
Abstract
Power management is addressed in the context of embedded systems from energy-aware design to energy-efficient implementation. A set of mechanisms specifically conceived for this scenario is proposed, including a power management API defined at the level of user-visible system components, the infrastructure necessary to implement that API (namely, battery monitoring, accounting, autosuspend, and autoresume), an energy-event propagation mechanism based on Petri nets and implemented with aspect-oriented programming techniques, and an autonomous power manager build upon the proposed API and infrastructure. These mechanisms are illustrated and evaluated using realistic wireless sensor network cases that sustain comparisons with other proposals at each of the considered levels. As a result, this paper has its main contribution on the introduction of a comprehensive and systematic way to deal with power management issues in resource-constrained, battery-operated systems.
1. Introduction
Power management is a subject of great relevance for two large groups of embedded systems: those that operate disconnected from the power grid, taking their power supply from batteries, photovoltaic cells, or from a combination of technologies that yet impute limitations on energy consumption and those that face heat dissipation limitations, either because they depend on high-performance computations or because they are embedded in restrictive environments such as the human body. Both classes of embedded systems can benefit from power management techniques at different levels, from energy-efficient peripherals (e.g., sensors and actuators) to adaptive digital systems to power-aware software algorithms.
Historically, power management techniques rely on the ability of certain components to be turned on and off dynamically, thus enabling the system as a whole to save energy when those components are not being used [1]. Only more recently, techniques have been introduced to enable some components to operate at different energy levels along the time [2]. Multiple operational modes and Dynamic Voltage Scaling (DVS) are examples of such techniques that are becoming commonplace for microprocessors. Unfortunately, microprocessors are seldom the main energy drain in embedded systems—peripherals are—so traditional on/off mechanisms are sill of great interest.
Even concerning microprocessors, which are the cores of the digital systems behind any embedded system, current power management standards, such as APM and ACPI, only define a software/hardware interface for power management, mostly disregarding management strategies and fully ignoring the designer knowledge about how energy is to be used—and therefore how it can be saved—in the system. Moreover, these standards evolved in the context of portable personal computers and usually do not fit in the limited-resource scenario typical of embedded systems. Other initiatives in the scope of embedded operating systems, some of which will be discussed later in this paper, introduce power management mechanisms at the level of hardware abstraction (viz. HAL), demanding programmers to go down to that level in order to manage energy. This compromises several aspects of software quality, portability, and time-to-marketing in particular. Yet, others assume that the operating system is capable of doing power management by itself, defining policies, and implementing automatic mechanisms to enforce them.
We believe that power management in embedded systems could be made far more effective if designers were provided with adequate means to express their knowledge about the power characteristics of the system directly to the power manager. In contrast to general-purpose systems, embedded systems result from a design process that is usually driven by the requirements of a single application. Assuming that the traditional autonomous power management mechanisms found in portable computers will ever be able to match the designers' expertise about such tailor-made systems is unrealistic. Furthermore, power management for portable computers is mostly conceived around the idea of maximizing operating time for a given energy budget. We believe that many embedded systems would prefer to have it modeled to ensure a minimum system lifetime.
In this paper, we introduce a set of mechanisms that enable designers to directly influence, or even control, the power management strategy for the system. These mechanisms have been modeled around typical embedded system requirements, including small footprint, little overhead, and noninterference with real-time constraints. They are
a power management API defined at the level of user-visible system components (e.g., files, sockets, and processes) that supports semantic energy modes (i.e., off, standby, light, and full), arbitrary energy modes (i.e., device specific), and dynamic voltage scaling; a power management infrastructure for system components, with accounting, autosuspend, and autoresume mechanisms, implemented around aspect-oriented programming (AOP) concepts and formalized through Petri Nets; an autonomous power manager, whose policies can be configured, statically or dynamically, and whose decisions take in consideration the interactions between applications and system done through the management API, thus enabling applications to override specific policies.
The reminder of this text discusses the design of these three mechanisms, their implementation in the Epos Project, experiments carried out to corroborate the proposal, and a discussion about related work and is closed with a reasoning about the proposed mechanisms.
2. Power Management API
In order to introduce a discussion about power management application programming interfaces (APIs), let us first recall how energy consumption requirements arise during the design of an energy-aware embedded system and how they are usually captured. In such systems, designers look for available energy-efficient components and, eventually, specify new components to be implemented. During this process, they inherently acquire knowledge about the most adequate operating strategy for each component and for the system as a whole. Whenever the identified strategies are associated to modifications in the energy level of a given component, this can be captured in traditional design diagrams, such as sequence, activity, and timing, or by specific tools [3].
Now let us consider the design of a simple application, conceived specifically to illustrate the translation of energy constraints from design to implementation. This application realizes a kind of remote monitoring system, capable of sensing a given property (e.g., temperature), reporting it to a control center, and reacting by activating an actuator (e.g., external cooler) whenever it exceeds a certain limit. Interaction with the control center is done via a communicator (e.g., radio). The system operates on batteries and must run uninterruptedly for one year. A block diagram of the system is shown in Figure 1.
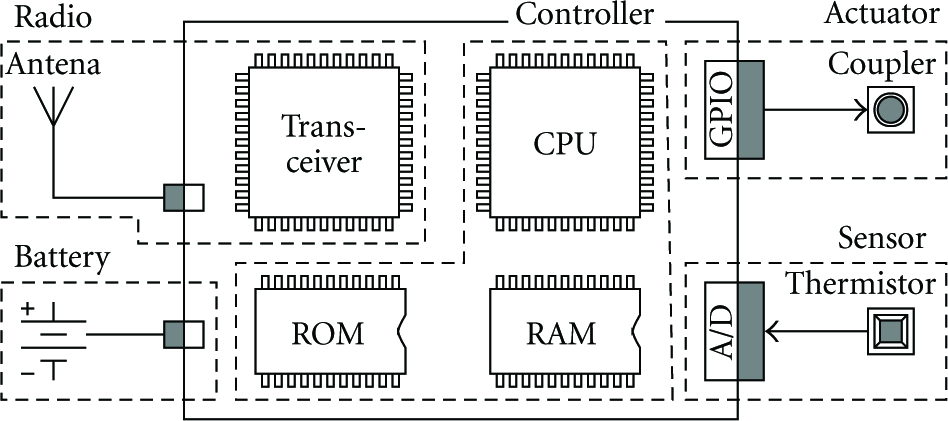
Example monitoring system block diagram.
The application is modeled around four tasks whose behavior is depicted in the sequence diagrams of Figures 2 through 5:

Main thread sequence diagram with power management actions.
In the sequence diagrams of Figures 2 through 5, energy-related actions captured during design are expressed by messages and remarks. For instance, the knowledge that the

Monitor thread sequence diagram with power management actions.
The diagrams also show power management hints for the
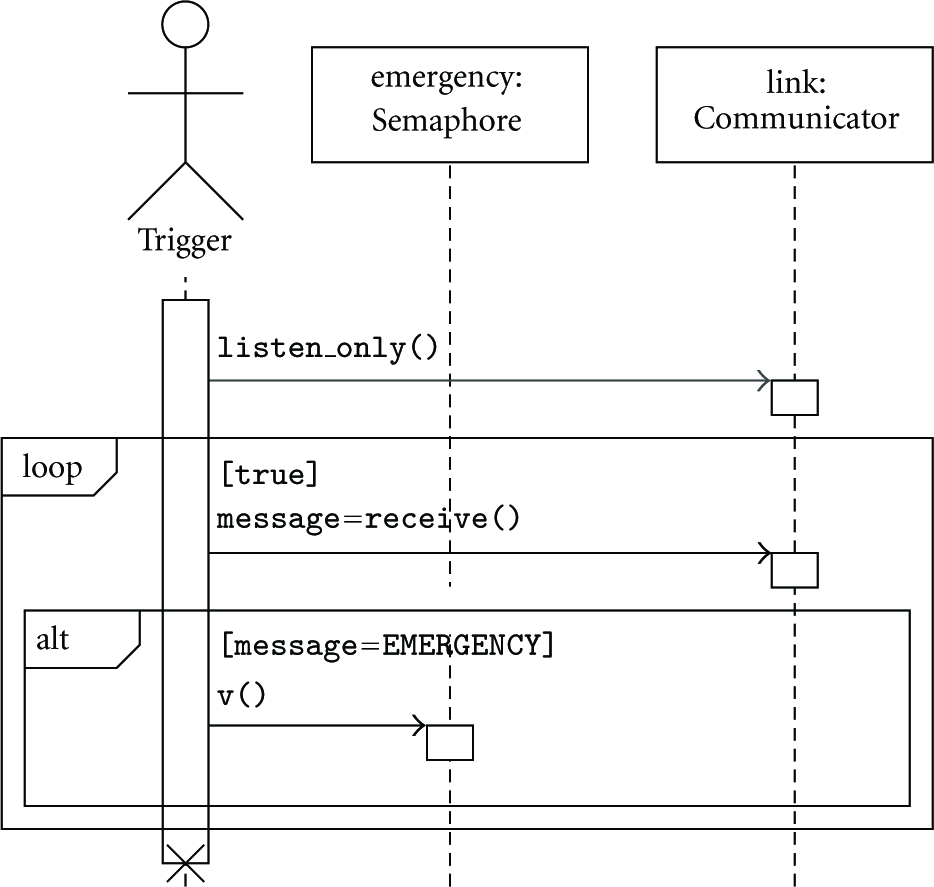
Trigger thread sequence diagram with power management actions.

Recovery thread sequence diagram with power management actions.
Considering the functional properties described so far and the execution period of each thread, it is possible to estimate duty cycles for each of the major components in the example system. This information can then be combined with energy consumption estimates of individual components to calculate the power supply required by the system. This procedure is summarized in Table 1, which shows hypothetical energy consumption estimates, duty cycles and energy consumption for the four major components in the system (Estimates were based on the Mica2 sensor node [5]).
Example monitoring system energy consumption estimates.

In order to match the requirement of operating uninterruptedly for one year, the system would demand a battery capable of delivering approximately 3576 mAh (at 3 V). For comparison, the same system operating with all components constantly active, that is, without any power-saving strategy, would require about 142 Ah, almost 40 times more.
2.1. Current APIs
Few systems targeting embedded computing can claim to deliver a real power management API. Nevertheless, most systems do deliver mechanisms that enable programmers to directly access the interface of some hardware components. These mechanisms, though not specifically designed for power management, can be used for that purpose at the price of binding the application to hardware details.
μCLINUX, like many other UNIX-like systems, does not feature a real power management API. Some device drivers provide power management functions inspired on ACPI. Usually these mechanisms are intended to be used by the kernel itself, though a few device drivers export them via the
The source code in Algorithm 1 is a user-level implementation of the
// Open ADC power attribute on sysfs = sysfs_open_attribute( “/sys/devices/i2c/AD8493/power/state#x201D; ); // Switching to power state 0 (ON) sysfs_write_attribute (adc_power, “0#x201D;, 1); // Read ADC result ad8493_get(adc_device, &value); accumulator += value; } // Switching to power state 3 (OFF) sysfs_write_attribute (adc_power, “3#x201D;, 2); // Convert reading into celcius degrees }
Algorithm 1:
TINYOS, a popular operating system in the wireless sensor network scene, allows programmers to control the operation of hardware components through a low-level, architecture-dependent API. Though not specifically designed for power management purposes, this API ensures direct access to the hardware and thus can be used in this sense. When compared to μCLINUX, TINYOS delivers a lighter mechanism, more adequate for most embedded system, yet suffers from the same limitations in respect to usability and portability. The use of TINYOS hardware control API for power management is illustrated in Algorithm 2, which depicts the implementation of the
// ⋯ // When initializing system event // ⋯ // Put radio in listening mode call RadioControl.start (); // ⋯ } // When data is received event message_t* Receive.receive ( message_t* bufPtr, ) { radio_sense_msg_t* rsm = (radio_sense_msg_t*) payload; // Turn radio off // Someone has to turn it on again later RadioControl.stop(); emergency_semaphore++; } } } // ⋯
Algorithm 2:
MANTIS features a POSIX-inspired API that abstracts hardware devices as Unix special files. Differently of μCLINUX and TINYOS, however, Mantis does not propose that API to be used for power management purposes; internal mechanisms automatically deactivate components that have not been used for a given time or perform an “on-act-off” scheme, thus implementing a sort of OS-driven power manager. This strategy can be very efficient, but it makes it difficult for programmers to express the knowledge about energy consumption acquired during the design process. This is made evident in the implementation of the
// Read from device dev_read (DEV_MICA2_TEMP, &data, 1); accumulator += data; } // MantisOS device driver turns sensor // ON and OFF for every reading
Algorithm 3: Thermometer::sample() method implementation for MANTIS.
Some systems assume that architectural dependencies are intrinsic to the limitations of typical embedded systems; however, this is exactly the share of the computing systems market that could benefit from a large diversity of suppliers [6] and therefore would profit from quickly moving from one architecture to another. This, in addition to the fact that current APIs do not efficiently support the expression of design knowledge during system implementation, led us to propose a new PM API.
2.2. Proposed API
The power management API proposed here arose from the observation that currently available APIs require application programmers to go down to the hardware whenever they want to manage power, inducing unnecessary and undesirable architectural dependencies between application and the hardware platform. In order to overcome these limitations, we believe a PM API for embedded systems should present the following characteristics:
enable direct application control over energy-related issues, yet not excluding delegation or cooperation with an autonomous power manager; act also at the level of user-visible components, instead of being restricted to the level of hardware component interfaces, thus promoting portability and usability; be suitable for both application and system programming, thus unifying power management mechanisms and promoting reuse; include, but not be restricted to, semantic modes, thus enabling programmers to easily express power management operations while avoiding the limitations of a small, fixed number of operating modes (as is the case of ACPI).
With these guidelines in mind, we developed a very simple API, which comprises only two methods, and an extension to the methods responsible for process creation. They are
The first method returns the current power mode of the associated object (i.e., component), while the second allows for mode changes. Aiming at enhancing usability and preserving portability, four power modes have been defined with semantics that must be respected for all components in the system: off, standby, light, and full. Each component is still free to define additional power modes with other semantics, as long as the four basic modes are preserved. Enforcing universal semantics for these power modes enables application programmers to control energy consumption without having to understand the implementation details of underlying components. It also helps to keep higher-level system components platform independent. For example, a semantic power mode change can be issued on a file regardless of where it is stored, since any underlying file system must implement that mode. File systems themselves are kept portable as they do not need to know details about the power management of underlying storage devices. They simply propagate the semantic mode change on the premise that the associated device driver will implement it accordingly. Allowing for additional modes, on the other hand, enables programmers to precisely control the operation of dedicated components, whose operation transcends the predefined modes. For example, a communication transceiver can have its power finely adjusted to reach a desired range.
The introduction of these methods in user-visible components such as files and sockets certainly requires some sort of propagation mechanism and could incur in undesirable dependencies. We describe a strategy to implement them using a combination of aspect-oriented Programming techniques and hierarchical Petri nets later in Section 3. For now, let us concentrate on the characterization of the API, not the mechanisms behind it.
Table 2 summarizes the semantics defined for the four universal operating modes. A component operating in mode full provides all its services with maximum performance, possibly consuming more energy than in any other mode. Contrarily, a component in mode off does not provide any service and also does not consume any energy. Switching a component from off to any other power mode is usually an expensive operation, particularly for components with high initialization and/or stabilization times. The mode standby is an alternative to off; a component in standby is also not able to perform any task, yet bringing it back to full or light is expected to be quicker than from mode off. This is usually accomplished by maintaining the state of the component “alive” and thus implies in some energy consumption. A component that does not support this mode natively must opt between remaining active or saving its state, perhaps with aid from the operating system and going off.
Semantic power modes of the proposed PM API.

Defining the semantics for mode light is not so straightforward. A component in this mode must deliver all its services, but consuming the minimum amount of energy. This definition brings about two important considerations. First, if there is a power mode in which the component is able to deliver all its services with the same quality as if it was in mode full, then this should be mode full instead of light, since it would make no sense to operate in a higher consumption mode without arguable benefits. Hence, mode light is often attained at the cost of performance (e.g., through DVS). This, in turn, brings about a second consideration: for a real-time embedded system, it would be wrong to state that a component is able to deliver “all its services” if the added latency is let to interfere with the time requirements of applications. Therefore, mode light shall not be implicitly propagated to the CPU component. Programmers must explicitly state that they agree to slow down the processor to save energy, or an energy-aware real-time scheduler must be deployed [7].
Besides the four operating modes with predefined, global semantics, a component can export additional modes through the API. These modes are privately defined by the component based on its own peculiarities, thus requiring the client components to be aware of their semantics in order to be deployed. The room for extensions is fundamental for hardware components with many operating modes, allowing for more refined energy management policies. For instance, the listen-only radio mode in our example (see Figure 4) relies on such an extension.
The proposed API also features the concept of a
Figure 6 presents all these interaction modes in a UML communication diagram of a hypothetical system instance. The application may access a global component (
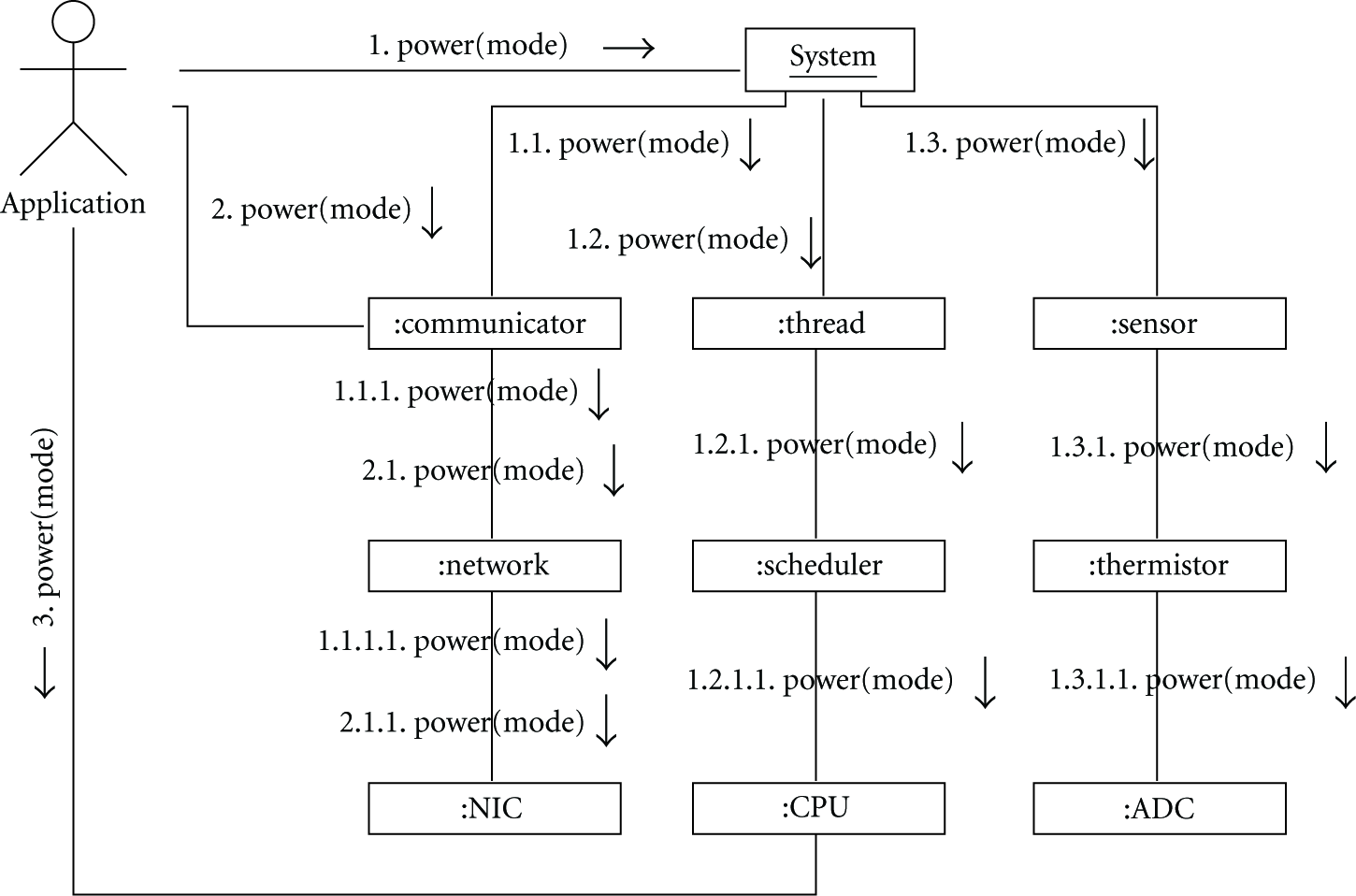
Power management API utilization example.
In a system that realizes the proposed API, the monitoring system introduced earlier could be implemented as show in Algorithm 4, a rather direct transcript of the sequence diagrams of Figure 2 through 5.
Thermometer thermometer; Actuator actuator; Semaphore emergency(0); Communicator link(CONTROL_CENTER); } thermometer.power(OFF); emergency.v(); link.write (temperature); link.power(OFF); } wait_for_next_cycle; } } link.power(LISTEN_ONLY); emergency.v(); } } emergency.p(); thermometer.power(OFF); actuator.shoot(); link.write (temperature); link.power(OFF); delay(STABILIZATION_TIME); temperature = thermometer.get(); thermometer.power(OFF); } } }
Algorithm 4: Example monitoring system implementation using the proposed PM API.
3. Power Management Infrastructure
From the discussion about traditional power management APIs for embedded systems in the previous section, we can infer that the infrastructure behind those APIs is mostly based on features directly exported by hardware components and does not escape from the software/hardware interface. As a matter of fact, the power management infrastructure available in modern hardware components is far more evolved than the software counterpart, which is often restricted to mimic the underlying hardware. For example, XSCALE microprocessors support a wide range of operating frequencies that allow for fine grain DVS. They also feature a power management unit that manages idle, sleep, and a set of quick wake-up modes, and a performance monitoring unit that furnishes a set of event counters that may be configured to monitor occurrence and duration of events.
Power management mechanisms can benefit from such hardware features to implement context-aware power management strategies. Device drivers for the operating systems discussed in the previous section, however, do not make use of most of these features. In order to take advantage of them, application programmers must often implement platform-specific primitives by themselves. This, besides being out of scope for many embedded application developers, will certainly hinder portability and reuse. The same can be observed with peripherals such as wireless network cards, which often provide a large set of configurable characteristics that are not well explored.
In order to support both application-directed and autonomous power management strategies, the infrastructure necessary to implement the proposed API must feature the following services.
(a) Battery Monitoring:
monitoring battery charge at run-time is important to support power management decisions, including generalized operating mode transitions when certain thresholds are reached; some systems are equipped with intelligent batteries that inherently provide this service; others must tackle on techniques such as voltage variation along discharge measured via an ADC to estimate the energy still available to the system [8].
(b) Accounting:
tracking the usage of components is fundamental to any dynamic power management strategy; this can be accomplished by event counters implemented either in software or in hardware; some hardware platforms feature event counters that are usually accessible from software, thus allowing for more precise tracking; in some systems, for which energy consumption measurements have been carried out on a per-component basis, it might even be possible to perform energy accounting based on these counters [9].
(c) Autoresume:
a component that has been set to an energy-saving mode must be brought back to activity before it can deliver any service; in order to relieve programmers from this task, most infrastructures usually implement some sort of “autoresume” mechanism, either by inserting mode verification primitives in the method invocation mechanism of components or by a trap mechanism that automatically calls for operating system intervention whenever an inactive component is accessed.
(d) Autosuspend:
with accounting capabilities in hand, a power management infrastructure can deliver “autosuspend” mechanisms that automatically change the status of components that are not currently being used to energy-saving modes such as standby or off; however, suspending a component and resuming it shortly after will probably spend more energy than letting it to continue in the original mode; therefore, the heuristics used to decide which and when components should be suspended is one of the most important issues in the field and is now subject to intense research [10–14].
Our proposed power management API allows interaction between the application and the system, between system components and hardware devices, and directly between application and hardware. Thus, in order to realize this API, each software and hardware component in our system must be adapted to provide the above-listed services.
3.1. Implementation through Aspect Programs
Aspect-oriented programming (AOP) [15] allows non-functional properties (e.g., identification, synchronization, and sharing control) to be modeled separately from the components they affect. Associated implementation techniques enable the subsequent implementation of such properties as aspect programs that are kept isolated from components, thus preventing a generalized proliferation of manual, error-prone modifications across the system. As a non-functional property, power management fits well into this paradigm.
EPOS [16], our test bed system, supports AOP through a C++ construct called scenario adapter. Scenario adapters enable aspects to be implemented as ordinary C++ programs that are subsequently applied to component code during system compilation, thus eliminating the need for external tools such as aspect weavers. Figure 7 shows the general structure of a scenario adapter. The aspect programs

EPOS scenario adapter.
Following AOP principles, energy accounting can be implemented as an aspect program that adds event counters to components and adapts the corresponding methods to manipulate them as illustrated in Figure 8. When

Energy accounting aspect.

Autoresume aspect.
Autosuspend mechanisms can also take advantage of AOP techniques. Turning off components that are no longer being used could be easily accomplished by an aspect program that maintains usage counters associated to components. An automated suspend policy could then be implemented in the corresponding
One pitfall in using AOP techniques to implement a power management infrastructure arises from the fact that individual software components manipulate distinct hardware components in quite specific ways. Implementing the proposed API, so that power mode transitions can be issued at high-level abstractions such as files and processes, would require the envisioned aspect program to consider a complex set of rules. In this proposal, we tackle this problem by formalizing the interaction between components through a set of hierarchical Petri nets that are automatically transformed in the component-specific rules that are used by our generic aspect programs.
3.2. Operation Mode Transition Networks
Petri nets are a convenient tool to model operating mode transitions of components, not only because of its hierarchical representation capability, but also due to the availability of verification tools that can automatically check the whole system for deadlocks and unreachable states [17]. Figure 10 shows a simplified view of the operating mode transition networks used in this proposal (only the transition from OFF to FULL is shown). The complete network encompasses all valid transitions in a similar way, with places being associated to operating modes (FULL and OFF in the Figure), and resources designating the component's current operating mode.

Generalized operating mode transition network.
The
The generalized network represents operating mode transitions from a high-level perspective, without modeling the specific actions that must be taken to put a component into a given power mode. Those actions are subsequently modeled by specializations of mode transitions (such as
For instance, the communicator in our example propagates a { _radio.power(Radio::FULL); _spi.power(SPI::FULL); _timer.power(Timer::FULL); }
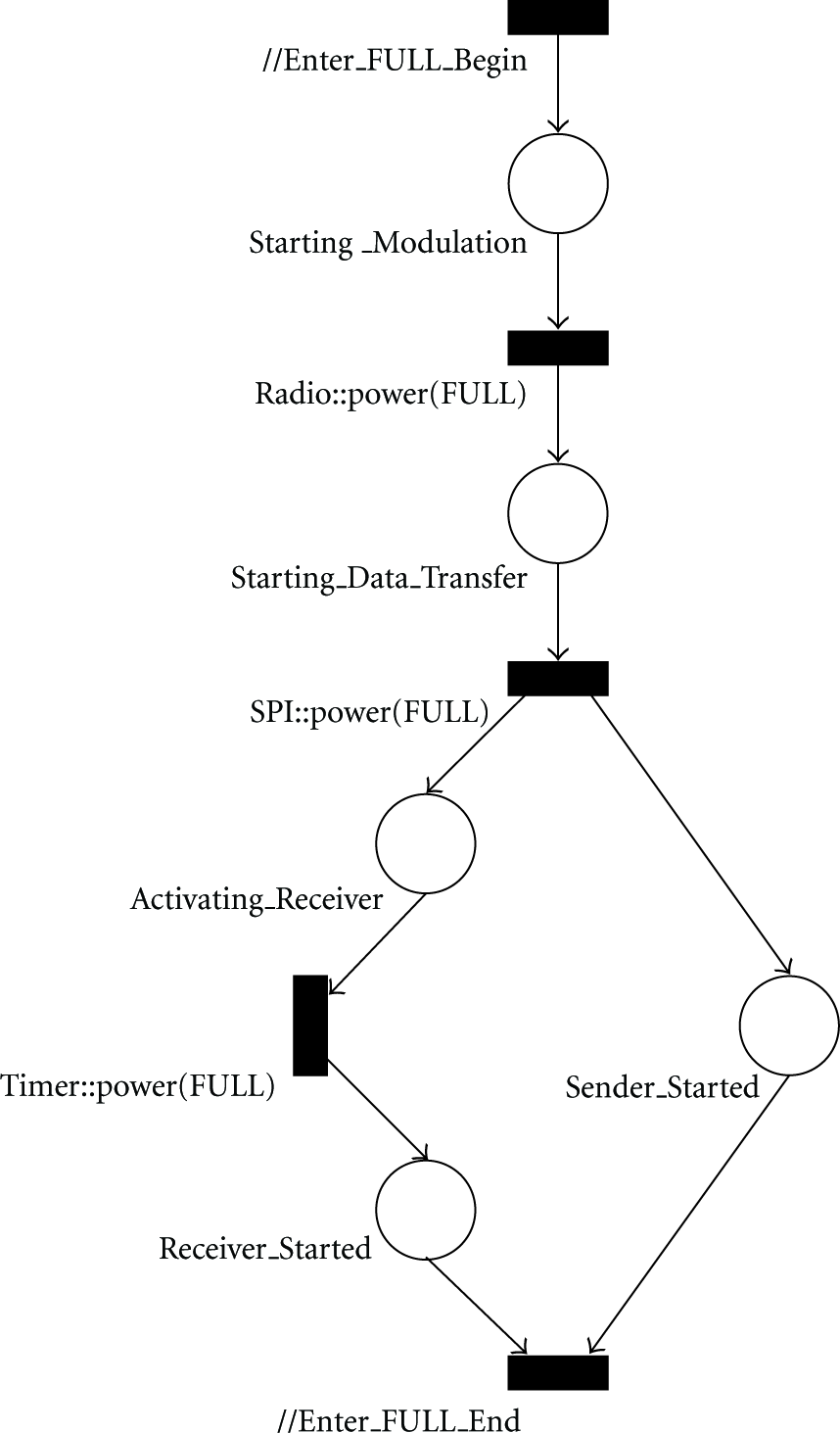
Communicator transition network to enter mode FULL.
Note that each distinct communicator has its own transition network, thus ensuring that an application issuing the power directive does not need to be patched if the radio on the hardware platform changes or even if it is replaced by a wired transceiver. Similar transition networks are used for all modes, including the apparently more complex standby and light modes. The role of transition networks is solely to propagate power management invocations from high-level abstraction down to hardware components in a consistent manner. The implementation of method
Furthermore, invocations of
4. Autonomous Power Manager
A considerable fraction of the research effort around power management at software level has been dedicated to design and implement autonomous power managers for general-purpose operating systems, such as Windows and Unix. Today, battery-operated portable computers, including notebooks, PDAs, and high-end cell phones, can rely on sophisticated management strategies to dynamically control how the available energy budget is spent by distinct application processes. Although not directly applicable to the embedded system realm, those power managers bear concepts that can be promptly reused in this domain.
As a matter of fact, autonomous power managers grab to a periodically activated operating system component (e.g., timer, scheduler, or a specific thread) in order to trigger operation mode changes across components and thus save energy. For instance, a primitive power manager could be implemented by simply modifying the operating system scheduler to put the CPU in standby whenever there are no more tasks to be executed. DVS capabilities of underlying hardware can also be easily exploited by the operating system in order to extend the battery lifetime at the expense of performance, while battery discharge alarms can trigger mode changes for peripheral devices [18, 19]. Nevertheless, these basic guidelines of power management for personal computers must be brought to context before they can be deployed in embedded systems.
Embedded systems are often engineered around hardware platforms with very limited resources, so the power manager must be designed to be as slim as possible, sometimes taking software engineering to its limits. Many embedded systems run real-time tasks; therefore, a power manager for this scenario must be designed in such a way that its own execution does not compromise the deadlines of such tasks. Furthermore, the decisions taken by an autonomous power manager must be in accordance with the requirements of such tasks, since the latency of operating mode changes (e.g., waking up a component) may impact their deadlines. For a real-time embedded system, having a power manager that runs unpredictably might be of consequences similar to the infamous garbage collection issues in JAVA systems [20]. Embedded systems often pay a higher energy bill for peripheral devices than for the CPU. Therefore, CPU-centric strategies, such as DVS-aware scheduling, must be reviewed to include external devices. Therefore, an active power manager must keep track of peripheral device usage and apply some heuristics to change their operating mode along the system lifetime. The decision of which devices will have their operating modes changed and when this will occur is mostly based on event counters maintained by the power management infrastructure, either in hardware or in software. As a matter of fact, critical real-time systems are almost always designed considering energy sources that are compatible with system demands. Power saving decisions, such as voltage scaling and device hibernation, are also made at design time and thus are also taken in consideration while defining the energy budget necessary to sustain the system. At first sight, autonomous power management might even seem out of scope for critical systems. Nonetheless, complex, battery-operated, real-time embedded system, such as satellites, autonomous vehicles, and even sensor networks, are often modeled around a set of tasks that include both critical and noncritical tasks. A power manager for one such embedded system must respect design-time decisions for critical parts while trying to optimize energy consumption by noncritical parts.
With these premises in mind, the next section briefly surveys the current scenario for power management in embedded systems.
4.1. Current Power Managers
Just like APIs and infrastructures, most of the currently available embedded system power managers focus on features exported by the underlying hardware. μCLINUX captures APM, ACPI or equivalent events to conduct mode transitions for the CPU and also for devices whose drivers explicitly registered to the power manager [21].
In TINYOS, OS-driven power management is implemented by the task scheduler, which makes use of the
MANTIS uses an idle thread as entry point for the system's power management policies, which put the processor in sleep mode whenever there are no threads waiting to be executed [23].
GRACE-OS is an energy-efficient operating system for mobile multimedia applications implemented on top of LINUX [24]. The system combines real-time scheduling and DVS techniques to dynamically control energy consumption. The scheduler configures the CPU speed for each task based on a probabilistic estimation of how many cycles they will need to complete their computations. Since the system is targeted at soft real-time multimedia applications, loosing deadlines due to estimation errors is tolerated. GRUB-PA follows the same guidelines but addresses hard real-time requirements more consistently by imposing DVS configuration restrictions for this kind of task [25].
Niu and Quan also propose a strategy to minimize energy consumption in soft real-time systems through adjusting in the system QoS level [26]. In this proposal, tasks specify CPU QoS requirements through (
Yet in the line of energy savings through adaptive scheduling and QoS, Odyssey takes the concept of soft real time to the limit. The system periodically monitors energy consumption by applications in order to adjust the level of QoS. Whenever energy consumption is too high, the system decreases QoS by selecting lower performance and power consumption modes. In this way, system designers are able to specify a minimum lifetime for the system, which might be achieved by severely degrading performance [27].
ECOS defines a currency, called currency, that applications use to to pay for system resources [28]. The system distributes currencies to tasks periodically accordingly to an equation that tracks the battery discharge rate as to ensure a minimum lifetime for the system. Applications are thus forced to adapt their execution pace according to their currency balances. This strategy has one major advantage over others discussed so far in this paper; the currency concept encompasses not only the energy spent by the CPU (to adjust DVS configuration), but also the energy spent by the system as a whole, including all peripheral devices.
Harada explores the trade-off between QoS maximization and energy consumption minimization by allocating processor cycles, and defining operating frequencies with QoS guarantees for two classes of tasks: real time (mandatory) and best effort (optional) [29]. The division of tasks in two parts, one is mandatory, that must always be executed, and the other is optional, that is only executed after ensuring that there are enough resources to execute the mandatory parts of all tasks, is the basic premise behind imprecise computation [30], which is also one of the foundations of the power manager proposed in this work.
4.2. Proposed Power Manager
From the above discussion about currently available power managers for embedded system, one can conclude that no single manager consistently addresses all the points identified earlier in this section: leanness, real-time conformance, peripheral device control, and design-time decision awareness. We follow these premises and build on the API proposed in Section 2 and on the infrastructure presented in Section 3 to propose an effective autonomous power manager for real-time embedded systems.
For the envisioned scenarios of battery-operated, real-time, embedded systems, energy budgets would be defined at design time based on critical tasks, while noncritical tasks would be executed on a best-effort policy, considering not only the availability of time, but also of energy. Along with the assumption that an autonomous power manager cannot interfere with the execution of hard real-time tasks (i.e., cannot compromise their deadlines), the separation of critical and noncritical tasks at design time leads us to the following scheduling strategy.
Hard real-time tasks are handled by the system as mandatory tasks, executed independently of the energy available at the moment. These tasks are scheduled according to traditional algorithms such as earliest deadline first (EDF) and rate monotonic (RM) [31], either in their original shape or extended to support DVS. Best-effort tasks, periodic or not, are assigned lower priorities than hard real-time ones and thus are only executed if no hard real-time tasks are ready to run. Furthermore, the decision to dispatch a best-effort task must also take into consideration whether the remaining energy will be enough to schedule all hard real-time tasks. Whenever a best-effort task is prevented from executing due to energy limitations, a speculative power manager is activated in order to try to change components, including peripheral devices, to less energy-demanding operating modes, thus promoting energy savings.
With this strategy, the autonomous power manager will only be executed if an excessive consumption of energy is detected (i.e., a best-effort task has been denied execution) and time is available (i.e., a best-effort task would be executed). Noninterference between power manager and hard real-time tasks is ensured, in terms of scheduling, by having the power manager to run in preemptive mode, so that a hard real-time task would interrupt its execution as soon as it gets ready to run (e.g., after waiting for the next cycle).
This scheduling strategy has only small implications in terms of process management at the operating system level but requires a comprehensive power management infrastructure, like the one presented in Section 3, in order to be implemented. In particular, battery monitoring services are needed to support the scheduling decisions around best-effort tasks, and component dependency maps are needed to avoid power management decisions that could impact the execution of hard real-time tasks.
The battery monitoring service provided by the PM infrastructure can be combined with the energy accounting service to reduce the costs of gauging the amount of energy still available to the system. With updated statistics from the energy accounting infrastructure in hand, the scheduler can predict battery discharge without having to physically interact with it, thus sparing the corresponding energy. In this way, battery monitoring is programmed to take place sporadically based on the lifetime specified for the system. An additional trigger is bound to the prediction counter kept by the scheduler, so monitoring also takes place when power consumption reaches specified thresholds.
The operating mode transition networks introduced in Section 3 as means to control the propagation of power management actions from high-level components down to the hardware can be used by the autonomous power manager to keep track of dependencies among components. Along with a list of currently active components maintained by the operating system, these transition networks build the basis on which peripheral control can be done by the power manager. For instance, if a task has an open file that is no longer being used, the power manager could track that component down to a flash memory and change its operating mode to standby or off.
Nevertheless, the compromise with real-time systems requires our power manager to take API calls made by hard real-time tasks as “orders” instead of “hints.” We assume that, if a hard real-time task calls the
5. Implementation in EPOS: A Case Study
In order to validate the power management strategy for embedded systems proposed in this paper, which includes an API specification, guidelines for power management infrastructure implementation through aspect programs, and design constraints for the development of autonomous power management agents, these mechanisms have been implemented in Epos along with the hypothetical remote monitoring application described in Section 2. Additionally, three other applications enrich the deployment scenario for the proposed mechanisms.
5.1. EPOS Overview
EPOS, the embedded parallel operating system, aims at building tailor-made execution platforms for specific applications [32]. It follows the principles of application-driven embedded system design [16] to engineer families of software and hardware components that can be automatically selected, configured, adapted, and arranged in a component framework according with the requirements of particular applications.
An application written based on EPOS's published interfaces can be submitted to a tool that performs source code analysis to identify which components are needed to support the application and how these components are being deployed, thus building an execution scenario for the application. Alternatively, users can specify execution scenarios by hand or also review an automatically generated one. A build-up database, with component descriptions, dependencies, and composition rules, is subsequently accessed by the tool to proceed component selection and configuration, as well as software/hardware partitioning based on the availability of chosen components in each domain. If multiple components match the selection criteria, then a cost model is used, along with user specifications for nonfunctional properties, such as performance and energy consumption, to choose one of them (Design-space exploration is currently being pursued in EPOS by making the cost model used by the building tool dynamic).
After being chosen and configured, software components can still undergo application-specific adaptations while being plugged into a statically metaprogrammed framework that is subsequently compiled to yield a run-time support system. This application-specific system can assume several shapes, from simple libraries to operating system microkernels. On the hardware side, component selection and configuration yields an architecture description that can be either realized by discrete components (e.g., microcontrollers) or submitted to external tools for IP synthesis. An overview of the whole process can be seen in Figure 12.
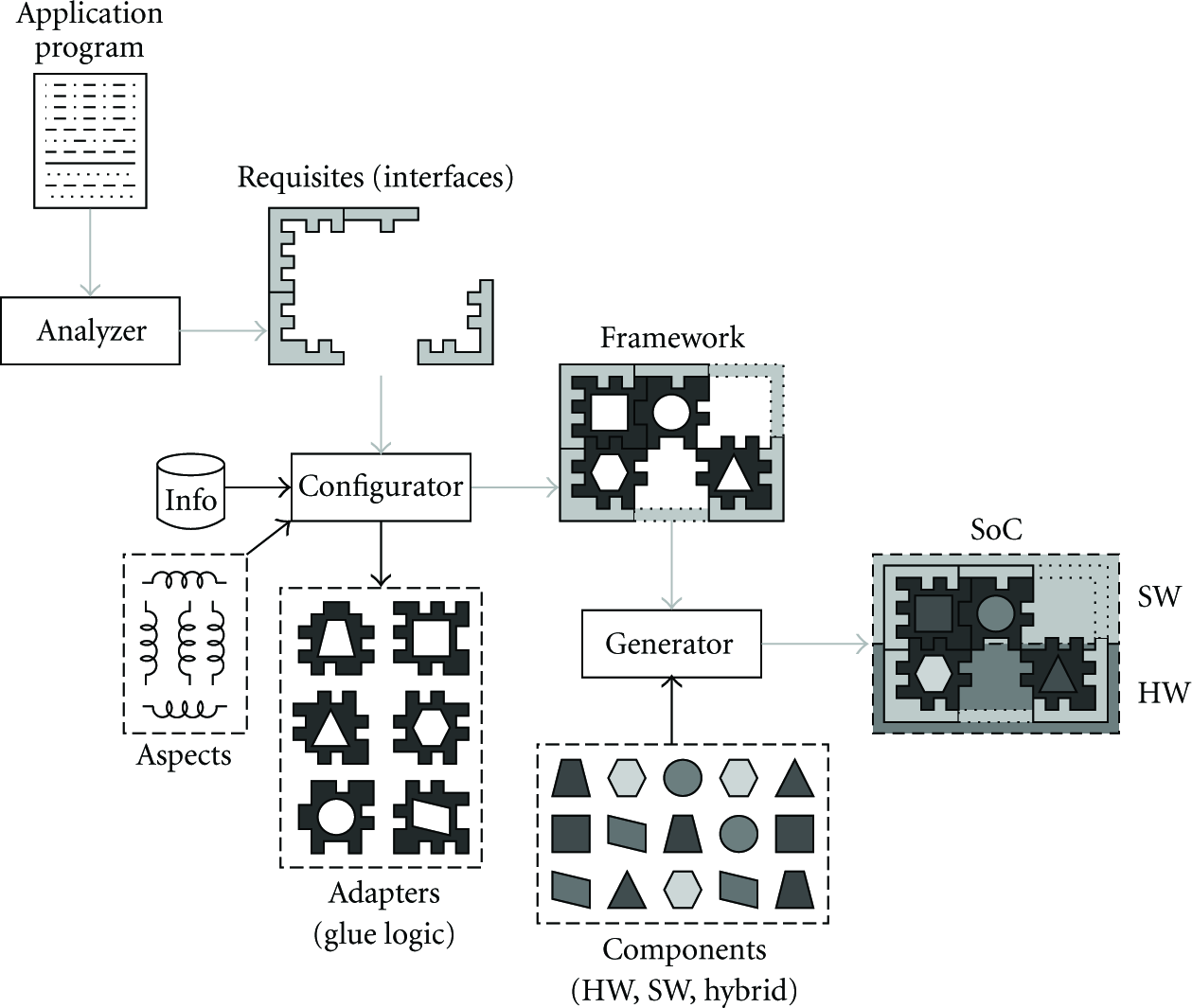
Overview of tools involved in EPOS automatic generation.
5.2. Example Monitoring Application
The remote sensing application described in Section 2 was implemented in EPOS as excerpted in Algorithm 4. When submitted to EPOS tools, the remote sensing program yielded a run-time library specification based on the required interfaces and a hardware description that could be matched by virtually any hardware platform in the system build-up database. We then forced the selection of a well-known platform, the Mica2 sensor node [5], by manually binding
In the experiment, energy for the system was delivered by two high-performance alkaline AA batteries with a total capacity of 58320 J (5400 mAh at 3 V), in excess of Table 1 estimates of what would be necessary to match the intended lifetime of one year (3576 mAh at 3 V). The system was configured with a scheduling quantum of 15 ms and a battery monitoring period of one day. Energy accounting was enabled and produced statistics that were used by the scheduler on every thread dispatching.
The experiment was profiled during approximately one week using a digital oscilloscope. From the collected data, we determined the average energy consumption per hour to be of 5.07 J. We then extrapolated the total energy consumption for one year to be of 4112 mAh. This extrapolation projects a system lifetime of 479 days, confirming that the system will match the expectations in this respect. This experiment also shows that the energy overhead caused by the implemented power management mechanisms is largely compensated by the power it saves (as calculated in Section 2, running the example application without any power management would demand 40 times more energy than the predicted 3576 mAh). It is also important to notice that the additional 536 mAh cannot be entirely accounted to power management. A fraction of it arises from the additional circuitry needed to couple the key components considered at design-time, another fraction from the nonlinear discharge nature of the chosen batteries, and yet another can be accounted to misleading estimates published by manufacturers.
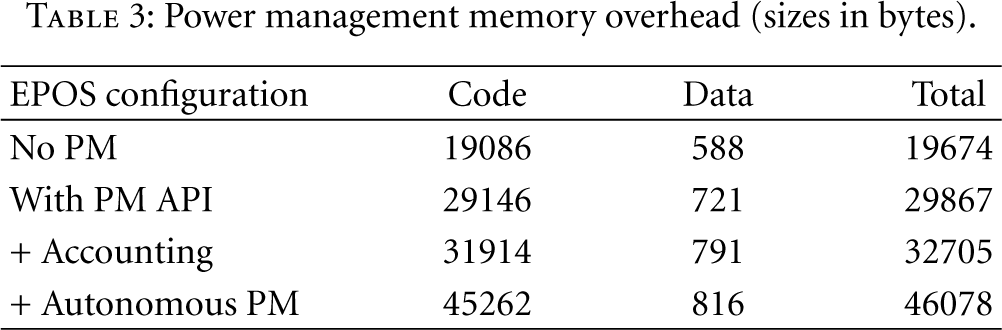
This experiment also allowed us to assess the strategy overhead in terms of memory and CPU utilization. Table 3 shows the memory increase caused by the proposed mechanisms. The reference system was stripped of any PM capabilities and then enriched with the PM API, power accounting, and finally the autonomous manager integrated into the scheduler. The considerable increase in size for every step is justified by the fact that they affect all components in the system. The PM API required versions of mediators that are able to control the power mode of associated devices plus a global
Power management memory overhead (sizes in bytes).
In respect to performance, the proposed mechanisms only substantially affect hardware mediators and the scheduler. Other system components, although adorned with
Power management performance overhead (times in μs).

5.3. Example Monitoring Application with Best-Effort Tasks
The example application discussed along this paper has been conceived to support the explanation of the proposed power management strategy. Its implementation described in the previous Section also allowed us to confirm most of the claimed benefits. Nonetheless, it does not feature a best-effort task that could corroborate the proposed autonomous power manager design. Therefore, we extended it with two additional best-effort threads on a second experiment: thread
Just like the example application, this second experiment was profiled during approximately one week using a digital oscilloscope and a new battery set. The results of the experiment are summarized in Table 5, which presents the system average energy consumption for five different setups: (a) executing without the additional threads; (b) executing the
Energy consumption under different autonomous power manager setups (RT = hard real time/BE = best effort).
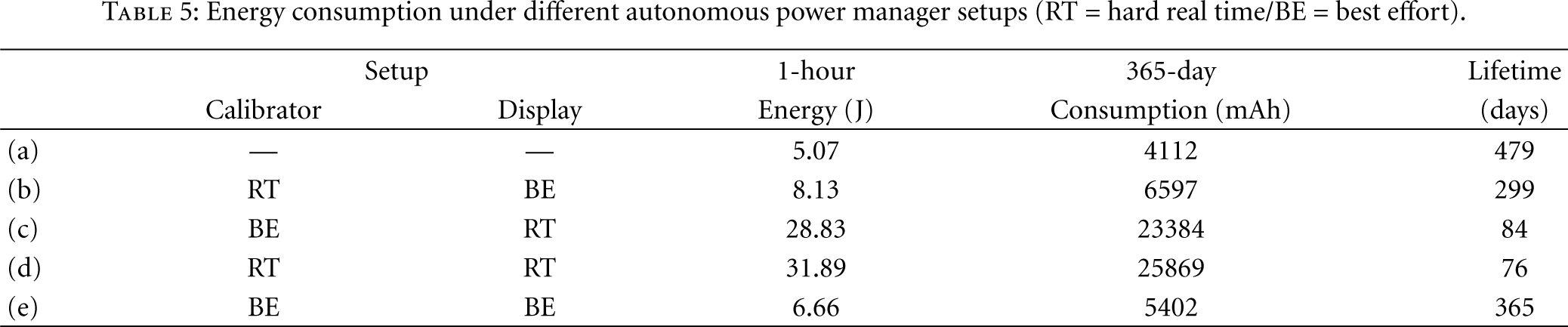
Setup (a) is equivalent to the example application evaluated in the previous section and produced equivalent results. Setup (b) is impacted by the periodic ADC operations performed by
For setup (d), both threads have been configured as hard real time, so they are always executed. This reduces the system's lifetime to about 76 days. Setup (e) is the one that best characterizes the proposed autonomous power manager. Running the additional threads in best-effort priority enables the scheduler to suppress their execution whenever the energy budget needed to achieve the specified lifetime is threatened. This smoothly drives the system toward the desired lifetime, enabling both threads to run just sporadically when the battery monitor indicates that there is enough energy.
5.4. C-MAC
C-MAC is EPOS highly Configurable Medium Access Control Protocol. It was conceived as an architecture of medium access control strategies that can be combined to produce application-specific protocols. By selecting the proper strategies and configuring their parameters, programmers can instantiate MAC protocols that closely match their applications' requirements. C-MAC relies on static metaprogramming techniques to achieve high configurability without compromising size and performance. A first implementation of C-MAC for the Mica2 mote yielded B-MAC-like instances that are smaller, faster and make better use of the network than the original TINYOS B-MAC [33]. A recent redesign of C-MAC for the EPOSMote [34], which features an IEEE 802.15.4 compliant radio, included additional configuration points such as beacon-based synchronization, contention, and error detection. This version has been implemented following the guidelines proposed here and using the same power management mechanisms.
In order to evaluate C-MAC's energetic efficiency, an experiment with five motes was executed. A central mote played the role of a coordinator while the remaining four played the role of working nodes that periodically transmit sensed data to the coordinator (the topology is illustrated by Figure 13). Two C-MAC configurations were considered: (a) with pure CSMA-CA and (b) with a best-effort thread implementing IEEE 802.15.4 beacon-based synchronization. The motes were powered by 3 V manganese dioxide lithium CR2 batteries with a total capacity of 9180 J (850 mAh at 3 V). Figure 14 shows the results. Note that the best-effort task has a very positive impact on the available energy budget, since it eliminates idle listening by synchronizing the nodes. After each communication cycle, it invokes

Topology used in the C-MAC experiment.

Energy consumed per byte received at the coordinator mote.
5.5. AD-ZRP
The Ant-based Dynamic Zone Routing Protocol (AD-ZRP) is Epos's answer to mobility in wireless sensor networks. It is a self-configuring, reactive routing protocol inspired by the HOPNET protocol for mobile ad hoc networks (MANETs) [35] and designed with the typical limitations of sensor nodes in mind, energy in particular. As a Zone Routing Protocol, AD-ZRP defines a zone around each node that comprises its neighboring nodes up to a giving number of hops. The protocol's proactive component keeps the routes within the zone updated by packing routing information on ordinary sensing data packet exchanged among nodes. AD-ZRP's reactive component relies on an ant colony optimization algorithm to discover and maintain interzone routes, eventually also adapting the size of zones. Ants are sent out of a zone to track routes, leaving a trail of pheromone on their way back. Routes with a higher pheromone deposit are preferred for interzone data exchange.
Aiming at corroborating the concepts and mechanisms proposed in this paper, AD-ZRP has been modified to be energyaware. The main idea was to achieve a homogeneous battery discharge across the network, thus improving the life time of the network as a whole. The routing information exchanged among nodes now includes the battery status kept by the monitoring service on participating nodes; pheromone evaporation rate on each node is adjusted according to its energy budget; ants are implemented as best-effort tasks. In this way, both intra and inter-zone routes are chosen on a compromise between distance (i.e., number of hops) and energy consumption: if a shorter route would traverse nodes that have reported lower power levels, it might happen that a longer route gets chosen. The overhead caused on the routing protocol by this scheme is minimal, since the monitoring service on each node implicitly updates its estimates as hardware mediators are accessed. Effective battery gouging is only performed sporadically, so checking for the current energy budget simply means reading a variable. Timed events used to decrement routes' pheromone counters now take the node's available energy into account, eventually decrementing the counter by more than 1. The cancellation of best-effort tasks implementing ants prevents the deposition of pheromone on routes crossing nodes that are running short of power, eventually inducing the discovery of alternative routes.
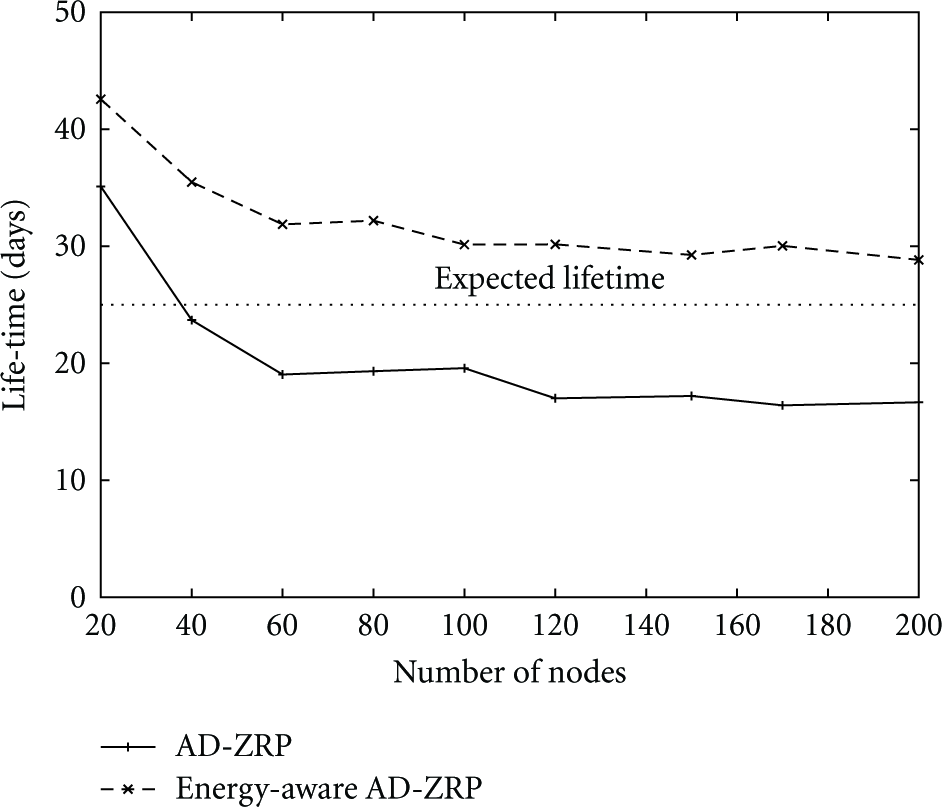
The energy-aware AD-ZRP was evaluated using the global mobile information system simulator (GLOMOSIM). Nodes were programmed to communicate intensively and move randomly within a simulated grid of 700 × 400 m for 25 days, thus stimulating both the routing protocol and the power management mechanisms. Average per-node energy consumption was obtained for both versions of AD-ZRP as shown in Figure 15. Note that the original AD-ZRP version would have exceeded EPOSMote's battery capacity of 9180 J in a real (i.e., nonsimulated) environment. This was confirmed by a second simulation, which is shown in Figure 16. In this setup, Epos autonomous power manager was configured to attain a 25-day lifetime for each node individually and thus for the network as a whole. The main source of energy savings in this experiment was the prevention of inter-zone route discovering ants from moving through low-battery nodes and the accelerated pheromone evaporation on those nodes.

Average energy consumption per node for the whole simulation.
Average node lifetime with EPOS configured to reach 25 days.
6. Conclusion
In this paper, power management in embedded systems was addressed from energy-aware design to energy-efficient implementation, aiming at introducing a set of mechanisms specifically conceived for this scenario. A power management API defined at the level of user-visible system components was proposed and compared with traditional APIs. Its implementation was discussed in the context of the necessary infrastructure, including battery monitoring, accounting, autosuspend, and autoresume. An energy-event propagation mechanism based on Petri nets was proposed and its implementation using aspect-oriented programming techniques was depicted. The use of the proposed infrastructure by an autonomous power manager integrated into a real-time scheduler was also discussed, thus covering the main components of a modern power management system for embedded systems.
The proposed strategy was first illustrated and evaluated through a didactic, yet realistic, example system targeted at environment temperature monitoring. The example was described from early design stages down to a real implementation for the EPOS system on the Mica2 Mote, a well-known platform that helps to put the proposal into perspective. Experiments with this implementation showed that integrating the proposed power management mechanisms into a hard-real time run-time support system comes at a high cost in terms of program memory, especially in platforms with limited hardware support. Nonetheless, they also showed a relatively small impact on performance, slightly adding to the latency of scheduling and I/O operations. This can be explained mainly by the sporadic nature of power management operations.
The strategy was subsequently validated using two additional wireless sensor network cases around Epos: C-MAC (a configurable medium access control protocol) and AD-ZRP (an ant-based dynamic zone routing protocol). For both cases, the radio was the most critical component in respect to power consumption. The strategy proposed in this paper was applied to both preexisting protocols in order to make them energy aware. The API was used to control the radio during inactive and low-power listening cycles from the high-level abstractions used by the application program (e.g.,
The experiments carried out also made evident the benefits of the proposed mechanisms in terms of energy efficiency and system utility as they confirmed the strategy's ability to sustain a given lifetime for the system without affecting the deadlines of hard real-time tasks at the same time it enables the safe usage of the remaining energy by best-effort tasks. These benefits arise from proposed strategy itself and are not dependent on Epos or the motes used. Therefore, the intended contribution for this paper is not “yet another power manager for embedded systems,” but the introduction of a broader and systematic way to deal with power management issues in embedded systems.
Footnotes
Acknowledgments
The authors would like to thank and acknowledge former LISHA members Arliones S. Hoeller Jr, Geovani R. Wiedenhoft, Giovani Gracioli, and Lucas Wanner for implementing many of the concepts and ideas presented in this paper.