
Abstract
More often than not, wireless sensor networks (WSNs) are deployed in adverse environments, where failures of sensor nodes and disruption of connectivity are regular phenomena. Therefore, the organization or clustering of WSNs needs to be survivable to the changing situations. On the other hand, energy efficiency in WSNs remains the main concern to achieve a longer network lifetime. In this work, we associate survivability and energy efficiency with the clustering of WSNs and show that such a proactive scheme can actually increase the lifetime. We present an easy-to-implement method named DED (distributed, energy-efficient, and dual-homed clustering) which provides robustness for WSNs without relying on the redundancy of dedicated sensors, that is, without depending on node density. DED uses the information already gathered during the clustering process to determine backup routes from sources to observers, thus incurring low message overhead. It does not make any assumptions about network dimension, node capacity, or location awareness and terminates in a constant number of iterations. The correctness of the algorithm is proved analytically. Simulation results comparing with contemporary approaches demonstrate that our approach is effective both in providing survivability and in prolonging the network lifetime.
1. Introduction
Compared to nodes in mobile ad hoc networks (MANETs), nodes in wireless sensor networks (WSNs) are more power constrained and have limited memory, computation, and transmission capabilities. In most applications, sensors are immobile and left unattended once deployed. These unique features necessitate novel algorithms suited for WSNs [1].
Clustering is a proven effective approach for self-organizing large WSNs into a connected hierarchy [2]. A WSN is partitioned into small groups called clusters. Each cluster has a coordinator called the cluster head (CH) to whom other member nodes (MNs) of the cluster communicate. CHs conduct data aggregation and send results to the sink. Thus, CHs form the virtual backbone of the network. Data relay may be single hop or multihop [3], and the hierarchy may have multiple tiers [4]. In Figure 1, a two-tier WSN is depicted. Besides achieving higher throughput due to reduced packet collisions, clustering has other desirable features related to energy conserving, network management, security, and scalability [5].

An example of clustered WSNs.
In recent years, the interest in clustered WSNs has generated a significant body of research works, most of which vary in assumptions about the WSN architecture, for example, global positioning system (GPS) capability [6–9], node mobility [10–13], presence of specially powerful nodes [6–8, 14], continuous or event-driven data delivery models [15, 16], and so on. The clustering algorithms also differ in their objectives. For example, in ACE (Algorithm for Cluster Establishment) [17], the aim is to form highly uniform clusters within a constant number of iterations, whereas in [18], dense clusters are favored to elect the minimum dominating set of CHs; and in WCA (weighted clustering algorithm) [11], limited-sized clusters are produced to prevent the degradation of media access control (MAC) performance. Examples of studies in which the ways to achieve an objective differ are clustering algorithms in [19–21], where energy efficiency is the objective. However, the ultimate reason to save energy in the clustering of WSNs should be the extension of network lifetime.
To prolong lifetime, we need to compensate for the large difference in power consumption between a CH and an MN. By and large, two approaches are followed in WSNs: load-balanced clustering [5–7, 22] and periodic rescheduling of CHs [23–25]. The load-balanced algorithms focus on balancing the intracluster traffic [7], or both the intra- and intercluster traffic [5, 6]. The authors in [22] minimize total energy consumption which does not necessarily maximize network lifetime [5]. A drawback of these designs is that CH positions are relatively fixed. A node which works as a CH for a long time is vulnerable to attack and single-point failure. The other approach to extend lifetime is to dynamically rotate the duty of CHs among sensors as in LEACH (low-energy adaptive clustering hierarchy) [23] and HEED (hybrid energy-efficient distributed clustering) [24]. In [25], several disjoint dominating sets are found and activated successively. These solutions, again, do not provide stability and robustness. A small modification in the network topology due to failures implies that new computations are needed to rebuild clusters and to re-elect CHs, thus incurring excessive overhead.
Both permanent and transient failures are inevitable in WSNs. These range from predictable failures (e.g., gradual energy drain of a sensor) to unexpected crashes (e.g., sudden enemy attack in battlefield monitoring). The failure of a CH is more detrimental than that of an MN. A failed CH may cause a cluster to remain isolated until the next reclustering. Meanwhile, important data from sensors cannot be reported and may be lost. This problem imposes a great need for dependable and survivable clustering, that is, clustering that is resistant to failures [26–28].
In this paper, we propose a rotation-based technique named DED (distributed, energy-efficient, dual-homed clustering) for WSNs, where the clustering itself provisions dual-homed protection for each sensor. The information gathered during clustering is used to “absorb” failures to minimize early reclustering. As a result, WSNs experience relatively stable clustering, reduced overhead, and prolonged lifetime. Our main contribution over other conventional schemes is that we provide survivability without the deployment of redundant sensors (i.e., independent of node density) and without the need of an extra layer of CHs. A notable consequence of our approach is that the neighborhood information is used to achieve survivability in a decentralized fashion (i.e., providing survivability at node basis), which is more fault tolerant and load balanced than centralized counterpart (i.e., providing survivability at cluster basis). We neither use dedicated energy-affluent nodes to serve as CHs nor use location-aware sensors. We prove the correctness of our algorithm analytically and compare the simulation results with other related works.
The rest of this paper is organized as follows. Section 2 briefly surveys earlier literature. Section 3 defines the network model and our objectives. Section 4 presents the details of the proposed protocol. Section 5 establishes the effectiveness of DED via extensive simulation, followed by the conclusion section. For the convenience of readers, the notations used in the description of the algorithm are summarized in Table 1.
Notation used in the description.
2. Related Work
We classify related studies into two categories: those that deal with general robustness issue in WSNs without concerning clustering protocols (e.g., fault-tolerant hardware and software design) and those that integrate robustness with clustering schemes. We are interested in the second category only. For a further review, please refer to [29, 30].
In [8], the authors show how to recover from a gateway collapse without reclustering and without predeployment of redundant gateways. Their gateways are not power constrained and sensors are GPS capable. A node density-based clustering algorithm is suggested in [10] for increased stability in dynamic wireless networks. Self-stabilization is attained by minimizing the maximum number of nodes that need to change their topology information as a result of node mobility. In [31], overlapping multihop clusters are formed that have expedited recovery of nodes after CH failures. In [32], a rigorous analysis of the k-fold dominating set problem for a synchronous communication model is presented. A distributed approximation algorithm for general graphs and a randomized algorithm for unit disk graphs are given. However, none of the works above has energy awareness as an issue.
In [14, 33, 34], both network lifetime and robustness are discussed. REED (robust energy efficient distributed clustering) [33] is a distributed method which constructs k independent CH overlays on the top of the physical network. This method requires each sensor to reach at least one CH from each overlay, and its success depends on the node density. Even for 2-connected overlays (i.e.,
3. Problem Statement
Let us consider a set of quasistationary and GPS-incapable wireless sensors that are dispersed randomly on a field. All sensors are equally significant and have similar processing and transmission capabilities (as in [23, 24, 31, 33]). That is, specially competent nodes are not supposed to be responsible for CHs. Due to man-made and natural reasons, failures of sensors may occur at any time.
Our primary goal is to find a distributed, energy-aware, probabilistic cluster formation algorithm that achieves fault tolerance by providing alternate routes from sources to observers (i.e., providing dual-home protection) without explicitly demanding dedicated CHs as backup services. Each regular node should have a primary CH and a secondary backup which may be either another CH or a neighboring MN. Data is forwarded to the secondary destination in case the primary CH fails. Figure 2 illustrates how sensors may be dual homed. Here, node x is backed up through the directly reachable CH of a different cluster. Since no such CH is found for node y, it is backed up by an MN of a neighboring cluster (thus utilizing multihop-based forwarding). In the third case, as for node z, the backup is a neighbor y who has the same primary CH (thus using the neighbor's backup). In the worst case where none of above dual-homing schemes is feasible (this may happen when the CH is the only neighbor of an MN), an MN itself may become a CH after its designated CH fails. Observe that our dual-homing scheme, unlike the traditional dual-homing proposals, does not enforce redundant idle backups and is independent of node density.
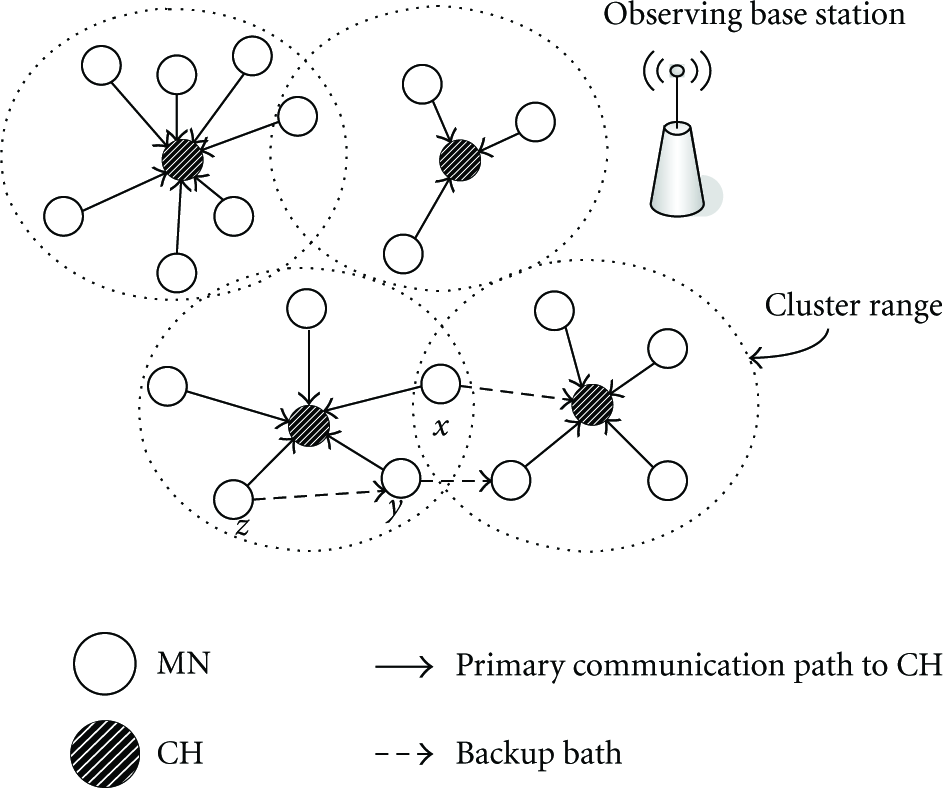
Different dual-homing schemes are shown for sensors x, y, and z.
We notice that providing protection for the entire cluster as a whole through a backup CH is worse than providing protection for each sensor node independently. The first approach requires that each member of the cluster be informed and comply unanimously with the designated backup CH. Therefore, the extra energy needed for establishing such a protection is not less than that for providing survivability at the sensor node granularity. Furthermore, the second approach accomplishes fault management in a noncentralized fashion. Such a distributed fault tolerance arrangement becomes important when multiple failures occur in the same locality. Figure 3 shows how MNs of a cluster are reaffiliated to the neighboring clusters using previously collected backup information after their CH in Figure 2 fails. Thus, multihop clusters are formed, and the triggering of reclustering is avoided. Since reaffiliation (i.e., partial reclustering) incurs less communication overhead than complete reclustering, it conserves energy.
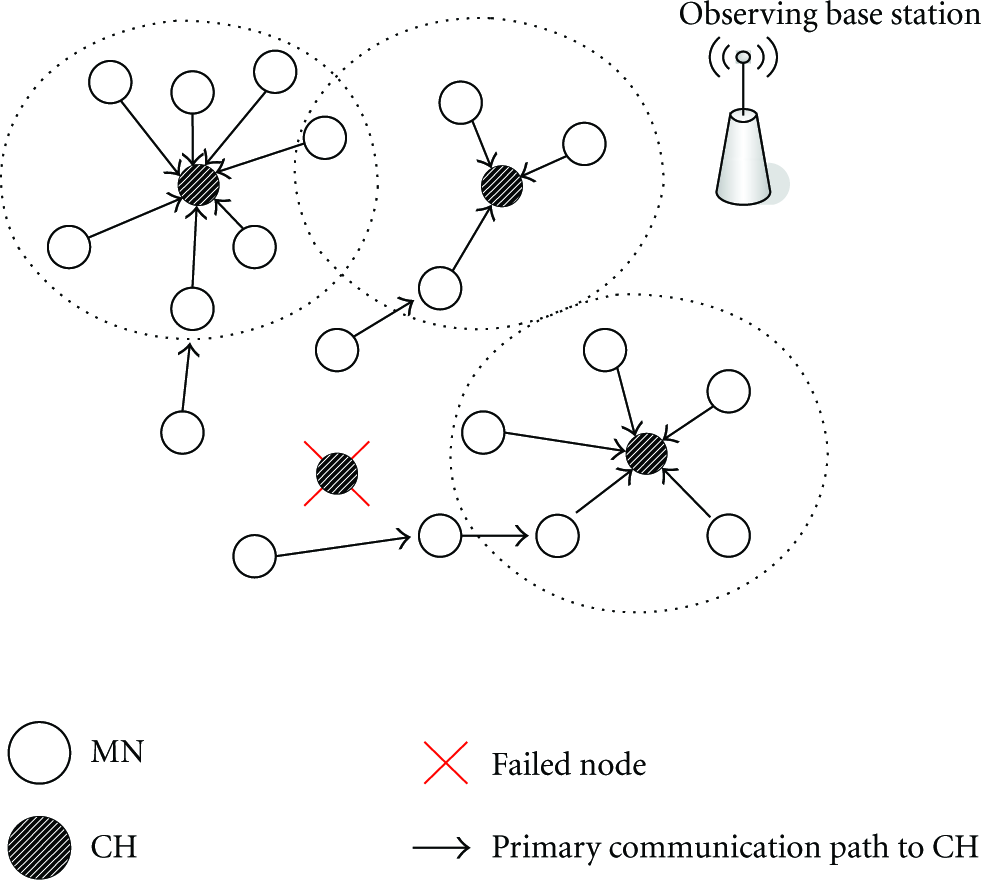
Re-affiliation of MNs are shown after a CH failure.
4. The Design of DED
In this section, details of the algorithm, including the parameter selections and the analysis, are presented.
4.1. Clustering Criteria
To lengthen WSN lifetime, the remaining lifetime of each sensor should be an important consideration during clustering. To explain further, the CH selection process can be viewed from two perspectives: initially a few nodes advertise themselves as tentative CHs (1st perspective) and eventually MNs select nodes from these advertised nodes as final CHs (2nd perspective).
From the 1st perspective, to be in the list of tentative CHs, a node tests itself whether it can work as a CH for a reasonable length of time without much energy loss. That is, it calculates remaining energy,
Note that both in [24, 33], a tentative CH is nominated based on the ratio of the residual energy and the maximum energy (when the battery is fully charged). This method does not necessarily encounter the remaining lifetime of a sensor, since it overlooks
From the 2nd perspective, every sensor tries to optimize lifetime while choosing the final CH from the tentative CHs that are advertised to it. We designate this secondary evaluation parameter as cost. In fact, cost breaks ties among multiple candidate CHs. MNs can use
4.2. Algorithm
The pseudocode of DED is given in Algorithm 1. In brief, each node independently executes the algorithm. Based on message exchanges containing corresponding clustering parameters, each node becomes either a CH or an MN. Using the same information, backup nodes are also decided. After a constant time interval, all nodes finish choosing CHs and backups. In Algorithm 1, we do not show message receptions, for example, updating the set of tentative CHs,
Phase I: Initialization (1) (2) Compute cost and probability (3) Broadcast a clustering initiation message (4) myCH ← NULL (5) myBackup ← NULL Phase II: Cluster Head Selection (6) while (7) if (8) if (9) broadcastCH (myID, cost, TENTATIVE) (10) else if (random(0, 1) ≤ (11) broadcastCH (myID, cost, TENTATIVE) (12) (13) endwhile (14) Remove those CHs from (15) if (16) myCH ← myID (17) broadcastCH (myID, cost, FINAL) (18) else myCH ← leastCost ( (19) joinCluster (myID, myCH) Phase III: Backup Selection (20) if (myCH ≠myID) (21) if ( (22) myBackup ← 2ndLeastCost ( (23) else myBackup ← randomly select a neighbor which is in the FINISH state and whose cluster head is not equal to myCH (24) if (myBackup = NULL) (25) my Backup ← randomly select a neighbor which is in the FINISH
state and whose backup is not equal to myCH
(26) if (myBackup = NULL) (27) myBackup ← myID (28) broadcast (myID, myCH, myBackup, FINISH)
Algorithm 1: Pseudocode of the DED protocol.
The algorithm is divided into three phases for clarity. Phase I initializes the parameters and variables. At the start of clustering, the set of neighbors is needed to compute cost and 
In Phase II, each node waits for the announcements of CH candidates that are advertised based on
In Phase III, the backup is determined locally from the information that a sensor collected at the end of previous phase. The preferable backup of an MN is another CH within cluster range, if any. Otherwise, the node randomly chooses one of its neighbors whose CH is different from its own CH. If no such neighbor is found, the node picks up a neighbor whose CH is the same as its own CH, but whose backup destination is not the same as its own CH. If no neighbors meet these conditions, the node represents itself as the backup. A node can be either a CH or the backup for itself but not both. As long as the WSN is connected, our approach will find two different nodes for the CH and the backup, which is proved in the next subsection. At the end of the algorithm, each node broadcasts a “FINISH” message informing its CH and the backup to other nodes. Although backups are selected from neighbors randomly here, the decision may be directed by some better metrics such as energy remaining, hop count, distance, node degree, or a combination of these attributes.
4.3. Analysis
We first prove that our algorithm finishes within a constant number of iterations.
Theorem 1.
The running time of DED is O(1).
Proof.
The algorithm has only one waiting loop in lines 6–13. Let us assume that it iterates i times before terminating at 
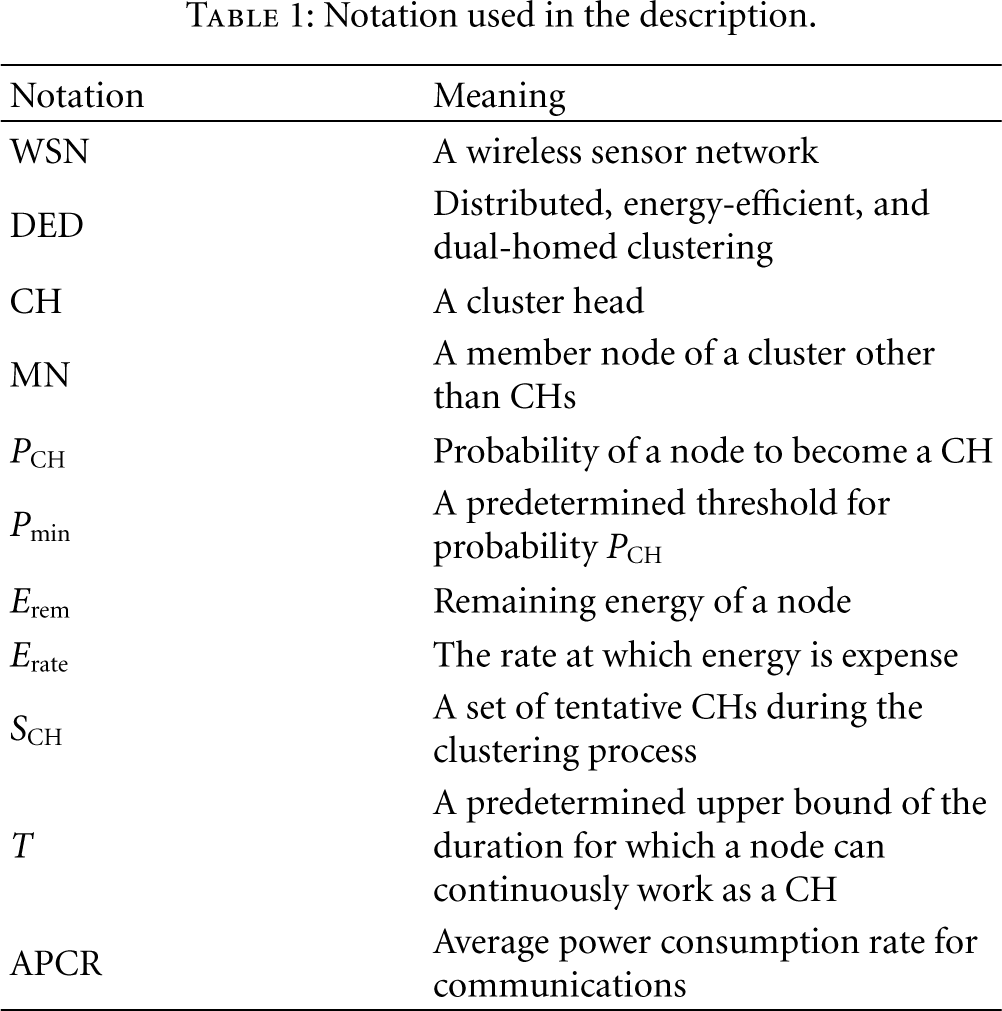
We analyze the message overhead incurred in DED with respect to the prominent clustering algorithm, REED [33]. The reason to select REED in comparison is that like DED, REED focuses on survivability and considers similar clustering assumptions (e.g., absence of extra power nodes for backups, GPS incapability, and so on). We exclude the neighborhood discovery procedure for both cases. In DED, one message is broadcasted at Phase I. At Phase II, there may be zero or one message broadcast in each iteration of the loop 6–13 and one message broadcast in lines 15–19. At Phase III, there is no broadcast if the node is a CH, but one broadcast if the node is an MN. Hence, in the worst case, the three phases of DED require a total of
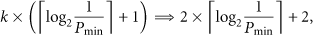

We next prove that the working CH and the backup destination chosen for a node are not the same to ensure survivability upon failures.
Theorem 2.
The CH and the backup for an MN found by DED are different if the nodes in the WSN are connected.
Proof.
Let us consider an arbitrary node x. After the execution of line 14 of the DED algorithm, If Assume that there is a single node in The last possibility, where the cardinality of Case 1.
Case 2.
Case 3.
We ascertain that the backups of MNs do not create a cycle. Otherwise, MNs cannot reach the sink after their CHs crash.
Theorem 3.
The backups of MNs never form a cycle.
Proof.
We will prove Theorem 3 by contradiction. Let there exists a cycle among c (≥2) distinct nodes
First of all, none of these nodes can be a CH, since a CH is not protected by a backup directly in the DED protocol. Also, a node cannot be chosen as a backup until it reaches the “FINISH” state. Let us sort the nodes in the cycle in the order of finishing. Since
5. Performance Assessment
Most of the current simulators for WSNs largely focus on networking issues and are difficult to extend for distributed computing issues [35, 36]. Moreover, no single effort to simulate WSNs is dominant under various assumptions since WSNs are often tailored for specific applications. We develop a C/C++ language-based event-driven simulator to ensure fast and scalable simulation [37, 38]. We use the same simulation model as in [23, 24, 33] for comparison purposes.
5.1. Simulation Model
We use a 2D field of area 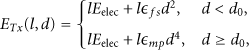

Here,
A node dies after 99.9% energy drainage. Other than this type of regular failure, there may be some unexpected failures. The probability of failing a CH unexpectedly is denoted by F (0%
5.2. Clustering Aspects
We study the effects of different cost functions. A good measure is to see how many clusters have only a single node. The fewer are such clusters, the better is the system organization. As depicted in Figure 4, we find that the number of nonsingle node clusters is increased when the cluster radius is increased. Both

Non-single node clusters in DED.
There are multiple definitions available for network lifetime [2, 39]. Lifetime can be regarded as the time elapsed until the first or last node dies, the time until a fraction of nodes dies, or the time until the WSN becomes partitioned. Using the last definition, Figure 5 plots lifetime for different cost functions. The WSN lifetime is found to be longer when cost is
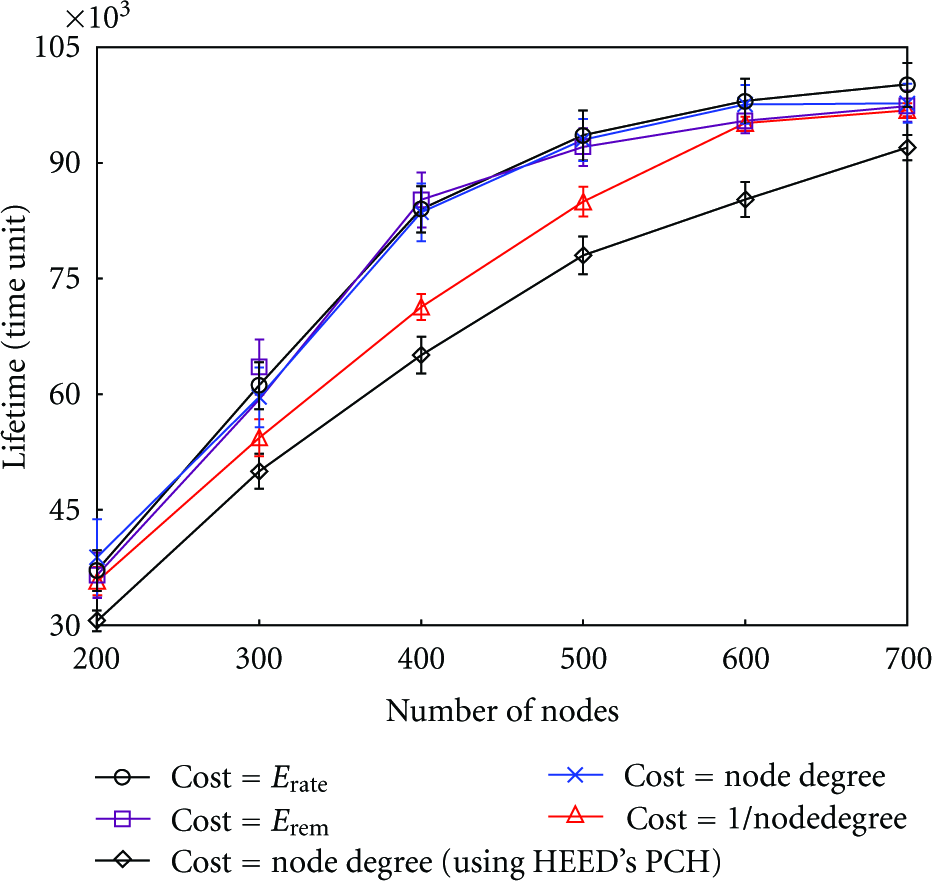
Lifetime at different cost metrics.
We also implement REED [33] clustering protocol for the 2-connected case. Since the two overlays there work independently, the percentage of nodes required to be CHs is found almost double to that of DED as depicted in Figure 6. This percentage is reduced at higher node density and larger cluster radius. Observe that narrower confidence intervals are achieved for the data points in this graph.

The number of CHs selected.
Figure 7 indicates that REED is more expensive than DED in terms of energy too. Clustering energy expended at each sensor is increased at larger cluster radius. Because longer cluster radius causes higher energy expense to send messages. Not only that, it causes higher energy expense to receive messages as the total number of receiving messages is increased due to the growth of neighbors. The growth of neighbors is also observed at higher node density resulting increased energy spent per clustering.

Clustering energy spent per node.
5.3. Fault Tolerance Properties
To view a comparative performance between DED and REED amid unanticipated failures of CHs, we study the first ten clustering rounds of each experiment to segregate failures due to energy depletion. The cost function is set node degree for both protocols. The default clustering radius is 15 meters. Figure 8 shows the increase in the percentage of successful data transmission (w.r.t. single-homed systems) at F = 0.2 and 0.4. Even though REED provides dual CHs per MN (at extra expense), the gain is not much higher (around 5%) than DED.

Comparison of throughput increase.
Figure 9 plots average total energy required (summing over all nodes of a WSN) for each clustering versus the number of nodes for different failure rates. We find that energy spent per clustering is independent of failure rates but goes up with node density.

Energy required per clustering.
Figure 10 shows that the time requirement to finish one clustering process does not differ at different failure rates. However, REED spends much higher time than DED due to the need for higher number of message communications as analyzed in Section 4.3. Unlike energy, time spent per clustering is not elevated with higher node density. The rationale behind this behavior is that clustering algorithms are executed in a distributed manner at each node, and the order of their running time do not depend on node density. In REED, increased node density rather results in fewer selection of proxy CHs, thus saving time a little bit.

Time spent per clustering.
Figure 11 demonstrates that the lifetime of WSNs reduces significantly at higher failure probability. However, increasing the node density prolongs network life. We find that DED achieves the much needed prolonged lifetime, as high as 200% of the lifetime in REED when there is 100% failure probability during normal operation. In REED, although each MN sends data through one of the two designated CHs at a time, all the nodes in WSNs may not be synchronized to use the same overlay. Consequently, the number of nodes serving as CHs during normal operation is higher. Not only that, the clustering process in REED is more expensive. Thus, the simplicity of DED clustering protocol helps it to perform better.
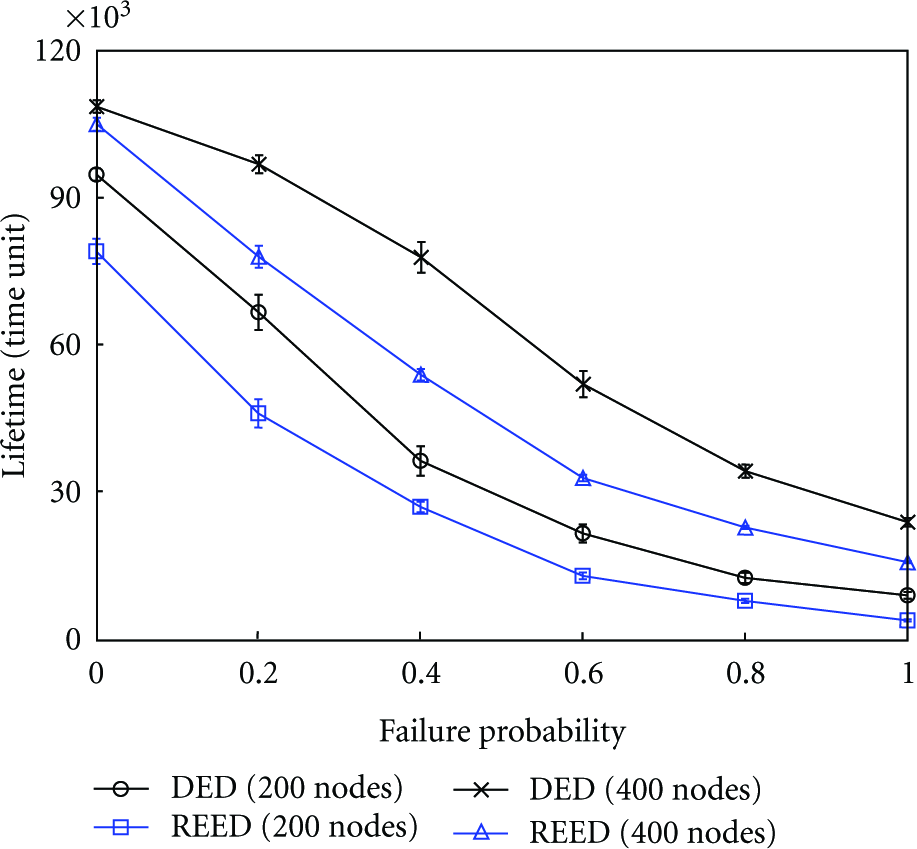
WSN lifetime over failures.
6. Conclusion
In this work, we propose an easy-to-implement, proactive, survivable, and energy-efficient organization scheme, DED, that does not depend on node redundancy for the purpose of fault tolerance, a feature contrasting with most of the survivable protocols suggested so far for WSNs. DED uses the information collected from its neighbors during the clustering process (thus inducing minimal overhead) to provide dual-home protection from failures and to reduce the number of reclustering. Rather than protecting the whole cluster collectively, DED provides backup at the member node level in a noncentralized fashion; this characteristic becomes more important when there are multiple failures in the same locality. The clustering parameters can address heterogeneous initial battery power as well. Analytical proofs of the correctness of the algorithm and simulation-based comparison with other protocols are provided. To the end, our scheme can achieve as much as 200% network lifetime of existing WSN protocols with dual-layer clusters, especially in highly failure-prone environment.
Our future research direction is to apply DED for multi-homing (higher than two) protection capabilities and study the tradeoff between network lifetime and extra energy spent on robustness. Rather than selecting backups randomly from neighbors, the selection may use some better metrics such as energy remaining, hop count, distance, node degree, or a combination of these attributes. We also plan to consider issues such as node mobility, triggering partial clustering in a local region in emergency cases, and forming non uniform cluster sizes by varying cluster radius to prevent a skewed load distribution near the sink [5].
Footnotes
Acknowledgments
This work has been supported in part by NSF Grant no. CNS-0435105. A preliminary and partial presentation of this study has appeared in IEEE Global Communications (GLOBECOM) Conference Proceedings, Washington, DC, Nov. 2007.