
Abstract
Many complex sensor network applications require deploying a large number of inexpensive and small sensors in a vast geographical region to achieve quality through quantity. Hierarchical clustering is generally considered as an efficient and scalable way to facilitate the management and operation of such large-scale networks and minimize the total energy consumption for prolonged lifetime. Judicious selection of cluster heads for data integration and communication is critical to the success of applications based on hierarchical sensor networks organized as layered clusters. We investigate the problem of selecting sensor nodes in a predeployed sensor network to be the cluster heads to minimize the total energy needed for data gathering. We rigorously derive an analytical formula to optimize the number of cluster heads in sensor networks under uniform node distribution, and propose a Distance-based Crowdedness Clustering algorithm to determine the cluster heads in sensor networks under general node distribution. The results from an extensive set of experiments on a large number of simulated sensor networks illustrate the performance superiority of the proposed solution over the clustering schemes based on k-means algorithm.
1. Introduction
Multiple sensor systems have been the target of active research since the early 1990s due to their widespread use in many agricultural, civil, industrial, and military applications that involve environmental monitoring, target tracking, and situational assessment [1, 2]. Recent developments in Microelectromechanical Systems (MEMS) make it now possible to deploy a large number of inexpensive and small sensors to perform complex tasks by obtaining quality through quantity. In some important applications, sensor networks are deployed for remote operations in vast unstructured geographical areas. In such deployments, wireless networks with low bandwidth are usually the only means of communication among the sensors. These sensors are typically powered by irreplaceable batteries with limited energy supply, a large portion of which has to be spent on data communication among sensors and the Base Station (BS). Therefore, minimizing the Total Energy Consumption (TEC) for sensor data gathering is critical to ensuring sustained operations of these large-scale Wireless Sensor Networks (WSNs), even though minimizing TEC does not necessarily maximize network lifetime, which also depends on the balance of residual energy across the network.
It has been well recognized that clustering provides an efficient and scalable way to design and organize large-scale WSNs for energy efficiency of data communication. In a typical hierarchical WSN that deploys a large number of homogeneous or heterogeneous sensors, clusters are formed around a set of strategically selected or randomly designated Cluster Heads (CHs). The sensors within each cluster, often referred to as Leaf Nodes (LNs), collect and send environmental measurements to their corresponding CH, which performs an appropriate form of data processing (i.e., aggregation and compression) and sends the result to a BS for integration with data from other clusters. The BS, which is located either inside or outside the sensor network region, could be wire connected or rechargeable, and hence is often considered to have unlimited energy supply. Apparently, the number and location of CHs in hierarchical WSNs have a significant effect on the energy consumption for data communication from LNs to the BS. Many existing clustering algorithms assume that the number of clusters is predetermined and each CH is also designated a priori or on a random basis [3, 4]. In practice, however, such information on CHs is not always readily available during network implementation and operation, especially when the network is deployed in an unstructured environment with unpredictable disturbances and threats. As a matter of fact, determining the optimal number and location of CHs has been raised as one of the most fundamental problems in clustering-based hierarchical WSNs.
The global knowledge of sensor locations is crucial for determining the optimal number and location of CHs. Once deployed, each sensor can acquire and report its geographical location through a certain location discovery process. The Global Positioning System (GPS) is certainly a very effective but prohibitively expensive solution due to its high cost and the constrained energy supply of sensors. Many other location discovery approaches use received signal strength, neighbor node position, or arrival time difference to estimate the distance between two sensors [5]. Based on the distance estimations, sensors can compute their locations by distance or angle combining (hyperbolic trilateration, triangulation, or maximum likelihood estimation). To make such combining feasible, the computation requires at least two known reference points, which can be obtained through either a GPS or a deterministic deployment.
We investigate the problem of selecting an optimal subset of sensors, which are designated as CHs to form clusters, to minimize the TEC for data communication per round from LNs to the BS in a predeployed WSN under a uniform or general node distribution. We rigorously derive an analytical solution to calculate the number of CHs for minimum TEC in WSNs where nodes are uniformly distributed. In WSNs where nodes are deployed according to an unknown probability distribution, we propose a heuristic algorithm, Distance-based Crowdedness Clustering (DCC), to determine the optimal number and location of CHs. The extensive experimental results on simulated WSNs ranging from small to large scales show the performance superiority of the proposed methods compared to the clustering and optimization schemes based on classical k-means algorithm in terms of TEC for data communication per round. However, the main purpose of these performance comparisons is to recognize the necessity of such CH optimization and illustrate the efficacy of the proposed research approaches. In fact, the proposed optimization schemes, which could be performed offline using global information prior to the actual deployment, are largely orthogonal to the main body of current research efforts on sensor network clustering, and the optimization results obtained by our approaches can be used to effectively guide the operation of, and therefore greatly improve the performance of, the classical clustering algorithms that require a priori knowledge on CHs.
The rest of the paper is organized as follows. We describe related work in Section 2. The energy consumption models are presented and the optimization problems are formulated in Section 3. In Section 4, we derive an analytical solution for WSNs under uniform distribution and develop a heuristic approach for WSNs under general distribution. Implementation details and performance evaluations are provided in Section 5. We conclude our work and discuss future efforts in Section 6.
2. Related Work
In WSNs, a CH, which may collect environmental sensing data as well in some cases, is responsible for receiving, processing, and transmitting data from the LNs in its service area to the BS, and hence it consumes much more energy than an LN. The sensor nodes in the close proximity of a CH may also run out of battery quickly due to frequent data forwarding. Therefore, designating an optimal subset of sensor nodes as CHs at appropriate locations is critical to minimizing the TEC for prolonging the lifetime of the entire network. There exist a large number of research efforts in the literature that have been devoted to solving various clustering problems with different objectives [3, 6–15].
Several clustering algorithms have been proposed to minimize the energy consumption or satisfy the network connectivity requirement with the assumption that the number of CHs is known a priori [3, 4, 12, 16]. Some other researchers tackle the problem of optimizing the number and location of CHs, which is closely related to our work. Kim et al. derived analytical formulas to estimate the optimal number of CHs to achieve the minimum TEC of the entire network, based on the assumption of even partition (i.e., each cluster covers an equal number of sensors) and one-hop communication in both intracluster and intercluster routing [6]. In [7], Wang et al. calculated the optimal number of CHs for a WSN by applying a cross-layer approach from both perspectives of the power efficiency in the medium access control (MAC) layer and the coverage performance in the physical layer. In [9], Xu and Cassandras determined the optimal location of CHs for minimum communication energy consumption in a two-level heterogeneous WSN. They formulated the optimization problem with the constraint that each LN is connected to at least p CHs and each CH has at most q LNs as a Mixed Integer Nonlinear Programming (MINLP) problem and achieved a global optimum based on an iterative decomposition algorithm and a randomized multistart technique. Srinivas et al. studied the problem of minimizing the number of backbone nodes and referred to it as the Connected Disk Cover problem in [17], where they controlled the mobility of the backbone nodes to maintain the connectivity of the network. In [18], Tao and Zheng proposed an improved algorithm that combines the optimal number of CHs with energy adaptive CH selection algorithm based on the classical Low-Energy Adaptive Clustering Hierarchy (LEACH) [3] protocol.
One commonly adopted way to ensure load balance and meet energy constraint of the entire network is to rotate the role of a CH and form a corresponding cluster on a random and periodical basis among all sensor nodes. The classical energy-efficient algorithm, LEACH [3], employed randomized rotation of CHs to evenly distribute the energy consumption among the sensors in the network. Yang and Sikdar [8] applied a sleep-wakeup scheme based on a decentralized MAC protocol to LEACH and further proposed an analytical framework for achieving the optimal probability with which a sensor becomes a CH in order to minimize network energy consumption and prolong network lifetime, assuming uniform distribution of all the sensors. A similar node election strategy that considers the amount of residual energy was also used in [19] with multihop data communication. Du and Xiao presented an energy-efficient Chessboard Clustering routing protocol for heterogeneous sensor networks [20] to balance node energy consumption and increase network lifetime, in which some sensors are initially set to be in sleeping mode and can be activated later on according to a certain procedure. Some research efforts along a different line allow sensors to adjust their locations after initial deployment. Mao and Wu proposed two new sensor location updating algorithms, VFSec and Weighted Centroid, to jointly optimize sensing coverage and secure connectivity [21].
Nonlinear programming has been widely used to model wireless sensor data communication as network flows to minimize TEC in WSNs. Besides [9], Ergen and Varaiya also formulated their problem as a nonlinear programming problem that determines the optimal location of relay nodes and the optimal energy provided to them so that the network is alive during the desired lifetime with minimum total energy [22]. In [23], Dasgupta et al. presented the sensor deployment problem for maximum lifetime with coverage constraints and proposed an algorithm motivated by force-directed/potential field-based approaches in robotics and graph drawing to place and assign the role of each sensor in the system to maximize network lifetime.
The probability of a sensor to be a CH is also considered in some work. Bandyopadhyay and Coyle proposed a distributed and randomized clustering algorithm to organize the sensors in a WSN into clusters, and they further extended this algorithm to generate a hierarchy of CHs and observed more energy savings as the number of levels in the hierarchy increases [24].
The main differences between our work and the aforementioned ones arise from the following aspects: (i) we investigate both uniform distribution and general random deployment for large-scale sensor networks; (ii) we propose both analytical derivation and heuristic algorithm to solve the CH optimization problems; (iii) we consider complete data aggregation and use a compression ratio to reflect the reduction in data size at CHs; (iv) we do not assume even partition of sensor networks as in [6].
3. Network Model and Problem Formulation
3.1. Energy Consumption Model
We consider two different types of energy consumption for data transmission and receiving, respectively: a transmitter consumes energy to run both the radio electronics and the power amplifier, while a receiver only consumes energy to drive the radio electronics. The mobile radio channels on typical sensor nodes are predominantly in the VHF (frequency from 30 MHz to 300 MHz, wavelength from 1 m to 10 m) and UHF (frequency from 300 MHz to 3 GHz, wavelength from 10 cm to 1 m), respectively [25, 26]. Since the intercluster communication distance is typically much longer than the intracluster communication distance, we employ (i) the free space (fs) fading channel model for intracluster wireless communication that incurs a
In a real communication system, the transmission power could be adjusted by suitably configuring the power amplifier. Therefore, the energy dissipation in transmitting one unit of data message over a directed wireless communication link can be modeled as

A CH, which also collects environment sensing data, receives data messages from LNs within the cluster and sends all the data to the BS after performing a certain type of data processing (such as data aggregation and data compression). We use a constant
3.2. Problem Formulation
The problem of determining the optimal number and location of CHs for minimum TEC in sensor networks is formulated as follows. We consider a WSN where n sensor nodes have been deployed in a bounded
We consider the following general conditions or assumptions in our problem formulation.
All sensors are predeployed and have constrained energy supply. The BS is also predeployed and has unlimited energy supply. The network is static, that is, neither the sensors nor the BS has mobility once deployed. The total number of sensors is known. Each CH forms exactly one cluster, and besides data processing, also performs the same task of environmental sensing and data collection as a regular sensor node. There exists a contention free MAC protocol for wireless communication.
We consider the energy consumption for data transmission of each LN, and for data receiving, processing, and transmission of each CH. Since the energy cost for environment sensing is generally much less than communication and processing tasks, we do not consider sensing energy cost here. Obviously, the TEC depends on the network distribution, the number and location of CHs, and the compression ratio α at CHs.
4. Optimizing Number and Location of CHs
4.1. Analytical Derivation for Uniform Distribution
When CHs perform data processing or are responsible for certain intracluster management duties, uniform distribution of sensors among the network is usually a goal for setting up the network, which can also leverage data delay [27]. In LEACH and other similar clustering algorithms, the expected number k of CHs per round is considered as a prefixed system parameter [3, 4, 12, 16]. Here, we shall rigorously derive an analytical formula for calculating the optimal value of k to achieve the minimum TEC of data transfer from LNs to the BS through their corresponding CHs. The optimal k value determined by our approach can be used to guide the execution of the clustering algorithms that require such information.
We first calculate the expected distances from an LN to its CH and from a CH to the BS using an approach similar to the one used in [8]. Since the CHs are uniformly distributed in an

Without loss of generality, we suppose that the BS location
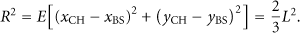
The TEC per round, denoted by





4.2. Algorithm Design for General Distribution
Though uniform distribution is suited for achieving energy balance, it may not always be feasible for practical sensor network applications, especially for those deployed in large and harsh environments not accessible to humans. In such environments, sensors may be airborne or dropped by other appropriate means that could lead to a more general node distribution.
We develop a heuristic algorithm, Distance-based Crowdedness Clustering (DCC), based on a cutoff distance and the concept of crowdedness to solve the CH optimization problem in WSNs under general node distribution. Here, the “cutoff distance” is the threshold that decides which cluster an LN belongs to: if the distance from an LN to the CH is within the cutoff distance, the LN is considered to be located inside this cluster; otherwise, it is not. The concept of “crowdedness”, which is closely related to the number of neighbor nodes of each sensor node, is used to describe the density of sensor nodes in a given region.
In the DCC algorithm, we first calculate the distances
randomly deployed in a and one BS deployed inside or outside the region. minimum TEC. (1) Calculate all-pair distances array (2) Initialize minimum TEC (3) (4) Set cutoff distance (5) Set (6) Sort all in a decreasing order and place them in an array (7) Insert all (8) Initialize a clustered sensor queue (9) Initialize the number of clusters (10) (11) Retrieve (12) Form a cluster (13) Insert all (14) Remove all (15) (16) Calculate the TEC; (17) (18) (19) k = (20)
5. Performance Evaluation
5.1. Implementation and Experimental Settings
The proposed DCC algorithm is implemented in C++ and runs on a Windows XP desktop equipped with a 3.0 GHz CPU and 2 Gbytes memory. We conduct an extensive set of experiments using a wide variety of simulated sensor networks, in which two deployment scenarios are considered: uniform and general distributions. We generate these simulation datasets by varying the size of network regions and the number of initially deployed sensor nodes. The parameters used in the testing sensor networks and the sensor radio characteristics of the energy cost models for wireless communication [6] are tabulated in Table 1. For testing purposes, we consider a fixed value 0.8 for the compression ratio α, which has an impact on the clustering process.
WSN communication parameters.

5.2. Case Study for Uniform Distribution
We first investigate the optimization problem on the number and location of CHs in a sensor network within a square region of

Analytical calculation of TEC per round with
From (8) in Section 4.1, we obtain the optimal number of CHs to be

Analytical calculation of TEC per round with
To evaluate the robustness of our solution, we perform more experiments on networks under uniform distribution with 10 different problem cases from small to large ones: in the first case, the total number of initial sensor nodes is set to be 10; in the rest 9 cases, it increases from 100 to 900 nodes at an interval of 100 nodes. The optimization results, that is, the optimal number of CHs, the expected distance from an LN to its associated CH, and the corresponding minimum TEC in each case, are plotted in Figure 3. We observe that the expected distance from an LN to its CH varies from 32 m to 116 m and it decreases when the optimal number of CHs increases.

Analytical calculation of minimum TEC per round in 10 cases ranging from small to large scales.
5.3. Case Study for General Distribution
To better illustrate the optimization process of DCC in WSNs under general node distribution, we calculate and plot the TEC per round under different cutoff distances at each optimization step for a network of
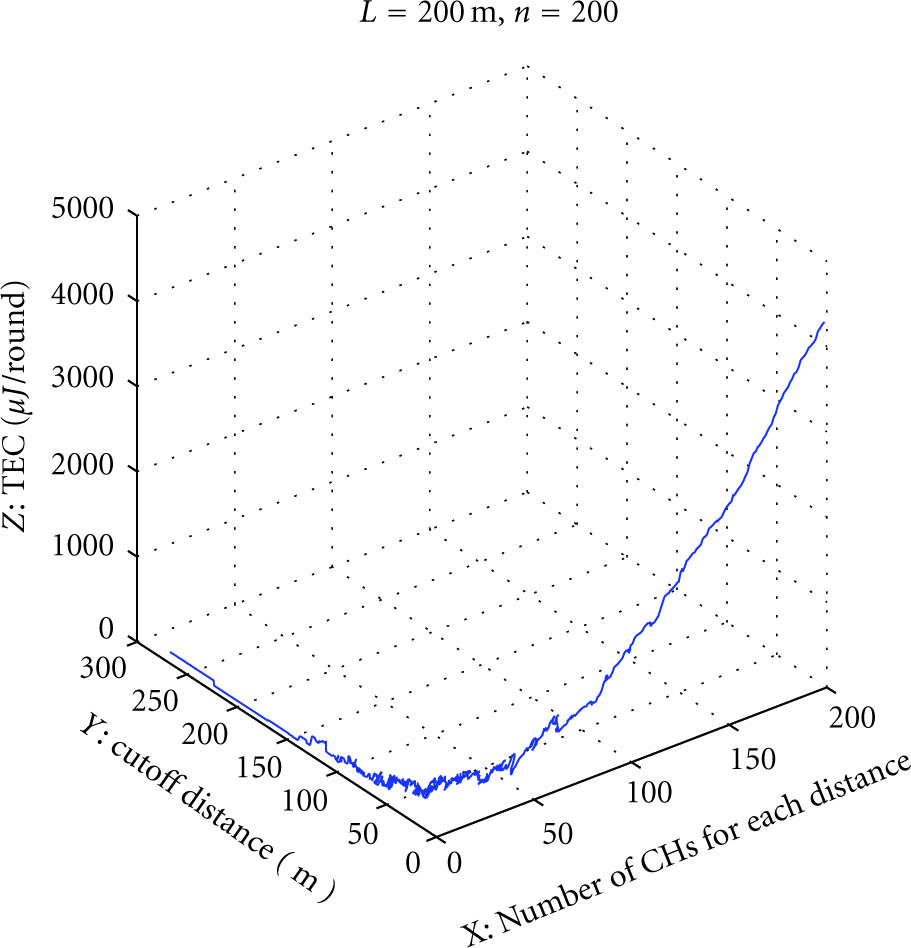
TEC per round at each optimization step using DCC algorithm.
For performance comparison, we adapt the classical k-means clustering algorithm to our problem and compare its performance with that of the proposed DCC algorithm using the same set of 10 problem cases previously considered for uniform distribution. We first determine the optimal number k of CHs and the corresponding minimum TEC using the proposed DCC algorithm, and then use k-means algorithm to perform clustering based on the k value obtained by the DCC algorithm, referred to as deterministic k-means algorithm. For visual comparison, we plot the performance measurements of TEC produced by these two algorithms in Figure 5. The results produced by the DCC algorithm outperform those produced by the deterministic k-means algorithm in all 10 cases we studied, which shows the performance superiority of the proposed DCC algorithm.

Performance comparison between DCC and deterministic k-means algorithms in 10 cases ranging from small to large scales.
For illustration purposes, we lay out the node distribution and clustering of the sensor network with 100 sensor nodes in Figure 6, in which the unclustered solid node denotes the BS. The clustering results obtained by the DCC algorithm are marked by the solid lines, while the results obtained by the deterministic k-means algorithm are marked by the dashed lines. The DCC algorithm produces 20 clusters in this instance.

Visualization of the clustering in a network of 100 nodes using DCC and deterministic k-means algorithms: the results of DCC are marked by solid lines and the results of deterministic k-means are marked by dashed lines.
We further compare DCC with a clustering method completely based on the classical k-means algorithm, in which we iteratively use k-means algorithm to cluster n sensor nodes for n times by varying the parameter k from 1 to n, and select the clustering result with the minimum energy cost. We refer to this clustering method as adaptive k-means algorithm. Two WSNs of problem sizes of 200 and 900 sensor nodes, respectively, are tested using adaptive k-means algorithm, and their partial optimization curves are plotted in Figures 7 and 8. The rest of the TEC values continuously increases as k increases.

TEC per round for each k value using adaptive k-means algorithm.

TEC per round for each k value using adaptive k-means algorithm.
We observe some small random variations on the performance curves produced by the adaptive k-means algorithm. These variations are mainly caused by the following two factors: (i) the k-means algorithm may be trapped in local optimal solutions by only considering the distance from LNs to CHs, while the TEC has to consider the distances from LNs to CHs and from CHs to the BS; (ii) as widely evidenced, the quality of the final solution produced by the k-means algorithm also depends on the initially (randomly) selected set of CHs. We apply the adaptive k-means algorithm to all 10 cases of different problem sizes, and plot the performance measurements in terms of minimum TEC and optimal number of CHs produced by DCC, adaptive k-means, and deterministic k-means algorithms in Figure 9. We observe that DCC achieves the best performance among the three algorithms in comparison and the adaptive k-means algorithm outperforms the deterministic k-means algorithm.
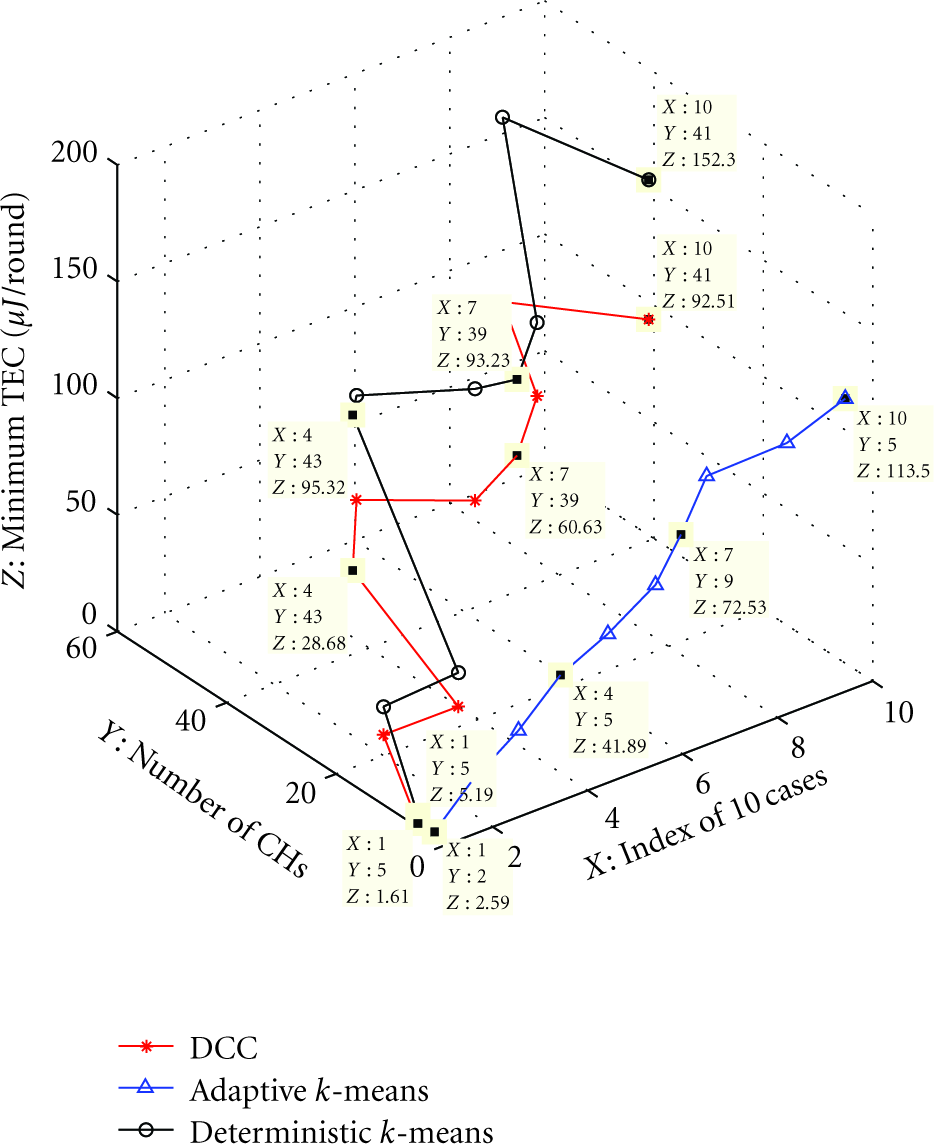
Performance comparison among DCC, adaptive k-means and deterministic k-means, algorithms in 10 cases ranging from small to large scales.
Using the same network instance of 100 sensor nodes, we visually compare the clustering results obtained by the DCC algorithm and the adaptive k-means algorithm, as shown in Figure 10. The 20 clusters marked by the solid lines are obtained by the DCC algorithm (the same DCC clustering in Figure 6), and the 4 clusters marked by dashed lines are obtained by the adaptive k-means algorithm. In Figure 10, we observe that the DCC algorithm achieves a more reasonable clustering result than the k-means-based algorithms in terms of local sensor density.

Visualization of the clustering in a network of 100 nodes using DCC and adaptive k-means algorithms: the results of DCC are marked by solid lines and the results of adaptive k-means are marked by dashed lines.
6. Conclusion and Future Work
We investigated the problem of selecting a subset of sensor nodes as CHs in WSNs to achieve minimum TEC. We considered two energy dissipation models, free space model for intracluster communication and multipath model for intercluster communication. We derived an analytical formula to determine the optimal number and location of CHs in WSNs under uniform distribution and proposed a heuristic clustering algorithm based on distance and crowdedness to optimize the number and location of CHs in WSNs under general node distribution. The simulation results illustrated the performance superiority of the proposed solution in comparison with the clustering schemes based on classical k-means algorithm.
In the present work, we only considered one-hop communications for both intracluster and intercluster data communication under uniform and general node distributions. We will consider multihop routing methods and the balance of sensor nodes in each cluster in our future work. It would also be of our future interest to derive an analytical performance bound of energy cost for the clustering of WSNs under complex and general distributions.
Footnotes
Acknowledgments
This research is sponsored by National Science Foundation under Grant no. CNS-0721980 and Oak Ridge National Laboratory, US Department of Energy, under contract no. PO 4000056349 with University of Memphis.