
Abstract
Source localization is an important problem in wireless sensor networks (WSNs). An exciting state-of-the-art algorithm for this problem is maximum likelihood (ML), which has sufficient spatial samples and consumes much energy. In this paper, an effective method based on compressed sensing (CS) is proposed for multiple source locations in received signal strength-wireless sensor networks (RSS-WSNs). This algorithm models unknown multiple source positions as a sparse vector by constructing redundant dictionaries. Thus, source parameters, such as source positions and energy, can be estimated by
1. Introduction
Wireless sensor networks (WSNs) [1, 2] are widely applied in environmental surveillance, such as detection, location, and tracking of multiple targets. Because of limited sensing range, communication capacity, computation ability, and energy in WSNs, it is necessary to utilize a collaborative signal processing algorithm [3, 4]. Source localization estimation is an important task that WSNs need to perform, which is fundamental for an accurate tracking and motion analysis of the source. Depending on the physical mechanism, most source location algorithms in WSNs or sensor arrays can be classified into three kinds, namely, direction of arrival (DOA) measurement [5, 6], time difference of arrival (TDOA) [7, 8], and received signal strength or energy (RSS) [9– 11]. DOA is applicable when the source emits a coherent, narrowband signal, which is not suitable to broadband sources. TDOA needs accurate distributable synchronization methods in order to keep distributed sensor nodes sampling in a synchronized fashion. However, these characteristics of DOA and TDOA are not very practical for low-cost and low-power WSNs. RSS can effectively overcome the limitations of DOA and TDOA, thus increasingly applied in source localization [9, 11].
Recently, many approaches for source location in RSS-WSNs have been proposed. Maximum likelihood (ML) estimation [10] is one of the state-of-the-art methods in RSS-WSNs. A multiresolution search algorithm based on ML is found in [10]. Expectation maximization (EM) algorithms [12] and alternating projection (AP) algorithms [9] are used for multiple source localization. A ML that is based on quantized data and can reduce the communication of RSS-WSNs is introduced by [11].
To reduce the Cramer-Rao lower bound (CRLB) of estimation, these preceding algorithms require more nodes and must be laid out as in a uniform formation as possible. However, more energy would be consumed in communication among nodes as a result of more nodes. Under some conditions, such as underwater surveillance, nodes are too expensive to deploy densely [13, 14]. Accordingly, how to locate multiple sources when spatial samplings are few or when WSNs are deployed sparsely is still an open problem [2].
The proposition of compressed sensing (CS) [15, 16] can solve the contradiction between the accuracy of source location and energy consumption of networks. CS provides a framework in which signals are compressed while they are measured. The paper [17] introduces a new theory for distributed compressive sensing (DCS) to enable new distributed coding algorithms that exploit both intrasignal (for single sensor) and intersignal (for sensor networks) correlation structures, which can be used in WSNs for reducing measurements. A novel sample mechanism based on CS is proposed in [18], where working nodes are randomly chosen in space, while the others are “sleeping” to save energy. The sparse event detection in large WSNs is formulated in CS framework in [19]. Moreover, [20] derives the theoretic bound to detection and estimation for compressive measurements. Since CS can cut down intersensor communications, thus it is applied to source localization in DOA-WSNs and RSS-WSNs in [21, 22], respectively.
However, the calculation of source location is much more complex when the observation scene is larger. The low-complexity algorithms based on CS are not found in [18, 21, 22]. Motivated by this, we proposed a low-complexity source location based on CS. In this algorithm, unknown multiple source positions are represented as a sparse vector by constructing redundant dictionaries which are similar to [22]. The positions of sources are converted to the position of nonzero elements in a sparse vector, and sources are located by
In the following section, the model of source localization based on CS is introduced, and the sampling mechanism is also presented. A low-complexity and adaptive algorithm for multiple source localization is presented in Section 3. Extensive experiments have been conducted to compare the performance of CS-based algorithm with that of the existing AP method in Section 4 and where the impact from WSNs deployment is also discussed. Conclusions and future works are given in Section 5.
2. Problem Formulation
2.1. Sparse Signal Model
A new sensing paradigm called compressed sensing or compressed sampling [15, 16] (CS) goes against the common knowledge in data acquisition-Nyquist sampling theorem. The main idea of CS theory is that the system can compress the redundant information in Nyquist bandwidth while the system is measuring. Thus, CS can recover certain signals from far fewer samples than traditional methods and can reduce the quantity of systemic data.
The first principle of CS is sparsity. Sparsity expresses the fact that many natural signals S are sparse, or sparse when expressed in a convenient basis as follows:

Here, Ψ consists of a group of orthonormal basis (such as a wavelet basis) named to represent a matrix and θ is the coefficient sequence of
Original CS theory proposes that Ψ is orthonormal basis. Some signals are sparse or compressible when expressed in a tight frame [16] or a redundant dictionary [23]. The papers [23, 24] extend CS to the theory under the condition of redundant dictionaries.
Consider that M sensor nodes are deployed over a three-dimensional region and defined as

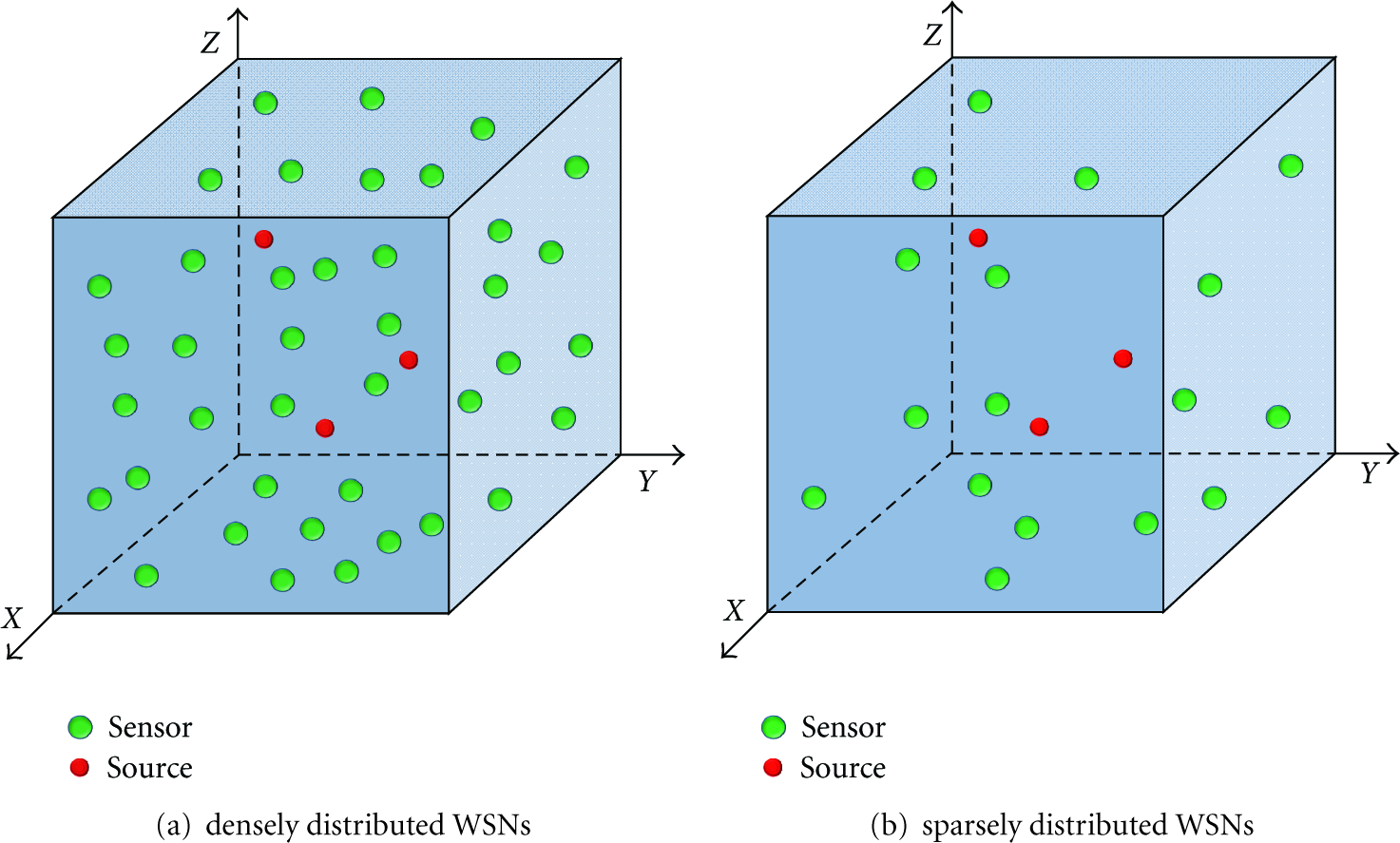
The geometry of WSNs and sources.
The positions of sources are relatively sparse in comparison with a large observation scene, which is shown in Figure 1. Here, the redundant dictionaries are adopted to represent the received signals of RSS-WSNs. The redundant dictionary is essentially the geometric projection in space. In the form of this dictionary, the measurement of mth node is denoted as


If the three-dimensional scene is divided into
One snap received signal is formulated in a matrix for RSS-WSNs with M nodes

For simplicity, (5) can be written as
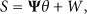
The advantage of this sparse representation is that signal
2.2. CS-Based Sampling in RSS-WSNs
As mentioned above, S is expanded in redundant dictionary

Another important principle of CS theory is incoherent sampling. Incoherent sampling demands the coherence between sampling matrix (Φ) and representing matrix (Ψ) to be as small as possible. Usually, the coherence
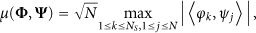
According to the measurement Z,

If Ψ extends from an orthonormal basis to redundant dictionary, it is necessary to give restrictions to
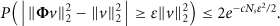
Here,

In this study, the Bernoulli matrix is adopted as the sampling matrix that satisfies the restriction of (10). More details are shown in [23]. The variable of Bernoulli matrix

According to (9) and (11), θ can be recovered by minimizing

Unfortunately, solving this

The optimization (14) is known as basis pursuit (BP). When the measurements contain noise, BP may be represented as the dual problem [8]

3. CS-Based Source Localization
3.1. Multiresolution Redundant Dictionary
A redundant dictionary is related to the grid number at each dimension (
According to CS sample principle, θ could be stably recovered by

Relationship between sample number and the high bound of N.
As mentioned above, a multiresolution redundant dictionary can sharply reduce the length of θ and the computation for a large-scale scene. Figure 3 shows the process of constructing a multiresolution dictionary. Firstly, the initial resolution is set to be low, and the sources are located in a certain grid or several grids by signal recovery. Secondly, the grid or the combination of several grids is considered as new space and is used to build a new redundant dictionary, which has smaller grids than before. Then sources are located in specified smaller grids by signal recovery. Thirdly, the combination of these smaller grids is considered as another new space, and the redundant dictionary is updated. Then the process is repeated until the minimum grid is up to resolution requirement.
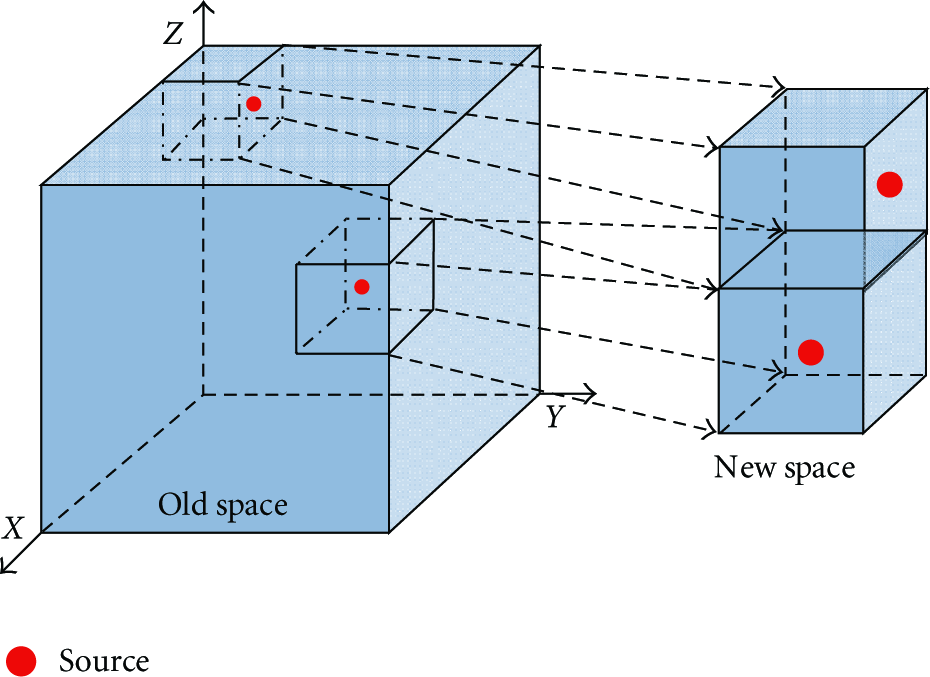
Multiresolution redundant dictionary.
For the same scene, iterative times of recovery would decrease with the increasing of N when constructing a redundant dictionary. A bigger N is likely to disobey the CS sample principle. Therefore, it is necessary to ensure proper N to make a tradeoff between iterative times and incoherence and a tradeoff between iterative times and recovery precision.
3.2. Adaptive Dictionary Refinement
The spatial subdivision schemes of dictionary can be divided into uniform and adaptive ones. The length of each grid is equal for uniform schemes, while the length of each grid is weighted by the data-driven criteria for adaptive schemes. In this study, both schemes are adopted in the localization algorithm. Because of none prior source location, the initial dictionary is made up of uniform grids. Then sources may be located in one or several interested and coarse grids, which would be adaptively partitioned into many subgrids. The numbers of subgrids are weighted by the recovery signal



Figure 4 shows the procedure of adaptive grid refinement in the iterations. First iteration adopts the uniform grid centers, and the sources are located coarsely in some grids (Figure 4(a)). Then these grids are split into subgrids with different resolutions depending on the estimated intensity from them. And the grid is more close to the source, which could have higher resolution, shown in Figures 4(b), 4(c), and 4(d).

Adaptive grid refinement in the iterations: the observation scene is 1000*1000*100.
3.3. Redundant Dictionary Arrangement
In this study, continuous coordinate indexing is utilized to arrange grids of redundant dictionary. The world Cartesian coordinates system is defined in Section 2.2. Additionally, we denote local axis as 1st-, 2nd-, and 3rd-axis depending on the indexing order, which are shown in Figure 5.

Continuous coordinate indexing of redundant dictionary in local coordinate system.
The indexing in local coordinate system has the following steps. Firstly, a 3rd-axis coordinate is fixed. Then the grids are arranged from small 1st-axis coordinate to big one on the plane that consists of 1st- and 2nd-axis, until all 2nd-axis coordinates are arranged. Secondly, turn to another plane that consists of 1st- and 2nd-axis. Then arrange all grids in this plane in the same manner as the first step. Finally, all 3rd-axis coordinates are arranged, and all grids are arranged (Figure 5). In other words, this redundant dictionary is indexed from 1st-axis to 2nd-axis, then to 3rd-axis. And the distance between neighbors in 1st, 2nd, and 3rd-axis is 1,
After sensors are deployed randomly in the interest of scene, there are multiple sources to be located. The arrangement of a redundant dictionary impacts the capacity to resolve multiple sources. For the same three-dimensional scene, redundant dictionary could be indexed in six manners, called redundant dictionary arrangement (RDA), in the form of
Six RDAs.

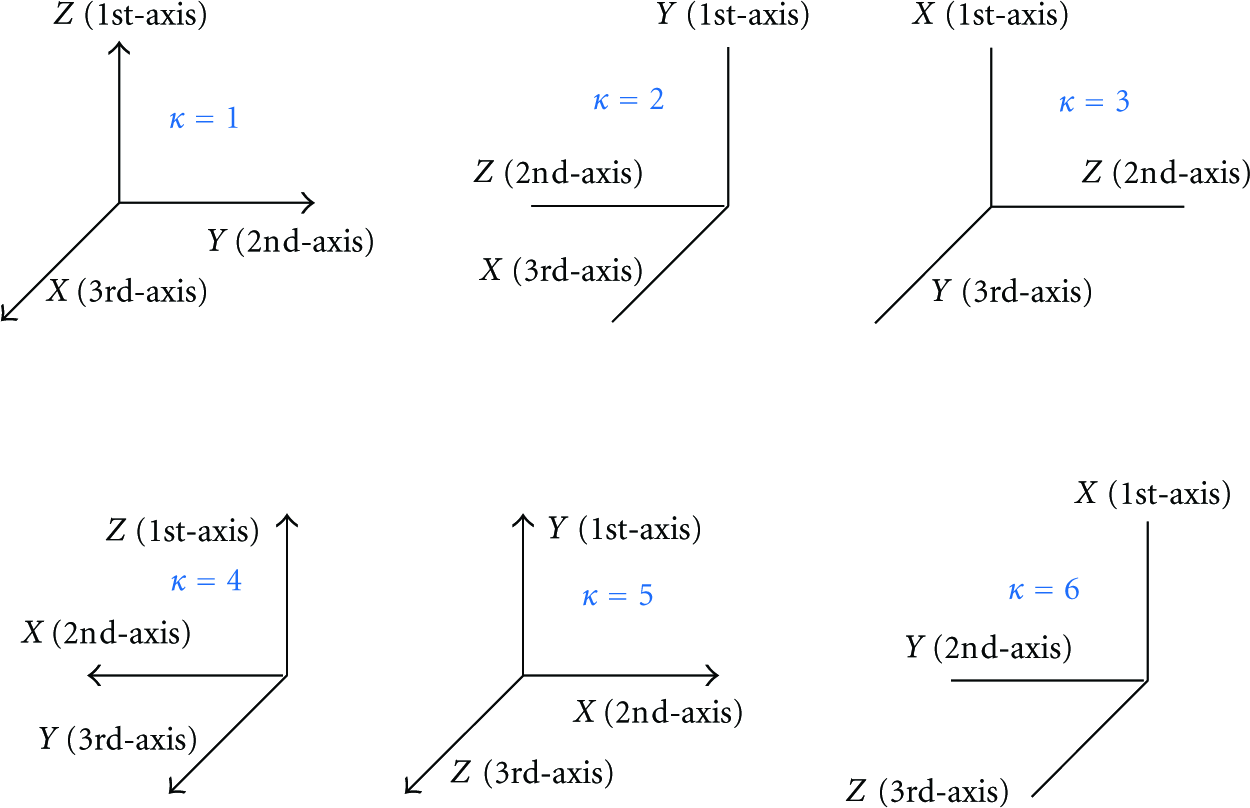
Six definitions of X-, Y-, and Z-axis.
Under certain form of RDA (κ), 
The optimization of RDA is essentially how to refine the direction of X-, Y-, and Z-axis in order to make the distance of two close sources in θ as large as possible, which is shown in

For instance two isotropic acoustic sources have been coarsely estimated and found that their distance has one grid in X-axis after previous iteration. This means that

Two sources are located in θ.
3.4. Signal Recovery Algorithm
It is well known that the signal can be recovered by nonconvex optimization, convex optimization, and statistics optimization. Orthogonal matching pursuit (OMP) [6] is a typical nonconvex optimization, which has a high calculation efficiency. And least absolute shrinkage and selection operator (LASSO) [7] is a typical convex method, that has a high recovery accuracy but the calculation is more complex than OMP. Statistics optimization, such as sparse Bayesian learning [26], has a higher calculation efficiency than convex algorithm and a higher recovery accuracy than nonconvex algorithm. Accordingly, sparse Bayesian learning [26] is utilized to locate sources.
In sparse Bayesian learning, a three-stage hierarchical form of Laplace priors is utilized to model the sparsity of the unknown signal 
3.5. CS-Based Source Localization Procedure
The proposed CS-based source localization algorithm is summarized in Algorithm 1.
(a) Construct redundant dictionary depending on the search space. (b) (c) Adaptive dictionary refinement based on (d) If If
4. Simulations and Analysis
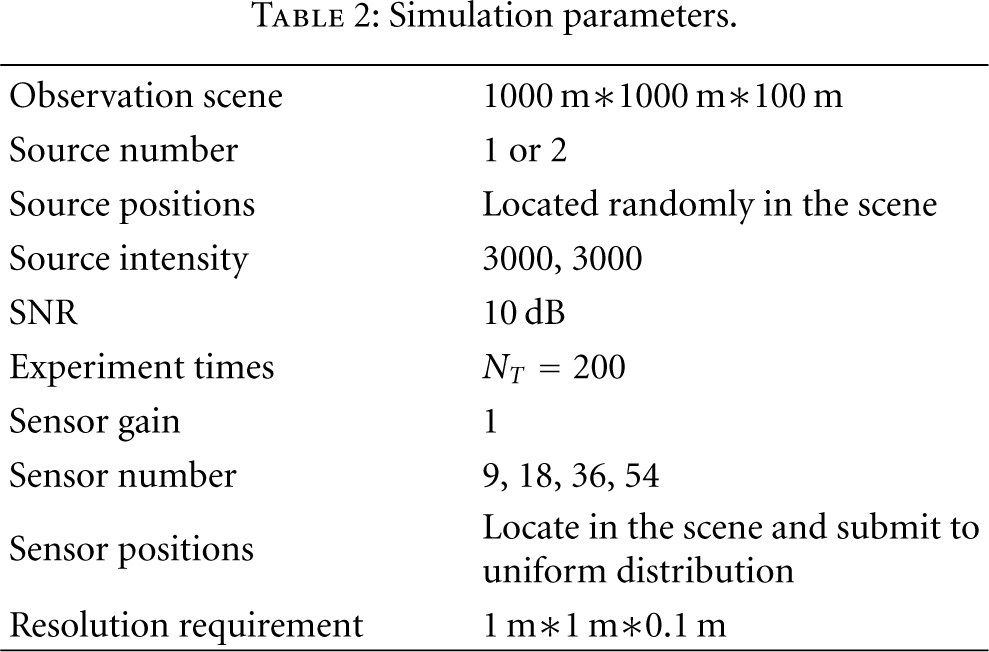
In order to evaluate the performance of the proposed algorithms, we conducted some typical numerical simulations. The simulation parameters are set in Table 2.
Simulation parameters.
4.1. RSS-WSNs Deployment
Generally speaking, sensor nodes can be deployed in a plane, or in two planes, or in a three-dimensional space. The manner of deployment [27] is classified into random distribution and uniform formation. In this study, area coverage is the primary objective for deployment, and more details are in paper [7, 13, 28]. For different localization algorithms, it is necessary to deploy nodes in a proper manner to improve localization accuracy. For ML, the more uniform the nodes are within the sensor field layout, the smaller the CRLR and the higher the localization accuracy are.
The localization accuracy is defined as the root mean square (RMS), given by

Here,
However, the CS-based algorithm is the opposite of ML. Because the distribution of nodes impacts on
We contract the impacts on

RSS-WSNs' deployment impacts RMS and
In Figures 8(a) and 8(b), the RMS of random distribution is smaller than the RMS of uniform formation, especially when
4.2. Coefficients of the Recovery Algorithm
As mentioned above,

Coefficients for recovery algorithm.
For the same
4.3. Single Source Localization
In this subsection, the sample number

RMS varies with SNR (single source).
Figure 10 shows that higher SNR leads to lower RMS for the same
In order to compare with other existing methods, the alternating projection (AP) algorithm [9] is also simulated as one effective localization algorithm based on ML. AP utilizes matrix projection to replace the inversion of matrix, and it locates unknown multiple sources through alternating optimization. The simulation results are shown in Figure 11 and Figure 13.

Compared to AP (single source).
For the same
4.4. Two-Source Localization
The observation scene can be adaptively divided into subscenes through constructing redundant dictionaries. For multiple sources, their locations can be converted into estimating of the positions of one source or two closely sources in a subscene. As mentioned above, single-source localization has been analyzed. It is known that RMS of multiple sources is a function of SNR,

Distribution of the estimated number of sources of different SNR and

Contrast between CS-based and AP in localization performance (two sources).
When SNR is 20 or 10 dB (Figures 12(a), 12(b), 12(e), and 12(f)), RSS-WSNs can stably distinguish two sources with the probability above 0.8, even if the distance of two sources is close to the resolution requirement (1 m). The probability of distinguishing sources decreases as SNR decreases. Especially, if SNR = −10 dB, the probability that two sources are well separated is below 0.5 (Figure 12(d)). Comparing Figures 12(a) 12(b) to 12(e) 12(f), it is found that few spatial samples would make the probability of fake source greater. For example, as SNR = 10 dB and
We explore the RMS of CS-based and AP algorithm in locating two sources, especially when they are close to each other. SNR is assumed to be 20 dB, and the distance between two sources ranges from 1 m to 29 m, increasing in steps of 4 m. The contrast between CS-based and AP is illustrated in Figure 13. The dotted lines and the solid lines stand for AP and CS-based, respectively. The triangles and the squares are the first source and the second one, respectively.
In Figure 13, for CS-based and AP algorithm, simulation shows that the RMS of locating two sources is larger than that of locating a single source. It is because the parameters that are needed to estimate increase with the augment of the number of sources. In CS-based algorithm, the augment of source number results in the augment of the sparsity
Theoretically, RMS decreases as the distance between sources increases for both CS-based and AP. However, when nodes are sparse, the RMS of multiple sources using AP is around 15 m (Figure 13). It is because the performance of AP has a strong relationship with the density of nodes, and RMS decreases as the density of nodes increases up to a certain level. If the density is not up to this level, RMS does not obviously decrease with the great increasing of the distance. However, CS-based algorithm has a different performance. At the same condition, the RMS of CS-based is smaller than AP, especially when
In Figures 13(c) and 13(d), when the two sources are close to each other
In order to explore the impact from the optimization of RDA, two sets of simulation results are shown in Figure 14. One set is without RDA optimization (dashed line), and the other is with RDA optimization (solid line). The triangles and the squares represent the first source and the second source, respectively.

RDA impacts on RMS.
In Figure 14, CS-based localization algorithm improves with RDA optimization. The RMS of two sources with the procedure is smaller than that without the procedure, which is obvious when the distance between the sources is less than 21 m. This demonstrates that RDA optimization can effectively improve the capacity to resolve multiple close sources. However, when two sources are far apart (i.e., the distance between the sources is more than 21 m), the impact on RMS from the procedure is little. This is because no matter which RDAs are utilized, the distance between sources is enough to be resolved. At this time, RDA optimization is not of much importance.
5. Conclusions and Outlook
This work proposes an effective source localization algorithm based on CS, which is used on sparsely distributed RSS-WSNs. Extensive simulations show that the proposed algorithm consistently outperforms the existing ML algorithms. Compared to ML, CS-based algorithm improves the accuracy of single- and multiple-sources localization at the same number of samples. With the same accuracy of localization, this algorithm can effectively reduce the number of spatial samples.
Additionally, multi-resolution redundant dictionary reduces the complexity of calculation, and the adaptive dictionary refinement and the optimization of RDA can improve the efficiency of multiple source localization. A simulation demonstrates that the random deployment of nodes is more suitable to this algorithm than uniform formation.
There are other adaptive spatial partitioning approaches to construct redundant dictionary, such as KD tree or RP tree. Future work concerns about tree partitioning and treeindexing in CS-based source location algorithm.
Footnotes
Acknowledgments
The authors would like to thank the anonymous referees for their kind comments and valuable suggestions. They would like to thank S. D. Babacan and R. Molina with Northwestern University and A. K. Katsaggelos with University of Granada for sharing the program of signal recovery (FastLaplace). they wish to give their sincere thanks to Chen Yong-qiang, Tan Wei-xian, Lin Yue-guan, Kou Bo, Jiang Hai, and Xiang Yin with IECAS for thoughtful comments and suggestions during numerous discussions. Finally, they wish to thank Mark Xiang Wei, Zeylord Bautista, and Dong Fang for their help during writing and thank Ouyang Yue with IECAS for his help during revision.