
Abstract
Sensor networks are especially useful in catastrophic or disaster scenarios such as abysmal sea, floods, fires, or earthquakes where human participation may be too dangerous. Storage technologies take a critical position for WSNs in such scenarios since the sensor nodes may themselves fail unpredictably, resulting in the loss of valuable data. This paper focuses on fountain code-based data storage and recovery solutions for WSNs in disaster scenarios. A review on current technologies is given on challenges posed by disaster environments. Two information fusion-based distributed storage (IFDS) algorithms are proposed in the “few global knowledge” and “zero-configuration” paradigm, respectively. Correspondingly, a high-efficient retrieve algorithm is designed for general storage algorithms using Robust Soliton distribution. We observe that the successful decoding probability can be provisioned by properly selecting parameters—the ratio of number of source node and total nodes, and the storage capacity M in each node.
1. Introduction
WSNs have attracted a lot of attention recently due to their broad applications. With the rapid development of microelectromechanical system, sensor nodes can be made much smaller with less cost. “Smart dust”, as a form of WSNs, will become one of the most potential applications in real world [1]. They can be deployed in tragedy, isolated, and obscured fields to monitor objects, detect fires, temperature, flood, and other disaster incidents such as earthquakes, landslides, and ice damage. Sensing networks are ideal for such scenarios since conventional sensing methods that involve human participation within the sensing region are often too dangerous. These scenarios offer a challenging design environment because the nodes used to collect and transmit data can fail suddenly and unpredictably as they may melt, corrode, or get smashed. Hence, it is necessary to design reliable storage strategies to collect sensed data from sensors before they disappear from the network.
In 2006, Kamra et al. [2] designed and analyzed techniques to increase “persistence” of sensed data based on growth code—a variant of fountain code. Later on, Lin et al. [3] proposed an algorithm that uses random walks with traps to disseminate the source packets in the WSNs. They employed the Metropolis algorithm to specify transition probabilities of the random walks. However, the knowledge of the total number of sensors N, sources K, and the maximum node degree of the graph are required in their works. Recently, Aly et al. [4] proposed two new decentralized algorithms with limited or no knowledge of global information based on raptor codes. They afterward proposed two distributed flooding-based storage algorithms [5] for a WSNs wherein all nodes serve as sources as well as storage nodes, and the results demonstrated that it is required to query only 20–30% of the network nodes in order to retrieve the data collected by the N sensing nodes, in such a specific scenario where the buffer size is 10% of the network size. As a conclusion, a review on fountain code-based storage technologies is elaborated in Section 2.
The ultimate goal of any storage strategies is to get the maximum data recovering possibilities while encountering loss of data. A storage strategy needs to include two parts, that is, “how to store” and “how to retrieve”. The two parts should be well matched with each other just like a decoding algorithm needs to be suitable for the encoding process. However, most of the previous works only focus on the storage part involving how to network the backup of sensing packages to each storage node and how to process the back-up packages in distributed way. In this paper, we extend the works to a complete solution including both storage and recovery sections. With respect to the storage part, two IFDS algorithms are proposed in the “limited global knowledge” and “zero-configuration” paradigm, respectively. For the recovery part, a belief propagation and Gaussian elimination-based recovery Algorithm (BGRA) is designed for data retrieve in close connection with the proposed storage algorithms, and it is suitable for any storage algorithms using Robust Soliton distribution. Moreover, the general scenarios with consideration of the percentage of source node number K among total number of nodes N and the storage capacity M of each node are studied. We analyze in detail how the three parameters affect the data retrieve. The results indicate that a WSN with designable successful decoding probability can be deployed by selecting proper N, K, and M, which lays some foundation for the application of WSNs in disaster scenarios.
2. Fountain Code-Based Storage in WSNs
Fountain codes are a new class of rateless codes with finite dimension and infinite block length. The first class of efficient universal fountain codes was invented by Luby [6] and is called LT codes. The codes are designed for channels with erasures such as internet, but many distinctive characteristics make the codes become an excellent solution in a wide variety of situations. MacKay [7] mentioned two major applications in his review of fountain code, one is for broadcast and the other is for storage. In storage applications, fountain codes can be used to spray encoded packets as backup of a file on more than one storage device so as to prevent data loss caused by catastrophic failures of unreliable storage device; and to recover the file, one simply needs to gather enough packets from any intact devices and skip over the corrupted packets on the broken devices. Actually, the distributed storage model in WSNs is very similar to the case, and it seems easier to implement in WSN since the communication network used to bridge nodes makes it convenient to spray the back-up packages. In a sensor network, the storage device is the node with storage units. In order to prevent data loss caused by unexpected failure of the storage node, a similar solution is to network the important sensed data to multiple storage nodes, encoding them distributedly using fountain code and to store them as a backup. The original sensed data can be retrieved as long as to query enough storage nodes with enough encoded packages.
Based on these points, many researchers follow closely with fountain code-based decentralized storage technology and give specialized solutions to the storage problems of WSNs in disaster environments [2–6, 8]. The basic approach is to achieve distributed encoding in each storage node using simple exclusive-or operations. Specific implementations adopt the encoding process of growth code [2], LT code [3], or raptor code [4], respectively.
The way to disseminate the original sensed data to each storage node assumes crucial role in recovery performance of storage data in WSNs. Random walks [3, 4] and flooding [5] are two major ways to spray sensed data. The flooding dissemination adopts a very simple operation that each node floods the sensed data to all its neighbors and decides whether to store or discard the received packages according to the probability computed by random algorithms. Random walks employ Metropolis algorithm to disseminate the source packets. The number of random walks launched from each sensing node and the probabilistic forwarding tables for random walks are computed by the Metropolis algorithm. As long as a source block stops at a node at the end of the random walk, this node will store this source block. After all source blocks are disseminated, each storage node generates its encoded block. The basic features of the methods are summarized in Table 1.
Comparison of flooding- and random walks-based data dissemination.
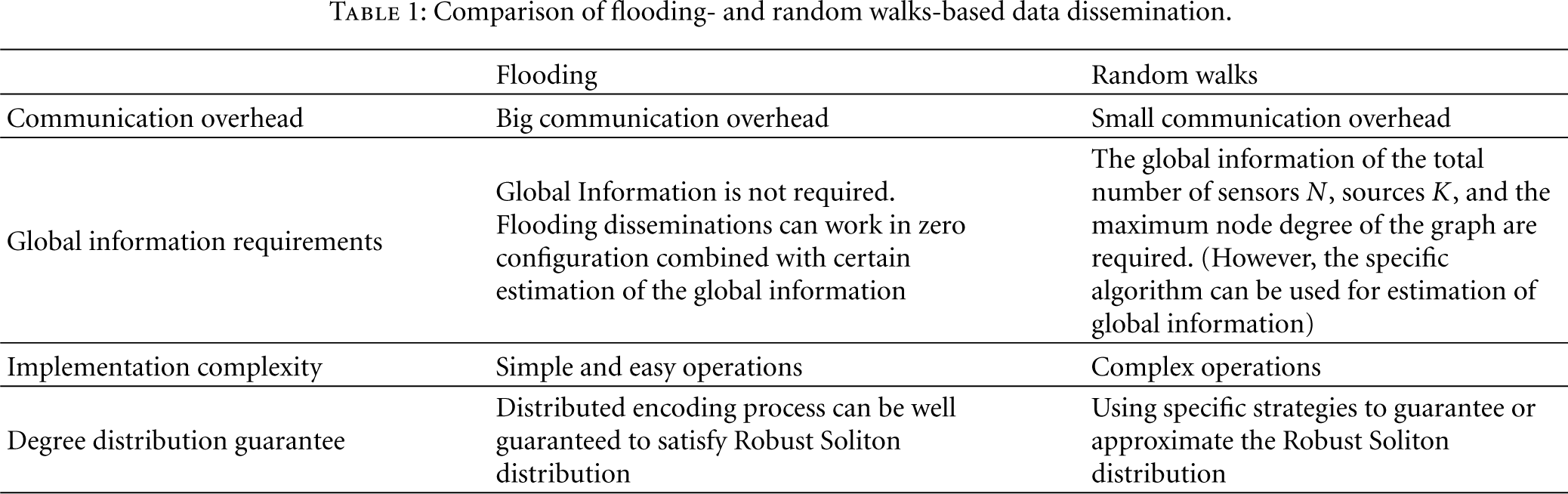
According to global information requirements, the storage algorithm can be classified into two categories—“limited global knowledge” or “zero-configuration” algorithms [3–5]. If each node in the network knows the value of K—the number of sources, and the value of N—the number of storage nodes as a prerequisite for the designed storage algorithm, then the algorithm works in the “limited global knowledge” paradigm. However, in many scenarios, especially, when changes of network topologies may occur due to node joining-in or node failures, the exact value of N may not be available for all nodes. On the other hand, the number of sources K usually depends on the environment measurements or some events, and thus the exact value of K may not be known by each node either. As a result, to design a fully distributed storage algorithm which does not require any global information with “zero configuration” is very important and useful. In previous literatures, exact decentralized fountain codes (EDFC) and approximate decentralized fountain codes (ADFC) [3], distributed storage algorithms (DSA)-I [5] and raptor codes based distributed storage (RCDS)-I [4] are “limited global knowledge” based algorithms, and distributed storage algorithms (DSA)-II [5] and raptor codes based distributed storage (RCDS)-II [4] functions in “zero configuration”. In the mode of “zero configuration”, random walks can be used to estimate the network scale and further to approximately compute N, K in order to decide how to set the TTL segment (or maximum hop) of the package.
Viewed from the perspective of the recovery behavior, LT codes or Raptor codes based storage algorithm adopts the belief propagation (BP) process, which is recommended by Luby for decoding of fountain codes [6], as the recovery algorithm due to its low complexity. However, even though BP algorithm is simple and easy to implement, it does not explore all the encoding information in generator matrix G, so we do some amelioration on BP algorithm for a full exploitation of all the encoding information to enhance the retrieve performance. The detailed description is presented in Section 5. In addition, Growth code takes two situations into account—full recovery or optimal partial recovery. The goal is trying to completely recover all the storage data, but while it does not achieve full recovery, then pursuing the maximum of partial recovery to retrieve more storage data. This is a reasonable consideration in storage application. Inspired by these works, we proposed the information fusion based storage and retrieve algorithms for WSNs in disaster scenarios. Compared with the classic WSN paradigm, the major advantages using IFDS are the following. (i) IFDS algorithms adopt “flooding” to achieve data dissemination task, and each node never needs to keep a route table to sink node. Hence, each node never needs to rebuild new routing and update the route table due to failure of the nodes on the path to sink node. It is suitable for application in disaster environment. (ii) Over the various paths to sink node by flooding, each path transmits the “supplementary data” which includes not only the data information but also its relationship with other encoded blocks, so it has certain degree of redundancy, serving as a kind of “back up” for storage purpose. However, these advantages are at the cost of increasing a degree of communication overhead, computational overhead, and complexity.
With respect to the previous algorithms, several improvements are provided by IFDS algorithms. In the storage block assembling phase, the proposed IFDS algorithms do not need judge to accept or reject a data packet every time while the packet arrives a node, and each node in WSN calculates its own degree in preprocessing phase, which does once for all. In data dissemination phase, IFDS has a robust estimation method for hop segment
3. Preliminaries and Modeling
In a real WSN, sensors are usually classified into several types based on different functions they assume. In Figure 1, we classify the set of sensors into the three kinds. Source sensors are located in the area where we expect to monitor for specific application. Source sensors are able to perform monitoring and generate packets of sensed data. Relay sensors collect received data into their buffer memory and are able to produce encoded blocks based on the distributed storage algorithm. Collector sensors or base station represents one or small number of WSNs nodes that are connected with the external network. The collector nodes is to collect data from their neighbors, recover the set of K source packets
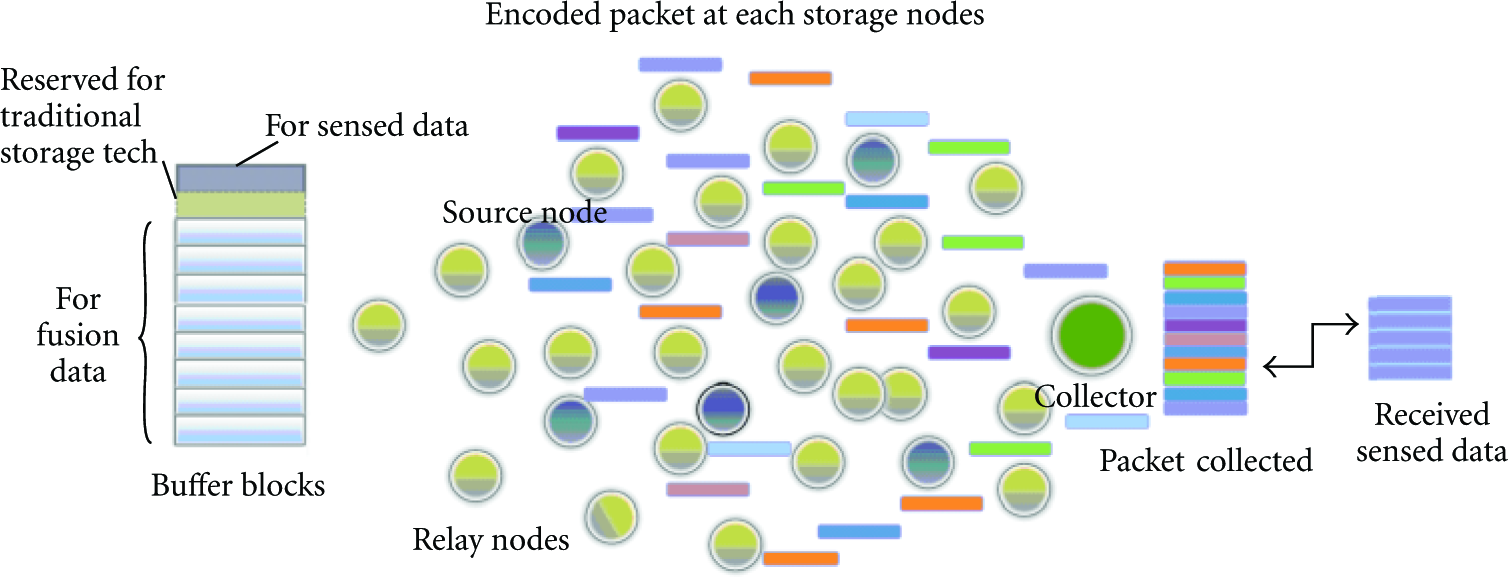
Illustration of information fusion-based distributed storage for WSNs.
4. Data Dissemination and Decentralized Storage
The concept of fountain code is a basis for the decentralized storage in WSNs. Although it is centralized in many coding literatures, we want to give a brief introduction of LT codes, especially concerning the Robust Soliton distribution for a better discussion on our storage and recovery algorithms in the following sections. Two storage algorithms are then presented to explain how to disseminate the sensed data and how to implement the encoding of LT codes at each storage node in decentralized way.
4.1. A Brief Introduction of LT Codes and Degree Distribution
Fountain is a class of erasure codes capable of reaching optimal erasure recovery on the binary erasure channels without fixing the rate. Fountain codes have remarkably simple encoding and decoding algorithms. In order to create an encoded symbol, an encoding host runs the encoding process as follows. Firstly, randomly choose the degree randomly choose the degree d of the encoding symbol from a degree distribution. The design and analysis of a good degree distribution is a primary focus of the remainder of this paper; choose uniformly at random d distinct input symbols as neighbors of the encoding symbol; the value of the encoding symbol is the exclusive-or of the d neighbors.
Each encoding symbol has a degree chosen independently from a degree distribution. Degree distribution
Definition 1 (Robust Soliton distribution [1]).
For constants 
Here, 
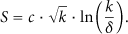

The Ideal Soliton degree distribution with

The Robust Soliton distribution
4.1.1. IFDS-I
In IFDS-I, each node in the network knows the limited global information N and K. Let Input. A sensor network Output. Storage buffer blocks Preprocessing. Step i. Choose randomly the code degree of the encoding packets from degree distribution function, structure a set
In order to show the data dissemination performance, we give an simple example for a WSN with parameters
In the example, we assume that

Data dissemination implemented in IFDS-I.
In Figure 5, the red curve indicates the TTL of data packets or the number of transmissions required for a successful data dissemination, in order to assure that all the sensed data can arrive at each node at least one time. The blue curve is the actual TTL used by IFDS-I. It is obvious that the value on blue curve is equal or greater than the red one; this means that IFDS-I provides the data packets with a longer living life than enough, or say that the packets can arrive at more nodes. And we find that the counter of packet could actually be set as a number smaller than
IFDS-I Storage Algorithm { { elements in { storage unit according to other packets stored in storage block before, then store it directly.} {Put the packet into forward queue, set hop segment as 1.} {Discard the packet

The relationship between network scale and
4.1.2. IFDS-II
In IFDS-II, we assumed that N and K are known in advance for each node in the network. This might not be the case in practical disaster scenarios where the change of connectivity status may occur between nodes due to the event of sensor failure or new nodes joining in. Therefore, we extend IFDS-I to IFDS-II that is totally distributed without knowing global information with “zero configuration”. The idea is that each source node
Hop estimation: let

The hop-estimation process flow of IFDS-II.
In the flow chart, each source node should maintain a hop value. The hop value is used for a real-time estimation of the network size based on the already received hop-estimation packets. It will be updated when a packet with a bigger estimated hop segment value is received. Every time when the packet passes through a node, the value of the estimated hop segment will increase one; so, a bigger hop segment means that the packet can reach to a node in a father location and it has come back to the source node again. Thus, the packets with the biggest estimated hop segment are those reaching the edge of the network. Continuous updating of the hop value until achieving convergence can be used to approximate the network radius or network scale. In this process, if structure of WSN alters, such as nodes failures, movements, or network expanding, all these changes will be reflected in the estimated hop segment of hop-estimation packets, and further the hop value will be also updated adaptively. For example, if the network is expanding, the hop value will increase and become stable after several updates. Moreover, while new sensing nodes are assigned in WSN, the estimation process will be triggered for these new source nodes which start estimating and knowing the network size. Once the hop counts
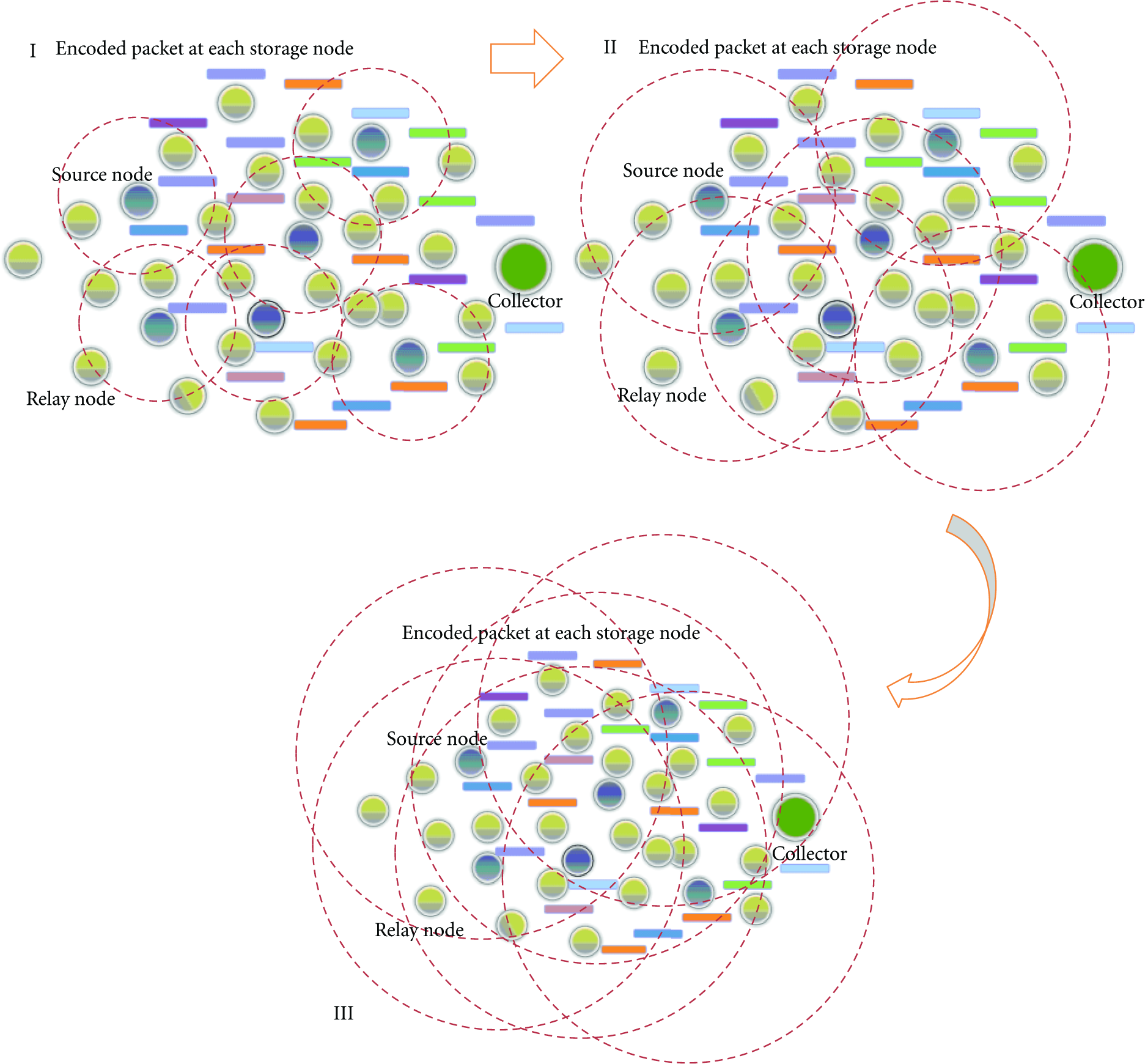
The data dissemination implemented by IFDS-II.
In the beginning stages (I, II), the maintained hop value is still never fully updated since the packets that spread to the network edge never come back; therefore, the assembled data packets cannot reach far from the source node due to a small TTL. Along with the dynamic estimation of the network size, the hop value is updated and continuously increasing; then the assembled data packet can reach farther in the process until the hop value reaches stable, and, at the point, the network radius or network scale can be correctly estimated; the packets flooded from source node can arrive at any nodes in the network. In our buffer model, one block is reserved for traditional storage method. Here we just randomly store one sensed packet with degree one using uniform distribution. The storage performance of both IFDS-I and IFDS-II will be elaborated in Section 6 combining with the recovery algorithm proposed in Section 5.
4.2. Power Consumption of IFDS Algorithms
The overall energy in the WSN nodes is consumed in three distinct processes: data processing, data transmission, and sensing tasks. The proposed IFDS algorithms will majorly affect the first two processes; certain overhead will be brought during implementation of the algorithms. The communication overhead is the major overhead due to wide flooding for data dissemination. However, on the other hand, since the algorithms never need to maintain the routing tables, so they would never introduce the routing overhead. The distributed storage encoding will cause certain computation power consumption. In order to decrease the computation complexity, the proposed IFDS algorithms do not need to flip a coin to accept or reject a data packet every time while the packet arrives a node; instead, each node in WSN calculates its own degree in preprocessing phase, which does once for all. This is more energy efficient than the previous algorithms that will calculate the code degree and make selection from every arriving packet for encoding. The typical energy management techniques with the basic idea, to shut down sensors when not needed and wake them up when necessary, can be easily applied and combined with IFDS algorithms, because IFDS can estimate the network size adaptively. Moreover, Since the deployment of the WSNs in difficult-to-access areas makes it difficult to replace the batteries of sensor nodes. The use of solar cells, super capacitors, or rechargeable batteries is necessary for the long-term sensor node operation. A long-term operation could be achieved by adopting a combination of hardware and software techniques along with energy efficient WSN design.
5. Recovery Algorithm
In Section 3, we refer that BP algorithm is generally used as a basic recovery algorithm to retrieve storage data in WSNs. However, the BP algorithm has some limitations while used for storage applications. BP algorithm is fast with low complexity but it must find degree-one column in generator matrix G for each iteration to make decoding process go ahead, which prohibits the improvement of recovery efficiency, because it may not use all the encoding relationship recorded in G while it cannot find degree-one column in process, or say that the BP algorithm never takes use of all the encoding information while encountering stop set which will greatly reduce the successful probability of complete recovery. Gaussian elimination (GE) is another typical way for decoding of LT codes, and now many improved algorithms are proposed for decoding of fountain codes [9–13]. In order to solve the problems caused by the stop set of the BP algorithm, we expect to combine BP and GE algorithms and to provide a good tradeoff between the advantages of both algorithms for a better recovery performance. The core idea is to first use BP algorithm with very low complexity directly to find degree-one column in G and then to consider adoption of GE operation to find the potential degree-one column from the remaining columns. It can overcome the negative influence of algorithm termination of BP and improve the decoding efficiency for LT codes through fully digging out encoding information from matrix G. We name the algorithm, Belief propagation and Gaussian elimination based Recovery Algorithm (BGRA). The algorithm flow is shown in Algorithm 2.
BGRA Recovery Algorithm { { { { { { { { { {
We give an intuition of how the BGRA works by considering a simple example. In the example, we set

The original G matrix and the evolvement of G, T, and
BGRA algorithm, as integration of BP and GE algorithm, provides a good tradeoff between the advantages of both the BP algorithm and the GE algorithm. The BGRA algorithm has reasonable decoding complexity that is in between the low complexity of the BP algorithm and the high decoding complexity of the GE algorithm. The BGRA algorithm has a successful decoding probability that is comparable to that of the GE algorithm and significantly better than that of the BP algorithm. Additionally, the decoding CPU computational time of BGRA algorithm does not rapidly increase with overhead, as is the case for the GE algorithm.
In order to compare the three algorithms, we experiment BP, GE, and BGRA algorithms with different values of overhead for the number of sensed source data

The successful decoding probability as a function of encoding overhead while
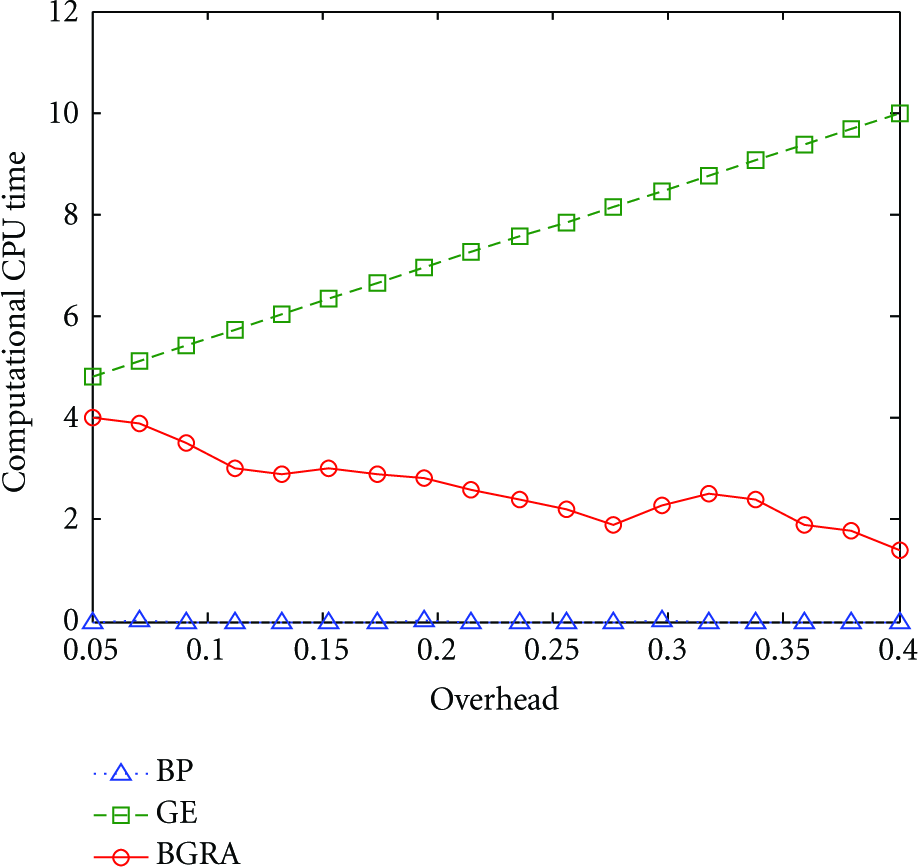
The computational CPU time as a function of encoding overhead while
6. Results and Discussion
Figures 11 and 12 show the decoding performance with IFDS-I for different network scale with fixed ratio of

(a) The successful decoding performance; (b) the mean number of recovered packets as a function of querying ratio while

(a) The successful decoding performance; (b) the mean number of recovered packets as a function of querying ratio while
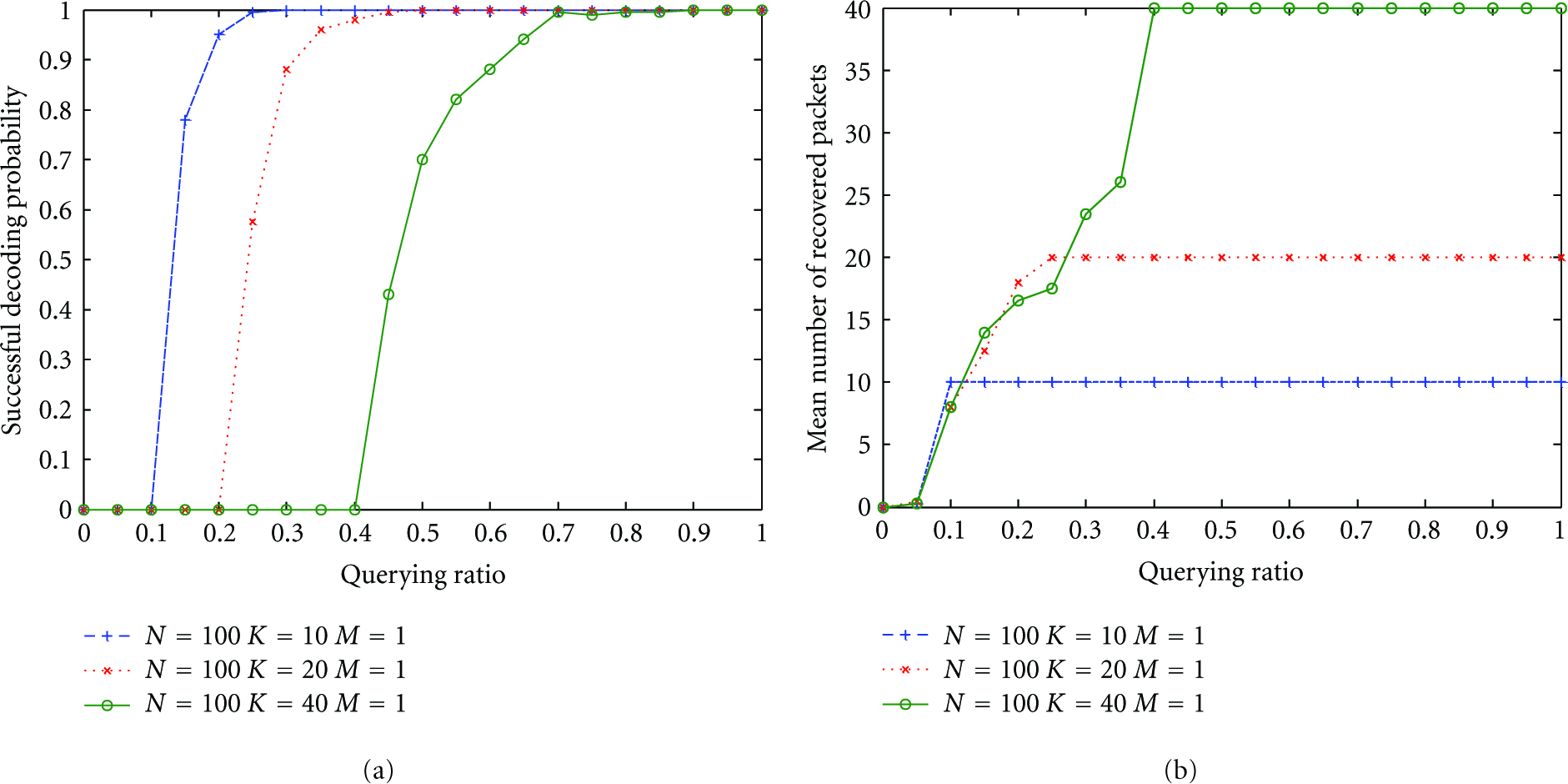
(a) The successful decoding performance; (b) the mean number of recovered packets as a function of querying ratio for networks with

(a) The successful decoding performance; (b) the mean number of recovered packets as a function of querying ratio for networks with

(a) The successful decoding performance; (b) the mean number of recovered packets as a function of querying ratio for networks with
Figures 13–15 illustrate the decoding performance with IFDS-II for different scale networks while each node has fixed one unit buffer block and
Figure 16(a) compares the performance of IFDS-I with DSA-I [5]. DSA-I algorithm utilizes flooding and the node degree of each node to disseminate the sensed data from sensors throughout the network, and the encoded data are stored distributedly in each node for later data retrieve. Both IFDS and DSA algorithms consider the storage capacity of each node which is modeled with the number of buffer units. In [5], the authors analyze the data retrieve performance of DSA-I when the node buffer size is 10% of the network storage size. Under the same condition, we give our results and we find that IFDS has a better decoding performance. Compared with 20–30% querying nodes using DSA-I, IFDS-I only requires to query 15% nodes in network with

(a) Comparison of decoding performance using IFDS-I and DSA-I; (b) comparison of decoding performance using IFDS and RCDS.
7. Conclusion
This paper proposes two IFDS algorithms in the “few global knowledge” and “zero-configuration” paradigm, respectively. An efficient retrieve algorithm is designed correspondingly, which is generally suitable for the storage algorithms using Robust Soliton distribution. The algorithms enhance the successful decoding probability. The detailed results of data retrieve performance and its relationship with three parameters—the total number of nodes N, the number of sensing nodes K, and the number of storage units equipped at each node M, is studied, which shows that we can control the successful decoding probability through setting up desired network parameters.
Footnotes
Acknowledgments
The authors thank the Research Project from Communication Branch of Yunnan Power Grid Corporation, Training Program of Yunnan Province for Middle-aged and Young Leaders of Disciplines in Science and Technology (Grant no. 2008PY031), and the National Natural Science Foundation of China (Grant no. 60861002) for financial support.