
Abstract
Cyber-Physical System (CPS) is an integration of distributed sensor networks with computational devices. CPS claims many promising applications, such as traffic observation, battlefield surveillance, and sensor-network-based monitoring. One important topic in CPS research is about the atypical event analysis, that is, retrieving the events from massive sensor data and analyzing them with spatial, temporal, and other multidimensional information. Many traditional methods are not feasible for such analysis since they cannot describe the complex atypical events. In this paper, we propose a novel model of atypical cluster to effectively represent such events and efficiently retrieve them from massive data. The basic cluster is designed to summarize an individual event, and the macrocluster is used to integrate the information from multiple events. To facilitate scalable, flexible, and online analysis, the atypical cube is constructed, and a guided clustering algorithm is proposed to retrieve significant clusters in an efficient manner. We conduct experiments on real sensor datasets with the size of more than 50 GB; the results show that the proposed method can provide more accurate information with only 15% to 20% time cost of the baselines.
1. Introduction
The Cyber-Physical System (CPS) has been a focused research theme recently due to its wide applications in the areas of traffic monitoring, battlefield surveillance, and sensor-network-based monitoring [1–6]. It is placed on the top of the priority list for federal research investment in the fiscal year report of US president's council of advisors on science and technology [7].
A CPS consists of a large number of sensors and collects huge amount of data with the information of sensor locations, time, weather, temperature, and so on. In some cases, the sensors occasionally report unusual or abnormal readings (i.e., atypical data); such data may imply fundamental changes of the monitored objects and possess high domain significance. To benefit the system's performance and user's decision making, it is important to analyze the atypical data with spatial, temporal, and other multidimensional information in an integrated manner. A motivation example is shown as follows.
Example 1.
The highway traffic monitoring system is a typical CPS application. With the sensor devices installed on road networks, the monitoring system watches the traffic flow of major U.S highways in 24 hours × 7 days and acquires huge volumes of data. In this scenario, one important type of atypical events is the traffic congestion. Some frequent questions asked by the officers of transportation department are (1) where do the traffic congestions usually happen in the city?, (2) when and how do they start? (3) and on which road segment (or time period) is the congestion most serious?
In such queries, the users are not satisfied merely on a database query returned with thousands of records. They demand summarized and analytical information, integrated in the unit of atypical event. The granularity of the results should also be flexible according to the user's requirements: some officers may be only concerned with the information in recent days, whereas others are more interested in the monthly or even yearly report. However, it is hard to support such multidimensional analysis of atypical events in CPS data, partly due to following difficulties.
Massive Data. A typical CPS includes hundreds of sensors, and each sensor generates data records in every few minutes. The CPS database usually contains gigabytes, even terabytes of data records. The management system is required to process the huge data with high efficiency. Complex Event. The atypical event is a dynamic process influencing multiple spatial regions. Those spatial regions expand or shrink as time passes by, they may even combine with others or split into smaller ones. Hence the atypical events do not have fixed spatial boundaries. They are difficult to be represented by traditional models. Information Integration. In many applications, the users demand integrated information for analytical purposes. For example, a transportation officer may need a monthly summary of the congestions in the city. Then the system has to measure the similarity among daily atypical events and integrate the similar ones to provide a general picture. Retrieving Effectiveness. A large-scale analytical query may contain the data from hundreds of atypical events; however, not all of them are interesting to the users. The users may only prefer a few significant results, that is, the most serious events that influence large area and last for a long time. The system should distinguish such significant events in the retrieving process and emphasize them from the majority of trivial ones.
In this study, we introduce the concept of atypical connection to discover the atypical events and summarize them as atypical clusters. The atypical cluster is a model describing multidimensional features of the atypical event. They can be efficiently integrated in a hierarchical framework to form macroclusters for large-scale analytical queries. To retrieve significant macroclusters, the system employs a guided clustering algorithm to filter out the trivial results and meanwhile guarantees the accuracy of significant clusters. The data structure of atypical cube, which is a forest of hierarchical clustering trees, is constructed to facilitate scalable and feasible analysis. The proposed methods are evaluated on gigabyte-scale datasets from real applications; our approaches can provide more detailed and accurate results with only 15% to 20% time cost of the baselines.
This paper substantially extends the ICDE 2012 conference version [8], in the following ways: (1) introducing the concepts of atypical cube as an integrated model for multidimensional sensor data analysis in CPS; (2) proposing the techniques to process OLAP queries based on the atypical cube, including the algorithms for both the large-scale and small-scale (i.e., drill-through) queries; (3) discussing the issues of extending atypical cube to other dimensions and introducing a case study in traffic application; (4) carrying out the time complexity analysis of proposed algorithms; (5) providing complete formal proofs for all the properties and propositions; (6) covering related work in more details and including recent ones; (7) introducing the bottom-up styled cube in more details as the background knowledge; (8) expanding the performance studies on real datasets.
The rest of the paper is organized as follows. Section 2 introduces the problem formulation and system framework; Section 3 proposes the models of atypical clusters and the algorithms to construct atypical cube; Section 4 introduces the techniques to efficiently retrieve significant clusters for OLAP queries; Section 5 evaluates the performances of proposed methods on real datasets; Section 6 discusses the extensions of proposed techniques; Section 7 makes a survey of the related work, and in Section 8 we make the conclusion.
2. Backgrounds and Preliminaries
2.1. Problem Formulation
The cyber-physical systems monitor real world by sensor networks. In most cases, a sensor reports records with normal readings. If an atypical event happens (such as a congestion is detected in traffic system), the sensor will send out atypical records. The detailed atypical criteria are different according to the application scenarios and environments (e.g., the highway types and speed limits); many state-of-the-art methods have been proposed to select the trustworthy atypical records in traffic, battlefield, and other CPS data [3, 9, 10]. Since the main theme of this study is on multidimensional analysis of atypical event, we assume that the atypical criteria are given and clean atypical records can be retrieved by CPS. In fact, some of such datasets are available to public [11].
The atypical records are represented in the format of (s, t,
The atypical events are dynamic processes including many atypical records. In the traffic application, the atypical event of a congestion usually starts from a single street, which can only be detected by one or few sensors. Then the congestion swiftly expands along the street and influences nearby sensors. A serious congestion usually lasts for a few hours and covers hundreds of sensors when reaching the full size. As time passes by, it shrinks slowly, eventually reduces the coverage, and finally disappears.
By observing the phenomenon of congestion, we find that those records in an atypical event are spatially close and timely relevant. Hence we introduce the following definitions.
Definition 2 (Direct Atypical Connected).
Let
Definition 3 (Atypical Connected).
Let
Based on the above concepts, we formally define the atypical event as follows.
Definition 4 (Atypical Event).
Let R be the set of atypical records. Atypical Event E is a subset of R satisfying the following conditions: (1) for all
Example 5.
Table 1 shows three atypical events. Each event contains hundreds of atypical records; part of their records are listed in the second column.
Example: atypical events.

Our task is to find out atypical events and integrate them in a data structure to support online analytical processing (OLAP) queries with multidimensional information. The data cube is a subject-oriented and integrated structure to support OLAP queries [12]. It organizes the data with multiple dimensions as a lattice of cells. In the cube, every cell corresponds to a degree of data summarization and stores the concrete measures for different queries. For example, a cell may store the atypical events as (Downtown LA, 8 am–9 am Oct. 10th:
Property 1.
The atypical event is a holistic measure.
Proof.
A measure is holistic if there is no constant upper bound on the storage size needed to describe a subaggregation [13].
Since the atypical events contain all the original records, although their number can be bounded, the sizes are still unbounded. Let us consider the worst case, in which there is a heavy snow and the traffic of the entire region is tied up through the whole day. In such case, even there is only one event, it includes all the atypical records of the sensor dataset. No constant bound of storage size can be found in this case. Hence the measure of atypical event is holistic.
The atypical event is not feasible for data cubing because a holistic measure is inefficient to aggregate and compute [13]. A more succinct measure is thus required. The key challenge in atypical cube construction is indeed at designing such measure to model the atypical events and developing the corresponding aggregation operations.
Task Specification
Let R be the atypical dataset in CPS; the atypical cubing tasks are (1) finding out the atypical events from R, representing them with a succinct measure and aggregating the measure to construct a data cube; (2) effectively and efficiently processing the OLAP query
2.2. System Framework
Figure 1 shows the overview of our system framework. The system consists of two components: the atypical cube construction module and the OLAP query processing module.
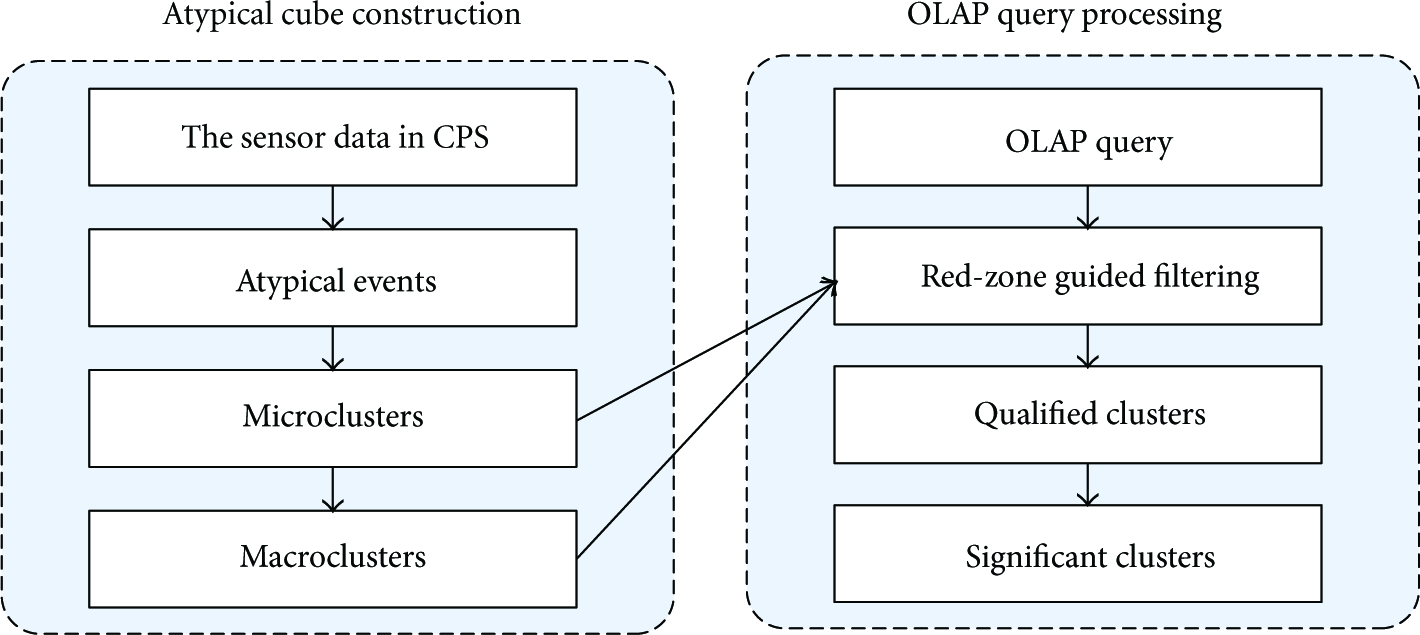
The overview of system framework.
Atypical Cube Construction
This component offline builds up the atypical cube from the sensor data in CPS. The system first retrieves the atypical events from the dataset and then constructs the atypical microcluster to store the features of each individual event. The similarity of micro-clusters is measured based on the retrieved features. The system merges similar micro-clusters as macroclusters to integrate multiple events. The clusters are formed in hierarchical trees to construct the atypical cube, which will be used to help process the OLAP queries.
OLAP Query Processing
This component online processes the OLAP query. The key issue is to efficiently retrieve significant clusters in the query range. The query processing algorithm first determines the possible regions where the significant clusters might be (i.e., red-zones) and then prunes the micro-clusters locating outside those regions. Only the qualified micro-clusters are selected to generate the macroclusters as query results. For the OLAP query in small range, the system utilizes a two-stage query processing technique: first returns an approximate answer in short time and then computes the detailed query results.
We will introduce the cube construction methods in Section 3 and query processing techniques in Section 4. Table 2 lists the notations used throughout this paper.
List of notations.

3. Atypical Cube Construction
3.1. Bottom-up Styled Cube
Traditional methods construct the atypical cube by aggregating severity measures in a bottom-up style. The hierarchies are predefined on temporal, spatial, and other related dimensions, and the severities are then aggregated following such hierarchies. For example, the severity is aggregated by hour, day, month, and year in temporal dimension. In the spatial dimension, the hierarchies are built by partitioning the data with fixed regions, such as zipcode areas, street names [14], highway numbers [15], or the R-trees rectangles [16].
In this study, we employ a common measure of severity to describe the seriousness of atypical data in CPS. The severity function 
Property 2.
The total severity
Proof.
A measure is distributive if it can be derived from the aggregation values of n subsets, and the measure is the same as that derived from the entire data set [13].
Let us partition the dataset in S and T into n subsets, each with 

The distributive measure is efficient to compute [13], and the bottom-up styled approach is fast in both cube construction and query processing. However, the information of total severity is too abstract to answer the queries like “where and how do the traffic congestions start and expand?”
Example 6.
The bottom-up styled cube is constructed by zipcode areas. The regions with high total severity are tagged out as red zones, for example,

Problems of Bottom-up Styled Cube.
The bottom-up styled cube cannot provide details since the numeric measure of total severity is not enough to describe the complex atypical events. In addition, the atypical events may not follow predefined regions. The three major congestions A, B, and C in Figure 2 are partitioned into seven red zones by bottom-up styled cube. It is natural to lead users to illusions that the fragments of A and B congest together in area a. But a careful examination reveals that the highway segments A (freeway 10W) usually congest in the morning rush hours and the segments B (freeway 10E) jam in the evenings. They seldom congest together and should be distinguished from each other.
3.2. Basic Atypical Cluster
In real applications, the users usually cannot provide accurate boundaries to separate atypical events. Instead, the system is required to discover such boundaries automatically and distinguish different atypical events to the users. For this purpose, we propose the concept of basic atypical cluster.
Definition 7 (Basic Atypical Cluster).
Let E be an atypical event with sensor set
Intuitively speaking, the spatial feature is the summary of the atypical event in temporal dimension, and the temporal feature is the summary of the event in spatial dimension.
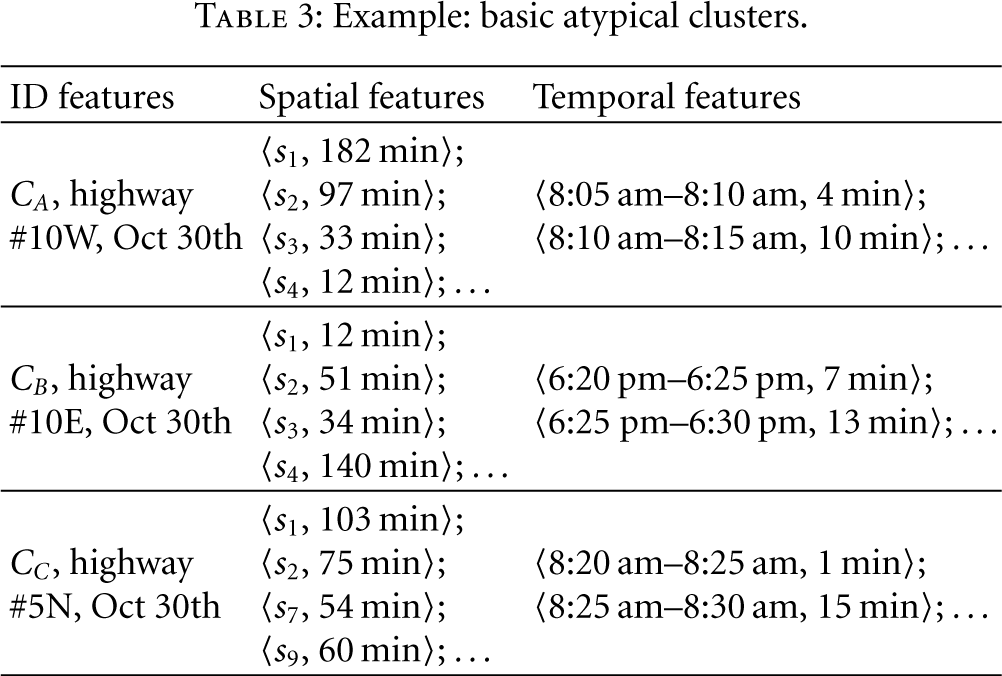
Example 8.
Table 3 shows the basic atypical clusters retrieved from Example 6. The ID feature is a general description of the corresponding atypical event; for example,
Example: basic atypical clusters.
The atypical events are retrieved by a single scan of the dataset, and the basic atypical clusters can be generated simultaneously. Algorithm 1 shows the detailed process.
dataset R
4 group those records to form an atypical event E(S; T);
The basic cluster generation algorithm randomly picks a seed record from the dataset (Line 2) and retrieves all the atypical connected records to it (Line 3). Then the algorithm groups those records as an atypical event (Line 4) and generates the spatial and temporal features of basic cluster (Lines 6–13). Those steps are repeated until all the data are processed.
Proposition 9.
The time complexity of Algorithm 1 is
Proof.
The major cost of Algorithm 1 is on Line 3 to retrieve the atypical connected records. If there is no index on the temporal and spatial dimensions, it costs
3.3. Atypical Cluster Aggregation
The first task of cluster aggregation is to compute the similarities between two atypical clusters. The cluster similarity is measured based on both the spatial and temporal features, as shown in (4). Two clusters are considered similar to each other only when they have atypical records at the same places during the same time periods. Equations (5) and (6) show the calculation of spatial and temporal similarities, where 


Once two micro-clusters are merged, a single macro-cluster is created to represent the result out of this merge (here we use the term micro-cluster to denote the merge input and macro-cluster to denote the merge result). The spatial feature of the macro-cluster is calculated as shown in (7): the system accumulates the severities of common sensors from two micro-clusters and keeps the nonoverlapping ones; so is the temporal feature. A new ID is generated for the macro-cluster:
Property 3.
The spatial and temporal features in atypical clusters are algebraic measures.
Proof.
A measure is algebraic if it can be computed by an algebraic function with m arguments (m is a bounded positive integer), and each of the arguments is distributive [13]. We will prove that the spatial feature is algebraic in the process of integrating n micro-clusters to a macro-cluster by mathematical induction.
(1) The Basis. First we study the case that
Let 
(2) The Inductive Step. Suppose that the statement holds for
The macro-cluster 
Therefore the statement holds for case of integrating n micro-clusters. The spatial feature is algebraic.
From the same steps, it is easy to obtain that the temporal feature is also algebraic.
The algebraic measures are also efficient to compute and aggregate [13]; thus we use atypical clusters as the measure in atypical cube. The detailed micro-cluster merging steps are shown in Algorithm 2. The system accumulates the severity of common sensors in two micro-clusters (Lines 2–6) and copies the nonoverlapping ones (Line 7); the same steps are carried out in temporal features (Lines 9–16).
Property 4.
The operation of merging atypical clusters is mathematically commutative and associative.
Proof.
To prove that the merge operation is mathematically commutative, we have to show that for any
For two clusters 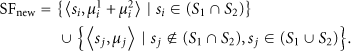
The positions of
To prove that the merge operation is mathematically associative, we have to show that for any
Let us denote the following:
The spatial feature 
Since 
Since 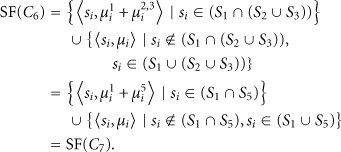
Equation (13) shows that the spatial features are the same for the macroclusters
Property 4 tells us that the order of micro-clusters does not influence the macro-cluster results. Thus we design the aggregation clustering process as Algorithm 3. The algorithm starts by checking each pair of the micro-clusters. If their similarity is larger than the given threshold, a merge operation is called to integrate them (Lines 2–4). This process is irrelevant to the order of micro-clusters. The new cluster is put back to the set, and the old pair is discarded (Lines 5–6). The program stops until no clusters could be merged (Line 9).
threshold
Proposition 10.
Let m be the number of micro-clusters; the time complexity of Algorithm 3 is
Proof.
In the worst case, there are no similar pairs that can be found to be merged together. Then the algorithm needs to check the similarity between every pair and the total calculation times are
Note that the similarity threshold
Example 11.
Table 3 lists three atypical clusters, namely,
The aggregation clustering algorithm takes the micro-clusters from children cells as input and outputs the macroclusters to store as measures in the parent cell. Such macroclusters are also going to be used as new inputs to get even higher-level clusters. In this way a hierarchical clustering tree is built up.
The atypical cube is constructed as a forest of hierarchical clustering trees, where each tree represents an aggregation path in the cube. Figure 3 shows the framework of atypical cube for the case of traffic congestions. Ten basic atypical clusters are stored in the lowest-level cells. The aggregation cells

Example: the framework of atypical cube.
4. OLAP Query Processing
4.1. Processing Large-Scale Queries
In practical applications we do not precompute the entire atypical cube due to storage limits. In most cases only the basic clusters and some low-level micro-clusters are precomputed. With such a partially materialized data structure, the system needs to dynamically integrate the low-level clusters to process OLAP queries in large query range. The online clustering process is similar to the cluster integration algorithm. However there are two problems. (1) The first one is efficiency: the time complexity of cluster aggregation algorithm is quadratic to the number of input clusters. Therefore the system should select only the relevant micro-clusters to reduce the time cost. (2) The second is effectiveness: if the query scale is large, for example, the users want the monthly congestion report of the whole city. There may be a large number of macroclusters in the query range, but only few of them are significant clusters with high severities, while the others are negligible. When constructing atypical cube, the process is offline and the system can store all the clustering results. When processing online queries, the users usually demand the significant clusters being delivered in short time and do not prefer the results mixed with trivial clusters.
Definition 12 (Significant Cluster).
Let
Note that the system measures the cluster significance by a relative threshold
The key challenge for online clustering is to prune the trivial micro-clusters and meanwhile guarantee the accuracy of significant macroclusters. One strategy is beforehand pruning: the system pushes down the prune step to lower levels by only selecting the significant micro-clusters for integration. However this strategy cannot guarantee finding all the significant macroclusters, because a micro-cluster that contributes to a significant macro-cluster may not be significant by itself. If the algorithm prunes all insignificant micro-clusters beforehand, the severity of the macro-cluster will also be reduced and may not be significant anymore.
Example 13.
The micro-clusters of Los Angeles in October 30th are shown in Figure 4(a), and the monthly significant macroclusters A and B are plotted in Figure 4(b). In Figure 4(a), the micro-clusters a, b, j, k, and o are going to be integrated as parts of the significant macroclusters even if they are relatively trivial. The micro-clusters e, h, and i are significant in the scale of one day, but actually they can be pruned since they have no contribution for any significant macroclusters in one month.

Example: problem of beforehand pruning.
Can We Foretell Which Microcluster Will Become a Part of the Significant Macroclusters and Which Will Not? If the system knows such guiding information, it can improve query efficiency and meanwhile guarantee the result's accuracy. The heuristic comes from the bottom-up method: recall that the bottom-up method uses total severity
One may worry that
Property 5.
Let
Proof.
We will prove the statement by contradiction.
Suppose that there is a cluster
Since 
We now have a contradiction with the condition that
Property 5 can be used to help filtering the micro-clusters. The system only needs to integrate the clusters in the regions where the total severities are larger than threshold, that is, the red zones.
Example 14.
In Figure 5, the red zones are tagged out. They are generated by the bottom-up styled cube with a predefined zipcode area hierarchy. The micro-clusters e, g, i, and m can be pruned safely since they are outside the zones; a, b, and d should be kept for clustering since they are in the zones; c, k, f, o, and n are also kept since they intersect with the red zones and may contribute to macroclusters.

Red-zone guided clustering.
Algorithm 4 shows detailed steps of red zone guided online clustering. The system first computes the severity on predefined regions in bottom-up styled cube and retrieves the red zones (Lines 1–4) and then selects out the micro-clusters in red zones (Lines 5–7). The clustering algorithm (Algorithm 1) is called to generate the macroclusters (Line 8). Since the algorithm can only guarantee there are no false negatives (i.e., not missing any significant macroclusters), it is possible to generate some false positives. A check procedure is processed to prune the clusters without enough severity at the last step (Lines 9–11).
children cells, bottom-up style cube threshold
The major cost of Algorithm 4 is at Line 8 to call the clustering algorithm. In the worst case, no cluster could be filtered out, and the algorithm's time complexity is still quadratic to the number of micro-clusters. However, in our experiments, about 80% micro-clusters could be filtered out with reasonable
4.2. Drill-Through Query Processing
In some rare cases, the users require detailed results in a very narrow range, such as “what is the congestion details from 8:45 am to 9 am of the highway #101 near downtown?” The system needs to decompose basic atypical clusters to answer them. Such queries actually drill through the atypical cube to the original sensor dataset.
We propose a two-stage algorithm to process this kind of queries. The system first returns the related basic atypical clusters as an approximate result and then decomposes them for precise answers. The details are shown in Algorithm 5 as a two-stage process: in the first stage, the system retrieves all related micro-clusters, directly integrates them and returns the macroclusters as approximate result (Lines 1–5); then it drills through to the sensor dataset and refines those micro-clusters in the second stage (Lines 6–12). The precise results are computed and returned later.
Since the query range is narrow, the size of the
5. Performance Evaluation
Since the idea of this study is motivated by practical application problems, we use real world datasets to evaluate the proposed approaches. Twelve datasets are collected from the PeMS traffic monitoring system [11]; each stores one-month traffic data in the areas of Los Angeles and Ventura. The data are collected from over 4,000 sensors on 38 highways. There are more than 1.1 million records for a single day and totally 428 million records for the whole year. The total size of all the datasets is over 54 GB.
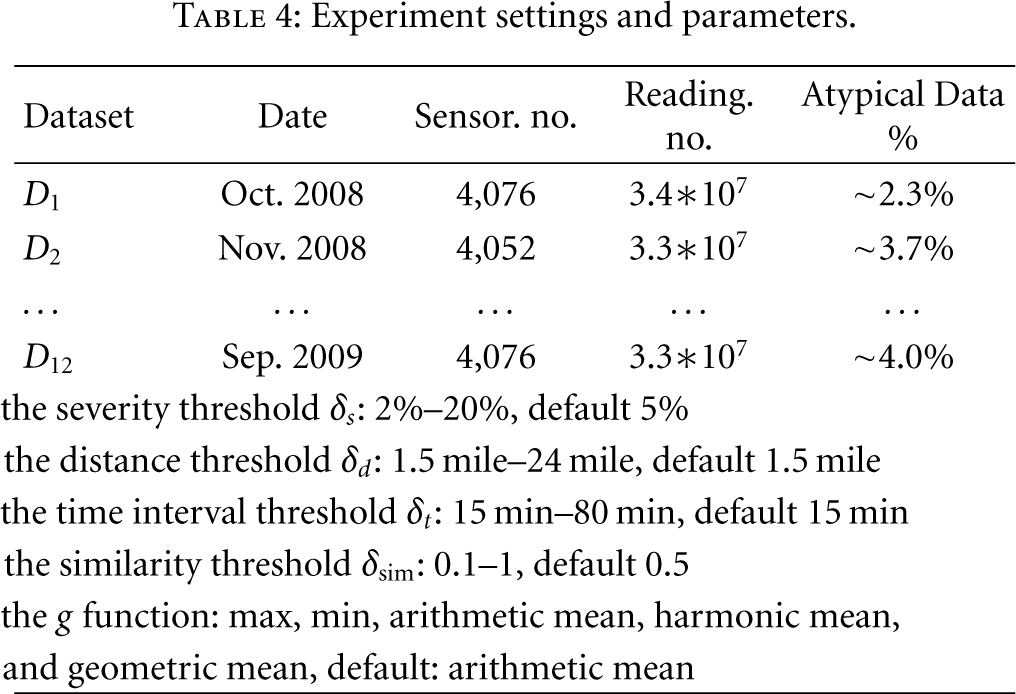
The experiments are conducted on a PC with an Intel 2200 Dual CPU at 2.20 G Hz and 2.19 G Hz. The RAM is 1.98 GB, and the operating system is Windows XP SP2. All the algorithms are implemented in Java on Eclipse 3.3.1 platform with JDK 1.5.0. The detailed experimental settings and parameters are listed in Table 4.
Experiment settings and parameters.
5.1. Evaluations of Cube Construction
In this subsection we evaluate the algorithms of offline cube construction. CubeView [14] is a bottom-up method on traffic data. The original CubeView algorithm aggregates all the traffic records with predefined spatial and temporal hierarchies. In this experiment, the system carries out a preprocessing step to select atypical records and adjusts CubeView to construct the cube only on the atypical data. We first construct the cubes on a single dataset, then gradually increase the number of datasets, until all the twelve datasets are used in the experiment. Figure 6 shows the time costs of the original Cubeview (OC), modified CubeView (MC), the preprocessing step (PR), and our atypical-cluster-based method (AC). The x-axis is the number of datasets used in the experiment, and y-axis is the time cost of the algorithms. MC and AC are an order of magnitude faster than OC because they are constructed on the atypical data, which are only 2% to 5% of the original datasets. The time cost of PR is close to OC since both of them have to scan the original datasets with huge I/O overhead. However the preprocessing step only needs to carry out once for constructing different cubes.
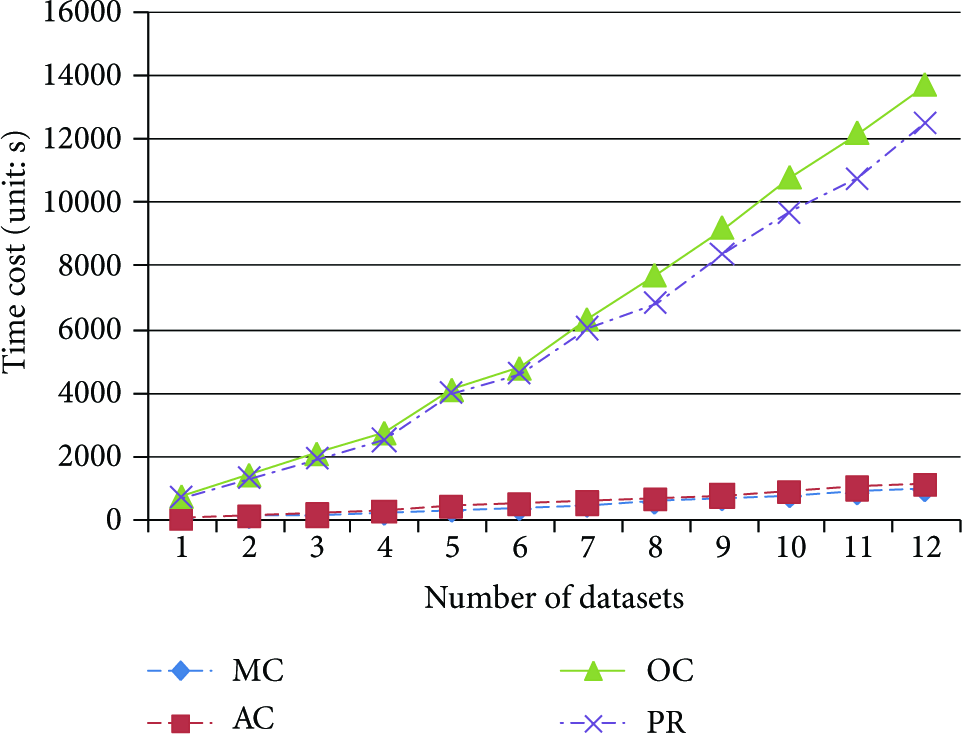
Efficiency: construction time cost versus no. of datasets.
Figure 7 shows the constructed cube size of original Cubeview (OC), modified CubeView (MC), and atypical cluster method (AC). The size of corresponding atypical events (AEs) is also recorded in the figure. MC achieves the best compression effects since it only records the numeric measure of total severity, but it cannot describe the complex atypical events. AC stores all the critical information about spatial and temporal features of AE, but only costs 0.5% to 1% space of AE.

Size: constructed cube size versus no. of datasets.
Figure 8(a) records the constructed cube size of the three methods on six different datasets. In general, the construction overhead and storage size of OC are acceptable since the cube is built offline. However, the results in Figure 8(b) show that OC cannot be used to process queries about atypical events. The average speeds of OC on all the datasets are all around 65 mph, which are close to the speed limit of California highway. The information is hence not interesting to the users since the atypical events are dwarfed by the majorities of normal data.

Results: cube size and avg. speed.
5.2. Comparisons in OLAP Query Processing
In this subsection we evaluate the performances of OLAP query processing. Three query processing strategies are compared: (1) integrating all the micro-clusters (All); (2) pruning the insignificant clusters beforehand (Pru); (3) the red-zone guided clustering (Gui).
In the experiments, the system only precomputes the micro-clusters of each day. The analytical query's spatial range is fixed as Los Angeles, and time range gradually increases from one week (requiring to aggregate the micro-clusters of 7 days) to three months (84 days). Figures 9(a) and 9(b) record the average time and I/O costs (measured by the number of input micro-clusters). Although Gui has extra cost to compute the redzones, the time efficiency is still close to Pru. From the figure one can see clearly that Gui and Pru are much more efficient than All. Gui's time cost is only about 15%–20% of All.

Efficiency: query time and I/O costs.
To evaluate the effectiveness of query results, we compute the precision and recall of the significant clusters. Since the integrating-all method prunes no clusters, its results contain all the significant clusters. The system checks the results of All and retrieves the true significant clusters as the ground truth. The measures of precision and recall are then computed as follows.
Precision
The precision is calculated as the proportion of significant clusters in the returned query results.
Recall
The recall is the proportion of retrieved significant clusters over the ground truth.
The system increases the query time range from 7 days to 84 days and records the precision and recall of three methods in Figure 10. For all the methods, their precision decreases with larger query range, because the cluster severity does not grow linearly with respect to the query range, and the significant clusters are inevitably fewer in larger query range with fixed severity threshold. In the experiment, Pru has the highest precision, because it prunes all the trivial micro-clusters and generates fewer macroclusters (Figure 10(a)). However, as shown in Figure 10(b), Pru cannot guarantee to find all the significant clusters. Its recall might even be lower than 50% in some cases. Therefore, even if Pru is the winner on efficiency and precision, it is not feasible to process analytical query since the significant clusters may be missed in the results.
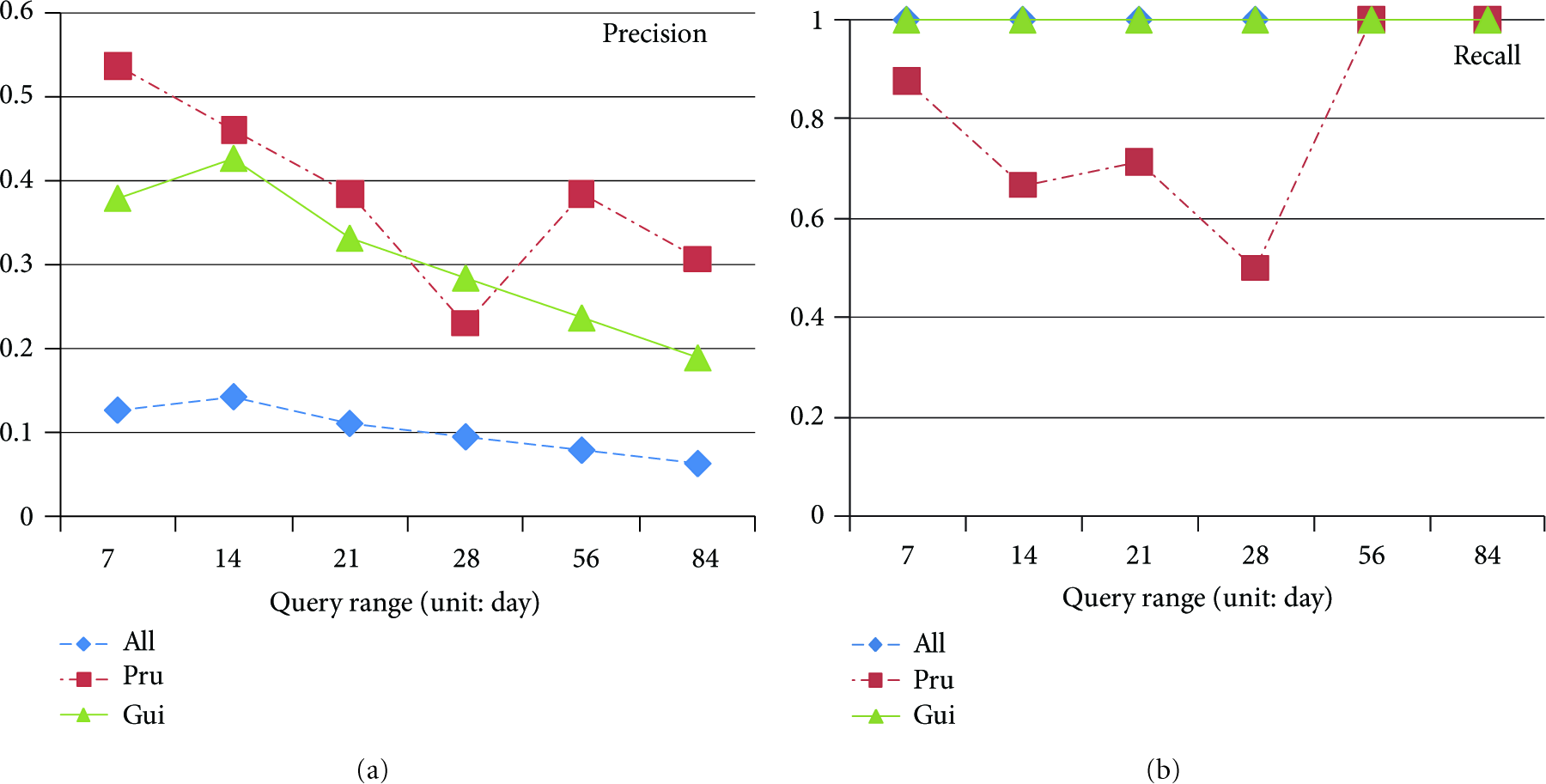
Effectiveness: precision and recall with respect to query range.
In the next experiment, we fix the query time range as 14 days and evaluate the influence of severity threshold

Effectiveness: precision and recall with respect to
The precision of Gui in the above experiments is not high; however this measure can be easily improved. The system can efficiently filter out the false positives and guarantee 100% precision by checking the macro-cluster's total severity. Gui has such a procedure (Lines 5–7 in Algorithm 4). This procedure is turned off in the experiments for a fair play.
5.3. Parameter Tuning for Atypical Cluster Method
In the next experiment, we study the influence of the parameters in the atypical-cluster-based method, including time interval threshold

Size: no. of clusters versus
We also study the influences of similarity threshold

Average severity of significant cluster versus
From Figures 12 and 13, we can also learn that the result of significant cluster is robust to the time interval threshold
5.4. Drill-Through Query Processing
At last we test the performances of drill-through query processing methods. In this experiment, the spatial range is no longer fixed to Los Angeles; instead it is set to a very narrow range of random road segments. In this way, the system has to drill through the basic atypical clusters to the original sensor dataset.
Since the algorithm is a two-stage process, we evaluate both stages separately in the experiments. We also compare the drill-through stage with indexes and the one without. Figure 14 shows their time costs w.r.t. the number of involved cells. Note that the axis of query time is in logarithmic scale. It is clear that the first stage of approximate query is much faster than the second stage of precise query. In drill-through queries, the I/O overhead is the dominant factor. The stage 1 of approximate query does not access to the detailed sensor data, so it is very efficient, and the results are returned to the users in less than ten seconds.
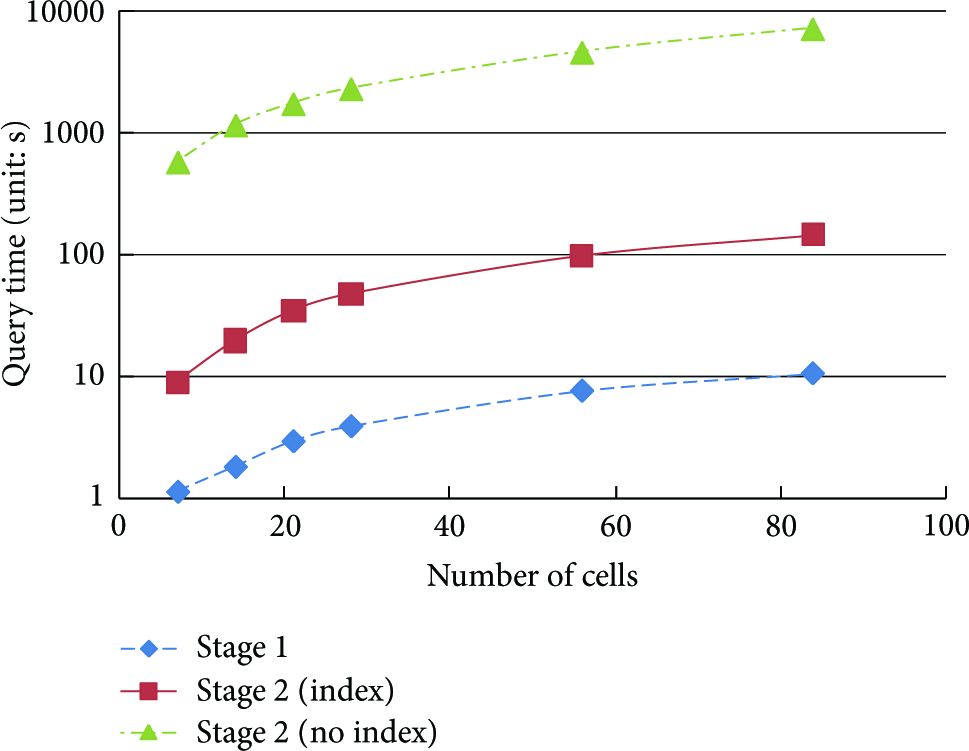
Efficiency: different stages of drill-through queries.
6. Extensions and Discussions
In this study, we illustrate the atypical cluster techniques mainly on spatial-temporal dimensions and carry out the performance evaluation on the sensor data in traffic system, because (1) the spatial and temporal dimensions are actually the most basic and important dimensions in many CPS applications, and the user's queries are usually related to such two dimensions; (2) large volume of sensor data in traffic applications is open to public; (3) the atypical events of traffic (i.e., the congestions) are actually more complex than in many other domains. Apart from spatial and temporal dimensions, the users may require to analyze the data on other domain specific dimensions. For example, in the traffic system, the transportation officer may want to check the congestions related to bad weather or the accident reports. The proposed framework can be easily extended to support the analysis on such context dimensions. The weather dimension can be joined with temporal dimension with the date, and the accident dimension can be joined with temporal and spatial dimensions by the accident time and location. Figure 15 shows a snowflake schema of the atypical cube with dimensions of temporal, spatial, weather, accident, and so on.

Atypical cube schema for congestions.
By joining those dimension tables, the system can support OLAP queries on more dimensions. For instance, if users want congestion reports related to traffic accidents, the system will first select out the region
In the cube construction component, the major time cost is on the preprocessing step, since the system has to scan the original datasets with huge I/O overhead. However, the preprocessing step only needs to carry out once for constructing different cubes. The massive data can also be pre-processed by the sensors themselves in a distributed manner [17]. In such a way, the amount of data and events can be reduced. Due to the hardware limitations, the sensors are likely to report some error messages and untrustworthy atypical data may be generated then. Since the main theme of this study is on multidimensional analysis of atypical data, we assume that the clean and trustworthy records can be retrieved by CPS. In our previous studies, we have proposed several methods to retrieve the atypical events from untrustworthy sensors and carry out trustworthiness analysis for the sensor networks. More details can be found in [3, 18].
The clustering and integration methods used in this study are all “hard-clustering”; that is, a micro-cluster could only be merged to one macro-cluster. Hence it is possible that the clustering result may not be deterministic. However, the influence is limited for the analytical query, because the macroclusters are usually aggregated from hundreds of micro-clusters, and there is almost no difference on merging a single micro-cluster or not.
7. Related Works
According to the methodologies, the related works of atypical cube can be loosely classified into two categories: the CPS applications and the spatial and temporal data warehousing.
7.1. CPS Applications
PeMS is a cyber physical system of freeway performance monitoring in California [1]. It collects gigabytes data each day to produce useful traffic information. PeMS obtains the data in the frequency from every 30 seconds to 5 minutes from each district. The data are transferred through the wide area network to which all districts are connected. PeMS uses commercial-of-the-shelf products for communication and calculation [19]. A g-factor-based algorithm [20] is used to estimate the average vehicle speed from collected data.
CarWeb is a platform to collect real-time GPS data from cars [2]. When sufficient information has been collected, the system estimates traffic information such as the average speed of vehicles. Several algorithms are employed to estimate more traffic measures.
Google Traffic is a service based on the Google Maps [21]. The feature package was officially launched in February 2007. It automatically includes real-time traffic flow conditions to the maps of thirty major cities of the United States. In a later released version a traffic model is used to predict the future traffic situation based on historical data.
Most CPS applications do not support OLAP queries. Some of them, like Google traffic, provide prediction functions but still do not support analysis on historical data.
7.2. Spatial and Temporal Data Warehousing
The pioneering work on spatial data warehousing is proposed by Stefanovic et al. with the concepts of spatial cube [22]. Spatial cube is a data cube where some dimension members are spatially referenced on a map [23].
In [24], Giannotti and Pedreschi summarize the ideas of trajectory cube. The motivation is to transform raw trajectories to valuable information that can be utilized for decision-making purposes in ubiquitous applications. The system supports two kinds of measures [22, 25, 26]: (1) spatial measures represented by a geometry and associated with a geometric operators and (2) numerical values obtained using a topological or a metric operator.
Shekhar et al. propose a web-based visualization tool for intelligent transportation system called Cubeview [14]. It is aimed to investigate high-performance critical visualization techniques for exploring real-time and historical traffic data. Based on Cubeview, the Advanced Interactive Traffic Visualization System (AITVS) is implemented by using two or more distinct views to support the investigation [15]. A traffic incident detection module is also developed by considering both spatial and temporal information [27].
Papadias et al. design efficient OLAP operations based on R-tree index [16]. The aggregation R-tree defines a hierarchy among MBRs that forms a data cube lattice. In a later study [28], the authors extend the indexing techniques to spatial and temporal dimensions. Historical RB-tree is built to help aggregating the measures on static and dynamic regions. The aggregate point-tree is proposed to solve range aggregate queries [29]. In [30], Tao et al. combine sketches with spatiotemporal aggregate indexes to solve the distinct counting problem.
However, those spatial OLAP techniques are not feasible for warehousing the atypical events in CPS data. The main reason is about their measures: most methods employ COUNT, SUM, AVG and other numeric measures and aggregate them in predefined hierarchies. They cannot describe the complex atypical events. In addition, those spatial aggregations must be carried out in predefined regions (e.g., R-tree rectangle, zipcode area, etc.), but the atypical events may not follow their fixed boundaries. Table 5 summarizes the differences among atypical cube and some related methods.
Comparison of related methods.

8. Conclusions and Future Work
In this paper, we have investigated the problem of multidimensional analysis of atypical sensor data in cyber-physical systems. A novel model of atypical cluster is designed to describe the atypical events in CPS data. The atypical cube is constructed as the forest of atypical clusters. The significant cluster is introduced for effective query execution, and the red-zone guided clustering algorithm is proposed to efficiently retrieve the significant clusters. Our experiments on large real datasets show the feasibility and scalability of proposed methods.
This paper is our first step in the CPS data analysis. In the future we will extend the atypical event analysis to support more complex applications, such as the event prediction and trustworthiness analysis in atypical data. We are also interested in applying the proposed methods to more applications, such as intruder detection on battlefields.
Footnotes
Acknowledgments
The work was supported in part by US NSF grants IIS-0905215, CNS-0931975, CCF-0905014, IIS-1017362, the US Army Research Laboratory under Cooperative Agreement no. W911NF-09-2-0053 (NS-CTA). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation hereon.