
Abstract
Many applications and protocols in wireless sensor networks need to know the locations of sensor nodes. A low-cost method to localize sensor nodes is to use received signal strength indication (RSSI) ranging technique together with the least-squares trilateration. However, the average localization error of this method is large due to the large ranging error of RSSI ranging technique. To reduce the average localization error, we propose a localization algorithm based on maximum a posteriori. This algorithm uses the Baye's formula to deduce the probability density of each sensor node's distribution in the target region from RSSI values. Then, each sensor node takes the point with the maximum probability density as its estimated location. Through simulation studies, we show that this algorithm outperforms the least-squares trilateration with respect to the average localization error.
1. Introduction
The process of determining the physical locations of sensor nodes is known as localization, which is a fundamental problem in wireless sensor networks [1, 2]. The locations of sensor nodes are essential in many applications and protocols. For example, the sensed information about an event without the location where it takes place is often meaningless. Similarly, geographic routing relies on the locations of nodes to forward packets [3].
The locations of sensor nodes can be directly obtained by preconfiguration or global positioning system (GPS). Preconfiguration requires each sensor node being placed at a known location, which is only suitable for the case that sensor nodes are easy to be placed and their number is small. On the other hand, a sensor node equipped with a GPS receiver is costly and does not work indoors. Therefore, both the above two methods are impractical for large-scale low-cost wireless sensor networks. It is desired that the locations of sensor nodes can be induced from their interactions, such as the detections of the distances between neighbors.
Many localization algorithms first use a ranging technique to estimate the Euclidean distances between nodes, and then use the least-squares trilateration to determine the locations of sensor nodes by these estimated distances. Some conventional ranging techniques are received signal strength indication (RSSI), time of arrival (TOA), time difference of arrival (TDOA), angle of arrival (AOA), and so forth [4]. Among them, RSSI ranging technique has the least requirement for hardware, as the radio chip of current sensor node usually has a built-in function of reading RSSI value. But RSSI value is vulnerable to being disturbed by the surrounding environment and the ranging error of RSSI ranging technique may be at most ±50% [5]. Furthermore, the least-squares trilateration is sensitive to ranging errors [2]. If using RSSI ranging technique together with the least-squares trilateration to localize sensor nodes, the average localization error is very large.
To reduce the average localization error, we propose a localization algorithm based on maximum a posteriori. This algorithm uses the probability approach to estimate the location of each sensor node directly from RSSI values. Extensive simulation results have shown that the average localization error of this algorithm is less than that of the least-squares trilateration.
The remainder of this paper is organized as follows. Related work is discussed in Section 2, the network model is defined in Section 3, and our proposed localization algorithm is described in Section 4. Simulation results that illustrate the performance are included in Section 5, and Section 6 is the conclusion.
2. Related Work
Since localization is a fundamental problem in wireless sensor networks, there are many research works focusing on it recently. Localization algorithms can be divided into two categories: anchor-based localization algorithms and nonanchor-based localization algorithms. An anchor is a special node which has a priori knowledge of its location.
In anchor-based localization algorithms, the location of each sensor node is determined only by its distances from anchors. Priyantha et al. developed the cricket location support system which provides localization services for indoor mobile node [6]. Bulusu et al. proposed a GPS-less localization algorithm in which each mobile node localizes itself to the centroid of its adjacent connecting anchors [7]. Niculescu and Nath proposed a family of distributed localization algorithms “adhoc positioning system” (APS) [8, 9]. In these algorithms, each node measures its distances from anchors by performing multihop propagation of distances to anchors throughout the network. Kumar et al. used RSSI-based weighted centroid to improve the localization algorithm proposed by Bulusu et al. [10]. Li and Liu proposed the rendered path (REP) protocol for locating nodes in anisotropic sensor networks with holes [11]. Lederer et al. also studied the problem of localizing a large sensor network having a complex shape, possibly with holes [12].
In nonanchor-based localization algorithms, the location of each sensor node is determined also by the distances between sensor nodes. Doherty et al. proposed a constraint-based localization scheme using semidefinite programming (SDP) to find a solution to the localization problem [13]. Shang et al. proposed an algorithm using classical multidimensional scaling (MDS) technique to calculate the locations of nodes given a set of distances [14]. Kwon et al. proposed a localization algorithm based on least square scaling (LSS) which is a variant of multidimensional scaling technique [15]. Khan et al. proposed a distributed iterative localization algorithm in m-dimensional Euclidean space with a minimal number of
Many of the above-mentioned algorithms [12, 14, 15, 17] have a similar optimization objective as the least-squares trilateration, that is, minimizing the (weighted) sum of all squared differences between each estimated distance and the corresponding distance calculated by the estimated locations of nodes. But when the distances are estimated by RSSI ranging technique, this optimization objective is likely subject to a large average localization error. In this paper, we present another optimization objective with which sensor nodes can be localized more accurately.
3. Network Model
Before describing our proposed localization algorithm, we first assume the model of wireless sensor network as follows.
A wireless sensor network is deployed in a planar region B. Suppose that B is a rectangle, whose length is l and width is w. But later we will see that the proposed algorithm is not dependent on the shape of B. Without loss of generality, we assume that the lower left corner of B is the origin and the coordinate of the upper-right corner of B is All sensor nodes are uniformly distributed in B. Anchors have a larger transmission range than sensor nodes. Each sensor node and anchor is denoted by a point in B. Let n denote the total number of anchors, Initially each anchor broadcasts a beacon containing its location information. Then, each sensor node collects the RSSI values of all its neighbor anchors through these beacons. The RSSI value read by a sensor node obeys the wide log-normal shadowing radio signal propagation model [19]:
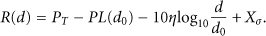
In (1),
Given these known RSSI values, the locations of sensor nodes can be estimated by a localization algorithm. The major measurement of a localization algorithm is the average localization error, defined as the average distance between the actual location and the estimated location of each sensor node [5]. Because wireless sensor networks often work in unfriendly environments, some anchors may be faulty, which means they have incorrect information about their own locations. Therefore, fault tolerance is also important to a localization algorithm. In this paper, we define it as the ability to maintain a good localization result even if some anchors are faulty. Besides, execution time is also a common measurement of a localization algorithm.
4. Algorithm Description
In this section, we will describe our proposed localization algorithm based on maximum a posteriori. Consider a sensor node s. Let (
Let

Because each sensor node is uniformly distributed in B, s has the same probability in each grid, that is, for all

Moreover, because s is also uniformly distributed in

When s is at a certain point in B, the RSSI value of each anchor read by s is not interfered with the RSSI values of other anchors. Therefore, under the condition that

According to (5), we need to calculate

Let

Combine (6) and (7), and we obtain the following equation:

We have

It can been seen from (9) that if

That is for the variable
Furthermore, we analyze (10). Let

Combine (10) and (11), and we obtain the following equation:
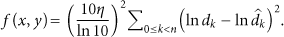
Equation (12) illuminates that the optimum estimated location of s should be the point with the minimum value of
5. Performance Evaluation
5.1. Simulation Environment
To evaluate the performance of our proposed localization algorithm based on maximum a posteriori (MAP), we developed a simulation program realizing MAP algorithm. We compare MAP algorithm with the least-squares trilateration (LST) in which the point with the minimum value of
In the simulation, the target region B is a square region of 1000 m × 1000 m. The transmission range of anchors is 1500 m. Sensor nodes and anchors are randomly and uniformly distributed in B. The RSSI value read by a sensor node is simulated according to (1). The value of each parameter is taken from a typical wireless sensor network [19]:
5.2. Grid Size
In MAP algorithm, the target area is divided into small grids to approximately obtain the point with the maximum probability density. The smaller the grid is, the closer the approximate solution is to the accurate solution, but the larger the amount of calculation is. Therefore, we first need to select the appropriate grid size. In the simulation, σ is set to 5, the number of anchors is set to 20, the number of sensor nodes is set to 100, and the side length of grid varies from 5 m to 100 m. Figure 1 shows the average localization errors of MAP algorithm. It can be seen that when the grid size is relatively large, the average localization error is significantly impacted by the grid size. But when the grid size of grid is small to a certain extent, this impact is almost negligible. In the following, we will take the grid size as 10 m × 10 m.
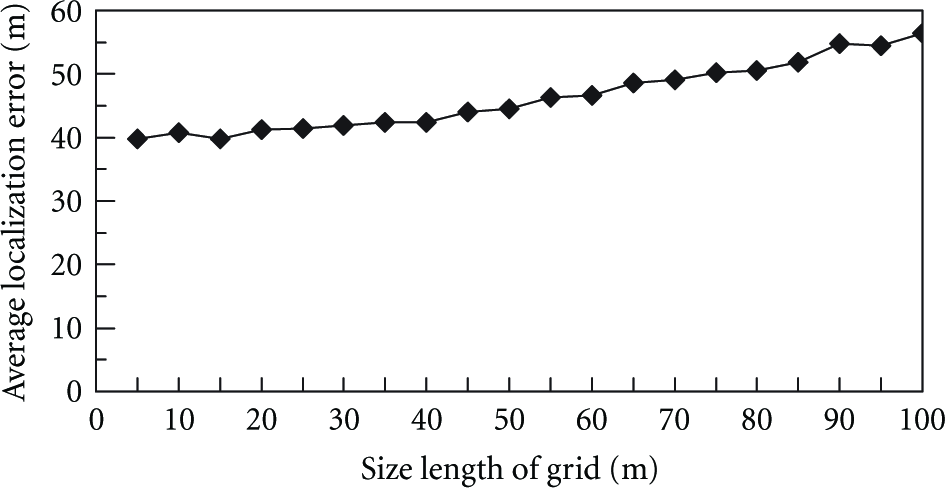
Average localization errors of MAP algorithm under different grid sizes.
5.3. Localization Error
Figure 2 shows a localization result of MAP algorithm and LST algorithm. Both algorithms have the same inputs: σ is set to 5, the number of anchors is set to 20, and the number of sensor nodes is set to 100. It can be seen that the estimated location of most sensor nodes computed by MAP algorithm are closer to their actual locations. Accordingly, MAP algorithm has a smaller average localization error than LST algorithm.

A localization result of MAP algorithm and LST algorithm. In the figure, the solid points represent the actual locations of sensor nodes, the hollow points represent the estimated locations of sensor nodes computed by MAP algorithm, and the cross points represent the estimated locations of sensor nodes computed by LST algorithm.
Next, we test how the localization error is impacted by the number of anchors. In the simulation, σ is set to 5, the number of sensor nodes is set to 100, and the number of anchors varies from 5 to 25. It can be seen from Figure 3 that with the number of anchors increasing, the average localization errors of both algorithms are reduced. But MAP algorithm can achieve a smaller average localization error, which is reduced by nearly 34.8% compared with the least-squares trilateration.

Average localization errors of MAP algorithm and LST algorithm under different numbers of anchors.
Then, we test how the location error is impacted by the layout of anchor nodes. In the simulation, σ is set to 5, the number of sensor node is set to 100, the number of anchors varies among 4, 9, 16, 25, 36, and 49, and anchors are placed by the random layout and the grid layout, respectively. Figure 4 shows the average location errors of MAP algorithm under these two layouts. The average location error under the grid layout is nearly 87.8% of that under the random layout. Therefore, anchor nodes should be placed by the grid layout in practice.
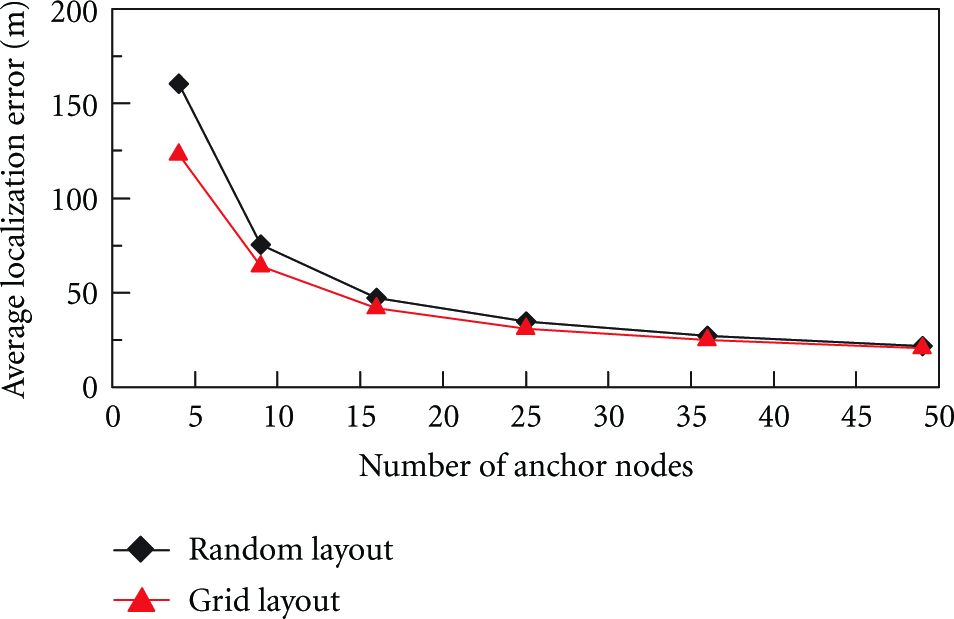
Average localization errors of MAP algorithm under the random layout and the grid layout of anchor nodes.
The ranging error is a primary cause of the localization error, which depends on σ: the larger σ is, the larger the ranging error is. In the simulation, the number of anchors is set to 20, the number of sensor nodes is set to 100, and σ varies from 2 to 14. Figure 5 shows the average localization errors of MAP algorithm and LST algorithm. It can be seen that the average localization errors of both algorithms are approximately proportional to σ.

Average localization errors of MAP algorithm and LST algorithm under different values of σ.
5.4. Fault Tolerance
In MAP algorithm, the location of each sensor node is determined by all its neighbor anchors. If only a small number of anchors are faulty, the estimated location of each sensor node cannot have a big change. In the simulation, σ is set to 5, the number of anchors is set to 20, the number of sensor nodes is set to 100, and the number of faulty anchors varies from 0 to 10. Figure 6 shows the average location errors of MAP algorithm and LST algorithm. It can be seen that when less than 25% of anchors are faulty, the average localization error of MAP algorithm increase less than 85%.
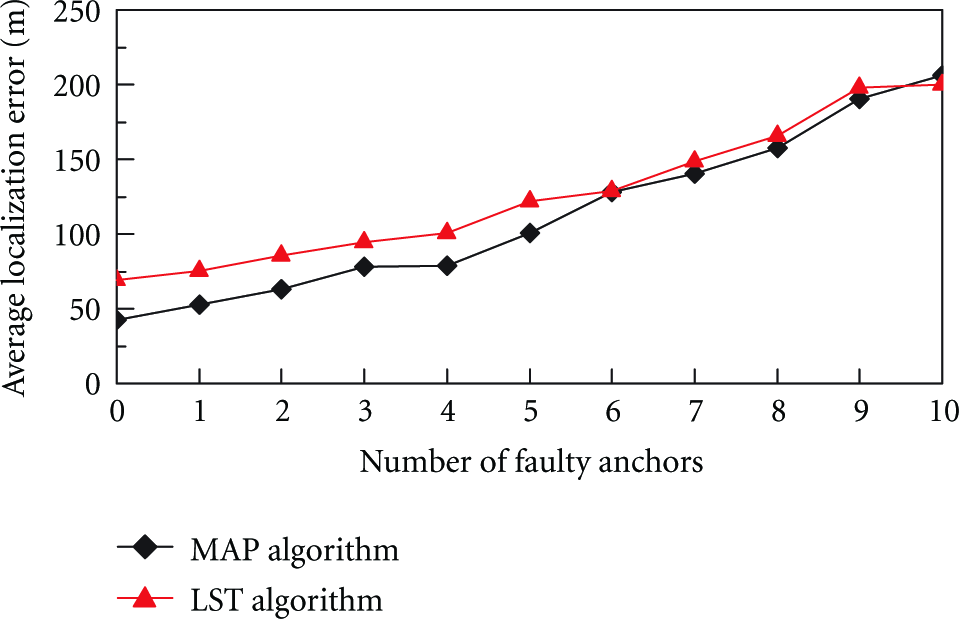
Average localization errors of MAP algorithm and LST algorithm under different numbers of faulty anchors.
5.5. Execution Time
Finally, we analyze the average execution time of MAP algorithm by simulation. In the simulation, the number of sensor nodes is set to 100. Figure 7 shows the average execution times of the two algorithms under different numbers of anchor nodes when the size of grid is 10 m × 10 m. Figure 8 shows the average execution times of the two algorithms under different grid sizes when the number of anchors is 20. It can be seen that the execution times of both algorithms are approximately proportional to the number of anchor nodes and are approximately inversely proportional to the acreage of grid. This result is consistent with the analysis in Section 4. In a general case, MAP algorithm can localize a sensor node in a short time. Since MAP algorithm has a more complicated calculation than LST algorithm, the execution time of MAP algorithm is longer.
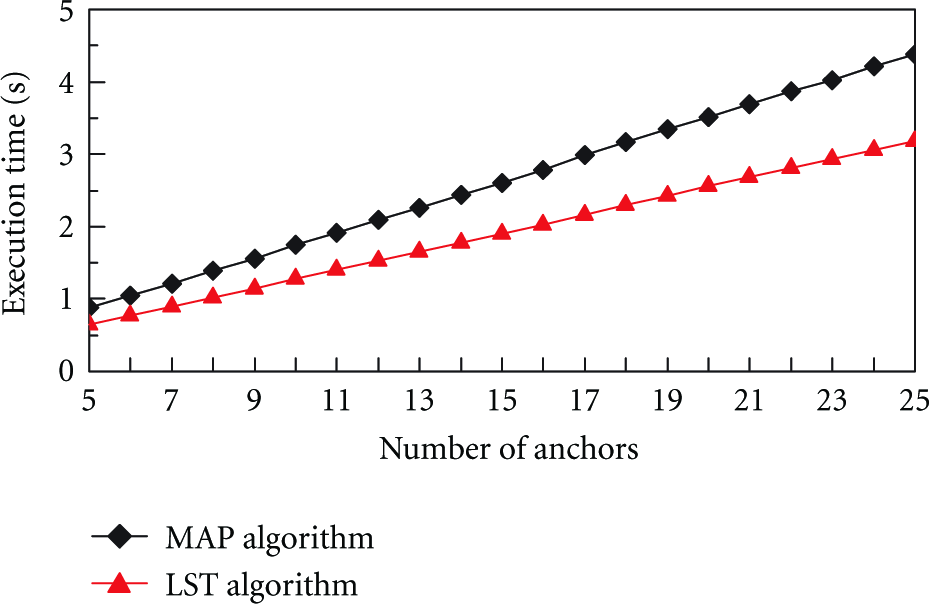
Execution times of MAP algorithm and LST algorithm under different number of anchors.

Execution times of MAP algorithm and LST algorithm under different grid sizes.
6. Conclusion
RSSI ranging-based localization is regarded as a cost-effective solution for sensor node localization. But RSSI ranging technique has a large ranging error, which will bring a large average localization error to the general least-squares trilateration. In this paper, we propose a localization algorithm based on maximum a posteriori probability (MAP). In this algorithm, the point with the maximum probability density in the target region is taken as the estimated location of a sensor node. Extensive simulation results demonstrate the effectiveness of MAP algorithm. This algorithm reduces the average localization error by nearly 34.8% compared with the least-squares trilateration. Even if the number of anchors is small, this algorithm can also achieve a relatively small average localization error. In addition, the execution time of this algorithm is very short.
As a future work, we are currently studying when anchors are absent, how to determine the probability density of the distribution of a sensor node only by the RSSI values of sensor nodes. Moreover, we plan to conduct some practical experiments to confirm the effectiveness of our proposed algorithm.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their helpful comments which have significantly improved the quality of the paper. This paper was supported by the National Natural Science Foundation of China (Grant no. 61003272, no. 61033009, no. 61170076, and no. 61103001), the Guangdong Natural Science Foundation (Grant no. 10351806001000000), and the Shenzhen Science and Technology Foundation (Grant no. JC201005280408A and JC2009D3120046A).