
Abstract
Performance analysis is crucial for designing predictable and cost-efficient sensor networks. Based on the network calculus theory, we propose a flow-based traffic splitting strategy and its analytical method for worst-case performance analysis on cluster-mesh sensor networks. The traffic splitting strategy can be used to alleviate the problem of uneven network traffic load. The analytical method is able to derive close-form formulas for the worst-case performance in terms of the end-to-end least upper delay bounds for individual flows, the least upper backlog bounds, and power consumptions for individual nodes. Numerical results and simulations are conducted to show benefits of the splitting strategy as well as validate the analytical method. The numerical results show that the splitting strategy enables much better balance on network traffic load and power consumption. Moreover, the simulation results verify that the theoretic bounds are fairly tight.
1. Introduction
With the advances of wireless communications and microelectronics technologies, wireless sensor networks (WSNs) have received more and more attention over the last decades due to their potential in a variety of application domains [1–4], such as environment monitoring, human activity tracking, healthcare, and military assistance, and so forth.
A typical sensor network consists of a larger number of sensor nodes that are capable of sensing the environment and forwarding their observation values to a fusion center (sink) through multihop wireless links. Thus, the traffic pattern in sensor networks is usually in a many-to-one manner. The nodes near the sink may need to forward more data and thus require more energy consumptions and bigger buffers than the nodes far away. Consequently, the distributions of energy and buffer requirements in WSNs are extremely uneven. However, energy supplies and buffers are limited and expensive resources in typical WSNs, since sensor nodes are usually made as tiny devices with limited buffers and equipped with batteries that may not be convenient or economical for replacement. One way to address these challenges is applying traffic splitting strategies which have been adopted by many researchers for load balancing in communication networks [5, 6]. With traffic splitting, a main flow is divided into several subflows and forwarded to the destination through different routing paths. By distributing traffic over the network, the overall network load balance can be improved. It is shown in [7] that the spare capacity can be reduced and thus the overall performance of the system can be improved by splitting traffic across multiple disjoint paths.
One popular application of WSNs is real-time monitoring and tracking, such as logistic chain tracking [4] and healthcare application [8]. In such kind of applications, it is crucial to ensure sensor data delivered to the sink within time constraints so that appropriate actions can be made. In order to design a WSN with predictable delay, backlog, and energy consumptions, formal performance analysis is desired for analyzing a sensor network before its actual deployment. While simulation-based methods can offer high accuracy, it can be very time-consuming and tedious to find the worst-case performance. Each simulation run may take considerable time and evaluates only a single network configuration, traffic pattern, and load point. Hence, formal methods are desired to dimension sensor networks in an analytical way rather than case-by-case simulations. Starting with the initial work by Cruz [9, 10], network calculus has been developed as a useful tool for the performance analysis of networked system [11]. In contrast to queueing theory, network calculus deals with performance bounds, such as worst-case delay and backlog bounds, rather than average values. It has been applied to sensor networks by many researchers recently [12–15].
In this paper, we propose a flow-based traffic splitting strategy and its analytical method for worst-case performance analysis on cluster-mesh sensor networks based on the network calculus theory. We introduce the flow-based traffic splitting strategy, which is useful in balancing not only network load but also power consumption. Aiming to evaluate the worst-case performance in terms of end-to-end least upper delay bound, least upper backlog bound, and power consumption, a splitting model is built for a single-node analysis and an analytical method is proposed for the network analysis. Through an example, we show that the performance analysis method is able to derive closed-form formulas of these bounds. The numerical results indicate that the backlog and power consumption can be balanced by applying the traffic splitting strategy. In addition, simulations are performed to validate the performance bounds of our analytical method. The results show that their tightnesses are satisfactory.
The rest of this paper is organized as follows. Section 2 introduces related work. Section 3 contains preliminaries including the cluster-mesh network topology and power consumption model, and basics of network calculus. Section 4 includes performance analysis of the flow-based traffic splitting strategy. An analysis example is given in Section 5. Numerical results and simulations are presented in Section 6. Finally, conclusions and directions for future work are given in Section 7.
2. Related Work
In general packet switching networks, network calculus provides methods to deterministically reason about timing properties and resource requirements. Based on the powerful abstraction of arrival curve for traffic flows and service curve for network elements, it allows computing the worst-case delay and backlog bounds. Systematic accounts of network calculus can be found in books [11, 16].
Network calculus has been extremely successful for ensuring performance bounds when applied to ATM, Internet, and other networks. It is recently extended and applied for performance analysis and resource dimensioning of WSNs by several researchers. In [12], Schmitt and Roedig firstly applied network calculus to sensor network and proposed a generic framework for performance analysis of WSNs with various traffic patterns. They further extended the general framework to incorporate computational resources besides the communication aspects of WSNs [14]. In [13], Kouba et al. proposed a methodology for the modeling and worst-case dimensioning of cluster-tree sensor networks. They derived plug-and-play expressions for the end-to-end delay bounds, buffering, and bandwidth requirements as a function of the WSN cluster-tree and traffic characteristics. Lenzini et al. [17] proposed a method for deriving tight end-to-end least upper delay bounds in sink-tree networks. The least upper delay bound is defined as the minimum value of the upper delay bound. In [15], the authors presented a method for computing the worst-case delays, buffering, and bandwidth requirements while assuming that the sink node can be mobile.
Traffic splitting strategies have several common features with multipath routing protocols. There have been plenty of research works on multipath routing and traffic splitting for sensor networks [18–23]. The authors in [18] proposed a multipath routing scheme that finds several disjoint paths. In this scheme, the source node or an intermediate node chooses one path from the available paths to deliver the data to sink based on the performance requirements such as delay and throughput. An energy efficient multipath routing protocol for WSNs with multiple sinks is presented in [19]. The path construction is implemented by the source node sending route messages to its neighbors. Traffic is distributed over the multiple paths according to a load balancing algorithm. The results show that the proposed scheme results in a higher energy efficiency. In [20], authors proposed an N-to-1 multipath routing protocol, in which nodes are arranged in a spanning tree. Multipaths are constructed by traversing the tree. The multipath scheme is a combination of end-to-end multipath traffic dispersion and per-hop alternate path salvaging. Zou et al. [21] studied the interplay between data aggregation and flow splitting in WSNs and proposed a flow-based scheme. The flows are preserved until the aggregation point. The aggregated data is splitted into multiple flows on the rest of the path to the destination. The results show that the scheme can balance energy consumption and therefore prolong the lifetime of WSNs. In [22], the authors investigated a joint coding/routing optimization of network costs and capacity in WSNs. By combining the link rate allocation and network coding-based multipath routing, the total energy consumption of encoding power, transmission power and reception power can be reduced. A backpressure collection protocol (BCP) for sensor networks is presented in [23]. In this protocol, routing and forwarding decisions are made based on a per-packet basis. By using ETX optimization and floating LIFO queues, BCP is capable of improving throughput and delivery performance under static and dynamic settings, respectively.
This work applies the network calculus theory for analytical performance evaluation of a traffic splitting strategy on cluster-mesh sensor networks. Our work differs from others' works and contributes to state of the art in the following aspects. First, we address the particular problem of deriving performance bounds and resource requirements for a traffic splitting strategy on the cluster-mesh topology, which we believe are of great interest for time-sensitive WSN applications. Second, we introduce a flow-based traffic splitting strategy that can be used to balance traffic load in the network. We define a splitting model and set up an equivalent packet delivery model for the original network. Based on these models, the end-to-end least upper delay bounds and backlog bounds are derived. The results show that the variance of backlogs can be greatly reduced by applying the traffic splitting strategy, which indicates better load balancing. Third, we conduct power consumption analysis, which is crucial for most applications of WSNs. The results indicate that the traffic splitting strategy also enables better balance on power consumptions. Since most applications of WSNs involve sensors with unreplaceable power supplies, better power balance would lead to longer lifetime of the whole network. On the other hand, even if the batteries of sensors can be recharged or replaced, better power balance would bring about less labor for recharging or replacing and thus can reduce the overall deployment costs. In addition, although our work focuses on performance analysis of a traffic splitting strategy on a particular network topology, we believe the intrinsic idea of the method is also very useful for analyzing sensor networks with other topologies and traffic planning policies.
We have described the traffic splitting scheme in our previous work [24, 25], from which we borrow many notations used in this paper. In this work, we have significantly extended and enhanced the previous work in the following aspects. First, in previous work, we only presented the analysis method without simulations. The analytical method in this work is validated through simulations which also prove the tightness of the delay and backlog bounds. Second, the end-to-end delay bound in [24, 25] is calculated by summing up the per-hop delay together. While, in this paper, the end-to-end delay bound is computed using the end-to-end equivalent service curve, the later method can get tighter bounds. A comparison between these two methods is shown in Figure 20. Third, we integrate power consumption analysis in this work, which we believe is of great importance for WSNs.
3. Preliminaries
This section presents system models, including the cluster-mesh network topology and power consumption model.
3.1. The Cluster-Mesh Topology
A wireless sensor network may consist of a large number of sensors that are densely deployed either inside the phenomenon of interest or close to it. These sensors can be organized in various topologies, such as mesh- and cluster-based topologies. The mesh networking has advantages like supporting path diversity which enables better balance on traffic load and energy consumption [26]. The cluster-based topologies are also quite suitable for WSNs with demanding requirements in terms of Quality of Service (QoS) support and real-time communications [13]. Considering these aspects, we adopt the cluster-mesh topology that merges advantages of mesh and cluster [3, 27]. It is a two-layered architecture with the mesh defining a backbone that consists of a set of cluster heads (CHs). A cluster is formed by grouping a number of sensors within a geographic neighborhood. We define the network composed by cluster heads and the sink as the layer-1 network and the network inside a cluster as the layer-2 network.
In summary, the cluster-mesh network contains three types of nodes: sink, cluster head, and sensor. Like in most sensor networks, the sink is responsible for controlling the network and collecting data from all the other nodes. A cluster head and multiple sensors form a cluster. In order to reduce the cost and complexity, sensors do not communicate with each other and data generated by them is collected by their cluster head and delivered to the sink through neighbor cluster heads. For simplicity and conciseness, we consider cluster heads are static and they do not sense the environment and generate input data. However, this assumption can be easily relaxed, and the subsequent analysis is straightforward. In the mesh network composed by cluster heads and the sink, links are considered bidirectional.
Figure 1 shows an example of the cluster-mesh topology. A cluster-mesh network is a mesh network where each cluster head and its connected sensors form their own logical cluster. The layer-1 network can be modeled as a direct graph

A cluster-mesh sensor network.
3.2. Power Consumption Model
In most types of sensor nodes, the energy consumption is mainly contributed by the transmitter, receiver, and computation module [28]. We consider the application scenario of sensor networks for fresh food monitoring in warehouses. In this scenario, sensors may perform tasks and send packets periodically. Consequently, the power consumption of the computation module can be considered as nearly constant denoted by
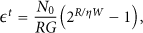

Energy per bit versus transmission rate [29]:
Therefore, the total power consumption

3.3. Traffic Model and Service Model
As stated in the previous section, sensor nodes inside a cluster generate input data and then send them to their cluster head. A traffic flow is defined as an infinite stream of data from a source to a destination. Following network calculus, we model the input flow at a cluster head using its cumulative traffic


(a) An affine arrival curve: the arrows show the packet generation process. (b) A rate-latency service curve.
Service curve is an abstraction to model the processing capability of a node, depending on link layer characteristics, such as transmission rate, channel characteristics, and packet scheduling. The node and the channel together are modeled as a network element which provides a service curve
In wireless networks, data transmission over wireless channels is usually unreliable due to their inherent uncertainties. The actual transmission rate and success probability are influenced by the transmission power, path loss, noise power, and interference. In spite of these uncertainties, deterministic network calculus can still be useful in modeling wireless networks by making reasonable assumptions and abstractions. First, the uncertainties in some applications of WSNs are low. An example scenario for which our framework suits well is the process monitoring and tracking in logistics systems [4]. Second, the link unreliability and data loss rate can be mitigated by applying high transmission powers, especially for the cases with small distances between a transmitter and a receiver. Third, the interference between adjacent nodes can be alleviated by using appropriate MAC layer protocols. There are plenty of research works on designing TDMA-based link protocols which can create collision-free slot schedules [31, 32].
Based on these assumptions about link reliability and interference, we can abstract and approximate the service capability of a node by a deterministic service curve with the idea of effective transmission rate. From information theory, the Shannon capacity of a wireless channel can be expressed as
3.4. Delay, Backlog, and Output Bounds
Given the arrival curve and service curve of a node, the least upper delay bound, least upper backlog bound, and output bounds can be derived according to network calculus [11]. The least upper backlog bound is defined as the minimum value of the upper backlog bound. Consider a node i provides a service curve

Moreover, the least upper backlog bound of node i can be calculated by

Additionally, the arrival curve of the departure flow can be derived by

4. Analysis of the Flow-Based Traffic Splitting Strategy
In this section, we first introduce the splitting and multiplexing models. Then, the formal performance analysis procedure is presented. After that, we discuss the scope and assumptions of our analysis approach.
4.1. The Splitting Model
To analyze the splitting strategy, we build a splitting model that identifies the relations of input, output, delay, and backlog for a single node. Without losing generality, we consider a main flow is split into two subflows. The node

(a) The main flow
We consider that the node performs a weighted proportional splitting scheme, in which the main flow is split according to the configured weights,
Consider a main flow

Let the splitter provide a service curve

Analogously, the equivalent service curve for

Furthermore, the equivalent bounds on backlogs can be calculated by

Therefore, the least upper bound of the total backlog is computed by

The least upper delay bounds consist of three parts: the processing time, the time to serve input burstiness, and the scheduling delay. Let

Furthermore, the departure arrival curves of

4.2. The Multiplexing Model
In order to analyze resource sharing when multiple input flows share the bandwidth of a link at a node, we propose a multiplexing model. We shall use this model for analyzing a network with various traffic flowing scenarios.
Without loss of generality, let us consider a node serve two flows
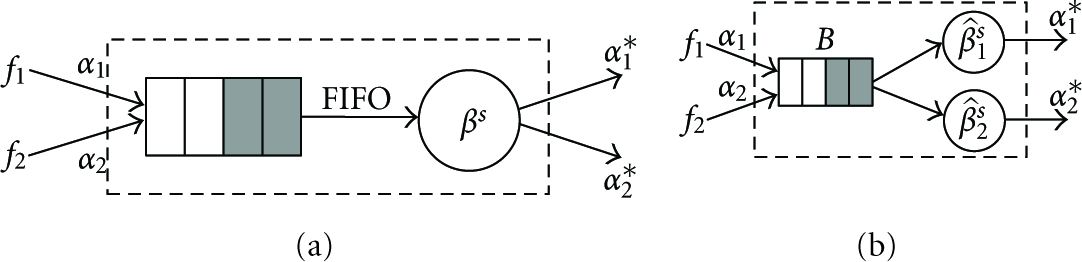
(a) A node serves two input flows. (b) The equivalent model.
We give an example to show how to compute

The least upper delay bound of

Furthermore, the least upper backlog bound of the node can be derived by

Additionally, the arrival curve of the departure flow of
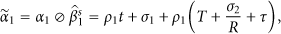
4.3. The Splitting-Based Performance Analysis Procedure
There have been several research works on the traffic splitting strategy in packet networks [6, 7], due to its efficiency in load balancing. In the flow-based splitting strategy, a traffic flow is split into multiple subflows at its source node, and these subflows are forwarded to the sink through different routing paths. The source node decides how the subflows are split. Given the traffic patterns, service models, the routing protocols, and the splitting strategy, we then detail the general performance analysis procedure as follows.
Step 1.
Based on the traffic pattern, routing protocols, and the traffic splitting strategy, construct a performance analysis model that converts the original network into an equivalent network.
Step 2.
Derive the input and departure arrival curves of all nodes in the network based on network calculus.
Step 3.
Derive the end-to-end equivalent service curves for the subflows; then compute the end-to-end least upper delay bound for the main flow using
Step 4.
Using the results in Step 2, compute the least upper backlog bound of each node
Step 5.
Compute the power consumption of a node s by
4.4. Discussions
4.4.1. Flow-Based Splitting versus Multipath Routing
Basically, a traffic splitting process consists of two stages: establishing multiple routing paths and allocating traffic on each path according to the splitting strategy. Multipath routing is a technique exploiting routing diversity by using multiple source-destination pairs. It has been receiving plenty of research attentions [33, 34]. There are plenty of works in the literature on how to set up multiple routing paths in ad hoc networks [18, 34, 35]. Our work focuses on analyzing the performance of the splitting strategy rather than finding multipath routes. We assume that multiple paths have already been established between source nodes and the sink.
There are several common features between multipath routing and flow-based traffic splitting: first, both of them use multipaths to explore routing diversities; second, both of them aim for improving load balance. Apart from these common features, there exist significant differences between them. In multipath routing, routing decisions are made on a per-packet basis, this is, each packet chooses its routing path and is forwarded to the destination individually. Multipath routing is mainly used for improving network performance in terms of reliability and robustness [33, 34]. While in flow-based splitting strategy, the routing and forwarding is made on a per-flow basis. So it is capable of realizing a controlled splitting and providing quality of service. For example, if there are two paths between a source and a destination, a flow may be split half to one path and half to the other. So the delay guarantees can be reasoned about.
4.4.2. Flow-Based Splitting versus Node-Based Splitting
According to the way that a traffic flow split, the traffic splitting strategy can be classified into two categories: flow-based splitting and node-based splitting.
In flow-based splitting, the source node decides how the subflows are scheduled and split. The subflows can be identified after splitting. As shown in Figure 6(a), the traffic flow
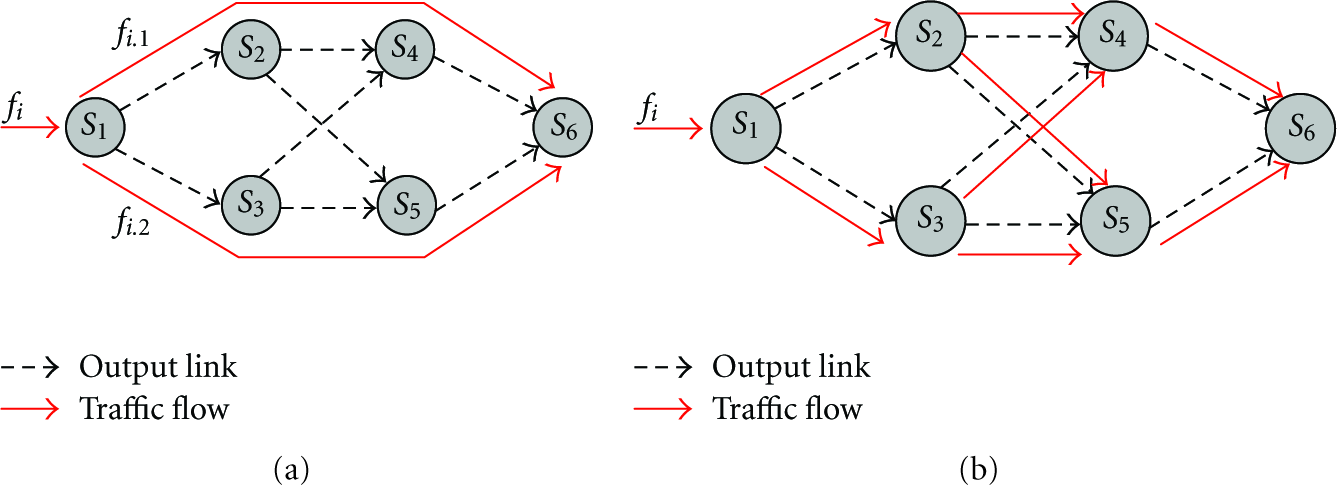
An example of splitting strategies.
4.4.3. How to Set Splitting Parameters?
Our work mainly provides a framework for quality of service analysis of the flow-based splitting strategy. Another research issue is on splitting parameter exploration, that is, how to set splitting factors? One way is to utilize static network state information, such as link capacity and buffer length, to set splitting parameters. For example, in Figure 6(a), source node
5. An Analysis Example
In this section, we exemplify the general performance analysis and derive close-form formulas for of delay bounds, backlog bounds, and power consumptions under the conditions of affine arrival curve and rate-latency service curve. Consider a network consists of four nodes as shown in Figure 7. We define the tagged main flow as the main flow for which we shall derive the end-to-end delay bound. In this example, we choose

(a) A network analysis example: the main flow
In order to compute the end-to-end least upper delay and the least upper backlog bounds, we first need to derive the input and departure arrival curves of each node.
5.1. Arrival Curves of Input and Output
According to the results of the splitting model, the arrival curves of departure flows at node

Node

For node

According to the connection relations, we can get the arrival curves of three input flows at node
5.2. The End-to-End Delay Bound
In order to compute the end-to-end delay bound, we first need to derive the service curve provided by individual nodes. Let


Analogously, the end-to-end equivalent service curve for
After we get the end-to-end service curves, the least upper delay bounds of

Hence, the end-to-end least upper delay bound for the flow

5.3. The Backlog Bound
Let

Node

Analogously, the least upper backlog bounds of node
5.4. Power Consumption
According to the power model (Section 3.2), the total power consumption of a node is contributed by the radio transmitter, radio receiver, and computation electronics. Thus, the power consumptions of all the nodes can be computed by

6. Performance Evaluation
To show benefits of the traffic splitting strategy and validate the network calculus-based performance analysis method, we provide numerical results and simulations under the scenario of a fresh food monitoring application. In the numerical results, the end-to-end least upper delay bounds, the least upper backlog bounds, and power consumptions are compared under two scenarios: general routing with no traffic splitting (NOS) and flow-based splitting strategy (FBS). In the simulations, we compare the results obtained by the analytical method with the simulation results also under these two scenarios.
The numerical results are based on an application example of a real-time fresh food monitoring system deployed in a warehouse [3, 4]. As shown in Figure 8, one sink and 9 cluster heads are uniformly distributed in a 20 m × 10 m warehouse. Each cluster head connects with 5 sensor nodes. The coordinates of cluster heads and sink (

A cluster-mesh sensor network:
6.1. Numerical Results
Assume sensor nodes in cluster
Parameters.


(a) General routing with no splitting (NOS): the tagged main flow
From the power model in (1) and Figure 2, the energy per bit is a monotonically increasing function of the transmission rate [29] if other parameters are fixed. Thus, it is better to use low transmission power for the sake of energy efficiency. On the other hand, the delay bound is a monotonically decreasing function of the service rate. (e.g., given an arrival curve
We compare the end-to-end least upper delay of
6.1.1. Uniform Service Rate
In the first numerical example, we choose a fixed service rate
Figure 10 shows the comparison of the end-to-end least upper delay bounds of the tagged main flow
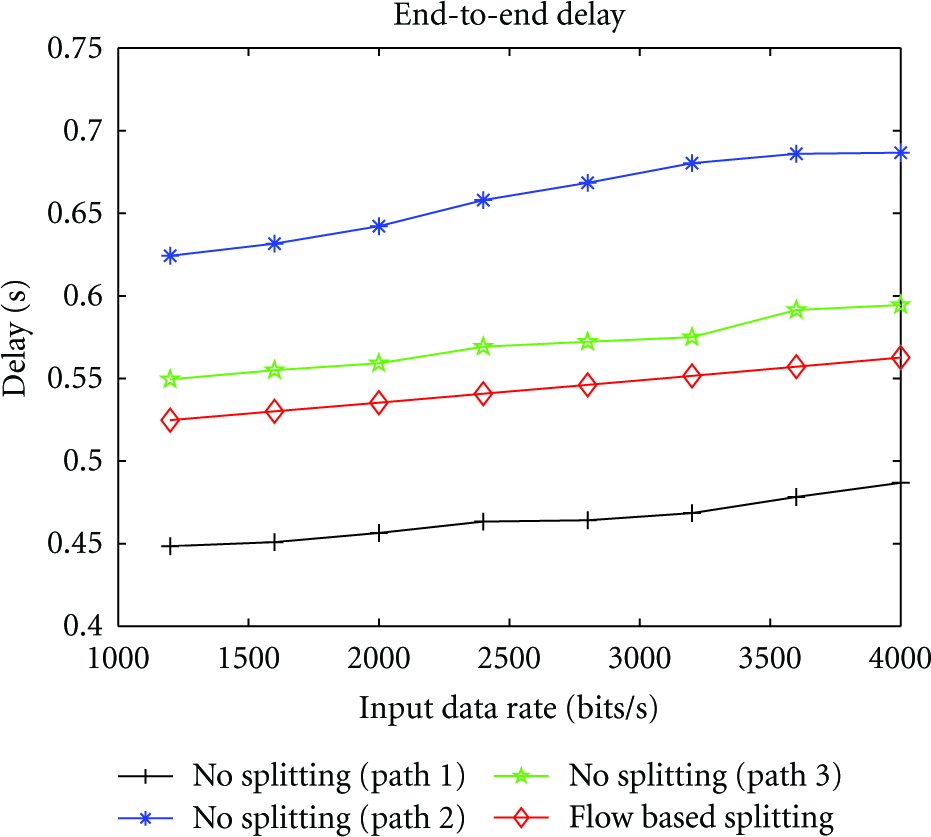
End-to-end least upper delay bound.
Figure 11 shows the least upper and average backlog bounds in the FBS and NOS scenarios with input data rates vary, where “Max-B(NOS)” means the maximum backlog in NOS which denotes the maximum value of backlogs among all nodes and “Ave-B(FBS)” means the average backlog in FBS which denotes the average value of backlogs over all nodes. From this figure, we can find that both the maximum and average backlogs in FBS are less than those in NOS. It indicates that the traffic splitting strategy can reduce backlogs. Moreover, the differences between the maximum backlogs of the two scenarios are much bigger than those of average backlogs. The average backlogs in FBS are 14.5% less than those in NOS on the average. While the maximum backlog in FBS is 23.4% less than that in NOS when the input data rate is 1.2 kbps, and the value increases to 40% when the input data rate is 4 kbps. We can also observe similar reduction in the variance of maximum backlogs (as shown in Figure 12), where the variance of backlogs in NOS is much bigger than that in FBS. It means that in NOS some nodes have very small backlogs, but some nodes have very large backlogs. Since the buffer size of a sensor node is basically determined by the value of maximum backlog, larger backlog would bring higher hardware cost. Therefore, applying the flow-based splitting strategy can bring better load balance and thus reduce overall cost.

Least upper backlog bounds (in NOS: flow 1 chooses path 3).

Variance of least upper backlog bounds (in NOS: flow 1 chooses path 3).
The maximum and average power consumptions of all nodes in NOS and FBS are shown in Figure 13, where “Max-P(NOS)” and “Ave-B(NOS),” respectively, denote the maximum and average power consumptions in the NOS scenario. First, we see from the figure that all the power consumptions increase with the input data rates. Furthermore, when the data rate increases, the average power consumptions in the NOS and FBS are almost the same. However, the maximum power consumption in NOS increases much faster than that in FBS, with the maximum differences between FBS and NOS increasing from 0.8% to 12%. It indicates that the power consumptions of nodes are uneven in NOS. We can also see this from Figure 14 showing the variance of power consumption of all nodes. From this figure, we can find the variance in NOS increases much faster than that in FBS. Usually, the lifetime of a WSN is determined by the first node exhausting its energy. Hence, the flow-based splitting scheme can be used for balancing power consumption and consequently increasing the lifetime of the network.

Power consumption (In NOSi: flow 1 chooses path i, where

Variance of power consumption.
6.1.2. Heterogeneous Service Rate
The data rate of
Being different from Figure 10, the end-to-end delays of FBS are basically bigger than those of NOS in this case (Figure 15). Moreover, when the input data rate increases, the end-to-end delay decreases. The reason is that the service rate increases with the input data rate. While the input burstiness is the same, so the delay would decrease.

End-to-end delay.
Figure 16 shows the comparison of backlog bounds in the FBS and NOS scenarios. From this figure, we can find that the average backlogs in FBS and NOS are almost the same. While the maximum backlog in FBS is −2.4% less than that in NOS when the input data rate is 1.2 kbps, the value gradually increases to 12.8% when the input data rate gradually increases to 4 kbps. Similar to Figure 12, from Figure 17, we can see that the variance of backlogs in NOS is bigger than that in FBS. It also means that in NOS some nodes have very small backlogs, but some nodes have very large backlogs.

Least upper backlog bounds (in NOS: flow 1 chooses path 3).

Variance of least upper backlog bounds (in NOS: flow 1 chooses path 3).
In the case of heterogeneous service rates, we see from the figure (Figure 18) that all the power consumptions increase with the input data rates. Furthermore, the average power consumptions in the NOS are approximately 11.4% bigger than those in FBS. However, the maximum power consumption in NOS increases much faster than that in FBS, with the maximum differences between FBS and NOS increasing from 23.9% to 33%. The differences of maximum power consumption in this case are much bigger than those in uniform service rate case Figure 13. We can also see this from Figure 19 showing the variance of power consumption. From this figure, we can find the variance in NOS increases much faster than that in FBS.

Power consumption (in NOSi: flow 1 chooses path i, where
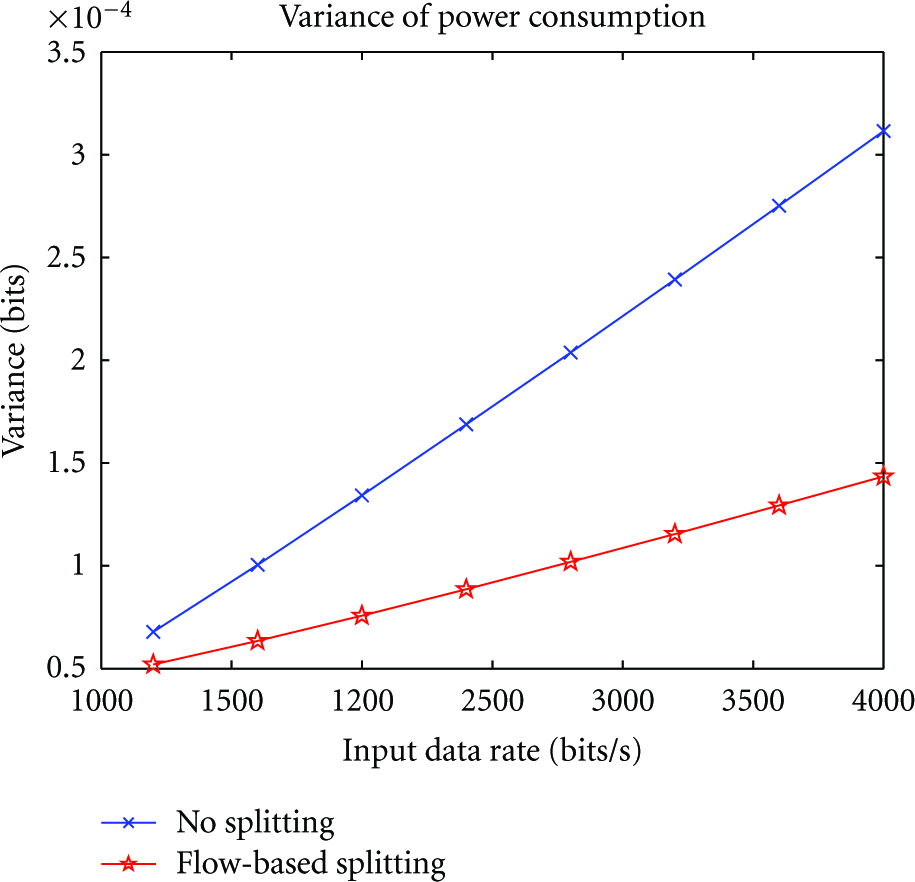
Variance of power consumption.

Compare the end-to-end delay computed by two methods.
From all those results and comparison, we can have the following conclusions: first, applying FBS strategy can balance traffic load and power consumption, so as to reduce overall system cost and increase the network lifetime. Second, there is a tradeoff between power consumption and system performance. Under uniform service rate, the end-to-end delays of FBS are less than those of NOS in most cases, and the power consumptions of FBS are slightly less than those of NOS. While under heterogeneous service rates, the end-to-end delays of FBS are generally bigger than those of NOS, but the power consumptions of FBS are much less than those of NOS. It means that the decreasing of power consumption is obtained at the cost of increasing delay.
6.1.3. Comparison of End-to-End and Hop-by-Hop Methods
As stated in [24], there are two ways to compute the end-to-end delay bound. The first method is summing up the per-hop delay together. The main idea of the other method is to derive an equivalent service curve for a given traffic flow. And then the end-to-end delay bound is calculated using the equivalent service curve. In [24], we use the first method (hop-by-hop). While in this paper, we adopt the second method (end-to-end). Figure 20 illustrates the comparison of these two methods in the scenario of FBS and NOS. In average, the hop-by-hop delay in NOS is 26.4% bigger than that of the end-to-end delay. And, in FBS, the hop-by-hop delay is 22.5% bigger than that of the end-to-end delay. Therefore, the end-to-end method can get tighter bound than the hop-by-hop method.
6.2. Simulation Results
Since a simulation environment allows us to create a realistic sensor network behavior while still controllable, we conduct experiments in a simulation environment based on OMNeT++ 3.3 rather than in a field trial. We define tightness as the ratio of maximum simulation value divided by the analytical value.
In the simulation, we use a most common log-normal path loss model [38]. This model can provide more accurate multipath channel models than Rayleigh and Nakagami models for indoor environments [39]. The simulation is also based on the application scenario shown in Figure 8. Parameters used in simulations are the same as those in Table 1. Other parameters used are
Figures 21 and 22 show the comparison of simulation results and analytical results of end-to-end delays of flow

End-to-end delays in NOS.

End-to-end delays in FBS.
For the backlog analysis, node
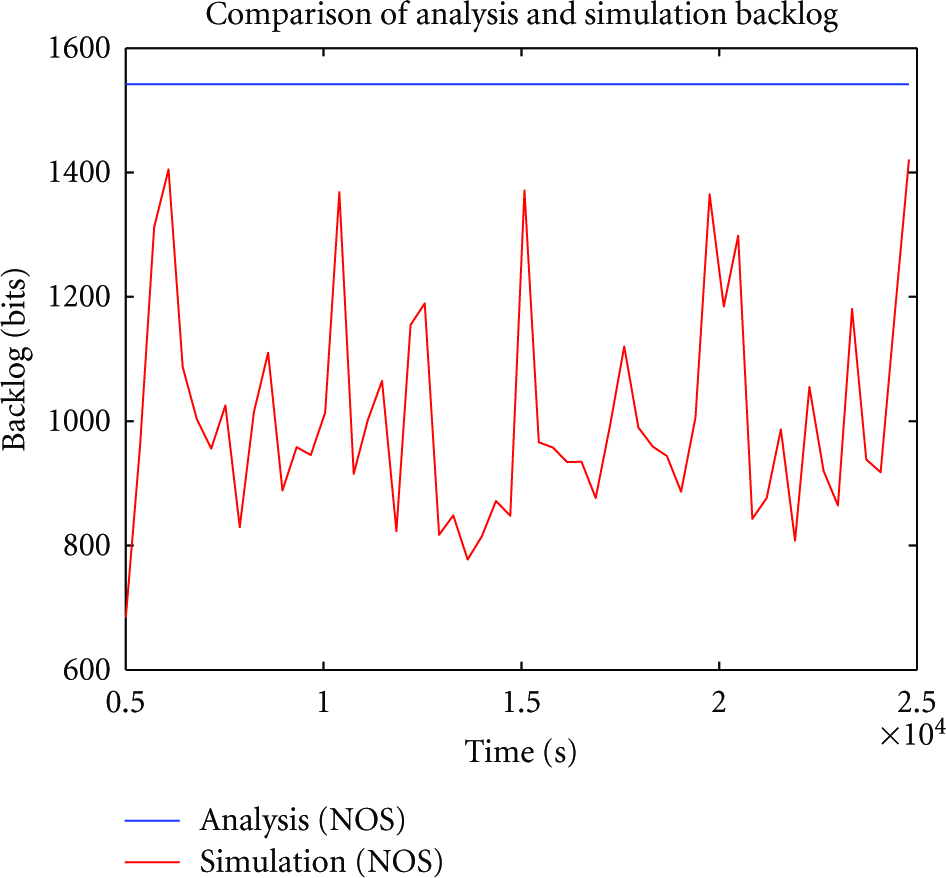
Nodes' backlogs in NOS.

Nodes' backlogs in FBS.
7. Conclusions and Future Work
Dimensioning timing-critical sensor networks requires formal methods to ensure performance and cost in any conditions. In this work, we present a network-calculus-based analysis method to compute the worst-case end-to-end delay bounds for individual flows, backlog bounds, and power consumptions for individual nodes. Based on network calculus and the splitting model, we are able to compute per-flow equivalent service curve provided by the tandem of visited nodes and the input and departure arrival curves of each node. Consequently, we can derive the performance bounds for the network which applies the flow-based traffic splitting strategy. Under the assumptions of affine arrival curve and rate-latency service curves, closed-form formulas of these bounds are computed. The numerical results for the example scenario show that, by applying the splitting strategy, the end-to-end delay can be reduced in most cases, the maximum backlog can be reduced up to 40%, and the power consumption can be reduced up to 15%. Furthermore, the simulation results verify that the theoretical bounds of our analysis are valid and fairly tight.
As stated in Section 4.4, there are several directions for future work. First, we will study the problem of designing a splitting scheme, this is, how to select splitting parameters based on network state information. Another research issue is to explore the optimized design space with given buffer sizes, performance requirements, and energy constraints for specific applications.