
Abstract
In wireless sensor networks, it is of great importance for fault diagnosis to ensure the gathering information accuracy and reduce energy additionally consumed by faulty nodes, for the deployment of a large number of sensor nodes in hostile environment. In this paper, we propose an energy-efficient data collection protocol which consists of clustering and multipath routing. Clustering based on fault diagnosis eliminates the possibility of cluster heads (CHs) acting by faulty nodes which reduce energy consumption and fault information transmission. Multipath routing provided by directed acyclic graph (DAG) increases system fault tolerance. Furthermore, clustering and multihop routing consider residual energy and routing cost, respectively; thus balanced energy consumption is achieved. Performance analysis shows that the message complexity disseminated in clustering and fault diagnosis is acceptable. Simulations demonstrate that the protocol has better energy efficiency compared with other related protocols.
1. Introduction
In recent years, Wireless Sensor Networks (WSNs) have become an attractive technology for a large number of applications, ranging from monitoring to event detection and target tracking [1]. To design and deploy successful WSNs, many issues need to be resolved such as deployment strategies, energy conservation, fault-tolerant routing in dynamic environments, localization, and fault diagnosis. To extend the network lifetime as long as possible, energy efficiency becomes one of the basic tenets in the WSNs protocol design. There are several possible solutions to balance energy consumption, such as deployment optimization [2], topology control [3], and data aggregation [4].
Among these schemes, clustering provides an effective way for promoting energy efficiency [5–9]. In clustering schemes, sensor nodes are organized into clusters and a main node is selected as the cluster head (CH) of a cluster, and the other nodes are called cluster members (CMs). Each CM collects local data from the environment periodically and then sends it to the CH. When the data from all the CMs arrives, the CHs aggregate the data and send it to the BS via single-hop or multihop. When the network is partitioned into clusters, data transmission can be classified into two stages, that is, intra- and intercluster communication. Mhatre and Rosenberg have shown that multihop intercluster communication mode is usually more energy efficient because of the characteristics of wireless channel [10]. Thus it is better to let CHs cooperate with each other to forward their data.
Due to the low cost and the deployment of a large number of sensor nodes in uncontrolled or even harsh environments, it is common for nodes to become faulty. The existence of these faulty nodes in WSNs brings the data collection protocol many adverse effects such as nonuniform distribution of the clustering effect and inaccuracy of the information collected. In addition, too many faulty nodes directly affect the connectivity of the network, resulting in premature network partition, which is an important factor affecting network lifetime. How to identify faulty nodes and eliminate the impact of these nodes gradually attractsmore and moreattentions.
Multipath routing between a source and a destination is a promising routing scheme to achieve robustness, load balancing, bandwidth aggregation, congestion reduction, and security compared to the single shortest-path routing that is usually used in most networks [11]. Techniques developed for multipath routing are often based on employing multiple spanning trees or directed acyclic graphs (DAGs) [12, 13]. Both of them offer resiliency to single-link failure. Due to the relative instability of communication links in WSNs, it is necessary to explore the feasibility of the multipath routing.
In this paper, we analyzed the opportunities and challenges of fault diagnosis based on comparison model in WSNs, and so far there is little work done for this owing to the inherent characteristic of WSNs. Furthermore, we design and implement a fault diagnosis-based clustering and multipath routing protocol (FDCM) for wireless sensor networks. FDCM mainly includes two phases: fault diagnosis-based clustering and multipath routing selection. The features making FDCM distinct are as follows. (i) Clustering based on fault diagnosis eliminates the possibility of CH acting by faulty nodes which reduce energy consumption and fault information transmission. (ii) The constructed DAG provides multipath routing approach, which increases system fault tolerance. (iii) Clustering and multihop routing consider residual energy and transmission cost, respectively, which balance energy consumption and promote network efficiency. Consequently, the communication overhead and network lifetime of FDCM are desirable.
The rest of the paper is organized as follows. The next section describes the related work. Section 3 introduces the network model and related terminologies at first, after which is the fault diagnosis model based on comparison model. Subsequently, it analyzes the fault diagnosis addressing WSNs and provides several requirements. The system design including clustering construction and multihop routing is detailed in Section 4. The simulation results are given in Section 5. Finally, the conclusion and the future work are drawn in Section 6.
2. Related Work
Clustering provides an effective way for prolonging the lifetime of WSNs. Heinzelman et al. [5] first proposed a clustering protocol called LEACH for periodical data gathering applications. It is an application-specific data dissemination protocol that uses clustering to prolong the network lifetime. HEED [6] introduced a variable known as cluster radius which defines the transmission power to be used for intracluster broadcast. EEUC [8] and EADUC [9] introduced cluster head competitive algorithms which extend LEACH and HEED by choosing CHs with more residual energy. Both of them achieve well distribution of CHs.
As faults are inevitable in every distributed computer system, especially in WSNs which consist of a large number of capacity-limited nodes, it is important to be able to determine which of them is working and which is faulty. Comparison-based diagnosis is a realistic approach to detect faulty nodes based on the outputs of tasks executed by system nodes. The model is based on comparisons of the outcomes returned by different units executing the same task and uses the invalidation rule of the generalized Maeng and Malek (gMM) model [14, 15]. Comparison-based diagnosis initially used for multiprocessor system has been firstly applied to mobile ad hoc networks (MANETs) by Chessa and Santi [16]. Later, Elhadef et al. considered the problems of self-diagnosis of wireless mesh networks (WMNs) and MANETs using the comparison approach [17, 18].
For WSNs, traditional comparison-based fault diagnosis protocols for multiprocessor systems, WMNs and MANETs are not suitable without changing. To the best of our knowledge, so far fault diagnosis based on the comparison model has not yet been applied to WSN efficiently. Chen et al. proposed a distributed fault-detection algorithm to locate the faulty sensors [19]. It calculated the measurement difference between neighbor sensors at different times to find if the current measurement of a sensor is different from its previous measurement. Wang et al. provided a cluster-based real-time fault diagnosis aggregation algorithm for WSNs [20]. The protocol is based on the comparison approach aiming at achieving a correct and complete diagnosis for hierarchical WSNs. They assumed that each sensor can transmit data to any other sensor and can communicate directly with the BS, which is unrealistic in practice.
3. System Models
3.1. Network Model
In this paper, we consider a sensor network consisting of N static and homogeneous sensor nodes uniformly deployed over a vast field to continuously monitor the environment. The communication topology of WSN is usually represented by the graph There is a unique identifier for every node. The computing, storage, and energy power of sensors are limited. Nodes are capable of operating in an active mode or a low-power sleeping mode. There is a stationary base station (BS) located far from the sensing field. BS distributes control messages in one-hop mode, and its energy and computing capability are not limited. Nodes are location-unaware, but a node can compute the approximate distance to another node based on the received signal strength, if the transmitting power is known. All nodes are static and homogeneous which are organized as clusters. CMs communicate with CH with one-hop manner, while the communication between CHs and BS is relayed by other CHs. Proper data aggregation mechanism is adopted for energy saving, and there exists a MAC protocol which is executed to solve contentions, providing reliable one-hop broadcast over logical links.
All of these assumptions are typical for wireless sensor networks, which means that our model is general, that is, not unrealistic. We use a simplified model for the communication energy dissipation [22]. Both the free space (

The electronics energy,

3.2. The Diagnosis Model
Each node in the system can be in one of two states: faulty or fault-free. There are different classifications for faulty type. Based on duration, faults can be classified as permanent, intermittent, and transient. A transient fault will eventually disappear without any apparent intervention, whereas a permanent one will remain unless it is repaired and/or removed by external administrator. Based on how a failed node behaves once it has failed, faults can be either hard or soft. When a node is hard-faulted, it cannot communicate with the rest of the system. In WSNs, a node can be hard-faulted either because it is crashed or due to battery depletion. Soft faults are subtle, since a soft-faulted node continues to operate and to communicate with the other nodes in the system, although with altered behaviors. In this paper, we utilize the invalidation rule of the gMM model [14, 15] that is summarized in Table 1.
The invalidation rule of the gMM model.
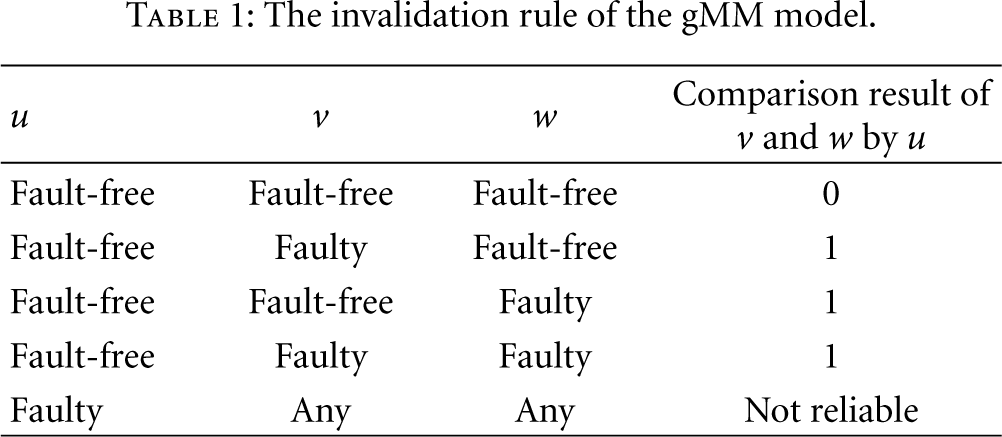
In the gMM model, diagnosis is based upon comparison of the results generated by test tasks assigned to pairs of units with a common neighbor. Let u be a unit adjacent to both unit v and w. If nodes
(1) Test Request Generation
In order to test adjacent nodes, each node u generates a test sequence number i, a test task
(2) Test Request Reception
Any node v in
(3) Test Response Reception
Any node w in
Case 1.
If
Case 2.
If
Case 2.1.
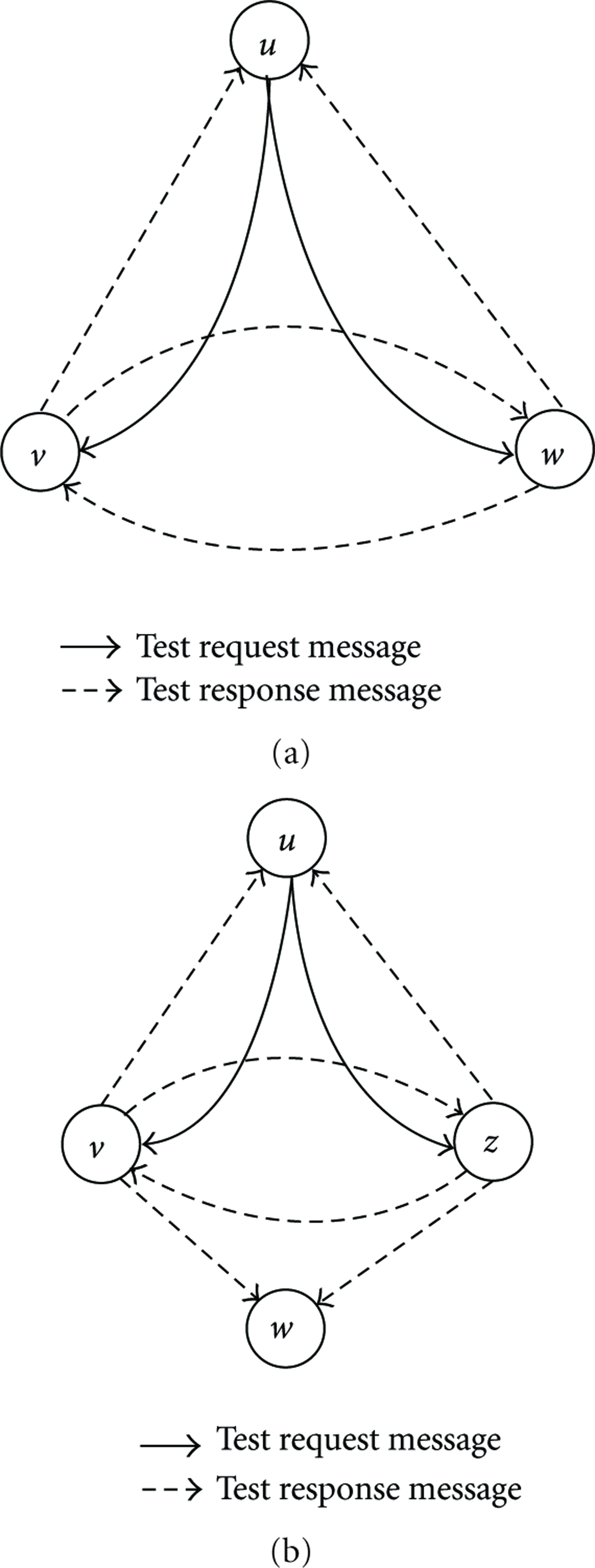
(a) Node w received u's test task and v's corresponding response reply. (b) Node w received v and z's response corresponding to u's test task.
Case 2.2.
(4) Timeout Reception
After sending its test response message, node u initiates a timer to
3.3. Problems and Requirements
The inherent characteristics of WSNs make the direct applications of existing fault diagnostic models that have been pervasively applied in traditional multiprocessor systems, WMNs, and MANETs are unrealistic. In the following, we sum up these problems and give the corresponding analysis.
On the one hand, we require a suitable fault diagnosis mechanism for WSNs which is energy-efficient and message complexity acceptable. Sensor nodes are limited in battery energy, computing, and storage capacity, and the protocol design need to consider the energy efficiency of the network nodes. That is, the amount of calculation performed by nodes should be moderate and the traffic generated by the exchange of messages should be reasonable. Clearly, there should be some mechanisms to isolate messages flooding in the networks. Owing to instability of nodes, the number of faulty nodes is far more than the traditional multiprocessor systems or MANETs. Besides, constrained by wireless communication capacity, the structure properties in terms of regularity, connectivity, and so forth, of the communication topology are worse than interconnection networks. As a result, the traditional diagnostic measures cannot meet the fault diagnosis requirements in WSNs.
On the other hand, an excellent clustering mechanism provides a good basis for fault diagnosis. Clustering WSNs, CMs only perform the sensing tasks, while in addition to collecting data from CMs, CHs also have to fulfill a variety of other tasks, such as data aggregation, cluster maintenance, and communication with BS via multihop or one-hop way. Considering the efficient mechanisms for CHs to reduce and balance energy consumption and to ensure the CHs fault-free is crucial, especially in fault diagnosis applications. Besides, nodes are left unattended after deployment requires adaptive node fault processing mechanism. For instance, the fault conditions can be transmitted to the BS, which are uniformly processed according to the actual requirements.
In this paper, we summarize the protocol design as clustering problem based on fault diagnosis and multipath routing problem based upon DAG. Since the networking nodes in WSNs are very limited in resources, clustering should not only have small size, but also be constructed with low communication overhead and computation cost. In addition, the amounts of communication and computation should be scalable as the networks are typically deployed with large network size. For the multipath routing problem, the backbone network composed of CHs can be abstracted as an edge and vertex weighted graph G(V, E, W, R). We view the CHs as vertexes set V, the communication links as edges set E, the communication cost (edge weight) as W: Clustering should be completely distributed with accepted message complexity. Each node independently makes its decisions based on local information and results into well-distributed CHs over the sensing field. At the end of clustering, each node is either a cluster head or a member node. Using message complexity acceptable diagnostic mechanism to eliminate the harmful influence and to avoid unnecessary energy consumption imposed by faulty nodes. Utilizing multipath routing mechanism to make the gathering data transmission reliable. In particular, it is necessary to select the cost-aware or energy-aware communication path among all of the possible paths. Avoiding excessive energy consumption of CHs and maintaining the energy consumption balance of network nodes.
4. System Design
Our fault diagnosis-based clustering and multipath routing data collection protocol (FDCM) can be divided into two phases mainly as follows. Phase (I): clustering construction based on fault diagnosis; Phase (II): resilient multipath routing selection. In the following, we explain how FDCM works in detail.
4.1. Clustering Construction Based on Fault Diagnosis
In network deployment phase, BS broadcasts a HELLO message to all the nodes in the network at a certain power level which includes a certain number of candidate CHs selected in advance. After receiving this message each sensor node checks whether it is a candidate CH. Each selected CH computes the approximate distance to the BS based on the received signal strength and then executes a distributed cluster head competitive algorithm similar to EEUC [8]. Our CH competition is primarily based on the fault status and residual energy of candidate CHs. The size of cluster is controlled by competition radius R, which is a constant tuned by typical situation. In addition, let
Definition 1.
Candidate CH
Before clustering, BS selects predefined candidate CHs randomly on certain probability to compete for final CHs. For the sake of saving energy, nodes that fail to be candidate CHs keep sleeping until the cluster head competition stage ends.
The distributed clustering algorithm which is initiated by BS and executed by each candidate CH is presented in Algorithm 1. First, each candidate CH broadcasts a
1. Candidate CH COMPETE_CH( 2. On receiving a COMPETE_CH from 3. 4. 5. 6. 7. On receiving a TEST_REQ( 8. 9. 10. On receiving a TEST_RES from 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. and R( 21. 22. and R( 23. 24. 25. 26. 27. 28. broadcast FINAL_CH( 29. 30. On receiving a FINAL_CH from 31. 32. broadcast QUIT_ELECT( 33. 34. On receiving a QUIT_ELECT from 35. 36. remove 37.
After all the final CHs have been elected, immediately, previous sleeping nodes now are waked up and each CM chooses their closest CH with the largest signal strength received. All the CMs register with the CH by sending a JOIN_CLU message. In order to determine the status of CMs in each cluster, the CH sends a test quest TEST_REQ to its member nodes. These nodes compute the tasks and feed back the results to the sender. The lower layer fault diagnosis algorithm based on comparison protocol is presented in Algorithm 2. Once the faulty nodes are determined, they will be ordered to turn dead. The final CH sets up a TDMA schedule and transmits it to the nodes in the cluster. After the TDMA schedule is known by all nodes in the cluster, the clustering phase is completed and the data transmission stage begins. Based on the execution of Algorithm 1, we can draw the following theorem.
1. generate test task 2. broadcast test request TEST_REQ( member nodes 3. generate the expected result R( 4. set the timer to be 5. Initialize the faulty CM set CM set 6. Each CM sends test response TEST_RES( in random back-off time 7. node 8. 9. 10. 11. 12. 13. send TURNDEAD message to
Theorem 2.
In clustering stage, FDCM has a message exchange complexity of
Proof.
During the execution of clustering algorithm, each candidate CH sends a COMPETE_CH message at first. In order to identify the faulty candidate CHs, which will be deprived of the eligibility of final CHs, each of them sends TEST_REQ and receives TEST_RES message one after another. If it becomes a final CH then broadcasts a FINAL_CH message to declare its win, otherwise broadcasts a QUIT_ELECT message to exit. After the declaration of winning the election, each regular node broadcasts a JOIN_CLU message. So each node has the message complexity of
Assume that network size is N, the number of candidate CHs is M and the number of final CHs/clusters is
The theorem is proved.
From Theorem 2 we can conclude that the clustering stage has a low message complexity both for individual node and entire network, thus requirement (1) is satisfied.
Theorem 3.
At the end of clustering phase, any fault-free node either is a final CH or a CM. Furthermore, each CM exactly belongs to a cluster, and only one final CH is allowed in each competition range.
Proof.
During the execution of Algorithm 1, for the nodes in sensor network there are at most four states in total: RegularNode, CandidateCH, FinalCH and deadNode. Here the status of RegularNode and FinalCH means it is a CM and CH, respectively.
In the following we first show that any node is either a final CH or a CM after execution of Algorithm 1. Initially, in addition to the selected candidate CHs in advance, the remainder nodes are all regular nodes. For candidate CHs, in lines 5–24, each of them knows the fault status of its adjacent CHs. If the node is determined as faulty nodes, then they quit the competition process, immediately. In lines 33–36, the faulty candidate CHs are ordered to turn dead (deadNode), and they do not participate in the subsequent work any more. For any candidate CH
After the election of final CHs has finished, each CM registers with only one CH based on received signal strength, thus each CM exactly belongs to a cluster. The competition process shows that for any candidate CH
To sum up, the theorem is proved.
Fault diagnosis in this paper refers to all faulty nodes within the sensor network are identified correctly and these faulty nodes are ordered to stop working, and the fault conditions about each cluster are reported to BS via data transmission by CHs. Upon receiving fault information, BS takes appropriate actions, such as forbid faulty nodes taking part in the final CH election in the next round. According to the description and analysis above, the fault diagnosis process consists of two phases. First, it eliminates the candidate CHs to participate in the final CH competition in the process of clustering. Secondly, after the clustering is finished, the fault diagnosis is done based on special comparison model between CH and CMs. These two phases together complete the diagnosis of all faulty nodes in the network correctly. A diagnostic message can be a test request, a test response, or a timeout message. The message complexity of diagnostic algorithm is presented in Theorem 4.
Theorem 4.
The communication complexity of our comparison-based fault diagnostic approach is
Proof.
According to Theorem 3, at the end of the clustering stage, any fault-free node is either a final CH or a CM. Each candidate CH
4.2. Resilient Multipath Routing
Before delivering their data to BS, each CH first aggregates the sensing data from its CMs, and then sends the data packet plus the fault information to BS via a multihop fault-tolerant path. We assume that any two CHs within their communication scope can communicate with each other and consider them as neighboring. Each CH has the information about its neighbors. The distributed multipath routing consists of three subphases: Construct Connected Network, Choose Next-hop Neighbor and Route Maintenance.
4.2.1. Construct Connected Network
Assume
Condition 1.
Condition 2.
Condition 3.
According to the model described in Section 3, we have mapped multipath routing problem into finding communication path in weighted graph G(V, E, W, R). On the basis of this mapping, we assume that there is a logical communication link between any two nodes which meet conditions 1–3 synchronously. Note that the links direction is always from sources to BS, thus a directed connected cost network (vertex and edge weighted digraph) is built. In order to model and depict mapped multipath routing problem, the definition of DAG is given followed by a theorem which satisfies requirement (4).
Definition 5.
A directed acyclic graph (DAG) is a directed graph with no directed cycles. We say that a DAG is rooted at r if it is the only node in the DAG that has no outgoing edges. Every other node has at least one outgoing edge.
Theorem 6.
The mapped weighted graph G(V, E, W, R) which meets Conditions 1 and 2 synchronously is a connected DAG rooted at BS. That is, the graph is connected, directed and without directed cycles. Furthermore, for any vertex in G, it is BS reachable.
Proof.
As stated before, there is an edge between any two vertexes which meet with Condition 1. For any two adjacent vertexes u and
Suppose that the mapping produces at least two connected components
Case 1. There is not any relay CH in
Case 2. There exists at least a relay CH
So both cases there must be at least a directed edge
Condition 2 ensures that the route moving toward BS from source CHs via relay CHs. Without loss of generality, we suppose that there is a directed circle
Therefore, the theorem is proved.
4.2.2. Next-Hop Neighbor Choosing
The reachability relation in a DAG forms apartial order, with which a routing path can be constructed, that is, the DAG provides a multipath routing mechanism. With Theorem 6, any CH can transmit its data along relay CHs to BS. Any node or link fails, based on the candidate nodes and links in DAG another one will be chosen. According to different requirements, the selection of the next hop node gives priority to the minimum energy strategy or the maximum residual energy strategy or any other factors. The former forwards packets along the minimum energy path to BS; while the latter farces packets to move toward the BS considering more residual energy of the node on routing path. The decision is made depending on the connected network model and the information gathered in clustering stage.
As an example, the distributed algorithm looking for next-hop neighbor for any cluster head
1. 2. 3. 4. 5. 6. 7. 8. 9. 10.
Figure 2 illustrates the communication path selection process. Each cluster head has 2 J initial energy, and the communication cost is denoted by edge weight, the residual energy is represented by vertex weight. The DAG shows the available communication paths. For sensor node

Intercluster multihop paths selection among DAG.
4.2.3. Route Maintenance
As stated previously, in the connected network each CH always chooses the neighboring CH with the minimum distance to BS as the next-hop routing node independently. The rest neighbors are maintained in its routing table in order of their distance to BS. If the optimal neighbor is unavailable due to node or link failure, then the node chooses a suboptimal one in its routing table, thus providing a robust routing. In addition, this multipath routing selection mechanism to some extent guarantees that the malicious attacker in network cannot obtain the communication path by listening in the signal simply. After each CH determined its next-hop neighbor, CHs are ready to start transmitting sensing data.
In intercluster multihop routing stage, Algorithm 3 finds a routing path, which approaches BS more quickly among all the available paths. While in clustering stage, candidate CH competition takes into residual energy into account. In round based protocol, both stages progress alternatively and thus provide network balanced energy consumption among all sensor nodes which meets requirement (5).
5. Simulations
5.1. Simulation Settings
In this section, we evaluate the performance of FDCM with simulations. Because LEACH [5], HEED [6], and EEUC [8] are the most similar clustering protocols, we use them for comparisons. For fault diagnosis-based clustering, CRFDA [20] is compared. One hundred of sensor nodes are randomly distributed over the region of
Simulation parameters.

Wireless sensor network deployment. Hollow circles denote fault-free nodes, and triangles show faulty nodes.
In our paper we make the following assumptions. (1) Nodes that are detected as faulty will turn into dead mode, that is, they will no longer generate information and consume energy. (2) During the network lifetime, nodes may be faulty at any time. The data sending by soft-faulty nodes is invalid. (3) Sensor nodes have idealized sensing capabilities. Ideal MAC layer conditions are assumed, that is, perfect transmission of data on a node-to-node wireless link. (4) In diagnosis process, we use the uniform rules to generate test Task
5.2. Simulation Results
Since our protocol is round based, we assume that sensor network randomly generates certain number of faulty nodes when it is running in a certain round. In ideal situation, we expect that the number of the fault-free nodes in network decreases correspondingly comparing with previous round. In our simulation, assume that 3 faulty nodes present in 100th, 200th, 300th round, respectively, and then the result of algorithms execution is shown in Figure 4. One of the curves indicates the result when there are faulty nodes in the network; while the other is fault-free case. From the figure, we can see that the number of fault-free nodes is reduced with faulty nodes arise when the network is running in each round. This means FDCM can correctly detect the faulty nodes in the network. Besides, by comparing, the existence of faulty nodes decreases the network lifetime observably.

The number of fault-free nodes changes with time.
Communication complexity is an important measurement for fault diagnosis efficiency. That is one of reasons why fault diagnosis mechanisms with high complexity in traditional MANETs are unrealistic using for WSNs directly. By means of introducing fault diagnosis based on the comparison model in the process of the candidate CHs running for final CHs, FDCM eliminates the chance of faulty nodes to participate in the election; Then, within each cluster only

Comparison of communication complexity.
When faulty nodes come into being, if they do not be diagnosed and excluded from the network, they will consume additional energy of other fault-free CHs. Then, it will shorten the lifetime of the entire network. In simulation, we monitor the number of nodes alive changing with time (round). We find that the network lifetime of FDCM may be influenced by various factors in different situations. The evaluation of the lifetime comparison between the cost-aware and the energy-aware is shown in Figure 6.

Comparison of network lifetime with different routing modes.
In contrast with similar clustering protocols, we run LEACH, HEED, and EEUC to compare their performance in network lifetime. As shown in Figure 7, FDCM and EEUC perform far better than LEACH and HEED in prolonging network lifetime attributed to the consideration of energy conservation. In FDCM, a certain amount of energy is spent by the nodes involving in fault diagnosis; however, this eliminates additional energy consumption caused by the faulty nodes. More importantly, the existence of fault diagnosis ensures the correctness of the information collected.
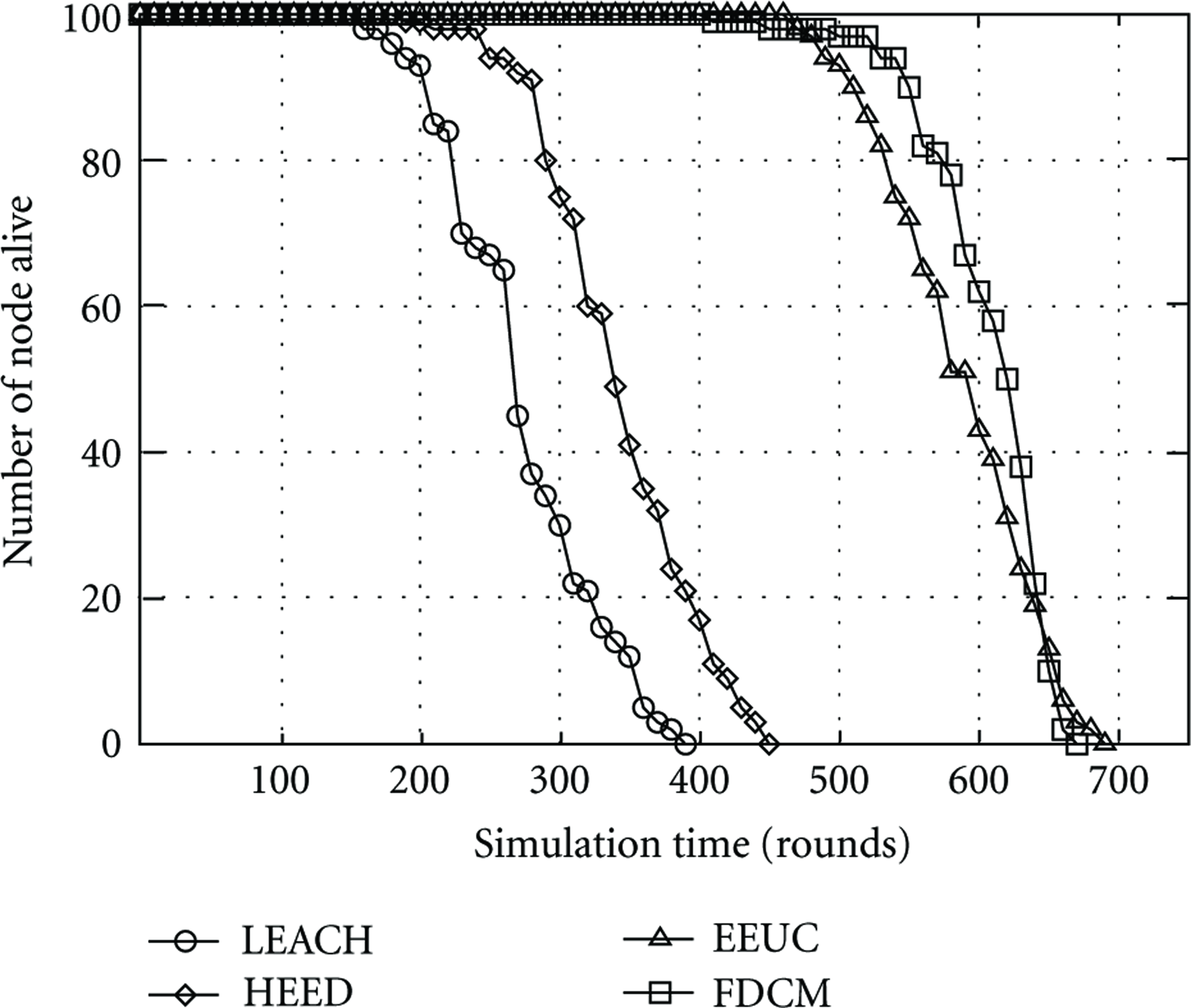
Comparison of Network lifetime with different protocols.
6. Conclusions
In wireless sensor network, it is of great importance for fault diagnosis to ensure the gathering information accuracy and reduce energy additionally consumed by faulty nodes, for the deployment of a large number of sensor nodes in hostile environment. For the inherent characteristics of sensor networks, this paper analyzes the issues and challenges of comparison based-fault diagnosis model for wireless sensor networks and gives the relevant design requirements.
As a complete data collection protocol, the proposed protocol mainly consists of fault diagnosis-based clustering and multipath routing. During clustering stage, a fault diagnosis approach based on comparison model is introduced. Fault diagnosis of the network nodes consists of two phases. At first, it eliminates the faulty candidate CHs to participate in the final CH competition in the process of clustering. Secondly, after the clustering is finished, the fault diagnosis is done based on special comparison model between CH and CMs. CH sends a test request message to its members and according to their responses to determine the fault status of these nodes, failure nodes are ordered to turn dead. These two phases together complete the diagnosis of all faulty nodes in the network.
In Multipath routing stage, communication characteristics impose certain conditions, which map the original abstract communication graph into the DAG. The new graph determines the feasible multipath communication path of any node to transfer data to the BS. In particular, we give an algorithm greedy select next hop neighbor which has the minimum distance to BS. When multiple nodes are optional, then the node with the highest residual energy is preferential. If any node in the routing path fails, then select an available path in the DAG depending on the highest residual energy or have the minimum distance to BS until the data transfer to the BS. Note that the transmitted data including node fault status, which can be used in the next round as a basis of cluster first election, that is, faulty nodes will lose the possibility of acting as the candidate CH.
For future work, we will consider two new directions. First, we intend to improve our algorithm effectiveness and obtain better performance, such as more accurate diagnosis and lower response time. Second, on condition that acceptable message complexity, we will study the possibility of new diagnosis approach which is appropriate for dynamic topology.
Footnotes
Acknowledgments
This work is supported by National Natural Science Foundation of China (nos. 61070169, 61170021), Natural Science Foundation of Jiangsu Province (no. BK2011376), Specialized Research Foundation for the Doctor al Program of Higher Education of China (no. 20103201110018), Application Foundation Research of Suzhou of China (nos. SYG201118, SYG201240), and sponsored by Qing Lan Project.