
Abstract
This paper discusses the distributed routing algorithm of wireless self-organized network and puts forward a new type of hybrid self-organizing clustering routing protocol by combining energy sense and maximum connectedness. This routing protocol adopts a mechanism which is mainly based on cluster routing with the theory of “on demand-based plane routing discovery mechanism” becoming secondary. The routing discovery and routing maintenance algorithm are also described in this paper. As the emulation experiment result shows, there is no significant difference between the routing protocol and the demand-based routing protocol; however, when there are quite a number of nodes in the network, the performance can be greatly enhanced compared with the demand-based routing protocol. The routing protocol discussed in this paper has better extendability, lower routing overhead, and better data transmission rate; thus it can extend network lifetime and enhance the network performance.
1. Introduction
In most cases, the on-demand routing protocol works effectively; however, as the network scale expands and the node number increases, the number of the routing control messages increases dramatically; as a result, the network congestion is caused and the network performance index decreases [1]. At present, the clustering algorithm is recognized as an effective self-organized method which can improve network extendability, realize smaller route and control overhead, reduce number of nodes that share same channels, and also reduce the collision rate [2]. In addition, the cluster algorithm can help implementation of the functions such as routing selection and resource management. As a commonly used clustering algorithm, the maximum link degree clustering algorithm (MAXD) [3], its node firstly derives number of the neighboring nodes via the interaction control message and then broadcasts its connectedness to the neighboring nodes. Among this node and all other neighboring ones, the node with maximum connectedness to the neighbor one should be selected as the cluster head. If the maximum connectedness between the nodes and their neighborhoods are the same, the node with smallest ID should be selected as the cluster head. The one-hop neighboring node of the cluster head becomes the member node in the cluster. The above-said procedure can be repeated until all nodes join one certain cluster. This cluster algorithm has the advantage of fewer number of clusters, that is to say, there are no many average hops between the source node and the destination one. By using the algorithm, the packet delivery delay can be reduced, but the overlapping between the created clusters is still high, and the network lifetime can be affected because the network loading balance is not taken into consideration. In such a background, we put forward a new self-organized clustering routing protocol based on link degree and energy aware. In this paper, the proposed clustering routing protocol is denoted as NSCR.
The basic principle of the NSCR is described as follows. On one hand, by referring to the theory of “on demand-based plane routing discovery mechanism” at the initial stage, the routing protocol later evolves as a mechanism which is mainly based on cluster routing; thus the theory of “on demand-based plane routing discovery mechanism” becomes secondary. On the other hand, when choosing the cluster head node, the system considers node connectedness and remaining energy. At the same time, each cluster head node chooses one candidate cluster head node (means the node which will become the cluster head once the node in the cluster head is not the head node) in its one-hop neighbor domain; when energy of the cluster head node is smaller than a certain value, the candidate node works as the new cluster head node instead, so that the network load balance can be achieved and network lifetime can be extended.
The rest of the paper is organized as follows. In Section 2, we present related works. Section 3 describes the proposed algorithm. Experimental results are reported in Section 4 and conclusions are drawn in Section 5.
2. Related Work
Grouping sensor nodes into clusters has been widely pursued by the research community in order to achieve the network scalability objective. The objective of clustering is mainly to generate stable clusters in environments with sensor nodes. In addition to supporting network scalability, clustering has numerous advantages [4].
“Self-organizing” is defined as the process where a structure or pattern appears in a system without intervention by external directing influences. It organizes through direct interaction in a peer-to-peer method [5]. Several self-organizing clustering protocols were studied as follows. Tournus et al. [6] propose a routing to self-organization, in which thin films obtained by deposition of size-selected CoPt clusters on graphite surface. The preformed clusters can easily diffuse on the surface and gather to form “islands” or “bunches” of clusters. By changing the cluster size, very different morphologies can be obtained, going from large-ramified islands to bunches of noncontacting clusters having the size of the initially deposited particles. Ahmed et al. [7] propose that energy efficiency and enhanced backbone capacity are obtained by exploiting the geometric orientation of cooperative nodes in wireless sensor network. The cooperative communication in wireless sensor networks gives people leverage to get the inherent advantages of its random node's locations and the direction of the data flow. Depending on the channel conditions and the transmission distance, the number of cooperative nodes is selected, that participate in an energy-efficient transmission/reception. Hasan and Jue [8] associate survivability and energy efficiency with the clustering of WSNs and show that such a proactive scheme can actually increase the lifetime. They present an easy-to-implement method named DED (distributed, energy-efficient, and dual-homed clustering) which provides robustness for WSNs without relying on the redundancy of dedicated sensors, that is, without depending on node density. DED uses the already gathered information during the clustering process to determine backup routes from sources to observers, thus incurring low message overhead. It does not make any assumptions about network dimension, node capacity, or location awareness and terminates in a constant number of iterations. Ahmed et al. [9] presents an energy-efficient selection of cooperative nodes with respect to their geographical location and the number of nodes participating in cooperative communications in wireless sensor networks. The cooperative communication in wireless sensor networks gives people leverage to get the inherent advantages of its random node's locations and the direction of the data flow. Depending on the channel conditions and the transmission distance, the number of cooperative nodes is selected, that participate in an energy-efficient transmission/reception. Simulation results show that increasing the cooperative receive diversity decreases the energy consumption per bit in cooperative communications. It has also been shown that the network backbone capacity can be increased by controlled displacement of antennas at base station at the expense of energy per bit. Sun and Gu [10] propose and evaluate an energy-efficient clustering scheme based on LEACH (low energy adoptive clustering hierarchy), that is, LEACH-Energy Distance (LEACH-ED). In LEACH-ED, cluster heads are elected by a probability based on the ratio between residual energy of node and the total current energy of all of the sensor nodes in the network. LEACH-ED is another self-organized protocol that is based on LEACH. AbdelSalam and Olariu [11] propose to construct what they call a network skeleton that is constructed immediately after network deployment and provides a topology that makes the network more tractable. The skeleton provides sensors with coarse localization information that enables them to associate their sensory data with the geographic location in which the data was measured. Moreover, it promotes a geographic routing scheme that simplifies data communication across the network through skeleton sensors. Younis et al. [12] propose REED (Robust Energy-Efficient-Distributed clustering) for clustering sensors deployed in hostile environments in an interleaved manner with low complexity. REED is a self-organized clustering method which constructs independent sets of CH overlays on the top of the physical network to achieve fault tolerance. Each sensor must reach at least one CH from each overlay. Sangjoon [13] introduces a clustering strategy and self-organizing scheme for cluster-based wireless sensor networks, while maintaining the merits of a clustering approach. This scheme is a clustering method to configure cluster by diffusing an interest from a sink node. When a sink node diffuses an interest, every node decides which node is elected as a cluster head or intermediary node by sending and receiving messages.
In summary, the routing protocol in the above-mentioned studies often consider connectivity or energy awareness singly, and their research results always have some defects. In this regard, combined with flat-based routing mechanism and clustering arithmetic, this paper presents an on-demand self-maintenance clustering routing protocol based on connectivity and energy awareness which cited a mechanism with clustering routing key point and with flat-based on-demand routing supplementary point. This protocol keeps the advantages of flat-based on-demand routing, improves the scalability, and enhances the network performance.
3. Algorithm Description
Extensive research has been conducted in the area of clustering routing algorithm in dynamic network, including MANETs and mobile sensor networks; a great deal of algorithms and protocols have been proposed. Most of the research focused on reducing routing overhead and increasing latency of the network. There are, without doubt, some open issues that are still worth to investigate. In our work, we assume the following content as our clustering routing protocol.
The ad hoc network, which consists of multiple free moving nodes, can be extracted as an undirected graph of
The self-organized clustering routing protocol (NSCR) proposed by this paper starts performing route query when there is data which needs to be transmitted; in such a case, the nodes form a cluster. In addition, the system considers node connectedness and remaining energy of cluster head election, and at the same time it sets the candidate cluster head. The proposed algorithm consists of five parts as shown in Figure 1.
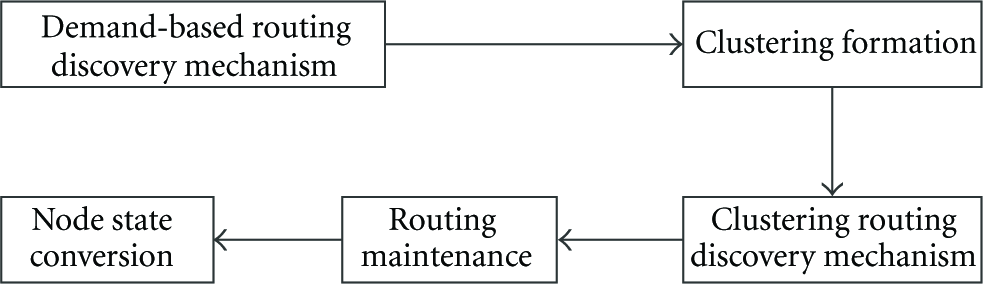
Algorithm Description.
3.1. Demand-Based Routing Discovery Mechanism
When the source node (s) wants to communicate with the destination node (d), it initiates the routing discovery procedure. At the beginning, all nodes are in pending state, meaning that it is not in the cluster.
The source node (s) firstly checks its own routing table, to see whether there is routing information to the destination node (d). If no, it creates RREQ [14] and then broadcasts the RREQ to all neighboring nodes. RREQ = (Type, Source_addr, Dest_Addr, Dest_squence, RList, ToL). Among the parameters, Type means packet type, Source_addr means source address of the packet, Dest_Addr means destination address of the packet, and Dest_squence means packet serial number. Please note that (Source_addr, Dest_squence) can uniquely identify the RREQ, RList records the route information, and ToL means RREQ's value of lifetime.
After the intermediate node (m) receives one RREQ, it performs the following procedure.
Step 1.
Substract 1 from ToL. If ToL value is 0, the intermediate node (m) shall discard the RREQ because the value means that RREQ's value of life is 0.
Step 2.
Check whether the RREQ has been received according to RREQ's (Source_addr, Dest_squence). If yes, the intermediate node (m) discards the RREQ; otherwise, it checks whether the Rlist of RREQ carries the node address; if yes, it discards the RREQ.
Step 3.
If the intermediate node (m) which carries the route information to the destination node returns the RREP [15] to the source node (s) after it receives the RREQ; otherwise, the intermediate node (m) continues broadcasting the RREQ. At the same time, the node (m) records the neighbor address carried in the RREQ and creates the reverse path.
Step 4.
When there are a number of roads between the intermediate node (m) and the destination node (d) can be selected, the algorithm selects the optimal next hop node (k) from the alternative nodes to transmit information according to the probability

Among the parameters,
Step 5.
After the destination node (d) receives the RREQ from the source node (s), it triggers the routing response procedure, which sends the RREP to the source node (s) in the created reverse path.
Figure 2 shows the demand-based routing discovery mechanism.

Demand-based routing discovery mechanism.
(i) Node Weight Calculation Method
In the reverse path where the destination node (d) sends the RREP to the source node (s), the passed node v and its neighboring node weight in the RREP can be obtained via calculation.
Definition 1.
Weight (

Among the parameters,
(ii) Generating Clustering Head Node
Node v broadcasts its weight to its neighboring nodes, and at the same time it updates neighboring node information list based on broadcast information of the neighboring nodes. After this procedure is finished, node v obtains weight and ID of its one-hop neighboring nodes. Then, node (v) compares the weights of this node with all other one-hop neighboring nodes and selects the node with maximum weights as the cluster head. If the maximum weight of the nodes is same, the node with smallest ID shall be selected as the cluster head. In the meanwhile, the node (as new cluster head) sends cluster head broadcast message to all its one-hop neighboring nodes; upon receiving the broadcast message from the cluster head, the neighboring nodes become member of the cluster and add the cluster head address into the head list.
(iii) Generating Distributed Gateway and Gateway Nodes
The member node i broadcasts the distributed gateway request message to its neighboring nodes. If the neighboring node j which receives the message finds that its cluster head node is different from that of the sending node i, then the neighboring node j shall returns a distributed gateway response message to node i; in such a case, node i becomes a distributed gateway in the cluster; later it adds its neighboring node j into its neighboring gateway list, and at the same time, the node i sends the distributed gateway message to its neighboring head node so as to allow the cluster head node to add the node i into its own distributed gateway list.
After this phase ends, the cluster is completely formed. The node is thus comprised of cluster head, gateway, distributed gateway, ordinary member, and pending node. All cluster head nodes are not directly neighbored to each other, which means that they are out of one-hop transmission range. The distance between cluster head node and cluster member node is always one hop.
3.2. Clustering Routing Discovery Mechanism
If the node becomes a cluster member, then the system shall set a cluster routing tag in the RREQ it sends and then query the routing according to the cluster routing discovery mechanism. In addition, the node which forwards RREQ determines whether to query the routing by adopting cluster routing discovery mechanism or demand-based plane routing discovery mechanism according to the fact whether the cluster routing tag is set in the received RREQ. If the node fails to find the route in the specified time, the plane routing discovery mechanism based on demand shall be used for routing discovery [16]. Figure 3 shows the clustering routing discovery mechanism.

Clustering routing discovery mechanism.
State of any node v can be converted under certain conditions.
(i) Clustering Head Node
When the cluster head node finds its cluster member is 0, it converts its own state to pending; when remaining energy of the cluster head node is below one certain value, the candidate head node becomes the head and the previous head node becomes an ordinary member.
(ii) Clustering Ordinary Member Node
When the cluster ordinary member node finds the cluster head in its neighboring node is not the same as its own cluster head, then its state shall be converted to distributed gateway. When the cluster ordinary member node receives the broadcast message from the heads in different clusters, its state can be converted to gateway. If the cluster ordinary member node is selected as the candidate node, when remaining energy of the cluster head node is below one certain value, its state becomes cluster head.
(iii) Gateway Node
If the gateway node finds that its cluster head is not reachable, then it deletes this node from its cluster head list. If the cluster head list contains only one head node, and the head in one-hop neighbor domain is not the same as its own cluster head, then its state shall be converted to distributed gateway; otherwise, its state shall be converted to cluster ordinary member.
(iv) Distributed Gateway Node
If the distributed gateway node finds that the node in its neighbor domain does not include the node from other clusters, then its state shall be converted to cluster ordinary member. When it finds the new cluster head node, its state shall be converted to gateway.
3.3. Routing Maintenance
After the routing discovery is finished, the network link loses effectiveness and reestablishes itself because it is affected by mode movement, energy reduction, and so forth. At the same time, the network topology structure also changes; so some nodes shall join new clustering from the old one, thus causing clustering structure change. In such a situation, the routing protocol requires the node to obtain state of the neighboring node via the broadcast message sent in a periodic manner and informs the nodes affected by disconnected links to perform the maintenance mechanism such as updating routing table by sending routing error group; besides, the related cluster maintenance mechanism should be adopted to maintain stability of the cluster structure.
(i) Local Routing Repair
If the node detects that its link to one neighboring node disconnects, then all routes using this link shall also fail. In this case, the direct route repair method can be adopted for route maintenance at link disconnection node. When the intermediate node m detects the link disconnection, it firstly puts the data from source node s into cache and then sends the route request to start new routing discovery by taking this node as the source node. If the destination node d receives the request, it replies with the routing response; upon the route is repaired successfully, the link disconnection node sends the data packets to the destination one in the new routing.
(ii) Self-Maintenance of Clustering Head Node
The clustering ordinary member node v in the cluster head node's one-hop neighboring domain can be used to obtain the weight
Definition 2.
Weight
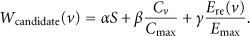
Among the parameters, S means similarity between node v and its clustering head node h,
Definition 3.
Similarity between node v and its cluster head node h is defined as S:
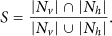
Among the parameters,
The clustering head node sends the candidate head request message to the node whose
(iii) Joining and Quitting the Clustering
When status of node v is standby, if it receives the clustering head node broadcast message, it shall send cluster join request message to the clustering head node. After node v receives the response message from the clustering head node, it saves the head node address, which indicates node v has joined the clustering. To reduce the overhead, the on demand-based method [17] is adopted to allow new nodes to join the clustering. When the clustering member nodes are not in head node's one-hop neighboring domain, they modify their statuses to pending state, which indicates that they have quit the clustering.
4. Experiment and Result Analysis
4.1. Experiment Design
By routing protocol simulation based on the Linux environment, the simulation experiment adopts NS-2 [18] as the emulation tool. NS-2 is a discrete event-driven network simulation tool; it is open source and free software and can be extended according to the needs of users. NS-2 can perform a variety of network protocols, offer a variety of data sources, achieve a variety of router queue management algorithms, bring about multicast and MAC algorithm, and provide communication model, random topology, and node mobility model generation tool. The scenario documents used in the simulation experiments are generated by the stochastic modeling tools. When the emulation begins, each node waits for a stopping duration at the initial location and then moves to a randomly selected direction with a random speed between 0 and the maximum moving speed. If the node reaches the randomly selected destination, it waits for the same period of stopping duration and then repeats the procedure described earlier until the emulation ends. All moving procedures should be recorded in the scenario documents. In the experiment, the average value is used as reference.
4.2. Parameter Settings
In the emulation scenario, we set a flat rectangular virtual environment with size as 1500 m × 1000 m and set the emulation duration as 2000 s. During the emulation, half of the nodes move randomly in the waypoint mode and the other half stay still. The maximum moving speed of all the nodes is 40 m/s, and the node stopping duration is 50 s. Besides, CBR data source is used, the data transmission rate is 10 packets per second [19], and MAC protocol is using 802.11DCF.
In this paper, two simulation scenarios are set.
(i) Simulation Scenario 1
The number of nodes is set to 100, 150, 200, 250, 300, 350, 400, 450, and 500, respectively.
(ii) Simulation Scenario 2
The number of nodes is set to 5, 10, 20, 40, 80, 120, 160, 250, and 300, respectively.
In order to analyze the performance of routing protocols, the following performance indicators of the routing protocols are assessed. First, lifetime: it refers to the time interval from the beginning of the simulation to the time when the first node in the network runs out of energy. Lifetime can be used to measure the viability of the ad hoc network. Second, routing overhead: it is used to establish and maintain the number of control packets generated by routing. Routing overhead can be used to measure routing protocol's scalability and ability to adapt to network congestion. Third, packet delivery fraction: it means the ratio of the total number of packets the destination node receives with the total number of packets the source node sends. Packet delivery fraction can be used to measure the efficiency of the routing protocol. Fourth, number of clusters: it directly reflects the structure and characteristics of the cluster network.
4.3. Result Analysis
In the emulation experiment, according to the parameters and performance indicators proposed in Section 4.2, we select representative plane on-demand distance vector (AODV) routing protocol [20] and maximum connectivity clustering algorithm (MAXD) as references, do simulation experiments to the proposed clustering routing protocol NSCR via AODV and MAXD, and select some representative simulation results be analyzed and discussed.
(i) Life Time of the Ad hoc Network
In simulation scenario 1, lifetime of the ad hoc network in NSCR clustering algorithm is greatly extended compared with the MAXD. The reason is that the NSCR clustering algorithm considers the node energy in the cluster head election process and thus adopts the candidate cluster head mechanism; by doing so, the network loading is balanced and lifetime of the ad hoc network is extended. Figure 4 shows the comparison of the lifetime of the network between NSCR and MAXD.
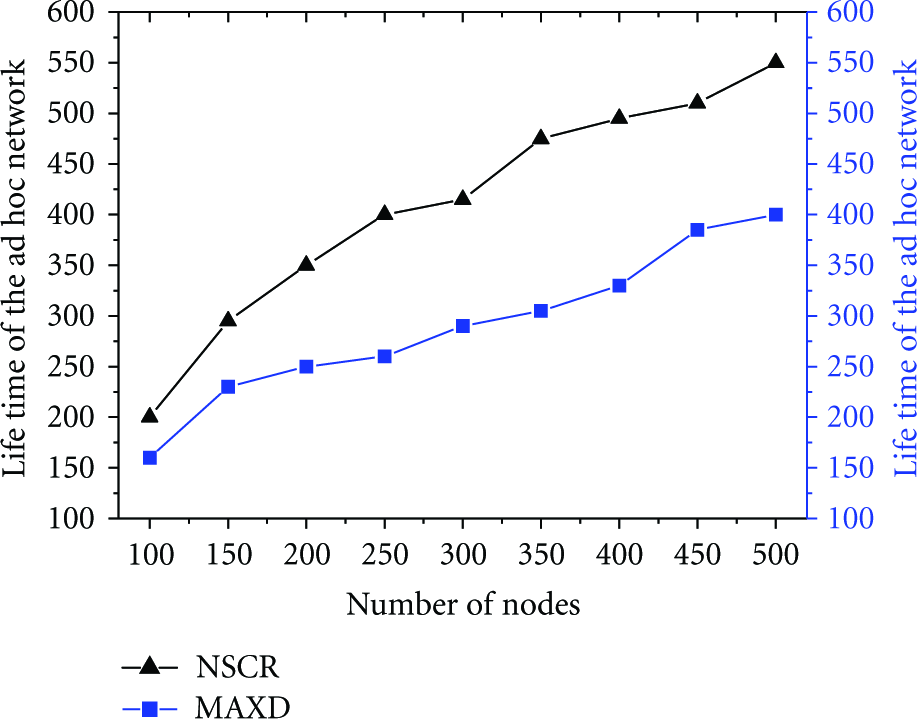
Life time of the Ad hoc network.
(ii) Routing Overhead
Figure 5 shows the routing overhead for both NSCR and AODV in simulation scenario 2. As the figure shows, when the number of the nodes in the network is only a few, routing overhead of NSCR and AODV is almost the same; however, as the number of network nodes increases, especially when the number of nodes exceeds 100, AODV's routing overhead increases at a relatively big pace; when the number reaches 200, AODV's routing overhead increases significantly but at the same time NSCR's routing overhead goes up in a slow pace. This phenomenon is mainly due to the NSCR routing protocol considers cluster routing mechanism, which to a certain extent improves the network scalability and reduces the network congestion. This experiment result shows that NSCR routing protocol can control network routing overhead effectively.

Routing overhead.
(iii) Packet Delivery Fraction
In simulation scenario 2, packet delivery fraction of both NSCR and AODV decreases when the number of the nodes in the ad hoc network increases, but the packet delivery fraction of NSCR is obviously higher than that of AODV when there are quite a number of nodes in the ad hoc network. The cause of this phenomenon is for the following reasons: on one hand, the NSCR reduces the routing control information and network congestion by using the cluster routing discovery mechanism; on the other hand, NSCR uses the partial routing repair to implement routing maintenance, which can reduce packet loss caused by link disconnection. Figure 6 shows the comparison of packet delivery fraction of NSCR and AODV.
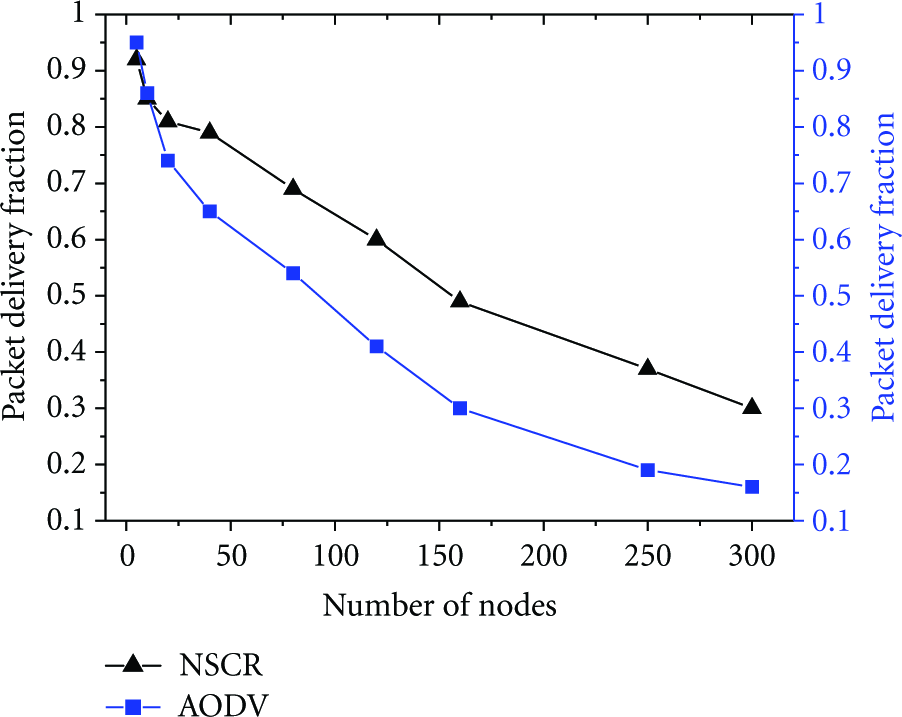
Packet delivery fraction.
(iv) Number of Clusters
In simulation scenario 1, the number of clusters produced by NSCR and MAXD is similar, which indicates that the NSCR clustering algorithm maintains the advantages of clustering algorithm of MAXD. Figure 7 shows the comparison of the number of clusters of NSCR and MAXD.

Number of clusters.
5. Conclusion
This paper puts forward a demand-based self-maintenance clustering routing protocol based on energy sense and maximum connectedness cluster algorithm. By analyzing basic principle of the clustering routing protocol, describing protocol work mechanism, and conducting the emulation experiments, the paper concludes that there is no much difference between performance of the proposed clustering routing protocol and demand-based plane routing protocol when the network is in a small scale. However, when there are quite a number of network nodes, their performance can be significantly improved compared with the demand-based plane routing discovery protocol. The HSCR routing protocol has better extendability, lower routing overhead, and better data transmission rate; at the same time, compared with the maximum connectedness cluster algorithm, the HSCR has the advantage of maximum connectedness cluster algorithm; thus it can extend network lifetime and meet routing requirement of the ad hoc network.
Footnotes
Acknowledgment
This research was supported by Ministry of Education of the People's Republic of China, Humanities and Social Sciences Project (no. 12YJC870036).