
Abstract
We propose sensor-to-task assignments algorithms that take into account location privacy issues. Our solutions enable the network to choose the “best” assignment of the available sensors to the tasks to maximize the utility of the network while preserving sensors’ location privacy. We focus on preserving the sensors’ locations during the assignment process in contrast to previous works, which considered location privacy while sensors are in operation. We also propose an energy-based algorithm that uses the remaining energy of a sensor as a factor to scale the distance between a sensor and a task such that sensors that have more energy appear to be closer than ones with less energy left. This does not only provide location privacy but will also consume the sensing resources more evenly, which leads to extending the lifetime of the network. From our simulations, we found that our algorithms can successfully hide sensors’ locations while providing performance close to the algorithms, which use the exact locations. In addition, our energy-based algorithm, while achieving results close to the exact location algorithm, was found to increase the network lifetime by as much as 40%.
1. Introduction
Wireless sensor networks consist of a large number of small sensor devices that have the capability to take various measurements of their environment. These measurements can include seismic, acoustic, magnetic, IR, and video information. These devices are highly resource constrained. They are equipped with a small processor and wireless communication antenna and are battery powered. To be used, sensors are scattered around a sensing field to collect information about their surroundings. For example, sensors can be used in a battlefield to gather information about enemy troops, detect events such as explosions, and track and localize targets. Upon deployment in a field, they form a wireless ad hoc network and communicate with each other and with data processing centers.
A sensor network is typically expected to perform multiple tasks. By a task we mean any job that requires some amount of sensing resources to be accomplished such as video monitoring a field, tracking a target or localizing an event. Tasks can be divided into multiple subtasks. For example, monitoring a large field can be divided into monitoring multiple smaller areas. Each task can be modeled with a profit that represents its importance. The utility (or amount/quality of information) that a sensor can provide to a task depends on several factors. These include the type of the sensor, its sensing range, its geographic location relative to the task, and its current operational status, such as its remaining energy. Because of the limited number of sensors deployed in a field and the potentially large number of tasks, competition will arise. In such cases, it might not be possible to satisfy the requirements of all tasks using available sensors.
In most cases, the utility that a sensor can provide to a task will depend on the distance between them; the closer the sensor the higher the utility it can provide. Hence, in most solutions the exact sensor's location needs to be determined to calculate its utility. That is, the sensor has to acquire its location, for example, by using GPS, and then reveal that exact location to the network control. This process, however, might not always be feasible due to security reasons especially when the sensor network is shared between multiple entities. In such case, we would like to allow these entities to use the sensor network with no or limited coordination, which is an important asset for operations. However, some entities might want to keep the locations of its sensing resources private due to their sensitivity. Consider for example a sensor network that is owned by the military and is used to monitor boarders. The military might want to share its sensing resources with researchers and scientists who would like to study the environment in a particular area but at the same time would like to keep the exact locations of its resources private. In this case, the exact locations of sensors should not be disclosed. This condition prohibits the use of current solutions, which depend on such information.
Another major concern for sensor networks is energy preservation. We would like to extend the lifetime of the network as much as possible while trying to satisfy the requirements of all tasks. To do this, we need to take into account the residual energy in each sensor that can be used by a task before we make the assignment decision.
In this paper, we will develop distributed algorithms for finding sensor-to-task assignments taking into account location privacy and energy preservation issues. We focus on detection tasks, which require a number of sensors that are close to the location to be monitored. Our algorithms enable the network to choose the “best” assignment of the available sensors to the tasks to maximize the utility of the network, that is, the total profit achieved from all tasks, while preserving sensors’ location privacy. We also propose an algorithm that takes into account the remaining energy in sensors before making any assignment decision. The goal here is to preserve the energy of sensors that have a small amount of energy left and prefer the ones that have more energy. Energy in this case is used as a factor to randomize the actual location of the sensor.
From our simulations, we found that our algorithms can successfully hide sensors’ locations while providing performance close to the algorithms which use the exact locations. In addition, our energy-based algorithm, while achieving results close to the exact location algorithm, was found to increase the network lifetime by as much as 40%.
The rest of this paper is organized as follows. Section 2 discusses related work in the areas of sensor assignment and location privacy in sensor networks. Section 3 provides the needed background. We present the different algorithms in Section 4. In Section 5, we analyze the performance of the proposed algorithms. Finally, Section 6 concludes this paper and discusses some future research directions.
2. Related Work
The general problem of choosing sensors to achieve an objective has received sizable attention lately. Several selection objectives have been considered. In [1, 2], for example, the goal is to cover the region using few sensors in order to conserve energy. The techniques used range from dividing the sensors in the network into a number of sets and rotating them, activating one at a time [1], to using Voronoi diagram properties [3] to ensure that the area of a sensor's diagram is as close to its sensing area as possible [2]. Another technique used is delayed sensor activation [4], in which sensors are initially inactive and are activated according to their coverage contribution. In that way, the schemes greedily turn on the sensors with highest probability of successfully sensing the areas of interest. Our problem is similar if we consider that covering a certain area is a task. A survey of sensor selection and assignment problems, including simple theoretical models of the problem, can be found in [5].
In [6, 7], the authors have considered several sensor-task assignment problems. In [7], the problems we considered are different from previous work since they consider multiple tasks with different priorities. These tasks contend for the same set of sensors, which calls for resolution mechanisms.
Our work extends on [8] which studied a closely related problem. In this paper, the authors considered both event detection and target localization problems and proposed solutions that use exact and fuzzy location. The main goal was to reduce the computational overhead by minimizing the number of choices a task leader has to consider. This is achieved by grouping sensors into different classes based on their location. In our work, we turn the focus on location privacy and energy preservation. We modify the algorithms that have been proposed for event detection and compare our results to theirs.
The issue of location privacy was studied recently by several researchers [9–15]. All of these works, however, focus on hiding the location of a source sensor during its operation and not during the assignment process. That is, they assume that the sensor is already in operation to perform a certain task. Our work focuses on preserving the sensors’ locations during the assignment process, that is, before the task starts.
The problem of energy preservation in sensor networks has been studied in many previous works in the literature. Both [16, 17] provide thorough surveys on this topic.
3. Background
In this section, we discuss the necessary background information. We start by introducing our system model. Next, we formally define the problem that we are trying to solve.
3.1. System Model
In our model, the sensor network consists of set of static sensors, which are directional in nature, for example, imaging sensors and directional acoustic arrays. Hence, we assume that a sensor can be assigned to at most one task at a time. The sensors are predeployed and the field and it is assumed that they know their location through the use of GPS devices or other localization mechanisms.
Although our proposed algorithms would work for any task in which the utility a sensor provides to the task depends on the distance between them, we focus on event detection tasks to facilitate the discussion. In our model, a task is specified by a geographic location, for example, detecting events occurring at location
3.2. Problem Definition
Our problem definition is similar to the one proposed in [8], which we explain next. The goal is to assign sensors to multiple ongoing tasks such that the sum of achieved profits from all tasks is maximized. The achieved profit of a task is equal to the task's original profit multiplied by the utility it receives from the assigned sensors. We base the calculation of the utility received by a task on the model in [18]. The authors of [18] presented a complicated model of sensor assignment, with an objective function that depends on the probability of detecting certain types of events, conditioned on the events occurring and the number of sensors assigned to detect the event in a given location.
In our model, given are collections of sensors and tasks. Each task is to monitor and detect events in a certain location. The utility of a sensor to a task is equal to the probability that it will, by itself, successfully detect an event if it occurs. Let
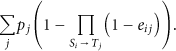
This problem is called the Cumulative Detection Probability maximization problem (MaxCDP). The utilities in this case are monotonic, that is, each sensor potentially raises the detection probability further but in nonlinear fashion. This problem has been shown to be NP-hard [8].
4. Assignment Algorithms
In this section, we introduce our algorithms for assigning sensors to tasks. We start by discussing the basic operation of the proposed algorithms. Then we discuss the operation of a generic assignment algorithm on which all the other algorithms are based. After that, we describe the different variations of the assignment algorithm, namely, the exact location, discretized location, random location, and energy-based location algorithms.
4.1. Basic Operation
The algorithms we propose below are similar in terms of operation to the algorithms we proposed in previous works [6–8]. They are distributed in nature and do not require any central node to make all the assignment decisions. This allows the leveraging of real-time status information about sensors—for example, which are operational and which are currently assigned to other tasks. Distributed algorithms are also scalable and more efficient in terms of communication cost compared to centralized approaches. As stated above, we assume a dynamic system, in which the tasks constituting the problem instances described above arrive and depart over time.
For each task, a leader is chosen, which is a sensor close to the task's location. The leader can be found using geographic-based routing techniques such as [19, 20]. Since location privacy is a concern, however, schemes such as [21], which provides geographic routing without location information, can be used. The task leaders are informed about their tasks’ locations and profits by the central command and control. Task leaders, then, run a local algorithm to match nearby sensors to the requirements of the task. Since the utility a sensor can provide to a task is limited by a finite sensing range
When nearby sensors hear this advertisement message, they propose to the leader with the utility they provide to the task at hand. To preserve location privacy, calculation of the utility may not use the exact location information. A sensor that is already assigned to a task may be reassigned to another task only if doing so will increase the total profit of the network. This is determined as follows. Assume that sensor
When a task ends, the leader sends out a message to advertise that the task has ended and all its assigned sensors are released. Because the system is dynamic, tasks that are not satisfied after the first assignment process will try to obtain more sensors once they learn there may be more available. This information can be obtained either from the base station or by overhearing the message announcing the end of a task.
4.2. Generic Assignment Algorithm
We now discuss how the leader chooses the sensors to be assigned to the task from the applicable nearby sensors. The generic assignment algorithm (originally proposed in [8]) runs in rounds, which allows sensors to be assigned to their best match. When a task arrives to the network, the task leader advertises the presence of the task and its profit to nearby sensors. The advertisement message is propagated to ensure that all tasks that are within twice the sensing range (
In order to conserve energy, the number of sensors that can be assigned to a task is limited to N, which is an application parameter. A higher value of N may yield a higher cumulative detection probability for an individual task. Between tasks, however, there will also be greater contention for sensors. Algorithm 1 summarizes the steps followed. Note that all the competing leaders will go through the steps shown for the task leader.
(1) initialize each (2) initialize each task cumulative detection probability (3) initialize number of assigned sensors to (4) advertise presence of (5) (6) (7) among responding sensors G, choose (8) update (9) send accept messages and advertise new (10) (11) done (12) (13) (14) wait for task requests (15) among requesting tasks Q, choose (16) send proposal to (17) (18) (19) done (20) (21) listen to current (22) (23) done (24) (25) update detection probability based on new (26) (27)
In the first round, each task leader that is participating in the process informs the nearby sensors of the details of its task (location and profit). A sensor, which may hear advertisement messages from one or more tasks, proposes to its current best match. This is the task for which it provides the highest detection probability weighted by the task's profit. More formally,
The sensor

where
Obviously, if the exact distance is used to calculate the detection probability, the task leader can do the reverse operation and determines the whereabouts of the proposing sensors. Hence, as we will see in the next subsections, sensors do not necessarily use the exact distance to calculate the utility. We note, however, that even if the exact distance from the sensor to the target is known, the task leader cannot accurately locate the sensor since it can be anywhere around a circle.
In the next round, each leader sends out an update on the status of its task's current CDP, after taking into account the currently assigned sensors. Sensors that were not selected in the first round recalculate
During the assignment process, sensors can continue the detection for the tasks to which they were initially assigned even while proposing to other tasks. Change only happens if a sensor chooses a task that is different from the one to which it is already assigned. In that case, it will change direction towards the new task's location and start detecting events.
4.3. Algorithm Variations
Here we describe the different variations of this algorithm. They only differ in the way sensors calculate their utility value (
4.3.1. Exact Location
This is the same algorithm that was proposed in [8] and will be used to benchmark the results of the other algorithms. In this variation, the distance used to calculate the utility is equal to the exact Euclidean distance between the sensor and the task's location. Hence, in this case:

4.3.2. Discretized Location
This variation of the algorithm was also proposed in [8] and will be used to compare the performance of the other algorithms (In [8], this algorithm was called Event Detection with Fuzzy Location.). Instead of using the exact distance between a sensor and a task to determine the utility, the area around the task is discretized into classes based on the distance. All sensors within the same class are considered to be equivalent from the task's leader perspective, that is, they provide the same utility. Figure 1 shows an example of this discretization in which the area around the task's location is divided into an inner disk and an outer ring. The distance between the center and the edge of the outer ring represents the sensing range

Example of discretized location.

Detection probability model.
Higher degree of location privacy is achieved by having fewer classes and hence the larger the area for each class. This means that there will be a larger number of sensors in each class and the task leader will not be able to distinguish them from each other. On the other hand, this will lead to lower performance since the chosen sensors may be far from the task's location. We define Distance Accuracy Degree (
Sensors in this case calculate the utility based on the expected distance to the task's location from the class to which they belong. More formally the distance used by the sensor to calculate the utility,

where
The task leader chooses sensors that provides the highest utility values. If there are multiple sensors with the same utility (this will happen if they are in the same class), then the leader choose randomly among them.
4.3.3. Random Location
In this variation, each sensor adds some random noise to the distance from the task's location before calculating the utility. The maximum noise added depends on the distance accuracy degree (

where

The task leader selects the sensors that provide the highest utility values based on Algorithm 1.
4.3.4. Energy-Based Location
In this variation, the actual distance from a sensor to the task is scaled by the remaining energy so that sensors will appear further as their energy gets depleted. This aims at providing location privacy and preserving energy as task leaders will choose sensors that appear closer, which will usually have higher amount of residual energy. In this variation, we do not control

where f is the fraction of remaining energy. When
The task leader selects the sensors with highest utility based on Algorithm 1, that is, the ones that appear to be closest. If there are multiple sensors with the same utility then the leader picks one randomly among them. This can happen when the energy of the applicable sensors has depleted to the level at which they all appear to be
5. Performance Evaluation
In this section, we discuss the result of the experiments used to evaluate our algorithms. We implemented a simulator in Java and tested our algorithms on randomly generated problem instances. We compare the results achieved by the different algorithms with the results achieved by what we call an optimal solution, in which for each currently active task separately, we find the optimal achievable profit for it, assuming there are no other tasks in the network, that is, no competition, and ignoring any energy constraints. The sum of these values provides an upper bound. This is an unrealistic solution used to measure the performance of the other solution.
5.1. Simulation Setup
The detection probability with sensor
Our goal is to maximize the achieved profits from all available tasks, that is,
We deploy 400 nodes in uniformly random locations in a 250 m × 250 m field. The communication range of sensors is set to 40 m. Tasks are created in uniformly random locations in the field. Tasks profits are exponentially distributed with an average of 10 and are capped at 100. So, they are in
Task lifetimes are also exponentially distributed to mimic realistic scenarios. In actual operations it is expected that many tasks will be of short durations and few with long durations. In our simulation we set the average lifetime to 1 hour and we cap the maximum lifetime to 6 hours. Tasks arrive based on a Poisson process. To test the robustness of our algorithms, we experimented with two loads, namely, average arrival rate of 4 tasks/hour and 8 tasks/hour.
Each sensor starts with a battery that will last for 6 hours of continuous sensing. To simplify our simulation, we assume that this battery is used solely for sensing purposes and is different than the sensor's main battery which it uses for communication and maintaining its own operation.
In our experiments, we show the average performance of the network for a period of 168 hours (1 week); we start collecting measurements after running the algorithms for 10 hours to allow it to reach steady state. The results are averaged over 500 runs.
5.2. Simulation Results
In Figure 3 we can see the performance of the algorithms in terms of the percentage of achieved profits over the lifetime of the network as

Total profit results after operating for 168 hours (1 week).
Below the exact location algorithm, we find the random location algorithm. This algorithm performs slightly lower than the exact location for small
Although the discretized location algorithm does not perform as well as the random location algorithm, it has another benefit which is highlighted in [8]. By dividing the sensors into classes based on their location, the task leader no longer needs to consider sensors individually for assignment but would rather need to consider the classes from which they are coming. This coarsens the problem instance to be solved and hence would reduce the computational overhead.
Figure 3(b) shows the same results but with increased network load. The arrival rate in this experiment is set to 8 tasks/hour. We see similar behavior of all algorithms. The only difference is that the achieved profits are now lower compared to the previous experiment. This is expected since with increased load sensors consume their energy at a faster rate, which leads to them dying earlier in the network lifetime and failing to contribute to later tasks. This will become clear when we consider the next set of results.
Figure 4(a) and Figure 4(b) show the profits achieved by the different algorithms over the lifetime of the network with lower network load (arrival rate = 4 tasks/hour) and high network load (arrival rate= 8 tasks/hour), respectively. Here, we set
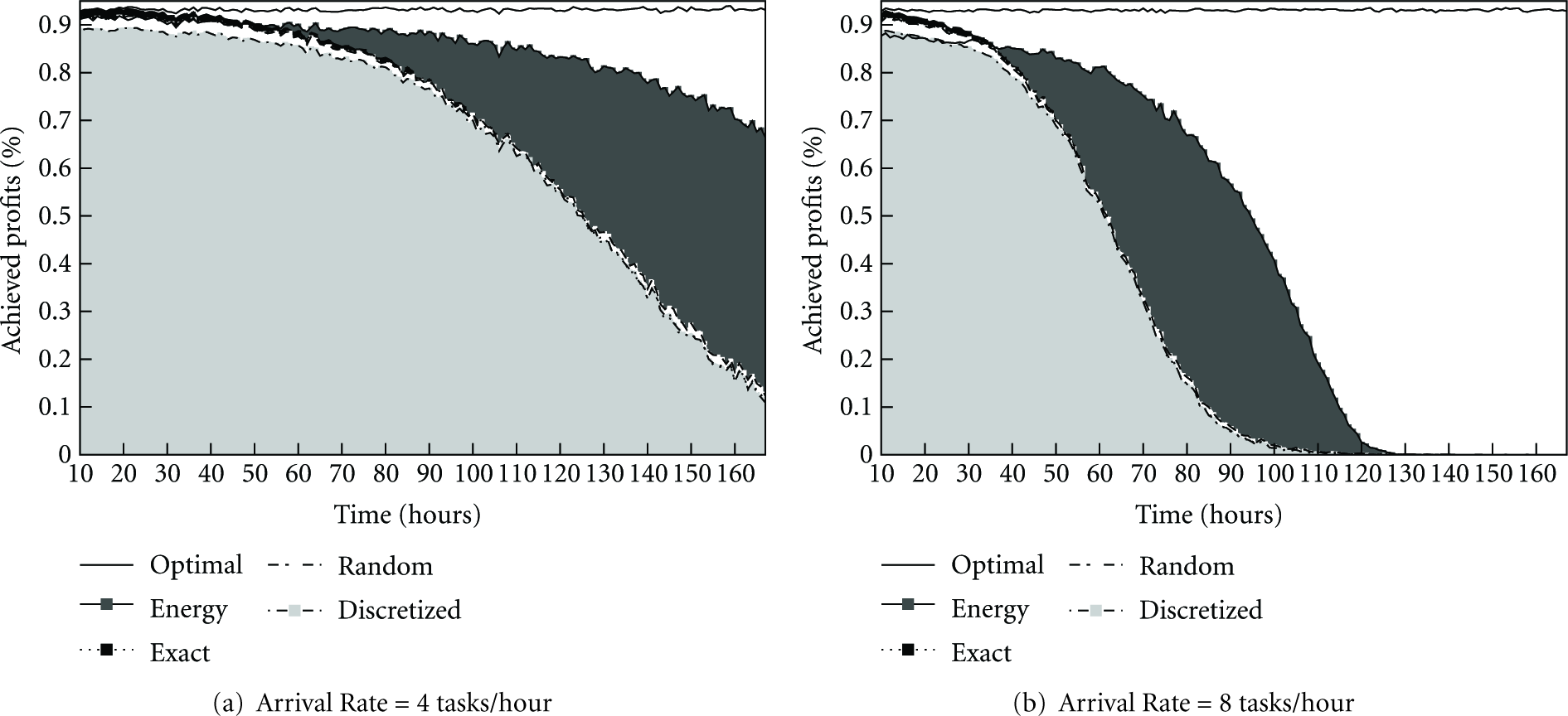
Profit over time for the different algorithm variations. Simulation time 168 hours (1 week). Distance Accuracy Degree
In Figure 4(a), we can see that all algorithms start with high profit values and decrease over time as sensors start to die. The exact algorithm starts as high as the optimal and then starts decreasing. The random and discretized algorithms come under the exact algorithm and again starts decreasing over time. What is interesting is the behavior of the energy-based algorithm, which starts close to the exact location algorithm but then starts to decrease at a much lower rate compared to the others. This is because it utilizes the resources more evenly, which keeps them alive for longer time making them available to serve more tasks in the future. If we consider the network to be alive as long as it can achieve 50% of the profits, then we can see that the energy-based location algorithm can increase the lifetime by almost 40% compared to the other algorithms.
Figure 4(b) shows similar results when the load is increased on the network by doubling the task arrival rate to 8 tasks/hour. The difference here is that we see the achieved profits going down at a much faster rate. This is due to the higher competition between tasks and higher consumption of resources, which leads to sensors dying at a faster rate leaving fewer of them to serve future tasks.
The third set of results, in Figure 5, show the percentage of alive sensors over the lifetime of the network under low and high loads of tasks (see Figures 5(a) and 5(b), resp.). Here, we see a behavior similar to the results shown in Figure 4 since the number of alive sensors directly affects the ability to satisfy tasks' requirements. As the number of alive sensors goes down, the network will have less capability to achieve high profits. It is clear that the energy-based location algorithm can keep more sensors alive for longer times since it utilizes the sensors more uniformly. Hence, in Figure 5(a) we can see that by the end of one week of operation the energy-based location algorithm was successful in keeping more than 80% of sensors alive, which allowed it to achieve more than 60% of the possible profits (Figure 4(a)). The other algorithms were able to keep less than 10% of the sensors alive and achieved only about 10% of the profits. When the load is increased to 8 task/hour (Figure 5(a)), we can see that by the end of the operation time of one week no algorithm was able to keep any of the sensors alive due to the increased demands of the tasks. It is clear, however, that the energy-based location algorithm was able to keep sensors alive for longer time and hence was able to achieve some profits for a longer period compared to the other algorithms (see Figure 4(b)).

Percentage of alive nodes over time for the different algorithm variations. Simulation time 168 hours (1 week). Distance Accuracy Degree (
5.3. Analysis of Location Privacy
Let us now define a privacy factor (

This is used for both the discretized and random location algorithms. When
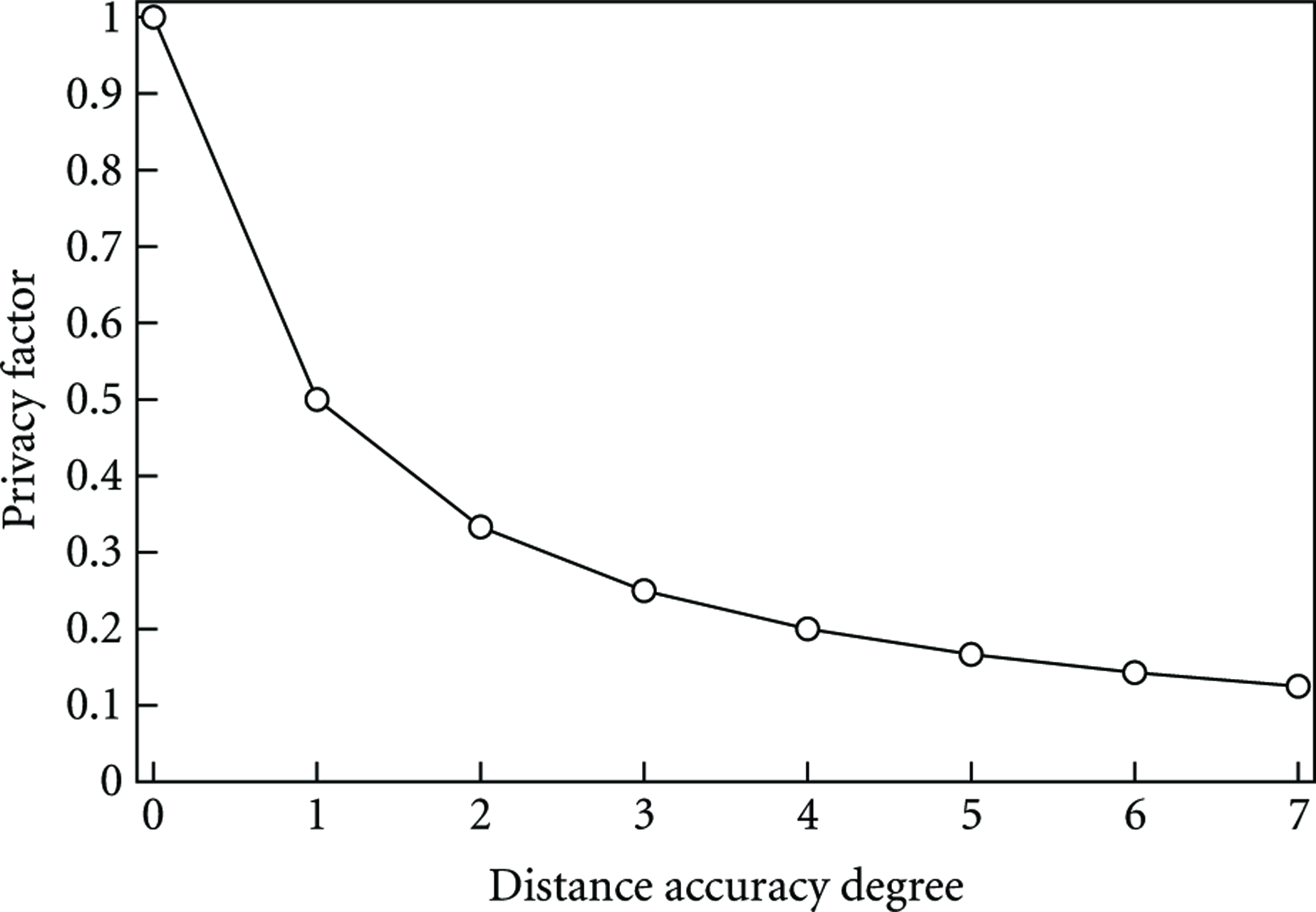
Location privacy.
For anonymity we use the notion of k-anonymity [23]. An algorithm provides k-anonymity if the proposal from one sensor cannot be distinguished from at least
The same analysis applies for the random algorithm. When
For the energy-based algorithm, the reported distance depends on the remaining energy and can range from the exact location to
Note that the anonymity level is affected by the network density. The more sensors deployed, the higher the value of
Sensor's location privacy is defined as the size of the area in which a sensor lies. If
Note that location privacy is affected by the sensing range. Given that everything else is equal, the larger the sensing range is the larger the ring area (or the added random noise) will be which leads to better location privacy.
6. Concluding Remarks
In this paper, we proposed distributed algorithms for finding sensor-to-task assignments taking into account location privacy and energy preservation issues. We focused on detection tasks, which require a number of sensors that are close to the location to be monitored. We extended the work in [8] by turning the focus on location privacy rather than savings in computational overhead, which was their main focus.
Our algorithms were designed to maximize the utility of the network, that is, the total profit achieved from all tasks, while preserving sensors’ location privacy. We proposed the random location algorithm, which adds random noise to the sensors' locations in order to hide their exact location. The magnitude of the random noise depends on the location accuracy that we would like to achieve. We also proposed the energy-based location algorithm, which takes into account the remaining energy as a factor to randomize the actual location of the sensor. This allows the network to use the sensing resources more uniformly by preserving the energy of sensors that have a small amount of energy left and preferring the ones that have more energy.
The performance evaluation showed that our algorithms can successfully hide sensors' locations while providing performance close to the algorithms which use the exact locations. Our random algorithm was able to achieve results that are very close to the ones achieved by the exact algorithm while maintaining location privacy similar to the one achieved be the discretized algorithm. We also found that the energy-based algorithm, while achieving results close to the exact location algorithm, was able to increase the network lifetime by as much as 40%.
It is important to note that in this paper we only considered directional sensors that can serve a single task at a time. Our algorithms may change if omnidirectional sensors are used. We also note that an adversary who would like to locate sensors may send repeated task requests from different location to determine which sensors are located in the area in which they intersect. These two issues require additional work and can be a venue of future research in this area.
Footnotes
Acknowledgment
This research was supported by King Fahd University of Petroleum and Minerals through the Deanship of Scientific Research under project JF100016.