
Abstract
In hierarchical two-tiered sensor networks, higher-powered relay nodes can be used as cluster heads for designing scalable sensor networks. It has been shown that, in such networks, the assignment of sensor nodes to clusters plays an important role in determining the lifetime of the network. In this paper, we have proposed two routing-aware, distributed algorithms for assigning sensor nodes to clusters in two-tiered networks. The first heuristic assumes that all relay nodes, acting as cluster heads, send their data directly to the base station. The second heuristic relaxes this assumption and is to be used with any network where each relay node uses a multihop route to send its data to the base station. Unlike conventional clustering algorithms, our approaches take into consideration the routing scheme used by the relay nodes, and attempt to balance the energy dissipation of the nodes. We have compared the results of our distributed approaches with the optimal solutions obtained using an integer linear program (ILP) formulation, as well as existing techniques, based on heuristics. The results indicate that our approaches, on average, can produce results that are close to the optimal solutions and consistently outperform existing heuristics.
1. Introduction
Sensor nodes are tiny, low-powered, and multifunctional devices operated by lightweight batteries. A network of sensor nodes performs tasks through the collaborative efforts of a large number (hundreds or even thousands) of sensor nodes that are densely deployed within the sensing area [1]. Data from each sensor node are gathered at a central entity, often called the base station [1, 2]. Replacing or recharging the batteries of sensor nodes is usually not feasible, so that a sensor network becomes nonfunctional when the batteries in a “sufficient” number of nodes are depleted. The lifetime of a sensor network is a measure of the duration, from the time the network is deployed, to the time it becomes nonfunctional. The limited transmission range and the battery power of sensor nodes affect the scalability and the lifetime of sensor networks. As a consequence, energy conservation in a sensor network to maximize its lifetime is a major research topic.
Recently, some special nodes, known as relay nodes (also called gateway nodes [3] and application nodes [4]), have been used to design sensor networks with increased lifetime. The sensor nodes in such a network are organized in clusters. Each cluster is assigned a relay node acting as its cluster head, defining a two-tier hierarchical sensor network [4, 5], with the sensor (relay) nodes defining the lower (higher) tier. The sensor nodes belonging to a cluster in a two-tier network send their data directly to the relay node acting as the cluster-head for that cluster. Each relay node collects the data it receives from its own cluster and transmits that data, either directly to the base station using the single-hop data transmission model (SHDTM), or forwards the data towards the base station using a multi-hop path, using the multi-hop data transmission model (MHDTM). In the case of multihop routing, in addition to the data gathered from its own cluster, each relay node also relays any data it receives from its neighboring relay nodes.
We have assumed the periodic [6] model for data reporting/gathering, so that data are collected and forwarded to the base station periodically, following a predefined schedule. Each period of data gathering is referred to as a round [7, 8]. In each round of data gathering, each relay node gathers the data it receives from its own cluster and transmits that data, either directly to the base station (i.e., using SHDTM), or forwards the data towards the base station using a multihop path (i.e., using MHDTM).
Each relay node is typically provisioned with higher energy, compared to the sensor nodes but, just like sensor nodes, are also battery operated, so that both relay nodes and sensor nodes are power constrained. It is possible that some relay nodes dissipate energy at higher rates, due to more load and/or longer transmission distances, compared to other relay nodes. This uneven energy dissipation among the relay nodes may lead to the faster “death” of some relay nodes in the network (i.e., the power supplies of these relay nodes are depleted to such an extent that the nodes are no longer functional), assuming that the initial energy provisioning for all relay nodes is equal. This may affect the functionality of the sensor networks, as the inoperative relay node(s) will not be able to perform their assigned functions. This may even cause the network to lose its usefulness, even though many other relay nodes in the network still retain power. Further, if MHDTM is used and the multihop routing strategy is not changed when a relay node becomes faulty, all data received by the failed relay node is “lost”, since the data is not forwarded to the base station. The loss of power of a relay node can, therefore, impact the functionality of the network much more severely than the depletion of the battery of a single sensor node.
In hierarchical networks, the lifetime is determined by the time interval from the deployment of the network to the time a critical number of relay nodes die. Researchers have proposed different ways to define these critical relay nodes, depending on their design objectives [4, 9–12]. In this paper we have measured the lifetime of a network, following the N-of-N [4] metric, by the number of rounds the network operates from the start, until the first relay node depletes its energy completely and ceases to function. We note that other metrics can be used as well, with straight-forward modifications to the algorithms.
The allocation of the sensor nodes to clusters in a hierarchical network is decided by the clustering scheme used. A proper clustering scheme can play an important role in balancing the load on different relay nodes [13] and, hence, significantly improving the lifetime of the network.
It has been shown that a proper clustering scheme can significantly affect the lifetime of the relay node network by balancing the load on different relay nodes [14]. The effectiveness of a clustering scheme depends on a number of factors such as the distribution of the sensor nodes, the number, and the locations of the relay nodes and the specific routing strategy used.
In this paper, we have proposed two distributed algorithms for load-balanced clustering to maximize the lifetime of a two-tier network. The first (second) algorithm is applicable for networks using the SHDTM (MHDTM). Some authors have characterized this type of algorithms as localized algorithm [15]—a specialized class of distributed algorithms. Both approaches assume that the relay node routing scheme for a given network is known beforehand, that is, our proposed approaches are “routing-aware.” Our objective, following [3, 16], is to form appropriate clusters of sensor nodes with the relay nodes acting as cluster heads. We take into account the cardinality of each cluster, the routing scheme, and the energy dissipation for transmitting/receiving data. We have directly maximized the network lifetime, rather than optimize a secondary objective such as the variance in the cardinalities. This makes our algorithms much more effective, compared to existing load-balanced clustering techniques. We have used a top-down approach, where we started with an initial clustering scheme. In successive iterations, our scheme gives an improved clustering scheme, until the algorithm terminates. A preliminary version of this work was presented in [17].
The main features of each of our algorithms are as follows.
It operates on local information only and can quickly generate efficient solutions for networks with hundreds of sensor nodes, with little communication overhead. It produces a valid clustering in each iteration. Therefore, convergence is not a problem, since the algorithm can always be terminated after a specified number of iterations. In each iteration, it is guaranteed that the overall network lifetime will never decrease, compared to the lifetime obtained in the previous iteration. Our algorithm consistently outperforms existing clustering heuristics available in the literature [14, 16]. The solutions obtained using our algorithm are comparable to optimal solutions generated using a centralized integer-linear-program- (ILP-) based approach [16].
The remainder of the paper is organized as follows. In Section 2, we briefly review some relevant background material. In Section 3, we present our algorithms. We discuss and analyze the experimental results in Section 4 and conclude with a critical summary in Section 5.
2. Review
Clustering of nodes in a sensor network is a well-researched field [2, 3, 16, 18–20]. The problem of clustering is illustrated in Figure 1, where the sensor nodes in the shaded region can be assigned to any of the clusters with A, B, or C as their cluster heads. Depending on the routing scheme and the energy dissipation of relay nodes A, B, and C, one assignment may be more advantageous than the others. The goal of a clustering algorithm is to assign each sensor node to an appropriate cluster in a way that extends the lifetime of the network.

Sensor nodes in overlapping coverage area.
In [3], G. Gupta and M. Younis investigated the problem of forming clusters around a few high-energy gateway nodes. The authors defined “cardinality” of a cluster as the number of sensor nodes associated with the cluster and provided a heuristic that attempts to minimize the variance of the cardinality of each cluster in the system. The idea was to distribute the sensor nodes as evenly as possible, over all the clusters. They have shown [14] that suitable clustering techniques can be used to increase the system lifetime. The clustering problem has also been addressed in [16], where an optimal solution is obtained using a centralized approach employing ILP.
Clustering techniques proposed in the literature [3] typically use simple heuristics to balance the amount of data that each relay node is required to forward towards the base station. However, this clustering approach, which measures the “load” on a relay node in terms of the cardinality of each cluster, defined as the number of sensor nodes associated with the cluster, fails to take into account the specific routing strategy used. For example, in the SHDTM model, where each relay node transmits directly to the base station, it may be more effective to assign fewer sensor nodes to clusters which are further away from the base station, rather than to distribute the sensor nodes equally among the different clusters. Existing heuristics cannot guarantee optimality in terms of directly extending the lifetime of the network, which is the primary objective of load-balanced clustering. Centralized approaches, based on integer linear program (ILP) formulations, that guarantee optimality (in terms of maximum possible lifetime), have been proposed [16]. Since autonomous systems are not under the control of a single, centralized agent, an ILP-based formulation is not appropriate.
In a hierarchical sensor network, if the N-of-N metric is used [4], assuming equal initial energy provisioning in each relay node, the lifetime of the network is defined by the ratio of the initial energy to the maximum energy dissipated by any relay node in a round, so that
The transmission power dissipated by a sender node to transmit each bit of data to a receiver node increases rapidly with the increase of the distance between the sender and the receiver [1–3]. We have assumed that the energy dissipation for communication is based on the first-order radio model [2], where the energy required to transmit (receive) b bits, at a distance d, is given by
We assume that all nodes are stationary after deployment and that the relay nodes are aware of the location of the base station. In the case of multihop routing, we assume that the routing scheme has been determined beforehand, so that each relay node knows the predecessor nodes (if they exist) and the successor node. We have assumed periodic data gathering, where each sensor node measures certain physical attribute(s) from the environment (e.g., temperature, pressure, humidity, pollution level) at predetermined intervals, and communicates data periodically [6]. Therefore, the average amount of data to be communicated by each sensor node in a round is known. We further assume that the placement strategy applied during the deployment phase of the network ensures that each sensor node is able to send its data to at least one relay node.
3. Distributed Algorithms for Load Balanced Clustering
In this section, we present two heuristics for distributed-load balanced clustering. The first heuristic assumes that each relay node sends its data directly to the base station using SHDTM. In the second heuristic, the relay nodes form a network, and, in general, each relay node uses MHDTM to send its data to the base station. Both heuristics use a top-down approach, where the relay nodes first form an initial feasible clustering. At each successive iteration, some sensor nodes are reassigned, from their respective clusters to other clusters so that
each iteration results in a valid set of clusters, and the lifetime of the network never decreases as a result of any reassignment.
3.1. Network Model
In a distributed environment, identifying the node dissipating the maximum energy is a time-consuming task. To reduce the energy needed, as well as the set-up time required when the clusters are being formed, each relay node takes decisions about clustering, after taking into account only the situation in the “neighboring” relay nodes. Our experiments, discussed later, show that such decisions, based on local information only, still give excellent results.
For convenience, we assign each node (sensor or relay node) a unique ID number. In our model,
3.2. Definitions and Notations
In our distributed algorithms, we will use the following definitions and notations.
A sensor node s is covered by a relay node j, if and only if s can communicate directly with j, that is, j is within the transmission range of s. A sensor node The transmission range of a sensor node is r. If the distance between relay nodes j and k do not exceed For all j, For MHDTM, When describing MHDTM, When describing SHDTM, Let A sensor node s is a favored node of j if
s is not essential to j, s is covered by j, and Two relay nodes j and k may cover a sensor node and have A relay node j is saturated, if and only if the cluster ℂ denotes the set of relay nodes that can accept, from more heavily loaded relay nodes, additional sensor nodes in any given iteration. For SHDTM, relay node For MHDTM, relay node
j is not a saturated node, and accepted_list is the list of sensor nodes sent by
A summary of the notations used to describe the algorithms is given in Table 1 for convenience.
Notation.

3.3. Distributed Clustering for Single-Hop Routing (DCSR)
The DCSR heuristic uses a top-down, iterative approach for clustering. We first obtain an initial assignment of sensor nodes to clusters. This can be done using any existing clustering technique, such as greedy clustering (GC) or least-distance clustering (LDC) [14, 16]. Based on this initial clustering, we calculate an initial value for the network lifetime, which provides a lower bound for the overall network lifetime. In each successive iteration, we form a new set of clusters, by reassigning one or more sensors from relay nodes having high energy dissipation, to other nodes with lower energy dissipation. The new sensor assignment is such that the overall network lifetime is never lower than that of the previous iteration. This process terminates when the specified stopping criteria (e.g., specified number of iterations completed or change in lifetime over a period of time is below a given threshold) have been met. The DCSR algorithm (Algorithm 1) has three phases, as described below.
(1) ∖∖ PHASE 1: Sensor Identification (2) Sensor nodes broadcast “hello” message. (3) Each relay node discovers the sensor nodes it can cover and exchanges this information with its neighbors. (4) Each relay node also broadcasts its own distance from the base station to its neighbors (5) ∖∖ PHASE 2: Cluster Initialization (6) Each relay node and “favored” sensor nodes. (7) Each relay j node broadcasts its current values of (8) (9) (10) Each relay node j checks to see if (11) (12) y accepts sensor node(s) from one or more neighboring clusters into (13) y broadcasts updated value of (14) (15) (16) k updates broadcasts this information to its neighborhood. (17) (18)
Algorithm 1: Distributed clustering for single-hop routing (DCSR).
PHASE 1: Sensor Identification
During the sensor identification phase (lines 1–4 of Algorithm 1), each relay node
PHASE 2: Cluster Initialization
Once each relay node is aware of the set of sensor nodes covered by itself and its neighbors, the cluster initialization phase (lines 5–7 of Algorithm 1) begins. During this phase, each relay node s is an essential node for cluster s is a favored node of j.
Since each sensor node s is either an essential node or a favored node of exactly one relay node j, this approach ensures that a sensor node is always assigned to exactly one cluster, and hence guarantees a feasible initial clustering. Each relay node then broadcasts, to its neighborhood, its current cluster
PHASE 3: Iterative Cluster Refinement
The third and final phase (lines 8–18 of Algorithm 1) is an iterative process, where we modify the current clustering scheme (either the initial clusters or the clusters obtained during the previous iteration) to generate a set of new clusters, which improve (or at least maintain) the overall network lifetime. In each iteration, after a relay node j has received the current cluster information from all its neighbors, it determines whether
3.4. Distributed Clustering for Multi-Hop Routing (DCMR)
In order to handle arbitrary multi-hop routing schemes, we need a more generalized form of our initial DCSR algorithm. In the case of multi-hop networks, relay node j, in general, sends data to the base station B through a multi-hop path
Multi-hop routing introduces additional complexities into the clustering scheme, since the decision to include a sensor node in cluster PHASE 1: sensor identification, PHASE 2: cluster initialization, PHASE 3: iterative cluster refinement.
(1) ∖∖ PHASE 1: Sensor Identification (2) Relay node j determines (3) ∖∖ PHASE 2: Cluster Initialization (4) j initializes (5) ∖∖ PHASE 3: Iterative Cluster Refinement (6) (7) j waits until it receives a down-stream message from each of its predecessors (i.e., nodes (8) j computes the value of message to (9) (10) j computes and sends, as an up-stream message to all of (11) (12) j waits until it receives the values of from its successor k (i.e., (13) j determines and communicates the values of (14) (15) j broadcasts the values of (16) j waits until it receives a down-stream message from each node (17) (18) j prepares a request list of sensor node(s) it proposes to accept into from cluster (19) (20) j combines all request lists it has received, and its own request list (if any) and eliminates requests that it cannot handle. (21) j communicates a down-stream message containing the updated request list to (22) j waits until it receives an up-stream message from (23) j updates and sends accpeted_list to all (24) j broadcasts, to nodes it has included in (25) j excludes, from (26)
Algorithm 2: Distributed clustering for multihop routing (DCMR).
The first two phases are almost identical to those in DCSR. During PHASE 1, each relay node j discovers the set
Iterative cluster refinement (PHASE 3, lines 5–26 of Algorithm 2) comprises the major portion of the DCMR algorithm. In this phase, we use the term “down-stream” to describe messages going from a relay node towards the base station and “up-stream” for messages going away from the base station. A single iteration of PHASE 3 consists of three main subtasks that each relay node j in the network must perform.
(a) Collect Critical Energy Information (Lines 7–15 of Algorithm 2)
In this first subtask of phase 3, our goal is to determine
(b) Create List of Potential Sensor Nodes to Be Included in ℂ (Lines 16–21 of Algorithm 2)
During this subtask, each relay node j determines the sensor nodes it should accept, if any, from other clusters and sends a request for this reclustering towards the base station. It also forwards reclustering requests from its up-stream nodes, which use j as an intermediate node in their respective paths to the base station. In order to determine if j is a potential candidate for accepting sensor nodes in the next iteration, node j first checks if
(c) Update Clusters (Lines 22–25 of Algorithm 2)
This is the last subtask in phase 3 where node j, if applicable, updates its cluster by including some sensors from other clusters, or by shedding some sensors to be acquired by other clusters. The accepted_list received by node j, from its down-stream neighbor
When node j completes all steps in an iteration, a valid clustering is formed with an overall lifetime no less than the previous clustering. This process continues, in an iterative manner, until the “stopping-criteria” are met. The stopping criteria can be based on a predefined number of iterations, a threshold limit for the relative amount of improvement, a combination of these factors, or any other suitable means. For our simulations, we allowed the iterations to continue until a stage is reached where there is no significant update in any cluster.
We note that a “valid cluster” is an assignment of sensor nodes to different cluster heads (relay nodes), such that each sensor node is assigned to exactly one cluster head and this cluster head is within its transmission range. It is easy to see that, in each iteration, the proposed distributed algorithms will produce a solution that is never worse than the previous iteration. In this sense, the algorithms converge towards the best solution within a given stopping-criteria. However, it is not guaranteed that the solution will be an optimal solution. Considering this as a convergence problem and developing techniques for improving convergence speed present an interesting extension that can be addressed in future work.
4. Experimental Results
4.1. Experimental Setup
We have studied the performance of our distributed clustering schemes through simulations. We considered two different network configurations, the first with 12 relay nodes, covering an area of 160 m × 160 m, and the second with 24 relay nodes, covering an area of 240 m × 240 m. The number and the positions of the relay nodes are determined, based on the distribution of sensor nodes, using an existing placement scheme proposed in [7]. For each configuration, we generated the sensor locations randomly, with the number of sensor nodes varying from 75 nodes to 1000 nodes. We set the transmission range of each relay (sensor) node to 100 m (40 m). We calculated the energy dissipation and network lifetime using the models given in Section 2, and followed [2] to set the values of the constants as given below:
path loss exponent,
For a given network and a given number of sensor nodes, we randomly generated 10 different sensor node distributions. For each relay/sensor node distribution, we compared the performance of our heuristics with the following existing clustering approaches [14, 16]:
Greedy Clustering (GC). In GC, each relay node works in sequence and greedily picks all sensor nodes which may communicate with the relay node under consideration Least Distance Clustering (LDC). LDC, a relay node j picks a sensor node s, if j closest to s among all relay nodes and j lies within the transmission range of s. ILP for Single-Hop Routing (ILP-S). ILP-S is an approach based on an integer linear program (ILP) formulation [16] that produces optimal results, for networks using SHDTM. ILP for Multi-Hop Routing (ILP-M). ILP-M is based on an ILP formulation [16] that produces optimal results for networks using MHDTM.
We obtained the results for ILP-S and ILP-M using ILOG CPLEX [21] and used custom-made simulators to obtain the results for the other approaches. In order to evaluate the performance of our distributed algorithms, it is important to take into consideration the energy overhead incurred by the relay nodes during the clustering phase. We did this by applying a penalty, equivalent to the energy required to transmit a 1 kb packet over a distance of
4.2. Performance Evaluation for DCSR
In this section, we have presented the simulation results for our DCSR approach, where the network uses SHDTM. Our objective was to cluster the sensor nodes around the relay nodes, such that the maximum energy dissipation of a relay node is minimized. Based on the N-of-N lifetime [4] considered in this paper, this is equivalent to maximize the network lifetime, as discussed in Section 2. Figure 2 (Figure 3) shows the average lifetime, counted by the number of rounds, achieved by these approaches for networks with 12 (24) relay nodes, where the number of sensor nodes differed from one network to another. In each figure, the lifetimes are shown in the order GC, LDC, DCSR, and ILP-S. Both Figures 2 and 3 demonstrate that the proposed approach not only significantly outperforms existing clustering techniques (GC and LDC) with improvements in the range 30%–40%, it produces results very close to the optimal solution obtained using ILP-S.

Lifetimes for a 12-relay node network with different clustering methods.
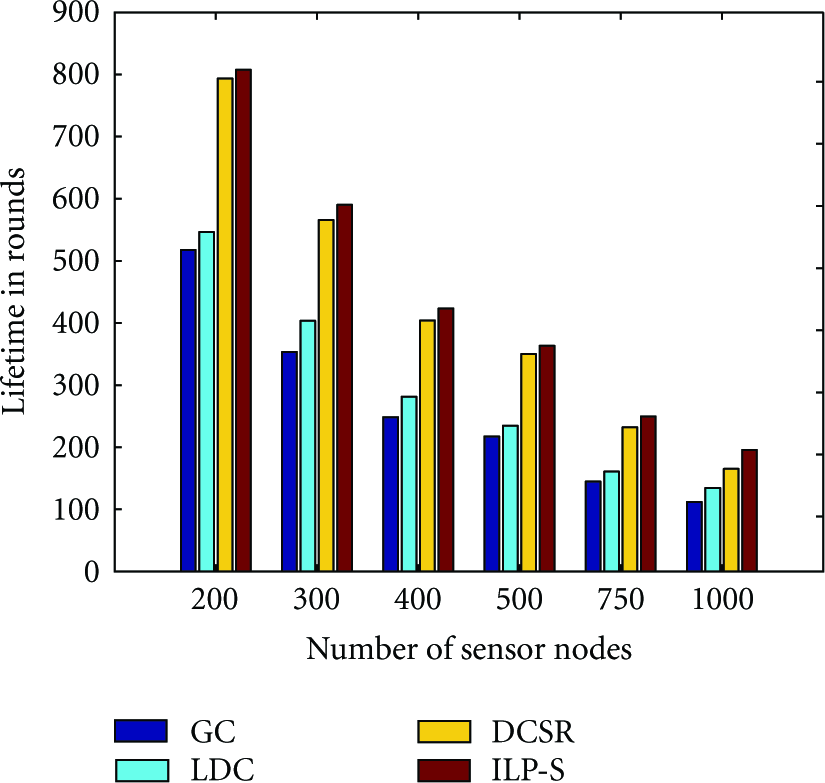
Lifetimes for a 24-relay node network with different clustering methods.
Table 2 shows the relative performances of the different clustering approaches with respect to the optimal lifetimes (computed by ILP-S) for networks with 24-relay nodes each. The results for networks with 12 relay nodes is similar. We see that, on an average, GC and LDC never achieve more that 70% of maximum lifetime, while DCSR can typically achieve 84%–98% of the maximum lifetime on average. As the network size and the number of sensor nodes increase, there is a wider gap between DCSR and the optimal solution.
Percentage of optimal lifetime achieved by different approaches on the 24 relay node network.

4.3. Performance Evaluation for DCMR
In this section, we have presented the simulation results for our DCMR approach. Since DCMR takes into consideration the specific routing scheme, we used two well-known strategies for multi-hop routing.
Minimum-Transmission Energy Routing (MTER). In MTER [2, 16], each relay node transmits to one of its nearest neighbors, which is closer to the base station (or to the base station itself). Minimum-Hop Routing (MHR). In MHR, each relay node finds a path to the base station, such that the number of hops required is minimized.
Figure 4 (Figure 5) show the average lifetimes obtained using existing heuristics (GC and LDC) compared to our approach (DCMR) and the optimal solution (ILP-M), for MTER on a 12- (24-) node network. The results indicate that DCMR consistently outperforms existing heuristics, although the differences in the overall lifetimes are not as high as for the single-hop case. We attribute this to
the cost associated with the additional broadcasts required by each relay node to update the energy information of the entire path, and the lack of global knowledge about the networks by each relay (each relay node has only local knowledge).

Network lifetimes for a 12-node network with different clustering methods when MTER routing is used.

Network lifetimes for a 24-node network with different clustering methods when MTER routing is used.
However, as shown in the figures, the lifetime achieved by our approach is always within 10% of the corresponding optimal lifetimes, obtained using the ILP-M formulation.
Figure 6 shows the average lifetimes obtained for a network with 24 nodes, where the transmission range of the relay nodes is set to 100 m using (a) existing heuristics (GC and LDC), (b) the optimal solution (ILP-M), and (c) the distributed clustering algorithm DCMR. We have noticed that, in most situations, LDC performs better than GC. However, there are some cases where GC outperforms LDC. One advantage of our proposed approach is that we can use any existing clustering scheme to form the initial cluster. Therefore, our approach is guaranteed to be as good as any specific clustering scheme (e.g., GC, LDC), since we can use the specific clustering scheme during the cluster initialization phase itself.

Network lifetimes for a 24-node network with different clustering methods when MHR routing is used.
We note that, in our simulations, the sensor nodes were distributed randomly over the entire sensing area. For this type of distribution and the number of sensor nodes we considered, the lifetime of the relay nodes were determined primarily by the distance over which they had to transmit data. So, for SHDTM, the nodes farthest from the base station depleted their energy much quicker, and since the network lifetime, based on N-of-N-lifetime metric, is over as soon as the first node dies, the overall lifetime for SHDTM has been found to be lower, as compared to MHDTM. However, we would like to note that for very densely populated networks, the load (total amount of data to be transmitted) on a relay node may become more important than the transmission distance. In such cases, SHDTM would be expected to perform better.
In MHDTM, each relay node transmits over a relatively smaller distance. So, the effect of moving a few sensor nodes from one cluster to another does not have as big an impact on the energy consumption of a relay node as it would for SHDTM, where a node might transmit over a much larger distance. So, the effects of clustering are not as pronounced for MHDTM.
5. Conclusions
In this paper, we have proposed the concept of “routing-aware” clustering for sensor networks that takes into consideration the effect of different routing strategies and adapts the clusters accordingly. We have developed two distributed clustering algorithms based on this concept—the first (DCSR) for single-hop routing and the second (DCMR) for multihop routing. The proposed approach is suitable for autonomous systems without any centralized control and provides quick, efficient solutions for networks with hundreds of sensor nodes. A useful feature of our approach is that each iteration of the algorithms DCSR or DCMR generates a feasible solution, and the network lifetime is guaranteed never to decrease as a result of cluster reassignments in future iterations. This means that our algorithm can be used in conjunction with any clustering heuristic (e.g., GC or LDC) to generate an initial cluster assignment. Then the iterative steps can be applied to further extend the network lifetime.
Through simulations, we have demonstrated that both DCSR and DCMR can produce results that are close to the optimal solutions obtained using ILP-based optimization approach. For a given set of relay nodes, the network lifetime decreases, as expected, with the increase of number of sensor nodes. However, in all cases, our approaches consistently outperform existing clustering algorithms, which do not consider the routing schemes used for data transmission.
Footnotes
Acknowledgment
The work of A. Jaekel and S. Bandyopadhyay has been supported by research grants from the Natural Sciences and Engineering Research Council of Canada (NSERC).