scheme, each normal node estimates its position by obtaining position information from anchor nodes within two-hop distance. An one-hop anchor node is an anchor node located within the data transmission radius r of a normal node. A two-hop anchor node is reachable by a normal node with a two-hop path alone. For an anchor node to be a two-hop anchor, the anchor is located within twice transmission range (

An example of one- and two-hop anchor nodes (
2.2. Related Work
In the range-free localization scheme, a normal node estimates its position using connectivity information between itself and its neighbor nodes. Thus, the scheme requires data transmission instead of additional devices to measure distances or angles between sensor nodes. In Centroid [10], each normal node estimates its position by calculating the average position of the neighbor anchor nodes, after gathering the position information of neighbor anchor nodes. This localization method is very simple but its accuracy becomes very low when there are a few sensor nodes in the field. In addition, its localization accuracy is highly depending on the deploying pattern of anchor nodes.
Convex position estimation (CPE) [11] proposed to relieve the wrong localization issue of the Centroid based on the position of anchor nodes. CPE also uses the connectivity information between sensor nodes, where each normal node assumes an imaginary rectangle, or an estimative rectangle (ER) that is tangent to an overlapped region of transmission radiuses of neighbor anchor nodes. The normal node should be on ER and the center of the rectangle is approximated as the estimated position of the normal node.
Distributed Range-free Localization Scheme (DRLS) [21] extends to use anchor nodes within two-hop distance. The scheme consists of two phases as initial placement (i.e., grid scan) and refinement. In the initial placement phase, the transmission range of each anchor node is virtually considered as a square instead of a circle and a normal node N assumes an ER as a region overlapped by the squares of anchor nodes within one-hop distance from the normal node. The ER calculated by this method covers a larger area than the one of CPE does. To compensate this looseness, the scheme applies a grid scanning so that the ER is divided to small grid-shaped cells. The number of times each cell overlaps with the transmission range of anchor nodes is calculated. The gray cells in Figure 2(a) have the highest value that is the number of nesting and the normal node N should be on these cells. The average position of gray cells,

An example of the position estimation by DRLS: (a) initial position estimation by grid-scan; (b) refinement of initial position.
However, DRLS has some problems. First of all, two-hop flooding of DRLS is based on anchor nodes. Each anchor node exchanges its position information with anchor nodes that are located within two-hop distance and provides all of information to its neighbor normal nodes. Even though normal nodes obtain some position information during the information exchange between anchor nodes, the normal nodes do not use the information. Secondly, localization accuracy can be worse depending on the deployment pattern of sensor nodes in the refinement phase as illustrated in Figure 3.

An example that localization error increases in the refinement of DRLS.

An example of error propagation in DRLS when two anchor nodes are distributed together.
3. Anchor-Node-Based Distributed Localization with Error Correction
This section presents the basic ADL and advances the ADL with error correction to reduce the error propagation in sparse anchor node environments. Figure 5 outlines our proposed scheme, the ADL with ERP. Each normal node obtains an initial estimated position after performing ADL, and then it check whether the position needs to be corrected because of the insufficient anchors within two-hop, that is, the node is in sparse anchor area. If yes, each node estimates the final position by hop progress, otherwise, the initial position becomes a final value.

Outline of proposed localization scheme.
3.1. Basic ADL
The Basic ADL consists of three steps: anchor node selection, ER construction, and distributed grid scan. We introduce the steps and the limitation of ADL in sparse anchor node environments.
3.1.1. Anchor Node Selection
In the anchor node selection step, two-hop flooding is used for normal nodes to obtain the information of anchor nodes within two-hop distance. Two-hop flooding is started from each anchor node, and each anchor node broadcasts its ID and position information to its neighbor sensor nodes. All normal nodes that receive the information broadcasted decide the anchor nodes of the information obtained as their one-hop anchor nodes. Then, the normal nodes that have the information of one-hop anchor nodes broadcast the information of their one-hop anchor nodes to its neighbor normal nodes. The normal nodes that receive the information of the one-hop anchor nodes from their neighbor sensor nodes consider the anchor nodes of the information obtained as two-hop anchor nodes.
3.1.2. ER Construction
A normal node can be located in a rectangle with thick lines of Figure 6(a). However, it is very difficult to calculate this region, since the region is presented by the subsumption relationship between circles. Therefore, an approximate region termed ER is determined by rectangles that are tangential to the transmission radius of each anchor node, to find this region with lower computational cost. Rectangles, that are tangential to the circles whose centers are the positions of one-hop anchor nodes and radiuses are the transmission radius of sensor nodes, are formed to create ER. In addition, rectangles that are tangential to the circles whose centers are the positions of two-hop anchor nodes and radiuses are the two times of transmission radius, are made. Subsequently, the overlapped region of all rectangles is selected as ER. Figure 6(a) shows an example to form an ER as the overlapped region of three rectangles.
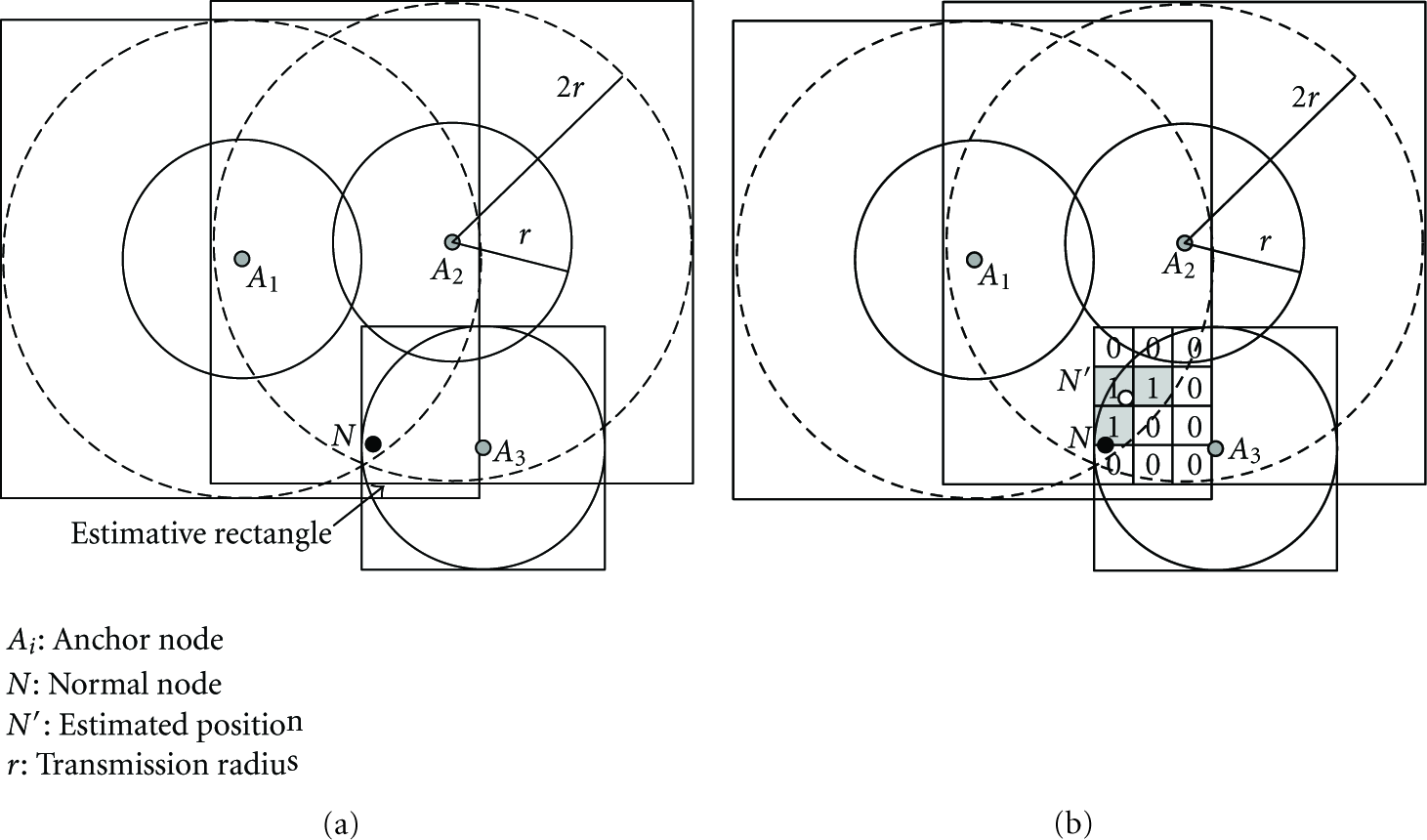
An example of ER construction and grid scan: (a) ER construction; (b) grid Scan.
3.1.3. Distributed Grid Scan
The ER calculated by a normal node includes a region that is larger than the region in which the normal node can actually exist. Accordingly, the localization accuracy can be enhanced by excluding the region where a normal node cannot actually exist from the ER using the grid scan algorithm. After dividing the ER into a set of grid cells, the normal node scans each cell to decide if the cell region should be excluded as shown in Figure 6(b). When the data transmission radius is r, the length of the edge on each cell is
In this paper, the scanning method is applied differently to one- and two-hop anchor nodes. If the normal node has two-hop anchor nodes, the values of cells, that are located within the data transmission radius r of each two-hop anchor node or outside a circle of radius
Since sensor nodes are deployed in the sensor field randomly, there can be normal nodes without any information of anchor nodes. Such normal nodes wait until the neighbor normal nodes estimate and broadcast their position. Then, they estimate their position by the information from neighbor normal nodes. For the estimation by neighbor normal nodes, all normal nodes that obtain their position, broadcast their position information and their one-hop anchor nodes. The normal nodes, that do not have any position information of an anchor node, receive the information of neighbor normal nodes and mark one-hop anchor nodes of the neighbor normal nodes as two-hop anchor nodes. They then perform the same ER construction and distributed grid scan as just explained steps.
3.2. Reducing Error Propagation (REP)
The REP handles only the error propagation by neighbor positions with low precision (e.g., one case that two anchor nodes are located together, thus error propagation would be enlarged as shown Figure 4, or the other case by insufficient anchor nodes within two-hop). Through hop progress calculation and repositioning, REP corrects the position information of normal nodes by rotating the estimated positions centering on anchor nodes. Lastly in this subsection, we explain about decision method for whether to apply REP.
3.2.1. Hop Progress Calculation
To reduce error propagation, other information is necessary for adjusting position information. REP uses the information of anchor nodes that is multihop away from normal nodes. Normal nodes can obtain the information of anchor nodes multihop away when other normal nodes finishing to estimate the initial position and broadcasting their position to their neighbor normal nodes. When sending information of themselves to their neighbor sensor nodes after completing to estimate their initial position, normal nodes that have neighbor anchor nodes send not only their estimated position information but also the position information of an one-hop anchor node and the distance between the normal node and the one-hop anchor node. The anchor node information obtained first is used as the center of the rotation. Moreover, the center of the rotation of each normal node that does not have any neighbor anchor nodes is fixed for the center of the rotation of the neighbor normal node. The distance between the normal node and the center of the rotation is determined by hop progress (i.e., an estimated hop distance using probability based on the density of sensor nodes) [24]. The density of normal nodes means the average number of sensor nodes in the transmission radius of a sensor node. Hop progress can be derived from (1) [24, 25]. In (1),

Each normal node estimates the distance between itself and the center of the rotation using hop progress. Then, the normal node broadcasts the position information of the center of the rotation and hop progress to the position for neighbor normal nodes that do not have any information of anchor nodes. This broadcast can be efficient by adding the information of the center of the rotation to the broadcast packet after the grid-scan phase. Through this procedure, all normal nodes have position information of 1~3 anchor nodes and hop progress to the anchor nodes as well as their initial position.
3.2.2. Repositioning
Each normal node that has the position information of three anchor nodes and hop progress to the anchor nodes corrects its initial position using its information obtained. Each normal node calculates two cross-points of two circles whose center point is the center of the rotation and radius is the hop progresses of two anchor nodes. These two cross-points are regarded as the position in which the normal node can be located. However, since the hop progresses are based on the probability, the accuracy of these two cross-points are low. Thus, these two points are used not to correct the initial position directly, but to decide the direction of the rotation. The direction of the rotation is decided as a cross-point of two circles that is nearer by the third anchor node that is not used to make two circles. The reason of the selection between two cross-points is that the cross-point far from the third anchor node cannot receive the information of the third anchor node.
To correct the initial position of a normal node by rotation, the angle of the rotation is necessary. As knowing the initial position and the center and the direction of the rotation, the normal node can obtain the angle of the rotation. Figure 7 shows an example of the center and the angle of the rotation, and the angle of the rotation can be obtained by (2):


Deciding the direction of the rotation with the information of three anchor nodes.
In (2),

Then, the coordinate of

In Figure 8,

Amending the position with the initial estimated position and the direction.
3.2.3. Decision for Applying REP
REP does not always reduce the estimation error. Even though REP is applied to amend the initial estimated positions of normal nodes, the error of the localization can be increased when the initial estimated positions are relatively correct. Therefore, whether to apply REP is decided for more accurate localization. Each normal node compares the variations of estimated positions before and after applying REP. The variation of the estimated position means the degree of error. The bigger the region that a normal node can be located in is, the bigger the variation is. When the variation of estimate position after applying REP is smaller than that before applying REP, REP is applied to the initial estimated position. On the contrary, the initial estimated position is decided as the final estimated position when the variation of estimate position after applying REP is bigger than that before applying REP. Generally, normal nodes that are close to anchor nodes have low variance for the estimated position, since the degree of error propagation is relatively small when normal nodes that are close to anchor nodes estimate their initial position.
4. Performance Evaluation
This section handles the performance results of ADL and ADL with REP. To show the degree of performance improvement, ADL and ADL with REP are compared to DRLS, a previous range-free localization scheme. The earlier part of this section presents the simulation environment, and the metrics and parameters of performance evaluation. The later part of this section presents the localization accuracy and message transmission cost of DRLS, ADL, and ADL with REP.
4.1. Methodology
The simulator in this section is realized using JAVA. Data transmission radiuses of all sensor nodes are same as r in the simulation of ADL and ADL with REP. The unit disk model [26] is used to transmit data. That is, a sensor node transmits data successfully to its neighbor sensor nodes that are located within r. The same sensor nodes are deployed randomly on the sensor field whose size is
The metrics for the performance evaluation are localization accuracy, mean squared error (MSE), and message transmission cost.
Localization accuracy. Localization accuracy is defined as the average of the Euclidean distance between the real positions and the estimated positions of all normal nodes. The data transmission radius r is the basic unit of localization accuracy. Localization accuracy denotes how accurately normal nodes estimate their positions. Mean squared error (MSE). MSE for the estimated position of normal nodes denotes the degree of variance of the estimated position of normal nodes. Message transmission cost. Message transmission cost is the number of messages used for normal nodes to obtain the information of anchor nodes.
The parameters for the simulation are the density of sensor nodes and the ratio of anchor nodes. The density of the sensor nodes is diversified by the change of the number of sensor nodes, and the number of anchor nodes is changed for the density of sensor nodes to be varied over the entire sensor field. Since the ratio of the anchor nodes is controlled by the fixed number of sensor nodes deployed in the sensor field, the number of normal nodes is decreased if the number of anchor nodes is increased.
4.2. Average Error and Mean Squared Error with Different Anchor Ratio
This section analyzes the localization accuracy and MSE of ADL and ADL with REP versus the ratio of anchor nodes. The data transmission radius of each sensor node is r. The simulation is performed against various numbers of sensor nodes, such as 200, 400, 600, and 800 in the sensor field whose size is
Figure 9 shows the mean error of the estimated position of DRLS, ADL, and ADL with REP in accordance with the variety of the ratio of anchor nodes. Localization accuracy of ADL with REP is the highest, and that of DRLS is the least, since ADL increases the localization accuracy by estimating the position of normal nodes without the vector-based refinement of DRLS. ADL with REP amends the initial estimated position of normal nodes in ADL by applying REP. The lower the ratio of anchor nodes is, the fewer the amount of the position information of anchor nodes is; therefore, localization accuracy is decreased. When the number of sensor nodes is low, localization accuracy is relatively low due to the hole problem. Moreover, when the number of the sensor nodes is high, localization accuracy is increased due to the increase in the information that a normal node can obtain. When there are 800 sensor nodes, the difference of localization accuracy between ADL and ADL with REP is little due to the fact that the initial estimated positions are already sufficiently accurate, and the estimation error can be increased by REP. The simulation results show that ADL with REP has a maximum of 18% higher accuracy compared to ADL and a maximum of 30% higher accuracy compared to DRLS, when there are 400 sensor nodes.

Mean error versus anchor ratio: (a) the number of sensors is 200; (b) 400; (c) 600; (d) 800.
Figure 10 shows MSE of DRLS, ADL, and ADL with REP versus the ratio of anchor nodes. Except for the cases with 200 and 800 sensor nodes, ADL with REP has the lowest MSE, and DRLS has the highest MSE since ADL with REP has the least variance of the estimated position by reducing error propagation. For 200 sensor nodes, MSE of DRLS is the lowest when the ratio of the anchor nodes is low, since the number of normal and anchor nodes is small and thus each normal node cannot receive the sufficient position information. When there are 800 sensor nodes, the MSE of ADL of REP is high, since the normal nodes, whose positions are already accurate, amend their positions by REP, so that the position estimation error is increased. The simulation results show that ADL with REP has a maximum of 7% lower MSE compared to ADL and a maximum of 22% lower MSE compared to DRLS when there are 400 sensor nodes.

MSE versus anchor ratio: (a) the number of sensors is 200; (b) 400; (c) 600; (d) 800.
4.3. Average Error and Mean Squared Error with Different Sensor Node Density
This section analyzes the localization accuracy and MSE with various densities of sensor nodes. The density of sensor nodes is defined as the average number of sensor nodes within the data transmission radius of a sensor node. When the data transmission radius is r, if 200 sensor nodes are deployed in the sensor field whose size is
Figure 11 shows the localization accuracy versus the density of sensor nodes. Mean error of ADL with REP is the smallest and that of DRLS is the largest, since ADL increases localization accuracy by estimating the position of normal nodes without the vector-based refinement of DRLS. ADL with REP amends the initial estimated position of normal nodes in ADL by applying REP. When the ratio of anchor nodes is 20% and the density of sensor nodes is 4, mean error of ADL is lower than that of ADL with REP since the number of both normal nodes and anchor nodes is small and thus accurate position estimation is impossible. The simulation results show that ADL with REP has a maximum of 13% higher accuracy compared to ADL and a maximum of 25% higher accuracy compared to DRLS when the density of anchor nodes is 10%.

Mean error versus node density: (a) anchor ratio is 5%; (b) 10%; (c) 15%; (d) 20%.
Figure 12 shows the MSE versus the various densities of sensor nodes. Due to the fact that more accurate position estimation is possible with many sensor nodes, the higher the density of sensor nodes is, the lower the MSE is. When the density of sensor nodes is low, MSE of DRLS is the lowest since normal nodes cannot receive sufficient position information from the small number of normal and anchor nodes. When the ratio of anchor nodes is 20%, MSE of ADL is lower than that of ADL with REP, since normal nodes whose initial estimated positions are sufficiently accurate from many anchor nodes amend their positions by REP so that MSE is increased. When the ratio of anchor nodes is 10%, the simulation results show that ADL with REP has a maximum of 8% lower MSE compared to ADL, and a maximum of 28% lower MSE compared to DRLS with an environment whose node density exceeds 12.
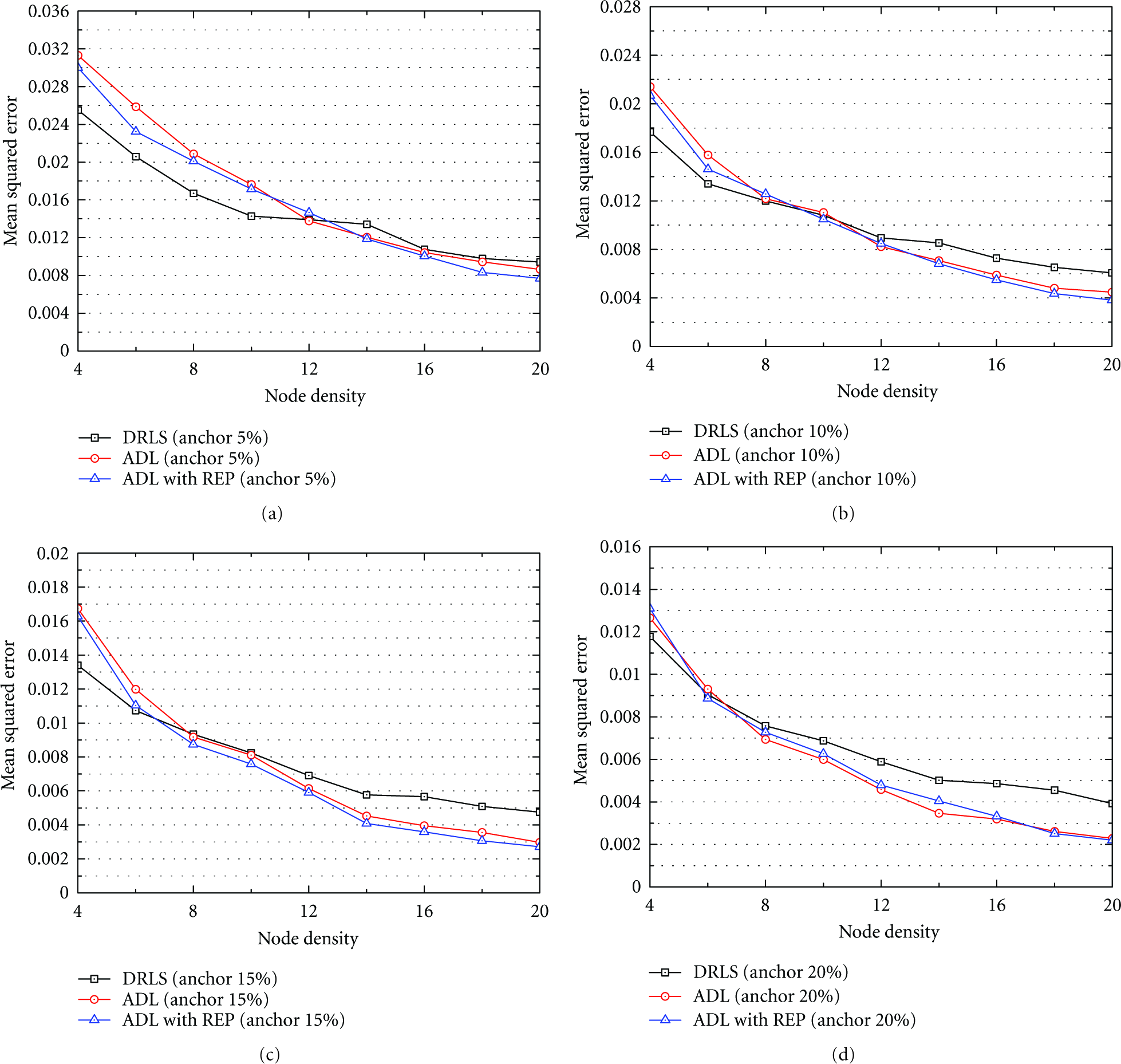
MSE versus node density: (a) anchor ratio is 5%; (b) 10%; (c) 15%; (d) 20%.
4.4. Message Transmission Cost
This section analyzes the message transmission cost for position estimation by ADL and ADL with REP. This cost is defined as the number of messages exchanged. The simulation environment is changed with the ratio of anchor nodes from 5 to 30% and the density of sensor nodes from 4 to 20.
Figure 13 shows the message transmission cost against various ratios of anchor nodes. Due to the fact that two-hop flooding is performed based on the anchor nodes in DRLS and based on normal nodes in ADL, the message transmission cost of ADL is the lowest. That is, each anchor node in DRLS exchanges its position information with anchor nodes that are located within two-hop distance, and provides all of information to its neighbor normal nodes. Even though normal nodes in DRLS obtain some position information during the information exchange between anchor nodes, anchor nodes after finishing the two-hop flooding transmit the information to normal nodes. Due to such unnecessary transmissions of DRLS, ADL outperforms DRLS a little from the viewpoint of transmission cost. The higher data transmission cost of ADL with REP is due to each normal node broadcasting the information of their center of the rotation additionally after applying REP. Generally, DRLS transmits more messages as many as the number of anchor nodes than ADL, and ADL with REP transmits more messages as many as the number of normal nodes than ADL. The simulation results show that the message transmission cost of ADL with REP is a maximum of 45% higher than ADL when the ratio of anchor nodes is low, and a maximum of 35% higher than DRLS when the number of sensor nodes is 400 and the ratio of anchor node is 10%.

Number of messages versus anchor ratio: (a) the number of sensors is 200; (b) 400; (c) 600; (d) 800.
Figure 14 shows the message transmission cost against various densities of sensor nodes. Like Figure 13, the message transmission cost of ADL is the lowest and that of ADL with REP is the highest since two-hop flooding of ADL is more efficient than that of DRLS. ADL with REP makes normal nodes to amend their initial estimated positions by additional message transmissions. When the ratio of anchor nodes is low such as 5%, in ADL with REP, normal nodes transmit their center of the rotation to their neighbor normal nodes additionally after applying REP, so there is a big gap between transmission costs of ADL and ADL with REP. The simulation results show that the message transmission cost of ADL with REP is a maximum of 45% higher than ADL and that of ADL is a maximum of 7% lower than DRLS when the ratio of anchor nodes is 10% and the density of sensor nodes is 10.

Number of messages versus node density: (a) anchor ratio is 5%; (b) 10%; (c) 15%; (d) 20%.
5. Conclusions
The paper has proposed ADL that is a distributed localization scheme to increase the position accuracy and reduce the message transmission cost, and ADL with REP that is a scheme to reduce the error propagation. In ADL, each normal node assumes an ER using anchor nodes within its transmission radius that is obtained by two-hop flooding, and initial position is estimated by grid scanning in the ER. However, since the initial estimated positions are affected by the error propagation in the environment with the small number of anchor nodes, initial estimated positions should be amended. The ADL with REP makes normal nodes to estimate their position more accurately by rotating the initial estimated positions whose centers are anchor nodes.
The simulation results with the various ratios of anchor nodes and the various densities of sensor nodes showed that localization accuracy of ADL is 12% higher and the data transmission cost is 10% lower than DRLS. In addition, localization accuracy of ADL with REP is 30% higher, but the data transmission cost is 35% higher than DRLS. Due to the fact that the data transmission cost of ADL with REP is high, we should decide a scheme among ADL and ADL with REP according to the application. We will enhance the proposed localization in order that the case whereby the amended position is more inaccurate than the initial estimated position by applying REP is avoided by the statistical analysis.
Footnotes
Acknowledgment
This research was supported in part by MKE and MEST, Korean government, under ITRC NIPA-2012-(H0301-12-3001), NGICDP(2011-0020517) and PRCP(2011-0018397) through NRF, respectively.