
Abstract
The objective of private authentication for Radio Frequency Identification (RFID) systems is to allow valid readers to explicitly authenticate their dominated tags without leaking the private information of tags. In previous designs, the RFID tags issue encrypted authentication messages to the RFID reader, and the reader searches the key space to identify the tags. Without key updating, those schemes are vulnerable to many active attacks, especially the compromising attack. We propose a strong and lightweight RFID private authentication protocol, SPA. By designing a novel key updating method, we achieve the forward secrecy in SPA with an efficient key search algorithm. We also show that, compared with existing designs, (SPA) is able to effectively defend against both passive and active attacks, including compromising attacks. Through prototype implementation, we demonstrate that SPA is practical and scalable for current RFID infrastructures.
1. Introduction
The proliferation of RFID applications [1–5] raises an emerging requirement—protecting user privacy [6] in authentications. In most RFID systems, tags automatically emit their unique serial numbers upon reader interrogation without alerting their users. Within the scanning range, a malicious reader thus can perform bogus authentication on detected tags to obtain sensitive information. For example, without privacy protection, any RFID reader is able to identify a consumer's ID via the serial number emitted from the tag. In this case, a buyer can be easily tracked and profiled by unauthorized entities. Nowadays, many companies embed RFID tags with produced items. Those tags indicate the unique information of the items they are attached to. Thus, a customer carrying those items might easily get subject to silent track from unauthorized entities in a much larger span. Some sensitive personal information would thereby be exposed: the illnesses she suffers from indicated by the pharmaceutical products; the malls where she shops; the types of items she prefers, and so on. To prevent such unexpected leakage of private information, a secure RFID system must meet two requirements. First, a valid reader must be able to successfully identify the valid tags; on the other hand, misbehaving readers should be isolated from retrieving private information from these tags.
To address the above issue, researchers employ encryptions in RFID authentication. Each tag shares a unique key with the RFID reader and sends an encrypted authentication message to the reader. Instead of identifying the tag directly, the back-end database subsequently searches all keys that it holds to recover the authentication message and identify the tag. For simplicity, we will denote the reader device and back-end database by the “reader” in what follows. Two challenging issues on the reader side must be addressed in the key storage infrastructure and search algorithm: the search efficiency and the security guarantee. Searching a key should be sufficiently fast to support a large-scale system, while the maintained keys should be dynamically updated to meet security requirements.
Many efforts have been made to achieve efficient private authentication. To the best of our knowledge, the most efficient protocols are tree based [7, 8]. They provide efficient key search schemes with logarithm complexity. In those approaches, each tag holds multiple keys instead of a single key. A virtual hierarchical tree structure is constructed by the reader to organize these keys. Every node in the tree, except the root, stores a unique key. Each tag is associated with a unique leaf node. Keys in the path from the root to the leaf node are then distributed to this tag. If the tree has a depth d and branching factor δ, each tag contains d keys and the entire tree can support up to
The tree-based approaches are efficient, nevertheless, not sufficiently secure due to the lack of a key-updating mechanism. Most tree-based approaches do not update keys of tags dynamically. Since the storage infrastructure of keys in tree-based approaches is static, each tag shares common keys with others. Consequently, compromising one tag will reveal information of other tags. To address this problem, we need to provide a dynamic key-updating mechanism to such approaches. The major challenge of dynamic key-updating in tree-based approaches is consistency. If a single tag updates its keys, some other tags have to update their keys accordingly. Till now, consistent and dynamic key-updating mechanisms have scarcely been seen in the literatures.
In this paper, we propose a strong and lightweight RFID private authentication protocol, (SPA), which enables dynamic key-updating for tree-based authentication approaches. Besides consistency, SPA also achieves forwarding secrecy without degrading key search efficiency. We also show that SPA outperforms existing designs in defending against both passive and active attacks, including the compromising attack.
The rest of this paper is organized as follows. We introduce related work in Section 2. We present the SPA design in Section 3. In Section 4, we analyze the security guarantee of SPA. We evaluate the performance of SPA via a prototype implementation in Section 5. We conclude this paper in Section 6.
2. Related Work
Many approaches have been proposed to achieve private authentication in RFID systems. Weis et al. [9] proposed a hash-function-based authentication scheme, HashLock, to avoid tags being tracked. In this approach, each tag shares a secret key k with the reader. The reader sends a random number r as the authentication request. To respond to the reader, the tag generates a hash value on the inputs of r and k. The reader then computes
Tree-Based Approaches
Tree based approaches [7, 8, 11] improve the key search efficiency from linear complexity to logarithmic complexity. Molnar and Wagner proposed the first tree-based scheme, which employs a challenge-response scheme [8], which achieves mutual authentication between tags and readers. The protocol uses multiple rounds to identify a tag and each round needs three messages. Since it requires
Synchronization Approaches
Synchronization approaches [12] make use of an incremental counter to enhance the authentication security. When successfully completing an authentication, the counter of a tag augments by one. The reader can compare the value of a tag's counter with the record in the database. If they match, the tag is valid and the reader will synchronize the counter record of this tag. However, incomplete authentications lead the tag's counter larger than the one held by the reader. To solve this problem, the reader keeps a window for each tag. Such a window limits the maximum value of the counter held by the tag. If a tag's counter is larger than the record held by the reader but within the window, the reader still regards this tag as valid. Such schemes are vulnerable to the Desynchronization Attack. In such an attack, an invalid reader can interrogate a tag many times so that the counter of this tag exceeds the window recorded in the valid reader. In [13], the authors proposed a protocol to mitigate the impact from desynchronization attacks by allowing tags to report the number of incomplete authentications since the last successful authentication with the reader. Dimitriou proposed a scheme in [14], in which a tag increases its counter only after successful mutual authentications. Those protocols, however, degrade the anonymity of tags. An attacker is still able to interrogate a given tag enough times so that the tag will be immediately recognized when replying with unchanged responses.
Time-Space Tradeoff Approaches
Avoine converted the key search problem to an attempt at breaking a symmetric key [15]. In [16], Hellman studied the key-breaking problem and claimed that recovering a symmetric key k from a ciphertext needs to precompute and to store O(
3. SPA Protocol
In this section, we first introduce the challenging issues of static tree-based private authentication approaches. We then present the design of SPA.
3.1. Challenges of Tree-Based Approaches
Existing tree-based approaches [7, 8, 11] construct a balanced tree to organize and store the keys for all tags. Each node stores a key and each tag is arranged to a unique leaf node. Thus, there exists a unique path from the root to this leaf node. Correspondingly, those keys on this path are assigned to the tag. For example, tag

A binary key tree with eight tags.

A basic RFID authentication procedure.
From the above procedure, we see that tags will, more or less, share some nonleaf nodes in the tree. For example,
A practical solution is to update keys for a tag after each authentication so that the adversary cannot make use of keys obtained from compromised tags to attack normal ones. However, the static tree architecture makes it highly inflexible to provide consistent key-updating. Suppose we update the keys of
This problem motivates us to develop a dynamic key-updating algorithm for private authentication in RFID systems. This is where our proposed SPA enters the picture.
3.2. SPA Overview
SPA comprises four components: system initialization, tag identification, key-updating, and system maintenance. The first and second components are similar to tree-based approaches such as [7] and perform the basic identification functions. The key-updating is employed after a tag successfully performs its identification with the reader. In this procedure, the tag and the reader update their shared keys. This key-updating procedure will not break the validation of keys used by other tags. SPA achieves this using temporary keys and state bits. A temporary key is used to store the old key for each nonleaf node in the key tree. For each nonleaf node, a number of state bits are used in order to record the key-updating status of nodes in the subtrees. Based on this design, each nonleaf node will automatically perform key-updating when all its children nodes have updated their keys. Thus, SPA guarantees the validation and consistency of private authentication for all tags. SPA also eases the system maintenance in high dynamic systems where tags join or leave frequently by the fourth component.
3.3. System Initialization
For the simplicity of discussion, we use a balanced binary tree to organize and store keys, as shown by an example in Figure 3. Let δ denote the branching factor of the key tree (e.g.,

A key tree of a system with four tags (
When a tag
3.4. Tag Identification
The basic authentication procedure between the reader and tags includes three rounds, as illustrated in Figure 4. In the first round, R starts the protocol by sending a “Request” and a random number

Authentication procedure in SPA. After receiving U, Reader R's operations are Step 1, identifying
R executes the basic identification procedure to identify
Fix SUCCEED ← false; l← DepthofNode(n);
Record n in Synchronization Message; m← FindChildren(n, i); Identification (U, m); SUCCEED ← true; Fail and output 0;
Level by level, R figures out the path of
Identifying a tag is similar to traversing from the root to a leaf in the key tree. The path is determined by using Algorithm 1. Instead of using only one key for each node, Algorithm 1 uses both the working key k and the temporary key
3.5. Key-Updating
After successfully identifying
When generating new keys, SPA still makes use of the hash function h. Let
Store the old key tkn←kn; Generate a new key kn←h(kn); m← FindParent(n); Set Set smr← 1; Reset Synchronization message; n ← m; Key-updating (n);
Two important issues must be addressed when updating keys. First, R should update the keys of the identified tag
To address the two issues, SPA introduces a number of state bits to each nonleaf node. The basic idea behind this mechanism is that each nonleaf node uses these bits to reflect the key-updating status of its children. Once a child has updated its key, the corresponding bit is set to 1. Each node updates its own key when all its state bits become 1.
Without losing generality, we still use balanced binary key tree S to illustrate this mechanism. Each nonleaf node j in S is assigned with two state bits, denoted as
When R finishes key-updating, it sends a message
The key-updating algorithm is suitable for an arbitrary balanced tree with
3.6. System Maintenance
If a tag
After initialization, R connects the root of S to the root of

Tag joining and leaving.
For any empty leaf node i in the key tree, SPA lets the i's parent node j to set the corresponding state bit
If a tag leaves, R sets the leaf node of the leaving tag to be empty. For example, in Figure 5(b), if the tag
3.7. An Example of Key-Updating
For the ease of understanding, we use an example to explain the key-updating algorithm. Here we show one reader R and four tags a, b, c, d (i.e., four leaf nodes in the key tree). We assume the sequence of tag authentication is (a, b, c, d, a). The original state of the key tree is shown in Figure 6(a). When tag a is identified, R sets the corresponding state bit of a's parent to 1. Meanwhile, R generates a new key of the leaf a as shown in Figure 6(b).

An example of the key-updating procedure.
When tag b is identified, the corresponding state bit of b's parent is set to 1, and R updates the keys of the leaf node b and b's parent as shown in Figure 6(c).
When tag c is identified, the situation is similar to that of tag a. Since all state bits of the parent node of a and b are set to 1, R clears the state bits (i.e., reset the state bits to 0) in the key-updating operation as illustrated in Figure 6(d).
When tag d is identified, all state bits of d's parent and the root are set to 1. Thus, R updates the keys of the path from the leaf node of d to the root as shown in Figure 6(e).
Since tag a does not know that the keys of a's parent and the root have been updated, it will still use the old keys for identification. As indicated in the description of Algorithm 2 (Algorithm 2 in Section 3.5), each node stores the old key as the temporary key. After identifying tag a, R informs tag a to update its keys, according to the new keys from the leaf node of a to the root in the tree, as shown in Figure 6(f).
4. Discussion
In this section, we first discuss the security requirements for designing private authentication protocols in RFID systems. To evaluate the security of SPA, we propose an attack model to represent existing attacking scenarios. We then demonstrate the ability of SPA to meet those requirements and to defend against attacks.
4.1. Security Requirements
A private authentication protocol should meet the following security requirements [7].
Privacy
The private information, such as tag's ID, user name, and other private information should not be leaked to any third party during authentication.
Untraceability
A tag should not be correlated to its output authentication messages; otherwise, it may be tracked by attackers.
Cloning Resistance
Attackers should not be able to use bogus tags to impersonate a valid tag. Also, the replay attack should be resisted.
Forward Secrecy
Attackers can compromise a tag to obtain the keys stored in it. In this case, those keys should not reveal the previous outputs of the captured tag.
Compromising Resistance
The privacy of normal tags is threatened if they share some keys with compromised tags. Thus, the number of affected tags should be minimized after a successful compromising attack.
Existing private authentication approaches are able to defend against passive attacks (i.e., eavesdropping), but are vulnerable to active attacks (i.e., cloning and compromising attacks). Therefore, our discussion will focus on how SPA protects tags from active attacks. From the attacker's perspective, two metrics are important for evaluating the capability of SPA in defending against active attacks: (a) past-exposing probability, the probability of successfully identifying the past outputs of a compromised tag—this metric reflects the forward secrecy property of an authentication scheme; (b) correlated-exposing probability, the probability of successfully tracing a tag when some other tags in the system are compromised.
4.2. Attack Model
Avoine [17] proposes an attack model for RFID system and introduces the concept untraceability. The model well-reflects the attack behaviors and impacts on the authentication protocols. Our discussions are mainly based on this model with slight modification as follows.
In our model, the attackers and the RFID system are abstracted into two participants: the Adversary A (the attackers) and the Challenger C (the RFID system). So, the model is like a game between A and C. A first informs C that A will start to attack. C then chooses two tags to perform SPA protocols. If A can successfully distinguish any tag from another one based on their outputs by performing passive or active attacks on the RFID system, we claim that A successfully compromises the privacy of the system. For simplicity, Let P denote the SPA authentication procedure.
We define four oracles, Query, Send, Executive, and Reveal, to abstract the attacks on each T or R. Thus, any attack on a given R or T can be represented as A's calling on its oracles.
Query (T,
,
)
A sends a request
Send (R,
)
A sends a message
Execution (T, R)
A executes an instance of P with T and R, respectively. A then modifies the response messages and relays them to both sides accordingly.
Reveal (T)
After accessing this oracle of T, A compromises T, which means A obtains T's keys. Note that A can distinguish any given tag T from other tags if it can obtain T's keys.
We claim that an authentication protocol is resistant to attacks
A tells C that the game begins. C chooses two tags
For two tags
C selects a bit
Based on the results from
A passive adversary who can only eavesdrop on the messages delivered by T or R has no access to any oracle. For an active adversary, it can access arbitrary oracles introduced above. For instance, if an adversary applies a cloning attack, it means that it can access the Query, Send, and Executive oracles in this attack model. If an adversary can apply compromising attack, it means that it can access the Reveal oracle.
4.3. Security Analysis
In this subsection, we show how SPA achieves the security goals.
Privacy
Due to the pseudorandomness and one-way properties of the cryptographic hash functions, it is safe to claim that the output of the hash function can be seen as a random bit string. Note that the pseudo-randomness of a hash function means no adversary can distinguish the output of the hash function from a real random bit string. Therefore, the messages sent by the reader and tags provide no useful information to an adversary. None of the passive adversaries is able to deduce the original messages based on the output of hash functions, unless it can invert the hash function. It is well known that the probability of inverting a hash function is negligible.
Untraceability
Since the authentication of SPA does not enroll the ID of a tag and all authentication messages are encrypted by a cryptographic hash function, any passive adversary cannot distinguish the tags from others based on their encrypted messages. That is, it cannot track a tag.
Cloning Resistance
In a cloning attack, an adversary monitors a tag, records its messages and resends the message repeatedly [9]. Similar to most previous protocols, in SPA, the reader and the tags generate random numbers
Forward Secrecy
If a tag is captured, the adversary might obtain the tag's current keys. However, the adversary cannot trace back the tag's past communications because the keys are updated by a cryptographic hash function in each authentication procedure. In this way, the adversary still cannot retrieve the past outputs of the tag, unless it is able to invert the cryptographic hash function. Therefore, we can consider that the past-exposing probability of SPA upon the forward secrecy approaches 0. On the contrary, the static key tree protocols [7, 8, 11] cannot update the keys in the system. When an adversary compromised a tag, it can identify the past outputs of the tag from the obtained keys. Thus, the past-exposing probability of the key tree protocols approaches 1.
4.4. Compromising Attack
As we discussed in Section 3.1, a compromised tag may reveal some of the keys of other tags in static tree-based protocols. The adversary is then aware of some paths from the root to the leaf nodes of the compromised tag. Based on those paths, the adversary partially compromises the tree infrastructure. Knowing the “positions” of those nonleaf nodes, the adversary can further identify a sub-tree to which
Now we use the attack model to discuss the impact of a compromising attack on SPA. The following analysis is based on Avoine's work [18]. The game procedure comprises six phases.
Phase 1.
The adversary A has compromised t tags and obtained their complete secret keys.
Phase 2.
The system (challenger) C chooses two normal tags
Phase 3.
A calls oracles
Phase 4.
C selects a bit
Phase 5.
A calls oracle
Phase 6.
A outputs a bit
We assume that A cannot carry out an exhaustive search over the key space. Suppose that A has compromised t tags except
In Phase 5, A impersonates the reader and queries T,

An example of the compromising attack.
Case 1.
If
Case 2.
If
Case 3.
If
Case 4.
If
Case 5.
If
For
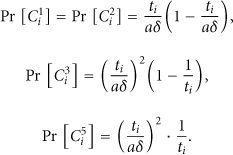
The probability that A succeeds is given by


Equation (2) shows that the correlated-exposing probability is mainly determined by three key parameters: (a) t, the number of compromised tags; (b) δ, the branching factor of the key tree; (c) a, the number of keys belonging to each nonleaf node. Note that if

Defending against the compromising attack.
We assume that the system contains 220 tags and the depth of key tree is 20. In the worst case, the adversary A can simultaneously compromise t tags at a given time. Then, A immediately starts attacks following the game strategy with challenger C. In addition, we assume there are only
As shown in Figure 8, SPA outperforms static tree-based approaches in defending against compromising attacks. In SPA, although A captures a number of keys shared by some normal tags, those tags are still secure if they update their keys. In contrast, normal tags in static tree-based approaches would be more vulnerable because the keys obtained by A will still be in use. This would ease A's tracking attempts.
In both SPA and static tree-based approaches, the correlated-exposing probability is reduced when enlarging the branching factor δ. This is because enlarging δ leads attackers to capturing fewer keys shared by tags which are not tampered with.
The static tree base approaches are extremely vulnerable to compromising attacks when t is sufficiently large. We find the correlated-exposing probability is close to 1 when
We here explain why increasing a can enhance the security of SPA. In an RFID system, a part of tags may not be accessed by the reader for a long time. Keys in those tags hereby cannot be updated. The reader must maintain these keys in nonleaf nodes' temporal keys for future use. As discussed in Section 3.2, temporal keys
5. Prototype Implementation
In this section, we introduce our experience on SPA prototype implementation. We also evaluate the performance of SPA and compare it with existing private authentication protocols.
5.1. Experiment Setup
We have implemented the SPA protocol on Mantis-series 303 MHz asset tags and Mantis II reader manufactured by RF Code [19]. In terms of its coding, this system is able to support over one trillion tags. A tags' typical transmission range is 300 feet, and the reader can communicate with them at distances of more than 1000 feet depending on the antenna configurations. The back-end database is implemented on the desktop PC with the following configurations: Pentium M 3.2 G dual core CPU, 1 GBytes memory, and 40 G hard disk. We use SHA-1 algorithm as the secure hash function.
In this implementation, the system is able to maintain up to
A fundamental concern upon SPA is the latency of key-updating. We use the metric key-updating Latency as the time required for the reader to update a tag's keys to evaluate the performance of SPA. On the other hand, the key-updating of SPA should guarantee that the keys are secure enough over their lifetime. We focus on two metrics in the experiments.
(a) Key-Updating Latency
It reflects the computational overhead of key-updating. In SPA, the whole processing overhead for an authentication procedure includes two components: identification and key-updating. Since the static key tree approaches only perform the identification function, we focus more on the computational overhead caused by key-updating of SPA.
(b) Key Security Degree (KSD)
It reflects the possibility of keys being obtained when an adversary attacks a RFID system. Let f denote the tag accessing frequency, which means how many tags interact with the reader per second. Let l be the length of a key, let n be the number of updated keys in one key-updating procedure, and let d be the depth of the key tree. We denote p as the probability of an adversary successfully gaining the n keys, and

KSD reflects the comprehensive ability of a protocol on defending against the active attacks. A higher KSD value represents a more secure protocol. Parameters in our experiments are summarized in Table 1.
Experiment settings.

5.2. Results
Figure 9 plots the average key-updating latency of SPA. With the increase of the tag accessing frequency, which means how many times a tag is accessed per second, the key-updating latency increases. The processing speed of SHA-1 is 1.73 MByte per second. We find that the latency of key-updating does not exceed 1.7 ms even when the tag accessing frequency approaches 10. Since we construct a tree with the depth of 20 in this experiment, each tag is assigned with 20 keys. Thus, the curve of key-updating is enclosed within two lines: one represents the upper bound (20 keys in a tag are updated) and another represents the lower bound (only one key is updated). The short key-updating latency of SPA enables a reader to support dense access patterns. Due to page limitation, results from other experiments are not reported here.

Key-updating latency of SPA.
Figure 10 shows the change of KSD of SPA with different tag access frequencies. The curve of KSD fluctuates when increasing the frequency. In Figure 10, two lines show the upper and lower bounds (

Key security degree of SPA.
In SPA, the main overhead is caused by SHA-1 computations on the side of R. Therefore, the number of SHA-1 computations reflects the computation overhead of SPA. Figure 11 shows the relationship between the computation overhead and KSD in different tag accessing frequencies. In Figure 11, the y-axis refers to the number of SHA-1 computations. We see that a high tag access frequency results in a smooth curve of overhead. We also find that the computation overhead caused by SPA does not exceed 900 times of SHA-1 even the tag accessing frequency is high, for example, R accessing 10 tags per second, while the PC used in our experiments can perform 86,500 SHA-1 computations per second. It indicates that a significant incensement of KSD only incurs small computation overhead to the system. Hence, SPA is scalable when providing high secure private authentication services.
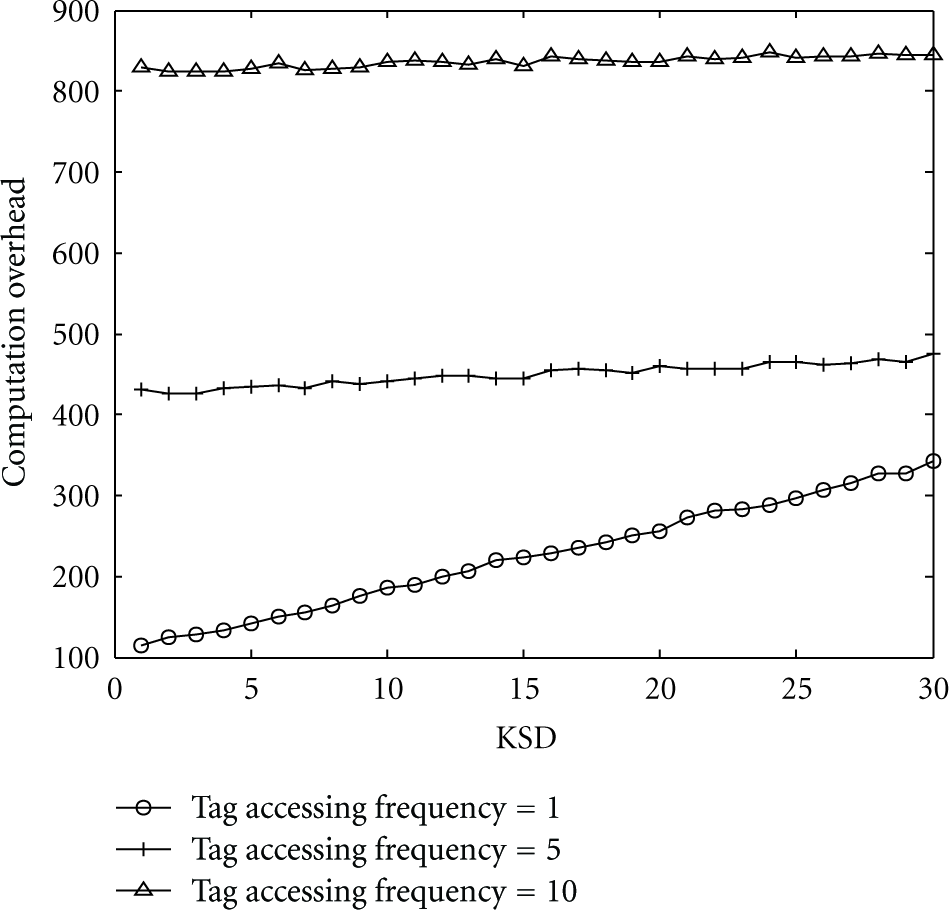
Computation overhead versus KSD.
6. Conclusion
We proposed a privacy-preserving authentication protocol, SPA, to support secure and efficient tag-reader transactions in RFID systems. By using a dynamic key-updating algorithm, SPA enhances the security of existing RFID authentication protocols. SPA is lightweight with high authentication efficiency: a reader can identify a tag within
Footnotes
Acknowledgment
This research was supported by NSFC 60903155 and NSFC 61173171.