
Abstract
Cluster-based organization of large sensor networks is the basis for many techniques aimed at enhancing power conservation and network management. A backbone network in the form of a cluster tree further enhances routing, broadcasting, and in-network processing. We propose a configurable top-down cluster and cluster-tree formation algorithm, a cluster-tree self-optimization phase, a hierarchical cluster addressing scheme, and a routing scheme. Such self-organization makes it possible to effectively deliver messages to a sink as well as within the network. For example, a circular sensor field with a sink in the center can establish cross-links and circular-paths within the cluster tree to deliver messages through shorter routes while reducing hotspots and consequently increasing network lifetime. Cluster and cluster-tree formation algorithm is independent of physical topology, and does not require a priori neighborhood information, location awareness, or time synchronization. Algorithm parameters allow for formation of cluster trees with desirable properties such as controlled breadth/depth, uniform cluster size, and circular clusters. Characteristics of clusters, cluster tree, and routing are used to demonstrate the effectiveness of the schemes over existing techniques.
1. Introduction
Advances in wireless communications and miniature, low-power, and low-cost sensors are enabling the deployment of large-scale and collaborative wireless sensor networks (WSNs). These networks enhance our perception of the surroundings by sensing the physical world at far greater temporal and spatial granularities than been hitherto possible. Numerous WSN systems are being proposed and implemented leading to novel applications in areas such as habitat monitoring, disaster response, eldercare, and battlefield intelligence.
Energy-efficient operation, channel contention, latency, and management of WSNs are complex and critical issues that have to be addressed to facilitate large-scale deployments. Cluster-based organization of large sensor networks is the basis for many techniques that address these issues [1–13]. Applications that span large sensor fields and/or support data aggregation are prime candidates for cluster-based configuration. Clustering is particularly useful in collaborative sensor applications that perform different tasks and deployed in the same physical area [14]. In general, the network is decomposed into a set of clusters, for example, for administrative or communicating purposes, with each cluster formed by grouping a set of nearby nodes. A designated node, namely, the cluster head (CH), manages each cluster. With many solutions based on clustering, the nodes within a cluster communicate only with their CH. The CHs are responsible for coordinating both intercluster and intracluster communication. Communication among CHs can be via either single or multiple hops.
Cluster formation can be either distributed or centralized. Many distributed clustering solutions including [1–4] achieve longer network lifetime by selecting CHs based on residual energy of nodes. LEACH-C [1] is a centralized solution that further enhances the network lifetime. Typically, overhead of local knowledge-based distributed clustering solutions is lower compared to that of centralized solutions such as LEACH-C. However, their lack of global knowledge limits the possibility of forming an optimum set of clusters, that is, fails to achieve maximum spatial coverage with least number of clusters. Even with the presence of such information, selecting a minimum set of clusters with maximum coverage is an NP-hard problem [15]. Hybrid schemes that combine local and neighbors' view of the topology can form better clusters while having low overhead [5]. For example, ACE [6] and FLOC [7] form more uniform and circular clusters. Solutions in [1–3, 6–8] assume all CHs are capable of directly communicating with the sink. This may not be possible in a geographically large network where the sink is beyond the transmission range of many nodes.
Though many clustering solutions have been proposed [16], only a few combines clustering with a data routing scheme that is appropriate for large-scale WSNs [9–12, 17]. Hierarchical topologies are attractive for such large networks because of the scalability. A backbone network that arranges CHs in the form of a cluster tree can facilitate both the node-to-sink and node-to-node communication. Cluster trees are useful for a multitude of tasks such as delivering unicast, multicast, and broadcast traffic, data fusion, and in-network query processing.
A cluster tree can be formed using either a top-down or a bottom-up approach. In top-down approach, a designated root node first forms its own cluster. It then selects some of its neighbors (as CHs) to form their own clusters, which in turn causes some of their neighbors to form the next level of clusters, and the process continues until the entire sensor field is covered. The cluster tree is formed by keeping track of the parent-child relationship among CHs, and it is guaranteed to be connected as new child CHs are selected from neighbors of existing CHs. The IEEE 802.15.4 cluster tree follows this concept [18].
In bottom-up approach, individual clusters are formed independently and later combined together to form a higher-level structure. In [9], for example, nodes probabilistically elect themselves as CHs at different levels of the hierarchy and form their own clusters. The hierarchy is then formed by directly connecting a set of CHs at level i to a CH at level
The bottom-up approach, although conceptually appears to be relatively simple, involves considerable communication overhead for building a cluster tree [8–10, 17], and it provides very little or no control over depth and breadth of the tree. Conceptually, the top-down approach provides better control while forming clusters and the cluster tree. However, the existing top-down approaches, such as the basic scheme for IEEE 802.15.4 standard, result in undesirable cluster and tree characteristics such as large variations in cluster size and distance to leaf nodes [5, 13]. Within the framework of the IEEE 802.15.4 standard, however, there is flexibility to deploy alternative clustering approaches while still being compatible with the standard. We propose a configurable top-down clustering scheme in which parameters such as the number of nodes in a cluster and the breadth/depth of the cluster tree can be easily controlled while maintaining compatibility with the IEEE 802.15.4 standard.
A good clustering and routing solution should achieve the following desirable properties. Overlapping clusters add redundancy [20] and increase intracluster signal contention [2]. Thus, a given sensor field should be covered with the least number of clusters. Hexagonal clusters have the highest coverage area and cover the network with the least number of clusters [6, 20]. None-overlapping clusters allow better load balancing within clusters, bound the number of clusters and depth of the cluster tree tighter, and generate networks with predictable topology characteristics [6, 7]. Predictable topology characteristics, even on a randomly deployed network, facilitate intelligent routing solutions without being tied to the cluster tree. Aggregation is more useful when the CH is in the center of the cluster and capable of receiving sensor readings from all the directions [7]. Performance of upper layer functions such as routing and data fusion depend on the number of hops between nodes and the sink. As the hop count increases, both latency and energy required to forward a message increase. Therefore, a lower depth cluster tree is desirable. Less overlapped clusters also reduce the breadth and depth of the cluster tree [13]. Furthermore, distance between two adjacent CHs needs to be bounded to ensure the connectivity of the cluster tree. In summary, a good clustering solution should form clusters with minimum overlap, minimize the depth of the cluster tree, and ensure connectivity.
We propose a compound solution that achieves the aforementioned desirable cluster and cluster-tree properties while enabling efficient communication within large-scale WSNs. First, we propose the generic top-down cluster and cluster-tree formation (GTC) algorithm. GTC achieves desirable cluster and cluster-tree properties by combining the controllability of the top-down approach with local and neighbors' views of the topology. The algorithm is independent of the physical network topology and does not require a priori neighborhood information, location awareness, or time synchronization. Parameters in the algorithm allow cluster and tree characteristics to be changed, for example, a tree with controlled breadth/depth, while achieving more uniform and circular clusters. The IEEE 802.15.4 cluster tree [18], hereafter referred to as simple hierarchical clustering (SHC), is a special case of GTC achievable by controlling algorithmic parameters. Another special case, hop-ahead hierarchical clustering (HHC), is presented that produces more circular and uniform clusters and a cluster tree with lower depth. Cluster properties of HHC are comparable with hexagonal packing, particularly for low-density networks. The cluster tree is guaranteed to be connected as GTC bounds the distance between a parent and its child CHs. Second, we propose a post cluster-tree self-optimization phase that further enhances the structure of the cluster-tree, reduces its depth, and improves routability. Third, a hierarchical addressing scheme that reflects the parent-child relationship among CHs is proposed. Such hierarchical addresses simplify routing and help to reduce the size of routing tables. Fourth, a cluster-tree-based routing scheme that can forward messages to the sink as well as within the network is presented. Two routing extensions, namely cross-link-based routing and circular-path-based routing, are presented, that deliver more than two, and five-times more messages, respectively. These routing schemes enable multiple and shorter routes to a given destination.
Section 2 presents the GTC algorithm, controlling the cluster and cluster tree properties, and the self-optimization phase. Hierarchical addressing and routing schemes are presented in Section 3. Section 4 presents the performance analysis. Concluding remarks and future work are presented in Section 5.
2. Cluster and Cluster Tree Formation
2.1. Top-Down Clustering Algorithm
A discussion of basic algorithm steps is presented first, followed by the specific details. The root node, one of the sensor nodes or a resourceful base station, initiates the cluster formation process by sending a broadcast indicating its interest to form a cluster. Nodes that hear the broadcast become members of the cluster by sending an acknowledgment (ACK) to the root node. Coverage of a cluster depends on whether a single-hop or a multihop cluster is formed by forwarding the broadcast through neighbors. The parameter hopsmax is used to provide a bound on the number of hops to a cluster member from the CH. After receiving ACKs from neighbors, the root node selects several new child CHs from subset of the nodes closer to the cluster boundary. Overlap among clusters can be reduced by selecting child CHs from nodes that are outside the cluster boundary. Such outside nodes can be discovered by forwarding the broadcast beyond hopsmax and their distance can be bound using the parameter TTLmax (TTLmax ≥ hopsmax). The root node then requests those selected child CHs to form their own clusters in turn by sending a unicast message to each of them. New CHs form their own clusters and then select the next set of child CHs and the process continues. Meanwhile, the cluster tree is formed by each CH keeping track of its parent and child CHs. The algorithm continues until all the possible clusters are formed.
The Generic Top-down Cluster and cluster-tree formation (GTC) algorithm is shown in Algorithm 1. The root node initiates the cluster formation process by executing the Form_Cluster function. All the other nodes execute the Join_Cluster function and listen for a cluster-formation broadcast. Root node sends a cluster-formation broadcast (Bcast_Cluster) indicating its node ID (NIDCH), Cluster ID (CIDCH), maximum number of hops to a cluster member from the CH (hopsmax), number of hops to forward the broadcast (TTLmax), and its depth in the cluster tree. Important algorithm parameters are listed in Table 1. A node hearing this broadcast will join the cluster, if it is not already a member of another cluster (my_CID = 0) and within hopsmax. A node joins the cluster by initializing its cluster parameters such as cluster ID, CH's node ID, and depth in the cluster tree (lines 17–19, Algorithm 1). An acknowledgment (ACK) is then sent to the corresponding CH (line 20) indicating its own node ID (my_NID), distance to the CH (hops), and set of properties of the node (
Algorithm parameters/variables.
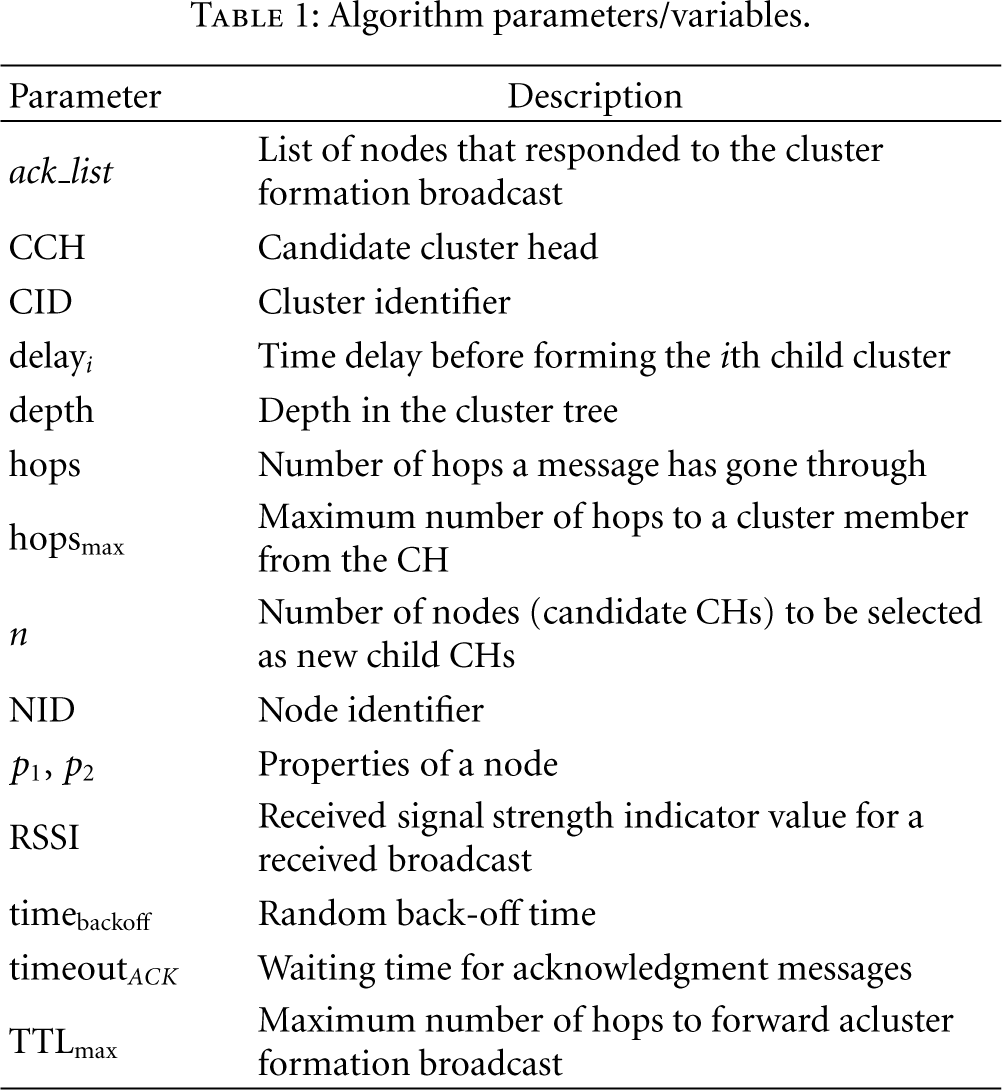
(1) Wait (delay) (2) (3) Bcast_Cluster ( (4) ack_list ←Receive_ACK ( (5) (6) Join_Cluster() (7) (8) (9) (10) delayi← Select_Delay (11) depthi← depth + 1 (12) Rqst_Form_Cluster ( (13) Lstn_Bcast_Cluster ( (14) (15) (16) (17) (18) (19) (20) Send_ACK (my_NID, hops, (21) (22) Wait (Random (timebackoff)) (23) Fwd_Bcast_Cluster ( (24) (25) Exit (26) (27) (28) Send_ACK(my_NID, hops, (29) (30) Form_Cluster (my_NID, CID, delay, n, (31) Exit (32) Join_cluster
Intermediate nodes between (hopsmax, TTLmax) hops do not join the cluster, instead help forward the broadcast further. They do not send any ACKs. A broadcast from a particular CH is forwarded only once by a receiving node; hence, broadcasts are forwarded outward from the CH. When the broadcast reaches the last hop (i.e., TTL expires) the nodes that received the broadcast are capable of being selected as new CHs. Such a node is called a candidate cluster head (CCH). At this stage, the CCH nodes are either at the edge of the cluster (if TTLmax = hopsmax) or outside the cluster (if TTLmax > hopsmax). By listening to the transmissions from neighbors, the possibility of selecting two nearby nodes as CCHs can be reduced. Therefore, each candidate node waits a random time (Wait_Lstn_Neighbors) before sending an ACK to the corresponding CH. While waiting, nodes keep listening and try to detect any ACKs sent by their neighbors to the same CH. If such an ACK is detected (line 27, function returns TRUE), the node gives up its candidacy to be a new CH and retries to join a cluster, that is, reruns the Join_Cluster function. If no ACK is detected by the time the function timeouts (no neighbor is still interested in becoming a CCH), node confirms itself as a CCH and informs this to the corresponding CH by sending an ACK (line 28). Child CHs are chosen from this spatially distributed set of CCHs, and therefore generates a less overlapping set of clusters. After sending the ACK, each CCH waits for a cluster formation request (Lstn_Form_Cluster) from the corresponding CH. Meanwhile, a CCH may join a different cluster if it hears a new broadcast and is within hopsmax from the new CH. This further prevents the formation of overlapping clusters and ensures all nodes are covered by clusters.
In the meantime, the corresponding CH keeps receiving ACKs until the Receive_ACK function timeouts (line 4). A new set of child CHs are then selected from the CCHs in the ack_list, using the Select_Child_CHs function. Finally, a request is sent to each selected CCH asking them to form their own clusters (Rqst_Form_Cluster). Each request also includes the new cluster's ID (CID i ), a hold-up time (delay i ) before forming the new cluster, and other relevant parameters. Upon receiving the requests, selected CCHs form their own clusters by executing the Form_Cluster function. These CHs then select the next set of child CHs and the process continues. The cluster tree is rooted at the root node and formed by each CH keeping track of its parent and child CHs. If a selected CCH is unable to attract any child nodes, a cluster is not formed and the related branch in the cluster tree is not expanded further. The algorithm continues until all possible branches are expanded.
2.2. Control of Clusters and Cluster Tree Characteristics
GTC algorithm can achieve a wide range of solutions by varying the implementation of functions Select_Child_CHs and Select_Delay, and controlling the parameters hopsmax and TTLmax. hopsmax controls the coverage of a cluster while TTLmax controls the distance between a parent and its child CHs. Multihop clusters are formed when hopsmax > 1. When TTLmax = hopsmax, CCHs are selected from nodes that are at the edge of the parent cluster. Figure 1(a) illustrates the best theoretical cluster packing that can be achieved when hopsmax = TTLmax = 1. For simplicity, only a selected set of CCHs is shown and one branch is expanded into several levels. It is sufficient for a CH to select three CCHs, if those are separated physically as widely as possible. Let

Physical shape of ideal single hop clusters: (a) simple hierarchical clustering, hopsmax = TTLmax = 1; (b) hop-ahead hierarchical clustering, hopsmax = 1, TTLmax = 3. Straight lines indicate the parent-child relationship among CHs.
The overlap between parent and child clusters can be reduced by selecting nodes that are outside the parent cluster as CCHs. Cluster-formation broadcasts can be propagated beyond the parent cluster (i.e., TTLmax > hopsmax) through a set of intermediate nodes to select some of the distant nodes as CCHs. When TTLmax = 2hopsmax, the overlap between a parent and its child clusters is reduced. It also ensures that both clusters have the same hop count. Though this is a significant improvement over SHC, clusters can still overlap due to random node placement, that is, it is not always possible to find an optimum set of CCHs that is furthest from the parent CH. For minimum overlap, the ideal distance between a CH and its CCHs should be just above 2hopsmax. Hence, it is more appropriate to select TTLmax = 2hopsmax + 1. This multihop forwarding approach is named hop-ahead hierarchical clustering (HHC). Figure 1(b) illustrates the ideal circular packing with single-hop HHC. The root node (
Each parent CH uses the Select_Child_CHs function to select child CHs from a set of CCHs. Implementation of the function depends on the availability of node properties such as node degree, residual energy, cryptographic key identifiers, or location information. When a node sends an ACK to the CH, such properties are reported using parameters
An RSSI-based heuristic to select a spatially distributed set of CCHs is presented next. Clusters overlap if CCHs are pushed by 2hopsmax, but coverage holes are created if they are pushed all the way up to 2hopsmax + 1 (Figure 1(b)). A better alternative would be to select a node that is just above 2hopsmax as a CCH [13]. An RSSI-based heuristic can be used to forward the cluster-formation broadcast to the maximum distance within 2hopsmax and then select a nearby node as a CCH. The heuristic can be implemented by modifying lines 22 and 27 of the GTC algorithm:
Wait (RSSI + Random (timebackoff))
The waiting time now depends on the RSSI value of the received broadcast and the random back-off time. Random back-off time is used to differentiate the waiting time among nodes with the same RSSI. According to line 22, a node with a lower RSSI (i.e., higher distance) gets priority in forwarding the broadcast than a node with a higher RSSI. This allows the nodes that are furthest away from the CH and within 2hopsmax to forward the broadcast first. Then in the last hop, a nearby node (i.e., one with higher RSSI; note 1/RSSI in line 27) gets priority in becoming a CCH than a distant node. Therefore, the time that such a node keeps listening for ACKs (sent by neighbors) is shorter than the nodes that are further away. If such an ACK is detected, the node gives up its candidacy to be a new CH and retries to join a cluster. Thus, the waiting time is used to prevent nodes in the same neighborhood from becoming CCHs and thereby achieve spatial separation. Distant nodes are selected only if they do not hear any ACKs from their neighbors. Consequently, CCHs are primarily selected from a spatially separated set of nodes that are just beyond 2hopsmax. Then n (
Cluster properties are affected when multiple child CHs try to form clusters at the same time. Therefore, we reduce collisions among cluster-formation broadcasts by a randomized scheduling scheme. Each parent CH determines a time delay (delay
i
) that each of its child CHs needs to wait before forming its own cluster, using the Select_Delay function. Furthermore, the shape of cluster tree can be controlled by appropriately selecting delay
i
values. For breadth-first tree formation, delay should ensure that cluster formation of level j completes before the start of level 
The cluster tree starts from the root node and is formed by each CH keeping track of its parent and child CHs. Parent and child CHs can be physically linked using either single-hop (high-power) or multihop (low-power) transmissions. Typically, long-range intercluster communication is desirable due to low latency and simplified routing [11, 16]. It further enables non-CHs to sleep while not sensing or transmitting [16]. Because any node is capable of becoming a CH, this approach is suitable if either the nodes can tune their transmission power or the CHs are later replaced by energy-rich actor nodes [11]. Henceforth, we assume high-power transmissions among CHs.
In top-down clustering, a set of child CHs is always selected from the nodes that are at a bounded distance from the parent CH. The cluster tree that connects those CHs is therefore guaranteed to be connected, if the intercluster communication range of CHs is higher than the distance bound. The same property holds for the GTC algorithm as the distance between a parent and its child CHs is bounded by TTLmax. Thus, the cluster tree is guaranteed to be connected if
Based on hexagonal packing, lower and upper bounds are derived for the depth of a cluster tree formed by interconnecting single-hop clusters. Assume a circular sensor field (see Figure 2) with uniform node distribution. The root node is placed in the center of the sensor field. Let C be the radius of the sensor field and r be the transmission range of a node. Let

Hexagonal packing of a circular sensor field.
Analysis along the X-axis provides an upper bound. Consider inset (b) in Figure 2, which shows analysis of a border case. If the edge of the sensor field is beyond the line QS drawn through point P (

Lemma 1.
Worst-case message complexity of the GTC algorithm is O(
Proof.
Let us first analyze the cost to form a single cluster and then analyze the number of clusters to be formed. Suppose N nodes are uniformly distributed within a sensor field (with area A) such that the network topology forms a connected graph for a given transmission range r. Because a node forwards the cluster-formation broadcast only once, the number of broadcast messages per cluster is the same as the number of nodes within (

Largest number of clusters is formed when nodes are placed along a line with internode distance of r. If the root node is placed at one end of the line, first cluster will contain hopsmax + 1 nodes. Rest of the clusters will have 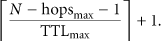
Lemma 1 is a very loose bound, thus average complexity is derived next. Let
2.3. Cluster Tree Self-Optimization Phase
Though the cluster tree formed with the HHC scheme is significantly better, it is suboptimal as the breadth and depth of the tree depend on several factors such as node distribution, which nodes are randomly selected as CCHs, and which of those selected CCHs are able to form clusters. A cluster-tree self-optimization phase is presented next that could further improve the breadth and depth of the tree.
Cluster tree self-optimization is performed by exchanging another set of messages among CHs. After the cluster formation phase, each CH (staring from the root node) sends at least one broadcast announcing its depth to neighboring CHs. A neighboring CH receiving this broadcast, checks whether the received depth is lower than its parent CH's depth. If so, the neighboring CH selects the broadcasting CH as its new parent CH and reorganizes its cluster tree membership. It then sends a new broadcast enabling its child and neighboring CHs to upgrade their depth. This approach increases the breadth of the cluster tree, while consequently reducing its depth.
Algorithm 2 formally describes this process. After the cluster formation phase, each of the CHs (except the root node) executes the Lstn_Optimize_Tree function to upgrade its depth in the cluster tree. The root node initiates the optimization phase by sending a broadcast (Bcast_CH_Presence) with its NIDCH, CID, and depth. When a broadcast is received, each CH compares its current depth (my_depth) with what was heard from its neighbor. If the new depth is lower, it sets the broadcasting CH as its new parent CH. After receiving the first broadcast, each CH generates a new broadcast with its own data (line 8). Even a CH that does not benefit from the new depth information, that is, current depth is lower, has to send its own broadcast once. This ensures that each CH receives at least one broadcast, and therefore gets the opportunity to upgrade its tree membership. If a CH hears a subsequent broadcast with even lower depth, it reorganizes the tree membership and regenerates a new broadcast with the updated depth.
(1) Lstn_Bcast_CH_Presence ( (2) (3) my_CID ←CID (4) my_CH ← (5) my_depth ←depth + 1 (6) opt_msg_send ← (7) (8) Bcast_CH_Presence ( (9) opt_msg_send ←
The self-optimization algorithm is independent of the intercluster communication mechanism. Therefore optimization messages can be forwarded as either single (TTL = 1) or multiple (TTL = TTLmax) hop broadcasts. Single-hop broadcasts utilizing high-power therefore can directly reach nodes that were not reachable during the cluster formation phase (due to lack of intermediate nodes). This enables many CHs to improve their cluster tree membership. Consequently, breadth of the tree increases and depth reduces. During this phase, non-clustered nodes can join a nearby cluster if they hear a broadcast.
3. Routing
3.1. Cluster-Tree-Based Routing
Though many hierarchical routing schemes are designed to deliver data only towards the sink [1, 2, 9, 10], many WSN applications also require communication within the network [8, 14, 26]. If root node is either the sink or capable of forwarding messages to the sink, node-to-sink communication can be easily facilitated by forwarding data to upper levels in the cluster tree. However, an addressing scheme is required to facilitate node-to-node communication. Assume that the sender knows the destination address, through some other mechanism. In [27], we propose a mechanism to determine destination addresses in virtual sensor networks [14].
Our routing scheme makes use of the cluster tree formed with the HH C scheme (Figure 3) because of its desirable cluster and tree properties. Assume CH J wants to communicate with CH P. The message is first forwarded to C, as it is the parent CH of J. C only knows about its parent A and children J, K, and L. Therefore, C has to either drop the message or forward it to parent A. Even A does not know about P. This problem can be overcome by each CH keeping track of all its descendants. If C was aware that P is the child CH of L, it could have directly forwarded the message to L, which can forward it to P. As we go up the tree, more and more data about descendant CHs needs to be stored and the root node has to keep track of the entire network. This approach is not scalable in supporting communication among the nodes.

(a) A hypothetical sensor field covered with ideal HHC clusters; (b) corresponding cluster tree with hierarchical addresses. Scattered lines indicate cross-links among neighboring CHs.
A variable length hierarchical addressing scheme (Figure 3(b)) that reflects the parent-child relationship among CHs to overcome these issues is proposed next. A hierarchical address is assigned to a CH based on its branch number and parent CH's address. Branch numbers are relative to the parent CH and are determined based on the order that child CHs are selected from the set of CCHs. Branch numbers have a zero-based index. The root node (A) does not have a parent CH hence we assign its address as 0. B is the first child CH of A therefore gets address 00, second child C gets address 10, and G being the sixth child CH gets address 50. When B assigns addresses to its child CHs, it merges its address 00 with the child's branch number. Thus, the first child H gets address 000 while the second child I gets address 100. The branch related to H is discontinued as it does not have any child CHs. Q is the one and only child of I hence gets the address 0100. Address 210 is not assigned because the child CH that was given the address did not form its own cluster. Each CH is aware of the addresses of child CHs that were not able to form a cluster. If needed, such addresses can be reassigned to new child CHs that are added during the self-optimization phase. Then L, the fourth child, gets the address 310. The hierarchical addresses of each child CH is generated by the Select_Next_CID function of the GTC algorithm. Our addressing scheme satisfies all the necessary properties defined in [26].
To enable routing, each CH needs to keep track of only the addresses of its parent and child CHs. Root node keeps track of its immediate child CHs. Therefore, hierarchical addresses significantly reduce the number of routing entries at a CH. Given the hierarchical address of a destination, entire path to the destination can be determined. Next hop to forward a message can be determined using the pseudocode in Algorithm 3. A hierarchical address can be represented as an array of digits (Figure 3(b)) with the least significant digit (LSD) indicating the root node's branch number. The input variables current and destination indicate the hierarchical addresses of the CH that is trying to determine the next hop and the destination CH, respectively. Individual digits of the two addresses are compared starting from the LSD (line 4), until a mismatch is found. When the loop terminates, variable i indicates the number of matching digits. Digits that match indicate the address of the CH that two addresses converge. If i < Depth (current), the rendezvous is above the current CH hence the message should be forwarded to the parent CH. Otherwise, the rendezvous is below the current CH (line 9) and the message should go to one of the child CHs. Child CHs branch number can be determined from the (
(1) (2) (3) min_depth ←Min(Depth (current), Depth (destination)) (4) (5) (6) (7) (8) (9) (10)
3.2. Cross-Link-Based Routing
The root node is a single point of failure in hierarchical topologies. It spends energy much faster than the rest of the nodes, as it handles all the traffic going either to the base station or across different branches. If it is not energy constrained, its power limited child CHs will run out of energy faster than the remaining nodes as they share the traffic going through the root node. Multiple high-energy nodes can be placed closer to the root node to handle more traffic [28]. Yet such solutions are unable to utilize the energy available in rest of the network, which is critical in enabling communication within the network. We propose two routing approaches that make use of the energy available in rest of the CHs.
In a clustered network, neighboring clusters may belong to different branches of the cluster tree, for example, CHs H and J in Figure 3 belong to completely different branches of the tree. As they are in the same neighborhood, they can hear each other's messages and figure out each other's hierarchical addresses. Cross-links formed among such neighboring clusters can be used to forward messages across different branches of the cluster tree. For example, suppose H wants to communicate with K. A message travelling through the cluster tree will take the path
It is not desirable to go through cross-links, just because they are available. The same hierarchical addresses can be used to determine whether it is shorter (or same) to go through the root node or across one of the cross-links. Given addresses of CHs H (000) and K (110), their rendezvous is the root node. Both H and K have two-hops to the root node hence the distance is four-hops. If H compares
3.3. Circular-Path-Based Routing
More uniform and circular clusters of the same depth tend to be somewhat localized and lie on approximately concentric set of rings (see Figure 2). Therefore, as seen in Figure 4, cross-link based routing can be further extended by combining multiple cross-links that are at the same depth of the cluster tree to form circular-paths within the network. A path can be formed by sharing cluster addresses not only with the neighbors but also with neighbors of neighbors, if they lead to a better route. Such circular-paths enable many alternative routes without being tied to the cluster tree.

Cluster tree with a circular path constructed by connecting level 2 CHs that are in the same neighborhood.
Suppose a node in CH U (see Figure 4) wants to communicate with a node in CH K. A message going from U to K has to travel five-hops if it goes through the cluster tree. U is not in a circular-path; therefore, tree can be used to forward the message to its parent CH M. M is in the circular-path hence has the option of selecting either the circular-path (needs three-hops) or the cluster tree (needs four-hops). The route through circular-path is preferable as it is shorter and avoids the root node. The resulting route U→M→P→L→K is four hops long and utilizes both the tree and the circular-path.
To determine the path length, M has to know about K's address through neighboring CHs P and L, beforehand. It is not useful to share each CH's address with all the other CHs in a circular-path. For example, CHs H and P require four-hops to communicate with each other using either the tree or the circular-path. Circular-path is preferred as it reduces the burden on the root node. Therefore, it is useful for H and P to know about each other. For P's neighbor M, it takes four-hops to reach H through the tree and five-hops through the circular-path. Therefore, H's address is not useful to M and should not be propagated any further. Hierarchical addresses are useful in determining path lengths and making sure that only relevant addresses are shared among CHs along a circular-path. Though it is not possible to form a complete set of circles in a randomly deployed network, even partial circles are useful. Using a simplifying example it is possible to show that cluster tree with circular-paths has the largest lifetime.
Example 3.3.
Lower bound of network lifetime using the three routing schemes has the ordering: cluster tree with circular-paths > Cluster tree with cross-links > cluster tree.
Argument
Consider the lifetime of the network to be the time before the first node dies. Performance of node-to-node communication is evaluated as node-to-sink performance is same for all routing schemes. Assume nodes are homogeneous, and source and destination nodes are uniformly distributed across the network. It is complicated to derive the exact lifetime of the network considering depth/breadth of cluster tree and position of all source/destination nodes [13]. Therefore, a lower bound is derived by considering only the root node and level 1 CHs. Let CH1 indicate a level 1 CH and λ be the packet arrival rate at a CH1. In cluster-tree-based routing, a packet arriving at a CH1 has to go to one of its descendants, to the root node, or to one of the remaining five level 1 clusters through the root node (Figure 3). Compared to the size of the network N, the root node has only a small number of cluster members. Therefore, it is reasonable to assume that each CH1 is responsible for relaying packets to N/6 nodes. Hence, 1/6 of the packets will go to the descendants while remaining 5/6 will go across the root node. As there are six CH1s, total load on the root node is 5λ. When cross-links are present, each CH1 has two neighboring CH1s (Figure 3). Then 1/6 of the packets will go to the descendants, 2/6 through neighboring CH1s, and remaining 3/6 through the root node. Hence, the total load on the root node is 3λ. It can be shown that root node is still the bottleneck. Distance between any two CH1s along the cluster tree is 2-hops (Figure 4). Therefore, when a circular-path is available each CH1 keeps track of neighboring CH1s that are within 2-hops. There are four such neighbors that could be used to reach 4N/6 nodes. However, CH1s are now the bottlenecks because excessive use of the circular-path overloads them. A CH1 has to forward λ packets originating from its descendants. In addition, its neighbors (two such neighbors) use it to reach 2/6 of the nodes while each of the remaining two-hop neighbors uses it to reach 1/6 of the nodes. Then the total load is λ + 4λ/6 + 2λ/6 = 2λ. Let P be the number of packets that can be relayed by a node. Therefore, lifetime of the network under each routing scheme is
Formation of cross-links and circular-paths at higher levels of the cluster tree will enable identification of better paths without coming all the way down to level 1. Therefore, the actual number of packets delivered by each routing scheme will exceed the lower bound.
4. Performance Analysis
4.1. Simulator
A discrete-event simulator is developed using C. 5000 nodes are randomly placed on a circular region with a radius of 500 m. The root node is placed in the middle of the sensor field. Single-hop clusters are formed using the breadth-first tree formation approach. Intercluster communication is single hop. Child CHs are selected randomly from a set of CCHs and for each simulation, the random function is initialized with a different seed. We compare our results with hexagonal packing that initiates from the root node. A circular sensor field is considered to make the comparison with hexagonal packing easier. Average circularity of clusters is defined as
4.2. Cluster and Cluster-Tree Characteristics
Figure 5 illustrates the physical shape of clusters formed by SHC and HHC schemes. Only the first SHC cluster has approximately a circular shape while the shapes of other clusters vary widely (Figure 5(a)). Child CHs are selected from nodes that are closer to the edge of the parent cluster, for example, CH of

Physical shape of single-hop clusters: (a) SHC clusters; (b) HHC clusters.
Circularity of single-hop clusters is summarized in Figure 6. HHC and RSSI heuristic-based HHC (R-HHC) clusters have much higher circularity than SHC. Ideal hexagonal clusters have the highest circularity. Ability to push CCHs further away from the parent CH reduces the overlap among most of the HHC clusters. However, as we push the CCHs further away, they can create coverage holes in the network (Figure 1(b)). Sometimes smaller clusters are formed to cover up such open regions, for example,

Circularity of clusters. Error bars indicate the 5th and 95th percentile.
Due to the following factors, circularity reduces as the intracluster transmission power
Number of clusters/CHs produced by each scheme is shown in Figure 7. Number of clusters required to cover a given sensor field depends on both the circularity and geographical area covered by a cluster. Because of higher circularity, HHC produces a lower number of large clusters. As
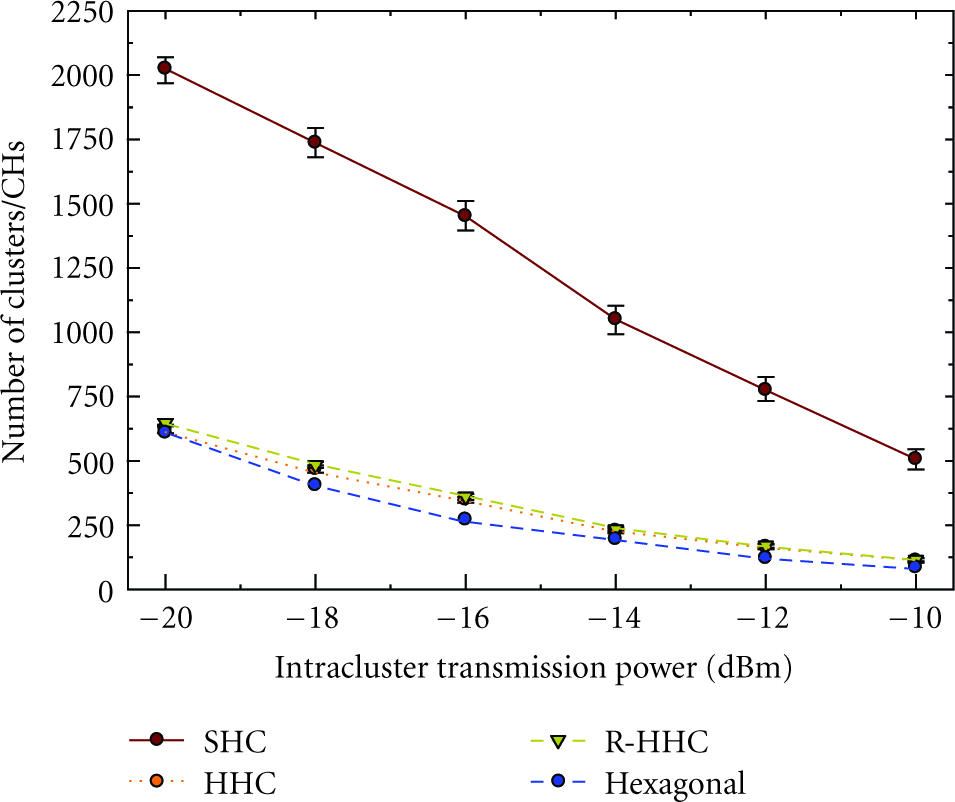
Number of clusters and cluster heads. Error bars indicate the 5th and 95th percentile.
We further evaluated the impact of node density on cluster characteristics. When the network is sparse, clusters are more circular. When it is dense, even a small coverage hole with one or two nodes needs to be covered by a new cluster. Consequently, circularity reduces with the increasing node density. Table 2 shows per node cluster and cluster-tree formation overhead. Uniform coverage property of R-HHC does not require the creation of new clusters to cover up coverage holes, and thus has the lowest overhead. Extra messages required by the post cluster-tree self-optimization phase (HHC-Opt) increase the overhead by approximately 1.5 messages per node, corresponding to around 25% increase. Per node overhead for different network sizes (N) are similar, which confirms that the average message complexity of GTC algorithm is O(N). We further build two other discrete-event simulators to compare HHC with FLOC [7] and the scheme given in [9]. While FLOC also shows a similar behavior for increasing
Number of control message per node.

Figure 8 shows the distribution of CHs in the cluster tree. HHC and R-HHC schemes form much shorter trees than the SHC scheme. Due to high overlap among SHC clusters, some branches of the cluster tree are discontinued, resulting in a longer tree. Alternatively, HHC and R-HHC clusters are more uniformly distributed; therefore, tree has a higher branching factor and a lower depth. R-HHC selects a spatially distributed set of CCHs. Hence, most of the selected child CHs can form their clusters resulting in increased branching factor and reduced depth. Such a lower depth and higher breadth cluster tree is desirable in many WSN applications. The self-optimization phase reorganizes the cluster tree membership allowing a CH to connect to a new parent CH with a lower depth, while producing a shorter tree. Clusters become larger as
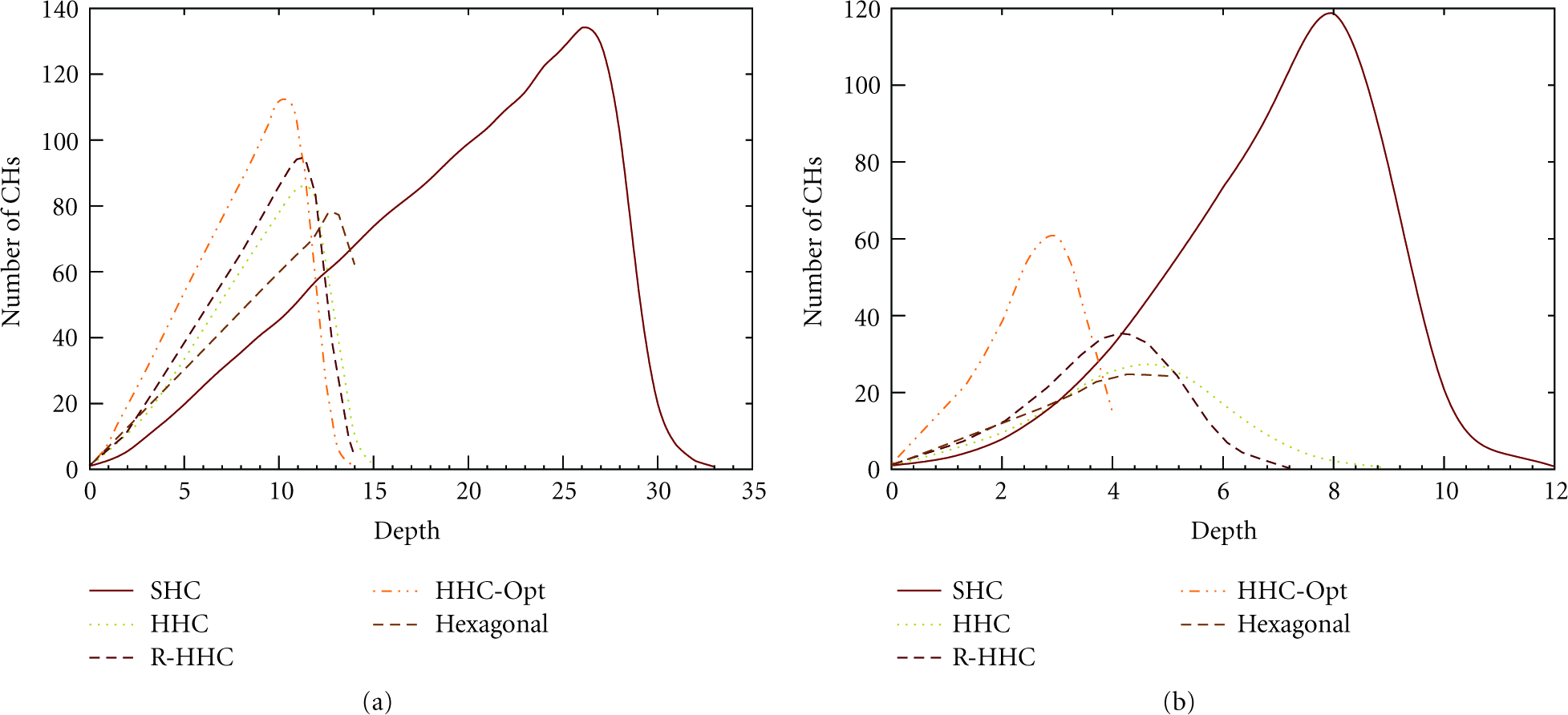
Distribution of CHs at different levels of the cluster tree: (a)
Physical shape of the cluster tree formed by one of the data samples is shown in Figure 9(a). Figure 9(b) shows the same tree after the cluster-tree self-optimization phase. The optimized tree is more structured and shorter than the original one. In addition to the maximum depth (see Table 3), the number of intersecting links and CHs having higher depth than their distant neighbors can be used to determine the orderliness and regularity of a cluster tree. In Figure 9(a), links AB and AC intersect link DE. Such intersections are not desirable as they could lead to collisions during intercluster communication. Original tree has 34 intersections and it is reduced to 15 in the optimized tree. Furthermore, node E is physically more closer to the root node than node A yet its depth is 3-hops higher than that of A. Such cases should be avoided as they unnecessarily increase the path length, and therefore increase the energy consumption and latency. Original tree has 24 such CHs and all of them are removed in the optimized tree. Thus, optimized tree is more structured. Note that after the optimization phase all the disconnected nodes in Figure 9(a) are connected to a cluster.
Comparison of theoretical and empirical depth of the cluster tree.


Physical shape of the cluster tree formed with HHC scheme: (a) before optimization; (b) after optimization.
Such a structured topology reduces path length and latency, and can be used to build an addressing scheme that reflects the geographical location of CHs, for example, using an approach similar to that in [31]. Simulation results and the depth predicted by (3) are compared in Table 3. For lower
4.3. Performance of Routing
After the cluster formation phase, each CH sends a broadcast with its hierarchical address allowing its neighbors to form cross-links. Circular-path based routing requires the formation of set of rings within the network by connecting CHs at the same depth. In practice, it may not be possible to build a closed ring because CHs with same depth may not lie on a set of concentric rings and could further depend on node positions and physical shape of clusters. Therefore, we relax the same depth constraint by allowing a CH to share addresses with neighboring CHs, if neighbors' depth is one level higher than its own depth. Messages are sent between randomly selected source and destination node pairs. For comparison, we take the number of messages delivered until the first node dies.
Figure 10 shows the number of messages delivered by each routing scheme. Use of cross-links reduces the workload on the root node, and therefore increases the message capacity by 2.1–2.4 times than routing with only the cluster tree. Circular-paths distribute the workload across many CHs, therefore they deliver 2.7–3.2 times more messages. Relaxed circular-path construction (Circular + 1) increases the capacity by 5.2–6.4 times. The cluster-tree self-optimization phase forms a more structured topology allowing even better construction of circular-paths. Therefore, circular-path routing on top of the optimized tree (Tree (Opt) + Circular) is able to deliver 3.6–5.5 times more messages while relaxed circular-path construction delivers 6.0–8.1 times more messages. Tree-based and cross-link-based routing schemes are unable to benefit from the self-optimization phase because the root node is the bottleneck (see the example in Section 3.3). Nevertheless, all routing schemes benefit from shorter routes along the optimized tree, and therefore become more suitable for latency bound sensor applications. All the routing schemes deliver lower number of messages with increasing
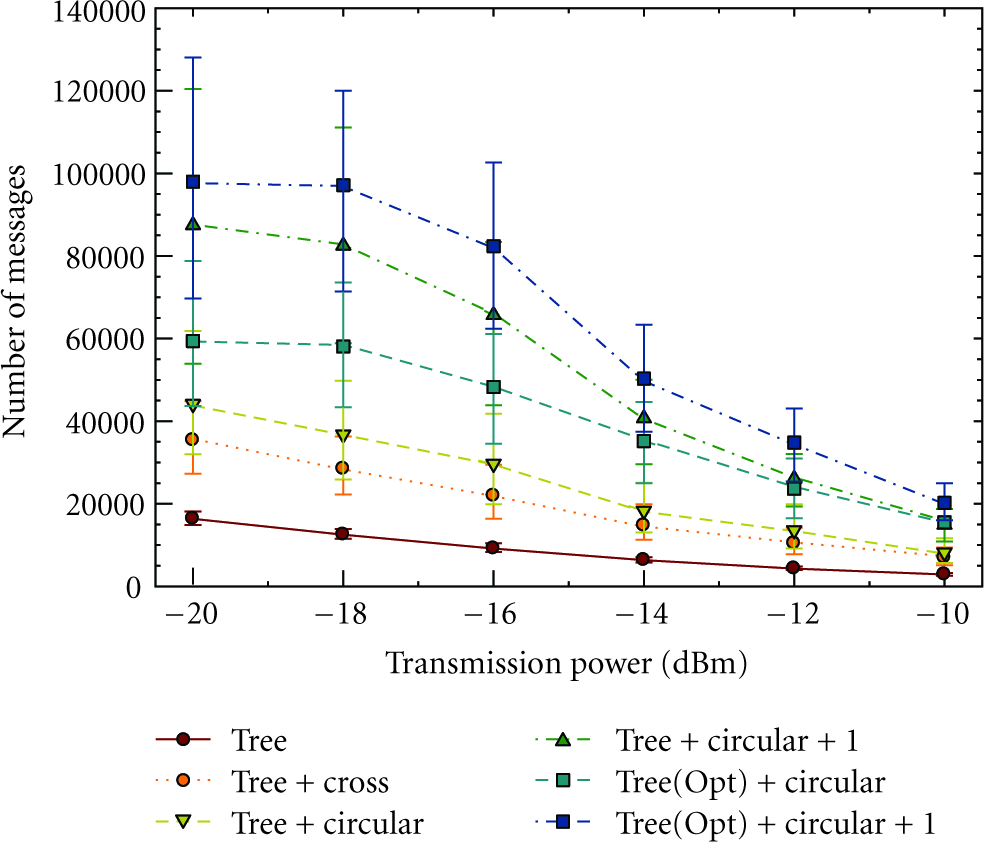
Number of messages delivered by each routing scheme. Error bars indicate the 5th and 95th percentile.
Average residual energy of CHs at the end of the network lifetime is shown in Figure 11. The root node depleted its energy in both cluster-tree-based and cross-link-based routing. For circular-paths, however, the bottleneck is among CHs between depths 1–4; thus, the bottleneck has shifted to the middle of the tree. Relaxed circular-path construction scheme is able to distribute the workload even more and utilizes energy available in CHs between depths 1–8, thereby delivering a significantly higher number of messages. This behavior of the routing schemes further confirms the analysis of example in Section 3.3. Figure 12 shows the energy consumption of the network assuming nodes have sufficient power to stay active for a long time. Cluster formation and address discovery overhead are constant. Therefore, all the routing schemes linearly increase the number of delivered messages as the energy per node increases, a behavior confirmed by simulation results as well. Though relaxed circular-path construction has the highest initial overhead (due to address sharing with many nodes), it performs best by being able to send a large number of messages over a long period. It reduces the energy per message by identifying shorter routes and thus significantly extends the network lifetime by distributing the workload across many CHs. Circular-path based routing's ability to distribute the workload while alleviating hotspots is desirable in WSNs that are capable of harnessing energy, where it allows sufficient time for nodes to regain energy thus extending the network lifetime.
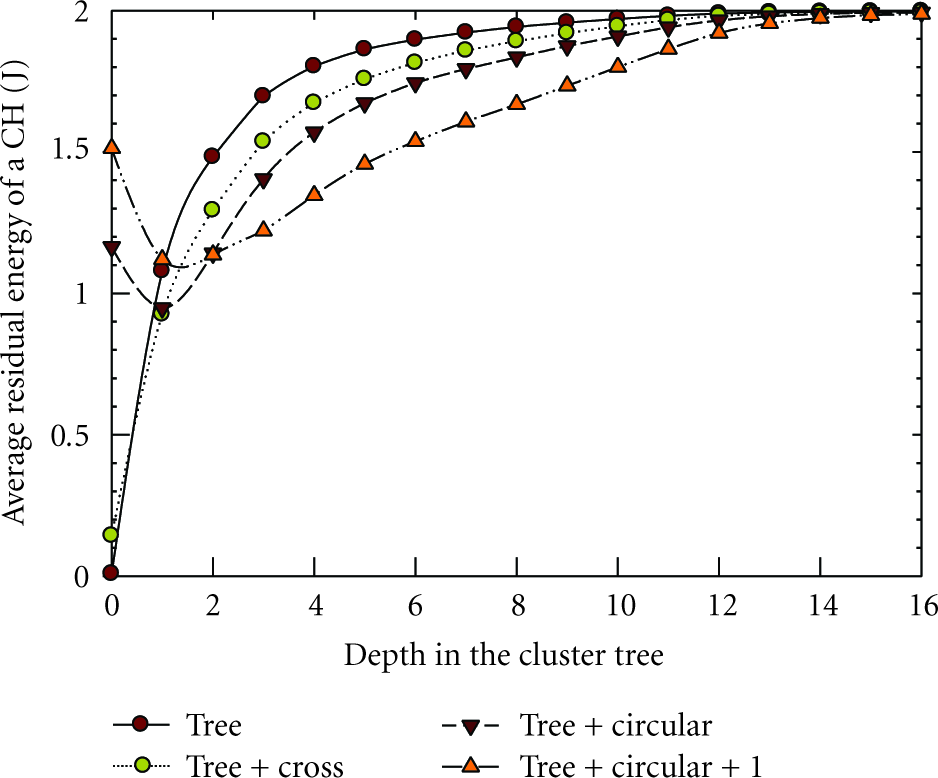
Average residual energy of CHs at different depths of the cluster tree at the end of the network lifetime.
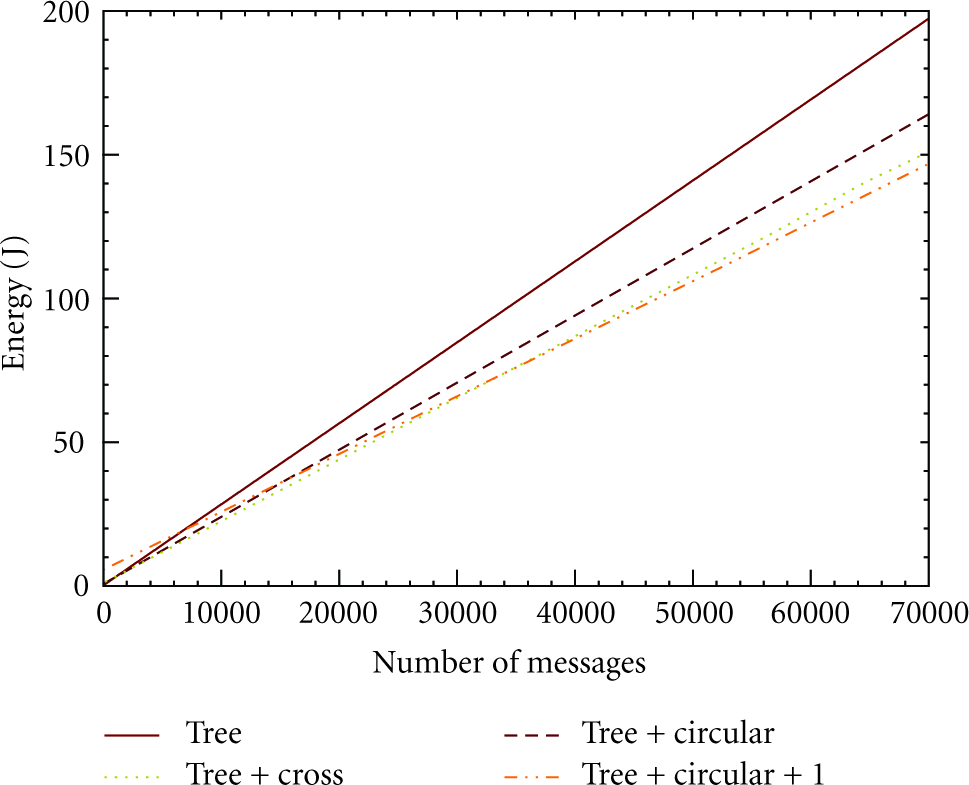
Energy consumption of the network with time.
5. Conclusions
A top-down cluster and cluster-tree formation algorithm that is independent of network topology, and does not require a priori neighborhood information, location awareness, or time synchronization is presented. GTC is configurable where parameters such as the number of nodes in a cluster and breadth/depth of the cluster tree can be controlled. For example, the HHC scheme of the GTC algorithm forms more uniform clusters and a cluster tree with a lower depth. RSSI-based heuristic forms even more uniform and circular clusters and a shorter tree, but relies on RSSI for distance estimation. Cluster and tree properties are comparable to hexagonal packing for low intracluster transmission power levels and sparse networks. The post cluster-tree self-optimization phase forms an ordered cluster tree and reduces its depth. Therefore, it is desirable in latency-bound applications. Hierarchical addresses based cluster tree routing facilitates communication within the network as well as with the base station. Cross-link-based and circular-path-based routing schemes increase the network lifetime by two and three times, respectively. Relaxed heuristic based circular-path construction improves the lifetime by five-times while it gains a six to eightfold improvement when self-optimization is enforced. It performs best over a long period, thus it is desirable for networks that exist over a very long period and networks with nodes that harness energy. In [27], we proposed a cluster-tree-based implementation of virtual sensor networks [14], and demonstrated the efficacy of our scheme by simulating a subsurface chemical plume monitoring system [13].
Footnotes
Acknowledgments
This paper is supported in part by grant from Environmental Sciences Division, Army Research Office (AMSRD-ARL-RO-EV). The authors wish to thank the reviewers for the comments that have resulted in significant improvements to the paper.